
车牌的字符分割和字符识别的研究与实现
2011-01-23 09:07:08单瑾,曾丹
成都工业学院学报 2011年1期
单 瑾,曾 丹
(成都电子机械高等专科学校 网管中心,成都 610071)
车牌识别技术(License Plate Recognition,LPR)是计算机视觉和模式识别技术在现代智能交通系统中的一项重要研究课题,是实现交通管理智能化的重要环节。它是以数字图像处理、模式识别、计算机视觉等技术为基础的智能识别系统。它利用每一辆汽车都有唯一的车牌号码,通过摄像机所拍摄的车辆图像,在不影响汽车状态的情况下,计算机自动完成车牌的识别,从而可降低交通管理工作的复杂度。
由于车牌识别涉及到很多复杂因素,现有理论和方法还存在识别速度慢、精度低、抗干扰性能差等问题,因此有必要进一步研究。本文提出了一种基于模板匹配的车牌识别方法[1],能有效地完成不同解析度和不同模糊程度的车牌识别工作,而且识别精度高、速度快,能满足实时系统的要求。
1 车牌字符分割
车牌图像的分割就是把车牌的整体区域分割成为单字符的区域,以便后续识别。从车辆图像中准确地定位分割出车牌区域是车牌识别中最为关键的步骤之一,只有有效地完成分割,才能进一步提取目标特征并识别目标。图像分割结合车牌的一些共同特征,例如,车牌呈规则的矩形,大小一般为44 cm×14 cm;文字与背景之间有明显灰度对比;第1、2个字符分别是汉字和字母,第3个字符是一个间隔符“·”等等,对图像中的车牌、背景进行标记、定位,然后将待识别的车牌字符从背景或其他伪目标中分离出来。笔者采用一种投影法粗分割结合先验知识后处理的字符分割方法,该方法简单、容易实现,取得了很好的分割效果。算法流程图如图1所示。
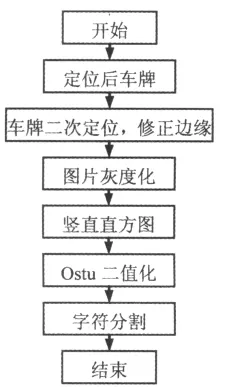
图1 分割算法流程图

图2 车牌图片灰度图
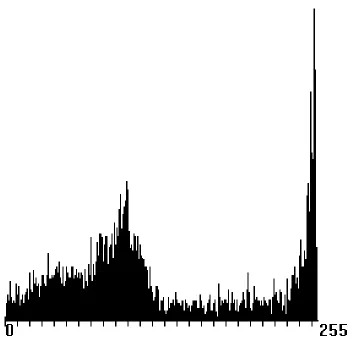
图3 车牌的灰度直方图
1.1 车牌图片的预处理
在完成车牌的精确定位后,进行字符的分割。首先将图像进行二值化处理,使图像仅呈现黑色和白色两种颜色,即在灰度图上形成仅包含255和0两种灰度,使图像在后期识别操作过程中更加容易处理。
车牌中的字和背景使用的是对比比较明显的颜色,在灰度图上表现的灰度值相差较大,如图2所示。在灰度直方图上面,车牌区域形成比较明显的“双峰型”,如图3所示。大量统计表明,对于某一类图像(如目标和背景有较强的对比)直方图中出现2个峰值,其中一个表示背景灰度,另一个表示目标灰度。在此前提下,在两峰的中间谷取阈值。
本项目中,灰度值在车牌底色和字的灰度值周围分布比较密集,因而在双峰中的波谷位置选择合适的阈值,能够很好地将车牌二值化,将字和底色分开。最简单的分类规则是依据区域相似性和不连续性,取定一灰度阈值。大于此阈值的像素点置成黑(白),而小于此阈值的像素点置成白(黑)。寻找阈值的算法选择Ostu算法(最大方差阈值选择法),Ostu算法同时考虑了图像的灰度信息和像素间的空间邻域信息,是一种有效的图像分割方法。其基本思想是选择一个阈值,使用该阈值进行分类时,2类之间的类间方差达到最大。
Ostu选择法的具体步骤是:
将直方图在某一阈值k处分为二组,C1={0~k},C2={k~255},各自产生的概率:
C1产生的概率为ω(k),
C2产生的概率为1-ω(k);
C1的平均值 μ1=μ(k)/ω(k),
C2的平均值μ2=(μ-μ(k))/(1-ω(k))
其中,μ是整体的灰度平均值;μ(k)是阈值为k时的灰度平均值,所以两组间的方差可以由式(1)求出:

然后在0~255之间计算式(1)的值,当该值最大时对应的k值作为二值化阈值。这种方法对于在灰度直方图上呈现出双波峰的情况效果比较好,而定位之后的车牌区域恰好符合这个条件。经过Ostu阈值二值化处理后的图片如图4所示。
1.2 字符分割
由图4可知,定位后的图片对于车牌的上下边缘已经定位非常准确。但是由于左右边缘用于定位的信息不够充分,同时车牌两旁的干扰信息具有不可预见性。所以往往左右的边缘都定位得不是那么准确,通常都要比实际的车牌多出一截。
因此,在进行字符分割时,确定一个可靠的分割起始点就显得非常重要。通过观察,发现在车牌中,第2个字符和第3个字符的间隔是所有相邻字符中最大的。所以可以寻找间隔最大的区域,把它认为是第2个和第3个字符所处的位置,以此为依据进行分割。具体方法如下:

图4 经过Ostu阈值二值化处理后的二值化图片
1)在二值图像中对白色像素进行垂直投影。
2)计算横向间隔最大的位置,认为该位置即是第2、3字符的中间位置。
3)以该位置为基础,按照字符的大致宽度,向左分割出2个字符,向右分割出5个字符。
字符分割计算出的分割线如图5所示。
该方法充分利用了车牌的布局特征,能够很好地分割出每个字符。缺点是对于不是横向排列的车牌不太适应,特别是公交车等车牌呈现上面2个字符,下面5个字符的情况。
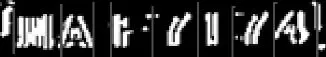
图5 字符分割计算出的分割线
2 字符识别
字符分割后要识别每一个字符究竟是什么。笔者采用了一种基于模
板匹配的车牌识别方法,建立大容量的车牌字符特征向量模板库,用统计学的方法将样本与模板进行比对。模板匹配的思想是将现有的图片和模板库进行比较,如果现有图片和模板中的一幅图片的相似度最大,
就认为现有图片和模板图片表示的是同一个字符。这里需要解决2个问题,一是图片进行模式识别前的特征提取采用什么方式,二是采用什么原则进行相似度比较。
2.1 字符识别的特征提取方式
特征提取采用网格化的方式,如图6所示,将一张字符图片分割成5×5的小方格,这样一共有25个格子,在每个格子中计算:白色像素个数/总像素,将得到的值作为特征值,这样形成一个25维的特征向量。可以将它们定义为X0~X24。
2.2 字符识别的模式及算法
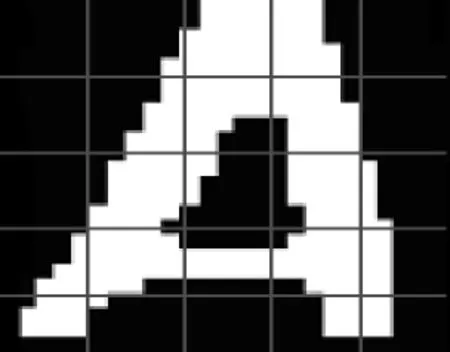
图6 字符分割计算出的分割线
字符识别的过程是利用现有的特征向量,从待识别的图像中提取若干图像的特征量与模板相对应的特征量进行比较,计算模板向量和现有向量之间的相似度,然后将现有特征向量归入与它相似度最高的模板一类。
本项目中计算图像和模板特征量之间的距离,用最小距离法判定所属图像所属类别。假设一个模板向量为M0~M24,特征向量为X0~X24。则特征向量和模板向量的欧氏距离为。分别计算每个模板向量和现有特征向量的欧氏距离d,当d最小时,特征向量X归入模板向量M所在的类。
采用该方法,当2个模板比较相似的时候,会出现误判的现象。比如“A”和“4”,如果当时的图片采集环境很差或车牌本身有污损的时候,最小距离法有误判的可能,这个时候可以采用模式识别中的k-近邻法来实现。k-近邻法是最近邻法的扩展,其基本规则是:在所有N个样本中找到与测试样本的k个最近邻者,取k大者即为识别的字符。
本项目初始建立车牌字符特征向量模板库时,首先需要采集大量的车牌图片,提取特征向量加入模版库,只有建立了较大规模的字符特征向量模版库,才能够保证较高的识别度。
2.3 车牌字符识别的特殊性
车牌字符可利用的规律如下:
1)第1个字符总是汉字。
2)第2个字符总是字母。
……
充分利用这些规律,可以在识别过程中加强判断条件,以提高识别率。
3 结语
采用本文中介绍的方法进行实验,对2 000个样本进行处理,识别正确1 958个,识别准确率为97.9%,效果理想。[2-4]
[1]单瑾,周娟.一种基于二值图像灰度变化特征的车牌定位方法[J].成都电子机械高等专科学校学报,2009(3):30-33.
[2]安勇,张高伟.基于灰度图像的车牌识别系统[J].计算机工程与科学,2006,28(2):61-62,65.
[3]宋晨光,叶海建.基于数字形态学的车牌字符分割算法[J].光电子技术与信息,2005,18(6):58-62.
[4]苏厚胜.车牌识别系统的设计与实现[J].可编程控制器与工厂自动化,2006(3):103-107.
[5]李孟歆,吴成东.基于分级网络的车牌字符识别算法[J].计算机应用研究,2009,26(5):1703-1705.
[6]崔江,王友仁.车牌自动识别方法中的关键技术研究[J].计算机测量与控制,2004,33(1):29-33.
猜你喜欢
电子制作(2019年12期)2019-07-16 08:45:16
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
小猕猴智力画刊(2017年5期)2017-05-25 21:44:09
电子制作(2017年22期)2017-02-02 07:10:11
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
电脑迷(2014年8期)2014-04-29 07:37:40
河南科技(2014年3期)2014-02-27 14:05:36
卷宗(2011年9期)2011-05-14 17:51:19
