
基于多分支HRNet的图像篡改检测与定位模型
2025-02-08 00:00:00曾桢谭平
现代电子技术 2025年3期









摘" 要: 传统的篡改方法如拷贝粘贴和拼接已演变为利用深度学习生成的高质量伪造图像,这些篡改技术在图像纹理和细节上留下难以察觉的痕迹,如高频噪声模式的异常、颜色分布的微妙变化,以及边缘区域的不自然过渡。这些痕迹分布在不同分辨率层次和空间位置,增加了检测的难度。现有模型在整合多尺度和多位置特征时存在不足,难以有效捕捉局部细微纹理变化。针对这一问题,文中提出一种基于多分支HRNet的图像篡改检测与定位模型。该模型通过集成纹理增强模块,增强对图像篡改细节特征的捕获能力。同时,结合Spatial Weighting与Cross Resolution Weighting策略优化特征融合,并使用新的损失函数W_Arcloss,显著提升了模型在复杂篡改检测任务中的性能。在CASIA、Columbia、COVERAGE和NIST16等数据集上,该模型的检测准确度相较于PSCC⁃Net、HIFI⁃Net模型分别平均提升了6.5%与0.8%,并且泛化能力得到提升。这些结果证明了模型在处理多种篡改类型时的有效性和鲁棒性,为图像篡改检测与定位领域提供了新的研究视角和技术手段。
关键词: 图像篡改检测; 深度学习; 多分支HRNet; 纹理增强模块; Spatial Weighting; Cross Resolution Weighting; W_Arcloss
中图分类号: TN911.73⁃34; TP391.41" " " " nbsp; " " " 文献标识码: A" " " " " " " " " 文章编号: 1004⁃373X(2025)03⁃0035⁃08
Image tampering detection and localization model based on multi⁃branch HRNet
ZENG Zhen1, 2, TAN Ping1
(1. School of Information, Guizhou University of Finance and Economics, Guiyang 550025, China; 2. Big Data Institute, Wuhan University, Wuhan 430000, China)
Abstract: Traditional tampering methods such as the copy and paste and the stitching have evolved into high⁃quality forged images generated by deep learning. These tampering technologies leave imperceptible marks on the textures and details of the image, such as anomalies in high⁃frequency noise patterns, subtle changes in color distribution, and unnatural transitions in edge regions. These traces are distributed at different levels of resolution and spatial positions, which increases the difficulty of detection. The existing models have shortcomings in integrating multi⁃scale and multi⁃position features, which makes it difficult to capture local subtle texture changes effectively. In view of the above, this study proposes an image tamper detection and localization model based on multi⁃branch HRNet (high⁃resolution net). This model enhances the ability to capture the image tampering details by integrating a texture enhancement module. In addition, the feature fusion is optimized by combining the strategies of Spatial Weighting and Cross Resolution Weighting, and a new loss function W_Arcloss is adopted, which significantly improves the model performance in complex tasks of tamper detection. On datasets such as CASIA, Columbia, COVERAGE and NIST16, the detection accuracy of this model has improved by an average of 6.5% and 0.8% in comparison with the PSCC⁃Net and HIFI⁃Net models, respectively, and its generalization ability has been improved. These results demonstrate the effectiveness and robustness of the model in processing multiple types of tampering, which provides a new perspective of research and technical means for the field of image tampering detection and localization.
Keywords: image tampering detection; deep learning; multi⁃branch HRNet; texture enhancement module; Spatial Weighting; Cross Resolution Weighting; W_Arcloss
0" 引" 言
在数字化时代,图像篡改技术快速发展,对图像真实性构成挑战。社交媒体虚假信息[1]和操纵图像造成公共秩序混乱[2]等问题引起关注。因此,开发高效、准确的图像篡改检测技术成为计算机视觉领域的重要课题。
传统图像篡改包括复制移动[3]、拼接[4]和移除[5]等。近年来,基于深度学习的DeepFake[6⁃7]和GAN[8]等技术生成的虚假图像更难检测。篡改方式多样,但现有检测方法通常只适用于特定类型的篡改。
针对深度学习伪造图像(如DeepFake和GAN),出现了一些检测方法。文献[9]提出ManTra⁃Net,一个全卷积网络提取操纵特征和捕捉异常,但未充分利用图像块间的空间关系。另外,文献[10]提出了SPAN(Spatial Pyramid Attention Network),通过空间金字塔注意力模块建立多尺度的像素级空间关系,虽然尝试利用空间信息,但其注意力机制仍基于单个像素,未能很好地捕捉像素之间的相关性。文献[11]提出了PSCC⁃Net,利用密集交叉连接融合不同尺度特征,从粗到细生成操纵掩码预测,展现出不错的鲁棒性,但该方法使用标准卷积操作,难以建模长范围上下文依赖。文献[12]则引入Transformer的自注意力机制,提出ObjectFormer,虽性能不错,但在无明显对象结构的篡改检测中可能受影响,难以深挖篡改属性和建立伪造像素的空间联系。文献[13]则提出HiFi⁃Net,从层次化细粒度分类出发,虽检测效果不错,但在浅层篡改细节捕捉和不同分辨率图像的权重处理上存在不足。
综上所述,近年来深度学习篡改检测方法虽有进展,但存在问题,如模型多针对单一篡改方式,难以应对实际场景;难以捕捉深度伪造图像的深层次痕迹;多数模型未能有效建模图像空间位置相关性,限制了检测能力。鉴于此,本文提出基于多分支HRNet的图像篡改检测与定位模型,具有以下三个创新点。
1) 提出了DuaTex_Extractor特征抽取器,通过图像频率域和颜色域抽取特征,并通过纹理增强模块提升对纹理的感知,增强对细微篡改特征的捕捉,提高复杂场景的检测精度。
2) 设计了HRWFuse⁃Net,在传统HRNet[14]结构上融合Spatial Weighting与Cross Resolution Weighting策略,通过加权融合不同分辨率下的特征以及空间位置信息,用于捕获空间和通道相关性,提升对篡改区域的定位精确性。
3) 提出W_Arcloss优化损失函数,使模型在训练过程中更加注重区分篡改区域与真实区域之间的差异,进一步提高识别篡改图像的准确率。
本文在CASIA、Columbia、COVERAGE和NIST16等多个公认的数据集上进行了广泛的实验,实验结果表明,与现有的基线模型相比,本文模型在[F1]分数和AUC值上分别提高了0.8%和0.1%。这些成果不仅证明了模型在处理多种篡改类型时的有效性和鲁棒性,而且为图像篡改检测与定位领域提供了一种新的解决方案。
1" 基于多分支HRNet的图像篡改检测与定位模型
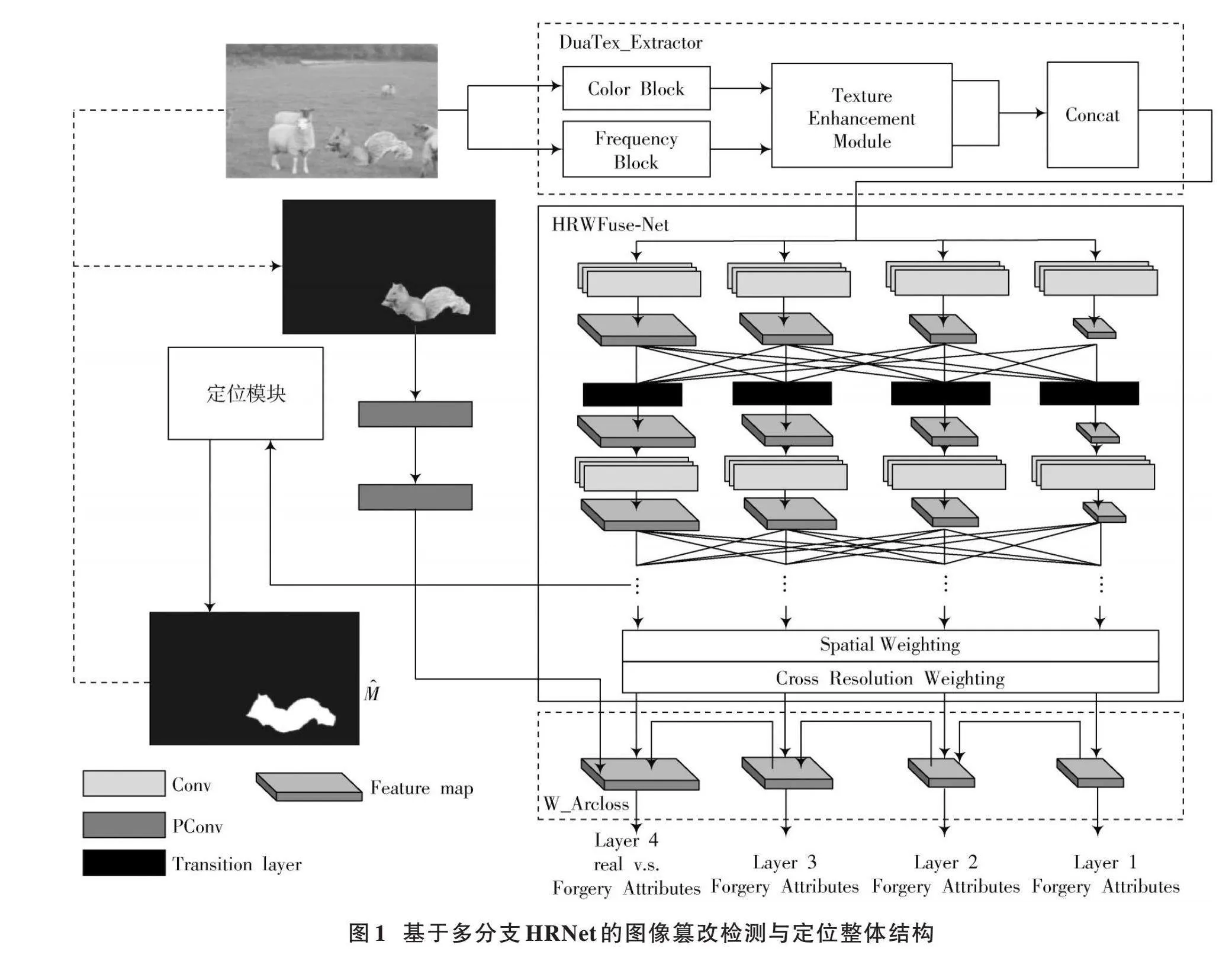
本文任务是检测可疑图像是否被篡改,并定位篡改区域。采用的多分支HRNet模型由DuaTex_Extractor、HRWFuse⁃Net网络、定位模块和分类模块构成,具体结构如图1所示。
设输入图像的尺寸为[H×W×C],[H]、[W]、[C]分别表示输入图像的长、宽和通道数。输入图像首先通过DuaTex_Extractor在频域和颜色域提取特征,提取后的特征各自经纹理增强模块(Texture Enhancement Module)进行纹理增强,使得模型能更准确地识别和理解图像的篡改细节特性,而后进行特征融合,融合后的特征输入HRWFuse⁃Net网络。定位模块通过直接依赖于HRWFuse⁃Net最高分辨率分支(即[L4])的特征输出生成二元掩码[M],二元掩码(Binary Mask)[M]与输入图像叠加得到掩码图像[Xmask],通过两层PConv后进入分类模块得到分类结果。
1.1" DuaTex_Extractor
针对现有模型难以捕捉深层次伪造痕迹和建模图像空间相关性的问题,本文提出DuaTex_Extractor特征提取器。该提取器从频域和颜色域捕捉分析篡改痕迹。该设计参考了文献[15],利用图像生成伪影可存在于RGB和频域的特点。篡改会在图像边缘留下不连续痕迹,本文采用高斯拉普拉斯(Laplacian of Gaussian, LoG)[16]滤波器增强边缘,捕捉伪造细节,专注分析异常高频模式或噪声,有效检测先进模型产生的篡改。
颜色域分支深入挖掘图像的颜色信息,包括色彩分布、饱和度变化等,这对于识别那些通过色彩调整进行掩饰的篡改区域至关重要。
此外,频域和颜色域分支抽取的特征会各自进入纹理增强模块。
图2是纹理增强模块的结构图。纹理增强模块旨在提升模型对篡改区域细节特征的敏感度,特别是伪造纹理细节。模块采用注意力机制使模型聚焦潜在篡改区域,自动检测并强调异常纹理特征。训练时重点关注这些区域,提高定位和识别篡改的准确性。
首先用3×3卷积层提取基本特征,然后1×1卷积核产生注意力图,以识别和强调可能篡改的区域。而后注意力图作为加权因子与原特征图相乘,使模型专注于可能含篡改痕迹的区域。接着,模块引入5×5卷积核的纹理增强层(Conv0)广泛捕捉上下文,识别异常纹理。之后,特征通过3×3卷积层(Conv1、Conv2、Conv3)增强,每层后接批量归一化和ReLU激活。在这个过程中,每个纹理增强层输出既进入下一层,也与之前层输出融合,确保网络深入时考虑更多纹理信息。例如,feature_maps1是feature_maps0和Conv1输出的融合,同样,feature_maps2和feature_maps3也是累积结果。最终的1×1卷积层整合所有特征,提供全面的篡改特征表示。
纹理增强模块结合频域和颜色域特征,通过注意力机制提高对篡改区域的识别敏感度。频域分支的LoG滤波器捕捉高频变化,如边缘不连续,与注意力加权特征结合,精确描绘篡改轮廓。颜色域分支分析色彩分布和饱和度变化,识别颜色调整异常,纹理增强后,颜色域信息强化,尤其在篡改区域纹理细节上,揭示掩饰的篡改行为。
1.2" HRWFuse⁃Net
为了在细粒度层次上检测伪造属性,设计了HRWFuse⁃Net,以HRNet作为基础框架,因其在保持高分辨率特征的同时,通过多分辨率并行结构提取丰富的上下文信息,对精确定位篡改区域至关重要。HRNet内部并行处理不同分辨率信息,确保特征丰富连贯,使模型同时观察细节和整体,在细粒度层次检测伪造特征。
然后通过Spatial Weighting和Cross Resolution Weighting两种策略对特征进行加权。
Spatial Weighting侧重于强化每个通道内的关键特征,关注局部区域的精确性。如式(1)所示,通过全局平均池化捕获通道的全局统计信息,而后通过一对1×1的卷积层和ReLU激活,将这些信息映射到一个较小的维度空间并重新投影回原始通道数量,通过sigmoid激活函数产生的空间权重图与输入特征图逐像素相乘,增强了对关键区域的关注,同时抑制了不太相关的区域。Spatial Weighting生成了一个按通道分的注意力图。这个注意力图被应用到输入的特征图上,细化模型焦点,以强调与伪造检测相关特征,空间加权确保模型优先考虑潜在操作区域。
[FLSP_W=FL⊙σConv2ReLUConv1AvgPool(FL)]
(1)
与此同时,Cross Resolution Weighting确保了不同分辨率特征之间的有效融合,平衡了全局上下文和局部细节之间的关系。如式(2)所示,首先将来自不同分辨率流的特征图进行自适应池化,以匹配最低分辨率,然后,这些特征图在通道上被合并,并通过一个1×1的卷积层,以减少参数数量并学习跨尺度的特征表示。经过ReLU激活和第二个1×1的卷积层,生成通道级的权重。最后,通过sigmoid函数将这些权重标准化,然后将它们应用到对应的特征图上,每个特征图都根据其分辨率大小通过最近邻插值被放大到原始尺寸。通过将来自所有分辨率的特征图聚合和加权,然后再重新分配回各自的分辨率流,确保模型在每个尺度上都有最适宜的特征表征。
[FLCR_W=FLUpsampleσConv2ReLUConv1CatPool(FL)]
(2)
二者共同为HRNet提供了全面的权重调整能力,不仅保留了高分辨率细节信息,同时也利用了低分辨率的上下文信息,为图像篡改检测带来了更细致的层次分析能力,允许在不牺牲高层次特征的情况下进行低层次的精准分类。
1.3" 定位模块
定位模块的目的是利用高分辨率特征输出([L4])生成二元掩码[M],以精确标识图像中的篡改区域。二元掩码[M]被覆盖在输入图像上以产生一个掩蔽图像[Xmask],用以突出显示被篡改的区域。定位模块采用自注意力机制[17⁃18],使潜在的篡改区域更加突出。
此外,参照文献[15]的方法,本文采用度量学习目标函数来增强模型对真实和篡改像素之间差异的识别。具体地,基于训练集中所有真实图像的像素特征,计算出一个参考中心向量[c∈RD]。使用[F′ij∈RD]表示最终掩码预测层的第[ij]个像素。因此定位损失[Lloc]为:
[Lloc=1HWi=1Hj=1WLFtij,Mij,c,τ] (3)
式中:
[L=F′ij-c2," " " Mij realmax0,τ-F′ij-c2," " " "Mij" forged]
与文献[15,19]的方法不完全相同,在特征空间中使用了预定的边界[τ],用于控制真实像素和篡改像素之间的最小特征距离。式(3)中,[Mij]表示在掩码图像[M]的[ij]位置像素。当[Mij]为真时,使真实像素的特征向量朝着参考中心收敛;当[Mij]为假时,强制篡改像素的特征向量与参考中心保持至少[τ]的距离。这种机制在训练中不断拉大两类像素间的特征距离,提高了模型的分类准确性,是生成高质量的掩蔽图[Xmask]的关键。
为了最大程度地利用掩蔽图像[Xmask],使用PConv(Partial Convolution Operato)[20]处理。PConv的卷积核经过改动后仅适用于未被掩盖的像素,从而确保特征图专注于被操作的像素。
1.4" 分类模块
二元掩码[M]不仅作为分类模块的前奏,也作为后续分类模块的重要先验。
采用式(4)掩码更新机制:
[M=1," " " " " "M≥00," " " " " otherwise] (4)
将掩码更新后的[M]与HRWFuse⁃Net不同分支([L1]~[L4])的输出特征一起传入分类模块。分类模块采用层次化方法预测伪造属性,学习不同属性间的依赖关系。以下是各层的属性分类。
[L1]:全局篡改检测,判断整张图像是否遭到篡改。利用HRWFuse⁃Net提供的高分辨率特征图,模型能在全局层面捕捉微妙的篡改迹象,如整体色调、纹理或边缘的异常变化。
[L2]:篡改类型区分,确定是完全合成(全图篡改),还是局部篡改(对象插入、移除或编辑),深入分析特定区域。
[L3]:篡改手法识别,识别用于篡改的具体技术或工具,如基于GAN的方法、克隆工具或图像编辑软件。
[L4]:细化篡改特征,关注篡改区域的纹理、边缘和噪点等细节。
层次化路径预测的原理如下。
给定图像[X],将分支[Lb]的输出对数和预测概率分别记为[Lb(X)]和[pybX],那么:
[pybX=softmaxLb(X)⊙1+pyb-1X] (5)
在计算分支[Lb]的概率[pybX]时,会结合前一个分支的预测概率,即[pyb-1X]与当前分支的输出对数logits[Lb(X)]来计算。
通过这一系列层次化的细粒度分类步骤,实现了对篡改图像的全面识别和定位,每一层级的分类都为最终的判定提供了支持。
1.5" W_Arcloss
为了增强模型的区分能力,本文基于ArcFaceloss[21]引入了基于样本难度和类别特异性的动态权重,创造W_Arcloss损失函数。具体见式(6):
[LW_Arc=-1Ni=1Nwi⋅loges⋅wc⋅cosθyi+mes⋅wc⋅cosθyi+m+j=1,j≠yines⋅cosθj] (6)
式中:[N]是批次中样本的总数;[wi]是第[i]个样本的权重,反映了样本的难度或对模型训练的重要性;[wc]是对应于样本真实类别[yi]的类别权重;[s]是缩放因子,用于调整特征向量的范数;[m]是加入到类别间角度的边界间隔,用于增加类别间的可分性;[θyi]是样本[i]的特征向量和其对应的类别权重[wyi]之间的角度。
W_Arcloss通过在特征空间中加入角度边界[m],显著增加了不同篡改类型之间的区分度。样本权重和类别权重使模型能针对难度不同的样本和重要性不同的类别进行优化,确保模型更关注提高整体性能最关键的部分。通过动态调整损失,W_Arcloss有助于模型在[L1]~[L4]分支上对具体篡改行为的细粒度分类任务实现更高的准确率。W_Arcloss通过角度间隔和权重调整,促进模型学习到的特征表示在类内紧凑、类间分离的同时,还具有高度的鲁棒性。这意味着即使在图像质量变化或篡改技术微妙变化的情况下,模型也能保持高效的分类性能。
2" 实验部分
2.1" 数据集和评价指标
模型训练使用的数据集是HIFI⁃IFDL[13]数据集。HIFI⁃IFDL数据集包含多张真实图像,以及通过先进的生成对抗网络(GAN),例如StyleGAN[22]、StarGAN⁃v2[23]和基于自动编码器的方法生成的伪造图像,以及使用其他图像编辑软件(如Photoshop)进行的手工篡改图像。具体数据集的构成和图像数量参考HIFI⁃IFDL[13]论文介绍。为了评估模型性能,使用了5个主流的篡改检测数据集进行测试,分别为:CASIA[24]、Columbia[25]、COVERAGE[26]以及NIST16[27]和IMD2020[28]。
评估指标使用了像素级曲线下面积(Area Under ROC Curve, AUC)、[F1]分数([F1]⁃score)。
[F1]分数的计算方式如式(7)所示:
[F1=2×TP2×TP+FN+FP] (7)
式中:TP表示模型预测正确的篡改像素点数目;FP表示模型预测错误的篡改像素点数目;FN表示模型预测错误的载体像素点数目。
2.2" 实验设置
本文的实验环境为:Python=3.7.16,PyTorch=1.11.0,Torchvision=0.12.0。使用的显卡为RTX 4090,采用Adam优化器降低网络损失,并加入学习率衰减使后期迭代不再需要手动调整,初始化学习率为0.000 1,一共训练了150个迭代次数(epoch)、批次大小(batchsize)为16。
2.3" 实验结果
篡改定位比二进制检测更具挑战性,因为它需要模型捕获更精细的篡改特征。沿用SPAN和PSCCNet的模型评估实验,将本文模型与其他最先进的篡改定位方法在两种设置下进行比较。
1) 经hifi⁃ifdl进行训练后,在完整测试数据集上评估。
2) 在NIST16、Coverage和CASIA上微调预训练模型,再对其评估。
2.3.1" 图像篡改定位性能对比
1) 预训练模型评估
将多分支HRNet模型与MantraNet、SPAN和PSCCNet、Objectformer、HIFINet进行了比较,结果见表1。在表1中报告了AUC分数,可以观察到Objectformer在多数数据集上取得了最佳的定位性能。特别地,多分支HRNet模型在真实数据集IMD2020上达到了84.5%,比HIFINet提高了1.1%。这表明本文方法具有优越的捕获篡改特征的能力,并且可以很好地推广到高质量的篡改图像数据集。在Columbia数据集上,超SPAN 3.7%、Objectformer 1.8%,但低于PSCCNet 0.9%、HIFINet 1.1%,认为原因可能是他们的训练数据与Columbia的分布非常相似。
2) 微调模型评估
为了微调多分支HRNet,遵循了与文献[19⁃20,22]相同的设置进行公平比较。在NIST16、Coverage和CASIA上微调预训练模型,微调后的模型性能对比如表2所示。本文方法在平均AUC和[F1]上取得最佳性能。具体来说,仅在NIST16上稍显落后。
2.3.2" 图像篡改检测性能对比
各模型篡改检测的性能如表3所示。
结果表明,本文模型取得了比HIFINet更好的性能,AUC为99.5%,[F1]为97.8%,这证明了本文方法捕捉伪造痕迹的有效性。
2.4" 可视化
图3为多分支HRNet模型与SPAN以及HIFINet预测图像可视化对比结果。在可视化时,三个网络都是以0.5为阈值,超过0.5则认为该像素被篡改,否则认为该像素未被篡改。
如图3所示,多分支HRNet模型相比于SPAN及HIFINet在定位篡改区域上表现得更加准确。这说明了多分支HRNet模型相较于其他模型具有更好的检测及定位性能。
2.5" 消融实验
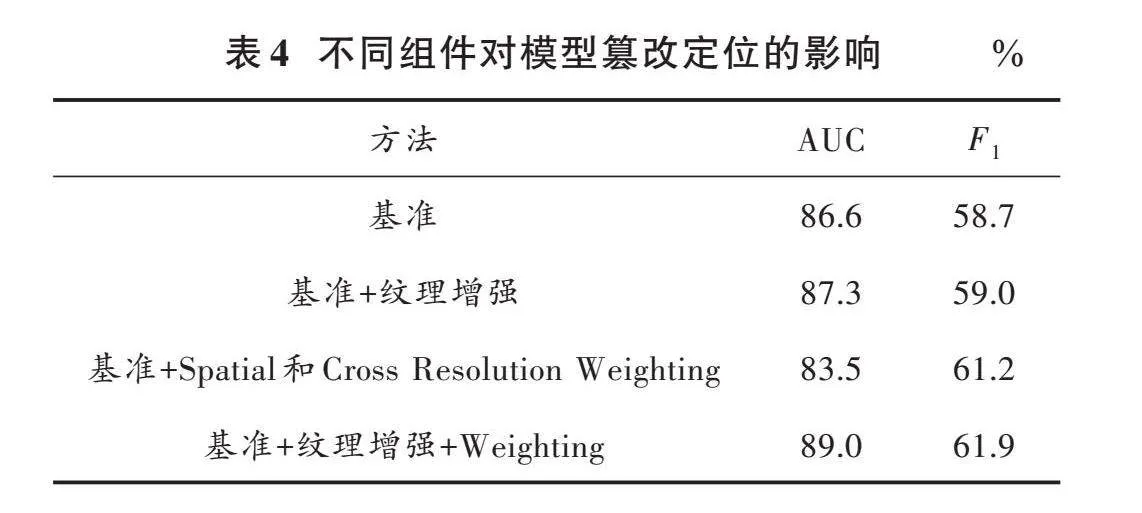
本节进行消融实验探究多分支HRNet模型中关键组件对篡改检测与定位性能的影响。表4呈现了在CASIA数据集上进行篡改定位任务时,不同模块和策略添加或移除后模型性能的变化。
首先关注纹理增强模块对性能的提升。基准模型引入纹理增强模块后,AUC和[F1]值分别提升0.7%和0.3%,证实了其提取异常篡改特征的重要性。
接下来考察Spatial及Cross Resolution Weighting策略加入的影响。实验显示,AUC从基准的86.6%降至83.5%,[F1]值反而从58.7%增至61.2%,猜测可能的原因是过度聚焦于特定区域或过度依赖伪造痕迹,忽略了全局语义。
但当它们与纹理增强模块共同使用时,AUC和[F1]值分别从87.3%和59.0%提升至89.0%和61.9%。这一明显改善印证了纹理增强模块与这两种权重策略之间存在协同效应,这意味着Spatial Weighting和Cross Resolution Weighting策略在确保对关键特征有效突出的同时,又与纹理增强模块互补,共同促进了对篡改区域的识别和定位精度。
表5呈现了在CASIA数据集上进行篡改检测任务时,随着W_Arcloss的加入带来的性能变化情况。
当单独加入W_Arcloss时,模型在CASIA数据集上的篡改检测性能指标[F1]提高了0.4%,尽管提升幅度相对较小,但也证实了W_Arcloss在优化模型对篡改区域与正常区域之间差异的区分能力方面起到了积极的作用。
3" 结" 论
在当今信息时代,图像内容安全成为重要议题,图像篡改检测成为维护内容真实性的关键手段。然而,过去工作常忽视现实中无法预知图像的具体篡改方式这一困难。
因此,本文提出了多分支HRNet图像篡改检测模型,能够对多种篡改方式进行检测。该模型集成了纹理增强模块DuaTex_Extractor,能更好地挖掘图像中细微的篡改特征。HRWFuse⁃Net中的Weighting策略优化了特征融合,使模型能更精确地定位篡改区域。本文还引入了W_Arcloss损失函数,通过基于样本难度和类别特异性的动态权重,显著提高了模型区分真实与篡改区域的能力。
实验结果表明,与现有基线模型相比,本文模型检测准确度平均提升了6.5%和0.8%,并通过消融实验证明了每个模块的必要性和贡献度。未来工作将围绕轻量化网络设计和更高效的特征提取融合策略,使模型能在资源受限环境中保持高性能。
注:本文通讯作者为谭平。
参考文献
[1] 廖汨,刘畅.广西柳州一男子P图篡改核酸检测结果被查[EB/OL].[2022⁃02⁃12]. https://www.chinanews.com.cn/sh/2022/02⁃12/9674485.shtml.
[2] 黄成.南京禄口机场要求成都旅客“原路返回”?机场回应:谣言![EB/OL].[2020⁃12⁃12]. https://m.news.cctv.com/2020/12/12/ARTIu2yVmUDoFiCpmRumHhaG201212.shtml.
[3] 赵鸿图,周秋豪.基于改进显著图和局部特征匹配的copy⁃move窜改检测[J].计算机应用研究,2023,40(9):2838⁃2844.
[4] HUH M, LIU A, OWENS A, et al. Fighting fake news: Image splice detection via learned self⁃consistency [C]// Proceedings of European Conference on Computer Vision. Heidelberg: Springer, 2018: 106⁃124.
[5] ZHU X S, QIAN Y J, ZHAO X F, et al. A deep learning approach to patch⁃based image inpainting forensics [J]. Signal processing: Image communication, 2018, 67: 90⁃99.
[6] TOLOSANA R, VERA⁃RODRIGUEZ R, FIERREZ J, et al. Deepfakes and beyond: A survey of face manipulation and fake detection [J]. Information fusion, 2020, 64: 131⁃148.
[7] DANG H, LIU F, STEHOUWER J, et al. On the detection of digital face manipulation [C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2020: 5780⁃5789.
[8] GOODFELLOW I J, POUGET⁃ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014. [S.l.: s.n.], 2014: 2672⁃2680.
[9] WU Y, ABDALMAGEED W, NATARAJAN P. ManTra⁃Net: Manipulation tracing network for detection and localization of image forgeries with anomalous features [C]// Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2019: 9543⁃9552.
[10] HU X F, ZHANG Z H, JIANG Z Y, et al. SPAN: Spatial pyramid attention network for image manipulation localization [C]// Proceedings of 16th European Conference on Computer Vision. [S.l.: s.n.], 2020: 312⁃328.
[11] LIU X H, LIU Y J, CHEN J, et al. PSCC⁃Net: Progressive spatio⁃channel correlation network for image manipulation detection and localization [J]. IEEE transactions on circuits and systems for video technology (TCSVT), 2022, 32(11): 7505⁃7517.
[12] WANG J K, WU Z X, CHEN J J, et al. ObjectFormer for image manipulation detection and localization [EB/OL]. [2022⁃03⁃29]. https://arxiv.org/abs/2203.14681.
[13] GUO X, LIU X H, REN Z Y, et al. Hierarchical fine⁃grained image forgery detection and localization [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2023: 3155⁃3165.
[14] SUN K, XIAO B, LIU D, et al. Deep high⁃resolution representation learning for human pose estimation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 5693⁃5703.
[15] MASI I, KILLEKAR A, MASCARENHAS R M, et al. Two⁃branch recurrent network for isolating deepfakes in videos [C]// Proceedings of the European Conference on Computer Vision (ECCV). Heidelberg: Springer, 2020: 667⁃684.
[16] BURT P J, ADELSON E H. The Laplacian pyramid as a compact image code [J]. IEEE transactions on communications, 1983, 31(4): 532⁃540.
[17] WANG X L, GIRSHICK R B, GUPTA A, et al. Non⁃local neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2018: 7794⁃7803.
[18] ZHANG H, GOODFELLOW I J, METAXAS D N, et al. Self⁃attention generative adversarial networks [C]// Proceedings of the International Conference on Machine Learning (ICML). New York: PMLR, 2019: 7354⁃7363.
[19] RUFF L, GORNITZ N, DEECKE L, et al. Deep one⁃class classification [C]// Proceedings of the International Conference on Machine Learning (ICML). New York: PMLR, 2018: 4390⁃4399.
[20] LIU G L, REDA F A, SHIH K J, et al. Image inpainting for irregular holes using partial convolutions [C]// Proceedings of the European Conference on Computer Vision (ECCV). Heidelberg: Springer, 2018: 89⁃105.
[21] DENG J K, GUO J, XUE N N, et al. ArcFace: Additive angular margin loss for deep face recognition [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 4690⁃4699.
[22] TERO K, SAMULI L, TIMO A. A style⁃based generator architecture for generative adversarial networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2019: 4217⁃4228.
[23] CHOI Y, UH Y, YOO J, et al. StarGAN v2: Diverse image synthesis for multiple domains [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE, 2020: 8185⁃8194.
[24] DONG J, WANG W, TAN T N. CASIA image tampering detection evaluation database [C]// 2013 IEEE China Summit and International Conference on Signal and Information Processing. New York: IEEE, 2013: 422⁃426.
[25] NG T T, HSU J, CHANG S F. Columbia image splicing detection evaluation dataset [EB/OL]. [2007⁃02⁃14]. https://www.ee.columbia.edu/ln/dvmm/downloads/AuthSplicedDataSet/detailed.htm.
[26] WEN B H, ZHU Y, SUBRAMANIAN R, et al. COVERAGE: A novel database for copy⁃move forgery detection [C]// 2016 IEEE International Conference on Image Processing. New York: IEEE, 2016: 161⁃165.
[27] NIST. Nist nimble 2016 datasets [EB/OL]. [2016⁃05⁃28]. https://www.nist.gov/sites/default/files/documents/2016/11/30/should i believe or not.pdf.
[28] NOVOZAMSKY A, MAHDIAN B, SAIC S. IMD2020: A large⁃scale annotated dataset tailored for detecting manipulated images [C]// IEEE Winter Applications of Computer Vision Workshops. New York: IEEE, 2020: 71⁃80.
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
软件(2020年3期)2020-04-20 01:45:18
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
学生天地(2019年28期)2019-08-25 08:50:54
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
数学物理学报(2018年1期)2018-03-26 08:16:36
Coco薇(2017年8期)2017-08-03 15:23:38
Coco薇(2015年5期)2016-03-29 23:22:15
CHIP新电脑(2016年3期)2016-03-10 14:22:03
