
基于Hadoop平台的图像检索模型
2017-01-14 21:11王柏翔姜佳鹏
计算机时代 2016年12期
王柏翔+姜佳鹏
摘 要: 处理海量图像数据问题时,针对传统的图像检索方法计算速度慢、检索效率低的问题,借助HBase和Hadoop分布式技术对海量数据超强的读写能力,提出一种适用于大数据背景下的基于Hadoop平台的图像检索模型。该图像检索模型提供了图像数据处理的可序列化数据类型,并通过输入模块实现大数据背景下数据类型的转换及海量图像的输入。理论验证了该模型为特征提取、图像处理等并行处理算法提供了可行的方案。
关键词: 图像检索; HBase; Hadoop; 并行处理
中图分类号:TP391 文献标志码:A 文章编号:1006-8228(2016)12-35-04
hods have the problems of lower computation speed and lower retrieval efficiency for processing massive image data. To solve these problems, this paper proposes a retrieval model applied to storage and process massive image data, which with the help of read and write property of Hadoop distributed technology and HBase. This model provides serializable data types for processing image data, and through the input module realizes the data type conversion and massive image input in big data background. The theory proves that the proposed model can provide a feasible solution for parallel processing algorithms of feature extraction, image processing and so on.
Key works: image retrieval; HBase; Hadoop; parallel processing
0 引言
从图像检索技术的发展看,基于文本标注的图像检索和基于图像内容的检索方法提高了图像特征提取、相似度对比[1],但是大数据时代,对现有的图像处理、表达与度量等方面增加了存储图像数据及高效处理海量数据集的要求。
传统的基于内容的图像检索方法,是对图像采用单机单线程进行特征提取及图像处理,然后将经过处理后的图像特征存入关系型数据库中。发起检索请求时,遍历关系型数据库对比查询到的图像特征和全库特征,对其结果进行排序即为检索的结果。现今图像数据快速增长,即使采用多线程技术处理图像也不能完全解决存储海量图像数据及其处理效率的问题,更不用说简单依赖单计算机的处理能力的传统图像处理技术。
采用HBase和Hadoop分布式技术[2-3]对海量数据进行基于内容的数据图像模型,解决了海量图像数据的存储与传输问题,并且原设计的图像检索算法可直接移植至分布式环境并行处理。该思想依赖基于Map-Reduce的并行模型并行检索大数据图像。
大数据背景下的图像数据,80%以上是以MB为单位的小文件,针对大文件的基于HDFS的分布式存储技术不适用。基于HBase和Hadoop分布式技术可实现系统层的小文件合并,实现全局命名,有良好的通用性[4]。
1 技术背景
1.1 基于内容的图像检索技术
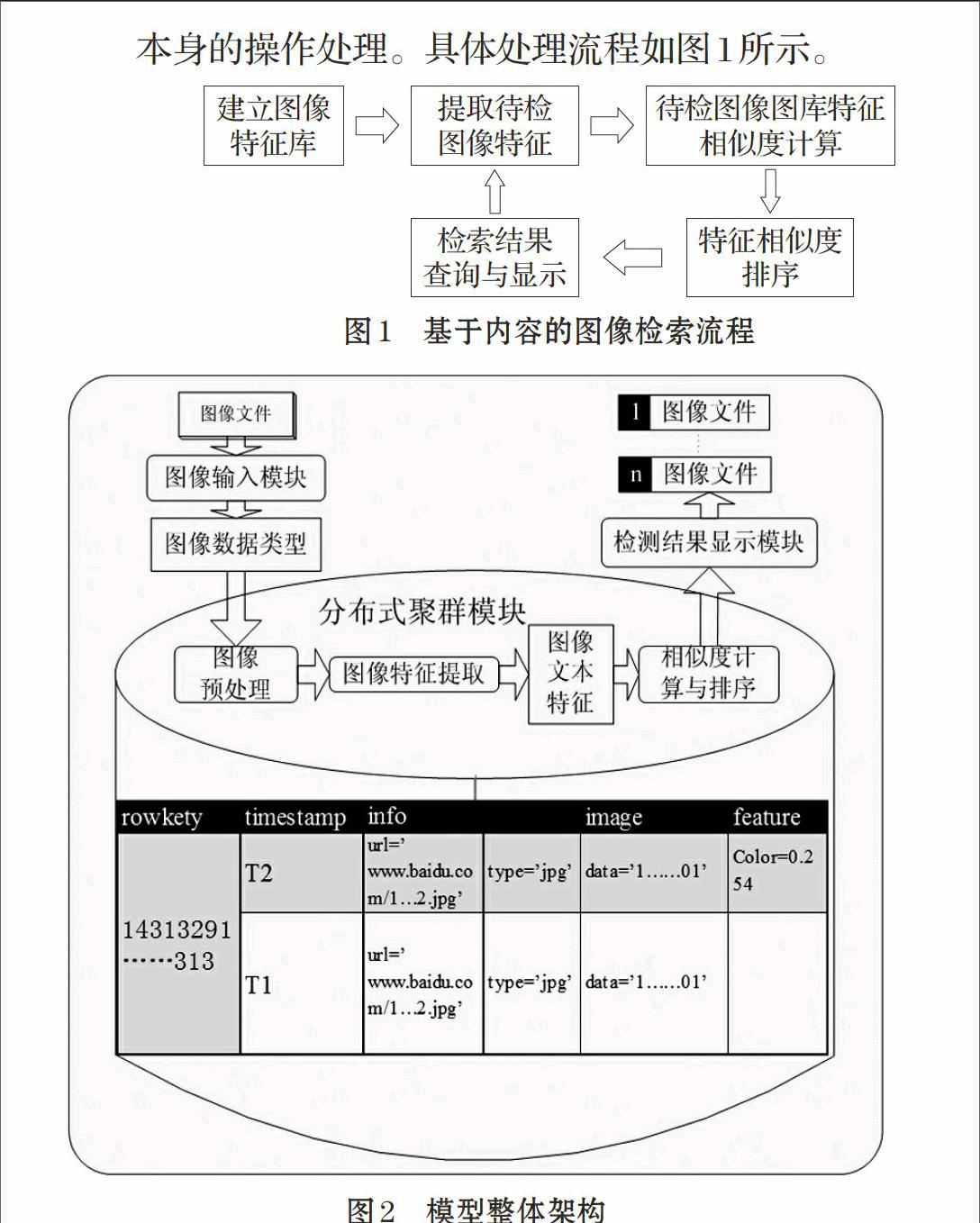
基于内容的图像检索的特点是对图像数据内容本身的操作处理。具体处理流程如图1所示。
图像特征的提取,虽然实现的算法各不相同,但提取的结果一般为文本表示的矩阵或数字。如今的计算机图像处理接口对数字图像的存取简化为对字节流的获取与输出。基于内容的图像检索技术之所以快速发展,一个重要原因就是只专注于研究图像处理算法,而忽略存取图像耗费的资源。
1.2 基于Hadoop的分布式技术
MapReduce分布式计算模型和Hadoop分布式文件系统HDFS(Hadoop Distributed File System)是Hadoop的核心。Hadoop提供分布式文件系统、通用I/O组件和接口以及分布式数据处理模式和执行环境。
MapReduce是一种简单的用于数据处理的编程模型,支持C++、Python和Java等多种编程语言。MapReduce的并行性使大规模数据的分析能在多个计算机上并行执行,提高效率的同时降低了消耗。
1.3 HBase数据库
HBase数据库是分布式列存储数据库,有超强的读写性能,底层通过HDFS存储数据,支持随机查询和Map Reduce的批量式计算。
用Java编写的HBase支持其他编程语言,提供原生的操作API。HBase的数据和坐标以字节数组形式存储,即支持任意类型的数据存储。HBase不存放空表格,只存放有内容的表格单元,其稀疏性适用于存储文件数据[5]。
2 模型设计与实现
2.1 模型整体架构
Hadoop集群的一系列优势如集群规模灵活、成本低廉、其承载的MapReduce模型有高效的并行计算能力。高效并行处理图像特征数据需要借助MapReduce模型,既能移植到现有的特征提取算法中,也能以图像的可序列化数据类型在分布式环境中存储、传输和操作。使用HBase面向列扩展的分布式数据库对图像数据以字节数组的形式进行压缩式存储和快速查询。因此,本文选择HBase为数据存储库,MapReduce模型实现并行处理,建立海量图像分布式检索模型。
检索模型的整体架构如图2所示,主要分为图像输入模块、分布式集群模块和检索结果显示模块。图像输入模块对图像数据进行预处理,将获取到的网络图像转换成可序列化图像数据类型[6-8],并转换成字节数组存储在HBase中;分布式集群模块以可序列化的图像数据类型为接口实现并行图像检索;检索结果显示模块主要还原相似度较高的图像文件,并将其显示或保存到指定的计算机硬盘。
2.2 可序列化的图像数据类型
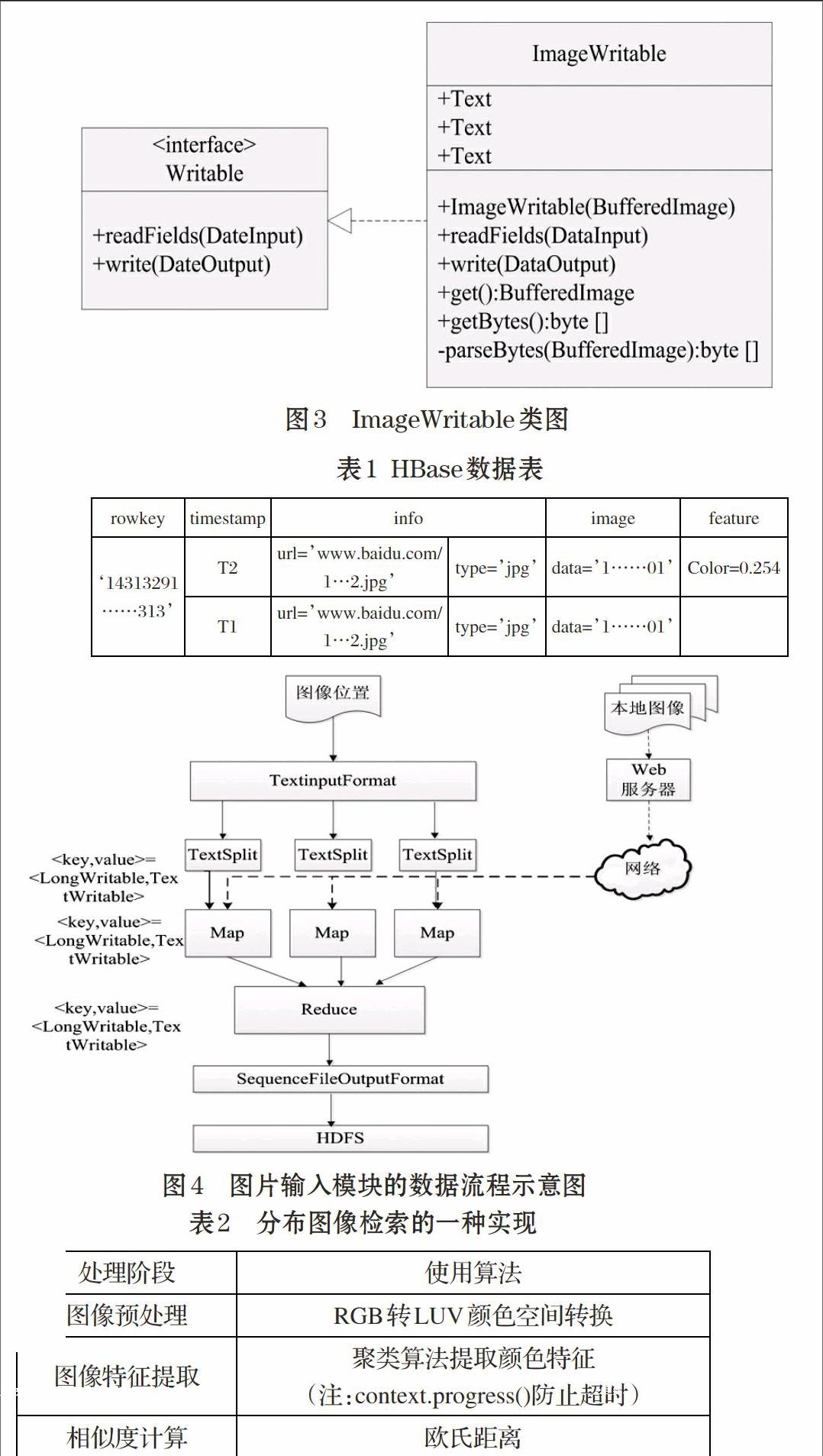
可序列化的数据类型要适用于分布式存储和传输,便于处理数据,因此系统设计的Hadoop API中基本的可序列化类型都有其对应的Java API基本数据类型。Java API中的BufferedImage是常用的处理图像的类,将对象本身转换成字节数组,进而转换成Text类型。Text类型最大值是2GB,通过可变长的int型以字符串编码形式存储海量图像数据。此外,BufferedImage类带有图像常用的数据信息。
ImageWritable类的具体实现,如图3所示。其中ImageWritable的构造方法需由BufferedImage对象作参数;私有函数parse Bytes实现将BufferedImage转换为字节数组,进而转换成Text类型。第二个Text类型和第三个Text类型分别保存的是图像文件的后缀名及获取图像的网址。
2.3 HBase的数据库设计
本文设计的图像检索模型针对海量图像,因此,采用HBase数据库存储图像内容的数据及预处理后的数据。因为行键要求定长且惟一,所以本文采用MD5摘要处理图像获取的路径或网址。HBase中单元格的默认块大小是64KB,对列值没有长度限制,此外行键长默认小于65536。为了不影响图片的存取效率,对于小图像文件则不对图像字节数组分段。对HBase的数据表设计见表1。
2.4 图像输入模块
ImageWritable类只是一种MapReduce模型中键/值对值的数据类型,将将图像文件输入HBase数据库或分布式文件系统的常规的做法是继承Hadoop API的文件输入格式类(FileInputFormat)。FileInputFormat认为一个计算机本地图像文件是一个文件分片,将其转换成自定义的可序列化类。该图像检索模型主要由MapReduce并行模型和一个Web服务器组成,其中Web服务器具有文件上传和浏览的功能。MapReduce模型是实现获取图像数据和格式转换的程序。本地图像通过Web服务器转换成网络图像,并将记录网络图像地址的文本文件作为输入。Map过程获取文件流,生成BufferedImage对象,并转换成ImageWritable对象,然后通过SequenceFile文件保存到HDFS中。此外,也可以通过ImageWritable类将响应的图像字节数组保存在HBase中。将图像数据存储在HDFS的MapReduce流程图如图4所示。
2.5 分布式集群模块
分布式集群模块主要包括图像预处理、特征提取及相似度计算。通过ImageWritable,可以从HBase或HDFS获取所需图像数据,然后将现有选用的预处理生成的BufferedImage对象构建ImageWritable对象,通过Reduce写入HBase或HDFS的SequenceFile中。MapReduce过程中,特征提取与预处理不同之处是输出数据的类型是数字类型还是文本类型。相似度计算及其排序的输入输出的数据类型都是数字类型或者文本类型。分布式集群模块的实现如表2所示。
2.6 检索结果的显示模块
检索结果的显示模块中,将输入模块作为待检模块,相似度计算并排序后,读取相似度高的图像集合对应的图像数据并转换成BufferedImage对象,通过UI界面显示,将检索结果保存到本地计算机硬盘中。
3 Image Writable类的封装与实现
本文图像检索模型的核心类是Image Writable类。图像检索首先要实现对象转换,即BufferedImage和byte[],图像文件后缀名从网址中抓取。基于Java编程实现对ImageWritable类的封装与实现。具体代码如下:
其中ImageIO类用于读取和生成图像,是Java API的常用图像工具类。getBytes()将BufferedImage转换成byte[]对象,byte[]对象用于建立Text对象。Text类保证数据存储和传输的正确性、可靠性。ImageWritable类实现的Writable接口二进制读写流算法如下:
4 结束语
本文提出的基于Hadoop平台的图像检索模型实现了存取和检索图像数据的功能。该图像检索技术采用HBase的分布式列存储数据库,通过Map-Reduce实现并行检索图像,提高了检索速度,数据输入灵活,可并行处理大数据图像,适用于重构现有的图像检索系统。但该模型是假设在不受噪音影响的条件下检索,这也是下一步需要研究和改进的地方。
参考文献(References):
[1] 李向阳,庄越挺,潘云鹤.基于内容的图像检索技术与系统[J].
计算机研究与发展,2001.38(3):344-354
[2] Borthakur D. The hadoop distributed file system:
Architecture and design[J]. Hadoop Project Website,2007.11(11):1-10
[3] White T. Hadoop:the definitive guide[J]. O'reilly Media Inc
Gravenstein Highway North,2010.215(11):1-4
[4] 朱晓丽,赵志刚.一种基于HBase的海量图片存储技术[J].信
息系统工程,2013.8:22-24
[5] 朱敏,程佳,柏文阳.一种基于HBase的RDF数据存储模型[J].
计算机研究与发展,2013.50(s1):23-31
[6] 郑欣杰,朱程荣,熊齐邦.基于Map Reduce的分布式光线跟
踪的设计与实现[J].计算机工程,2007.33(22):83-85
[7] 李倩,施霞萍.基于Hadoop Map Reduce图像处理的数据类
型设计[J].软件导刊,2012.11(4):182-183
[8] 张良将,宦飞,王杨德.Hadoop云平台下的并行化图像处理
实现[J].信息安全与通信保密,2012.10:59-62
