
基于阈值的动态交互在公共物品博弈中的合作演化
2025-01-22 00:00:00许向阳刘亚捷马金龙
河北科技大学学报 2025年1期



摘 要:为了分析带有惩罚机制的公共物品博弈模型下交互规模对合作水平和种群收益的影响,通过蒙特卡洛仿真,结合现实复杂的交互环境特征,提出了一种基于合作阈值的动态交互域模型。首先,根据博弈圈内合作者数目不同的特点设计了基于合作阈值的动态交互规则;其次,对加入交互域更新规则后公共物品博弈模型中的合作水平、种群收益、交互域范围等进行了仿真实验,观测其演化过程;最后,通过对比不同参数值下新旧模型对种群合作演化的影响,讨论了该机制作用的原理和效果。通过大量的仿真实验,验证了较高的合作阈值和增加交互域的变化强度都能更有效地促进合作并提高种群的平均收益。该模型能有效提高合作水平和群体收益,从而为研究动态交互环境下的公共物品博弈提供一种新的视角。
关键词:系统建模;公共物品博弈;合作阈值;交互域;收益;合作
中图分类号:TP301.6;F224.32
文献标识码:A"" DOI:10.7535/hbkd.2025yx01006
收稿日期:2024-07-03;修回日期:2024-10-25;责任编辑:冯民
基金项目:
国家自然科学基金(71871233)
第一作者简介:
许向阳(1967—),男,河北石家庄人,副教授,硕士,主要从事无线自组网、卫星通信方面的研究。
通信作者:
马金龙,副教授。E-mail:mzjinlong@163.com
Cooperation evolution of dynamic interaction based on
threshold in public goods game
XU Xiangyang LIU Yajie MA Jinlong 2
(1.School of Information Science and Engineering, Hebei University of Science and Technology,
Shijiazhuang,Hebei 050018, China;
2.Hebei Technology Innovation Center of Intelligent IoT, Shijiazhuang,Hebei 050018, China)
Abstract:To analyze the impact of interaction size on cooperation level and population average payoff in the public goods game with punishment, by combining Monte Carlo simulation with the characteristics of real complex interaction environments, a dynamic interaction domain model was proposed based on a cooperation threshold. First, a dynamic interaction rule based on the cooperation threshold is designed, taking into account the characteristics of different numbers of cooperators in the game group. Secondly, simulation experiments are conducted to observe the evolution of cooperation level, population payoff, and interaction domain range in the public goods game model after incorporating the interaction domain update rule. Finally, we compare the effects of the traditional and new models on the evolution of cooperation under different parameter values and discuss the principles and effectiveness of the model. Extensive simulation experiments have validated that increasing the cooperation threshold or the variation parameter more efficaciously fosters cooperation and enhances the population's average payoff.This provides a new perspective for the study of public goods game in dynamic interactive environment.
Keywords:system modeling;the public goods game; cooperation threshold; interaction domain; payoff; cooperation
公共物品博弈(public goods game,PGG)是描述多个参与者共同使用有限资源的特殊非零和博弈。背叛策略广泛传播会造成公地悲剧,比如大气污染治理、公共交通拥堵等。但是,现实中也存在合作[1]与公平使集体利益最大化。因此,如何解决公共物品博弈模型中个人与集体之间的利益矛盾,促进合作行为的涌现与维持,成为众多学者研究的重点[3-4]。
已有研究中,学者们在公共物品博弈模型框架下,提出了许多诱导合作涌现与维持卓有成效的机制,比如惩罚[5-8]、激励[9-11]、驱逐[12-13]、异质性投资[14-16]、声誉[17-20]和自愿参与[21]等。而对于惩罚机制[22-23]下公共物品博弈研究,学者大多并未考虑种群结构和邻域多样性对个体之间相互作用的影响。大量证据表明,现实世界的相互作用结构并非是混合良好或者规则的,这种结构上的多样性深刻影响着合作演化。SHANG等[24]将同质邻域改为非均匀邻域,发现合作者更易保持策略并稳定。LI等[25]考虑了不同邻域类型和规模,证明更大的交互域和更小的学习邻域都将提高合作簇稳定性。XU等[26]揭示了动态变化种群中不同团体规模促进合作涌现的机理。ZHU等[27]证明了邻域大小能显著影响合作策略的传播。KIMMEL等[28]发现无论邻域大小是随机变化还是策略依赖变化都能通过破坏单态的稳定性而有利于共存。本文以冯·诺依曼邻域为研究对象,对带有惩罚机制的公共物品博弈模型中交互域对合作的影响进行了深入研究。
1 基于合作阈值的动态交互域模型
本文考虑了在L×L(L= 99)具有周期性边界条件的规则网络上,以冯·诺依曼邻域为例进行的空间公共物品博弈(spatial public goods game,SPGG),每位玩家占据一个节点。
1.1 惩罚机制下的SPGG
最初,网络中的每位玩家以相同概率选择合作者(cooperators,C)、背叛者(defectors,D)或惩罚者(punishing cooperators,PC)中的任一策略。在惩罚机制下,每个合作者或惩罚者都会向公共池贡献一个单位的资源,而背叛者却不贡献任何资源。惩罚者需要对投资圈内的所有背叛者施加成本进行惩罚,背叛者也因被惩罚需要缴纳罚金。以冯·诺依曼邻域为例,每位玩家通过参与以交互邻居或自己为中心的共G(5≥G≥2)轮博弈来积累收益。因此,当玩家选定某种策略,玩家i在第g组中的收益为πgi,如式(1)所示;玩家i逐一参加以自己和交互邻居为中心的博弈圈后,获得最终累积收益πi,如式(2)所示。
πgi=
r(ngC+ngPC)
k(i)g+1-"""""" if Si(t)=C,
r(ngC+ngPC)k(i)g+1-
βngPCk(i)g,"" if
Si(t)=D,
r(ngC+ngPC)k(i)g+1-1-γngDk(i)g," if Si(t)=PC,
(1)
πi=∑g∈Ωiπgi,(2)
式中:ngC,ngD,ngPC分别代表组g中采取合作、背叛或者惩罚策略的玩家数目;r表示增强因子;Ωi表示由i和选择i作为其交互邻居的玩家组成的集合;β和γ分别表示背叛者缴纳的罚金和惩罚者的惩罚成本的乘法系数。为了与文献[29]中的假设保持一致,这里β和γ分别设为0.3和0.2。每个背叛者会被要求向组内的每个惩罚者缴纳β/k(i)g的罚款,而每个惩罚者将为每个被惩罚的背叛者承担γ/k(i)g的惩罚成本。
1.2 基于合作阈值的动态交互范围
在本文提出的模型中,假设每个玩家的互动邻居数目不固定,这对应了现实中不同特性个体交互的异质性社会范围[30-31]。也就是说,每个玩家的博弈对手是动态变化的。而事实上,由目标玩家及其邻居组成的群体可能是分离的群体[32],也可能是由网络组成的群体。这些群体也可以是静态的,如网格或不随时间演变的网络,也可以是动态的[33-34],随着群体的形成和解散而变化。以交互域中动态变化的规模和成员展开仿真研究,可以为应对现实复杂的博弈环境提供思路。
假设玩家i交互范围变化的概率主要由当前它自身及交互域中合作者数目决定。为了探究合作者数目如何影响交互范围的变化,引入有关玩家自身及交互域内合作者总数的阈值Z,记为合作阈值。若玩家自身及交互域内合作者总数大于或者等于阈值Z,则将保持原有的交互邻居数目;如果合作者总数低于阈值Z,玩家在下一轮博弈开始前,将有概率改变自己的交互邻居数目。当前博弈组(玩家自身加交互邻居)中合作者的数目nC对玩家是否更改交互范围的概率的影响,可以写成等式,如式(3)所示。
fi=
Z-nCZ ," if Z≥nC,
0,"""" if Zlt;nC。 (3)
1.3 交互邻居和策略更新规则
如果满足了交互范围更新的可能性,那么对于在t时刻采用不同策略的参与者在(t+1)时刻的交互范围变化如式(4)所示。
k(t+1)=
k(t)C-l(n(t)D-n(t)PC)," if Si
(t)=C,
k(t)D-l(n(t)C+n(t)PC)," if Si(t)=D,
k(t)PC+l(n(t)C+n(t)D)," if Si
(t)=PC,(4)
式中:k(t)C、k(t)D、k(t)PC分别表示玩家i在t时刻,采用C、D、PC任意一种策略时的交互范围值;
n(t)C、n(t)D、n(t)PC分别表示在t时刻,玩家i与交互域内的邻居中分别采取3种不同策略的玩家总量;变化参数l代表交互范围变化的波动程度,l越大,代表交互范围改变的震荡程度越高,l越小,则交互域的波动越小,交互范围仅进行微调。在交互范围更新过程中,交互邻居数目遵守以下边界条件:如果
k(t+1)lt;0,则k(t+1)=0;如果k(t+1)gt; 则k(t+1)=4。当交互范围发生改变时,对应数目的交互邻居通过随机选择得到。
为了鼓励合作策略的传播,合作者不仅需要通过缩小交互域驱逐隐藏在当前投资圈中的背叛者,同时也会增大交互范围,让更多合作者与惩罚者参与到投资中。因此,这类玩家的交互域是动态增减的。但是背叛者只会对投资成果分割,却提供不了任何贡献,这类玩家的交互范围越小,种群中合作者收益更高,合作水平也更高。因此,背叛者的交互范围要不断减少。而对于惩罚者来说,越来越大的交互域一方面有利于更快察觉邻域中的背叛者,对背叛行为进行处罚,从另一方面来说,这也能够充分发挥合作性的惩罚者的合作功能,提供更高的种群收益。
每轮博弈后,每位玩家除了需要更新自己的交互域,还需要对策略进行更新。策略更新规则有很多,比如交互网络更新[35]、与强化学习结合的策略更新[36]都能有效选择策略,本研究采用费米更新规则。玩家i模仿邻居j的策略时,会比较自身所获得的收益与邻居的收益,并以费米函数的形式计算概率P从而选择策略更新:
P(Sj→Si)=11+exp(-πj-πiκ) ,(5)
式中:πi和πj分别是玩家i和玩家j的累积收益;κ是噪音因子,用于量化个体的不理性程度。当κ→0时,只有当玩家j的收益更高时,玩家i才会确定性地模仿玩家j的策略;κ→∞表示完全随机模仿,即无论玩家j的收益如何,玩家i都以相同的概率维持或改变其当前策略。
本文重点研究了相互作用邻域的多样性对合作水平的综合影响。为了更好地呈现讨论结果,种群的合作水平定义如下:
ρC+PC=NC+NPCN,(6)
式中:ρC+PC为种群中合作者和惩罚者的比例;NC、NPC和N分别表示整个群体中合作者的数量、惩罚者的数量和群体的总规模。
2 实验结果及分析
在以下模拟中,实验在大小为L × L(L=99),具有周期边界条件的方格网络上通过蒙特卡洛仿真进行演化动力学分析。为了避免有限尺寸的效应,并使模拟结果更具准确性,MCS步长设为M=10 且取8次独立实验的平均值作为最终数据。
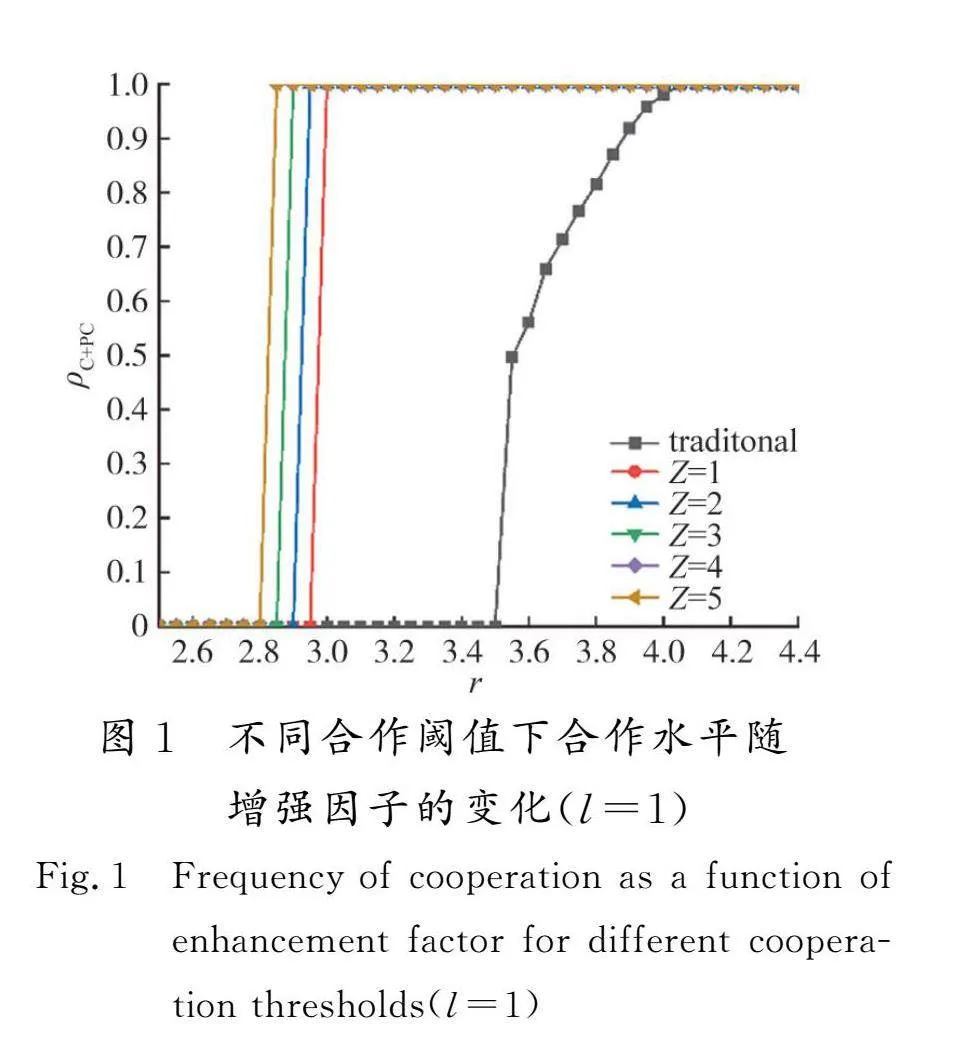
为了对比基于合作者数目的动态交互域模型与惩罚机制下的传统模型对合作水平的影响,图1依次展示了2种模型下合作水平ρC+PC随增强因子r变化的曲线。可以观察到,与传统模型相比,动态交互域模型中合作水平被极大促进。传统模型中的合作行为在r=3.5左右才开始涌现,而动态交互域模型中无论阈值Z如何取值,都能够比传统模型更快逆转全是背叛者的困境。这是因为动态交互域模型中的玩家都有着异质性的交互域结构,这种结构使得合作策略被快速传播,而传统模型下,所有玩家与冯·诺依曼邻域中4个邻居都产生交互,这种均匀的交互域导致合作策略的演化完全依赖网络互惠而不利于合作策略的扩散。还可以观察到,合作阈值从Z=1到Z=5逐渐增大时,合作开始涌现所需要的增强因子r越来越小,并且进入到ESS的速度越快。这意味着,只需要给予种群极少的资源,种群就能达到理想的状态。在种群中,Z值越大,意味着种群中的更多玩家需要不断调整自己的交互域,减少交互邻居中的背叛者。因此较高的阈值会更有益于抑制背叛行为。不难发现,在传统模型中,合作水平随着增强因子的变化经历了全背叛状态、背叛与合作共存的混合状态、全合作状态3个阶段。而动态交互域模型中却不存在背叛与合作共存的稳定状态。随着增强因子的增大,种群中的玩家从非合作的状态突然转变为合作状态。这说明合作水平在特定的增强因子临界点前后发生了突然的、不连续的一阶相变。且当l=1时(即l取最大值),随着合作阈值的增大,发生一阶相变所需要临界增强因子也越小,背叛者被驱除的速度越快。也就是说,在相同的增强因子下,该模型比传统模型实现了更高水平的合作。这是因为一旦引入动态交互域,背叛者会不断被种群驱逐,直到其交互域为0后进入稳态,背叛策略消失在种群中。
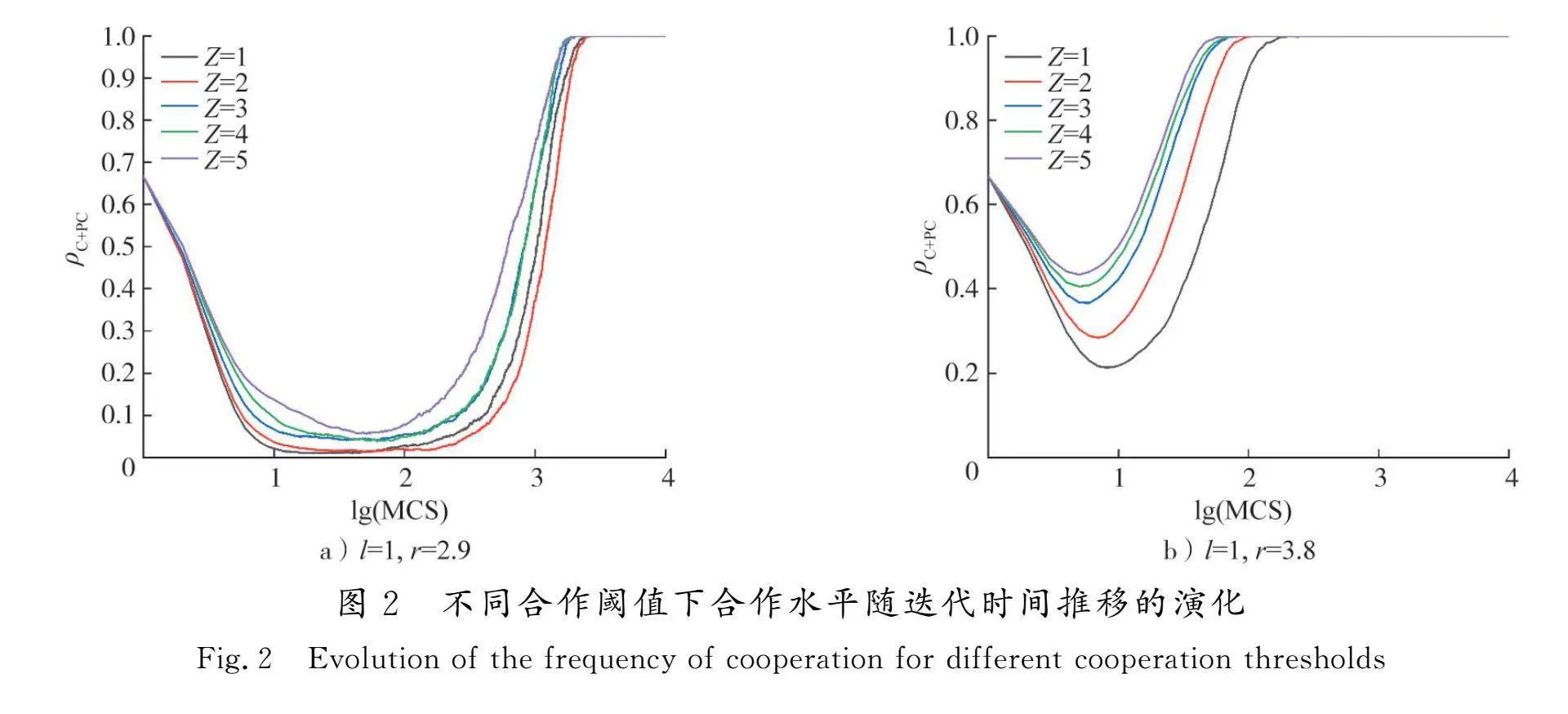
为了探索不同合作阈值Z的取值对合作演化的影响,图2展示了分别将增强因子r固定在2.9和3.8时,合作水平在不同合作阈值下随着时间如何变化。可以看出:合作水平随着博弈的进程经历了下降、上升和稳态3个阶段;随着合作阈值的提高,下降阶段时种群合作水平
ρC+PC的最低值会更高,演化稳态下达到全合作状态所需的时间也逐渐提高。当Z=2时,种群中的任意玩家只要在自己及交互域中至少存在2个合作者,就会保持当前的交互域,这样导致邻域中的背叛者没有机会通过动态交互域被排除,合作策略就无法被很好传递。而当Z=5时,玩家只有当交互域为4且自己和交互邻居全部为合作者时,才会停止对交互域的调整。也就是说,Z值越大,越多的背叛者会被排查出来,减少了合作者被大量背叛者肆意剥削的处境,实现合作策略的更快传播,这也说明了合作阈值对合作的促进效果是显著的。
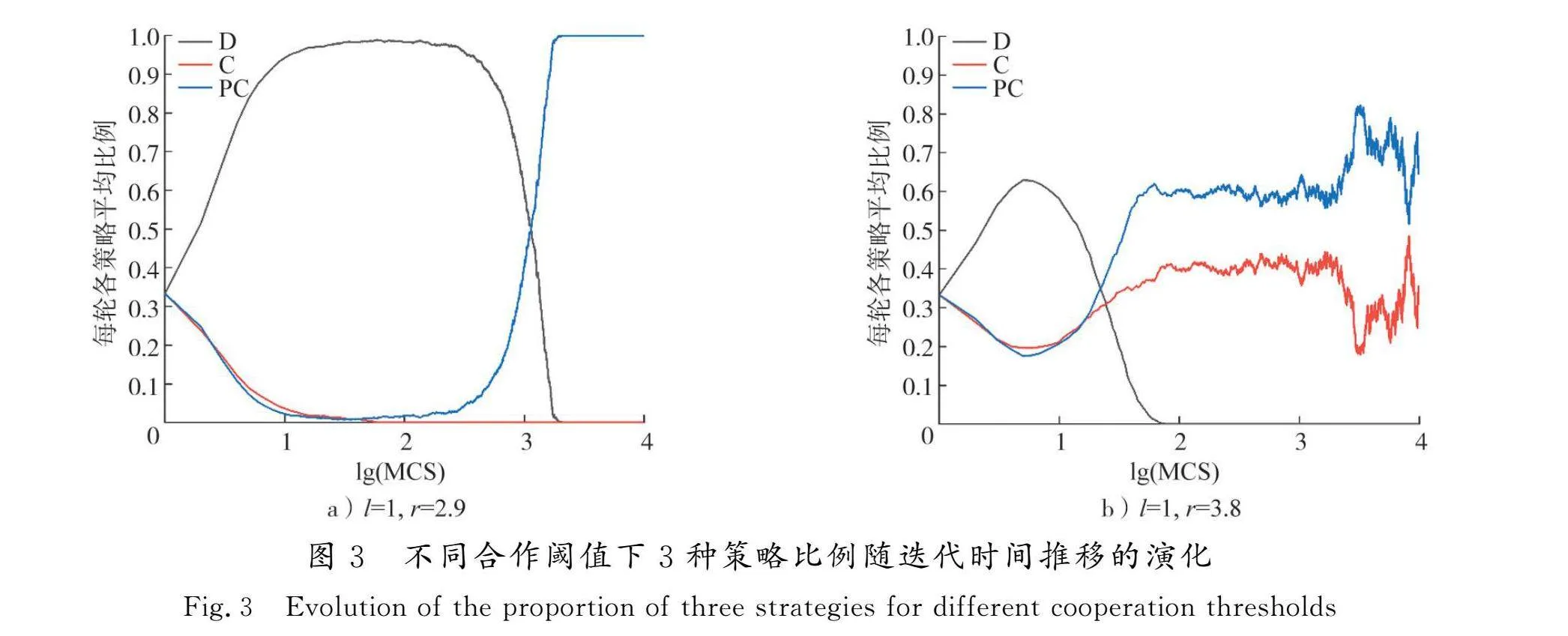
为了进一步解释合作策略、背叛策略和惩罚策略这3种策略在网络中如何演化,绘制了3种策略的微观动力学过程,如图3所示。初始时,3种策略在网络中是随机且均匀分布的,每个策略在网络中的比例均为1/3。当r=2.9、tlt;100时,合作者和惩罚者的比例开始迅速下降,背叛者的比例不断上升。背叛者不付出任何贡献却有着更高的收益,所以它们率先抢占了种群中的主动权,其他策略不断学习背叛策略,使背叛者几乎占据了整个网络。但惩罚者具有惩罚特性,比起合作者更能抵抗背叛者的入侵,惩罚者在t=100左右没有像合作者一样完全消失,而是维持在网络中。此时背叛者的数目达到顶峰,它们无法从同类中继续获利,因此收益极低。背叛策略的比例开始急速下降,惩罚策略可以通过惩罚背叛策略,令其缴纳罚款。越来越低的收益使得背叛者开始更新策略成为惩罚者。于是惩罚策略的比例开始不断蚕食背叛者,比例不断攀升。当t=1 000后不久,背叛者经历了一段急剧的减少后,最终在网络中完全消亡,惩罚策略占据整个种群。而r=3.8时,由于增强因子r足够大,合作者在背叛者急速上升阶段并未完全泯灭,而是与惩罚者一样,以一定的比例保持存活。当tgt;10时,背叛者的收益开始降低,惩罚者与背叛者之间发生“惩罚”斗争,合作者利用惩罚者的惩罚效果,比例开始有所上升。同时合作策略通过网络互惠性[37],不断扩张自己的合作簇,直至t=100,背叛者在与惩罚者的战斗中败下阵来,消失在种群中。此后,由于背叛策略的消失,合作者和惩罚者的收益公式变得相同,二者以对数粗化的形式在网络中存在[38]。
值得注意的是,即使引入了微小的合作阈值,也会使得种群的合作者和惩罚者在与背叛策略的斗争中产生巨大优势。为了探究这种现象的内在原因,图4给出合作阈值Z取不同值时,任意玩家自身及交互域中合作者数目的平均值随时间的变化。当r=2.9时,玩家自身及邻域中的合作者平均数目从初始的1.6迅速下降到0。合作阈值越小,平均合作者数目下降得越快。背叛者获得的高额收益会促使它们很快占据种群的主导地位,合作者快速消失,而较小的Z会使种群初始状态下几乎所有的玩家自身和交互域内的合作者数目都高于合作阈值,这些玩家对于邻域中合作者的消失感知不敏感,无法通过调整交互域的方式及时筛选并驱逐背叛者。各个玩家邻域内合作者的锐减形势无法被逆转,合作者无奈消失在网络中,只剩余极少量的惩罚者残存并战胜背叛者达到稳态。当r=3.8时,玩家及交互域内的平均合作者数目在急速下降后,再次上升至比开始更高的数目(最后的对数粗化正与图3中背叛策略消失后的合作策略和惩罚策略比例的走势一致)。
这得益于较大的增强因子,使得合作者和惩罚者在抵制背叛者的剥削时更具优势。一旦背叛者数目开始上升触发合作阈值机制,交互域内的合作者数目急速下降,大量玩家迅速“觉醒”,开始驱逐邻域中的背叛者,使得合作者得到生存并较快地达到稳态,这在一定程度上缩短了达到稳态的时间。
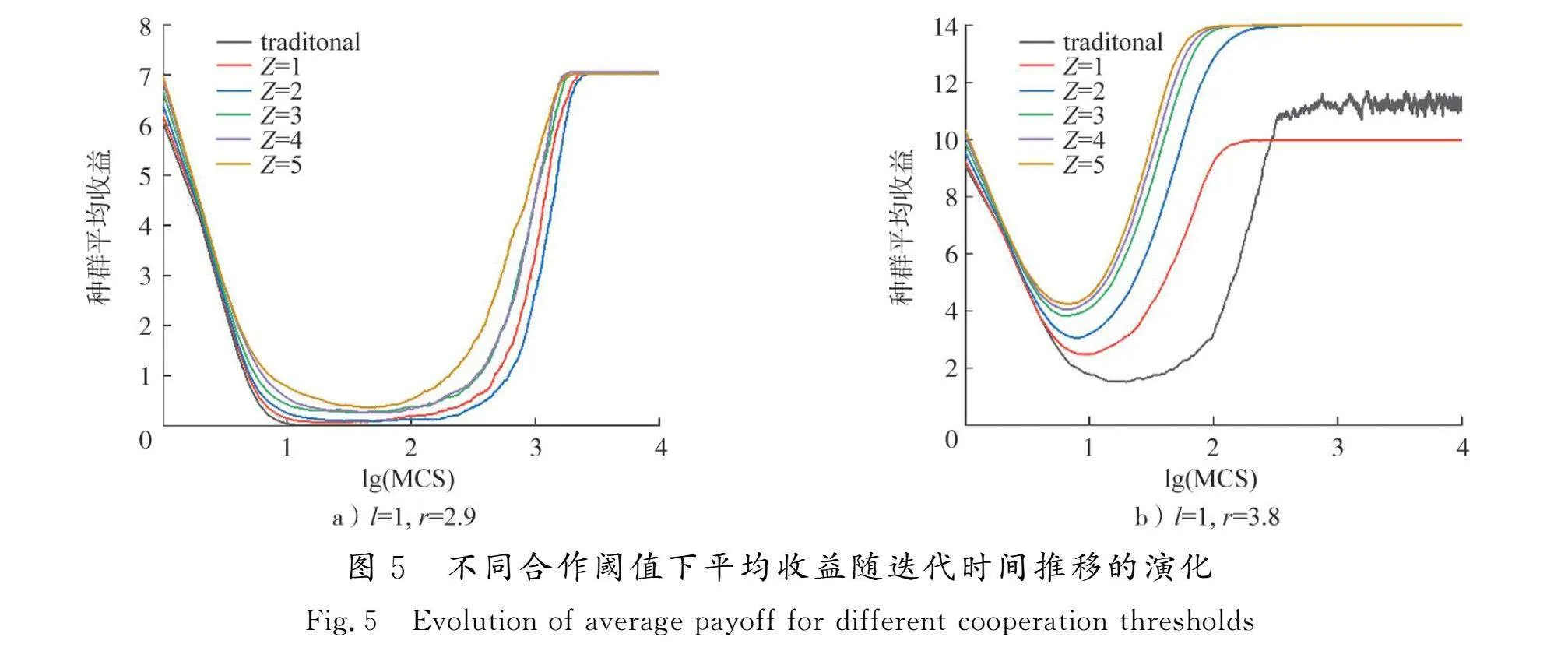
为了进一步探究基于合作阈值的动态交互域模型对群体收益的影响,图5绘制了不同合作阈值下种群平均收益随时间变化的曲线。在基于合作阈值的动态交互域模型中,对比r=2.9与r=3.8的2种情况,当r取较小值时,初始阶段种群平均收益较低,随着演化进程平均收益降低得更快、更剧烈,稳态时所达到的平均收益也更低。甚至于,传统模型在r=2.9时,玩家在演化进程中收益会变为0;而在新模型中,无论Z取何值,种群平均收益在经历一段短暂的收益下降阶段后发生回升,到稳态时会达到比初始状态更高的平均收益,且Z值越大,演化过程中种群维持的平均收益水平越高,达到平均收益稳态值的速度越快。这是因为,传统模型对背叛策略的抑制更多地依赖于惩罚者付出高昂的惩罚成本,这种机制必然会损伤惩罚者在种群中的利益,使得在与背叛者的斗争中处于较弱的优势,背叛者肆意利用合作者获得高收益后,不利于合作策略和惩罚策略传播,种群平均收益较低,达到稳态收益的速度更慢。动态交互域有效缓解了这种困境。种群内低于收益阈值的玩家,根据自身策略类型不断调整自己的交互域,过程中背叛者的交互域不断缩小,逐渐被孤立出来,无法获得高昂的剥削收入。同时,惩罚者在逐渐扩张的交互域中检测出残余的背叛者进行惩罚,再次打击了背叛者的“搭便车”行为。合作阈值越大,对种群平均收益的提高效果越明显。这种方式避免了惩罚者对所有背叛者都付出惩罚成本的大量收入损失,抑制了背叛策略的传播,合作策略和惩罚策略得以维持和涌现。
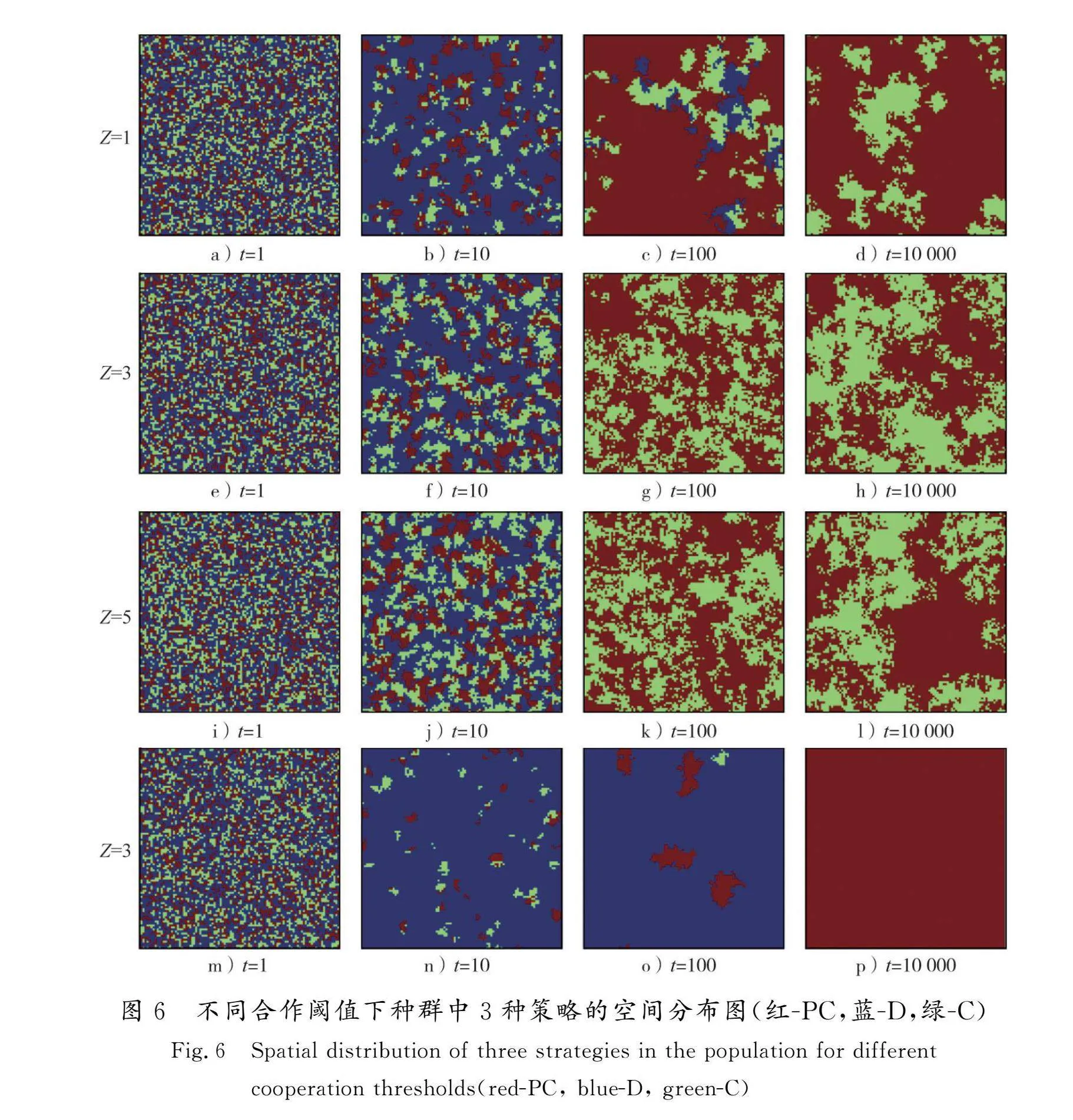
为了探索合作阈值如何影响合作策略的空间演化过程,图6给出了这3种策略的演化快照。如图6所示,在4种不同的演化条件下,各个策略稳态时在方格网络上呈现为簇的分布形式(红色代表惩罚者,蓝色代表背叛者,绿色代表合作者)。图6 a)—l)展示了当r=3.8且l= Z取不同值时策略分布随时间的演变过程。从t=1到t=10,3种不同的演化背景下,策略分布相似。从初始时3种策略的均匀随机分布开始,背叛策略凭借不劳而获的高额利益优势开始迅速在网络中蔓延。合作者和惩罚者开始逐渐聚集,形成许多小簇以抵抗背叛者的入侵。从t=10到t=100,背叛者数量逐渐开始减少,最后几乎完全消失在种群中,合作者和惩罚者占据上风,直到t=10 000种群中只有合作者和惩罚者存活。同时,对比图6 b)、f)和j)可知,当r和l保持不变,随着合作阈值Z的增大,合作者和惩罚者在t=10时刻存活的比例会更高。尤其是合作者,在Z=1时仅残存极少一部分,而当Z=5时,合作者的数量几乎与背叛者相差无几。这是因为,此时网络中的惩罚者将合作者包裹起来,隔绝开了背叛者,形成了一个“真空保护罩”。背叛者无法与合作者直接接触利用其获利,却受到了惩罚者的审判,且Z=5时,较高的合作阈值使大量玩家频繁调整交互域,背叛者更加快速地从交互域中被“踢出局”,遏制了背叛策略的传播,合作者得以喘息,并凭借合作簇的网络互惠性质得以维持。而图6 m)—p)展示的是当Z=3、l=1、r=2.9时的演化条件下策略分布的变化。当t=100时,背叛者几乎占据整个种群,有少量的合作者和惩罚者存活,t=10 000时,只存在惩罚者一种策略。而在其他3种情况下,稳态时却同时存在合作者簇和惩罚者簇。这主要是因为,增强因子越小,合作的促进效果相对越差。显然,可以得出结论,更大的增强因子和收益阈值都能促进合作策略的生存与维持。
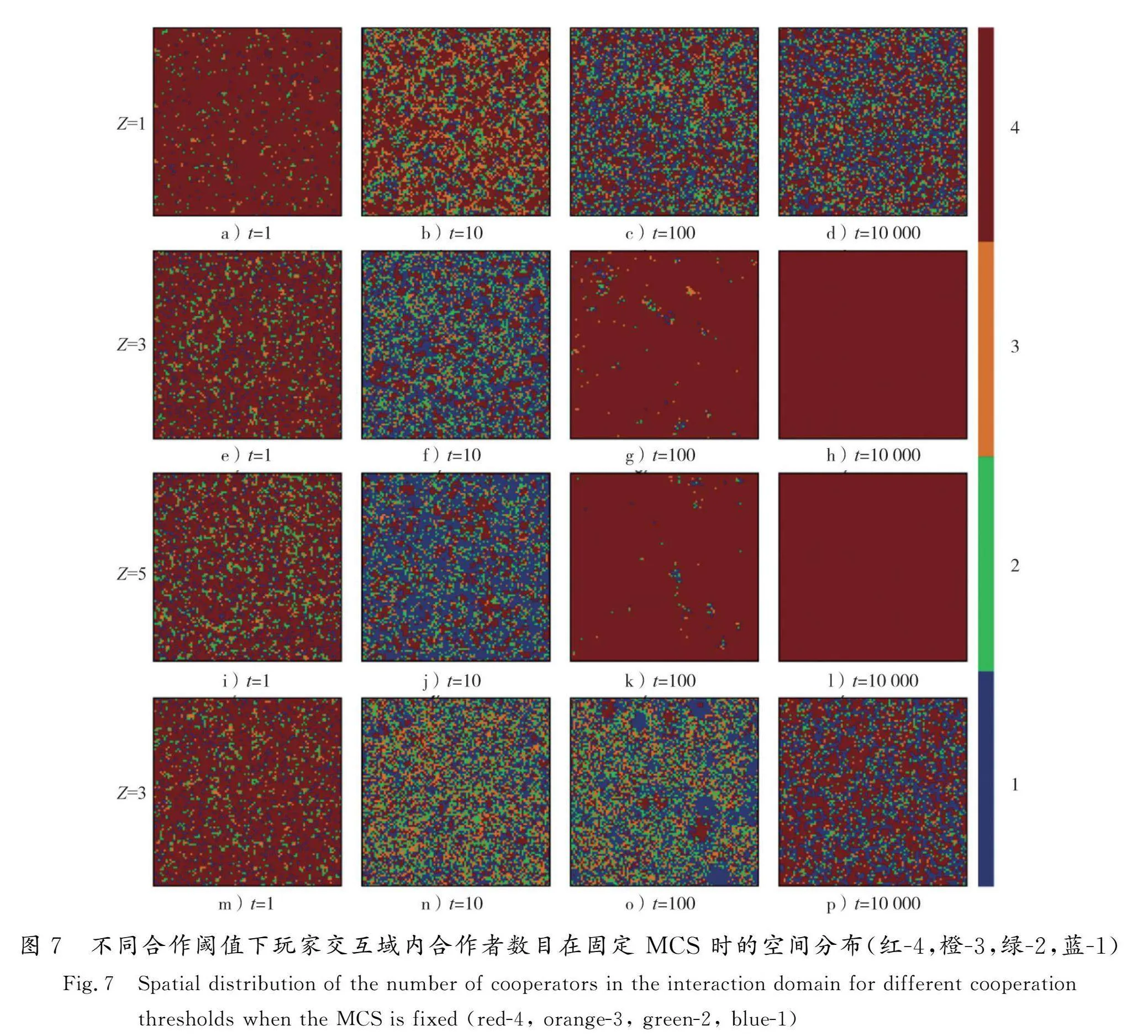
为了探究基于合作阈值的动态交互域模型下玩家的交互域是如何更新演化的,图7比较了不同合作阈值下,玩家的交互域随时间的动态分布。从交互域分布的角度看,合作阈值越高,稳态时的平均交互域范围越大。图7 a)—l)描述的是当r=3.8、l=1、Z取不同值下玩家的交互域的动态演化图。从t=1到t=10,当Z越大,玩家的交互域值越多样化。例如,Z=1时网络上更多的玩家及自身交互域中的合作者数目高于合作阈值,因此更不容易感知到合作者数目的减少,无法及时调整交互域的大小以应对背叛者的利用。与图6对比观察,当t=10时,背叛者的比例激增,较大的Z值下(比如Z=5),许多位于背叛者周围的玩家迅速调整交互域以避免与背叛者接触,低交互域的个体比例开始上升,但是,惩罚者却依旧保持更高的交互域值。这一方面是为了遇见更多背叛者并惩罚对方,另一方面也通过与合作者的合作获得更高收益,维持自身的生存。当t=100时,背叛者交互域受到式(4)的限制不断降低,比例开始下降,几乎完全消失在网络中。网络上大多数玩家都为合作者和惩罚者,因此为了获得更高水平的合作,交互域开始扩大,整体呈现为高交互值的分布。当t=10 000、Z=3和Z=5时,种群的交互域值均为 而Z=1时玩家交互域却依旧保持多样性。这证明了合作阈值的引入会使玩家的交互域动态变化,合作阈值越高,对合作策略的促进效果越好,达到全合作稳态后,玩家可以保持最大的交互范围。对比当Z=3、l=1、r=3.8和r=2.9时交互域的不同分布特点,如图7 e)—h)和图7 m)—p)所示。可以看出,r取较小值时演化过程中交互域的多样性更强,且在稳态时存在大量玩家交互范围保持在较低的水平。这证明,更大的合作阈值和增强因子能够促使网络中玩家对交互域进行更快的调整并恢复至最高的交互范围。
此外,通过比较图6和图7可以发现,惩罚簇的平均交互域高于合作簇的平均交互域,背叛簇的平均交互域最低。这表明,基于合作阈值的动态交互模型不仅可以驱逐背叛者,而且可以帮助策略为PC或C的合作参与者建立更大的交互域,从而获得高收益,达到共赢。
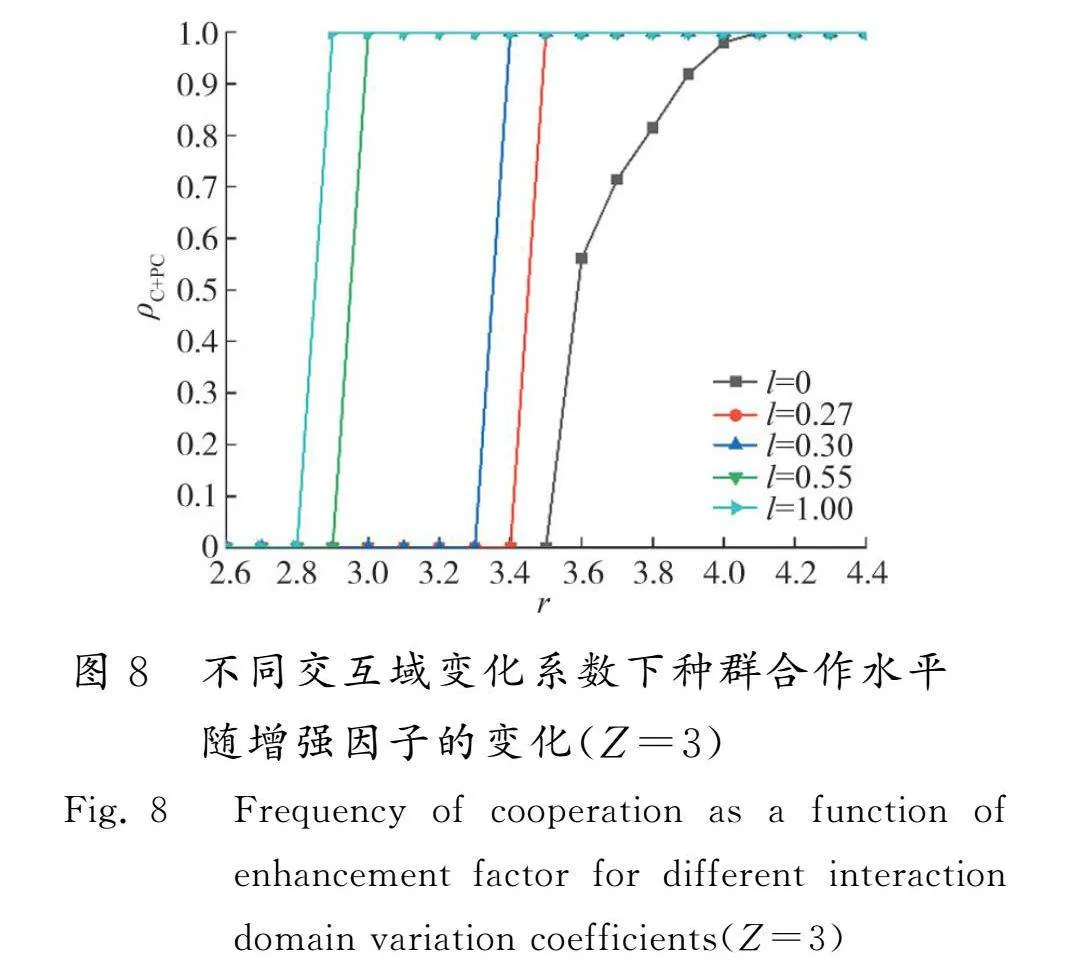
针对交互域k(t)如何影响合作演化的问题,图8考察了在不同的l值(代表交互域变化强度)下,增强因子r如何影响合作演化。假设l越大意味着交互域每次变化的程度越剧烈,交互域波动越大。当l=0时,等同于传统带有惩罚机制下种群的合作演化,在这个过程中交互域不会发生任何改变。可以看出,当l=0时,稳态时存在合作策略所需的增强因子最大(rgt;3.5),且当r处于中间值(3.5lt;rlt;4.1)时,存在有背叛策略和合作策略共存的较低水平合作稳态。而当l≠0时,只需要很小的增强因子便可以达到全合作的高水平合作稳态。可以看到,当l=0.27时,由于交互域的波动程度较低,在rlt;3.4的条件下,未被驱逐出交互域的背叛者在整体上占据了主导地位。当l=0.3时,可以看到合作行为可以出现并维持的r为3.3。当l=0.55时,合作行为出现的r从3.3降低到2.9,背叛者在很长的一段时间内是优势策略,但是当r≥2.9时,合作策略和惩罚策略占据了整个种群。当l=1时,交互域的动态变化强度最大,只需要极小的增强因子(r=2.8)就能轻易地逆转种群全是背叛者的局势为全合作水平。即在动态交互域模型中,若Z取较大值(Z=3)时,随着增强因子的增大,合作水平发生了从非合作状态到合作状态的一阶相变,且l越大,交互域波动的程度越剧烈,发生相变所需要的r越小,这能更有效地防止玩家采取背叛行为。
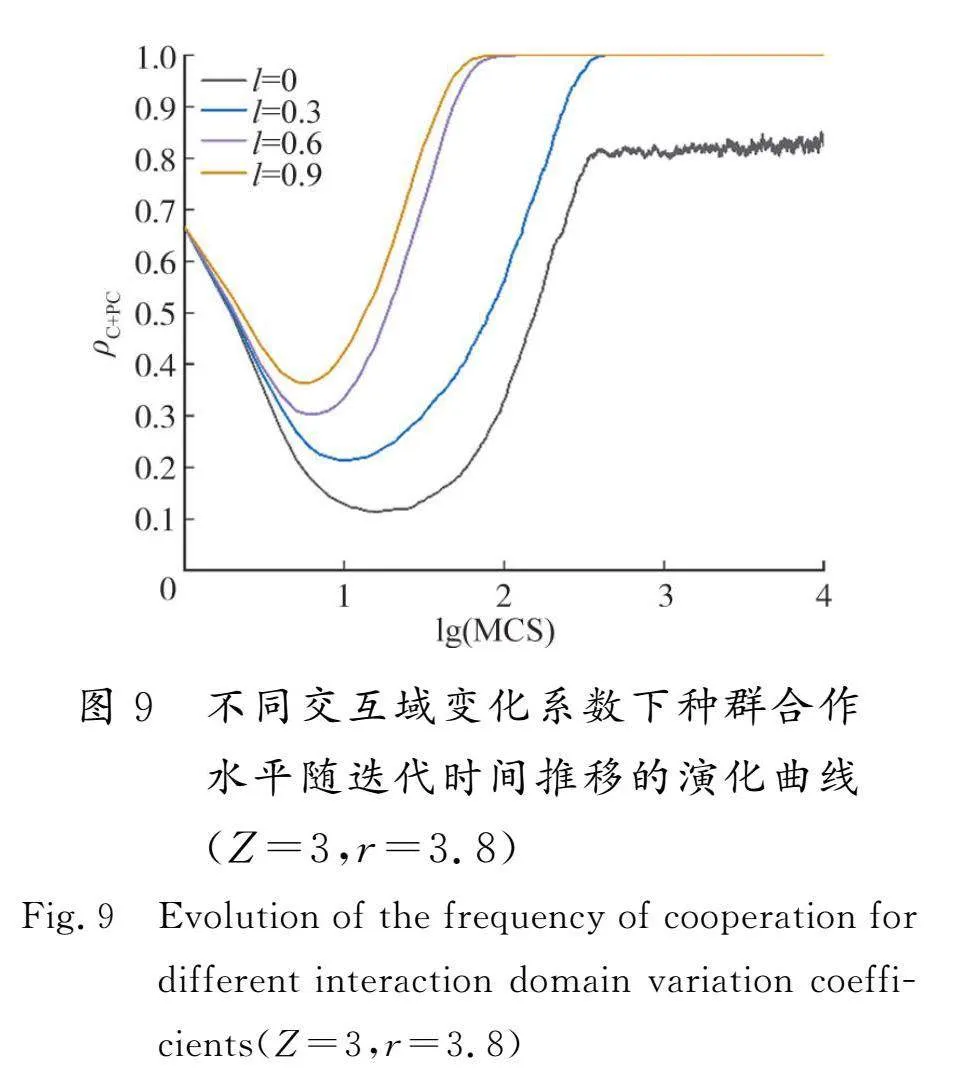
为了进一步探讨在不同的l值下如何影响合作水平,图9给出了当Z=3、r=3.8、l取不同值时,合作水平ρC+PC随时间t的演化趋势。在图中由于一些曲线存在重叠,故只绘制出来涵盖了所有典型情况的4条曲线。l=0时即等同于传统模型。在初始阶段,无论l取何值,曲线总是从66.6%的合作水平开始,逐渐减少到最小值。这是一个合作者和惩罚者的比例减少的过程。这种现象的原因是,背叛者不需要成本却获得高收益的特点使它比合作者和惩罚者更容易被其他玩家选择学习它的背叛策略。在传统模型中,合作者和惩罚者试图形成簇并利用网络互惠生存传播,但是由于这些簇过于分散,惩罚成本过高,这种斗争的过程更艰难和持久。合作者无法生存,稳态时仅剩余惩罚者和背叛者存活。与这种情况相比,在动态交互域模型中,背叛者的交互域降低,扩散也受到抑制,更有益于合作者和惩罚者的传播。动态交互域使得大多数玩家在博弈过程中不可能一直与所有近邻交互,这可以在一定程度上防止背叛者利用合作者,最终导致完全的合作,超出了网络互惠的本身。同时,从动态交互域的曲线中可以观察到,l的取值越大,合作水平在t=10左右时抵达的合作水平最低值越高,也能更快地到达完全合作的稳态。据此,可以推断出造成上述趋势的原因是变化参数l的取值越大,种群对于检测到的背叛行为越难以容忍,通过越剧烈的交互域变化来抵制背叛行为,使得合作水平快速上升。
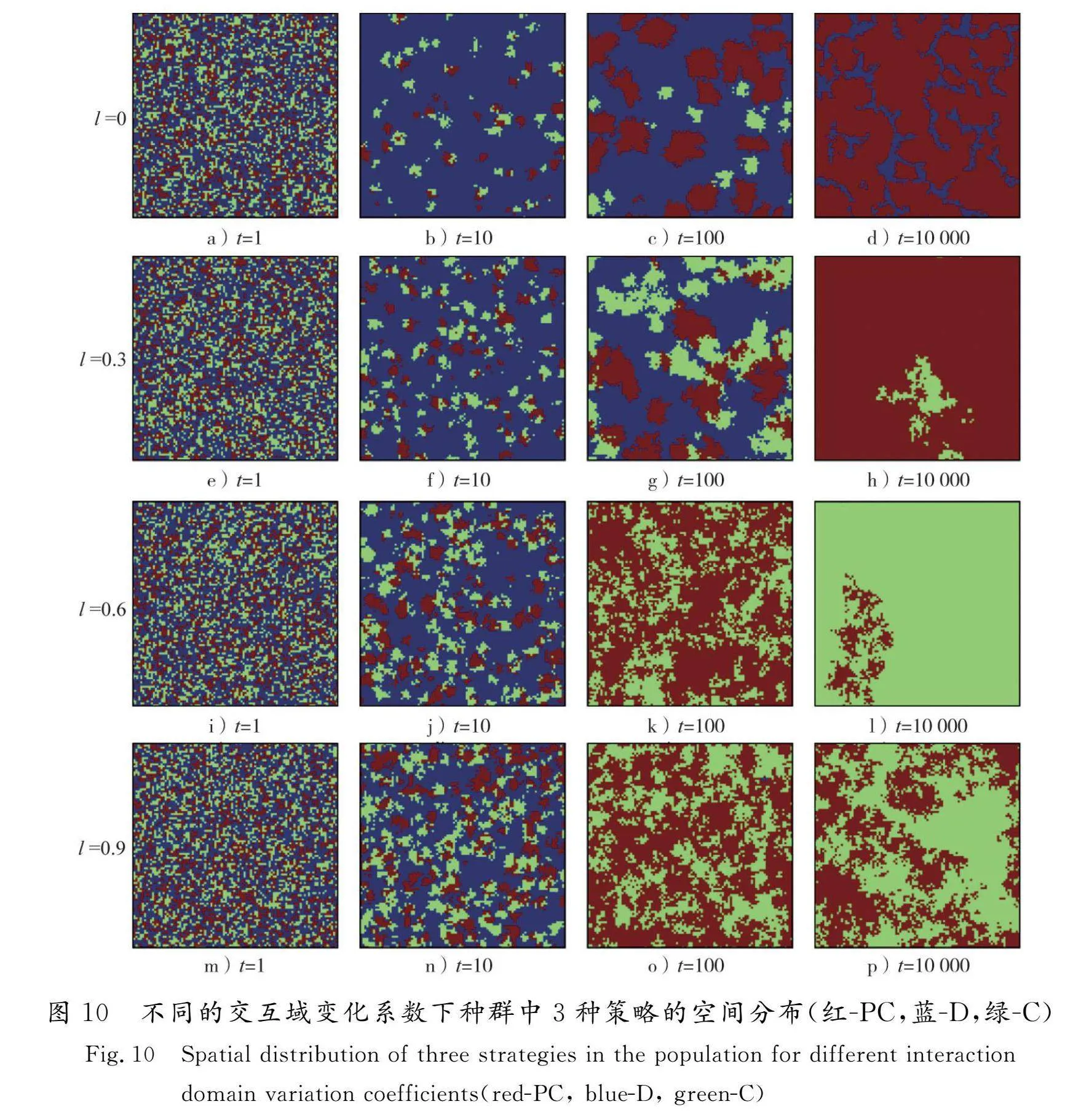
为了探索动态交互域波动程度所促进的合作行为的微观变化,图10呈现了当l取不同值时,这3种策略分布的动态变化过程。在较小的初始状态下,3种策略随机等概率分布。t=10左右,背叛者比例达到最大值,此时合作策略和惩罚策略只能以分散的小簇存活。观察第2列的4张图不难发现,l越大,网络中存活的合作者比例越高,合作者和惩罚者形成混合簇,位于合作簇边缘的惩罚者保护了它们不受背叛者侵蚀。当t=100时,合作者和惩罚者逐渐在网络中占据优势,区别在于,当l取较小值(l=0和0.3)背叛策略还未消失,惩罚者和合作者仍需通过调整交互域和施加惩罚来遏制背叛者的比例。当t=10 000时,所有种群均达到稳态。由于l=0是传统模型,在r=3.8时无法达到全合作水平,背叛者仍以线性小簇包裹在惩罚簇边缘,二者比例达到动态平衡。而在交互域存在动态演化的其余3种情况下,总能在稳态时完全消灭背叛者。从该图的演化过程可以得知,在较大的变化参数l下,更剧烈的交互域调整有助于合作者和惩罚者的传播,并形成更强大的集群联盟来抵抗背叛者的剥削。l越大,种群对背叛行为的感知越敏锐,背叛者越快被驱逐出交互域,促使合作策略和惩罚策略的传播越快。
3 结 语
构建了一种动态交互的公共物品博弈模型,引入了基于合作阈值的交互域更新规则,得出如下结论。
1)合作阈值越大,对种群合作水平和平均收益的促进效果越好,这更大程度地降低了惩罚支出,更高效地避免了合作者被惩罚者利用。
2)交互域更新程度越剧烈,种群对背叛行为的容忍度越低。背叛策略的传播受到更强烈的惩罚者制裁和驱逐出交互域的双重压力,更多的背叛者不得不放弃不劳而获,转而选择合作策略才得以生存,这加快了合作稳态的进程。
综上所述,引入基于阈值的动态交互模型对合作的促进效果显著。尽管基于合作阈值的动态交互域模型可以很好地提高种群的集体利益,达到全合作的高水平稳态,但由于交互域的更新方式单一,应付复杂多变的现实交互环境还存在一定难度,在今后的研究中需要进一步改进优化更新方式。
参考文献/References:
[1] YANG Zhihu,LI Zhi.Oscillation and burst transition of human cooperation[J].Nonlinear Dynamics,202 108(4):4599-4610.
YANG Zhihu.Role polarization and its effects in the spatial ultimatum game[J].Physical Review E,2023.DOI:10.1103/PhysRevE.108.024106.
[3] 荣智海,许雄锐,吴枝喜.合作演化与网络博弈实验研究进展[J].中国科学:物理学力学天文学,2020,50(1):114-128.
RONG Zhihai,XU Xiongrui,WU Zhixi.Experiment research on the evolution of cooperation and network game theory[J].Scientia Sinica Physica,Mechanica amp; Astronomica,2020,50(1):114-128.
[4] 全吉,周亚文,王先甲.社会困境博弈中群体合作行为演化研究综述[J].复杂系统与复杂性科学,2020,17(1):1-14.
QUAN Ji,ZHOU Yawen,WANG Xianjia.Review on evolution of cooperation in social dilemma games[J].Complex Systems and Complexity Science,2020,17(1):1-14.
[5] 兰婷,程磊,戚静云.空间公共品博弈中条件相互惩罚对合作的影响[J].科技通报,2017,33(6):26-31.
LAN Ting,CHENG Lei,QI Jingyun.Effect of conditional mutual punishment on the cooperation in the spatial public goods game[J].Bulletin of Science and Technology,2017,33(6):26-31.
[6] 全吉,储育青,王先甲.具有惩罚策略的公共物品博弈与合作演化[J].系统工程理论与实践,2019,39(1):141-149.
QUAN Ji,CHU Yuqing,WANG Xianjia.Public goods with punishment and the evolution of cooperation[J].Systems Engineering-Theory amp; Practice,2019,39(1):141-149.
[7] WANG Qiang,LIU Linjie,CHEN Xiaojie.Evolutionary dynamics of cooperation in the public goods game with individual disguise and peer punishment[J].Dynamic Games and Applications,2020,10(3):764-782.
[8] SZOLNOKI A,SZAB G,PERC M.Phase diagrams for the spatial public goods game with pool punishment[J].Physical Review E, Statistical, Nonlinear, and Soft Matter Physics,2011.DOI:10.1103/PhysRevE.83.036101.
[9] 谢逢洁.复杂网络上博弈行为演化的合作激励[J].上海交通大学学报,201 49(8):1256-1262.
XIE Fengjie.Incentive mechanism for cooperation in evolution of game behaviors on complex networks[J].Journal of Shanghai Jiaotong University,201 49(8):1256-1262.
[10]高世萍,武斌,杜金铭,等.激励机制下合作行为的演化动力学[J].控制理论与应用,2018,35(5):627-636.
GAO Shiping,WU Bin,DU Jinming,et al.Evolutionary dynamics of cooperation driven by incentives[J].Control Theory amp; Applications,2018,35(5):627-636.
[11]郑巍,彭雨松,杨丰玉,等.基于利他激励的群体演化合作模型[J].计算机应用研究,202 38(2):475-478.
ZHENG Wei,PENG Yusong,YANG Fengyu,et al.Group evolution cooperation model based on altruistic incentive[J].Application Research of Computers,202 38(2):475-478.
[12]ZHUO Siqing,LIU Jie,REN Tianyu,et al.Evolution dynamics with the switching strategy of punishment and expulsion in the spatial public goods game[J].New Journal of Physics,2022.DOI:10.1088/1367-2630/aca995.
[13]李霞.具有条件驱逐策略的空间公共物品博弈与合作演化[D].武汉:武汉理工大学,2021.
LI Xia.Cooperation Evolution of Spatial Public Goods Game with Conditional Exclusion Strategy[D].Wuhan:Wuhan University of Technology,2021.
[14]HUANG Keke,WANG Tao,CHENG Yuan,et al.Effect of heterogeneous investments on the evolution of cooperation in spatial public goods game[J].PLoS One,2015.DOI:10.1371/journal.pone.0120317.
[15]CAO Xianbin,DU Wenbo,RONG Zhihai.The evolutionary public goods game on scale-free networks with heterogeneous investment[J].Physica A:Statistical Mechanics and Its Applications,2010,389(6):1273-1280.
[16]FAN Ruguo,ZHANG Yingqing,LUO Ming,et al.Promotion of cooperation induced by heterogeneity of both investment and payoff allocation in spatial public goods game[J].Physica A:Statistical Mechanics and Its Applications,2017,465(6):454-463.
[17]WANG Xiaofeng,CHEN Xiaojie,GAO Jia,et al.Reputation-based mutual selection rule promotes cooperation in spatial threshold public goods games[J].Chaos,Solitons amp; Fractals,201 56:181-187.
[18]FU Feng,HAUERT C,NOWAK M A,et al.Reputation-based partner choice promotes cooperation in social networks[J].Physical Review E, Statistical, Nonlinear, and Soft Matter Physics,2008.DOI:10.1103/PhysRevE.78.026117 .
[19]汤彩霞.空间公共物品博弈中基于声誉机制的合作演化研究[D].武汉:武汉理工大学,2021.
TANG Caixia.Cooperation Evolution Based on Reputation Mechanism in Spatial Public Goods Game[D].Wuhan:Wuhan University of Technology,2021.
[20]辛琦.基于声誉的网络成长模型[J].山东农业大学学报(自然科学版),2018,49(1):166-170.
XIN Qi.Network growth model based on reputation[J].Journal of Shandong Agricultural University(Natural Science Edition),2018,49(1):166-170.
[21]全吉,储育青,王先甲.自愿参与机制下的公共物品博弈与合作演化[J].系统工程学报,2020,35(2):188-200.
QUAN Ji,CHU Yuqing,WANG Xianjia.Public goods game under voluntary participation mechanism and the evolution of cooperation[J].Journal of Systems Engineering,2020,35(2):188-200.
[22]ZHU Peican,GUO Hao,ZHANG Hailun,et al.The role of punishment in the spatial public goods game[J].Nonlinear Dynamics,2020,102(4):2959-2968.
[23]HELBING D,SZOLNOKI A,PERC M,et al.Evolutionary establishment of moral and double moral standards through spatial interactions[J].PLoS Computational Biology,2010.DOI:10.1371/journal.pcbi.1000758.
[24]SHANG Lihui,SUN Sihao,AI Jun,et al.Cooperation enhanced by the interaction diversity for the spatial public goods game on regular lattices[J].Physica A:Statistical Mechanics and Its Applications,2022.DOI:10.1016/j.physa.2022.126999.
[25]LI Hongyang,XIAO Jian,LI Yumeng,et al.Effects of neighborhood type and size in spatial public goods game on diluted lattice[J].Chaos Solitons amp; Fractals,201 56:145-153.
[26]XU C,HUI P M.Evolution of cooperation in public goods game in populations of dynamic groups of varying sizes[J].Physica A:Statistical Mechanics and Its Applications,2023. DOI:10.1016/J.PHYSA.2023.128519.
[27]ZHU Chengjie,SUN Shiwen,WANG Li,et al.Promotion of cooperation due to diversity of players in the spatial public goods game with increasing neighborhood size[J].Physica A:Statistical Mechanics and Its Applications,201 406:145-154.
[28]KIMMEL G J,GERLEE P,BROWN J S,et al.Neighborhood size-effects shape growing population dynamics in evolutionary public goods games[J].Communications Biology,2019.DOI:10.1038/s42003-019-0299-4.
[29]HELBING D,SZOLNOKI A,PERC M,et al.Punish,but not too hard:How costly punishment spreads in the spatial public goods game[J].New Journal of Physics,2010.DOI:10.1088/1367-2630/12/8/083005.
[30]周万珍,宋健,许云峰.异质网络社区发现方法研究综述[J].河北科技大学学报,202 42(3):231-240.
ZHOU Wanzhen,SONG Jian,XU Yunfeng.Survey of community discovery method of heterogeneous network[J].Journal of Hebei University of Science and Technology,202 42(3):231-240.
[31]陈蔚颖,潘建臣,韩文臣,等.具有异质增益因子的超图上的演化公共品博弈[J].物理学报,202 71(11):25-33.
CHEN Weiying,PAN Jianchen,HAN Wenchen,et al.Evolutionary public goods games on hypergraphs with heterogeneous multiplication factors[J].Acta Physica Sinica,202 71(11):25-33.
[32]JANSSEN M A,GOLDSTONE R L.Dynamic-persistence of cooperation in public good games when group size is dynamic[J].Journal of Theoretical Biology,2006,243(1):134-142.
[33]YANG Zhihu,LI Zhi,WU Te,et al.Effects of adaptive dynamical linking in networked games[J].Physical Review E,Statistical,Nonlinear,and Soft Matter Physics,2013.DOI:10.1103/PhysRevE.88.042128.
[34]YANG Zhihu,YU Changbin,KIM J,et al.Evolution of cooperation in synergistically evolving dynamic interdependent networks:Fundamental advantages of coordinated network evolution[J].New Journal of Physics,2019.DOI:10.1088/1367-2630/ab32c7.
[35]WANG Pai,YANG Zhihu.The double-edged sword effect of conformity on cooperation in spatial Prisoner’s Dilemma Games with reinforcement learning[J].Chaos Solitons amp; Fractals,2024.DOI:10.1016/j.chaos.2024.115483.
[36]DU Chunpeng,LU Yikang,MENG Haoran,et al.Evolution of cooperation on reinforcement-learning driven-adaptive networks[J].Chaos:An Interdisciplinary Journal of Nonlinear Science,2024.DOI:10.1063/5.0201968.
[37]WANG Zhen,SZOLNOKI A,PERC M.Interdependent network reciprocity in evolutionary games[J].Scientific Reports,2013.DOI:10.1038/srep01183.
[38]DORNIC I,CHAT" H,CHAVE J,et al.Critical coarsening without surface tension: The universality class of the voter model[J].Physical Review Letters,2001.DOI:10.1103/PhysRevLett.87.045701.
猜你喜欢
今日农业(2020年20期)2020-12-15 15:53:19
中国自行车(2018年10期)2018-11-30 02:09:30
海峡姐妹(2017年6期)2017-06-24 09:37:34
小学教学参考(综合)(2016年11期)2016-11-14 20:28:48
人间(2016年28期)2016-11-10 23:25:06
体育时空(2016年9期)2016-11-10 20:39:18
体育时空(2016年8期)2016-10-25 14:19:44
科学与财富(2016年28期)2016-10-14 22:11:09
金色年华(2016年1期)2016-02-28 01:38:19
IT时代周刊(2015年8期)2015-11-11 05:50:38
