
一种改进的 X2统计量方法
2010-12-27 09:16:54程传鹏
中原工学院学报 2010年6期
程传鹏
(中原工学院,郑州 450007)
一种改进的 X2统计量方法
程传鹏
(中原工学院,郑州 450007)
对文本特征提取中的统计量方法进行了介绍,并且指出了该方法在分类中的不足之处;在此基础上,提出了一种改进的特征选择方法,并把该方法应用到后续的文本分类中.分类实验结果表明,分类准确率得到了一定的提高.
文本分类;特征提取;X2统计量
在文档分类中,通过分词后的文档词汇,数量是相当大的,原始的特征空间可能由出现在文章中的全部词条构成.而中文的词条总数有二十多万条,这样高维的特征空间对于几乎所有的分类算法来说都偏大[1].为了提高分类的效率,在分类之前务必要进行特征提取,以剔除那些类别区分度差的词汇.本文考虑到特征词的分布密度问题,对 X2统计量公式进行了一定的变形,大大降低了原始特征集中经常出现的大量版权和广告等对分类无用的高密度词,使抽取的特征词更能体现类别的主题思想.此外,在特征提取过程中,考虑到中文词语之间的同义、近义、反义等语义关联,对特征词进行合并,减少了相似性比较时的计算量.
1 X2统计量方法介绍
在文本分类算法中,常用的文档特征抽取方法有文档频次方法、互信息方法、信息增益方法、X2统计量方法等.Yang Yi-ming通过大量的实验研究证明,X2统计量方法是目前效果最好的特征选择方法之一[2],其计算公式如下:
X2(t,c)= N×(A D-CB)2(A+C)×(B+D)×(A+B)×(C+D)
式中各参数的含义如下:
t—特定的词条;
N—总的文档数,N=A+B+C+D;
A—属于c类且包含t的文档数;
B—不属于c类但是包含t的文档数;
C—属于c类但是不包含t的文档数;
D—既不属于c也不包含t的文档数.
X2用于度量特征 t和类别C之间的独立性.特征t的 X2统计值越高,它与该类之间的相关性越大,其越能代表该类特征[3].该方法类似于互信息MI方法,某词条的 X2统计值决定了该词条对一个类别的贡献和对其余类别贡献的大小,以及该词条和其他词条对分类的影响.当特征t和类别C之间完全独立的时候,X2统计量为0.直观地看,X2(t,c)的值越小,说明词条关于类C的独立程度越高,因此应当选择那些X2(t,c)值最大的词作为特征词.
2 X2统计量方法的不足及改进
利用 X2统计量方法来进行特征抽取是基于如下假设:在指定类别文本中出现频率高的词条与在其他类别文本中出现频率比较高的词条,对判定文档是否属于该类别都是有益的.但是在某些类别中,低频词往往是这些类别的特征,具有很强的代表性.在公式X2(t,c)中,如果 A →0,且 B →0,那么 X2(t,c)→0,所以 X2统计量对低频词不公平.按照 X2统计量的计算方法,在多类中普遍出现的高频词的权重将比只在特定类中出现的低频词的权重高,如果某个词条在很多类别中都多次出现,反而不能很好地体现类别信息.比如广告信息以及版权信息,这样的词条也不应该作为特征词.
综上所述,子宫颈癌外科手术经历了130年的发展历程,手术路径经历了经腹、经阴道,开腹、微创手术,输尿管内侧入路、外侧入路,根治性子宫切除、根治性子宫颈切除,传统根治术、保留神经手术等历史变迁和进化。相信随着材料和技术的不断进步以及临床医生的不断努力,未来微创手术会使得更多的患者从中获益。
所以,我们提出了一个变形后的 X2*公式:

式中:N、A、B、C、D 的含义同 X2统计量;Nft表示出现t的文档数.
它基于如下假设:如果词条出现的文档数接近训练集中所有的文档数时,即 Nft→N时,log(N/Nft)→0,此类词条大量出现在各个类别中,类别区分度差,应该过滤掉.此外,该方法还适当地提高了低频词的权重.
3 特征提取算法描述
在上述研究的基础上,本文提出了如下的算法:以分词后所有的词条作为候选特征词,最后输出特征词.
(1)初始情况下,从分词后所得到的词条集合里去掉停止词后,所有的词条都作为候选特征词;
(2)对于每个候选特征词,按如下公式计算候选特征词及其类别的 X2统计量:

(4)依据排序的结果,抽取一定数量的词作为特征项;
(5)将每类中所有的训练文本映射到特征词空间上,根据抽取的特征项进行向量维数压缩.
特征词集的形成过程如图1所示.
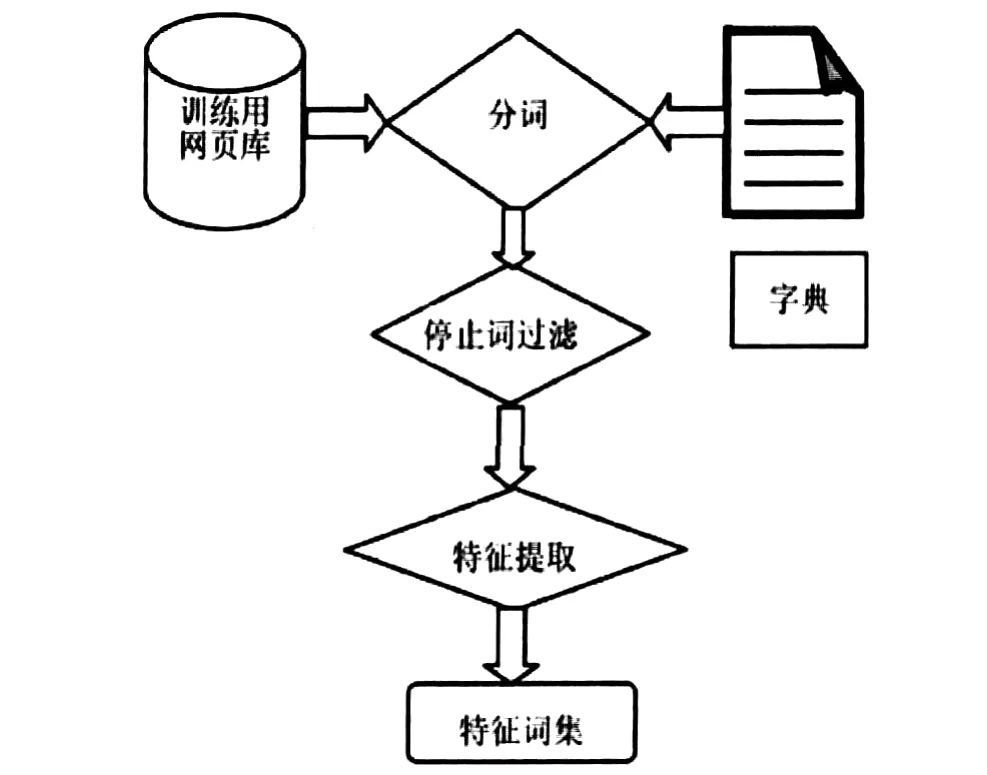
图1 特征词集形成过程示意图
4 实 验
为了验证本算法,我们从新浪网站下载一些已经进行人工分类的网页进行分类测试.对这些网页进行信息提取,去掉其中的 html标签后,把网页转换为纯文本的形式.特征词提取分别采用传统的 X2统计量方法和本文所提出的方法,分类结果如表1所示.

表1 实验结果
从表1可以看出,采用本文所提出的算法,分类准确率可以得到一定的提高.
5 结 语
我们针对中文文本的特点和 X2统计量在特征选择上的不足,根据特征词的分布密度,对 X2公式作出了一些改进,在一定程度上提高了文本分类的精度.如果考虑到中文词语之间的同义、近义、反义等关系,那么我们就可以对这些具有语义关联的特征词进行合并[4],合并带来的直接效果就是特征词的个数减少,从而可以缩小向量空间的维数,大大减少了相似性比较时的计算量.
[1] 代六玲.中文文本分类中特征抽取方法的比较研究[J].中文信息学报,2004,24(1):26-32.
[2] Yang Yi-ming.An Evaluation of Statistical Approaches to Text Categorization[J].Journal of information Retrieval,1999(1):67-88.
[3] Dunning T E.Accurate Methods for the Statistics of Surprise and Coincidence[J].Computational Linguistics,1993,19(1):61-74.
[4] 程传鹏.中文网页分类中特征提取的研究[J].中原工学院学报,2005,16(6):42-44.
An ImprovedX2Statistics Method
CHENG Chuan-peng
(Zhongyuan University of Technology,Zhengzhou 450007,China)
This paper introducesX2statistics method of features selection.And then we modify the currentX2statistics method.The research results in this paper has been applied in web page classification.It is proved that the accuracy of classification is promoted
web page classification;feature selection;X2statistics
TN391.07
A
10.3969/j.issn.1671-6906.2010.06.017
1671-6906(2010)06-0073-03
2010-11-08
程传鹏(1977-),男,河南信阳人,讲师,硕士.
猜你喜欢
电子制作(2018年19期)2018-11-14 02:37:08
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
自动化学报(2017年11期)2017-04-04 02:52:58
知识经济·中国直销(2016年5期)2016-11-07 09:35:07
知识经济·中国直销(2016年4期)2016-11-07 09:34:04
知识经济·中国直销(2016年10期)2016-02-27 16:16:54
中文信息学报(2015年4期)2015-04-21 08:29:12
信息安全研究(2015年3期)2015-02-28 20:17:53
噪声与振动控制(2015年4期)2015-01-01 07:08:21
