
基于特征的人脸分类算法研究
2010-05-05 02:39李霞赵宇明
微型电脑应用 2010年4期
李霞,赵宇明
0 引言
人脸是人类最重要的生物特征之一,反映了很多重要的信息,在许多场合都需要进行可靠的人脸特征分类。比如在一些实用的实时监控系统中,人脸分类技术有助于从监控录像中找出符合某种指定特征的那些人,这在机场、海关、火车站、银行、饭店等出入系统中有很大的需求。另外,在公安刑侦破案系统中,人脸分类技术可以帮助目击者查询目标人像数据库中是否存在嫌疑人员。此外,人脸分类技术在人机交互系统中也有重要作用,如依据属性进行人脸搜索,以及个人相册的管理等。
本文考虑基本正面的人脸,针对墨镜和口罩两个属性,将人脸图像分成4类:没有佩戴任何饰物的人脸、带有墨镜的人脸、带有墨镜和口罩的人脸、带有口罩的人脸。
一般的人脸分类系统,可以大致分为以下几个步骤:人脸检测、特征提取、分类。本文的研究重点是各种不同的分类算法,在研究前人工作的基础上,对一些现有的分类算法做了理论和方法上的探讨,通过实验系统地分析了五种解决方案,包括PCA+LDA+Correlation方法,SVM方法,PCA+LDA+SVM 方法,SVM+Adaboost方法,以及PCA+LDA+SVM+Adaboost方法,并比较了这些方法的性能,分析了它们的不足。需要指出的是,本文在前3种方法中用到的是 Haar特征,在后两种方法中则是将特征值进行一系列处理,这将在1.4节中进行详细的介绍。实验结果表明,采用PCA+LDA方法降低特征维数,可以大大减少分类速度,同时对分类器性能没有明显影响。另外,第4种方案的分类正确率达到了94.5%,满足实际应用的需求。
1 分类算法
在人脸领域应用较多的分类算法有:主分量分析(PCA)、线性判别分析(LDA)、相关系数(Correlation)、支持向量机(SVM)、Adaboost算法等,在这里对各个方法进行了深入的探讨,并总结出五种典型的组合方案,在本节中分别介绍如下:
1.1 PCA+LDA+Correlation
主分量分析[1](PCA,Principal Component Analysis)是一种非常有效的降维方法,其主要思想是:将原数据空间投影到一个新的坐标空间,在减少数据集维数的同时,保持数据集对方差贡献最大,从而能保留数据的最重要方面。假设训练样本,用PCA方法将其降到m维(m<n)的步骤如下:计算样本集合的协方差矩阵其中ц为均值向量;将Σ的特征值从大到小排列,取前m个特征值对应的特征向量构成变换矩阵;则样本x的降维公式为。在很多模式识别方法中,PCA方法都被用来对高维样本进行压缩降维,从而加快处理速度或降低问题复杂度。然而,PCA并没有充分利用训练样本中的类别信息,LDA则弥补了这个缺陷。
线性判别分析[2](LDA,Linear Discriminant Analysis)也是一种常用的降维方法,其目标是降维后样本的类间离散度和类内离散度的比值最大,即各类样本在特征空间中有最佳的可分离性。假设训练样本,对于C类问题而言,构成变换矩阵WLDA的向量最多只有C-1维,用LDA方法将x降到C-1维的步骤如下:计算样本集合的类间离散度矩阵和类内离散度矩阵;计算的广义特征值和特征向量,将λi从大到小排序,取前C-1个特征值对应的特征向量构成变换矩阵在实际应用中,LDA方法则存在类内分散度矩阵总为奇异阵而使求解变得很困难等缺点,因此本文先用 PCA进行降维,然后用LDA来得到维数更低的最佳判别特征,最终的变换矩阵就是
相关系数(Correlation)是变量之间相关程度的指标,计算公式为,取值范围为值越大,变量之间的线性相关程度越高。
1.2 SVM
支持向量机SVM[3],[4],[5](Support Vector Machine),是一种监督式学习的方法,广泛应用于统计分类和回归分析中。其主要思想可以概括为两点:(1)它是针对线性可分的情况进行分析,对于线性不可分情况,通过非线性映射的方法,将低维输入空间线性不可分的样本转化为高维空间,使其线性可分;(2)基于结构风险最小化理论之上,在特征空间中构建最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。
许多研究人员已经开发出了SVM的工具箱,方便用户使用,如libsvm,svmlight,stprtool等等。本文使用了台湾大学林智仁博士等开发设计的libsvm软件包。
1.3 PCA+LDA+SVM
对于大规模复杂问题,SVM训练时间过长,计算量很大,为此本文提出第三种方案,在进行SVM训练之前,用PCA+LDA的方法降低特征向量的维数,因此能大大减少SVM训练的负担。实验表明,在分类前对特征向量进行降维处理,起到了压缩样本,减少计算量的作用,而且不会明显降低分类正确率。
1.4 SVM+Adaboost
依据文献[6],本文提出第四种解决方案。这里特征提取的大致过程为:如表1所示,对于指定区域(上部或下部)的像素值,首先转化成第2列中的一种类型,然后利用第3列中的一种方法进行归一化处理,最后选择是否进行直方图处理,输出最终的特征向量。下面进行详细的介绍。
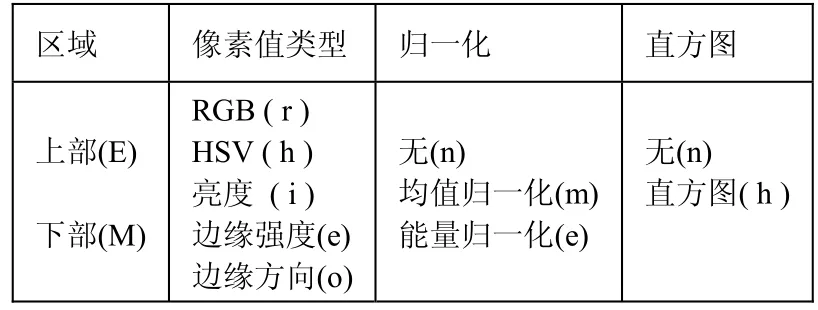
表1 可选择的特征类型
(1)区域:如果选择整个人脸图像中的像素,将会给分类器带来时间和空间上的负担,并且有可能引入一些不易区分的像素点。为此,将人脸图像分为上下两部分,如图1所示,分别用于墨镜分类和口罩分类的处理。

图1 区域选择
(2)像素值类型:本文用到了不同的颜色空间和图像导数值作为像素类型,因为对于一些属性而言,这些信息通常比标准的RGB值有更大的可区分度。表1列出了不同的选项。
(3)归一化:归一化处理可以消除光照的影响,在此,均值归一化和能量归一化作为选择,其中µ和σ分别是指定区域内所有特征向量x的均值和标准方差。
(4)直方图:对一些属性而言,在整个区域内的直方图信息可能比单个像素点的信息更加有用,因此可以考虑对图像提取直方图信息。
Boosting[7]算法是一种现代统计方法,理论上可以用来改进任何学习算法的性能。Adaboost是一种自适应的Boosting算法,其核心思想是将若干个弱分类器整合为一个强分类器,其中弱分类器指的是那些性能比随机分类略好一点的分类器,本文选用SVM作为弱分类器。Adaboost算法本身是通过改变数据分布来实现的,它根据每次训练样本的分类是否正确,以及上次的总体分类的正确率,来确定每个样本的权值。将修改过权值的新数据送给下层分类器进行训练,最后将每次训练得到的分类器整合起来,作为最终的决策分类器。使用Adaboost分类器可以排除一些不必要的训练数据特征,并将重点放在关键的训练数据上。
1.5 PCA+LDA+SVM+Adaboost
同样的,考虑到SVM训练时间过长,占用内存过大等问题,引进最后一种方案,PCA+LDA+SVM+Adaboost。实验结果表明,特征向量经过降维处理之后,可以大大的减少后期的训练时间,并且最后的分类正确率和第四种方法几乎一样。
2 实验
2.1 人脸库
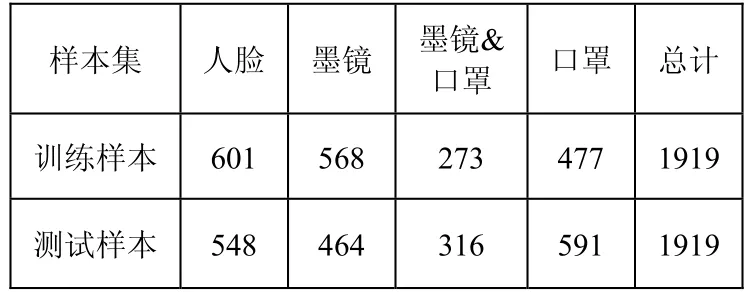
表2 样本集大小汇总
本文用到的样本来自于OMRON公司的人脸库,其中训练样本1919个,测试样本1919个。针对墨镜和口罩这两个属性,样本分别属于四个不同的类别,每个类别所含的样本数如表2所示。
2.2 人脸样本预处理过程
对于不同姿态的人脸图片,需要一个预处理的过程,将这些人脸统一到标准大小和姿态条件下,在这里进行了基于特征点的几何标准化,即根据人脸的特征——左眼中心,右眼中心和嘴中心,经过几何变化,将人脸调整到规定尺度。在本文的实验中,最终得到的标准化人脸图像分辨率为128*105。
2.3 五种分类方法的性能比较
对经过标准化之后的人脸图像进行特征提取,然后用第1节中的5种不同的分类器进行分类,得到的实验结果如表3所示。对比发现,本文提出的第四种方案SVM+Adaboost拥有最低的错分类率5.05%,能够达到实际应用的要求。通过PCA+LDA的方法对特征进行降维处理能够大大的减少执行时间,并且节省了内存空间。

表3 五种分类方法的性能比较
3 总结
根据不同的属性对人脸图像进行分类,是一个应用十分广泛的实际问题,本文利用了OMRON公司的人脸库,系统地比较了五种分类方法的性能。从实验结果可以看出,在分类之前先对样本进行压缩降维,可以提高分类速度,而且正确率也不会有太大损失。依据文献[6]提出的第四种方案的分类正确率达到了94.5%,但是在这种方法中SVM训练的时间耗费很大,导致系统分类时间过长。相比之下,第五种方案分类正确率达到94%以上,由于对特征进行了降维处理,总的执行时间大大减少,仅为第四种方案的12%左右。对于大型数据,应用第五种方案“PCA+LDA+SVM+Adaboost”进行人脸分类是可行的。
同时,本文的工作还有一些尚未解决的问题。目前考虑到的仅仅是正面姿态的人脸,对于非正面姿态的情况还需要进一步的研究。并且本文只考虑了两种属性——墨镜和口罩下的分类,如果增加其它属性进行分类,文中提到的方法尚不具备可扩展性,这有待完善的。
[1]赵海霞,武建,“浅析主成分分析方法”[J],科技信息,2009(02).
[2]Zhao W,Chellappa R,Krishnaswamy A,“Discriminant Analysis of Principal Components for Face Recognition”,Proc.of the 3rd IEEE International Conference on Automatic Face and Gesture Recognition,Nara,Japan,pp.336-341,April 1998.
[3]Boser B E,Guyon I M,Vapnik V N.“A training algorithm for optimal margin classifier”,Proc.5th ACM Workshop on Computational Learning Theory,Pittsburgh,PA,pp.144-152,July 1992.
[4]董李燕,刘艺蕾,王晓峰,“基于人脸局部特征和SVM的表情识别”[J],合肥学院学报(自然科学版),2009,(01):24-27.
[5]Cortes C,Vapnik V.“Support vector networks”,Machine Learning,20:1-25,1995.
[6]Kumar N,Belhumeur P,Nayar S.“FaceTracer:A Search Engine for Large Collections of Images with Faces”,Proc.of European Conference on Computer Vision,2008.
[7]Seiffert C,Khoshgoftaar T M,Hulse J V,Napolitano A.“Resampling or Reweighting:A Comparison of Boosting Implementations”,2008 20th IEEE International Conference on Tools with Artificial Intelligence,2008.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
车主之友(2022年4期)2022-08-27
保定学院学报(2022年2期)2022-04-07
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
海峡姐妹(2019年12期)2020-01-14
动漫星空(2018年9期)2018-10-26
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
火控雷达技术(2016年1期)2016-02-06
