
多类SVM分类算法的研究
2010-03-19 03:20郭显娥刘春贵张景安
山西大同大学学报(自然科学版) 2010年3期
郭显娥,武 伟,刘春贵,张景安
(山西大同大学数学与计算机科学学院,山西大同 037009)
机器学习从早期Fisher分类器到人工神经网络都是基于传统的经验风险最小化原则进行的,即采用在训练样本集上的学习能力,作为衡量一个学习机性能好坏的标准.这种机器学习存在着过拟合问题,使得学习机的泛化能力差.支持向量机(SVM)是一种建立在统计学习理论基础之上的机器学习方法,其最大的特点是根据Vapnik结构风险最小化原则[1],即在函数复杂性和样本复杂性之间进行折中,尽量提高学习机的泛化能力,具有优良的分类性能.
支持向量机在解决小样本、非线性及高维模式识别问题中表现出了许多特有的优势,基于支持向量的分类越来越受到广泛的关注与重视.支持向量机的出现最初是为了解决两类模式识别问题.当它在两类问题中展现出其卓越的性能之后,人们自然而然地想到了利用它来解决机器学习等领域中的其它难题.对于我们所处的客观世界来说,许多问题所需要面对的事物类别远远不止两类,例如语音识别,手写体数字识别问题等.因此如何将SVM方法有效的应用于多类分类问题迅速成为SVM研究热点.针对多类分类问题的经典SVM算法主要有一对一方法(1-vs-1),一对多方法(1-vs-all),有向无环图方法(DAG-SVM)和二叉树法(BT-SVM)等几种.下面将对这些主要的多类SVM算法以及优缺点进行全面的讨论.
1 支持向量机原理[2]
1.1 线性可分问题
SVM是从线性可分情况下的最优分类面发展而来的,所谓最优分类面就是要求分类面不但能将两类样本正确分开 (训练错误率为0),而且使分类间隔最大.设有n个样本xi及其所属类别yi表示为:

超平面W·X+b=0方程,能将两类样本正确区分,并使分类间隔最大的优化问题可表示为在式(1)的约束下求式(2)的最小值.

满足式(1)条件且使|w|2最小的分类面就是最优分类面.过两类样本中离分类面最近的点且平行于最优分类面的超平面上的训练样本就是式(1)中使等号成立的那些样本,它们叫做支持向量(Support Vectors).因为它们支撑了最优分类面.
1.2 线性不可分问题
最优分类面是在线性可分的前提下讨论的,在线性不可分的情况下,就是某些训练样本不能满足式 (1)的条件,因此可以在条件中增加一个松弛项ξi≥0(i=1,…,n),此时约束条件式(1)变为式(3):
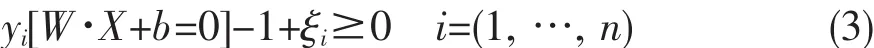
寻优目标函数式(2)变为式(4):
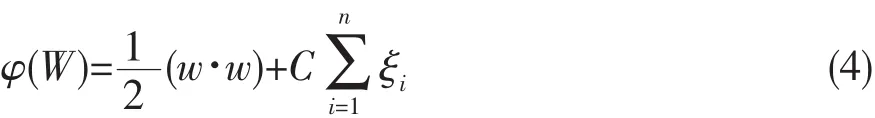
(4)式中的C为某个指定的常数,起到对错分样本惩罚程度控制的作用,实现在错分样本的比例和算法复杂程度之间的“折衷”.该问题可转化为其对偶问题.即在式(5)和式(6)的约束条件下求式(7)的最大值.
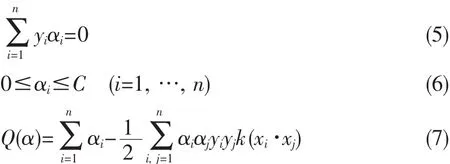
这是一个不等式约束下二次函数极值问题,存在唯一解.求解出上述各系数α、W、b对应的最优解α*、W*、b*后,得到最优分类函数为式(8).
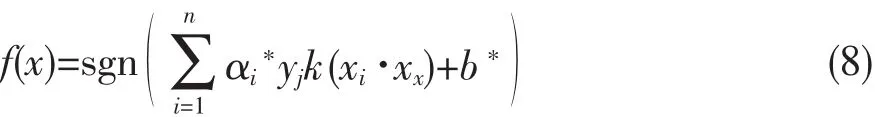
其中:sgn()为符号函数,b*为分类的域值.
1.3 非线性问题
现实问题几乎都是非线性可分的,对非线性问题,可以通过非线性变换转化为某个高维空间中的线性问题[3],在变换空间求最优分类面.根据泛函的有关理论,只要一种核函数k(x,xi)满足Mercer条件,它就对应某一变换空间中的内积.因此,在最优分类面中用适当的内积核函数k(x,xi)就可以实现从低维空间向高维空间的映射,从而实现某一非线性变换后的线性分类,而计算复杂度却没有增加.
2 多类SVM分类算法分析与研究
2.1 一对一支持向量机(1-vs-1 SVM)
一对一支持向量机(1-vs-1 SVM)[2]是利用两类SVM算法在每两类不同的训练样本之间都构造一个最优决策面.如果面对的是一个k类问题,那么这种方法需要构造k(k-1)/2个分类平面(k>2).这种方法的本质与两类SVM并没有区别,它相当于将多类问题转化为多个两类问题来求解.具体构造分类平面的方法如下:
从样本集中取出所有满足yi=s与yi=t(其中1≤s,t≤k,s≠t)通过两类SVM算法构造最优决策函数:
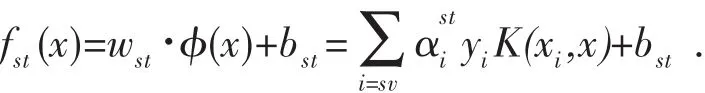
用同样的方法对k类样本中的每一对构造一个决策函数,又由于fst(x)=-fts(x),容易知道一个k类问题需要k(k-1)/2个分类平面.
根据经验样本集构造出决策函数以后,接下来的问题是如何对未知样本进行准确的预测.通常的办法是采取投票机制:给定一个测试样本x,为了判定它属于哪一类,该机制必须综合考虑上述所有k(k-1)/2个决策函数对x所属类别的判定:有一个决策函数判定x属于第s类,则意味着第s类获得了一票,最后得票数最多的类别就是最终x所属的类别.
1-vs-1 SVM方法,优点在于每次投入训练的样本相对较少,因此单个决策面的训练速度较快,同时精度也较高.但是由于k类问题需要训练k(k-1)/2个决策面,当k较大的时候决策面的总数将过多,因此会影响后面的预测速度.这是一个有待改进的地方.在投票机制方面,如果获得的最高票数的类别多于一类时,将产生不确定区域;另外在采用该机制的时候,如果某些类别的得票数已经使它们不可能成为最终的获胜者,那么可以考虑不再计算以这些类中任意两类为样本而产生的决策函数,以此来减小计算复杂度.
2.2 一对多支持向量机(1-vs-all SVM)
一对多支持向量机(1-vs-all SVM)[4]是在一类样本与剩余的多类样本之间构造决策平面,从而达到多类识别的目的.这种方法只需要在每一类样本和对应的剩余样本之间产生一个最优决策面,而不用在两两之间都进行分类.因此如果仍然是一个k类问题的话,那么该方法仅需要构造k个分类平面(k>2).该方法其实也可以认为是两类SVM方法的推广.实际上它是将剩余的多类看成一个整体,然后进行k次两类识别.具体方法如下:
假定将第j类样本看作正类 (j=1,2,…,k),而将其他k-1类样本看作负类,通过两类SVM方法求出一个决策函数这样的决策函数fj(x)一共有k个.给定一个测试输入x,将其分别带入k个决策函数并求出函数值,若在k个fj(x)中fs(x)最大,则判定样本x属于第s类.
1-vs-all SVM 方法和 1-vs-1 SVM 相比,构造的决策平面数大大减少,因此在类别数目k较大时,其预测速度将比1-vs-1 SVM方法快.但是由于它每次构造决策平面的时候都需要用上全部的样本集,因此它在训练上花的时间并不比1-vs-1 SVM少.同时由于训练的时候总是将剩余的多类看作一类,因此正类和负类在训练样本的数目上极不平衡,这很可能影响到预测时的精度.另外,与1-vs-1方法类似,当同时有几个j能取到相同的最大值fj(x)时,将产生不确定区域。
2.3 二叉树支持向量机(BT-SVM)[5]
对于k类的训练样本,训练k-1个SVM,第1个SVM以第1类样本为正的训练样本,将第2,3,…,k类训练样本作为负的训练样本训练SVM1,第i个支持向量机以第i类样本为正的训练样本,将第i+1,i+2,…,k类训练样本作为负的训练样本训练SVMi,直到第k-1个支持向量机将以第k-1类样本作为正样本,以第k类样本为负样本训练SVM(k-1).可以看出二叉树方法可以避免传统方法的不可分情况,并且只需构造k-1个SVM分类器,测试时并不一定需要计算所有的分类器判别函数,从而可节省测试时间,同时提高了训练和测试的速度.该思想也给它带来了问题:假设共有k类训练样本,根据类别号码的排列次序训练样本,不同的排列直接影响生成的二叉树结构,如果某个节点上发生分类错误,则错误会沿树结构向后续节点扩散,从而影响分类器的性能.因此选择合适的二叉树生成算法,构造合理的二叉树结构以提高分类器的推广能力是值得进一步研究的问题.
2.4 有向无环图支持向量机(DAG-SVM)
DAG-SVMS是由Platt提出的决策导向的无环图DAG导出的,是针对1-vs-1 SVMS存在误分、拒分现象提出的[6],该方案训练阶段和一对一相同,如果有n类,则要训练n(n-1)/2个分类器,但在预测阶段则要先构造一个有向无环图,该图共有n(n-1)/2节点和n个叶,每个节点代表一个分类器,每个叶为一个类别.当对测试样本预测时,先用根节点的分类器预测,根据结果选择下一层中的左节点或右节点继续预测,直到最后到达叶就得到测试样本所属类别.
该方法和1-vs-1 SVM一样,训练的时候,首先需要构造k(k-1)/2个分类决策面.然而和1-vs-1 SVM方法不同的是,由于在每个节点预测的时候同时排除了许多类别的可能性,因此预测的时候用到的总分类平面只有k-1个,比1-vs-1 SVM要少很多,预测速度自然提高不少.但DAGSVM算法也有其不足之处.正由于它采取的是排除策略,那么最开始的判定显得尤为重要,如果在开始阶段就决策错误的话,那么后面的步骤都没有意义了.因此如何选取判定的顺序和得到令人信服的开始阶段的判定,是值得进一步研究的问题.图1给出了使用DAG算法解决一个九类问题的分类示意图.
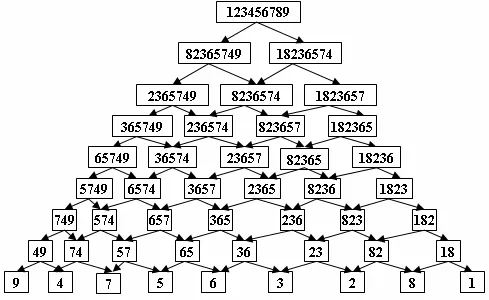
图1 DAG算法分类示意图
3 结论
从分类器的复杂度方面分析,一对多和二叉树算法对n类问题分别需要构造n和n-1分类面;构造分类面最多的是一对一和DAG算法,对n类问题需要构造n(n-1)/2个分类面.从分类精度方面分析,一对一和DAG算法比一对多和二叉树算法高,可以看出由于在目标分类问题中,分类精度和分类器复杂度常为一对互相矛盾的指标,因此在解决实际问题中究竟采用那种分类器,应根据用户的要求而定,对分类精度要求较高的问题可使用一对一和DAG算法,如果需将分类精度与分类速度综合考虑,则可以使用一对多和二叉树算法;也可以将不同分类器组合成混合的分类器来协调二者间的需求矛盾.
[1]Vapnik V N.The nature of statistical learning theory[M].New York:Springer Verlag,1995:4-80.
[2]王亮申,欧宗瑛.基于SVM的图像分类[J].计算机应用与软件,2005,22(5):98-99.
[3]赵金凤,张日权.比例可加模型参数估计的相合性[J].山西大同大学学报:自然科学版,2009,25(1):3-7.
[4]Burges C J C.A tutorial on Support Vector Machines for Pattern Recognition[J].Knowledge Discovery and Data Mining,1998,2(2):121-167.
[5]Weston J,Watkins C.Support vector machines for multi-class pattern recogni-tion[D].In Proceedings of 7th European Symposium on Artificial Neural Networks,1999:219-224.
[6]Platt J,Cristianini N,Shawe-Taylor J.Large margin DAGs for multiclass classification[A].Leen T K,Mu¨ller K R.Advancesin Neural Information Processing Systems 12[C].S A Solla:The MIT Press,2000:547-553.
猜你喜欢
电脑报(2022年37期)2022-09-28
现代计算机(2021年14期)2021-07-09
科技创新与应用(2020年6期)2020-02-29
武汉轻工大学学报(2016年4期)2017-01-16
北京理工大学学报(2016年6期)2016-11-22
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2014年15期)2014-04-04
