
改进的交叉算子在遗传算法中的研究及应用
2011-01-11 01:55:53袁桂霞
终身教育研究 2011年5期
袁桂霞
遗传算法是模拟生物在自然环境下的遗传和进化过程而形成的一种自适应全局优化概率搜索方法。它最早由美国密西根大学的H.Holland教授提出,起源于20世纪60年代对自然和人工自适应系统的研究。1967年,Bagley发表了关于遗传算法应用的论文,在其论文中首次使用“遗传算法”一词。20世纪70年代 De Jong基于遗传算法的思想在计算机上进行了大量的纯数值函数优化计算实验。在一系列研究工作的基础上,20世纪80年代由Goldberg进行归纳总结,形成了遗传算法的基本框架。[1-3]。算法受到进化思想“优胜劣汰,适者生存”的启发,将这一思想引入到优化问题中。首先用合适的编码形式形成染色体种群,根据问题的约束条件选取适应度函数作为评价个体优劣的标准,通过遗传算子即选择、交叉、变异对个体操作筛选,使适应度函数值高的个体进入下一代进化中,迭代该过程直到满足一定的条件。
遗传算法具有天然的并行性,可以更快地得到全局最优解。[4]但它也存在许多不足,如容易出现陷入局部最优等。[5]遗传算子用来进行在整个解空间中广泛搜索并且能从局部最优中逃离,进而可以搜索到解空间中新的区域。选择算子就是执行复制操作,根据每个个体的适应值和选择的规则从种群中剔除低适应值的个体,把高适应值的个体进行复制,使得搜索朝着解空间靠近。不过此过程并没有产生新的个体,而是保留了精英个体为交叉操作的进行做准备。变异算子则是对部分个体信息进行变异,小概率改变个体染色体的基因。而交叉算子是对双亲个体进行操作得到不同的两个新个体的过程。交叉算子可以将父代优良基因传给下一代,这个过程也算是一种变异操作,而且利用增加群体染色体的多样性,防止陷入早熟,所以遗传算子中主要的算子是交叉算子,交叉算子的改进对于解决局部最优有很好的作用[6-7]。目前也有许多相关的改进算法,但改进的算法通用性不明显。只有对其算子做本质的改进才能发挥更广泛的作用。
对交叉算子的改进可以从两方面展开,首先遗传算法的控制参数包括种群大小、交叉概率、变异概率等,而这些参数的选取会对遗传算法的性能产生很大的影响,也就是参数的合理性关系到算法寻优的成败,所以对交叉算子改进的第一个方面是对交叉概率参数的选取,另一方面就是对交叉算子的操作策略。[8]
一、交叉概率的改进
遗传算法本身就具备“优胜劣汰,适者生存”的规律,个体有根据周围环境变化自适应的能力,即种群中个体适应度值与平均适应度值都能逐渐演化为某一范围。在算法设计中,应该引导个体适应环境保留好的模式,使其更好地适应环境。[9]这也是改进交叉概率的出发点。
交叉概率控制了交叉算子进行操作的频度,频度过高虽然可以一时增强遗传算法搜索新区域的能力,但根据Holland提出的模式定理和积木块定理,高频度的交叉算子也会破坏高性能的模式,不利于低阶、高适应值的个体快速增长;频度过低,也会导致遗传算法可能陷入迟钝状态,产生局部最优解,寻找不到全局最优解,进而不利于进化的完成。所以一般遗传算法交叉概率的选取都介于0.4-0.9之间。但是具体的交叉概率还是不能确定实际可行的值,本文在标准遗传算法的基础上提出一种自适应交叉概率选取的方法,在一定交叉概率范围内再结合适应度值来动态调整交叉概率,进而改进了交叉算子,用于求解函数优化问题,具体实现方法如下。
交叉算子可以产生新个体,在种群的大范围内搜索避免过早收敛,不过到了进化的后期,要针对性地在局部范围内搜索,尽可能提高解的精度。所以前提的交叉概率应该大一些,尽量覆盖全局,后期应该针对适应度高的进行大概率操作,其他进行小概率操作。按照公式(1)进行自适应交叉概率操作。
(1)
本文采用权重的思想来对各个阶段适应度值的个体交叉概率进行调整,其中f代表要交叉的两个个体中较大适应度值,交叉概率的取值范围介于0.4-0.9之间,对适应度值划分了低适应度值fmin、平均适应度值favg和高适应度值fmax三个层次作为种群适应度值的集中程度,对应的把交叉概率的范围也分为三个层次依次是Pc1=0.4,Pc2=0.6,Pc3=0.9。按照上面介绍的原则,以一代种群为单位,自适应地改变整个种群的交叉概率Pc,使其随着个体的适应度值在种群的低适应度值fmin、平均适应度值favg和高适应度值fmax之间进行调整。改进的交叉概率Pc有以下特点:
(1) 当个体的适应度值f小于平均适应度值favg时,适应度值处于偏低集中状态,容易陷入局部最优,此时通过调整权重增大交叉概率偏向Pc,提高搜索全局的能力,这样可以增加种群中个体的多样性。
(2) 当个体的适应度值f大于平均适应度值favg时,适应度值处于偏高分散状态,容易陷入随机搜索没有目的而导致收敛慢,此时通过调整权重减小交叉概率Pc,提高算法的收敛速度。
(3) 交叉概率总是介于0.4和0.9之间,如果个体的适应度值f小于平均适应度值favg时,交叉概率介于0.6和0.9之间,越靠近低适应度值,交叉概率越接近最大交叉概率即0.9;反之,若个体的适应度值f大于平均适应度值favg时,交叉概率介于0.6和0.4之间,越靠近高适应度值,交叉概率越接近0.4。
根据以上提出的自适应交叉概率调整公式可以得到交叉概率Pc的变曲线,如图1所示。

图1 自适应的交叉概率调整图
改进后的交叉概率在最佳交叉概率参数下,随着适应度值的变化不断调整,既避免了陷入局部最优,又加快了算法的收敛速度,不至于出现近似停滞不前的状态。对于遗传算法的改进具有很好的指导作用。
二、交叉算子的混合策略
交叉算子是根据交叉原则和交叉概率对双亲结合来产生后来的算子,其策略关键是确定交叉点位置和交换部分基因信息。经常用到的遗传交叉算子包括单点交叉、两点交叉、均匀交叉等,下面具体举例如下:
(1)单点交叉:对两个个体的编码串随机选择同样的交叉点,组合第一交叉点前的编码串和第二个交叉点后的编码串为一个新个体,另外第二个交叉点前的编码串和第一个交叉点后的编码串组合为另一个新个体。例如图2单点交叉,两个双亲个体p1和p2(交叉点以“|”标记)将按照单点交叉的方式产生后代o1和o2。

图2 单点交叉
这种单点交叉方式简单易行,但是却容易破坏种群中的长定义距模式和染色体串尾重要基因。为改进这一缺点,给出两点交叉,也是实际中经常用到的交叉算子。
(2)两点交叉:为了尽量保留染色体的串尾重要基因,给双亲个体都同时设定两个交叉点,位置相同,分别交换其两个交叉点之间的染色体串。例如图3两点交叉,两个双亲个体p1和p2(交叉点以“|”标记)按照两点交叉的方式产生后代o1和o2。
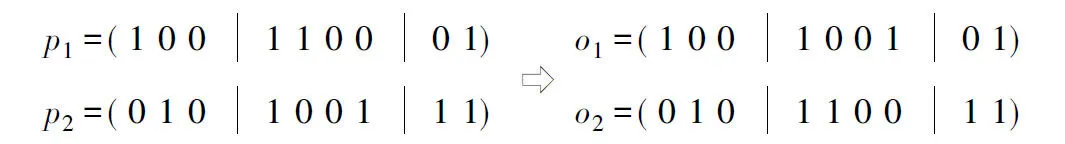
图3 两点交叉
(3)均匀交叉:与上两个交叉策略不同,它的交叉点可能是每一个位置,不是固定的,具体是由下面成为二进制屏蔽字的随机生成串决定。步骤如下:
① 随机生成一个二进制屏蔽字p=W1W2…Wn,长度n与染色体编码长度相同,它决定了父代具体复制位置。
② 按下列规则从p1和p2两个父代个体中产生两个新后代个体o1和o2。
若Wi=0,其中1 若Wi=1,其中1 ③ 具体操作过程如图4所示。 图4 均匀交叉 均匀交叉相对于前两种交叉而言,对于定义距较大的模式有保护作用,而对于定义距较小的模式破坏较大,因此具有更好的鲁棒性。 除了上述的三种交叉算子策略还有多点交叉方式,多点交叉是比两点交叉多了几个固定交叉点,一般而言,多点交叉较少采用。因为在多点交叉时被保存的结构很少,也就是说,多点交叉不能有效地保存某些重要的模式。 在实际情况中有时需要满足约束条件,如交换后要求所有的基因不能重复且不能丢失,就必须对交换操作进行修正。如果交换后出现交叉段外与交叉段内的基因位值重复,则将原来的交叉段内的映射关系按位再反映射施行到重复编码上。 笔者采用改进的交叉概率和交叉策略相结合的方式,并应用到函数优化过程中。 遗传算法与其他一些随机搜索算法(如模拟退火算法)的不同之处在于,它维持了应该具有一定数目个体的种群。定义遗传算法的收敛性存在两种思路:一种是针对整个种群进行定义,另一种思路是针对个体进行定义。在本算法中,需要考虑保证,并尽可能高地提供算法的收敛速度。De Jong博士提出了“精英选择(elitist selection or elitism)”策略,也称为“精英保留”(elitist preservation)策略。该策略的思想是,把群体在进化过程中迄今出现的最好个体(称为精英个体elitist)不进行配对交叉而直接复制到下一代中。20世纪90年代,Rudo1Ph基于 Markov chain理论证明了保留精英的遗传算法(EGA)以概率1收敛[10-11]。笔者在实际算法的设计中也采用此方法来保证收敛性。 1.算法步骤 (1) 初始化种群:随进生成N个二进制编码的染色体,组成初始化种群P。 (2) 计算适应度值:对初始化种群中的所有个体计算其适应度值。 (3) 选择:根据适应度值进行选择复制操作,这个过程都是对高适应度值的个体进行选择,使搜索朝着解空间靠近,尽早收敛到全局最优解。同时为保证算法的收敛性,对选择操作进行部分改进,采用EGA的思路保留当前最佳个体(精英),且不参与遗传操作。 (4) 交叉:按照本文改进的交叉概率和交叉策略进行操作,对个体双亲结合产生新的个体作为后代。 (5) 变异:本文给定的变异概率对个体编码中的部分信息实施变异,产生新的个体。 (6) 终止条件判断:如果满足终止添加,则执行步骤(7),否则执行步骤(2)。 (7) 输出:最后把群体中最好个体作为遗传算法的解输出,即问题的最优解。 2.试验结果分析 本文改进的自适应的交叉概率调整算法ICGA要应用到具体的函数优化当中,同时给出比较典型的Schaffer’s F6函数,通过与经典遗传算法SGA的比较,分析本文改进算法的优良特性,具体函数如下: (2) 函数定义域为[-100,100],实验中采用二进制编码,本文分别对标准遗传算法和改进的交叉算子的遗传算法应用到该函数优化中,独立运行30次作为一次实验,种群代数设为200。 对于标准遗传算法SGA参数为:种群N=100,Pc=0.65,Pm=0.01;对于改进的交叉算子遗传算法ICGA种群N=100,Pm=0.01。所得实验结果比较如图5所示。 图5 SGA、ICGA算法最大适应度值比较 从结果可以看出,改进后的交叉算子在遗传算法中有较强的自适应性能和较强的寻优能力,避免了初期陷入局部收敛的情况,同时在全局收敛和全局最优之间也得到了平衡。在收敛性方面,通过采用保留精英个体方式,有效地提供了收敛速度,多次实验结果表明,由于采用了保留精英方法,其收敛速度较不采用方式约提升20%-30%。实验结果进一步证明了改进交叉算子的算法应用到遗传算法中的有效性。 笔者对遗传算法的主要遗传算子交叉算子进行了改进,用提出的自适应交叉概率参与遗传操作,细致分析了交叉操作的几种策略,并在此基础上提出了一种新的改进算子的遗传算法,并采用EGA方式提升了收敛速度。通过该算法可以抑制优化初期的“早熟现象”,加快后期的收敛速度,实现全局寻优,获取最优解。但它也存在一些缺点,目前应用到函数优化上效果比较好,其他应用还需要进一步的探讨。 [1] Illinois Genetic Algorithms Laboratory,University of Illinois at Urbana-Champaign,Illinois Genetic Algorithms Laboratory Home[EB/OL].[2006-10-13].http:∥www-illigal.ge.uiuc.edu. [2] 周明,孙树栋,遗传算法原理及应用[M].北京:国防工业出版社,1999:4. [3] 王小平,曹立明,遗传算法——理论、应用与软件实现[M].西安:西安交通大学出版社,2002:34. [4] Holland J H.Adaptation in Natural and Artificial System[M].Mit Press,Cambridge,Mass,1975. [5] 李敏强,寇纪凇.遗传算法的基本理论与应用[M].北京:科学出版社,2002. [6] 卢厚清.一种遗传算法交叉算子的改进算法[J].解放军理工大学学报:自然科学版,2007(3):250-251. [7] 田东平.遗传算法中的交叉算子研究[J].内蒙古师范大学学报:自然科学汉文版,2007(3),308-309. [8] 屠惠远.交叉算子的性质分析[J].武汉大学学报:理学版,2005(2),22-24. [9] 袁桂霞.运用项目反应理论的试题评价模块的设计与实现[D].苏州:苏州大学,2006. [10] Rudolph G.Convergence Analysis of Canonical Genetic Algorithms[J].IEEE Trans Neural Networks,1994,5(l):96-101. [11] 张文修,梁怡.遗传算法的数学基础[M].西安:西安交通大学出版社,2000.
三、算法的收敛性
四、改进交叉算子在遗传算法中的应用
五、结论与展望
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02数学物理学报(2021年2期)2021-06-09 08:54:26应用数学(2020年2期)2020-06-24 06:02:44小学生学习指导(中年级)(2019年3期)2019-04-10 01:58:06数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:54数学物理学报(2016年3期)2016-12-01 05:36:27中国塑料(2016年11期)2016-04-16 05:26:02中学生物学(2016年8期)2016-01-18 09:08:18中华建设科技(2014年6期)2014-08-27 04:16:40教育与职业(2014年16期)2014-01-19 01:24:36
