
物联网海量不均衡数据组内方差SNM清洗算法
2025-02-08 00:00:00伍阳陈科基
现代电子技术 2025年3期



摘" 要: 由于物联网数据通常是不均衡的,导致采集的数据集中各个类别的样本数量差异很大,无法准确反映其内部的方差情况,使得数据文本相似度较高,为此,提出物联网海量不均衡数据组内方差SNM清洗算法。使用网络爬虫技术爬取海量不均衡数据,对不平衡数据字段过滤处理,设计可伸缩滑动窗口方式改进SNM算法,计算不均衡数据组内方差,将其作为清洗不均衡数据的约束,通过对比物联网海量不均衡数据组内方差阈值,实现物联网海量不均衡数据清洗。实验结果表明:该方法具备较强的物联网海量不均衡数据清洗能力,且清洗后的物联网海量不平衡数据的文本相似度较低,应用性较强。
关键词: 物联网; 不均衡数据; 组内方差; SNM清洗算法; 滑动窗口; 网络爬虫; 数据字段; 约束条件
中图分类号: TN919⁃34; TP391" " " " " " " " " " "文献标识码: A" " " " " " " " " " 文章编号: 1004⁃373X(2025)03⁃0124⁃05
SNM cleaning algorithm for intra⁃group variance of massive imbalanced data
in the Internet of Things
WU Yang, CHEN Keji
(College of Electrical Engineering and New Energy, China Three Gorges University, Yichang 443002, China)
Abstract: The data of the Internet of Things (IoT) is usually imbalanced, so the number of samples in each category in the collected data set varies greatly, which leads to failure to reflect the internal variance accurately, and makes the data texts similar with each other to a large extent. Therefore, an SNM (sorted⁃neighborhood method) cleaning algorithm for intra⁃group variance of massive imbalanced data in the IoT is proposed. The web crawler technology is used to crawl massive imbalanced data. The imbalanced data fields are filtered. A scalable sliding window is designed to improve the SNM algorithm. The intra⁃group variance of the imbalanced data is calculated. The intra⁃group variance obtained is taken as the constraint for cleaning the imbalanced data. By comparing the intra⁃group variance threshold of massive imbalanced data in the IoT, the massive imbalanced data of the IoT can be cleaned. The experimental results show that the method has a strong ability to clean the massive imbalanced data of the IoT, and the text similarity of the cleaned massive imbalanced data of the IoT is low, and its application scope is broad.
Keywords: IoT; imbalanced data; intra⁃group variance; SNM cleaning algorithm; sliding window; web crawler; data field; constraint condition
0" 引" 言
由于物联网设备的部署环境复杂、工作条件恶劣,使得物联网数据中常常存在噪声、缺失值、异常值等质量问题[1⁃2],如何清洗和预处理这些数据,成为物联网数据分析的重要问题。然而,由于物联网数据通常是不均衡的,在收集的数据集中,各个类别的样本数量差异很大。这种不均衡性来源于物联网设备部署位置、使用习惯、事件发生频率等因素。因此,研究物联网海量数据清洗新方法具有重要意义。
文献[3]提出异常数据清洗方法,通过采集海量需要清洗的数据建立数据集,提取数据集内不平衡数据特征后,计算所有数据特征的相似度,通过对比相似度阈值的方式实现数据的清洗。但该方法阈值设定过高,导致一些本应保留的正常数据被误判为异常数据而被清洗,因此数据清洗精度不足。文献[4]提出特征检测的异常数据清洗方法,运用聚类方式对海量数据进行聚类处理,得到每个数据标签对应的特征模式,运用二分类算法识别数据标签特征内的异常特征,将其对应的数据清除后,实现异常数据的清洗。在不同场景下,异常数据特征与正常特征在数据表现上非常接近,使得二分类算法难以准确区分,进而导致该方法对数据清洗的效果无法满足用户需求。文献[5]提出伪波动数据清洗方法,利用卡尔曼滤波方法对海量数据进行清洗处理,使用皮尔逊时序相关系数对海量数据二次清洗,利用卷积神经网络模型对可疑脏数据识别并进行第三次清洗。卷积神经网络在图像识别等领域表现出色,但用于数据清洗时,其泛化能力受到训练数据和参数设置等多种因素的影响。如果模型训练不足或过度拟合,将无法准确识别出所有的可疑脏数据,导致清洗结果不准确。文献[6]提出基于KPCA⁃IF⁃WRF模型的数据清洗方法,运用核主成分分析方法对海量数据降维处理,使用孤立森林算法剔除海量数据中的异常数据后,运用加权随机森林对缺失的数据进行填补。但该方法建立的KPCA⁃IF⁃WRF模型在迭代过程中容易陷入局部极值情况,其无法跳出局部极值,导致输出的数据清洗结果不够准确。
排序邻域算法(Sorted⁃Neighborhood Method, SNM)也称为基本邻近排序算法,该算法通过设置固定大小的窗口,对窗口内数据记录检测,可得到不同窗口内的重复数据[7],该算法在数据清洗领域应用较为广泛。因此,本文以SNM算法为基础,研究物联网海量不均衡数据组内方差SNM清洗算法,为物联网海量不平衡数据的应用提供一种有效的数据处理手段。
1" 不均衡数据组内方差SNM清洗方法
1.1" 基于爬虫技术的物联网海量不平衡数据获取
由于物联网数据通常呈现不均衡性,使用爬虫技术可以有选择地获取各类别数据,从而在一定程度上平衡样本数量,尤其是对少数类别的数据补充采集,以减小不均衡性带来的影响。因此,利用网络爬虫技术采集物联网海量不平衡数据,以Python软件内的Scrapy功能作为网络爬虫框架,在该框架内设置HTTP请求库、解析库、代理库等基本参数后,执行网络爬虫程序,其步骤如下。
第1步:发送爬虫请求,根据目标网站或API的要求构建HTTP请求,包括设置合适的请求头(如User⁃Agent)、请求参数等。使用HTTP请求库(如requests)发送请求,获取网页内容或API返回的数据。
第2步:对于HTML网页,可以使用BeautifulSoup或lxml等库解析,提取所需的数据元素。对于API返回的JSON数据,可以直接使用Python的JSON库解析数据。
第3步:如果目标数据是分页的,需要分析分页机制,编写循环代码遍历所有页面并获取数据。对于动态加载的内容,使用Selenium等库模拟浏览器行为[8],触发JavaScript代码以加载隐藏的数据。
经过上述过程,得到物联网海量不平衡数据。
1.2" SNM算法清洗不平衡数据逻辑分析
不平衡数据集往往存在较多的噪声和异常值,SNM算法采用排序方式来确定样本之间的距离和邻域关系,可以有效地减少噪声和异常值的影响,提高数据清洗的鲁棒性。该算法在对物联网海量不平衡数据清洗时,从物联网海量不平衡数据集内选择一个关键词,按照该关键词对物联网海量不平衡数据集内的数据排序处理,在物联网海量不平衡数据集内设置一个滑动窗口,该窗口大小为定值[9],在对物联网海量不平衡数据检查时,仅检查窗口内的若干条数据,物联网海量不平衡数据集上的滑动窗口如图1所示。
SNM算法通过图1的窗口滑动方式,按照选择的关键词计算窗口内存在的[m]个物联网海量不均衡数据的属性值,通过设置属性值阈值的方式,对比该窗口内物联网海量不均衡数据是否存在重复现象,若存在重复的物联网海量不均衡数据,则将邻近窗口的下一条数据移动到窗口内,反之,则将窗口内最上一条数据移出,如此往复,可实现物联网海量不均衡数据的重复数据清洗。
1.3" 改进SNM算法清洗不均衡数据
1.3.1" 物联网海量不平衡数据字段过滤处理
由于SNM算法在对物联网海量不均衡数据清洗时,对用于排序的关键字依赖性较大,若选择的关键字不够合理,会导致相似的物联网不平衡数据无法出现在同一个滑动窗口内,从而导致物联网海量不平衡数据的漏清洗[10]。
在处理物联网海量不平衡数据时,数据往往包含大量的特征,其中很多都不一定对解决特定问题具有重要性。通过字段过滤,可以仅保留和关注最相关的字段,提高数据处理的效率和准确性。为避免上述情况的出现,引入字段过滤方法对物联网海量不平衡数据进行处理,其详细处理过程如下。
令[H=H1,H2,…,HN]表示待清洗的物联网海量不均衡数据集,其中[N]为该数据内物联网海量不均衡数据总数,[H]内的不均衡数据具有[p]个属性和[m]个关键属性。物联网海量不均衡数据[Hi]和[Hj]在第[t]个属性上的相似度由[SimA(Hit,Hjt)]表示,则[Hi]和[Hj]的整体相似度[SimR(Hi,Hj)]的表达式如下:
[SimR(Hi,Hj)=t=1mSimA(Hit,Hjt)ϖt] (1)
式中[ϖt]表示物联网海量不均衡数据属性权值。
通过对比物联网海量不均衡数据属性相似度阈值,对属性关联不强的物联网海量不均衡数据字段过滤处理,可使排序后的物联网海量数据滑动窗口内的数据属性更统一[11⁃12],提升数据清洗效率的同时,还可有效提升物联网海量大数据清洗的精度。令[U]表示物联网海量不均衡数据属性相似度阈值,当式(1)结果小于或等于[U]时,则[Hi]和[Hj]的整体相似度[SimR(Hi,Hj)]可改写为:
[Sim'(Hi,Hj)=t=1pSimA(Hit,Hjt)ϖt] (2)
1.3.2" 可伸缩滑动窗口设计
在处理物联网海量数据时,数据通常以数据流的形式连续产生,传统的滑动窗口方法无法灵活地应对不断变化的数据流。设计可伸缩的滑动窗口可以根据不同的数据流速率来自动调整窗口大小,使得窗口能够适应不同速率和不规则的数据流,确保数据清洗的实时性和连续性。
令[C]表示滑动窗口,设置该滑动窗口的最大值和最小值分别为[Qmax]和[Qmin],该滑动窗口的初始值为[Qmin],该滑动窗口记录的物联网海量不均衡数据位置为[1,w],其中[1]为该窗口内首条记录,[w]为窗口末位记录。滑动窗口[w]的大小[Qn]的计算公式如下:
[Qn=Sim'(Hi,Hj)Qmin+(Qmax-Qmin)(w-i)Bi] (3)
式中[Bi]为滑动窗口[C]内第[i]条物联网海量不平衡数据。
1.3.3" 不均衡数据组内方差约束优化
当物联网海量不均衡数据属性较为接近但数据表述不同时,容易将该类数据一并清洗掉[13],为避免出现错误清洗现象,对SNM算法添加约束条件。使用最大类间方差法,计算物联网海量不均衡数据组内方差,使用该方差作为SNM算法清洗物联网海量不均衡数据的约束条件,避免错误清洗情况的出现。物联网海量不均衡数据组内方差计算过程如下。
当物联网海量不均衡数据总数为[N]时,第[i]个物联网海量不均衡数据[ni]的出现概率[Pi]的表达式如下:
[Pi=Qn⋅niN] (4)
令[T]表示物联网海量不均衡数据分组阈值,使用该阈值对物联网海量不均衡数据进行分组处理,则第[C0]和[C1]组的物联网海量不均衡数据产生的概率[r0]、[r1]的表达式如下:
[r0=Pi⋅T] (5)
[r1=Pi⋅Sim'(Hi,Hj)] (6)
依据式(5)、式(6),物联网海量不均衡数据组间均值[μ]的表达式如下:
[μ=r0μ0+r1μ1] (7)
式中:[μ0]、[μ1]分别表示[r0]和[r1]的均值。
依据式(7),物联网海量不均衡数据组间方差计算公式如下:
[σ2=r0(μ20-μ2)+r1(μ21-μ2)] (8)
式中,[σ2]表示物联网海量不均衡数据组间方差,将该数值作为SNM算法的约束,使其对物联网海量不均衡数据的清洗效果得到提升。
综上依据物联网海量不均衡数据组间方差,SNM算法清洗物联网海量不均衡数据的步骤如下。
第1步:使用1.3.1节的方法对物联网海量不均衡数据进行字段过滤处理,再对物联网海量不均衡数据关键词进行排序。
第2步:运用1.3.2节设计的动态滑动窗口对物联网海量不均衡数据进行窗口检测。
第3步:判断滑动窗口内的物联网海量不均衡数据是否重复,若否,则将滑动窗口向下移一位,再次判断数据是否重复。当滑动窗口内物联网海量不均衡数据存在重复时,通过式(8)计算物联网海量不均衡数据组间方差,当该方差低于方差阈值时,则将其对应的物联网海量不均衡数据进行记录并清除,反之,则将其对应的数据重新添加到待清洗数据集内。
2" 实验分析
使用本文方法爬取某时间段物联网数据,该类数据内含有结构化的表格类数据,也存在非结构haul的文本、视频和图像类数据,数据类型多样同时数据价值密度较低,具备不平衡特征。选取约100万条记录,包括传感器读数、设备状态等表格数据,抓取约10万条文本评论、5 000个视频片段和1万张图像。其中,结构化数据包括整型、浮点型、字符串型等,如温度(浮点型)、湿度(整型)、设备ID(字符串型)等;非结构化数据包括文本为字符串型,视频和图像为二进制或特定格式的文件。在利用上述物联网海量不平衡数据时,需要对其清洗处理,去除数据内含有的重复数据,运用本文方法实现物联网海量不平衡数据的清洗过程,并验证本文方法的实际应用效果。
利用本文方法爬取物联网海量不平衡数据后,建立待清洗物联网海量不平衡数据集,使用本文方法对其进行清洗处理,清洗结果如图2所示。
从图2中可明显看出,原始物联网海量不平衡数据集中存在大量重复数据(图中方形数据),增加了数据处理的复杂性和存储成本。然而,在运用本文方法对该数据集清洗后,这些重复的数据均被有效识别和去除,数据集的纯净度得到了显著提升。证明了本文方法在处理物联网海量不平衡数据清洗方面的强大能力,其应用效果显著,不仅可以提高后续数据分析的准确性和效率,还能为物联网应用的决策提供更可靠的数据支持。因此,本文方法对于物联网海量不平衡数据的处理具有重要的实用价值。
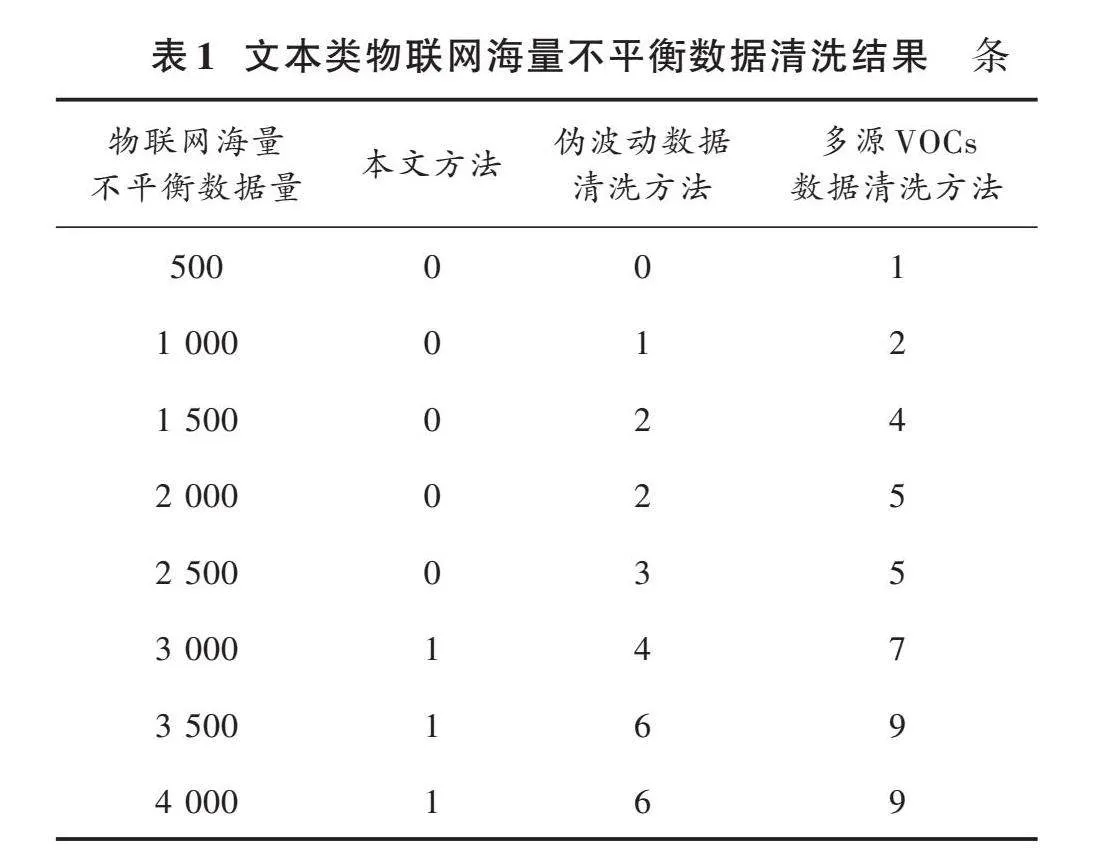
物联网海量不平衡数据内的文本类数据是存在冗余数据较多的数据类型,以文本类型的物联网海量不平衡数据作为实验对象,使用本文方法对其清洗处理,以剩余重复数据数量作为衡量指标,为使实验结果更加充分,同时运用文献[5]的伪波动数据清洗方法和文献[6]的多源VOCs数据清洗方法展开测试,测试结果如表1所示。
分析表1可知,三种数据清洗方法在应用过程中,重复数据剩余数量均随着物联网海量不平衡数据量的增加而增加,在物联网海量不平衡数据量为2 500条之前时,本文方法清洗后的物联网海量不平衡数据重复数据剩余数均为0条,在物联网海量不平衡数据量为4 000条时,本文方法清洗后的物联网海量不平衡数据重复数据剩余数仅为1条,而伪波动数据清洗方法和多源VOCs数据清洗方法则在物联网海量不平衡数据量相同时,其清洗后的物联网海量不平衡数据重复数据剩余数均高于本文方法。上述结果表明:本文方法清洗文本类物联网海量不平衡数据能力较强,应用效果较好。
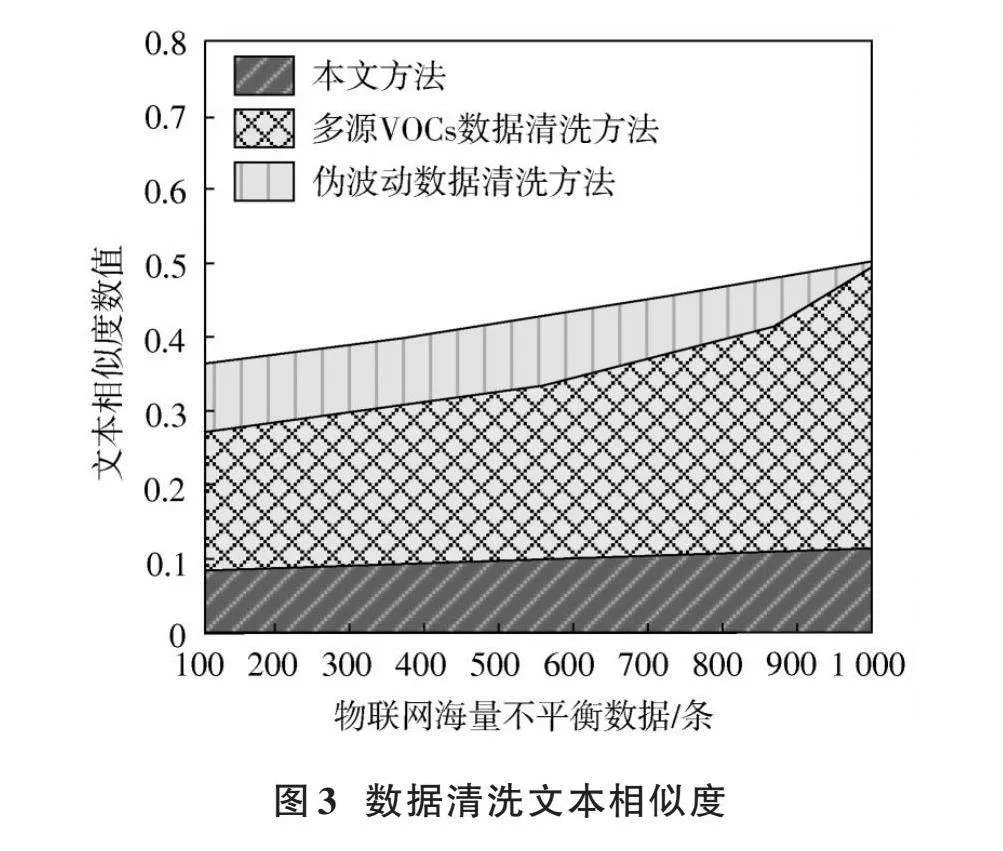
以文本相似度作为衡量指标,测试本文方法在清洗不同数量物联网海量不均衡数据后,文本类物联网海量不均衡数据的相似度结果如图3所示。
分析图3可知,在三种数据清洗方法中,本文方法对物联网海量不平衡数据进行清洗后,文本类物联网海量不平衡数据的文本相似度数值在0.1左右,该数值说明清洗后的物联网海量不平衡数据的属性均不相同,本文方法对物联网海量不平衡数据的清洗效果较好。
3" 结" 论
物联网海量不均衡数据组内方差SNM清洗算法的研究与应用,对于提升数据处理效率和准确性具有重要意义。该算法通过计算数据组内的方差来识别并清洗重复或冗余数据,有效解决了物联网海量数据中存在的数据质量问题。在实际应用中,该算法展现出了强大的数据清洗能力,能够显著减少数据冗余,提高数据集的纯净度,为后续的数据分析与挖掘奠定了坚实基础。
参考文献
[1] 匡俊搴,赵畅,杨柳,等.一种基于深度学习的异常数据清洗算法[J].电子与信息学报,2022,44(2):507⁃513.
[2] 郭慧军,李永亭,齐咏生,等.两阶段CP⁃Copula的风电机组异常数据清洗算法[J].计算机仿真,2022,39(11):85⁃91.
[3] YAN H Y, MA L D, ZHAO T Y, et al. Research on repair method of abnormal energy consumption data of lighting and plug based on similar features [J]. Energy and buildings, 2022, 268: 1⁃18.
[4] LONG H, XU S H, GU W. An abnormal wind turbine data cleaning algorithm based on color space conversion and image feature detection [J]. Applied energy, 2022, 311: 118594.
[5] 高正男,杨帆,胡姝博,等.面向新能源电力系统状态估计的伪波动数据清洗[J].高电压技术,2022,48(6):2366⁃2377.
[6] 黄光球,赵羲轩,陆秋琴.基于KPCA⁃IF⁃WRF模型的多源VOCs数据清洗方法研究[J].安全与环境学报,2022,22(6):3412⁃3423.
[7] 鲁树武,伍小龙,郑江,等.基于动态融合LOF的城市污水处理过程数据清洗方法[J].控制与决策,2022,37(5):1231⁃1240.
[8] 韩京宇,陈伟,赵静,等.基于异常特征模式的心电数据标签清洗方法[J].计算机研究与发展,2023,60(11):2594⁃2610.
[9] 张婷婷,李伟,郝晓艳.基于R软件对医学研究中多选题的数据清洗与分析[J].东南大学学报(医学版),2022,41(6):764⁃768.
[10] 夏延秋,夏和民,冯欣.一种基于风功率曲线的SCADA数据清洗方法研究[J].可再生能源,2022,40(11):1499⁃1504.
[11] 谢智颖,何原荣,李清泉.基于时空相关性的公交大数据清洗[J].计算机工程与应用,2022,58(1):113⁃121.
[12] 李洪烈,夏栋,王倩.基于回归模型的采集数据清洗技术[J].电光与控制,2022,29(4):117⁃120.
[13] 许小刚,王志香,王惠杰.基于深度长短记忆网络的汽轮机数据清洗[J].热力发电,2023,52(8):179⁃187.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
党的生活(黑龙江)(2022年4期)2022-04-25 22:14:17
当代陕西(2019年14期)2019-08-26 09:42:00
制造技术与机床(2018年11期)2018-11-23 01:08:02
通信世界(2018年27期)2018-10-16 09:02:56
意林(绘英语)(2018年1期)2018-04-28 01:21:42
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
城市轨道交通研究(2015年11期)2015-02-27 11:02:50
风能(2015年10期)2015-02-27 10:15:34
雷达学报(2014年4期)2014-04-23 07:43:07
