
一种具有增量挖掘功能的Web点击流聚类算法
2010-01-04 07:57李晓明夏秀峰
沈阳大学学报(自然科学版) 2010年3期
李晓明,夏秀峰,张 斌
(1.沈阳航空工业学院 计算机学院,辽宁 沈阳 110136;2.东北大学 信息科学与工程学院,辽宁 沈阳 110004)
一种具有增量挖掘功能的Web点击流聚类算法
李晓明1,2,夏秀峰1,张 斌2
(1.沈阳航空工业学院 计算机学院,辽宁 沈阳 110136;2.东北大学 信息科学与工程学院,辽宁 沈阳 110004)
分析了典型的聚类算法及其适用范围,针对其处理Web点击流数据的不足,提出了一种用于Web点击流的增量挖掘的聚类算法WCSCluster,给出了相关定义及存储结构,并用实例说明了算法的运行过程·最后对比同类算法给出实验结果·实验结果表明该算法具有良好的性能,能够发现更优的簇·
Web使用挖掘;点击流;增量挖掘;聚类
Web使用挖掘就是把数据挖掘技术应用到Web点击流数据中,从而发现使用模式的过程·Web使用挖掘是从数据挖掘发展而来的,在对大量数据进行分析的基础上,作出归纳性的推理,以预测客户的行为·Web使用挖掘用于数据库知识发现的特征化(Characterization)、分类(Classification)、预 测 (Prediction)、聚 类(Clustering)、关联(Association)和序列模式(Sequential Pattern)分析等技术·Web服务器能够记录每次Web访问的详细点击信息,例如页面URL、IP地址、日期、Web站点及配置信息等·其中,通过对Web点击流数据进行聚类技术研究可以使站点管理者发现用户的访问模式,改进Web服务器的设计,提高Web服务器的性能,以方便用户使用,增加个性化服务,发现电子商务中潜在的客户·
1 现有算法及存在的不足
传统的聚类技术研究最早源于统计学,利用数据(点)之间的曼哈顿距离、欧几里德距离、闵科夫斯基距离[1]来衡量数据点之间的相似程度,进而将其划分到距离最近的簇中·然而,现实世界中的数据往往是高维的,并且拥有不同种类的数据类型·最常见的数据类型分以下6种[2]:区间标度变量,二元变量,分类变量,序数变量,比例标度变量,向量对象·
经典聚类算法并不适用于直接处理Web点击流数据,因此,近年来国内外不少学者在经典聚类算法基础上提出许多改进算法,主要有:FCM dd[3]、时间意识聚类[4]、相似矩阵结构分解[5]、扩展的人工神经网络 k均值[6]等算法·其中一些取得了不错的效果·但仔细分析上述这些算法,不难发现它们都存在一个或几个如下所述的弊端:①不能处理混合属性的数据;②需用户来指定最终簇的数目;③聚类结果受离群点数据的影响;④大多数算法不具备增量挖掘功能;⑤数据点只属于一个簇·针对这些弊端,本文提出一个针对Web点击流数据的聚类算法WCSCluster(Web Click Stream Cluster)·
2 相关概念和定义
设非空集合I={P1,P2,…,Pn},其中的Pi(1≤i≤n)称为Web页面·
定义1 Web点击流:Web点击流是用户访问Web页面时的一组连续访问序列,记作〈P1,P2,…,Pm〉,其中Pi∈I,1≤i≤m·
定义2 会话(session)序列:会话序列是某个用户特定时间段的页面浏览序列,记作〈(P1,t1),(P2,t2),…,(Pk,tk)〉,其中ti(1≤i≤k)是用户在Pi页面的驻留时间·为方便以下讨论我们把会话分成两个部分,即访问序列〈P1,P2,…,Pk〉与驻留时间序列〈t1,t2,…,tk〉·
考虑到一个大型的站点可能含有上千个URL,这会造成访问者之间的公共访问序列很有可能为空,那么访问者之间的相似度则为0,即任意两个用户都不可能划分到一个簇中,这显然不是我们所希望的·这里我们用到了一个层次提升的概念,即将一个站点中的所有URL归类,如新浪网中可以将所有URL归类成新闻、军事、体育、财经等,体育类可再分为篮球、足球、排球等,具体划分程度可视实际应用而定·
3 算法描述
文中采用一种类十字链表的存储结构来存储聚类过程与结果,具体分为簇头节点与会话节点两个部分·
为了便于算法描述,对涉及到的相关概念给出简要介绍·
定义3 特征访问序列:特征访问序列是指一个簇中所有会话节点访问序列的交集序列·
定义4 特征访问时间:特征访问时间是指特征访问序列中对应的、本簇中所有会话节点对应的访问时间的平均时间序列·
WCSCluster算法伪代码如下:

4 实验分析
与本文最相近的工作是文献[3]中的FCM dd算法,有别于该文;本文采用了会话节点与簇头节点的相似度计算代替了该文中的相异度矩阵的计算,且本文中的模糊划分也有别于该文:所以采用FCM dd算法与WCSCluster算法进行比较·实验采用C#语言,在VS2005下完成,后台数据库采用SQL Server2005,实验 PC机配置为2.0 GHz AMD,1 GB RAM,WinXP Professional操作系统·实验数据来自沈阳航空工业学院Web服务器上的日志文件,大小约287 M.约有2 455 600条点击记录·
4.1 进行会话重构
本文设定会话的持续时间上限为30 min,两个连续访问页面的时间间隔下限为1min,上限为6min,同时剔除那些序列长度小于4的会话(设定的时间及序列的长度可视具体应用调整)·利用文献[7]中的方法处理点击流数据,从而形成用户会话·在VS2005下利用C#语言编写日志抽取程序·进行页面的层次提升后最终归为11个大类,对形成的大类进行编码,即将它们赋值从A到K,清洗掉无用的点击记录,最终形成约34 000条会话记录·将抽取后的结果存储到后台数据库中·
将抽取后的会话记录分成3个大小不等的数据集 DS1、DS2、DS3,DS2与 DS3分别为 DS1的整数倍,分别约为5 700、11 320、16 980条会话记录·首先验证不同阈值下的聚类效果,在3个数据集下同时将阈值λ分别取 0.3、0.4、0.5,结果DS1分别形成9,10,12个簇,DS2分别形成21,24,28个簇,DS3分别形成53,61,72个簇·从聚类结果上看,随着阈值的增大簇的数目会急剧上升,不难看出不同的阈值取值对应了不同的划分结果,这也验证了WCSCluster的模糊聚类功能,对比如图1所示·
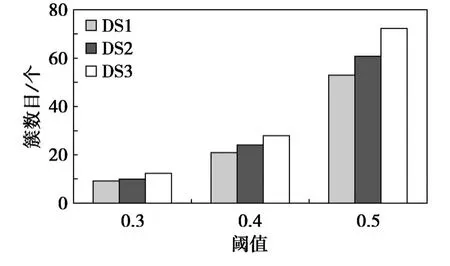
图1 WCSCluster聚类结果比较
4.2 对比在相同实验环境下的WCSCluster算法与FCMdd算法的处理速度与空间消耗
为客观起见,WCSCluster算法的阈值λ分3次取值,分别为0.3、0.4、0.5,然后两个算法分别在3个数据集上运行·最终两个算法的时间消耗对比如图2所示,空间消耗对比如图3所示·从运行时间比较看来,WCSCluster处理数据的时间基本是线性的,时间消耗随着数据集的增大而线性增大·而FCM dd随着处理数据量的增加,处理时间急剧上升·一个好的聚类算法在时间上应该近似满足线性规律,故从可伸缩性角度上看WCSCluster要比FCM dd更优·同时也看到,相同数据集下聚类结果受到阈值大小的影响,但聚类时间主要受数据集大小影响,而受阈值影响不大·从空间消耗来看,在相同数据集下,WCSCluster的空间消耗比FCM dd要小·仔细分析不难发现,FCM dd建立了相异度矩阵进行数据存储,当会话数目增多时内存消耗会急剧增加·
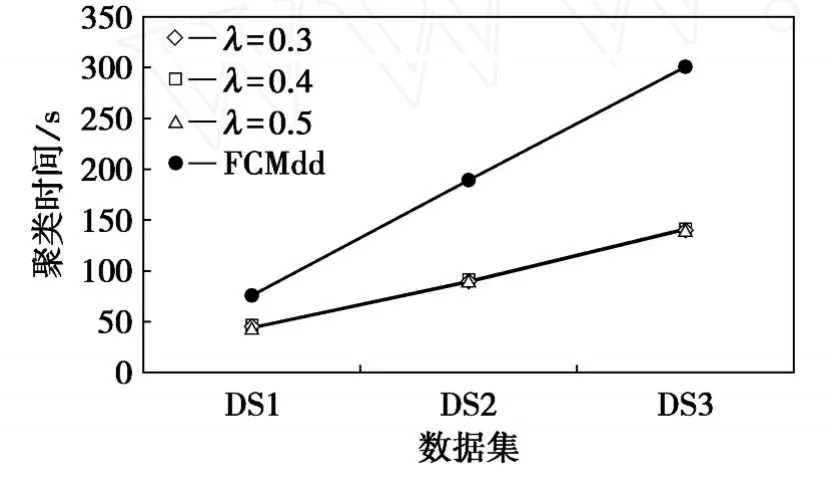
图2 WCSCluster与FCMdd运行时间比较

图3 WCSCluster与FCMdd内存消耗比较
5 结 论
文本全面对比了传统聚类的各种算法,针对其处理Web点击流数据的不足,提出了一种用于Web点击流聚类的算法WCSCluster,该算法克服了同类算法中的缺点,具有增量挖掘、模糊聚类、删除过期会话等功能·分析表明,该算法在处理Web点击流的聚类问题上优于同类其他算法·目前,越来越多的数据以流的形式出现·与静态Web数据相比,动态Web点击流具有潜在无穷大、迅速、时变和连续到达等特点·其中的数据按照固定的次序,只能被读取一次或几次,不再是永久的关系形式,数据无法全部保存后再进行处理,即无法甚至不可能进行多次 IO操作,对于数据的在线处理性、实时性处理提出了更高的要求·如何在动态环境下对Web点击流进行有效聚类是我们下一个研究目标·
[1] Tan Pangning,Steinbach M,Kumar V.Introduction to Data Mining[M].Addison Wesley:Pearson Education,2006:33-35.
[2] Han Jiawei,Kamber M.Data Mining Conceptsand techniques[M].Beijing:Machinery Industry Press,2007:47-48.
[3] Kamdar T,Joshi A.Using incremental Web log mining to create adaptive Web servers[J].Int J Digit Libr,2005(5):133-150.
[4] Petridou S G,Koutsonikola V A,Vabali A I,et al.Time aware Web users clustering[J]. Know ledge and Data Engineering,2008,20(5):653-667.
[5] 周宽久,王艳萍,李瑶.Web用户聚类算法[J].计算机工程与应用,2006,42(16):184-186.
[6] Park S,Suresh N C,Jeong B K.Sequence-based clustering for Web usage mining:a new experimental framework and ANN-enhanced K-means algorithm[J].Data&Know ledge Engineering,2008,65:512-543.
[7] Sadagopan N,Li Jie.Characterizing Typical and Atypical User Sessions in clickstreams[C].Beijing:[s.n.],2008:21-25.
An Incremental M ining Clustering Algorithm for Web Clickstreams
L I Xiaom ing1,2,XIA Xiufeng1,ZHANG Bin2
(1.Computer School,Shenyang Institute of Aeronautical Engineering,Shenyang 110036,China;2.College of Information Science and Engineering,Northeastern University,Shenyang 110004,China)
After analyzing the classic clustering algorithmsand itsconfine,an incrementalmining clustering algorithm w hich is used in Web clickstream s field called WCSCluster is p roposed.Relevant definitions and storage structure are given;running p rocedure is show n by a specific example.Experimental results are given comparing w ith congener algorithms.Experimental results demonstrate that the algorithm has good performance w hich can find superior clusters.
Web usagemining;clickstreams;incrementalmining;clustering
TP 311.131
A
1008-9225(2010)03-0008-03
2010-04-09
李晓明(1980-),男,辽宁丹东人,沈阳航空工业学院工程师,东北大学硕士研究生·
【责任编辑 刘晓鸥】
猜你喜欢
昆钢科技(2022年4期)2022-12-30
保健医苑(2022年1期)2022-08-30
昆钢科技(2022年1期)2022-04-19
昆钢科技(2021年6期)2021-03-09
艺术品(2019年9期)2019-10-26
艺术品(2019年4期)2019-05-30
小学科学(学生版)(2019年4期)2019-05-11
长江丛刊(2018年8期)2018-11-14
科技视界(2014年22期)2014-04-17
网络安全技术与应用(2011年3期)2011-03-14
