
基于Pair-Copula的社保基金投资组合风险测度研究①
2011-01-12 03:05江红莉何建敏
统计与信息论坛 2011年8期
江红莉,何建敏
(东南大学 经济管理学院,江苏 南京 211189)
基于Pair-Copula的社保基金投资组合风险测度研究①
江红莉,何建敏
(东南大学 经济管理学院,江苏 南京 211189)
社保基金是社会保障事业健康发展的基石,风险管理是社保基金保值增值的关键问题之一。提出pair-copula-GARCH-EVT模型以测度社保基金投资组合风险,与传统的n维copula-GARCH-EVT模型相比,该模型不仅考虑了维数的影响,而且还能灵活地选择copula的类型。实证研究发现,基于pair-copula-GARCH-EVT模型测度社保基金投资组合风险的准确性要高于传统的copula-GARCH-EVT模型。
社保基金;Pair-Copula;多元Copula;GARCH;极值理论
社保基金是社会保障制度的物质基础,其安全和保值增值是社会保障事业健康发展的关键。社保基金进入资本市场,其最终目的是在保证安全性的前提下实现收益的最大化。自2001年中国成立全国社会保障基金理事会后,社保基金开始试水资本市场,据《全国社会保障基金理事会基金年度报告》(2009),自全国社会保障基金成立至2009年末,累计投资收益额2 448.59亿元,年均投资收益率为9.75%,远远高于银行年存款利率。但是社保基金在获得相对较高收益的同时,又承担着怎样的风险?社保基金投资的首要原则是安全性,准确地测度社保基金投资风险是控制风险的前提,对保证社保基金投资的安全性具有重要的意义。
测度投资组合风险,关键问题之一是准确测度组合中资产间的相关结构。自从Embrechts将Copula引入到金融领域[1]后,Copula在风险测度领域取得了一系列的成果[2-4]。从理论上讲,Copula方法可以简单推广到高维情形,但现有文献中的Copula函数绝大多数为二元Copula,对高维Copu-la函数的构造研究尚处于初始阶段。得益于Bedford和Cooke、Kurowicka和Cooke等人的工作,高维数据建模可以采用pair-copula(也称为Vine copula,藤copula)方法[5-7]。Bedford和 Cooke在简单构造模块pair-copula的基础上引入了一种构造复杂多元相关结构模型的新方法,它将多元联合密度函数分解成一系列pair-copula模块和边缘密度函数的乘积,为copula方法推广到高维提供了理论基础[5]。相比于经典分级模型,当变量间不存在条件独立性时,pair copula模块构建不要求条件独立假设,因此,这种新的方法在描述高维相关构建时就更加灵活[8]。近年来,pair-copula被用于金融资产收益率建模和其他的数据建模[9-11]。国内学者也逐步将pair-copula应用到风险管理领域,如杜子平、闫鹏、黄恩喜、程希俊等人[8,12]。
传统的n维copula函数对多元数据建模在描述尾部相关性时只有一个参数,没有考虑到维数的影响,现实中资产组合中两两资产间的尾部相关性往往不同,这就可能导致在分析多维资产间的相依结构时出现误差,而基于pair-copula建模就可以有效地避免此问题。本文基于pair-copula模型测度社保基金投资组合的风险:首先,确定pair-copula的分解类型,即C-Vines或D-Vines;其次,选择copula函数类型,即选择正态copula、T-copula或其他的copula函数建模;再次,基于GARCHEVT对边缘分布建模,得到独立同分布的序列,并采用极大似然估计法估计每对Copula函数的参数;最后,基于pair-copula参数估计的结果,根据Aas等人给出的算法思想[9]模拟pair-copula分解模型的仿真序列,计算投资组合的VaR和ES,并将基于pair-copula预测VaR的结果与传统的n维copula预测的结果进行比较研究。
一、pair-copula的理论基础
考虑一个n维向量X= (X1,X2,…,X n),其联合概率密度函数为f(x1,x2,…,x n),可以分解为
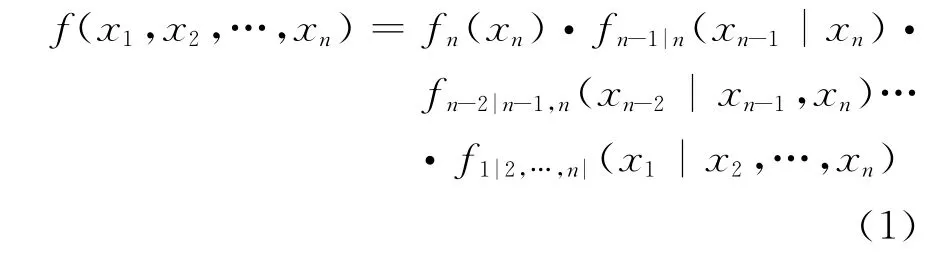
根据Sklar定理[13],多元联合分布函数可以通过copula函数和边缘分布Fi(i=1,2,…,n)表示:
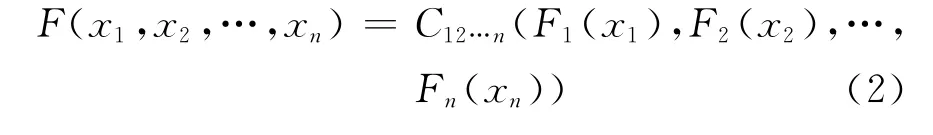
那么,多元联合密度函数可以表示为

其中,c12…n(·)表示n维的copula密度函数,f i(x i)代表边缘密度函数。
当n=2时,式(3)变为
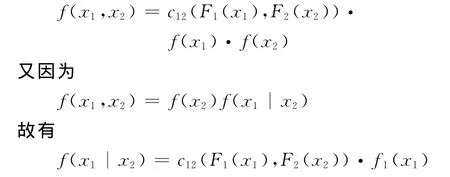
即对于条件概率密度函数f(x1,x2),可以分解为pair-copula的密度函数c12(F1(x1),F2(x2))和一个边际密度函数f1(x1)的乘积。
更一般的情况,式(1)中的每一项可以分解为适当的pair-copula函数乘以一个条件边缘密度,即

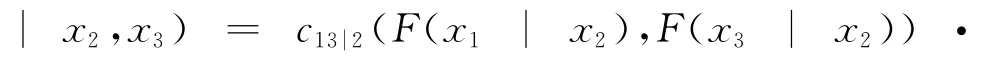
总体而言,在合适的分解规则下,多变量的联合密度函数可以表示为一系列的pair-copula密度函数与边缘条件概率密度函数的乘积。
Pair-copula结构中包含边际条件分布F(x|v)。对于每一个j,均有
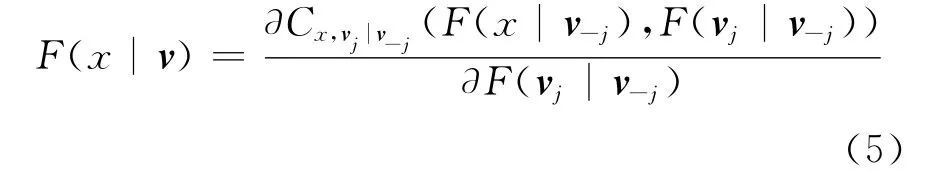
其中,Cx,vj|v-j是一个双变量copula的分布函数。特别地,如果v是一个单变量,有
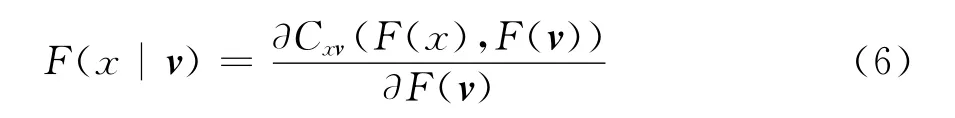
当x和v是(0,1)上的均匀分布时,用h(x,v,Θ)代表条件分布函数F(x|v),即

其中,h(·)的第二个参数是条件相关变量,Θ是连接x和v的copula函数的参数集。
二、高维分布的pair-copula分解
对于高维联合分布,存在多种pair-copula结构。如,五维联合分布存在240种不同的paircopula分解。Bedford和Cooke引入了称之为“正则藤(the regular vine)”的图形建模工具来描述这些pair-copula[6]。N维变量的藤是一类树的集合,树j的边是树j+1的节点,j=1,2,…,N-2,每棵树的边数均取最大。C(Canonical)藤和D藤是两类最特殊的藤,其中,C藤中,在每棵树Tj中仅有唯一的点连接到n-j条边;D藤中,树中任一结点所连接的边的条数最多为2。C藤和D藤的适用范围不同:当数据集中出现引导其他变量的关键变量时,适合用C藤建模,而当变量相对独立时,则适合用D藤建模。图1和图2分别给出了4维C藤和D藤。藤由树、结点和边组成,每棵树上有若干个结点,每个结点的元素都对应一个pair-copula密度函数。
Bedford和Cooke给出了基于藤的n维联合密度函数的表达式[5]:

图1 C藤图
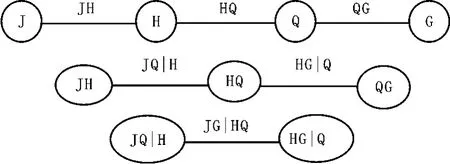
图2 D藤图
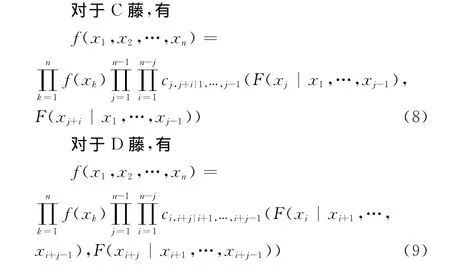
三、高维联合分布下的pair-copula建模
pair-copula建模主要分为三块:1.选择paircopula的结构,即选择C藤、D藤或者是其他的分解规则;2.选择pair-copula的类型;3.估计paircopula函数的参数。
选择C藤或D藤,一个原则是:当数据集中出现引导其他变量的关键变量时,适合用C藤,而当数据集中的变量相对独立时,适合用D藤。通常是通过比较Kendall’sτ或者是Spearman’sρs的大小来测度某个变量与其他变量的相关程度。常见的二元pair-copula函数类型有正态、T、Clayton、Gumbel copula,正态copula不能刻画尾部相关性;T-copula既能刻画上尾相关性,也能刻画下尾相关性;Clayton copula只能刻画下尾相关性;而Gumbel copula却相反,只能刻画上尾相关性。最简单的方法是通过画变量的散点图来选择paircopula类型。
模型参数的估计方法很多,常用的是极大似然估计法,本文也基于该方法估计模型参数。但是与传统的n维copula参数估计方法不同,对pair-copula密度函数作极大似然估计前,必须先估计出每棵树的参数初值。Pair-copula参数估计的基本思路:第一步,基于原始数据估计第1棵树上的copula函数的参数;第二步,基于第一步参数估计的结果及h函数,计算观测值(即条件分布函数值),基于此观测值估计第2棵树上的copula函数的参数;第三步,重复第一步和第二步,直到计算出每棵树上copula函数的参数。将第一、二、三步所得的参数值作为初始值,最大化总体似然函数,求得最终的参数估计值。
以4维D藤为例,具体说明pair copula参数的估计步骤。

得到参数估计的最终值,再通过式(10)求出n维联合密度函数f(x1,x2,x3,x4)。通常,初始值与最终值的差别不大。
四、基于pair-copula的投资组合VaR和ES计算
一般来说,很难求出投资组合的VaR和ES的解析式,通常采用Mont Carlo模拟方法。用Mont Carlo模拟计算投资组合VaR和ES的关键在于对pair-copula分解模型的仿真,即通过正则藤分解下copula分布函数Cx,vj|v-j(·,·)求出的条件分布函数F(x j|x1,x2,…,x j-1),生成服从多元联合分布的仿真序列{x1,x2,…,x n}。Aas等人给出了仿真方法[9],发现pair-copula分解模型的仿真序列和实际序列拟合的很好。
根据Aas等人给出的仿真思想[9]用matlab7.9编程,得到仿真序列{x1,x2,x3,…,x n},利用标准化残差的逆分布函数(即逆概率积分变换),得到标准化残差序列,然后根据上文中估计所得的GARCH模型求出收益率r′t,i,i=1,2,…,n,由此可得资产i在时间(t,t+1)内的损失率为

假设投资组合中资产i的权重为w i,i=1,2,…,n,则投资组合在时间(t,t+1)内的损失率为
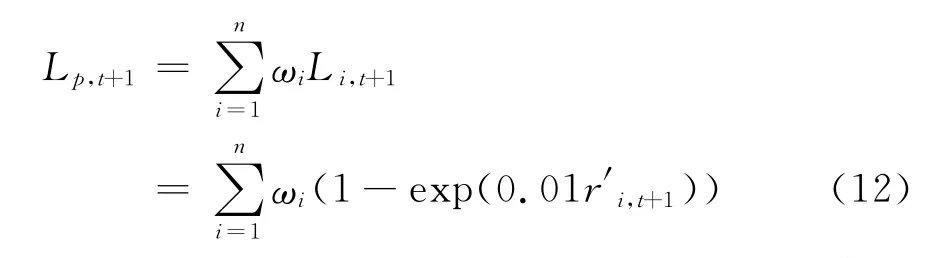
重复Monte Carlo模拟若干次得到投资组合的损失率的仿真序列,进而求出该序列的经验分布,给定置信水平1-α,根据P{L p,t+1≤ VaRt+1(α)}=α求出投资组合在时间(t,t+1]内的VaR值,进而根据ESα=E(L p,t+1|L p,t+1≥VaRt+1(α))求出投资组合的ES值。
五、实证研究
(一)数据来源及基本统计分析
《全国社会保障基金投资管理暂行办法》对社保基金投资的金融工具种类和比例做出了规定:1.银行存款和国债投资的比例不得低于50%。其中,银行存款的比例不得低于10%。在一家银行的存款不得高于社保基金银行存款总额的50%。2.企业债、金融债投资的比例不得高于10%。3.证券投资基金、股票投资的比例不得高于40%。根据社保基金的投资渠道和投资资产比例,首先构造一个基准投资组合,设定各类资产的投资比例分别为:股票w1=30%,国债w3=50%,基金w2=10%,企业债、金融债w4=10%。选用沪深300指数、国债指数、基金指数以及企债指数(将金融债也归为企业债)分别代表社保基金投资的股票、国债、基金、企业债与金融债。样本数据时间区间为2005年5月10日至2010年12月10日,共1 364组数据。所有数据来源于大智慧行情系统,数据处理及参数估计均采用Matlab7.9和 Ox Metrics5.0。
将价格定义为指数每日的收盘价Pt,i,并将指数i在第t个交易日的收益率定义为
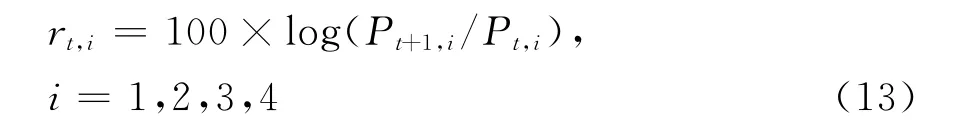
沪深300指数(H)、国债指数(G)、基金指数(J)和企债指数(Q)对数收益率的描述性统计如表1所示。
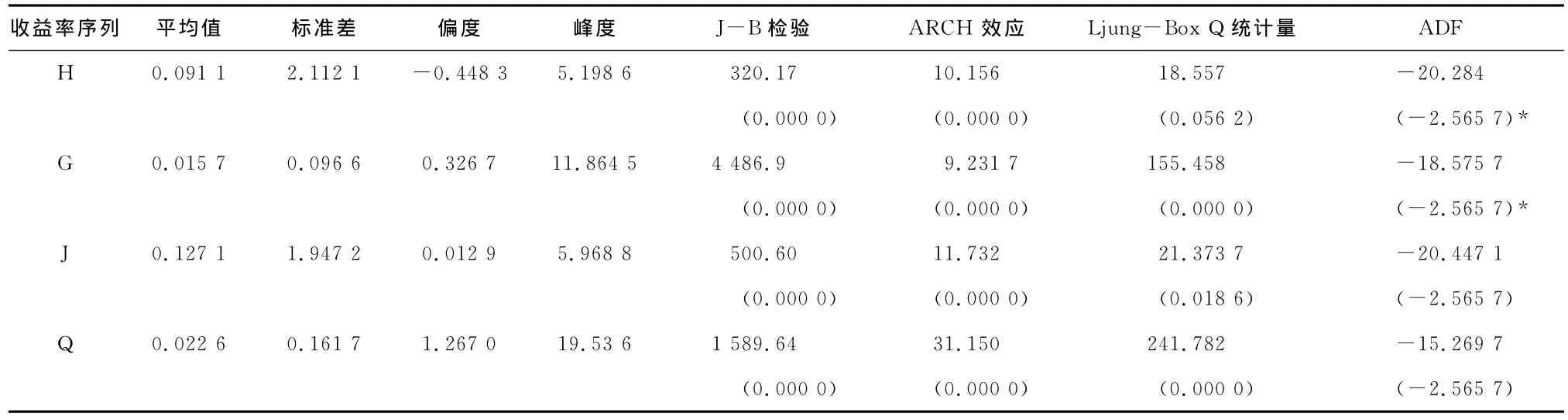
表1 H、G、J和Q收益率序列的描述性统计表
由表1可知,在样本观察期间内,四个指数的平 均收益均为正,基金指数的平均收益率最大,沪深300指数的平均收益率次之,国债指数的平均收益率最小,但是国债指数收益率的波动也是最小,验证了“低风险低收益”。四个指数的收益率中,只有沪深300指数收益率偏度为负,意味着收益率存在着下降的可能性。峰度统计量表明四个指数收益率分布均具有比正态分布更厚的尾部特征;J-B检验统计量的值及其相伴概率,也表明收益率均不服从正态分布。对四个指数收益率进行Engle’s ARCH/GARCH效应检验,结果表明收益率序列都具有明显的条件异方差性。Ljung-Box Q统计量显示,滞后10阶,在5%的显著水平下,四个指数收益率均存在自相关性。单位根ADF检验表明,收益率序列均不存在单位根,是平稳的。
(二)边缘分布建模
根据表1中的Ljung-Box Q统计量,结合AIC和SC准则,在1%的显著性水平下,确定沪深300指数和基金指数的均值方程为AR(0),其余两个指数收益率的均值方程模型为AR(1)。
基于GARCH(1,1)-T对收益率序列建模,利用Ox Metrics5.0估计参数,结果如表2。
由表2可知,四个指数的GARCH(1,1)模型的参数估计值都是显著的;标准化残差序列的Ljung-Box Q统计值和ARCH效应检验表明标准化残差序列不存在自相关和ARCH效应。
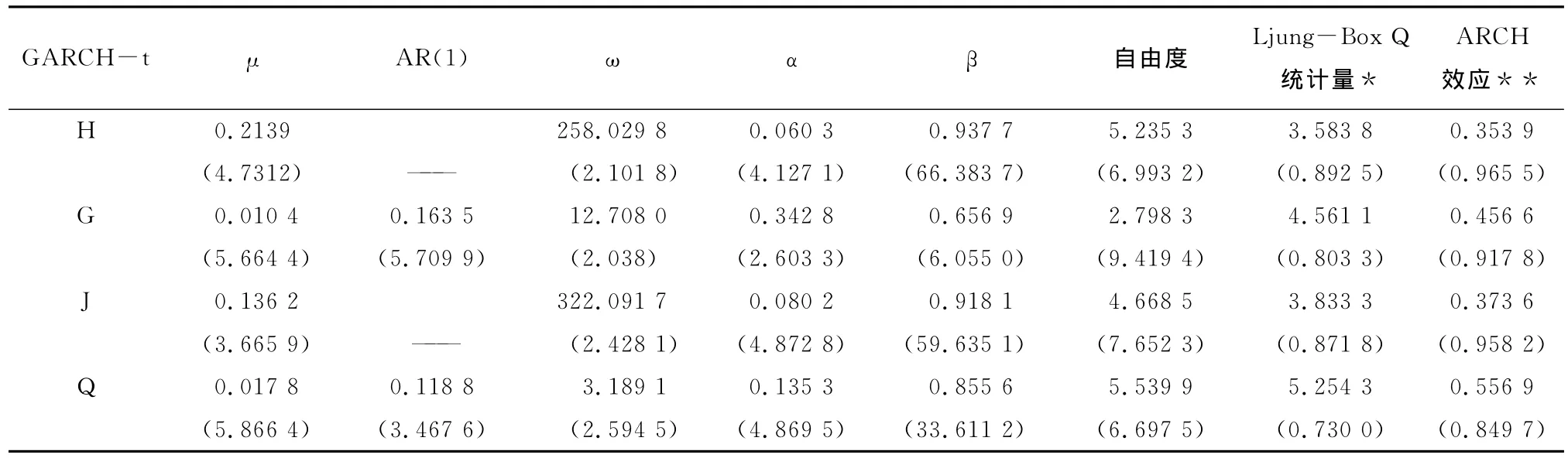
表2 H、G、J和Q的GARCH(1,1)-T估计结果表
借鉴Neftci的做法[14],选取10%和90%作为序列阈值的分位数。基于极大似然估计法估计四个指数的上、下尾部参数(中间部分采用非参数核估计)拟合的结果如表3。

表3 H、G、J和Q尾部分布的参数估计结果表
(三)pair-copula建模
1.pair-copula的分解
基于Kendall’S tau及C藤、D藤的适用范围,选择合适的pair-copula分解类型。经GARCHEVT过滤后的两两标准残差序列间的Kendall’Sτ值如表4所示。
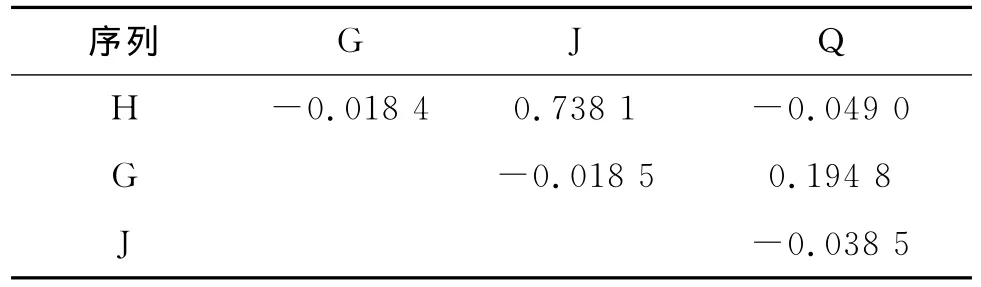
表4 H、G、J和 Q间的Kendall’Sτ值表
根据Kendall’sτ值,相关性从强到弱依次为:H-J,G-Q,H-Q,J-Q,J-G,H-G,除了沪深300指数与基金指数之间具有较强的相关性外,其余指数间的相关性较弱,因此,四个指数间不存在引导其他变量的先导变量,所以不适合用C藤分解,故选择D藤,结构如图3所示。
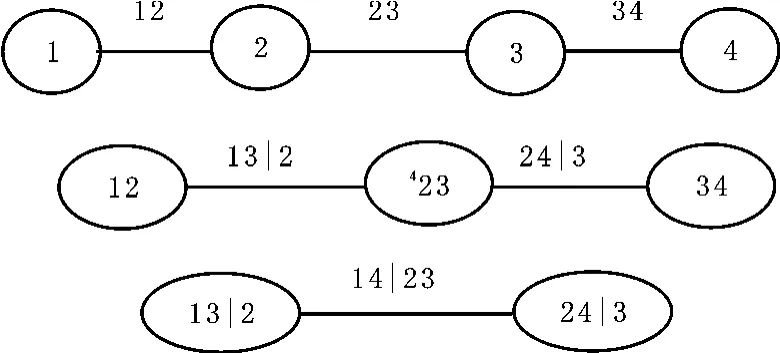
图3 四个指数的D藤结构图
2.pair-copula的参数估计
由于金融资产时间序列间经常同时呈现上下尾相关,相比于其他类型的copula函数,T-copula更好地反映了变量间的上下尾相关性,为了简单起见,以T-copula作为pair-copula的类型。基于Matlab的Dynamic Copula工具箱,先估计初始参数值,然后代入式(10)中,最大化对数似然函数值,得到参数估计的终值。结果如表5所示。
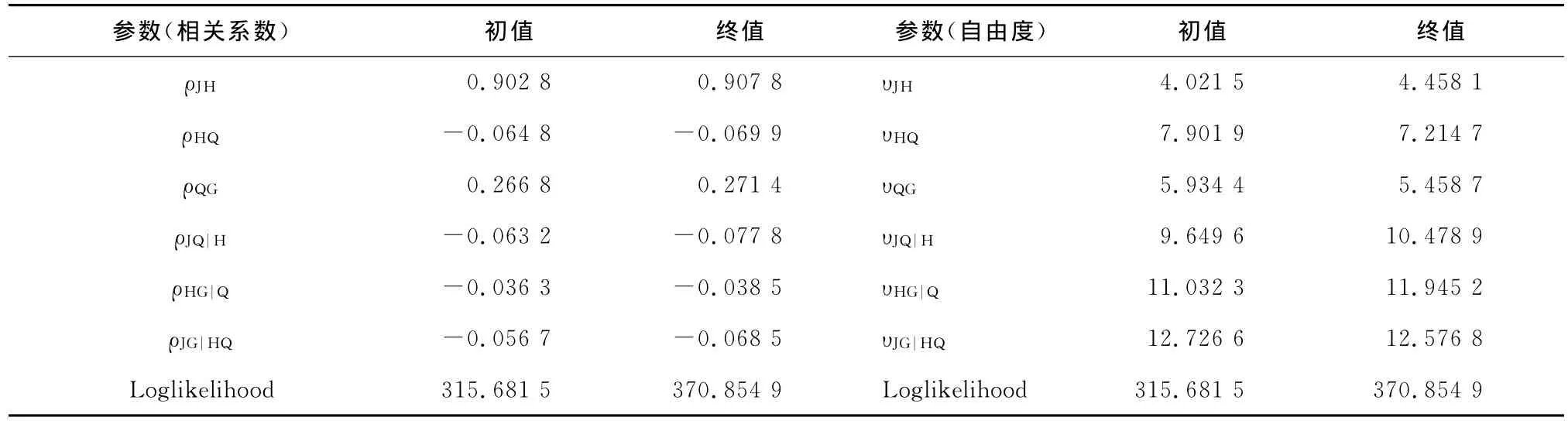
表5 pair-copula的参数估计结果表
为进一步比较分析,本文也基于4维T-copula模型估计社保基金投资组合,结果如下:
相关系数矩阵R为:

自由度为9.341 5,对数似然函数值为256.487 1。
从对数似然函数值,也可以看出,基于paircopula模型的拟合效果要优于传统的n维copula。
3.投资组合风险的仿真计算及后试检验
估计出pair-copula模型的参数后,根据Aas等人给出的仿真程序[9],采用 Monte Carlo方法模拟服从pair-copula分解的联合分布函数的仿真序列,根据投资组合中资产的权重,计算投资组合的收益率,进而计算投资组合的VaR和ES。根据《全国社会保障基金投资管理暂行办法》中的相关规定,假设沪深300指数、国债指数、基金指数和企债指数的权重分别为0.3,0.5,0.1和0.1。根据表5给出的pair-copula参数估计最终值,仿真5 000次,得到四个指数的仿真收益率序列,再根据式(14)计算得到投资组合的仿真损失率序列。根据VaR和ES的定义,计算得t+1时刻95%置信度下的VaR和ES分别为:0.438 2,0.490 1。
为进一步检验模型是否合适,对投资组合VaR进行Kupiec检验,也称LR似然比检验,其基本思想是假定实际考察天数为N0,失败天数为n,失败率为p=n/N0,VaR置信度为p*。假定VaR估计具有时间独立性,则失败天数n服从参数为N0和p的二项分布,即n~B(N0,p),在零假设p=p*下,似然比),在5%的显著水平下,如果LR>3.841 5,拒绝本模型。分别基于多元T-copula和pair-copula模型预测了样本内的日VaR,得出了预测失败的天数、失败率以及LR值,结果如表6所示。
由表6可以看出,在95%的置信度下,拒绝了T-copula模型,而无论在95%还是在99%置信度下,均接受了pair-copula模型,总体而言,基于pair-copula模型预测的效果要优于基于多元T-copula的预测效果。图4给出了5%分位数和95%分位数下基于pair-copula的VaR预测值。

表6 投资组合VaR预测的失败次数、失败率及LR值表

图4 5%分位数和95%分位数下基于pair-copula的VaR图
六、结 论
与传统的多元copula函数相比,pair-copula分解不仅考虑了维数的影响,能够更好地刻画投资组合中不同资产风险两两之间的尾部相关性,而且可以根据实际数据拟合的情况对每一对copula函数选择不同类型的copula函数,建模更加灵活。本文基于Aas等人的pair-copula模型和参数估计方法,结合边缘分布建模的GARCH模型和极值理论(EVT),提出了投资组合风险测度的GARCHEVT-pair-copula模型,为测度投资组合的风险提供了一种新的方法,并将该方法应用到社保基金投资组合的风险测度中。实证研究测得95%置信度下日VaR值和ES值分别为0.4382和0.4901,并且Kupiec检验说明本文提出的模型预测日VaR的能力要优于普通的多元copula模型。
[1] Embrechts P,Mcneil A,Straumann D.Risk Management:Value at Risk and Beyond[M].Cambridge:Cambridge University Press,1999.
[2] Embrechts P,Hoeing A,Juri A.Using Copulae to Bound the Value at Risk for Functions of Dependent Risks[J].Finance and Stochastics,2003,7(2).
[3] 白保中,宋逢明,朱世武.Copula函数度量中国商业银行资产组合信用风险的实证研究[J].金融研究,2009(4).
[4] 李建平,丰吉闯,宋浩,蔡晨.风险相关性下的信用风险、市场风险和操作风险集成度量[J].中国管理科学,2010,18(1).
[5] Bedford T,Cooke R M.Probability Density Decomposition for Conditionally Dependent Random Variables Modeled by Vines[J].Annals of Mathematics and Artificial Intelligence,2001,32(1/4).
[6] Bedford T,Cooke R M.Vines——A New Graphical Model for Dependent Random Variables[J].The Annals of Statistics,2002,30(4).
[7] Kurowicka D,Cooke R M.Uncertainty Analysis with High Dimensional Dependence Modelling[M].New York:Wiley,2006.
[8] 黄恩喜,程希俊.基于pair-copula-GARCH模型的多资产组合VaR分析[J].中国科学院研究生院学报,2010,27(4).
[9] Aas K,Czado C,Frigessi A,Bakken H.Pair-Copula Constructions of Multiple Dependence[J].Insurance:Mathematics & Economics,2009,44(2).
[10]Fischer M,Kock C,Schlüter S F W.An Empirical Analysis of Multivariate Copula Models[J].Quantitative Finance,2009,9(7).
[11]Min A,Czado C.Bayesian Inference for Multivariate Copulas Using Pair-copula Constructions[J].Journal of Financial Econometrics,2010,8(4).
[12]杜子平,闫鹏,张勇.基于“藤”结构的高维动态copula的构建[J].数学的实践与认识,2009,39(10).
[13]Sklar A.Fonctions de répartitionàn dimensions et leurs marges[J].Publication de l’Institut de Statistique de l’Universitéde Paris,1959,8.
[14]Neftci S N.Value at Risk Calculation,Extreme Events,and Tail Estimation[J].Journal of Derivatives,2000,7(3).
A Research on Risk Measurement of Social Insurance Fund Portfolio Based on Pair-Copula
JIANG Hong-li,HE Jian-min
(School of Economics & Management,Southeast University,Nanjing 211189,China)
Social insurance fund is the base of social insurance business's development.Risk management is one of keys to the value preservation and increment of social insurance fund.The model of pair-copula-GARCH-EVT is put forward in order to measure the risk of social insurance fund portfolio in this paper.Compared with traditional multivariable copula-GARCH-EVT model,the model of paircopula-GARCH-EVT can consider the influence of dimensions,and can select the type of copula flexibly.The empirical research shows that the pair-copula-GARCH-EVT is more accurate than copula-GARCH-EVT model in the aspect of measuring the risk of social insurance fund portfolio.
social insurance fund;pair-copula;multivariable copula;GARCH;EVT
(责任编辑:马 慧)
F830.32
A
1007-3116(2011)08-0028-07
2011-02-23
国家自然科学基金项目《基于复杂网络的银行间传染风险及其演化模型研究》(71071034)
江红莉,女,湖北随州人,博士生,研究方向:风险管理;
何建敏,男,江苏无锡人,教授,博士生导师,研究方向:管理决策、金融工程。
① 本文所研究的社保基金,是指全国社会保障理事会所管理的“全国社会保障基金”,目前,只有这部分社保基金和企业年金可以在资本市场上投资。
【统计理论与方法】
猜你喜欢
数学物理学报(2022年3期)2022-05-25
数学物理学报(2022年2期)2022-04-26
哈尔滨工业大学学报(2022年5期)2022-04-19
北京航空航天大学学报(2020年10期)2020-11-14
数学物理学报(2020年4期)2020-09-07
数学年刊A辑(中文版)(2020年2期)2020-07-25
统计与决策(2017年2期)2017-03-20
债券(2016年11期)2017-01-12
债券(2016年11期)2017-01-12
债券(2016年10期)2016-11-28
