
一种基于语义可理解的信息过滤算法
2010-03-27 06:55张波向阳王坚
电子与信息学报 2010年10期
张 波 向 阳 王 坚
(同济大学电子信息与工程学院 上海 201804)
1 引言
面对互联网中浩如烟海的信息,人们往往为无法准确获取自己真正关心的信息而束手无策。如何准确有效地为用户获取信息,实现个性化信息获取,是当前信息检索领域一个重要的课题。信息过滤是将用户需求和动态信息流进行近似计算,从信息流中抽取符合用户个性化需求的信息并主动推送给用户的系统化方法[1,2]。尽管传统的信息系统及其信息获取技术(如搜索引擎等)已经取得了长足的发展[1−4],但是由于无法真正针对不同用户进行个性化的服务,人们依旧需要通过不停地变换关键词进行重复搜索,或者面对大量搜索返回信息进行再次检索。信息中所包含的大量内容以及用户的真实意图无法被机器真正理解,导致信息获取效果不佳。
信息过滤的研究在国内外已经开展了很多。Cohen[5]提出了利用基于RIPPER规则学习算法和关键词学习规则进行邮件分类。文献[6]中提出了隐私意识交互作用下的垃圾信息协同过滤方法;文献[7]则提出了一种基于隐马尔可夫模型的通用过滤算法;文献[8]提出了一种规范化的交互信息特征选择方法,利用信息特征规范化表示和选择等实现交互信息的过滤。在国内,清华大学的曾春等提出利用领域分类模型上的概率分布表达用户的兴趣模型,给出相似性计算和用户兴趣模型更新方法[9]。文献[10]提出了一种建立信息流二元近似关系模型,辅助信息过滤系统识别和屏蔽反馈中的噪声。在众多基于语义技术的信息过滤研究中,文献[11]提出了一种基于本体的信息检索技术,利用本体概念的语义描述能力实现信息准确检索。文献[12]则提出利用OWL描述信息语义,进而在语义网环境中实现信息过滤。文献[13]则给出了一种通过奇异值分解以及独立分量分析获取的潜在语义描述方法实现信息过滤。然而目前有很多信息过滤系统[3,4,14],最大问题在于计算机无法自动对用户需求和网络信息进行自动理解和处理,无法将用户个性化需求和信息所包含内容进行有效识别,从中获取最为相符的结果。
针对上述问题本文首先给出信息语义的定义,并且给出了信息语义被信息领域本体理解的判定方法。然后定义了信息过滤过程中的用户需求语义和用户兴趣语义,并分别提出了用户需求语义被信息领域本体理解的判定方法,及用户兴趣语义的权重计算。最后给出了一种语义可理解基础上的信息过滤算法。实验证明这种信息过滤算法能够有效地提高信息获取的效率。
2 信息领域本体
信息领域本体IO是4元组:IO=(C,SR,IR,P),其中C表示概念名;SR表示概念之间的上下位结构性关系;IR表示概念之间的非结构性关系;P表示描述概念的属性。IO中概念的权重rc与属性的权重rp满足如下条件1)本文后面所采用的概念权重计算方式为,若c''是c'的直接子概念,则rc''=rc'/n;属性权重计算为,若概念c'存在m个描述属性c'⋅pj ,则rpj =1/m。:
(1)根概念节点的权重为1;
(2)存在n概念c'与概念c''具备如下关系:c''={x|∃x∈IO.C∧SR(c',x)},即c''是c'的直接子概念,则满足
(3)概念ci存在m个描述属性c'.pj,则对于一个概念的所有属性而言,其权重满足
定义1 概念语义扩展是指在信息领域本体IO中,对于一个概念c'来说,若存在概念c''∈IO.C,满足c''={x|SR(c',x)∨SR(x, c')∨IR(c',x)∨IR(x,c')},则称概念c''为概念c'的语义扩展,概念语义扩展得到的集合记为rel_c(c')。
3 信息语义
3.1 信息语义表示及理解判定
若信息中的概念在该信息中的重要度大于给定阈值,则称该概念为特征项,记做CT。特征项CT若存在对其性质的描述集合CS,描述集合中的个体csk⊆CS 称为特征项CT的解释,cs的值记为cs_val。
信息I完整的语义可以表示为如下形式:

其中特征项cti的权重为righti; 序对|_val表示特征项cti的第k个解释及其解释的值。
定义2 对于信息领域本体IO,给定的特征项及其解释集合(ct,(cs1|cs1_val,cs2|cs2_val,…))若存在赋值映射N,满足Nct→IO.c,且存在至少一个解释csk=IO.c. p,则称该信息特征项可被IO理j解;若所有解释csk=IO.c. pj,则称该信息特征项可被IO完全理解。
定义3 信息I可被IO理解,当且仅当所有特征项cti⊆CT 可被IO理解;信息I可被IO完全理解,当且仅当所有特征项cti⊆CT 可被IO完全理解。
算法1 信息被信息领域本体理解判定算法

上述算法中,函数find(cti,IO)用于找到并返回特征项在IO中的匹配概念;函数match(,IO)判断find函数中返回的概念属性是否与解释cs匹配。
3.2 信息特征项的权重计算
信息特征项权重分为3类:词频权重、位置权重以及本体权重。特征项权重计算的公式定义为
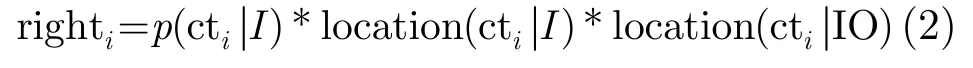
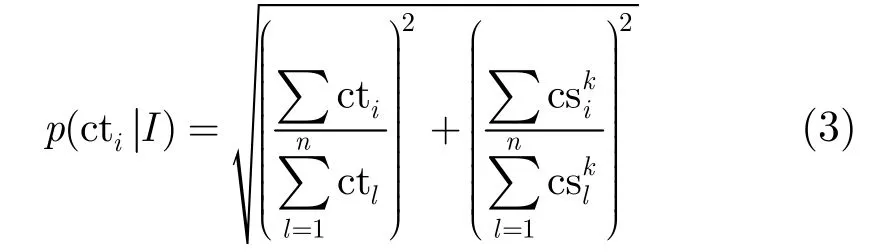
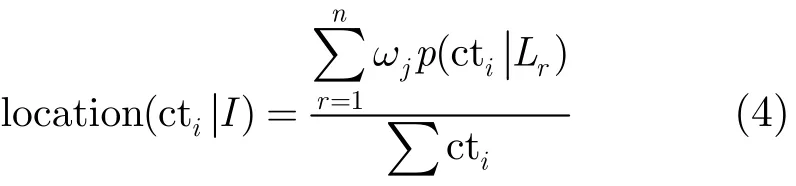
其中p(ctiLr)表示词cti在位置Lr上的出现次数;而对于那些无位置结构关系的信息而言,位置权重忽略计算。

其中rco表示概念IO.co的权重;表示描述概念IO.co的所有IO.co. pj属性的权重总和;0≤λ≤1是预设参数。
4 用户语义
4.1 用户需求语义表示及其理解判定方式
用户需求包含用户直接输入的需求特征以及其潜在可能的需求特征项。用户需求语义可表示为:R=<(definite_R,latent_R)>,其中definite_R为显性需求集合,latent_R为隐性需求集合。本文引入需求内涵与外延两个方面表征用户需求。用户需求的内涵connotation是有关用户需求的内容、中心含义,用户需求外延extention是有关主题涉及的范围、特征等。
定义4 对于给定IO,以及给定的用户需求r的内涵、外延集合(connotation,(extention1,extention2…)),如果存在一个赋值映射N,对于该用户需求的内涵而言,使得Nr.connotation→IO.c ,且满足存在至少一个外延extentionu=IO.c. pj,那么该用户需求称为可被信息领域本体IO理解。
对于给定的用户需求集合R,若至少存在一个用户需求r∈R可被信息领域本体IO理解,则称该用户需求集合R可以被信息领域本体IO理解;若所有的r∈R都可以被信息领域本体IO理解,则称该用户需求集合R可以被信息领域本体IO完全理解。
定义5 若一个显性需求definite_rv可被信息领域本体理解,对应的本体概念为IO.co,则其相对应的隐性需求集合满足latent_R=rel_c(IO.co)。
算法2 显性需求理解判定与隐性需求获取算法

算法2中,find()函数与算法1中相同,get()函数为概念语义扩展函数,返回是否找到语义扩展概念以及这些语义扩展概念集合。
4.2 用户兴趣语义表示及权重计算
用户兴趣是若干用户主题组成的对信息的复杂心态。用户主题表示为序对Ts|ws,其中Ts表示主题的概念,ws表示该主题的用户关心度。本文定义两类评价结果:积极评价positive_Ts和消极评价negative_Ts。评价附加权重η计算为

假设有固定样本集合N,对于某一个主题T而言,其在信息领域本体中对应的概念为ci,描述属性为ci. pj,而通过语义扩展得到的相关概念为rel_c(ci),函数P(x)表示对象x在固定样本集合N中的出现概率。那么该主题的权重w可以表示为

其中a, b, c分别为调节参数,满足0≤a≤1,0≤b≤1,0≤c≤1,且a+b+c=1。
5 基于语义可理解的信息过滤算法
5.1 映射索引与未知表
本文采用概念映射索引(CMI)和属性映射索引(PMI)表示信息领域本体中对应的概念和属性。
定义6 概念映射索引是一个2元组CMI=(IO.C, M(IO.C)),其中IO.C是信息领域本体中概念集合,M(CT)是概念IO.c在信息中满足赋值映射Nct→IO.c的信息项ct;或满足赋值映射Nr.connotation→IO.c 的用户需求r的集合。
定义7 属性映射索引是一个3元组PMI=(IO.C. P, M(IO.C. P),CMI),其中IO.C. P是信息领域本体中概念的属性集合,M(IO.C. P)是信息领域本体中该属性对应的信息特征项的解释集合,或用户需求的外延集合,CMI指明属性与解释如何通过概念与特征项建立对应关系。
在CMI中,若满足Nct→IO.c∧Nr.connotation→IO.c ,则称信息特征项与用户需求内涵建立了映射索引,同理在PMI中可建立信息特征项解释与用户需求外延的映射索引。CMI映射索引函数形如f(r.connotation)=ct ;PMI映射索引函数形如f(r.extention)=ct.cs 。
信息语义I与用户需求语义R之间的映射索引相似度Sim_MI(I, R)可以表示如下:
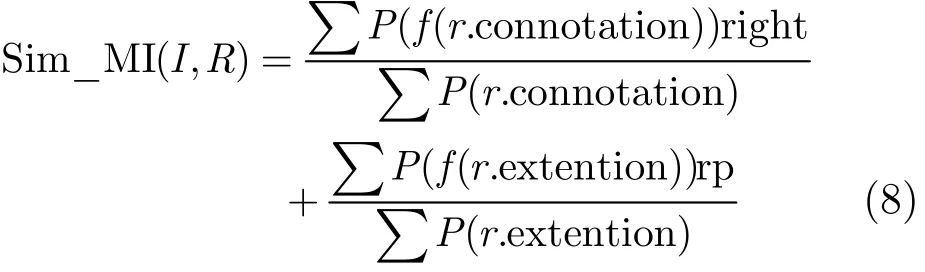
其中函数P(x)表示x出现次数;函数f(x)表示x在映射索引CMI和PMI中建立映射的对象,right为对应信息特征项的权重值,rp为信息特征项的解释对应的信息领域本体中概念属性的权重。
本文采用未知信息表(UIT)存放不能被信息领域本体理解的信息语义,同时采用未知需求表(URT)存放无法被信息领域本体理解的用户显性需求。不可理解的信息语义和用户需求语义之间的未知相似度Sim_U(I, R)可以用式(9)计算:
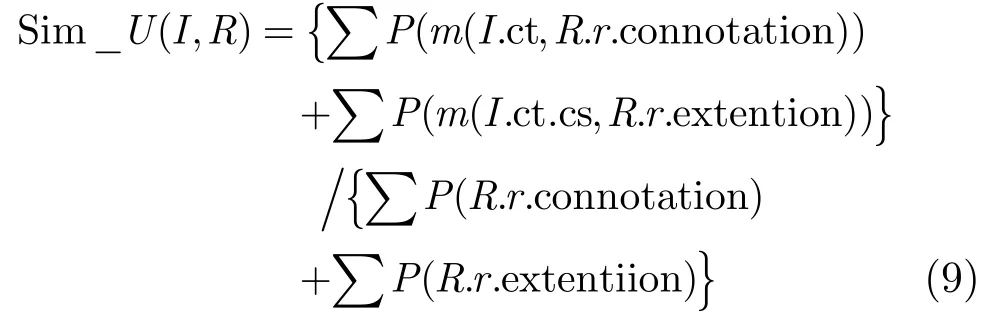
其中函数m(I.ct,R.r.connotation)表示有哪些不可理解的信息特征项与不可理解的用户需求内涵完全匹配;m(I.ct.cs,R.r.extention)则表示哪些不可理解的信息特征项的解释与不可理解的用户需求外延匹配。
5.2 用户兴趣与特征项相似度计算
本文将通过计算出兴趣主题与信息特征项之间的相似关系,从而得到尽可能符合用户兴趣的信息。假设信息语义为I,其中可以被信息领域本体理解的特征项记为mctj;不可被信息领域本体理解的特征项记为nctj;用户兴趣为In。用户兴趣主题与信息特征项相似度可计算如下:

5.3 语义可理解的信息过滤流程
设信息I可被信息领域本体理解的特征项记为mctj;不可被信息领域本体理解的特征项记为nctj;用户兴趣为In,本文采用如下信息过滤算法流程:
(1)对于信息中的所有特征项,利用算法1判定该信息被信息领域本体理解的程度,分为3类情况:
(a)若信息为可完全理解的,则将该信息中所有特征项与本体概念形成概念映射索引(CMI),同时将特征项解释与对应的本体概念属性形成属性映射索引(PMI);
(b)若信息为可理解的,则按照(a)形成CMI和PMI。同时将未被理解的特征项及其解释提取,形成未知信息表;
(c)若信息是不可理解,则按照(b)方法将该信息特征项与解释形成未知图存储;
(2)对于一个用户请求Pro,首先利用算法2判定显性需求被理解的情况,并获取隐性需求集合latent_R。分为以下情况:
(a)若用户需求为可完全理解,则建立用户需求与信息本体间CMI和PMI;
(b)若用户需求为可理解的,则按照(a)方法建立CMI和PMI,并将不可理解对显性需求的内涵和外延形成URT;
(c)若用户需求不可理解,按照(b)中方法形成URT,此时用户需求中的隐性需求集合为空;
(3)计算Sim_MI(I, R)与Sim_U(I, R);
(4)信息语义与用户需求语义相似度为(公式中θ为预设调节参数):

(5)将Sim(I, R)的值大于预设阈值的信息保留,其他结果去除;
(6)计算Sim(Ts,mctj),进而计算μs=(sim(Ts,mctj)+ws+rightj)/3;
(7)计算sim(Ts,nctj),进而计算σs=(sim(Ts,nctj)+ws+rightj)/3;
(8)计算信息与用户需求的语义相似度为(ϑ为预设调节参数):
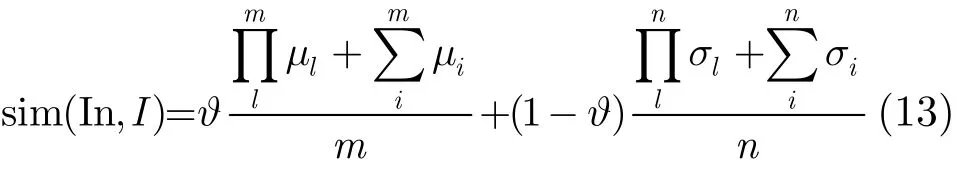
(9)根据用户设定进行信息推送2)本文所指的用户设定信息推送方式由用户事先指定。。
6 实验分析
本文利用自主开发的计算机领域学术论文过滤原型系统来验证提出的信息过滤方法的有效性。该系统包括自主开发的计算机领域本体,中文词语分析系统以及论文过滤系统3个部分。计算机领域本体采用protege3.1开发;中文分词系统在eclipse下采用JAVA开发;论文过滤系统采用JAVA开发。实验中有关公式计算的取值如下:式(2)中的计算符*为3个权重的算术平均值;所有式中的预设参数以及预设阈值均为0.5;式(6)和式(8)中取值为a=0.4,b=0.3,c=0.3,公式(7)中α=0.3,β=0.3,γ=0.4。
6.1 信息语义与用户需求语义的理解效果测试
实验1 用户需求语义理解对信息过滤的影响
本文测试时采集了300篇学术论文用于过滤,经过前期测试,其中142篇可以被计算机领域本体完全理解,记为Group 1;117篇可以被计算机领域本体理解,记为Group 2;另外41篇不能被理解(非计算机领域论文),记为Group 3。
实验方案:该实验将3组论文合并一起,同时作为信息过滤的候选论文集。此时,由于经过前期测试,所有论文的信息语义被理解状态已经确定。因此,过滤效果依赖于所输入的用户需求语义被理解的情况。我们进行了20次用户语义理解对信息过滤的效果测试,每一输入一次用户需求语义则仅针对全体候选集合进行一次信息过滤实验。为了检验用户需求语义理解程度对过滤效果的影响,前10次过滤为用户需求语义被计算机完全理解,第11到第15次为用户需求语义被计算机理解,第16到第20次,用户输入需求语义不能理解。
在每次信息过滤实验完毕后,我们将系统所返回的论文依据其来源将其人工归类到原有Group中,并从中挑选用户真正满意的不同Group中的论文。该效果检验值计算方式可表达如下:
图1中可以看出,前10次过滤由于用户需求语义明显理解清晰,因此效果最好;第11到15次,由于语义仍有能被计算机理解,因此过滤效果也好于最后5次。可见能得到语义可理解的信息和用户需求,其过滤效果最好。
实验2 信息语义理解对信息过滤的影响
本实验测试时,我们给出了3组不同的用户需求。第1组为20个可被计算机完全理解的用户需求语义,记为Group 4;第2组为20个可被计算机理解的用户需求语义,记为Group 5;第3组为20个不可被理解的用户需求语义,记为Group 6。
实验方案:该实验在用户需求语义理解状态确定的情况下针对不同信息语义理解对过滤效果的影响测试。从实验1的3组论文中选取信息语义理解效果不同的对象,进行测试。实验针对不同的用户需求语义分为3组,每组同时进行20次过滤。前10次实验中所采用的候选论文集均为实验1中Group 1的论文;第11到15次所采用的过滤候选集为实验1中Group 2中的论文;最后5次过滤候选集为实验1中Group 3中的论文。检验标准计算方式如式(15)。

从图2中可以看出,与前一个测试相似,语义被完全理解的情况下,过滤效果最佳,而不能被理解语义的情况下,过滤效果明显较低。
6.2 信息过滤算法有效性实验
实验3 信息过滤算法有效性实验
实验方案:为了验证本文过滤方案的有效性,我们采取3组信息获取手段,分析3组手段中对获得有效信息的情况。Group 7采用传统的直接输入关键字进行学术论文搜索;Group 8采用本文开发的原型系统,但是改组过滤时不对无法被计算机理解的信息特征项或用户需求进行语义计算,仅仅对不能理解的项进行传统的匹配;Group 9采用开发的完整原型系统进行信息过滤。每组进行10人次的信息获取,每次的需求均不相同。系统进行分析的对象是我们所采集的1000篇内容不同的学术论文(有一部分是非计算机领域论文)。我们进行实验的评价标准按式(15)计算。结果如图3所示。从对比实验看出,由于没有进行相应的层次过滤,Group 7直接用关键词匹配的方法,获得的效果最差。Group 7、Group 8中,能够体现用户兴趣的搜索,效率提高在后期搜索中能够得到很好的体现。而Group 8中,对于无法被本体理解的那些特征项和需求,仅仅做了单一的匹配计算,所以效果总体上低于Group 9中进行完整过滤的方法。

图1 用户需求语义理解对信息过滤的影响

图2 信息语义理解对信息过滤的影响
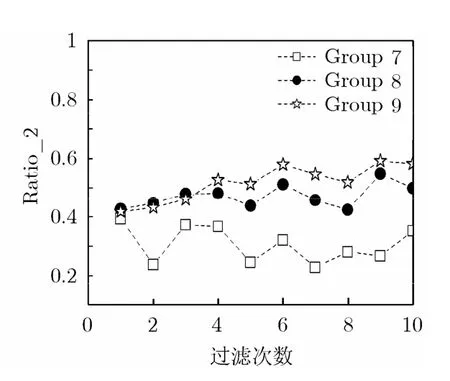
图3 实验对比效果图
7 结论
使计算机拥有自动处理信息内容和用户需求的能力的关键就是能够找到有效的信息语义和用户语义表达方式,并在此基础上使这些语义能够得到很好的理解。本文尝试通过信息领域本体来表达语义,通过有效的语义判定方法使信息语义和用户语义得到很好的处理。在此基础上,本文提出一种信息过滤方法,利用有效的语义表达方法针对信息进行用户需求过滤和用户兴趣过滤,使计算机能够在理解语义的基础上提高信息过滤的效果。通过实验分析,证明本文的算法是可行且有效的。我们的进一步工作将集中在信息领域本体的理解能力的完善研究和语义表达的细粒度化工作上,提升信息过滤效果。
[1] Peter F W and Susan D T. Personalized information delivery:An analysis of information filtering methods.Communications of the ACM, 1992, 35(12): 51-60.
[2] Belkin N J and Bruce Croft W. Information filtering and information retrieval: Two sides of the same cion.Communications of the ACM, 1992, 35(12): 29-38.
[3] Bhandarkar Suchendra M and Luo Xing-zhi. Integrated detection and tracking of multiple faces using particle filtering and optical flow-based elastic matching, Computer Vision and Image Understanding, 2009, 113(6): 708-725.
[4] 徐小龙,王汝传. 基于智能Agent 的多维权值信息检索模型.电子与信息学报, 2008, 30(2): 482-485.Xu Xiao-long and Wang Ru-chuan. The agent-based information retrieval model with multi-weight ranking algorithm. Journal of Electronics and Information Technology,2008, 30(2): 482-485.
[5] Cohen W. Learning rules that classify email. AAAI Spring Symposium on Machine Learning in information Access,Stanford, USA, March 1996: 18-25.
[6] Li Kang, Zhong Zhen-yu, and Ramaswamy Lakshmish.Privacy-aware collaborative spam filtering. IEEE Transactions on Parallel and Distributed Systems, 2009, 20(5):725-739.
[7] Moon Taesup and Weissman Tsachy. Universal filtering via hidden Markov modeling. IEEE Transactions on Information Theory, 2008, 54(2): 692-708.
[8] Estévez Pablo A, Tesmer Michel, Perez Claudio A, and Zurada Jacek M. Normalized mutual information feature selection. IEEE Transactions on Neural Networks, 2009,20(2): 189-201.
[9] 曾春,邢春晓,周立柱. 基于内容过滤的个性化搜索算法. 软件学报. 2003, 14(5): 999-1004.Zeng Chun, Xing Chun-xiao, and Zhou Li-zhu. A personalized search algorithm by using content-based filtering. Journal of Software, 2003, 14(5): 999-1004.
[10] 洪宇, 张宇, 郑伟, 刘挺, 李生. 信息过滤中基于二元近似关系分布的噪声屏蔽算法. 软件学报, 2008, 19(11): 2887-2898.Hong Y, Zhang Y, Zheng W, Liu T, and Li S. Algorithm of shielding noises in information filtering based on distribution of two-dimension similarity relation. Journal of Software,2008, 19(11): 2887-2898.
[11] Dridi Olfa and Ahmed Mohamed Ben. Building an ontology-based framework for semantic information retrieval:application to breast cancer, 2008 3rd International Conference on Information and Communication Technologis:from Theory to Applications, Damascus, Syria, April 2008.
[12] Wang Shuda and Yang Jing. Research on the information filtering of OWL text based on semantic analysis, 2008 International Conference on Wireless Communications,Networking and Mobile Computing, Dalian, China,September 2008.
[13] Yokoi Takeru, Yanagimoto Hidekazu, and Omatu Sigeru.Information filtering using latent semantics. Electrical Engineering in Japan, 2008, 165(2): 53-59.
[14] Salvador NietoSanchez, Triantaphyllu Evangelos, and Donald Kraft. A feature mining based approach for the classification of text documents into disjoint classed Information.Processing and Hamagement, 2002, 38(4): 583-604.
猜你喜欢
当代陕西(2020年17期)2020-10-28
开放教育研究(2020年2期)2020-03-31
人大建设(2018年5期)2018-08-16
制造业自动化(2017年2期)2017-03-20
现代语文(2016年21期)2016-05-25
文学教育(2016年27期)2016-02-28
应用科技(2015年5期)2015-12-09
大连民族大学学报(2015年2期)2015-02-27
河南科技(2014年15期)2014-02-27
图书与情报(2013年1期)2013-11-16
