
基于时频分布的汉语语音关键频率分布研究
2011-03-14 05:12王钟斐王彪
电子设计工程 2011年10期
王钟斐,王彪
(宝鸡文理学院数学系,陕西宝鸡721013)
语音识别(speech recognition)是机器通过识别和理解过程把人类的语音信号转变为相应的文本或命令的技术。其根本目的是研究出一种具有听觉功能的机器,这种机器能直接接受人的语音,理解人的意图,并做出相应的反映[1]。
目前,语音识别技术已成为世界上最热门的技术之一,它以语音为研究对象。因此,掌握语音的关键信息将有助于提高语音识别效果,而本文就是通过时间-频率联合分布来研究汉语语音关键频率分布的情况。
1 汉语语音简介
语音是指人类通过发音器官发出来并且具有一定意义的声音,其目的是进行社会交际。汉语语音[2]的特点是音节结构简单,音节界限分明,声调是音节的重要组成成分。音素是按照音质的不同划分出的最小的语音单位。
音节是语音结构的基本单位,是说话时自然发出、听话时自然感到的最小的语音片断。一般来说,汉语中用一个汉字来代表一个音节。只有儿化韵两个汉字只记录一个音节。音节可以构成词,词可以构成句子。汉语的音节结构有很强的规律性。中国传统把一个音节分为声母、韵母和声调3部分。声母是指处在音节开头的辅音。音节的开头如果没有声母,就是零声母音节。韵母是指音节中声母后面的成分,可以只是一个元音,也可以是元音的组合或元音和辅音的组合。汉语各方言虽然语音分歧相当大,但声母、韵母和声调的基本结构是一致的。
研究汉语语音关键频率分布,要首先研究声母和韵母的频率分布,因为二者结合起来就是汉语语音,了解了声母和韵母的频率分布,就必然能够大体确定汉语语音关键频率分布。因此,下面主要以声母和韵母为例来研究。
2 语音信号时频分析
语音信号时域分析和频域分析都有一定的局限性:前者对语音信号的频率特性没有直观的了解;而后者提供的信息中又没有语音信号随时间的变化关系,即无法标定信号发生的时间位置和发生变化的剧烈程度。因此要想比较准确的分析语音信号,单独依靠时域分析或者是频域分析,是不能完成的。要从时域、频域两方面同时入手,对语音信号进行分析,得到代表其本质的特征参数,才能达到辨析语音的要求。
而时频分析方法就提供了时间域与频率域的联合分布信息,清楚地描述了信号频率随时间变化的关系。其基本思想是:设计时间和频率的联合函数,用它同时描述语音信号在不同时间和频率的能量密度或强度。时间和频率的这种联合函数简称为时频分布。利用时频分布来分析信号,能给出各个时刻的瞬时频率及其幅值,并且能够进行时频滤波和时变信号研究。也就是,借助于时间和频率的联合表示,能够准确地描述非平稳信号的特性,从而能够对其进行分析[3]。
2.1 时频表示
对于非平稳信号,为了得到信号的频率随时间变化的情况,需要使用时间和频率的联合函数来表示信号,这种表示称为信号的时频表示。其目的是将一维时间信号x(n)或频域信号X(ejω)映射成时间-频率平面上的二维信号Px(n,ω)。那么,信号的瞬时能量和功率谱可以分别表示为
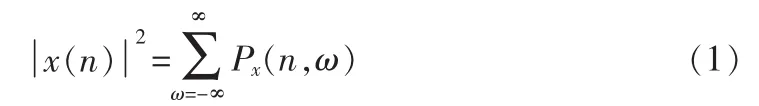
和
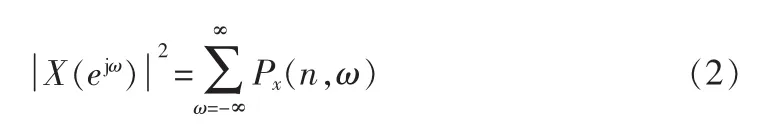
信号在时频域n∈[n1,n2]和ω∈[ω1,ω2]的能量成分表示为:

可以根据函数Px(n,ω)计算在某一特定时间内的频率密度,计算该分布的整体和局部的各阶阵等。
目前,有很多种时频表示方法,主要有线性时频表示、二次时频表示(又称双线性时频表示)。线性时频表示主要有短时傅里叶变换、Gabor变换及小波变换。二次时频表示是由能量谱或功率谱演化而来,特点是变换为二次的。在某些实用场合,要用双线性时频表示来描述描述语言信号的能量密度分布,这种更严格意义下的时频表示就称为信号的时频分布。
2.2 时频分布
能量谱或功率谱具有双线性变换特点,也就是说当信号之间满足下式时

能量谱函数有如下的双线性关系:
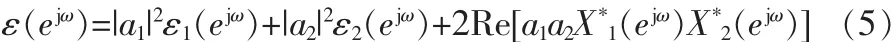
式中,ε(ejω)、ε1(ejω)与ε2(ejω)分别为x(n)、x1(n)和x2(n)的能量谱,而*号表示对信号的频谱取共轭操作。此时,当x1(n)和x2(n)的频谱随时间变化时,根据能量谱或功率谱得到的时频表示Px1(n,ω)和Px2(n,ω)是二次的,则有
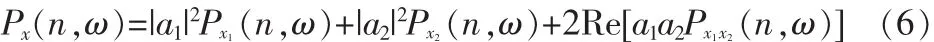
其中,Px(n,ω)是x(n)的时频表示。上式右边的最后一项称为交叉项或互项,而Px1x2(n,ω)称为x1(n)和x2(n)的互时频表示。
此外,其他一些二次型能量化的时频表示可统一的由Cohen L提出的广义双线性时频表示,即
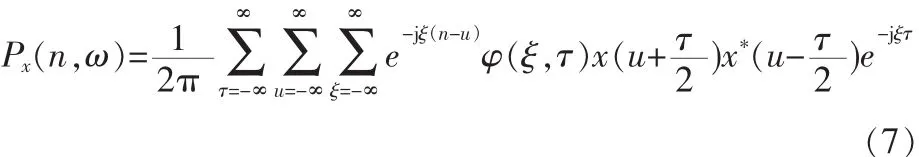
其中,φ(ξ,τ)表示核函数,它决定Px(n,ω)的特性。
采用不同的核函数,会得到不同的时频分布。而对核函数要求是:一能压缩交叉干扰项,二能有好的特性。
2.3 语谱图
语谱图是语音信号短时频谱的时间-强度表示[4]。语谱图是语音信号时频分布的一个比较好的应用。其横坐标表示时间,纵坐标表示频率,每个像素的灰度值大小及颜色的浓淡反映相应时刻和相应频率的能量。能量功率谱具体表示为
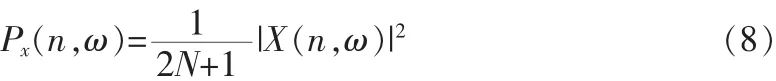
其中,
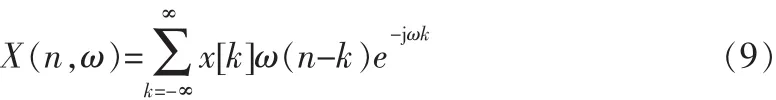
ω[n]是一个长度为2N+1的窗函数,X(n,ω)表示在时域以n点为中心的一帧信号的傅里叶变换在ω处的大小。
下面图1给出了语音“开始”的语谱图。图中横轴表示时间,纵轴表示频率,颜色的深浅表示(n,ω)处的能量大小,一般用能量的对数表示,即lg(Px(n,ω))。语谱图根据带通滤波器的带宽分为宽带语谱图和窄带语谱图。通过语谱图很容易看出语音信号关键频率的分布情况和能量的分布情况。图1(a)和(b)分别是“开始”的宽带语谱图和窄带语谱图。
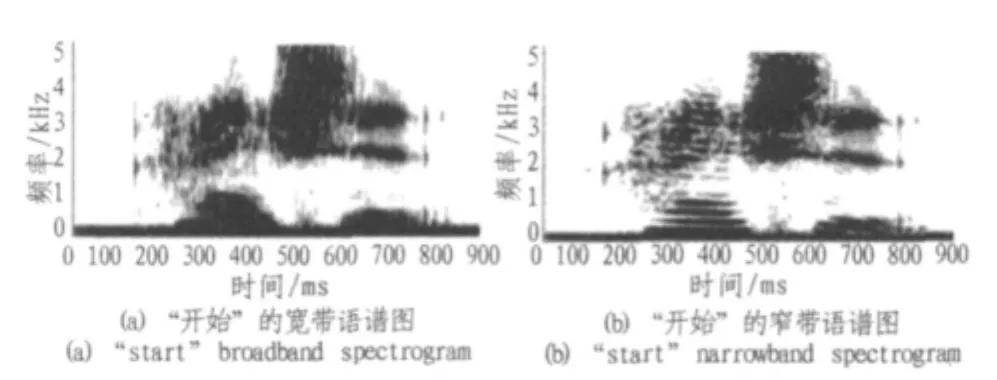
图1 语音“开始”的宽带语谱图和窄带语谱图Fig.1Speech“start”broadband spectrogram and narrowband spectrogram
由于宽带语谱图的频率分辨率较高,时间分辨率较低,因而语谱图呈现的是垂直的条纹;而窄带语谱图则相反,从而呈现的是横向的条纹。从上图中可以看出,条纹较明显的分成两个部分,其中第一部分是汉字“开”的图谱,第二部分是汉字“始”的图谱。
3 语音采集及分析处理
3.1 语音信号采集
本文中所用的语音信号示例分为两类:一是电视台、广播台播音员的标准普通话语音录音,二是现实生活中普通人的普通话录音。这样,语音示例既具有标准语音有具有普通语音,能够比较全面的反映人类语音的大致情况,从而使下面得出的结论具有一定的代表性。
1)电视台、广播台播音员的标准普通话语音录音可以在网络上下载,本文下载了播音员用普通话朗读汉语拼音声明、韵母的语音录音,这样就得到了较为标准的语音信号范本。
2)现实生活中的普通人用普通话朗读汉语拼音声明、韵母,然后通过电脑麦克风进行录音,并保存为.wav的文件格式,音频的位速为352 Kb/s,采样大小为16位,级别为22 kHz,为单声道录音。而这就是普通人的语音信号范本。
上面的两类语音信号范本作为后面的分析处理对象。其中,声母共23个,即:b、p、m、f、d、t、n、l、g、k、h、j、q、x、zh、ch、sh、r、z、c、s、y、w;韵母共24个,即:a、o、e、i、u、v、ai、ei、ui、ao、ou、iu、ie、ve、er、an、en、in、un、vn、ang、eng、ing、ong。
3.2 语音信号分析处理
在前面介绍了时频分布的特点和优势,下面就利用时频分布来处理上一小节中的语音信号范本。在此,本文采用了两类方式进行处理:一是使用语音处理软件Adobe Audition 3.0来播放语音文件,得到其频率-能量-时域图(即语谱图),从图中观察总结其频率分布等重要信息;二是使用自己设计的MATLAB程序来播放语音文件,得到其语谱图,从而观察总结其频率分布等重要信息。两种方式相互验证比较,将使结论变得更全面、更具有说服性。
3.2.1 Adobe Audition 3.0软件处理语音文件
将用Adobe Audition3.0软件分别播放前面的语音信号文件,得到其语谱图,并从中观察总结出其关键信息。但由于声母、韵母较多,在此不一一列举,分别以韵母a、声母b为例。
1)韵母
下面图2是韵母a的语谱图,分别是标准普通话、普通男声和普通女声的图谱。
图2中,横轴表示时间,单位是ms,纵轴表示频率,单位是Hz。图中的带颜色区域表示语音信号在对应时刻所携带的能量,颜色愈亮,表示能量愈大;反之,颜色愈暗,则表示此时刻能量愈小。图中开始和结束的地方颜色发暗发黑,表示语音信号未发音及已发音结束,不携带能量,所以颜色发暗发黑。由于韵母a的发音平缓且变化不大,所以图中反映的能量也呈不变趋势,是一道较平滑的语音带。从图2(a)中可以看出,语音a的能量主要集中于0~4 000 Hz频率范围之间,在4 000~7 000 Hz的频率范围内能量分布较少,而当频率高于7 000 Hz时,几乎没有能量。而在0~4 000 Hz频率范围内,能量分布具有如下的特点:几乎语音一半的能量集中于0~1 600 Hz频率范围内,频率在2 800 Hz及3 800 Hz处又具有较大的能量,其余地方能量相对较小。从图2(b)中可以看出,语音a的能量主要分布在两个频率范围内,其中第一个频率范围是0~1400Hz,第二个频率范围是3000~5000Hz,且从图中颜色明亮度可以看出语音a的大约70%的能量集中于第一个频率范围内,即0~1 400 Hz之间。从图2(c)中可以看出,语音a的能量主要分布在0~1 800 Hz频率范围内,其余频率段内能量可以忽略不计。因此,可以得出结论:韵母a的能量集中分布于0~4 000 Hz频率范围之间,而这也就是其关键频率范围,而这个结论将为其后续处理提高一定的理论依据。
2)声母
下面图3是声母b的语谱图,分别是标准普通话、普通男声和普通女声的图谱。
图3(a)中可以看出:语音b的能量主要分布在两个频率范围内,大约70%的能量分布在0~1 200 Hz频率范围内,其余的能量分布在2 200~4 000 Hz之间。而图3(b)的情况与图(a)类似,语音b的能量大致分布在两个频率范围内,其中大约80%的能量分布在0~1 200 Hz频率范围内,其余能量大致分布在2 800~4 000 Hz之间,另外在频率5 000 Hz以上的地方也有一定的能量,可以忽略不计。从图3(c)可以看出,语音能量绝大部分分布在0~1 200 Hz频率段内,其余能量可以忽略不计。因此,可以得出结论:声母b的能量大致分布在0~4 000 Hz频率段内,但主要分布在0~1 200 Hz之间,这也是其关键频率所在频率段,是后续研究的重点区域。

图2 韵母a的语谱图Fig.2Vowels a spectrogram
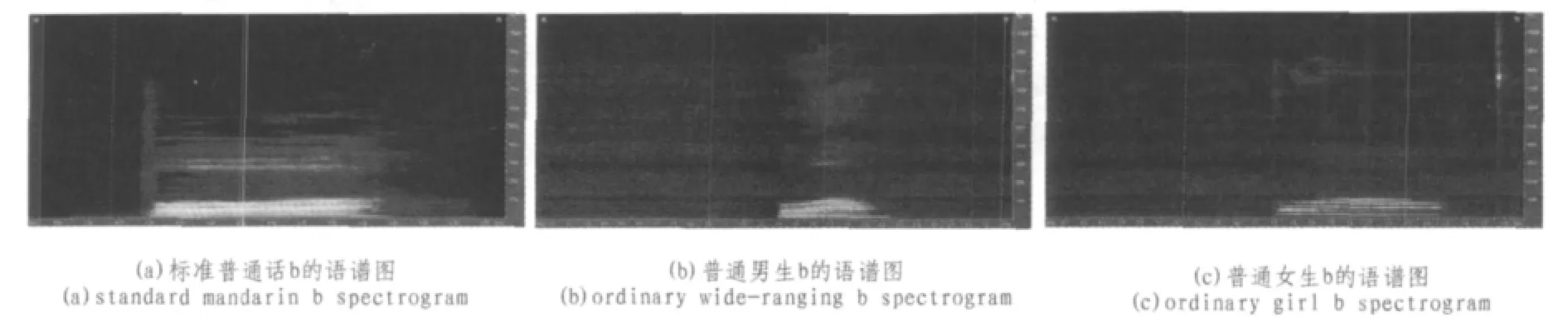
图3 声母b的语谱图Fig.3Initials b spectrogram
3.2.2 自制MATLAB程序来处理语音文件
本文应用自制MATLAB软件处理语音信号,通过调用MATLAB程序来得到语音文件的三维立体语谱图,从中分析总结出其携带的关键信息。与上一小节类似,分别以韵母a、声母b为例。
1)韵母
下面图4是韵母a的语谱图,分别是标准普通话、普通男声和普通女声的图谱。
上图中的语音信号语谱图是表示时频联合分布的三维图,它的横坐标是时间,单位是ms,纵坐标是频率,单位是Hz,竖坐标是幅度,表示语音的数据能量,单位是db(分贝)。能量值的大小是通过颜色深浅来表示的,颜色深,表示该点的语音能量越强;反之,颜色浅,则表示语音能量越小。从图4(a)中可以看出,语音a的能量主要集中于0~4 000 Hz频率范围之间,在4 000~9 000 Hz的频率范围内能量分布较少,而当频率高于9 000 Hz时,几乎没有能量。而在0~4 000 Hz频率范围内,能量分布具有如下的特点:几乎语音70%的能量集中于600~1 600 Hz频率范围内,频率在3 500 Hz及4 000 Hz处又具有大约20%的能量,其余地方能量相对较小。从图4(b)中可以看出,语音a的能量主要分布在两个频率范围内,其中第一个频率范围是0~2 000 Hz,第二个频率范围是2 500~4 500 Hz,且从图中颜色明亮度可以看出语音a的大约80%的能量集中于第一个频率范围内,即0~2 000 Hz之间。从图4(c)中可以看出,语音a的能量主要分布在0~2 000 Hz频率范围内,其余频率段内能量可以忽略不计。因此,可以得出结论:韵母a的能量集中分布于0~4 500 Hz频率范围之间,而这也就是其关键频率范围,而这个结论将为其后续处理提高一定的理论依据。
2)声母
下面图5是声母b的语谱图,分别是标准普通话、普通男声和普通女声的图谱。
在图5(a)中可以看出:语音b的能量主要分布在两个频
图4韵母a的语谱图
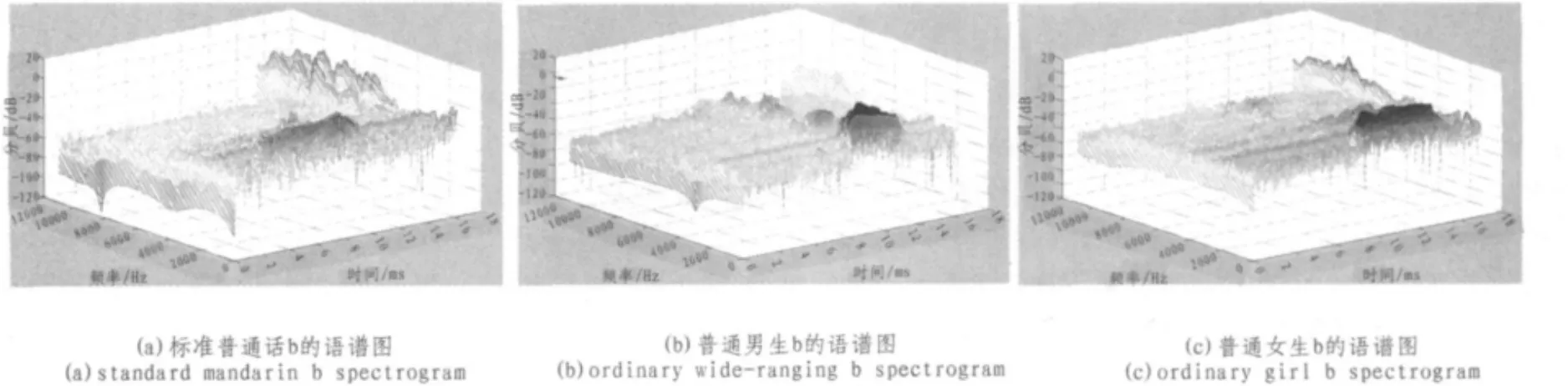
图5 声母b的语谱图Fig.5Initials b spectrogram
Fig.4Vowels a spectrogram率范围内,大约90%的能量分布在0~1 600 Hz频率范围内,其余的能量分布在2 000~4 000 Hz之间。从图5(b)可以看出,语音b的能量大致分布在两个频率范围内,其中大约70%的能量分布在0~1 700 Hz频率范围内,其余能量大致分布在3 000~4 200 Hz之间。从图5(c)可以看出,语音能量绝大部分分布在0~1 700 Hz频率段内,其余能量可以忽略不计。因此,可以得出结论:语音b的能量大致分布在0~4 200 Hz频率段内,但主要分布在0~1 700 Hz之间,这也是其关键频率所在频率段,是后续研究的重点区域。
3.3 汉语语音关键频率分布
按照上面3.2小节中的方法,将两种方法结合起来,可以得出所有声母和韵母的频率大致分布情况,而汉语语音是有声母和韵母拼合而成的,了解了声母和韵母的频率大致分布情况,那必然经能够大体确定汉语语音的频率分布情况,从而为后面的辨析语音提高一定的理论基础。
经过比较分析得出如下结论:在所有声母和韵母中,绝大部分的频率分布范围是0~5 000 Hz,在这个频率范围内,0~1 200 Hz是一个关键频率分布范围段,即在此频率段内语音能量较多,接下来2 000~4 000 Hz又是一较为关键的频率段,也具有一定的语音能量,其余频率段内语音能量较小,几乎可以忽略不计。由于汉语语音中用一个汉字来代表一个音节,一般来说,一个音节由声母、韵母和声调3部分组成,因此,确定了声母和韵母的频率分布情况,那么也就大体确定了汉语语音的频率分布情况。所有上面的结论也适用于绝大部分的汉语语音,这个结论为后面的辨析语音提供了很好的理论基础。
在有关电子耳蜗的研究中,有的研究所选用滤波器的通带带宽在300~6 250 Hz之间[5],说明通过电子耳蜗的语音信号的关键频率大致分布在300 Hz到6 250 Hz这个频率范围内。而这也间接说明了上面的结论具有一定的准确性,是可行的,可以作为后续研究的理论依据。
4 结束语
本文首先介绍了有关汉语拼音[6]的知识;然后介绍了时频分布的特点和优势;最后通过时频分布,用两种方法分析总结了声母和韵母的频率分布情况及关键频率分布特点,从而确定汉语语音的关键频率分布情况,以为语音识别的研究提供一定的理论基础。
当然,本文还要一定的不足:声母和韵母的频率分布情况能否更加细化、更加准确?这是以后工作中亟待解决的问题,需要进一步去研究。
[1]韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004.
[2]付妮妮.汉语拼音字母词研究[D].辽宁:辽宁师范大学,
2007.
[3]郑普亮,许刚.时频分布不同特性进行语音分类[J].计算机工程与应用,2005(22):48-50.ZHENG Pu-liang,XU Gang.Classification of speech using the different properties of the time-frequency distributions[J].Computer Engineering and Applications,2005(22):48-50.
[4]马义德,袁敏,齐春亮,等.基于PCNN的语谱图特征提取在说话人识别中的应用[J].计算机工程与应用,2005(20):81-84.MA Yi-de,YUAN Min,QI Chun-liang,et al.Research of feature extraction from spectrogram based on pulse coupled neuralnetworkinspeakerrecognition[J].Computer Engineering and Applications,2005(20):81-84.
[5]孟丽,肖灵,李平,等.定点DSP实现电子耳蜗CIS策略研究[J].中国生物医学工程学报,2009,28(3):386-392.MENGLi,XIAOLing,LIPing,etal.Researchonimplementation of CIS strategy for cochlear implants on fixed-point DSP[J].Chinese Journal of Biomedical Engineering,2009,28(3):386-392.
[6]吴葵.汉语拼音在对内汉语教学中的应用研究[D].湖南:湖南师范大学,2007.
猜你喜欢
今日农业(2022年16期)2022-11-09
汉字汉语研究(2020年2期)2020-08-13
作文周刊·小学一年级版(2020年28期)2020-08-06
小天使·一年级语数英综合(2019年10期)2019-11-10
作文周刊·小学一年级版(2019年28期)2019-09-07
魅力中国(2018年31期)2018-03-26
舰船科学技术(2015年8期)2015-02-27
电测与仪表(2014年17期)2014-04-04
振动、测试与诊断(2014年6期)2014-03-01
太原城市职业技术学院学报(2014年9期)2014-02-27
