
基于新双模融合算法的情感检测系统
2010-12-06 12:10黄永明章国宝刘海彬达飞鹏
天津大学学报(自然科学与工程技术版) 2010年12期
黄永明,章国宝,刘海彬,达飞鹏
(东南大学自动化学院,南京 210096)
情感在人类交流中具有重要作用.情感检测系统也在远程教学[1]、电子机器宠物[2]、辅助测谎[3]、自动远程电话服务中心[4]以及临床医学[5]等方面有着广阔的应用前景.语音信号视频信号都能传递丰富的情感信息,由于音频、视频在情感检测上都存在一些固有的缺陷,从单一的途径来进行情感检测已经越来越不能满足工程的实际需求,因此,从双模提取互补性的特征成为提高识别率的新途径.
多分类器信息融合,首先是分类器之间要有差异性,且融合算法要考虑分类器对各种情感的敏感度,这样才能得到较好的信息融合效果.对于分类器选择,如果选用同性质的分类器,虽然融合简单,但无法保证分类器的差异性.对于融合算法,简单采用多个分类器的投票法、加法法则、乘法法则,由于没有考虑到分类器的差异性,故而分类效果并不理想;采用传统的融合算法融合,虽然考虑到分类器的差异性,但却忽略了分类器本身对特定情感的敏感度,并不能保证有更好的分类效果;使用层叠泛化算法,即引入二级分类器对一级分类器的结果进行仲裁[6],这样虽然考虑得比较全面,但是二级分类器的物理意义显得很不明确,也不容易收敛,并不能保证有更好的分类效果,并且引入二级分类器,使系统的训练和识别的运算复杂度提高,影响实时性.
针对这些问题,笔者从音频、视频提取双模特征参数,引入了不同性质的分类器,即基于概率统计的混合高斯模型(Caussian mixture models,GMMs)分类器和基于函数拟合的小波神经网络(module wavelet neural network,MWNN)分类器;为保证分类器间的差异性,引入表情图片特征的一阶、二阶差分特征向量对GMMs 进行了时序化补偿;在分类器输出匹配化后,引入了基因遗传算法(genetic algorithm,GA)信息融合算法,充分发挥各分类器本身对特定情感的敏感特性,达到较好的融合效果.为了比较,本文还进行了单独MWNN 识别、单独GMMs 识别、无差别投票法、加法法则、乘法法则和层叠泛化算法(其二级分类器为BP 神经网络)识别实验,为了更好地参照效果,针对本文的特定情况(只有2 个分类器,且分类器性质不同),将以上传统融合算法进行了匹配化输出融合改进.
1 系统设计
1.1 整体流程
如图1 所示,整个流程大致分为信号处理与情感训练识别两大部分.首先,对麦克风的语音输入进行适当的预处理以获取有效的语音信号,这些预处理包括分帧、预加重、端点检测等;对摄像头捕获的表情视频文件分帧,每帧转成图片格式,然后进行人脸检测、定位等预处理以获取有效的表情图片信息.随后,从这些处理过的语音信号里提取韵律特征、处理过的表情图片提取人脸几何特征分别形成特征向量.最后,语音韵律特征向量和人脸几何特征向量都利用主元分析法(principle component analgs,PCA)来降维,从而获取最终的特征向量.
在训练阶段,基于语音训练样本的韵律特征被用来训练MWNN 模型,从表情图片训练样本提取几何特征来训练GMMs 模型.在模型训练好的基础上,再次将训练样本输入到MWNN 模型和GMMs 模型,将识别结果形成一个新的样本空间,用GA 在这个样本空间里搜索最优的融合系数向量其中每个λ分别对应一种情感.在识别阶段,音频测试样本经韵律特征参数提取、降维后输入训练好的MWNN 模型识别,视频测试样本经人脸几何特征参数提取、降维后输入训练好的GMMs 模型识别.最后对GMMs、MWNN 2 个分类器的识别结果进行融合,并对情感进行最后裁定.
1.2 情感与特征
如何给情感分类是个有趣又复杂的问题,不同研究者在进行情感识别的研究时选择的情感分类数量和种类往往不尽相同[7-8].本文的最终目的是为了让机器宠物更好地识别主人的基本情感,因此选择了生活中几种常见的基本情感(生气、平静、高兴、悲伤和厌烦)来对情感进行分类.
心理学和韵律学研究表明,说话者的情感在语音中最直观的表现是韵律特征和语音质量的变化,如音调、音强和音质的变化[9].通常与情感相关的声学特征包括基音、持续时间、能量和共振峰,以及它们衍生的均值、最大值、最小值、中间值、取值范围、一阶导、二阶导和变化率等.经过反复地实验,本文最终选取了下面几种韵律特征:语速、能量最大值、能量均值、极点数、基音频率、最大共振峰.
人脸特征一般有几何特征、外貌特征、混合特征这3 种.外貌(appearance)特征泛指使用全部人脸图像像素的特征,反映了人脸图像底层的信息,侧重于提取局部的细微变化,由于要提取的特征点较多,造成维数过高、运算复杂.混合特征将几何特征、外貌特征两者结合起来,计算也较为复杂,而且初始点获取困难.虽然几何特征的识别效果对基准点提取的准确性要求较高,同时几何特征的提取忽略了脸部其他部分的信息(如皮肤的纹理变化)等,但其能描述人脸宏观的结构变化,且提取简单、维数较低,非常符合本系统的要求.
1.3 分类器模型建立
1.3.1 GMMs 模型建立
用多个高斯(正态)概率密度函数的线性组合可以逼近任意密度分布,基于统计思想的GMMs 可以对任意的图片表情特征分布进行精确的描述.由于经过PCA 降维后的20 维的人脸表情几何特征向量在20维空间中的分布不是椭球状的,单个的标准高斯分布不能很好地拟合,所以要建立GMMs 模型.虽然更多的高斯分布能更准确地拟合人脸表情几何特征的分布,但势必会引起更高的运算复杂度,而这对于基于嵌入式平台的智能机器宠物显然无法承受,为了更贴近工程运用,选用4 个高斯函数来加权表示,即
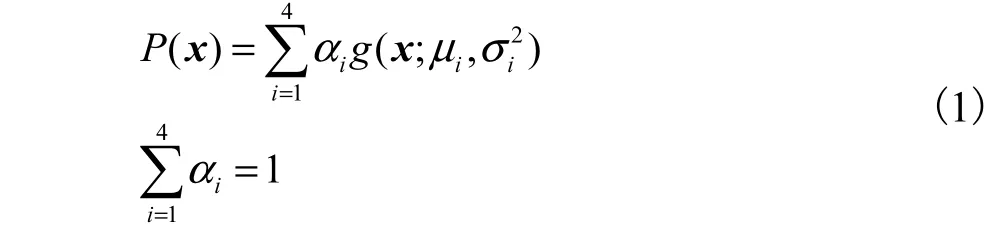
笔者采用最大似然估计法(EM 算法)求取最佳P(θ)的参数值θ,为此需要构造函数
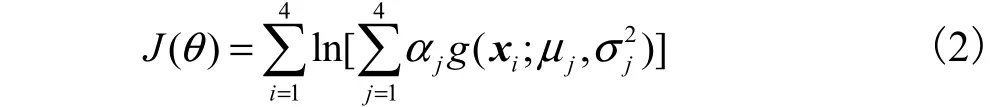
并求其最大值.为讨论方便,引入数学符号
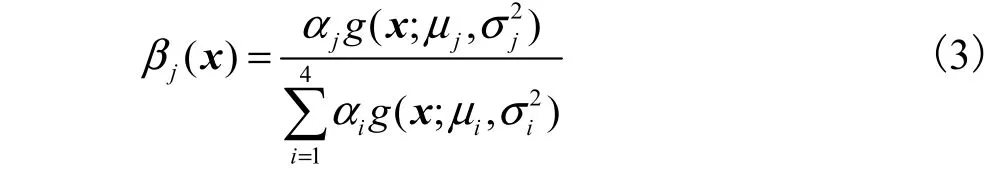
为求 ()J θ极值,求其对 jμ与 jσ的微分,并令其为零,得到8+4d 变量的方程.采用迭代法,得到最佳的(P)x的参数值.
训练就是使用EM 算法确定每种情感的权重系数、均值和协方差,建立各情感的模型,识别过程为求取各情感模型产生测试语音的观测特征序列的条件概率;最大条件概率对应的情感即可作为识别结果.
1.3.2 MWNN 模型的建立
MWNN 有5 个子网络构成[10],如图2(a)所示,每个子网络分别对应一种测试的情感.对于每条情感语句,其情感的识别过程为:语音特征向量分别输入到5个子网络,然后会得到一个输出向量 (v1,…,v5),这个向量表征的是输入的情感语句与5 个情感子网络的相似度,最后根据输出向量元素值、逻辑判决器选取最大值(超过一定阈值时)所代表的情感子网络,并将该子网络所对应的情感作为最终识别结果.
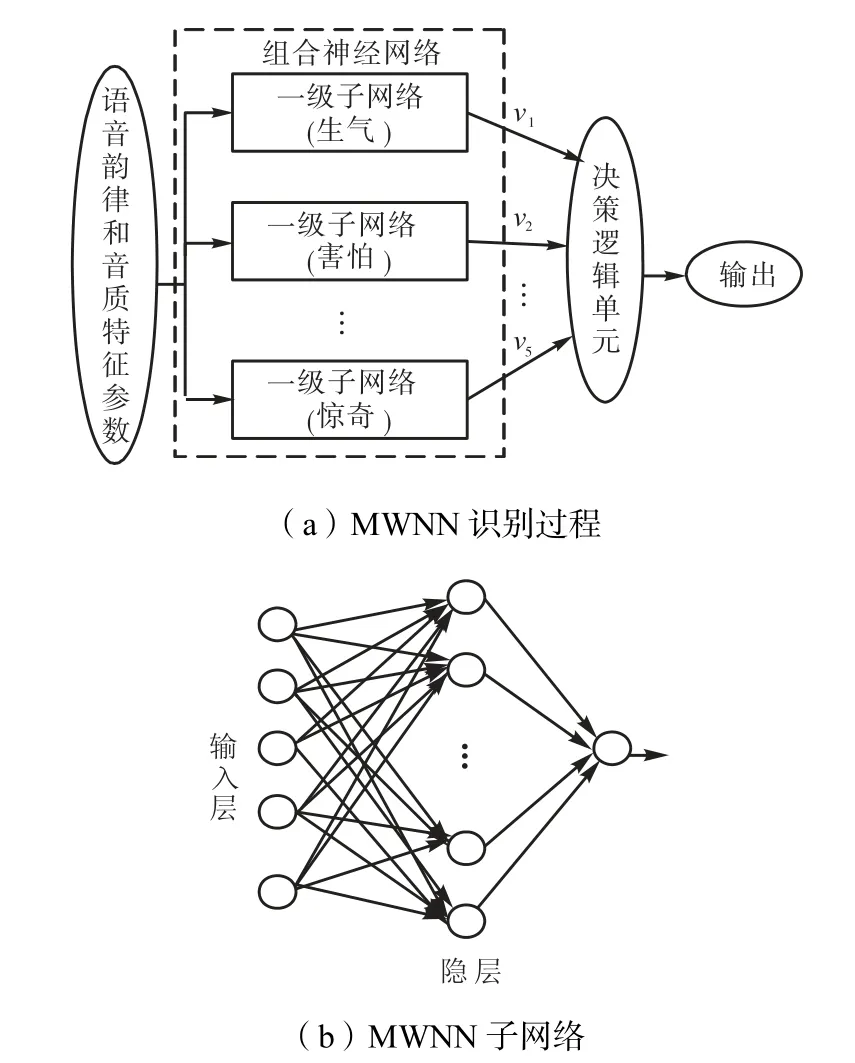
图2 MWNN识别过程及其子网络拓扑Fig.2 Recognition processing flow and sub-networks of WMNN
图2(b)显示了MWNN 的5 个子网络的结构,每个子网络都为3 层网络,由5 个节点的输入层、12 个节点的中间层以及1 个输出节点的输出层构成.当训练时,输出节点值为0.99 或0.01 的一个逻辑量,如果输入的情感语句与对应的情感子网络相匹配,则输出值为0.99,否则为0.01.用5 个单独的子网络对应5 种测试的情感,使得每个网络能够单独调整.如果能够只改变单独的1 个子网络参数,而不需要对整个网络进行调整,对于提高神经网络的学习效率与更新特征参数都是非常有利的.为了提高学习效率,加快收敛速度,采用增加动量梯度下降的学习算法有式中α为动量系数,一般有α∈ (0,1).动量项反映了以前积累的经验,对于t 时刻的调整起阻尼作用.关于小波基函数的选取,目前尚无统一理论方法,通常依据经验及实际情况而定,也可借鉴小波分析中的经验,较早提出的Morlet 小波cos(1.75x )e-0.5x2(该小波为有限支撑、对称、余弦调制的高斯波)已被广泛用于特征提取、图像压缩、分类等领域,本文基于这种思想,选取Morlet 小波作为网络隐层的激活函数.
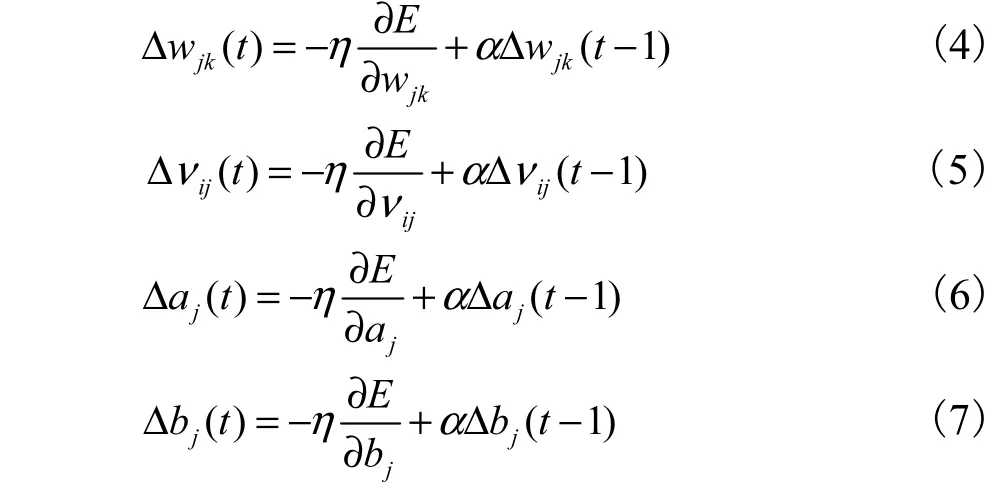
1.4 信息融合算法
1.4.1 传统的融合算法及改进
1) 无差别投票法
传统的投票法采用少数服从多数的原则,一般来说分类器多于2个,且为奇数,避免出现票数相等的情况.由于考虑工程应用的实时性,本文只选择了2 个分类器,且性质不同.MWNN 基于非线性函数拟合,其值较大,接近1;GMMs基于概率统计,其值较小.二者数量级不匹配,因此要进行改进,规则为:① 2 个分类器意见统一时直接输出;② 意见不统一时,则先对GMMs 的输出结果匹配化处理(式(8)),使GMMs与MWNN 输出数量级匹配,然后输出大者胜出.
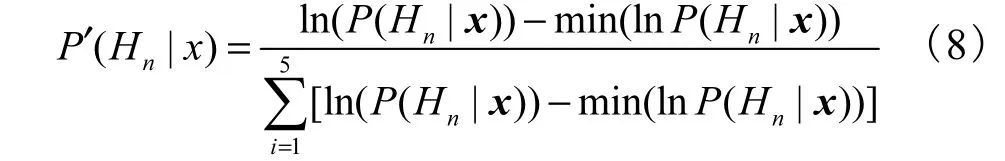
式中n=1,2,3,4,5.
2) 求和法
传统的求和法为
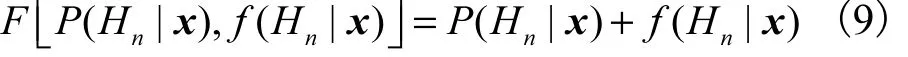
为了改进效果,将GMMs 的输出用式(8)匹配,则
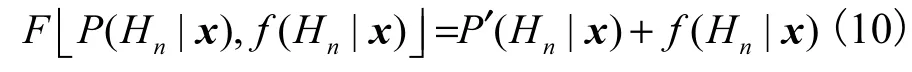
求积法和单系数融合法也用上述方法改进.
3) 改进的求积法
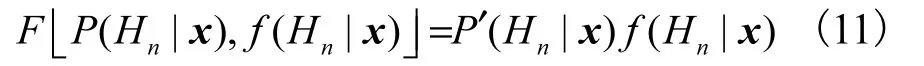
4) 层叠泛化算法
层叠泛化算法即为引入二级分类器对一级多分类器的结果进行仲裁.本文引入的二级分类器为收敛速度比较快的BP神经网络,其为3 层网络,由10 个节点的输入层、12个节点的中间层以及5 个输出节点的输出层构成.训练时,将每个训练样本经过MWNN与GMMs 的输出组成一个10 维的向量来构成此2 级BP 分类器的训练样本集,输出节点值为0.99 或0.01的一个逻辑量,如果输入的情感语句与对应的情感子网络相匹配,则输出值为0.99,否则为0.01.
5) 改进的单系数融合算法
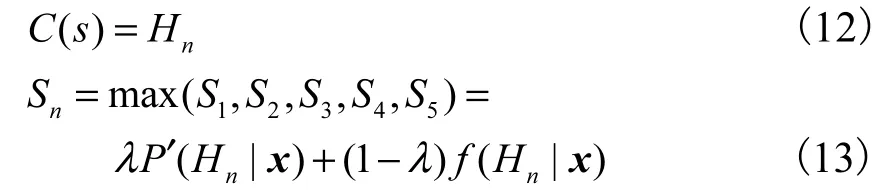
1.4.2 基于GA 的双模融合算法
1) 分类器输出匹配化处理
由于GMMs 模型的各个子模型得到的似然估计是个非常小的正数,而MWNN 模型的各个子网络得到的是介于(0,1)之间的一个较大的正整数,直接融合效果不佳,本文使用式(8)匹配化处理.
2) 建立适应度函数(目标函数)
设输入的测试样本属于m 类,则GA 搜索的适应度函数为
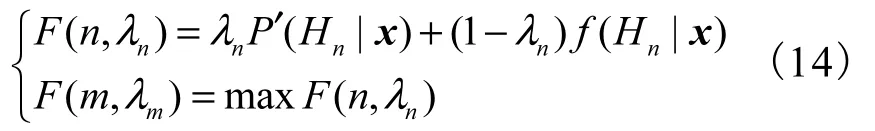
为了简化运算,加入约束条件:①0.01 ≤λn≤1 .00;②λn只能取0.01 的整数倍;③采用十进制编码.
3)信息融合
利 用 融 合 系 数(λ1,λ2,λ3,λ4,λ5)对 匹 配 化 后 的GMMs 及WMNN 的输出结果进行融合,即
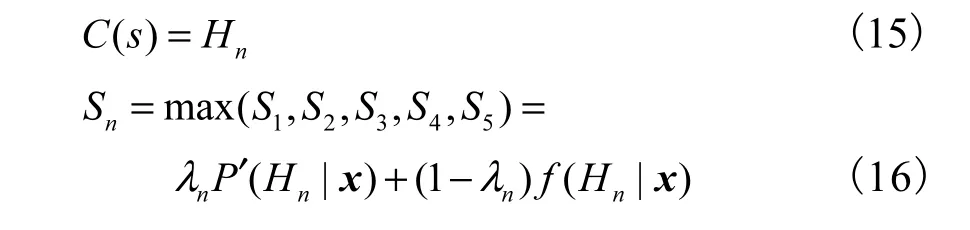
2 实验与结论
2.1 数据库的建立
邀请了3 位富有表演天赋的同学(分别用M1、F1、F2 表示)来完成情感音频、视频联合数据库录制,录制者正脸对着摄像头,近距离对话筒以5 种不同的情感来朗读笔者准备好的30 条情感短句.其中音频文件录制要求嘴唇到话筒距离2~3,cm,采样频率11,025,Hz,16 位量化精度,单声道,并以WAV 格式保存.视频文件采用Sony 摄像头录制,人脸距摄像头50,cm,25 帧/s,并以AVI 格式存储.录制结束,音频文件要用Cool Edit Pro 1.2a 进行适当地预处理,视频文件用AD Video Processor 软件将AVI 视频转成连续的BMP 格式图片保存.最后还要进行语音库、图片库情感成分测试,测试结束,只有符合要求的语句与图片被保留,其他被删除,并将语音文件与图片序列关联保存,作为最后训练与测试的样本.图3 为M1以“高兴”情感朗读“过来”这个语句的联合样本.
2.2 特征提取
2.2.1 语音韵律特征
实验采用短时分析法来分析语音特征,一帧的短时特征为

式中:s(n)为语音信号;w(m-n)为帧长为N的窗体[11].实验最终选择语速、能量最大值、能量均值、极点数、基音频率和最大共振峰作为韵律参数,每一帧的短时能量和过零率分别为

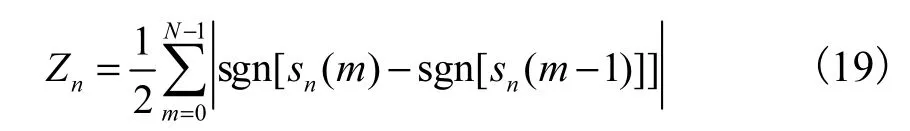
2.2.2 人脸几何特征
本文应用数学形态学和点轮廓检测法[12](point contour detection method,PCDM)获取眼睛、嘴、眉毛和鼻子这4 个正面特征器官的正确轮廓.该方法在提取特征之前,应用数学形态学技术产生边界强度图像,结合原图、先验知识,给面部器官定位.定义原始图像为I,边界强度图像为edgeφ.
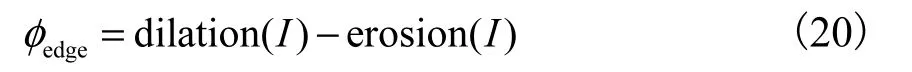
式中:dilation 为膨胀操作;erosion 为腐蚀操作.图4为实验中“高兴-过来” 表情图片的处理结果.

图4 表情图片轮廓提取过程Fig.4 Contour extraction processing flow of facial expres-Fig.4 sion
按照上述的方法,每张表情图片提取20 个面部特征点来描述上述4 个特征器官的位置和形状,其中每条眉毛3 个点,每只眼4 个点,鼻子2 个点,嘴巴4个点,坐标原点取眉心处.
为了体现视频分帧后的表情图片的时序特性,每张(帧)表情图片先用20×2 的向量表示,然后进行向量拉直为40×1 向量,这些向量作为一次样本,引入一阶差分特征、二阶差分特征,形成二次样本;将这些样本集合起来,经过PCA 降维后形成20 维的样本集,作为最终的GMMs 训练、识别样本集.
2.3 实验结果
2.3.1 泛化能力
分类器在工程应用中最为核心的问题就是它的泛化性能(推广能力),即训练完成后的模型对测试样本或工作样本做出正确反应的能力,没有泛化能力的分类器便没有任何价值.
由图5 可见,传统的融合算法如果不匹配化处理,如传统求和法得到的识别率与单独MWNN 是一样的(50 样本时均为82%,100 样本时均为84%),这是因为基于统计规律的分类器GMMs 输出结果很小,加到MWNN 的输出结果上并不能起到改进的效果.经过分类器匹配化处理后,求和法、求积法和投票法识别率都得到提高,虽然层叠泛化算法效果也比较好,但无论是小训练样本(50 个训练样本),还是大训练样本(100 个训练样本),基于新的GA 融合算法在相同条件下都能获得更高的识别率,分别为92%和94%,因而具有更强的泛化能力.
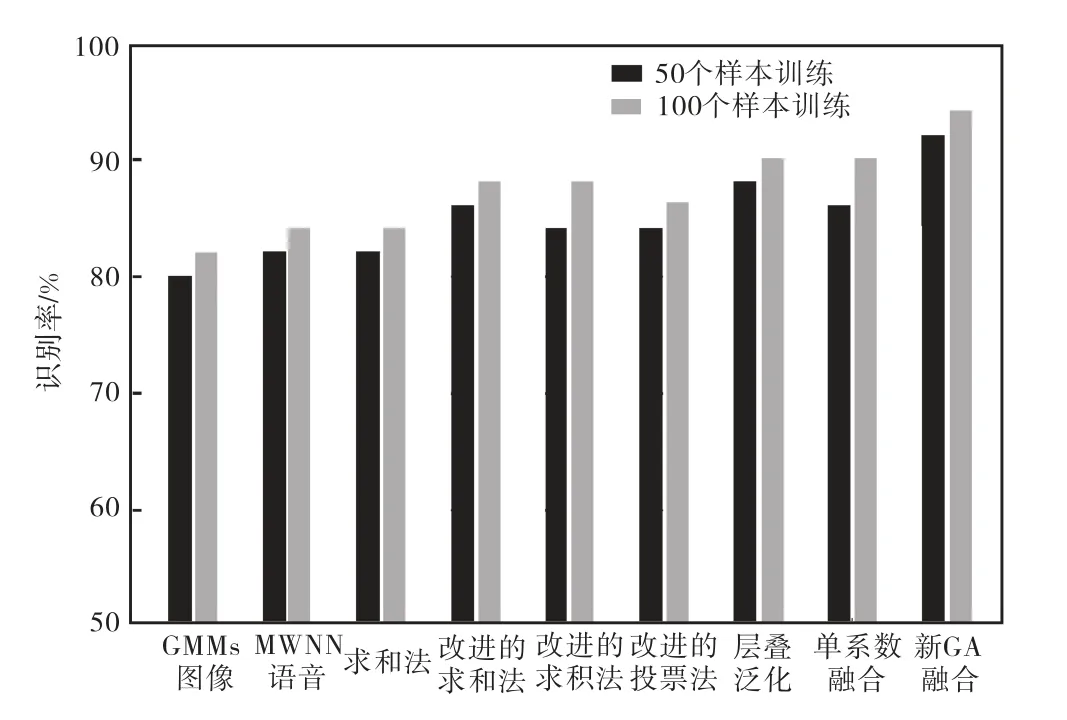
图5 各种算法的泛化能力Fig.5 Generalization ability of various algorithms
2.3.2 识别率
图6中所有的识别结果都是以100 个样本进行训练,50 个样本进行测试,不难发现,对于3 位测试者(M1、F1、F2),都存在如下规律.
(1) 对于分类器匹配化,传统的融合算法中求和法则与求积法则受分类器性质的影响最大,如果不匹配化输出,则结果与单独MWNN 一样,基本不会有任何改善;投票法、直接融合算法虽然也受影响,但影响不大,匹配化后识别率也会有一定的提升;分类器性质对层叠泛化这种传统融合算法基本不会有任何影响,所以这种算法不需要匹配化输出.
(2) 对于识别率,在传统的融合算法中,层叠泛化算法是最高的,其次是改进后的直接融合算法,经过输出匹配后,求和法、求积法、投票法各有千秋,其中求和法与投票法识别率相对比较稳定,而求积法更容易受数据库的影响(对于F1 识别率在三者中最低,到了F3 则变为最高).
对于所有测试者,图6 还显示了一个更为明显的结论:相比于单模态或其他的分类器融合算法,基于新的GA 融合算法在相同条件下都能获得更高的识别率, F1 为94%、F2 为92%、M1 为90%.
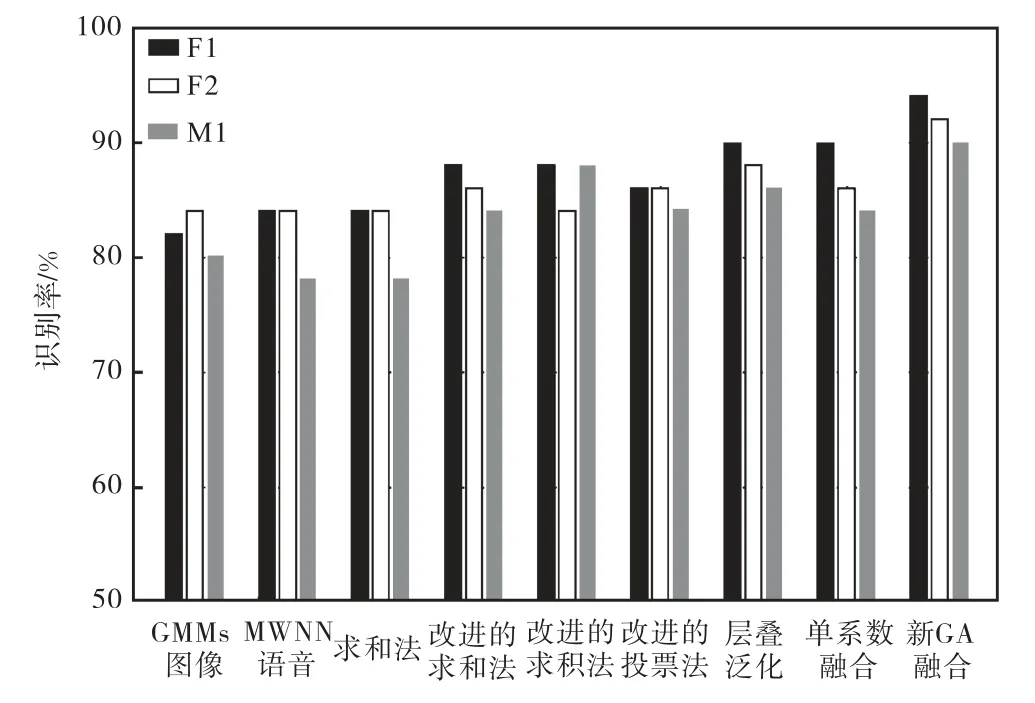
图6 各种算法的识别率Fig.6 Recognition rate of various algorithms
3 结 语
为了提高识别率和泛化能力,笔者从音频、视频两方面来提取特征参数(语音韵律参数与人脸几何参数),选择了差异性强的MWNN和GMMs 分类器,并匹配化了分类器输出,提取表情图片特征的一阶、二阶差分特征向量对GMMs 进行时序化补偿,引入了GA 算法来搜索最优的融合系数向量,充分发挥各分类器本身对特定情感的敏感特性,提高了融合效率.
为了更贴近工程运用,并最终应用于智能机器宠物,GMMs 只引入4 个基本高斯分布来简化模型,MWNN 每个子网络均采用单隐层,5 个输入节点,单输出节点的简单网络拓扑结构,WMNN、GMMs 均为5个独立的子模型构成,每个模型对应一种情感,当系统进行反馈学习时,只要调节相应的子模型即可,简化了再学习过程.特征提取后,利用PCA 进行降维处理,降低系统的计算复杂度,WMNN 采用增加动量梯度下降的学习算法来提高收敛速度,提高系统的实时性.笔者根据识别结果加入一个反馈再学习环节,因此分类器模型不是固定不变的,而是随着时间更新而动态变化,这样才符合人类情绪表达方式会随着时间推移而变化的事实.
[1]Fragopanagos N,Taylor J G. Emotion recognition in human-computer interaction[J].Neural Networks,2005,18(4):389-405.
[2]Bosch L. Emotions speech and the ASR framework[J].Speech Communication,2003,40(1/2):213-225.
[3]Cowie R,Douglas-Cowie E,Tsapatsoulis N,et al. Emotion recognition in human-computer interaction[J].IEEE Signal Processing Magazine,2001,18(1):32-80.
[4]Morrison D,De Silva L C. Voting ensembles for spoken affect classification[J].Journal of Network and Computer Applications,2007,30(4):1356-1365.
[5]France D J,Shiavi R G,Silverman S,et al. Acoustical properties of speech as indicators of depression and suicidal risk[J].IEEE Trans Biomed Eng,2000,47(7):829-837.
[6]Morrison D,Wang Ruili, De Silva L C. Ensemble methods for spoken emotion recognition in call-centres[J].Speech Communication,2007,49(2):98-112.
[7]Bhatti M W,Wang Y,Guan L. A neural network approach for human emotion recognition in speech[C]//IEEE International Symposium on Circuits and System. Canada,2004:181-184.
[8]Murry I R,Arnott J L. Applying an analysis of acted vocal emotions to improve the simulation of synthetic speech[J].Computer Speech and Language,2008,22(2):107-129.
[9]林弈琳,韦 岗,杨康才. 语音情感识别的研究进展[J]. 电路与系统学报,2007,12(1):90-98.Lin Yilin,Wei Gang,Yang Kangcai. A survey of emotion recognition in speech[J].Journal of Circuits and Systems,2007,12(1):90-98(in Chinese).
[10]Huang Yongming,Zhang Guobao,Xu Xiaoli. Speech emotion recognition research based on wavelet neural network for robot pet[C]// 5th International Conference on Intelligent Computing.Korea,2009:993-1000.
[11]Ververidis D,Kotrropoulos K. Emotional speech recognition:Resource,features,and methods[J].Speech Communication,2006,48(9):1162-1181.
[12]Chang J Y,Chen J L. Automated facial expression recognition system using neural networks[J].Journal of the Chinese Institute of Engineer,2000,24(3):345-356.
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中国交通信息化(2016年2期)2016-06-06
