
基于OGRE的大规模场景核外渲染的研究
2011-01-23 09:07王全占
成都工业学院学报 2011年1期
王全占,吴 博
(西南交通大学 电气工程学院,成都 610031)
大规模场景模型动辄数GB、甚至数十GB的超大数据量与计算机内存以及计算性能严重不匹配,引起了国内外虚拟现实、视景仿真领域的极大重视。文献[1]对大规模场景的实时绘制技术进行了综述,但未就单一技术进行深入探讨。文献[2]对单一巨大模型的核外简化及实时绘制技术进行了详细的阐述,但是很遗憾该文献中的方式更适用于单个的巨大物体,而对于如数字地球、虚拟现实等领域的众多小模型组合而来的大规模复杂场景模型显得不太合适,并且不太适用于多纹理模型的绘制。文献[3][4]等则是从核外计算的角度对数据的I/O优化策略进行了对比研究,并未就场景绘制这一方面进行研究。本文对文献中的核外资源处理的思想进行继承,并提出了基于OGRE图形引擎的、更适用于大规模多纹理场景模型的实时绘制的新思路。该方法首先将仿真业界的事实标准Open Flight格式的三维场景模型按照区域划分,分割成若干适合图形工作站内存大小、能够达到数据预取要求的小模型,然后利用模型转换工具将该小模型从Open Flight格式转化为OGRE引擎支持的MESH模型,最后利用数据预取技术以及多线程编程技术完成大规模场景数据的实时读取、实时渲染。
1 OGRE图形引擎的渲染机制
OGRE(object-oriented graphic render engine,面向对象的图形渲染引擎)是用C++开发的面向对象且使用灵活的3D引擎。其目的是让开发者能更方便和直接地开发基于3D硬件设备的应用程序或游戏。引擎中的类库对更底层的系统库(如:Direct3D和OpenGL)的全部使用细节进行了抽象,并提供了基于现实世界对象的接口。引擎中资源加载与渲染是分离的两部分,因此能够支持后台加载。
OGRE能直接利用的模型文件为:.mesh文件,与之对应有一个.materail文件,以及若干纹理图片(png,jpg,tga等)。其中.materail文件中存储了若干个材质,每个材质包含有折射率、反射率、纹理图片名称等信息。.mesh文件中包含有若干submesh(子网格),每个子网格与一个材质名相对应,每个子网格里有应用该材质的顶点的坐标、法向量、纹理贴图uv值等信息。
当代的GPU更适合于渲染少数的大批次的几何体,而不是许多小的批次。这里的批次是指GPU渲染状态的改变,包括折射、反射、纹理等。也正是如此,单纯的三角形数目已经不是GPU关注的热点,渲染一个单一批次的100万个三角形的场景,可能到300帧/s以上,然而渲染1 000个批次,每个批次中有1 000个三角形的场景却可能只有30帧/s。
为了防止材质的频繁切换,OGRE的.mesh文件以材质为单位进行组织,极大限度的减少材质的切换。
2 核外算法的I/O优化策略
核外算法的I/O策略包括数据筛选、数据预取、数据重用等方式。数据筛选主要指为了降低外存访问次数、提高内外存交换的有效数据量而采取的一系列措施。数据预取技术的主要思想是利用数据处理的时间,并行地预取下一时间段需要处理的数据。这就要求I/O操作的数据与CPU/GPU处理的数据不重叠,并且需要保证数据预取的时间要小于数据处理的时间。数据重用主要是指为实现内存中数据的重复利用率而采取的一系列措施。
3 基于OGRE的核外渲染方法
基于以上讨论,OGRE支持.mesh格式的网格模型的渲染,并且在渲染期间会按照不同的材质重新排列,按照批次进行渲染,以实现更适合当代GPU渲染的渲染队列。而核外渲染的I/O优化策略包括数据筛选、数据预取、数据重用3种方式。大规模的场景数据都是存在外存(硬盘等)中的,读取到内存中的数据必须包括当前帧所需要的模型数据以及预取的在一个时间段内需要的模型数据冗余。
3.1 模型分块与存储
首先需要将大的场景模型按照三维空间分块成小的模型,用以动态加载/卸载,这里有2个问题,一是小模型如何存储,二是切分的小模型的大小如何确定。由于OGRE是以资源组的形式进行资源管理,因此只需将切分好的模型数据,包括三角形数据、材质文件、纹理文件均放到同一文件夹下,然后声明该文件夹为一个资源组,这样就可以实现该模型的所有数据同时加载/卸载。
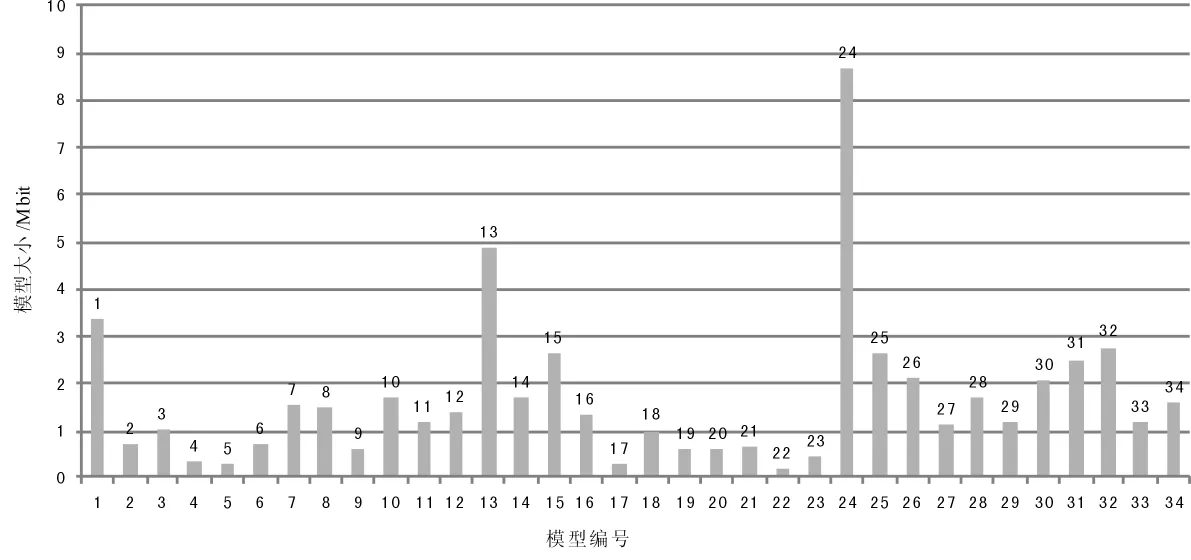
图1 模型的大小
至于如何确定小模型的大小,由于需要将同一三维空间内的模型数据单独放到一个文件夹内,这就无形中增加了不少冗余数据,比如同一张纹理在区域A中要用到,同时也在区域B中也要用到。因此切分的小模型必须在保证渲染的实时性的前提下,越少越好。因此将模型划分为34个小模型,模型大小以及所含纹理数量如图1、图2所示。
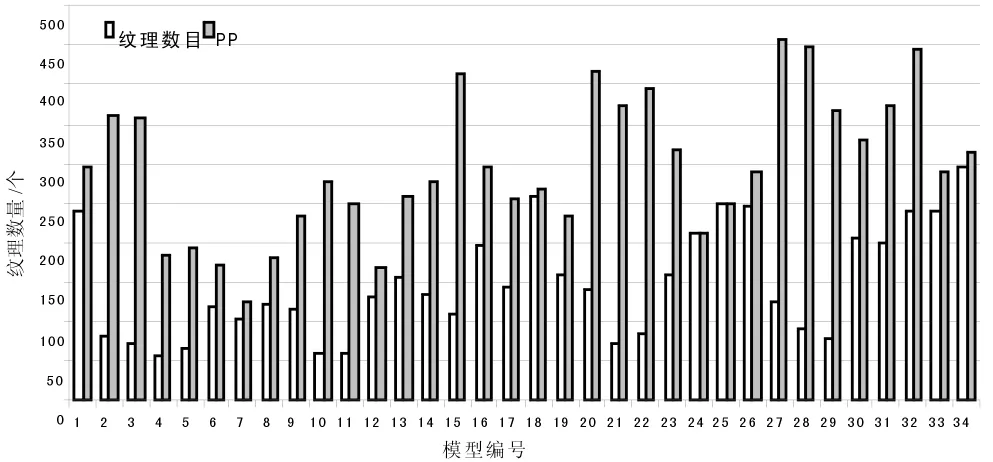
图2 模型的纹理数量
相对应的出现卡帧现象的区域块如表1所示:

表1 出现卡帧现象的区域块
由表1可见,发生卡帧现象的区域编号全是与较大模型块相对应的。由于动态优化是有代价的,尤其是寻求全局最优解,更由于不同纹理、不同组织结构的模型等使得寻求全局最优基本不可能。因此根据反复测试,归纳出适用于当前使用机器的模型大小为:单个模型大小不超过3 MB,纹理数量不超过200张。该结构可作为以后在该计算机上实时大模型时的经验数据。
3.2 核外渲染
实时渲染的同时,启动一个资源管理线程,完成资源的后台调度功能。处理流程如图3所示。
渲染线程根据当前漫游方向以及速度来计算当前视点参数,并进行相应渲染操作,同时将当前速度、方向、视点位置等数据写入公共数据区。资源管理线程负责判断当前视点下,是否需要进行I/O操作并及时更新场景图。
具体的资源管理策略,选用了OGRE的后台加载队列进行后台加载。这个类提供了一个简单的接口,可自动创建一个后台线程去加载/卸载资源,并在处理完毕后返回到主线程一个ID编号。由于返回的信息太少,因此在OGRE主线程中创建了一个专门用于调度的资源管理线程,该线程负责加载/卸载资源组,并建立资源组编号与后台处理队列ID的映射关系。
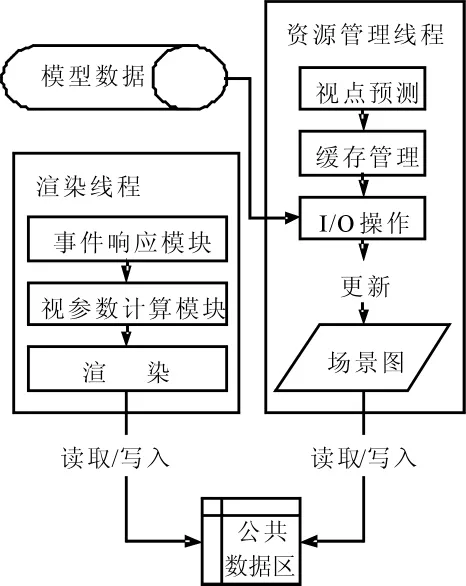
图3 处理流程图
这样,首先对分割好的小模型建立相应的资源组编号,以及对应的三维空间包围盒数据,然后资源管理线程通过读取公共缓冲区的当前视点及其运动参数,进行下一帧的视点预测,然后根据当前帧以及下一帧的视点位置所在的区域块,以及视域的设置来确定下一时刻需要在内存中的资源组编号,并根据当前区域的属性来决定是否进行资源加载/卸载操作。区域块的数据结构设计如下:

然后通知OGRE的后台加载策略进行加载/卸载操作,OGRE会另外开辟一个线程去加载/卸载资源组,在这个资源组中,包含模型的mesh网格模型、材质文件以及相应的纹理,OGRE会在后台完成网格数据的加载/卸载,并解析材质文件找到需要处理的纹理文件,将纹理进行加载/卸载操作。资源处理完成将返回给资源管理线程资源处理完毕的标志,以便资源管理线程及时更新场景图。
在资源管理线程进行资源处理的同时,渲染线程会按批次渲染当前场景图中的三维场景。当前存在于内存中的数据只是略大于视域范围的较小区域的场景,因此场景视域剔除的效率会很高。影响GPU渲染效率的主要因素就是渲染状态的频繁改变,即渲染批次的数量很大地影响了图形渲染的效率。OGRE本身是面向GPU加速的图形引擎,它会在力所能及的范围内尽量把相同渲染状态的物体一起渲染,进而减少渲染状态改变。OGRE也尊重用户设置的Renderable整体(也就是说Renderable是处理批次的最小原子结构),并不进行拆分。比如,有若干个使用相同材质的片段组成的模型,就可以把它们合并成一个Renderable对象,这样就可以省略掉系统检查这些片断是否是一个相同的渲染状态的步骤,从而可以一次处理完毕。基于上述讨论,渲染线程会在响应突发事件(运行故障等)、及视点计算的基础上根据当前场景图,将同一个材质的片段的模型重组到一个Renderable,最后OGRE按材质的优先级、按批次地完成当前场景的渲染,实现GPU加速。
根据以上模型分块以及核外渲染方法,笔者在西南交通大学智能控制与仿真工程研究中心的高性能图形工作站上实现了所设计的系统。完成了3 000 km×2 km范围内的大规模场景模型的实时绘制,模型总量为4 GB,超过了试验机系统内存。图4为完成后的效果图,图5为帧速率曲线。

图4 大规模场景模型绘制的效果图

图5 帧速率曲线
4 结论
大规模场景模型的实时渲染,在列车仿真器视景系统等计算机图形系统中占有非常重要的地位。实时渲染超过内存大小的超大模型,更是近年来的研究热点。本文基于OGRE开源图形引擎,构建了一个简单、高效的大场景核外渲染方法。经过实验证明,该方法能够实现数GB乃至数十GB模型的实时渲染,并且帧率稳定,能够适应高速铁路列车仿真器超长线路场景实时渲染的要求。
[1]崔雪峰,王林旭,王珏.大规模复杂场景的交互绘制技术[C]//刘晓平,蒋建国,李琳,等.全国第19届计算机技术与应用(CACIS)学术会议论文集(上册).合肥:中国科学技术大学出版社,2008:129-134.
[2]王威,胡铭曾.核外计算中I/O优化策略的研究[J].哈尔滨商业大学学报.2005,21(5):600-603.
[3]王海洋,蔡康颖,王文成,等.外存模型简化中数据读取及内存分配的优化[J].计算机辅助设计与图形学学报.2005,17(8):1736-1743.
[4]段化鹏,杨卫平,孙农亮,等.基于OGRE和ODE的碰撞检测在巷道漫游系统中的研究[J].电脑知识与技术,2009,5(19):5219-5221.
[5]李云飞,程甜甜,何伟.一种湖面波浪模拟的方法[J].系统仿真学报,2009,21(23):7507-7510.
[6]苏虎,金炜东.列车驾驶仿真器及其关键技术[J].科技导报,2007,25(12):12-17.
[7]刘波.大规模城市场景的高效建模及其实时绘制研究[D].浙江大学,2008.
猜你喜欢
山西电子技术(2021年3期)2021-06-28
软件(2020年3期)2020-04-20
网络安全技术与应用(2020年1期)2020-01-07
摄影之友(影像视觉)(2018年12期)2019-01-28
商周刊(2017年22期)2017-11-09
Coco薇(2017年8期)2017-08-03
环球市场(2017年36期)2017-03-09
Coco薇(2015年5期)2016-03-29
河南电力(2015年5期)2015-06-08
皖西学院学报(2015年5期)2015-02-28
