
基于BiFPN和注意力机制改进YOLOv5s的车辆行人检测
2025-02-08 00:00:00刘丽丽王智王亮李嘉琛方国香吕亦雄
现代电子技术 2025年3期
关键词:自动驾驶
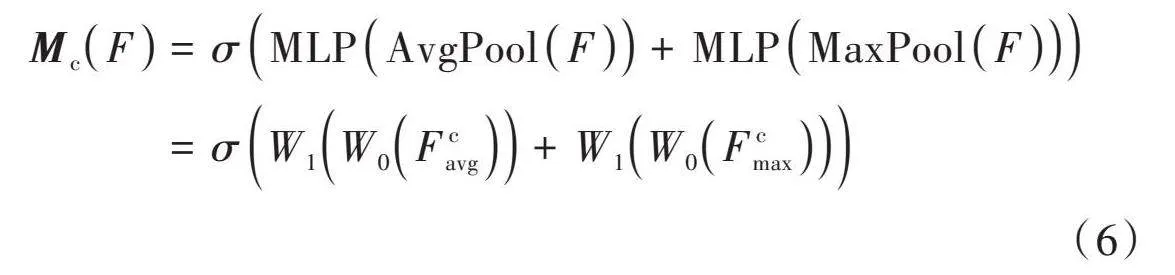







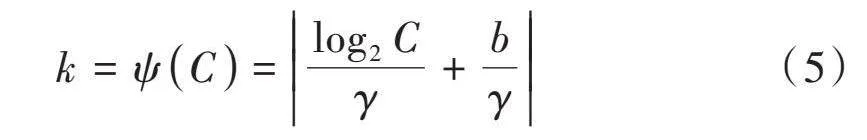



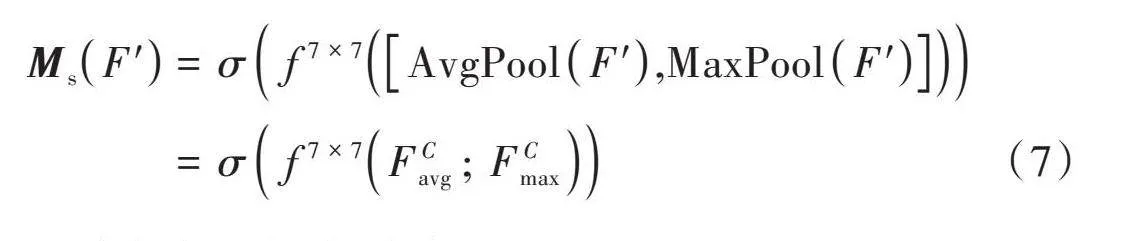
摘" 要: 随着人工智能技术在交通领域的深入应用,实时检测和跟踪交通道路中的车辆与行人成为自动驾驶技术不可或缺的组成部分。为了提升在复杂环境中的检测精度与速度,文中提出一种基于BiFPN和注意力机制改进的YOLOv5s模型。通过集成双向特征金字塔网络(BiFPN)和引入CBAM注意力机制,优化了模型对小目标的识别能力,并通过数据增强技术处理自动驾驶公开数据集SODA10M,解决样本不均问题。实验结果显示,改进模型在SODA10M数据集上的mAP值达到85.2%,较原始YOLOv5模型提高2.7%,同时FPS达到了42 f/s,相比原模型下降了7 f/s,虽有所下降,但在保持较高精度的同时实现了较快的检测速度。该研究在复杂环境下提升目标检测与跟踪技术方面展现出了新的思路和潜力,对于自动驾驶技术的发展具有重要的应用价值。
关键词: 自动驾驶; YOLOv5s; CBAM; BiFPN; DeepSORT; ByteTrack
中图分类号: TN911.73⁃34; TP391" " " " " " " " "文献标识码: A" " " " " " " " " " 文章编号: 1004⁃373X(2025)03⁃0174⁃07
Improved YOLOv5s vehicle and pedestrian detection
based on BiFPN and attention mechanism
LIU Lili1, WANG Zhiwen1, WANG Liang2, LI Jiachen1, FANG Guoxiang3, LÜ Yixiong1
(1. School of Electronic Engineering, Guangxi University of Science and Technology, Liuzhou 545006, China;
2. School of Electronic Information Engineering, Changchun University of Science and Technology, Changchun 130013, China;
3. School of Computer Science and Technology, Guangxi University of Science and Technology, Liuzhou 545006, China)
Abstract: With the deep application of artificial intelligence (AI) technology in the field of transportation, real⁃time detection and tracking of vehicles and pedestrians on traffic roads has become an indispensable component of autonomous driving technology. In order to improve detection accuracy and speed in complex environments, an improved YOLOv5s model based on BiFPN (bidirectional feature pyramid network) and attention mechanism is proposed. By integrating BiFPN and introducing CBAM (convolutional block attention module) attention mechanism, the model′s recognition ability for small objects is optimized. The data augmentation technology is used to process the publicly available dataset SODA10M for autonomous driving, so as to get rid of the sample non⁃uniformity. The experimental results show that the improved model achieves an mAP of 85.2% on the SODA10M dataset, which is 2.7% higher than that of the original YOLOv5 model. In addition, its FPS reaches 42 f/s, which is 7 f/s lower than that of the original model. Although there is a slight decrease for FPS, it achieves fast detection speed while maintaining high accuracy. This study demonstrates new ideas and potential in improving object detection and tracking technology in complex environments, and has significant application value for the development of autonomous driving technology.
Keywords: autonomous driving; YOLOv5s; CBAM; BiFPN; DeepSORT; ByteTrack
0" 引" 言
在当前的智能监控和自动驾驶领域,YOLOv5s以其轻量级结构和高效的检测速度受到广泛关注。尽管其性能卓越,但在处理现实世界复杂场景时,尤其是在小目标检测和遮挡问题上仍面临着挑战。小目标因其在图像中占据的像素少,加之拍摄角度和距离的多样性,往往导致检测精度下降[13]。为了解决这些问题,本文提出了改进的YOLOv5s算法,旨在增强其对小目标的检测能力并优化遮挡场景下的性能。首先,引入注意力机制到主干特征提取网络中,以便更有效地从背景噪声中提取出有用的目标信息;其次,通过增加P2特征层参与特征融合,新增了专门针对小目标的预测分支,以提高模型对小目标的敏感度;最后,采用BiFPN替换原有特征融合结构,以增强不同尺度特征间的信息流动。这些改进旨在提升YOLOv5s在各种复杂环境中的适应性和准确性,为实际应用中的目标检测技术发展提供新的思路。
1" 相关理论
1.1" YOLOv5目标检测算法
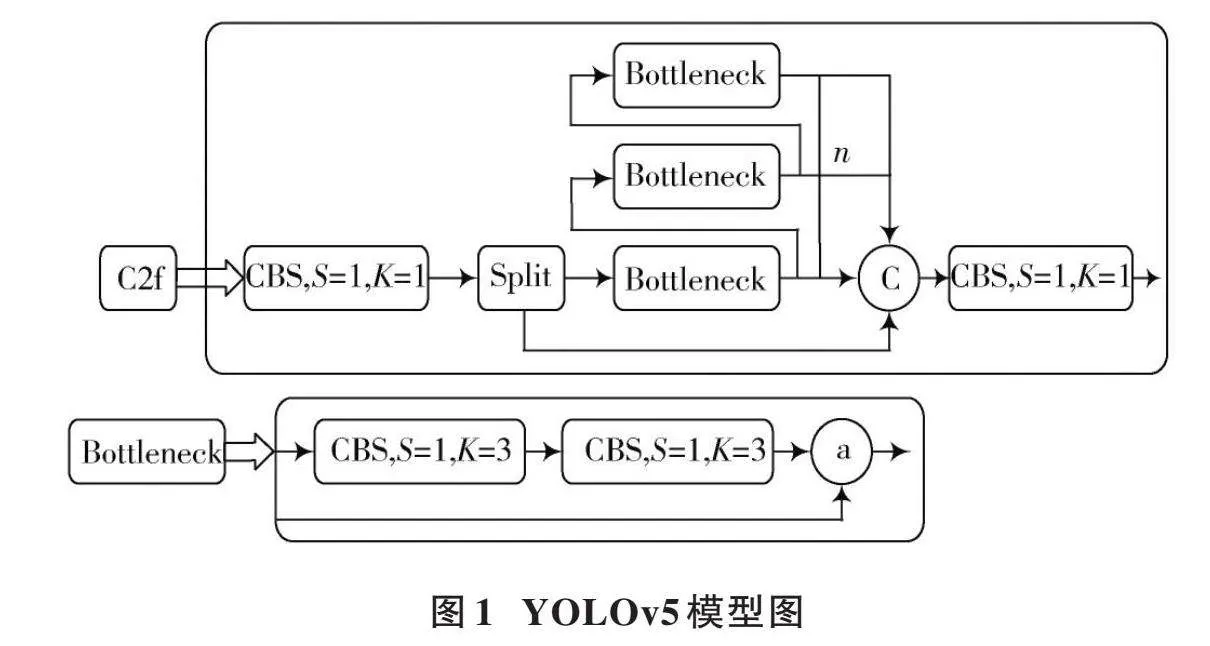
YOLOv5通过精炼模型结构,实现资源受限条件下的高效目标检测,模型结构如图1所示。模型包括CBS模块、CSP1模块、CSP2模块、SPPF和Head五个部分,为实时目标检测奠定了基础。
1.2" 目标检测评价指标
本文采用精确度([P])、召回率([R])、平均精确率(AP)和平均精确率的平均值(mAP)作为评价目标检测算法性能的指标。
[P]计算了分类器预测为正样本实际上也确实是正样本的比例,用式(1)计算:
[P=TPTP+FP×100%] (1)
[R]是衡量分类器正确识别为正样本的数量占实际正样本总数的比例,如式(2)所示:
[R=TPTP+FN×100%] (2)
式中:TP表示被模型预测为正样本、实际为正样本的数量;FP指被模型误判为正样本、实际为负样本的数量;FN代表实际上是正样本却被模型预测为负样本的数量。
AP为某一检测类别下[PR]曲线所围成的面积大小,如式(3)所示。mAP表示加权后所有类别的平均精度的平均结果,用来衡量目标检测网络性能的好坏,如式(4)所示:
[AP=01PRdR] (3)
[mAP=i=1NAPiN] (4)
式中:[N]表示所有目标类别的数量;[i]表示第[i]类目标。
2" 基于改进YOLOv5s的车辆行人检测
2.1" 引入注意力机制
在卷积神经网络(CNN)的结构中,卷积操作的权重共享特性意味着图像中的每个像素点都被同等对待,这样的设计虽然提高了模型的计算效率,但同时也使得模型难以有效区分图像中的前景与背景,尤其在背景复杂的情况下,模型可能会错误地将背景信息识别为目标[8]。为了解决这一问题,研究者引入了注意力机制,让模型自动学习一组权重系数,这些权重会被不均等地分配到图像的不同区域,特别是那些包含关键信息的目标区域。这样,模型就可以将更多的关注集中在重要的信息上,减少对无关背景的干扰,从而提升对目标的识别和关注能力。
2.1.1" ECA注意力机制
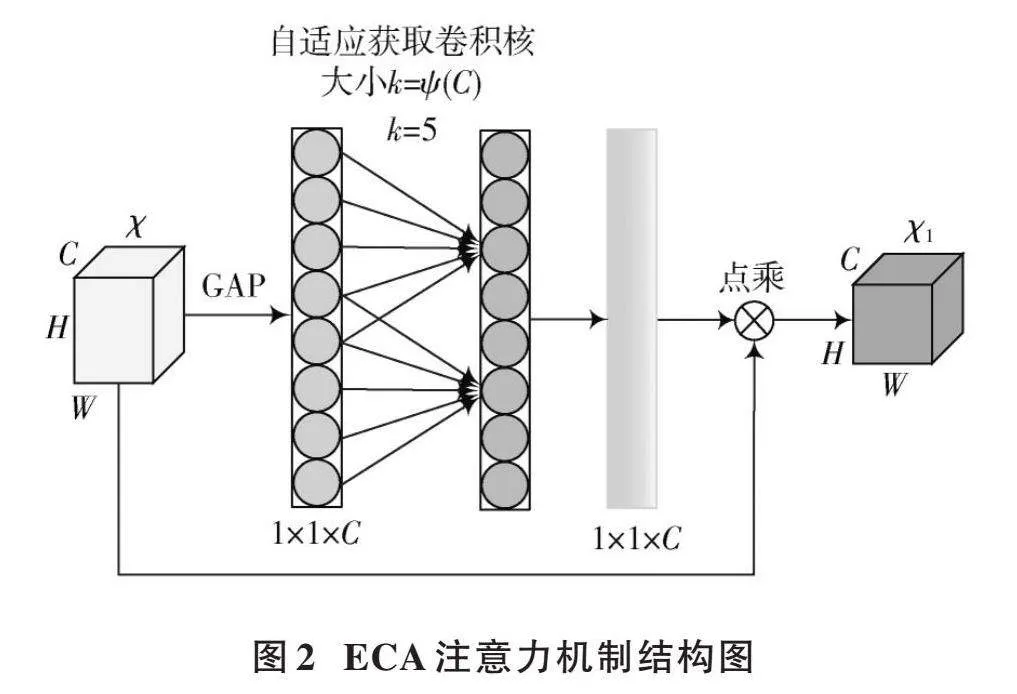
ECA注意力机制对SE注意力机制进行了改良,目的是提高通道注意力计算的效率和效果。SE机制通过两轮全连接层实现了通道的降维与升维操作,这种降维方法可能对通道注意力的准确预测产生负面影响,同时,捕捉所有通道之间的相互依赖性既不高效也非必需。ECA机制采用了一种更为精简的方法,只关注每个通道及其[k]个最近邻通道之间的局部交互,来优化跨通道的信息捕获过程。
ECA注意力机制的结构如图2所示。首先对输入特征图应用全局平均池化,以生成一个1×1×[C]维的特征向量;接着,利用一个大小为[k]的1D卷积层对该向量进行处理,产生一个维度相同的特征矩阵[6],通过Sigmoid函数激活后,得到通道权重;最后通过点乘操作将权重应用于输入特征矩阵上。其中,卷积核的大小[k]是用式(5)计算得到的一个自适应核。
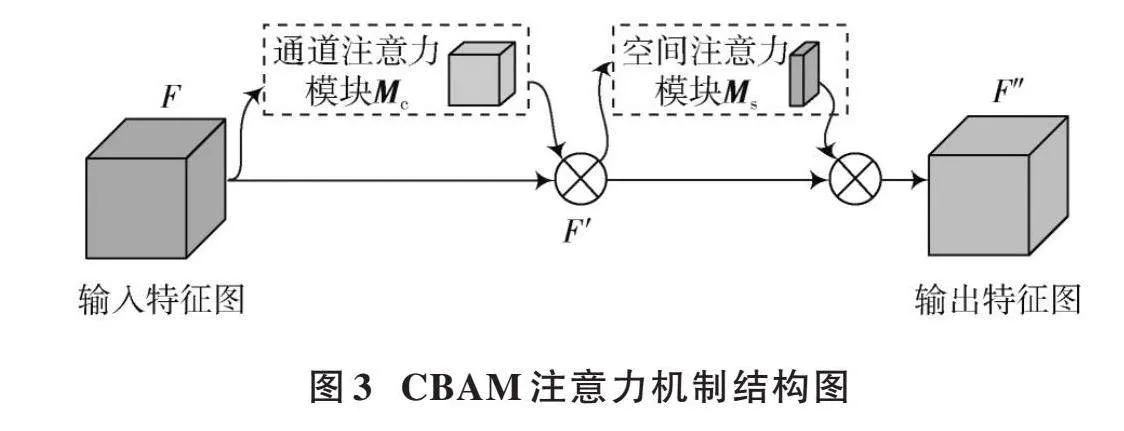
2.1.2" CBAM注意力机制
CBAM注意力机制[7]分为通道和空间两个模块,如图3所示。首先,输入特征图通过通道模块,为关键特征分配更高权重,通过相乘得到调整后的特征图;然后,此特征图进入空间模块,强化重要空间特征;最终,CBAM输出经过两阶段增强的特征图[6],提升了模型对关键信息的识别能力。
[k=ψC=log2 Cγ+bγ] (5)
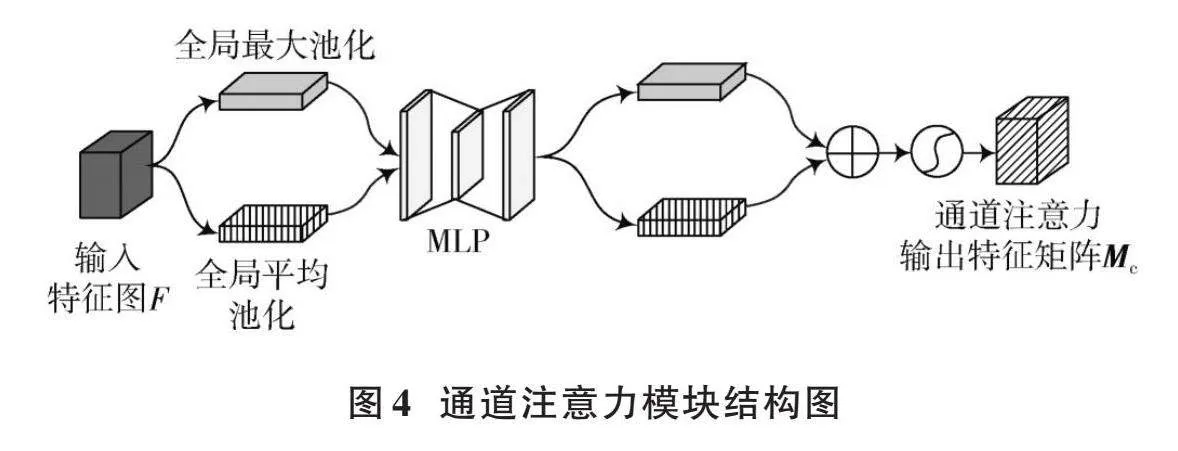
在图4所描述的通道注意力模块架构里,初始步骤涉及将输入特征图通过最大池化和平均池化两种处理方式,在其宽度和高度上形成两个1×1×[C]维的特征图。将这两个处理后的特征图分别传递给一个多层感知机(MLP),目的是提升其特征的表达能力。经过MLP处理的结果将被合并,然后经过Sigmoid函数激活,最终生成该通道注意力模块的输出特征图[Mc]。
在图4中,[F∈RC×H×W],输出特征图,[Mc∈RC×1×1],则[Mc]可用式(6)表示。
[McF=σMLPAvgPoolF+MLPMaxPoolF=σW1W0Fcavg+W1W0Fcmax] (6)
式中:[σ]为Sigmoid激活函数;[W0]和[W1]分别表示MLP中的降维和升维操作,降维之后经过ReLU激活函数再进行升维,降维后得到的特征图维度为[Cr×C],升维之后得到的特征图维度为[C×Cr]。通道注意力上的权重生成后,与输入特征图相乘,得到通道注意力模块的输出特征。
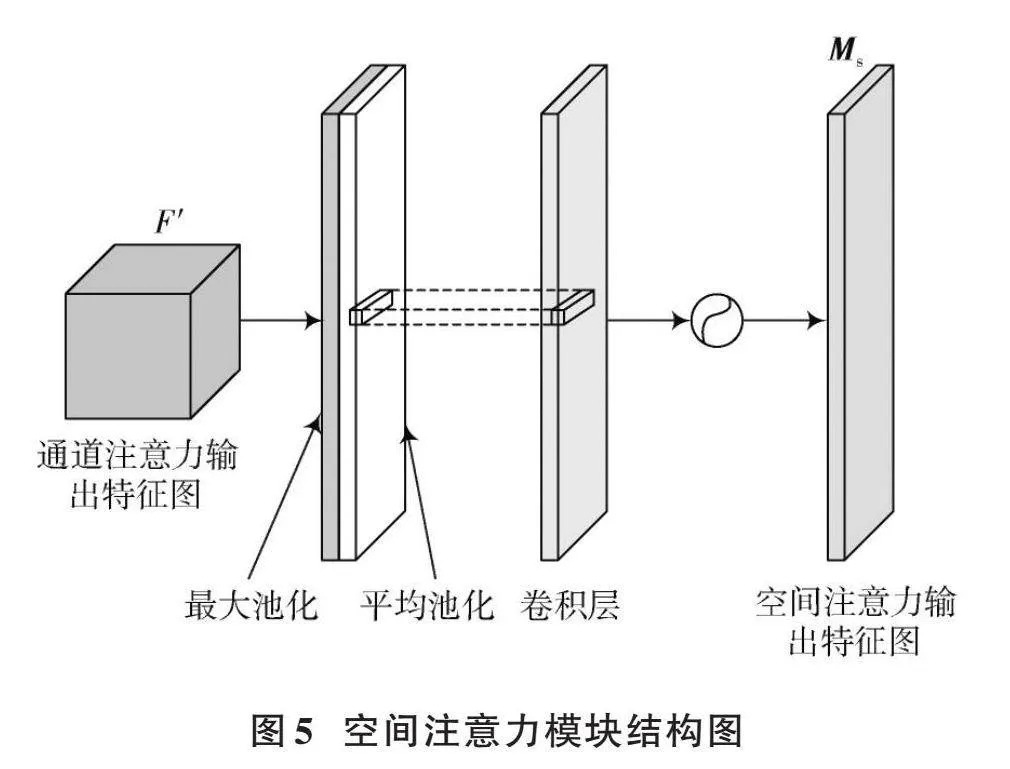
对于空间注意力模块,其结构如图5所示。
该模块首先对通道注意力模块的输出特征执行最大池化和平均池化操作,生成两个维度为[H]×[W]×1的特征图;接着,这两个特征图会在通道层面上合并起来,并通过一个7×7大小的卷积层处理将特征图的通道数减少到1;最后,通过Sigmoid激活函数处理,得到空间注意力模块的输出特征图[Ms]。图5中,[Ms∈RH×W],[Ms]可用式(7)表示。
[MsF'=σf7×7AvgPoolF',MaxPoolF'" " " " " " =σf7×7FCavg;FCmax" " " ] (7)
2.2" 增加小目标检测层
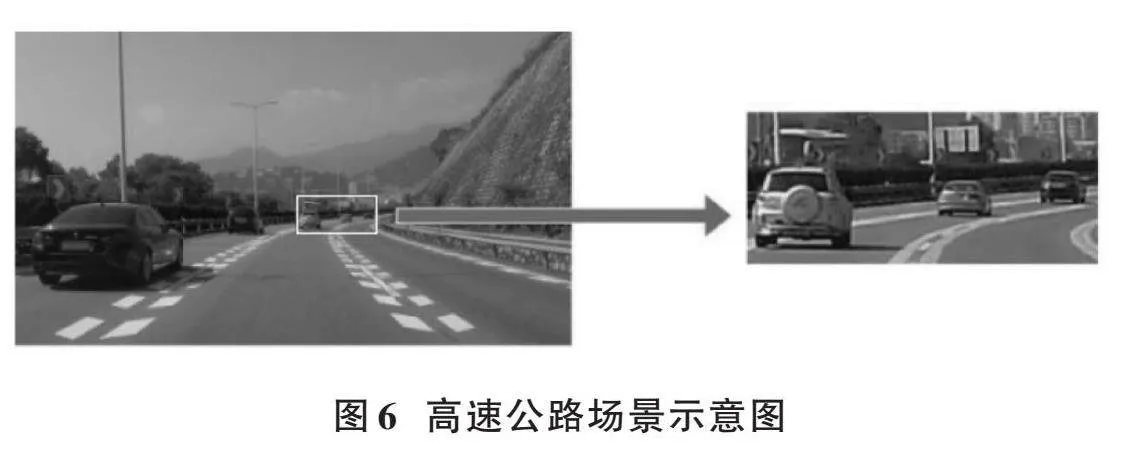
[YOLOv5]的架构设计包含三个检测头,旨在处理图像中的不同尺度目标,以覆盖多数标准检测场景下的尺度变化需求。然而,当面临极端的尺度变化,尤其是在特定的复杂环境或小目标检测[9]场景中,模型的性能有限,容易出现漏检现象。如在图6所示的高速公路场景下,远处的车辆有时不被检测到,暴露了应对某些挑战性情况时的局限性。
在特征提取网络中,浅层网络捕捉的是丰富的局部细节,具有较小的感受野和高分辨率,这使得它能够捕获到小目标的详细信息。相反,深层网络提供的是全局信息,随着网络深度的增加,感受野扩大,得到的特征图分辨率较低但包含了更多的中到大尺寸目标信息。这种设计虽然能够处理多种尺寸的目标,但对小目标的检测效果不尽人意。为了增强对小目标的检测能力,本文在[YOLOv5s]三个检测层的基础上,引入了一个专门针对小目标检测的层,创建了改进型模型YOLOv5⁃P2,如图7所示。在该模型中,第19层对80×80的特征图进行上采样,与第2层的160×160特征图在第20层进行融合,实现深层与浅层特征的合并。检测层因此增加到4层,分别位于网络的第21层、24层、27层、30层。虽然这种改进提升了小目标的检测性能,但也带来了网络运算成本的增加,进而影响了训练速度和检测效率。尽管如此,该方法对小目标的检测精度有显著改进。
2.3" BiFPN特征融合
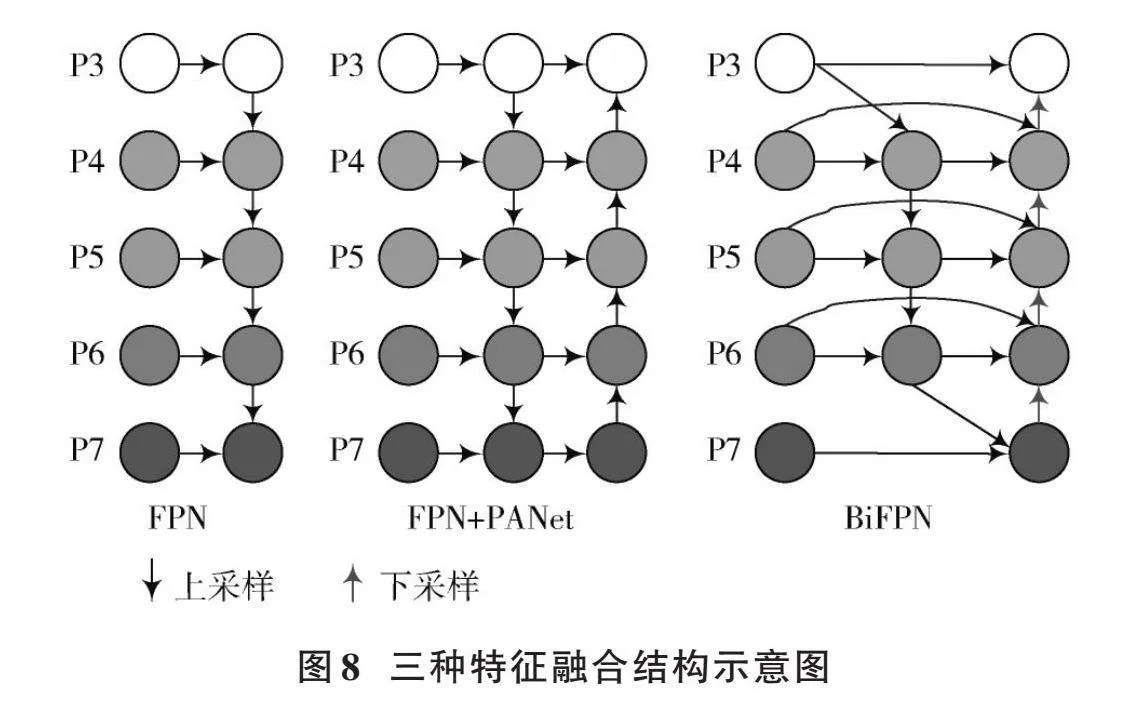
2019年,谷歌大脑团队在EfficientDet[4]目标检测算法中引入了双向特征金字塔网络(BiFPN),是对PANet的进一步改进。本文将BiFPN引入YOLOv5中进行特征融合,BiFPN结构如图8所示。通过引入可学习的参数调节各输入特征的权重,进一步提升了模型的特征提取和融合能力。
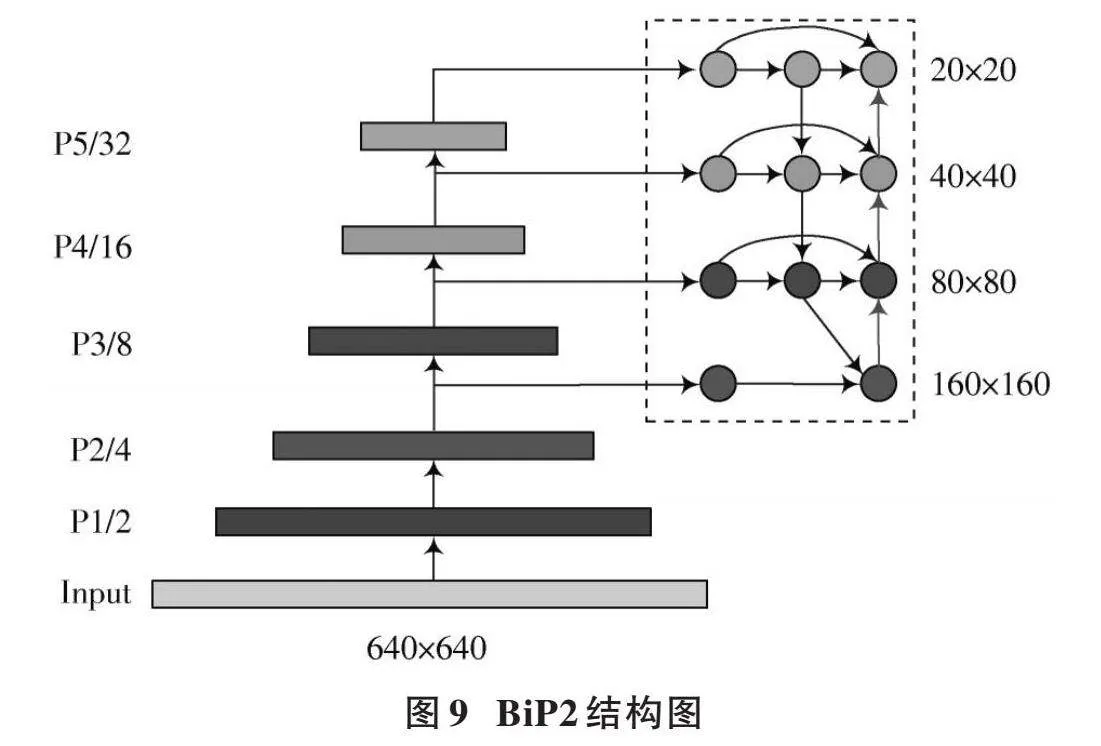
为了将BiFPN结构引入YOLOv5⁃P2模型,需要对BiFPN结构做进一步改进。针对YOLOv5⁃P2模型,去掉了BiFPN的一个输入特征层,将输入端的特征层由5个变为4个,把YOLOv5⁃P2模型中的P2~P5特征层作为BiFPN的输入端,根据自顶向下、自底向上规则建立BiP2结构,如图9所示。
3" 实验结果与分析
3.1" 引入注意力机制
在相同的实验环境和实验条件下,在YOLOv5s的主干网络中分别加入SE[1]、ECA[2]、CBAM、CA,五种模型的实验性能结果定量比较如表1所示。
从表1可以看出,加入CBAM注意力机制之后,mAP相比原始YOLOv5s模型提高了0.2%,精确度下降了1.4%,召回率提高了0.9%,FPS达到了47 f/s,满足实时检测的要求。
四种注意力机制应用于主干特征提取网络后的热力图如图10所示,性能明显得到了提升,其中CBAM[3]表现最佳,能更有效地集中于感兴趣区域。针对小目标的检测结果如图11所示,用矩形高亮显示了小目标,对比了添加SE、ECA、CBAM、CA这四种注意力机制后与YOLOv5s比较的检测效果。
图11检测结果表明在加入CBAM注意力机制之后,模型对小目标和遮挡场景的识别能力明显超过了原始模型及其他注意力机制[12]改进的模型。总体而言,加入CBAM的模型表现出更优越和平衡的性能[11]。因此,本文通过引入CBAM,有效提高了模型的鲁棒性和目标特征提取能力,实现了更精准的检测效果。
3.2" YOLOv5⁃P2和YOLOv5⁃BiP2
在相同的实验环境和数据集下,比较原始YOLOv5s、YOLOv5⁃P2、YOLOv5⁃BiP2三种模型的性能,如表2所示。
由表2可以看出,增加小目标检测层的YOLOv5⁃P2模型以及采用BiFPN特征融合的YOLOv5⁃BiP2模型准确率和召回率相比原始的YOLOv5s模型均有所提升,其中YOLOv5⁃BiP2模型提升最多,准确率提升了1.5%,召回率提升了2.3%,mAP提升了2.8%,FPS达到了47 f/s,虽然相比原始YOLOv5s下降了2 f/s,但是仍能满足实时检测的要求。[YOLOv5s]、YOLOv5⁃P2和YOLOv5⁃BiP2三种模型的检测结果如图12所示。
图12的检测结果显示,在添加小目标检测层后,目标漏检现象仍然存在。通过采用BiFPN特征融合策略,目标漏检问题得到了一定程度的缓解。BiFPN是在PANet架构基础上进行的改进,它通过在同级特征节点中增加一条从基础节点到输出节点的额外连接线,实现了在不显著增加计算成本的前提下,更有效的特征融合。此外,BiFPN还引入了一种根据不同层级特征对检测结果贡献度不同,为不同层节点分配加权值的方法,这一策略在实验中展示了更良好的性能。
3.3" 各类改进方法实验结果对比
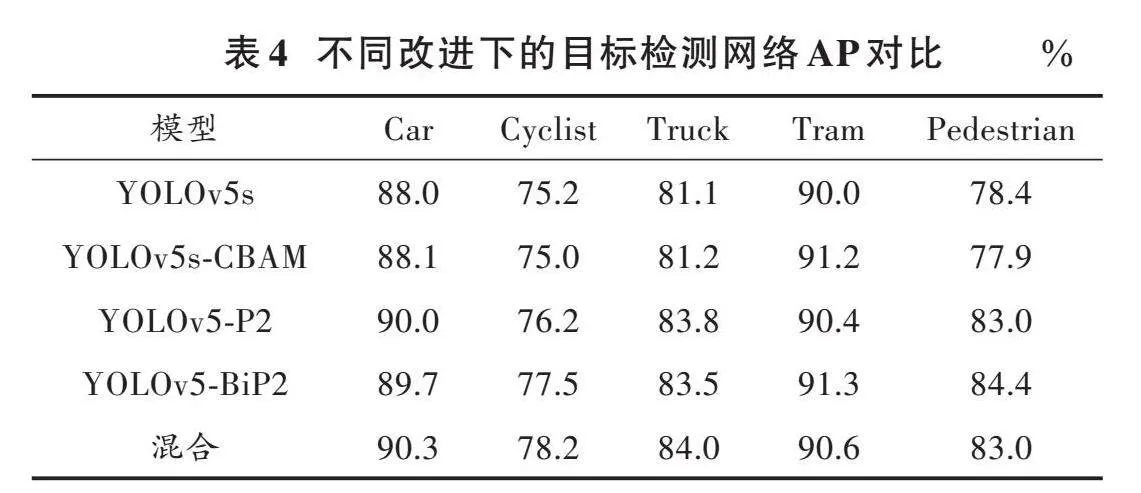
表3、表4分别显示了采用CBAM[5]注意力机制、增加检测层、BiFPN特征融合以及混合改进后的目标检测模型性能对比。
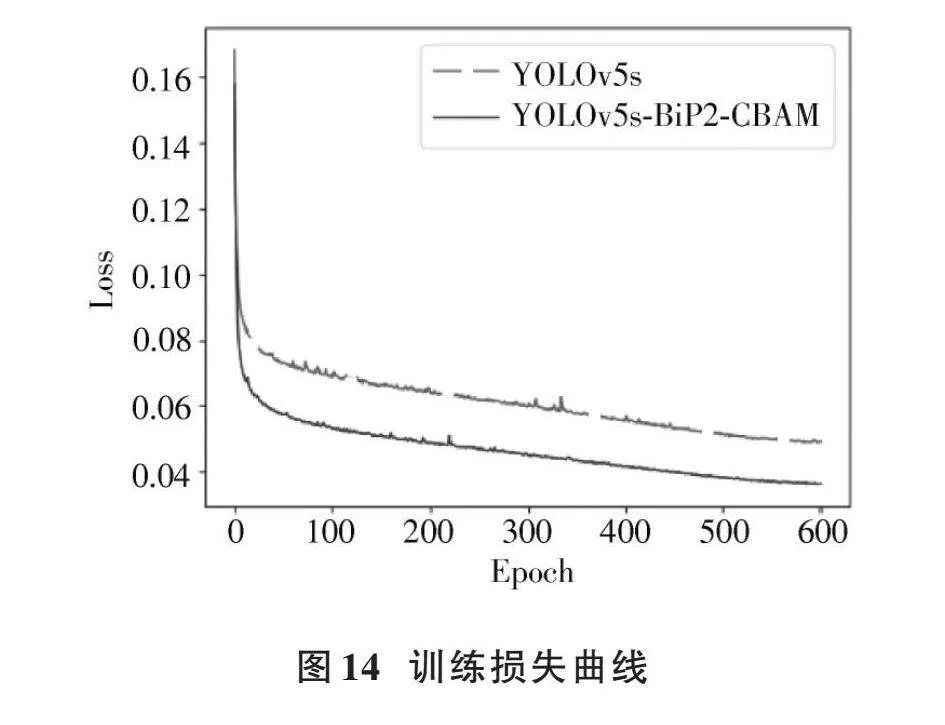
由表3、表4可知,混合改进后的目标检测模型mAP达到了85.2%,FPS达到了42 f/s,相比YOLOv5s模型,mAP提升了2.7%,FPS下降了7 f/s。虽然mAP值相比YOLOv5⁃BiP2模型下降了0.1%,但从各个类别的AP值来看,混合改进后,Car(汽车)、Cyclist(骑行者)、Truck(卡车)三种类别的AP值相比YOLOv5⁃BiP2模型均有所提升,证明了改进后模型的有效性[10]。图13为YOLOv5s和混合改进后模型的检测效果。改进后模型的训练损失曲线和原YOLOv5s的损失曲线如图14所示。
由图14可以看出,改进后的模型相比于原YOLOv5s能够更快地收敛。
4" 结" 语
本文探讨了针对车辆和行人检测中漏检问题的解决方案,对YOLOv5s网络实施三种不同的优化策略,并对每种改进进行了实验和对比分析。实验结果显示,采用一种综合的改进方法能够在保持检测速度和提高精度之间实现最佳平衡。虽然检测速率有轻微下降,但相比原始网络模型,检测精度得到了明显提升。
参考文献
[1] HU J, SHEN L, ALBANIE S. Squeeze⁃and⁃excitation networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 7132⁃7141.
[2] WANG Q L, WU B G, ZHU P F, et al. ECA⁃Net: Efficient channel attention for deep convolutional neural networks [C]// CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2020: 11531⁃11539.
[3] WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision (ECCV). Heidelberg: Springer, 2018: 3⁃19.
[4] TAN M X, LE Q V. EfficientNet: Rethinking model scaling for convolutional neural networks [C]// Proceedings of the 2019 IEEE International Conference on Machine Learning. New York: IEEE, 2019: 6105⁃6114.
[5] 张德春,李海涛,李勋,等.基于CBAM和BiFPN改进YOLOv5的渔船目标检测[J].渔业现代化,2022,49(3):71⁃80.
[6] 田宇.基于深度学习的小目标检测算法研究[D].秦皇岛:燕山大学,2021.
[7] 赵婉月.基于YOLOv5的目标检测算法研究[D].西安:西安电子科技大学,2021.
[8] 孟利霞.基于深度学习的车辆行人检测方法研究[D].太原:中北大学,2021.
[9] 贾旭强.基于深度学习的船舶目标检测方法研究[D].兰州:兰州大学,2021.
[10] 胡俊超.基于深度学习的多道路场景多尺度车辆目标检测算法优化研究[D].成都:西南交通大学,2021.
[11] HAN J H, LIANG X W, XU H, et al. SODA10M: A large⁃scale 2D self/semi⁃supervised object detection dataset for autonomous driving [EB/OL]. [2021⁃11⁃08]. https://arxiv.org/abs/2106.11118?context=cs.
[12] 朱佳丽,宋燕.基于迁移学习的注意力胶囊网络[J].智能计算机与应用,2021,11(2):44⁃49.
[13] 郭玉彬.基于视频图像的车辆检测跟踪及行为识别研究[D].北京:北京交通大学,2021.
猜你喜欢
南风窗(2017年23期)2017-11-23 11:15:33
科技创新导报(2017年26期)2017-11-08 08:42:58
科学与财富(2017年28期)2017-10-14 14:15:17
中国计算机报(2017年22期)2017-09-16 22:10:44
山东工业技术(2017年15期)2017-09-05 06:02:15
中国科技术语(2017年3期)2017-07-10 10:59:13
汽车周刊(2017年5期)2017-06-06 14:02:49
中国科技纵横(2017年4期)2017-05-16 08:29:17
中国科技博览(2017年5期)2017-04-25 16:37:32
移动通信(2016年24期)2017-03-04 22:12:26
