
基于元学习和轻量化注意力机制的小样本图像检索方法
2025-03-04 00:00:00宋阿隆崔学荣
物联网技术 2025年5期

摘 要:图像检索算法在化工厂安全防护中起着重要作用,但是部分化工厂图像检索任务由于其场景特殊,缺乏标记样本,图像检索精度较低。为解决上述问题,提出基于元学习和轻量化注意力机制的小样本图像检索方法,基于元学习思想构建小样本图像检索框架,使用深度可分离卷积提取图像特征时能够降低网络复杂度;为增强网络的特征提取能力,在深度可分离卷积中引入注意力模块,构建轻量化注意力机制的特征提取网络。试验结果表明,采用该方法进行图像检索时的mAP是65.41%,参数量是2.13 MB,计算量是5.98 GFLOPs;与其他网络相比,降低了参数量和计算量,提高了检索精度。
关键词:图像检索;小样本;元学习;深度可分离卷积;注意力机制;轻量化
中图分类号:TP183 文献标识码:A 文章编号:2095-1302(2025)05-00-04
0 引 言
与一般的图像检索场景[1]相比,化工厂的图像检索任务场景比较特殊,受安全性和隐私性限制,部分图像检索任务缺少训练样本,此时传统的图像检索算法的检索精度较低。因此,亟需基于少量图像构建泛化能力强的图像检索模型。
目前,主流的小样本[2]问题解决方法是元学习(Meta-Learning)[3],元学习方法模型可从不同的子任务中学习面对一个新任务时如何较好地进行泛化。与模型无关[4]的元学习(Model-Agnostic Meta-Learning, MAML)方法是其中重要的一种,其核心思想是使模型能够在一系列任务上学习,快速、有效地适应新任务。
将元学习和度量学习(Metric Learning)[5]相结合是针对元学习方法进行研究的主流方向之一。文献[6]提出了关系网络(Relation Network),对输入的关系进行建模,通过学习样本之间的关系进行图像处理。文献[7]提到的原型网络(Prototypical Network)是通过学习每个类别的原型向量,将输入样本映射到这些原型向量的空间中,再通过最接近的原型进行图像匹配。
上述元学习方法均面向的是图像分类任务,对于图像检索问题,情况有所不同。图像检索是在一个图像数据库中根据查询图像找到相似的图像,这种任务不同于图像分类任务,因为它不需要识别图像的类别,只需要在图像集合中寻找与查询图像相似的图像。上述元学习方法对样本质量要求高,且要求模型不能太复杂。基于上述原因,提出一种基于元学习和轻量化注意力机制的小样本图像检索方法MS-LCAM。该方法通过构建小样本图像检索框架和轻量化特征提取网络,有效地提高小样本图像检索的精度。
1 MAML算法概述
1.1 MAML算法原理
元学习与传统的深度学习思想不同,传统的深度学习需要大量的训练数据,从而模拟该任务的模型参数,而元学习是从不同的任务中学习经验与知识,做到“学会学习”。元学习分为元训练和元测试两个阶段,元学习问题一般包含两个数据集:目标数据集Ds和辅助数据集Dh,Ds内仅含有少量的带标记目标样本,Dh数据集内包含足够多的带有标签的样本,可以根据目标数据集制作。在元训练阶段,每次会在辅助数据集Dh中采样得到不同子任务,在每个子任务中,从辅助数据集中选择出N个类,然后从N个类中选取K个样本构成了支持集Support Set,查询集Query Set会在N个类中的剩余样本数据中采样得到,这种任务被称为N-way K-shot任务[8]。在元学习训练阶段,使用构建的子任务训练模型,学习经验与知识。在元学习测试阶段,使用目标数据集Ds提供的带标签的数据与元训练阶段学到的知识对网络进行微调,可以在新任务上迅速学习和适应。
1.2 MAML算法缺点
MAML是一种元学习框架,可以帮助模型在小样本情况下快速适应新任务。然而,MAML并不是设计用于解决小样本图像检索任务的框架,在解决小样本图像检索任务时,需对MAML框架进行优化。
在MAML框架下,对模型要求严格,要求模型不能太复杂。在每个子任务的训练样本数量很少的情况下,如果模型过于复杂,可能会在任务训练阶段学习到任务特定的噪声,而不是泛化到新任务的规律。
2 MAML框架改进
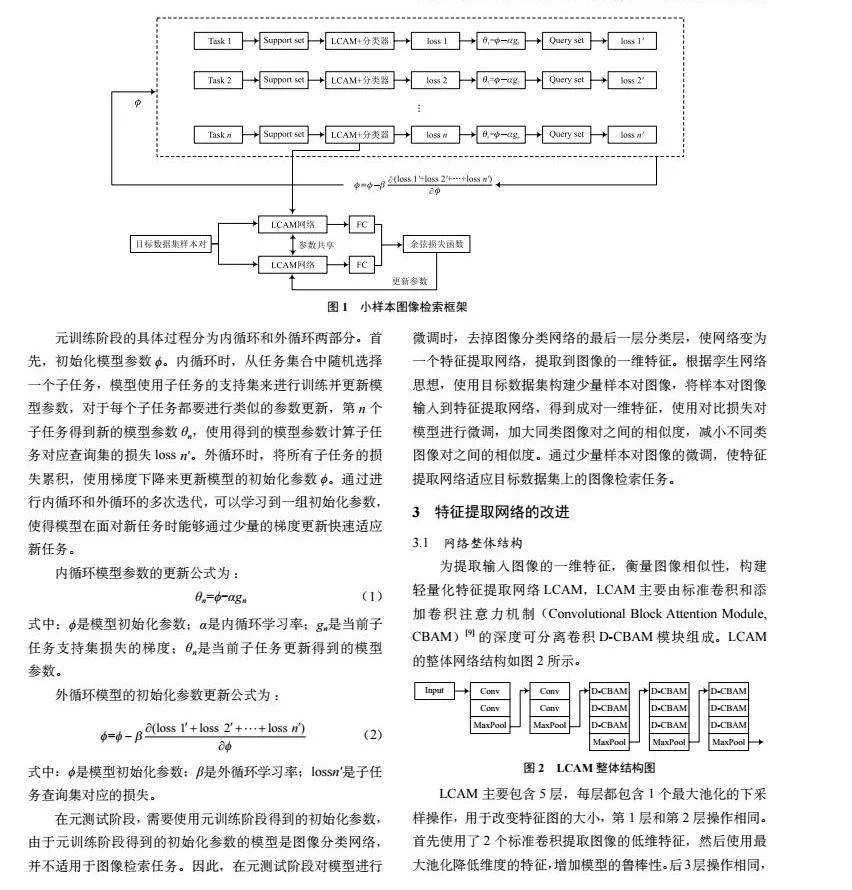
对MAML框架进行改进,使其适用于小样本图像检索任务,得到小样本图像检索框架MS。MS分为2个阶段:第1个阶段是元训练阶段,根据MAML思想在辅助数据集上划分小样本图像分类子任务,训练出图像分类网络;第2个阶段是元测试阶段,在这个阶段会删除元训练阶段的图像分类网络的最后一层分类层,保留其他层作为元测试阶段的特征体提取网络,在元测试阶段对特征提取网络进行微调,使其提取的特征更适用于图像检索任务。MS框架如图1所示。
元训练阶段的具体过程分为内循环和外循环两部分。首先,初始化模型参数ϕ。内循环时,从任务集合中随机选择一个子任务,模型使用子任务的支持集来进行训练并更新模型参数,对于每个子任务都要进行类似的参数更新,第n个子任务得到新的模型参数θn,使用得到的模型参数计算子任务对应查询集的损失loss n′。外循环时,将所有子任务的损失累积,使用梯度下降来更新模型的初始化参数ϕ。通过进行内循环和外循环的多次迭代,可以学习到一组初始化参数,使得模型在面对新任务时能够通过少量的梯度更新快速适应新任务。
在元测试阶段,需要使用元训练阶段得到的初始化参数,由于元训练阶段得到的初始化参数的模型是图像分类网络,并不适用于图像检索任务。因此,在元测试阶段对模型进行微调时,去掉图像分类网络的最后一层分类层,使网络变为一个特征提取网络,提取到图像的一维特征。根据孪生网络思想,使用目标数据集构建少量样本对图像,将样本对图像输入到特征提取网络,得到成对一维特征,使用对比损失对模型进行微调,加大同类图像对之间的相似度,减小不同类图像对之间的相似度。通过少量样本对图像的微调,使特征提取网络适应目标数据集上的图像检索任务。
3 特征提取网络的改进
3.1 网络整体结构
为提取输入图像的一维特征,衡量图像相似性,构建轻量化特征提取网络LCAM,LCAM主要由标准卷积和添加卷积注意力机制(Convolutional Block Attention Module, CBAM)[9]的深度可分离卷积D-CBAM模块组成。LCAM的整体网络结构如图2所示。
LCAM主要包含5层,每层都包含1个最大池化的下采样操作,用于改变特征图的大小,第1层和第2层操作相同。首先使用了2个标准卷积提取图像的低维特征,然后使用最大池化降低维度的特征,增加模型的鲁棒性。后3层操作相同,使用3个相同的D-CBAM模块提取图像的高维特征,然后经过最大池化降低维度特征,减轻模型的过拟合风险并保留主要特征。经过5层操作后,特征进入全连接层输出图像一维特征。LCAM同时兼备深度可分离卷积和CBAM的优点,使得网络更加轻量、高效。
3.2 轻量化特征提取模块
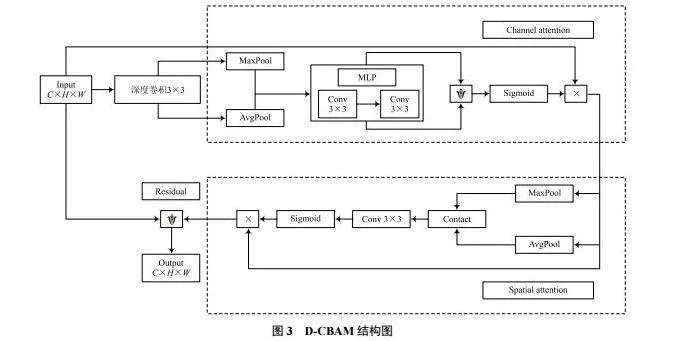
使用深度可分离卷积提取特征时,网络复杂度虽然下降,但特征提取能力也随之下降。为增强网络判别性特征的提取能力,在特征提取网络中使用CBAM注意力模块。构建了轻量化注意力特征提取模块D-CBAM,如图3所示。
对于大小是C×H×W的输入特征,D-CBAM模块首先进行深度卷积,沿通道将特征分为C个,每个特征的大小都是1×H×W,对C个子特征分别进行标准卷积,提取图像特征。深度卷积通过多个卷积层逐层堆叠,可以逐渐学习到输入数据的层次化特征,捕获输入数据的局部和全局特征。
将深度卷积的结果经过CBAM注意力模块,CBAM模块能够自适应地学习图像中不同区域的通道注意力和空间注意力,有助于提取更具区分性的特征,强化关键信息,增强模型对图像中重要特征的关注,从而提高图像检索性能。
在CBAM后使用一个1×1逐点卷积,对特征进行降维,改变特征的通道数,并且对不同位置上的特征进行信息整合。为了防止网络退化和梯度消失,在D-CBAM模块上添加了残差操作,将D-CBAM的输入与逐点卷积之后的结果相加,作为整个模块的输出。
4 实验及结果分析
4.1 实验数据和评价指标
采集化工厂图像数据构建目标数据集(Target Dataset, TD),将其应用于元测试阶段,以此评价本文提出的方法,TD共有5个类别,每个类别包含50张图像。同时,从其他公开数据集上选取与目标数据集TD相似的数据构建辅助数据集(Auxiliary Dataset for Chemical Plants, ADCP),ADCP共由16个类别组成,每个类别包含100张图像。
实验使用平均精度均值(mean Average Precision, mAP)评价算法性能。精度表示前n个结果中有多少是同一类别的,平均精度是不同召回率上的平均值,mAP是对所有平均精度进行平均的结果。将mAP作为综合性评价指标,能够更全面准确地评估模型。
4.2 实验设置
本文方法基于Pytorch深度学习框架实现,在元训练阶段,子任务通过5-way和1-shot的元学习思想对ADCP数据集进行数据划分,每个子任务中含有5个支持集和5个查询集,训练任务每代有24个子任务,使用Adam优化算法[10],内部学习率为0.04,外部学习率为0.001,输入图像大小为224×224×3。在元测试阶段,根据孪生网络思想对TD数据集进行小样本图像检索任务划分,输入成对图像,将输出成对特征的余弦相似度作为损失函数,使用SGD优化算法[11]对模型进行微调。
4.3 实验结果及分析
为了验证对MAML框架的改进是否有利于小样本图像检索任务,将其与其他元学习方法进行了对比实验。具体而言,其他方法在元训练和元测试阶段均以图像分类任务为目标进行训练和微调,获得图像分类模型后,直接使用其全连接层输出作为图像的一维特征表示。在此基础上,本文将基于此方法的图像检索结果与所提方法进行了对比分析,结果见表1。
相较于直接使用图像分类模型的全连接层作为图像特征,本文提出的方法在TD上的图像检索准确率最高,mAP达到了65.41%。相较于性能较好的Meta-baseline,本文方法的mAP提高了2.04个百分点。Prototypical Network和Relation Network方法的mAP很低,不适用于小样本图像检索任务。由此验证了MS-LCAM算法在小样本图像检索任务中的有效性。
由表2可知,LCAM网络在小样本图像检索任务中取得了最高的mAP,在TD数据集上达到65.41%。相较于VGG16、ViT,LCAM网络的参数量和计算量明显降低,检索性能反而更高。与RepVGG相比,尽管RepVGG计算量较低,但是它的参数量却是LCAM的3.68倍,且RepVGG的mAP比LCAM低了5.5个百分点。ResNet50的计算量较低,同时图像检索性能只比LCAM模型低了1.78个百分点,然而ResNet50的参数量却是LCAM的11倍。总体而言,LCAM模型不仅在性能上有显著优势,而且在参数和计算效率上相对较优。
为了验证文中所提出的网络改进策略对小样本图像检索性能的影响,在网络改进前后进行了图像检索实验对比,结果见表3。改进后网络的参数量降低12.59 MB,计算量降低9.42 GFLOPs,mAP提高了8.19个百分点,证明了改进模型的有效性,在小样本图像检索任务中使用轻量化网络可以取得更好的检索结果。
5 结 语
针对化工厂图像检索任务中样本数据缺乏的问题,提出基于元学习和轻量化注意力机制的小样本图像检索方法。基于MAML和孪生网络思想构建了小样本图像检索框架MS,同时构建了轻量化注意力机制的特征提取网络LCAM,在深度可分离卷积中加入CBAM模块,构建了D-CBAM模块,降低了网络复杂度并提高了其在小样本情况下的特征提取能力。实验通过构建的辅助数据集ADCP进行训练,在采集的化工厂小样本数据集TD上进行验证。结果表明,相比于现有的模型和元学习方法,本文方法拥有更高的mAP,达到65.41%,为小样本图像检索提供了一个有效的方法。下一步的研究将考虑设计一种损失函数,将评价指标mAP直接应用于模型训练过程,以提高图像检索的性能。
参考文献
[1] 杨慧,施水才.基于内容的图像检索技术研究综述[J].软件导刊,2023,22(4):229-244.
[2] ZHANG D, PU H, LI F, et al. Few shot object detection via a generalized feature extraction net [J]. Journal of internet technology, 2023, 24(2): 305-312.
[3] 李凡长,刘洋,吴鹏翔,等.元学习研究综述[J].计算机学报,2021,44(2):422-446.
[4] FINN C, ABBEEL P, LEVINE S. Model-agnostic meta-learning for fast adaptation of deep networks [C]// Proceedings of the 34th International Conference on Machine Learning. Sydney, NSW, Australia: JMLR.org, 2017: 1126-1135.
[5] HU J, LU J, TAN Y P, et al. Deep transfer metric learning [J]. IEEE transactions on image processing, 2016, 25(12): 5576-5588.
[6] SUNG F, YANG Y, ZHANG L, et al. Learning to compare: Relation network for few-shot learning [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 1199-1208.
[7] SNELL J, SWERSKY K, ZEMEL R S. Prototypical networks for few-shot learning [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, California, USA: Curran Associates Inc, 2017: 4080-4090.
[8] 王圣杰,王铎,梁秋金,等.小样本学习综述[J].空间控制技术与应用,2023,49(5):1-10.
[9] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision (ECCV). Springer, Cham, 2018.
[10] LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization [C]// Proceedings of the European International Conference on Learning Representations. [S.l.]: [s.n.], 2017.
[11] LU F. An overview of improved gradient descent algorithms for DNN training within significant revolutions of training frameworks [C]// 2021 2nd International Conference on Computing and Data Science (CDS). Stanford, CA, USA: IEEE, 2021: 181-186.
猜你喜欢
精密成形工程(2022年2期)2022-02-22 05:44:14
数字技术与应用(2019年2期)2019-05-14 08:25:10
智富时代(2019年2期)2019-04-18 07:44:42
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
数字技术与应用(2016年11期)2017-02-09 20:54:11
计算机时代(2016年12期)2017-01-14 21:11:57
软件导刊(2016年11期)2016-12-22 21:42:53
电脑知识与技术(2016年1期)2016-03-22 14:16:05
