
准确性与公平性视角下能力分布异常对测验等值的影响
2025-01-19 00:00:00王少杰张敏强黄菲菲
考试研究 2025年1期





[摘 要] 考生能力分布情况在测验等值中极为关键。采用蒙特卡洛模拟,探讨能力分布异常对测验等值的影响。结果表明,各测验等值准确性较为理想。在将能力范围限定为[-1.1,1.1]中等异常能力情境下,等值系数与分数准确性不如其他情境。在低分段和高分段,等值分数误差不存在明显区别。对于等值公平性,分类一致性与准确性均达到较高水平。在中等异常能力分布情境下,等值结果的分类误差估计与真值差异较大。需要重视并设法降低考生能力分布情况对准确性与公平性的影响。
[关键词] 能力分布;测验等值;准确性;公平性
[中图分类号] G424.74 [文献标识码] A
[文章编号] 1673—1654(2025)01—055—010
不同测验间的分数或题目参数由于测验难度、考查内容及考生群体能力分布等存在差异,通常需要借助测验等值方法进行比较。测验等值(test equating,scaling,and linking)是指通过调整不同测验的分数或题目参数,使其能够相互替代的统计过程[1]。项目反应理论(item response theory,IRT)测验等值方法以其优异的表现,在许多大规模测评的题库建设、测验开发与施测、数据分析、分数量尺化与解释等环节发挥着关键作用,成为目前关注最多、应用最广的测验等值方法之一[2-5]。然而,在教育测评实践中,许多选拔性或合格性考试的考生分数和能力并非总是呈现理想的正态分布[6-9]。在非正态(异常)能力分布情况下,测验等值的准确性成为亟需探索和解决的重要问题。同时,相对于常模参照测验(norm-referenced assessment)中的信度与效度概念,在标准参照测验(criterion-referenced assessment)中,测验对考生的分类一致性(classification consistency)与准确性(classification accuracy)极其重要[10-11],它们是衡量测验公平性的关键工具。因此,除分数准确性外,在测验等值实践中,还需重点关注考生能力分布情况对其分类公平性(一致性与准确性)的影响。本研究基于测验等值准确性与分类公平性的视角,探讨能力分布异常对测验等值的影响。
一、测验等值与公平性
(一)IRT测验等值方法
IRT测验等值方法主要包括矩估计方法、特征曲线方法(以下简称“传统方法”)[1]。本研究所指测验等值方法准确称谓应为量尺转换(scale transformation)或参数链接(parameter linking)方法,但由于国内习惯将其与后续的测验分数等值(test score equating)环节统称为测验等值方法,同时本研究也涉及测验分数等值内容,因此延续此惯例。特征曲线方法同时考虑由IRT模型所有参数构成的特征曲线间的差异,表现最为优异,应用最为普遍,主要包含项目特征曲线方法(item characteristic curve method,ICC;又被称为Haebara方法)、测验特征曲线方法(test characteristic curve method,TCC;又被称为Stocking-Lord方法)[12-13]。但传统方法忽略了参数估计的不确定性,并未将估计误差考虑在内,影响了测验等值结果的解释,甚至影响到相关教育考试决策,损害了考生能力评估与人才选拔的准确性、公平性[2,4]。为此,Wang等人采用信息量对特征曲线方法的损失函数进行自适应加权,提出项目信息量加权特征曲线方法(item information weighted characteristic curve method,IWCC)与测验信息量加权特征曲线方法(test information weighted characteristic curve method,TWCC)(以下简称“信息量加权方法”)[14]。以三参数Logistic模型为例,两种信息量加权方法的损失函数分别为:
[IWCCcrit=iwiVICC(θYi;aYj,bYj,cYj)-ICCθYi;aXjA,AbXj+B,cXj2×IIFθYi;aYj,bYj,cYj+IIFθYi;aXjA,AbXj+B,cXj]
与
[TWCCcrit=iwiTCC(θYi;aY,bY,cY)-TCCθYi;aXA,AbX+B,cX2×TIFθYi;aY,bY,cY+TIFθYi;aXA,AbX+B,cX],
其中,[IIFθi;aj,bj,cj]与[TIFθi;a,b,c]代表题目与测验信息量,[IIFθi;aj,bj,cj=a2j(1-cj)cj+eaj(θi-bj)×1+e-aj(θi-bj)2],[TIFθi;a,b,c=jIIFθi;aj,bj,cj]。
aYj,bYj,cYj,θYi与aXj,bXj,cXj,分别为新测验X与旧测验Y量尺上的题目区分度、难度、猜测系数与考生能力参数;a,b,c,分别为相应题目参数向量,A与B分别为需要计算的测验等值系数;wi为损失函数中考生i的权重,为方便计算,本研究在[-4,4]区间内每隔0.05选择均匀分布的能力点,共161个,并且其权重wi=1[15]。
需要注意,将IWCC与TWCC方法损失函数信息量部分均赋予相同的非零值作为权重,可得到传统方法的损失函数。换言之,传统方法为信息量加权方法的特殊形式[14]。理论上,通过分别采用题目和测验信息量对损失函数进行自适应加权处理,IWCC与TWCC方法可降低参数估计误差对测验等值的影响。同时,IRT中能力分布影响参数估计误差[16-17],从而影响测验等值。无论是学校范围内的小规模学业考试,还是省市乃至国家间的大规模素质评价项目,常见教育测评中的考生成绩(能力)并非总是理想的正态分布[7,8]。非正态的能力分布(能力分布异常)在教育考试实践中也占据重要位置,但针对此方面的测验等值研究相对匮乏。因此,本研究拟探讨能力分布异常对两类测验等值方法的影响。
(二)分类公平性
分类公平性包括分类一致性与准确性(即分类误差)。分类一致性指在采用相同测量程序(测验内容、时间等)的重复(通常是两次)测验中,考生被划分至相同类别的程度。分类准确性指使用观察到的划界分数(cut score)进行分类与根据真实划界分数进行分类所得结果的一致程度[18-19]。但是,在实践中,用于计算分类误差的真实划界分数往往并不可知。为此,学者们提出多种解决方法用于计算分类一致性和准确性,如基于经典测量理论(classical test theory,CTT)的方法与基于IRT的方法。因本研究探讨IRT测验等值,故采用后者,主要包含Lee方法[20]与Rudner方法[21]。这两种方法的主要区别在于分类的量尺。Lee方法在总分量尺上分类,根据考生的潜在能力和项目参数计算其对应概率;而Rudner方法在潜在特质量尺上分类。因后者聚焦于IRT能力参数(潜在特质)量尺,更符合本研究设定,故采用该方法开展后续计算。Rudner方法假设考生能力θ真分数服从正态分布,而其相应估计值[θ]服从均值为[θ]、标准差为SE([θ])的正态分布。这样,给定一个θ值,就能求出其观察分数落在某个分数区间内的概率,以及两次测量分数落入同一个或不同区间内的联合分布概率[22-23]。基于上述思路,分类准确性指标可定义为,[ν=-∞θCϕ(θC-θσθ)f(θ)dθ+θC+∞ϕ(θ-θCσθ)f(θ)dθ];分类一致性指标可定义为,[γ=-∞θC[ϕ(θC-θσθ)]2f(θ)dθ+θC+∞[ϕ(θ-θCσθ)]2f(θ)dθ],其中,θC为划界能力值,[σθ=1I(θ)],I(θ)为IRT测验信息量函数TIF(θi;a,b,c),[ϕ](·)与f(·)分别为标准正态分布的分布函数和密度函数。
测验等值准确性主要涉及等值系数和分数层面的系统误差、随机误差与总误差。因其较为通用且广为熟知,在此不再展开。
二、研究方案
(一)研究目的
在非等组锚测验设计(non-equivalent groups with anchor test design,NEAT)下,采用蒙特卡洛模拟,操纵考生能力分布情况,探讨IRT测验等值方法的准确性与公平性,为该领域的理论与实践提供建议。
(二)变量设计
1. 自变量
自变量包括考生能力分布情况和测验等值方法。其中,考生能力分布情况可分为无异常、中等异常、极端异常三种情况。无论是何种能力分布情况,参与新测验X与旧测验Y的考生初始能力均在N(0,1)中随机抽取并限定其范围为[-3,3]。在中等异常情况下,将能力范围限定为[-1.1,1.1],代表此时测验等值主要基于中等能力考生群体完成;在极端异常情况下,将能力范围限定为[-3,-1.1]和[1.1,3],代表此时测验等值主要基于极端(高与低)能力考生群体完成[24];相比之下,无异常情况则对能力范围不做额外限定。依据统计原理,在标准正态分布下,[-1.1,1.1]包含72.87%的考生,为中等水平考生群体,将其命名为“中等异常”。相较之下,[-3,-1.1]和[1.1,3]共包含26.86%的考生,为能力较高和较低的考生群体,将其命名为“极端异常”。通过此操作,可模拟三种常见的现实考试测评情境,将无异常考生能力分布情境作为参照,从而探讨能力分布异常对测验等值准确性与公平性的影响。测验等值方法包括两种传统方法(ICC与TCC方法)以及两种与其相对应的信息量加权方法(IWCC与TWCC方法)。
2. 固定条件
在IRT测验等值条件下,重点关注能力分布异常对测验等值的影响,故对其余相关条件做出限定。具体而言,在NEAT下,两组考生能力θ~N(0,1),且均为2000人[14]。两测验X与Y的题目采用三参数Logistic模型,区分度参数a~U(0.4,1.4),难度参数b~N(0,1),猜测系数c~Beta(8,24),且题目总数均为100,其中包括20道锚题(内锚)[25-28]。因此,测验等值系数真值为A=1与B=0;同时,在测验分数层面,两测验对应相同分数即为等值分数的真值。
(三)评价指标与模拟流程
1. 测验等值系数准确性
测验等值系数A与B的准确性主要由Bias、SE和RMSE衡量,分别代表随机误差、系统误差与总误差。[Bias(λ)=1Rr=1Rλr-λ],[SE(λ)=1Rr=1Rλr-1Rr=1Rλr2],
[RMSE(λ)=Bias2(λ)+SE2(λ)]。其中,[λ]代表等值系数A与B,R为模拟重复次数,按照教育测评模拟设定习惯,本研究为500。三种误差指标的绝对值越小,说明对应测验等值方法表现越优。进一步,为方便比较信息量加权方法与传统方法的测验等值表现差异,计算相对改善指标(relative improvement,RI),[RI(λ)=Crtraditional(λ)-Crnew(λ)Crtraditional(λ)],其中[Crtraditional(λ)]与[Crnew(λ)]分别为基于传统方法与信息量加权方法计算得到的误差指标;具体而言,即IWCC较ICC方法的改善程度以及TWCC较TCC方法的改善程度。RI指标越接近1,代表信息量加权方法较传统方法提升的比例越高,表现越为优异;RI指标为负值,代表信息量加权方法的表现不如传统方法。
2.测验等值分数准确性
为评估测验等值方法在分数层面的表现,计算分数xi处IRT真分数等值估计值与相应真值间的绝对偏差(absolute bias,AB),以此作为其总误差度量指标,[AB(xi)=1Rr=1Rxir,e-xi,t]。其中,[xir,e]为第r次重复时[xi]的等值分数估计值,[xi,t]为其真值。同时,将模拟中各分数对应的频率作为权重[wi,e],可计算出代表整个分数区间的加权绝对误差(weighted absolute bias,WAB)指标,[WAB(x)=wi,e×AB(xi)]。上述两种等值分数误差的值越小,代表相应测验等值表现越优秀。
3.分类一致性与准确性
基于IRT的Rudner方法计算测验等值结果的分类一致性与准确性,设定划界能力值为1.1[24]。基于等值后参数估计值与模拟真值分别计算的分类误差指标越接近(差值的绝对值越小),代表相应等值结果分类一致性与准确性的返真性越好,测验等值方法对考生的公平性越高。
4.模拟流程
除参数估计(采用mirt包[29])与分类误差计算(采用cacIRT包[30])外,其余模拟与分析均采用R软件自编程序完成[31]。模拟流程包括:(1)随机抽取参加测验X与Y的考生能力θ;(2)随机抽取测验X与Y的题目参数值a,b,c;(3)构建考生作答反应矩阵;(4)采用传统方法与信息量加权方法,计算测验等值系数;(5)采用Rudner方法,计算测验等值的分类一致性与准确性;(6)采用IRT观察分数等值方法,计算等值分数;(7)重复上述过程500次,计算相应评价指标。
三、研究结果
(一)测验等值的准确性
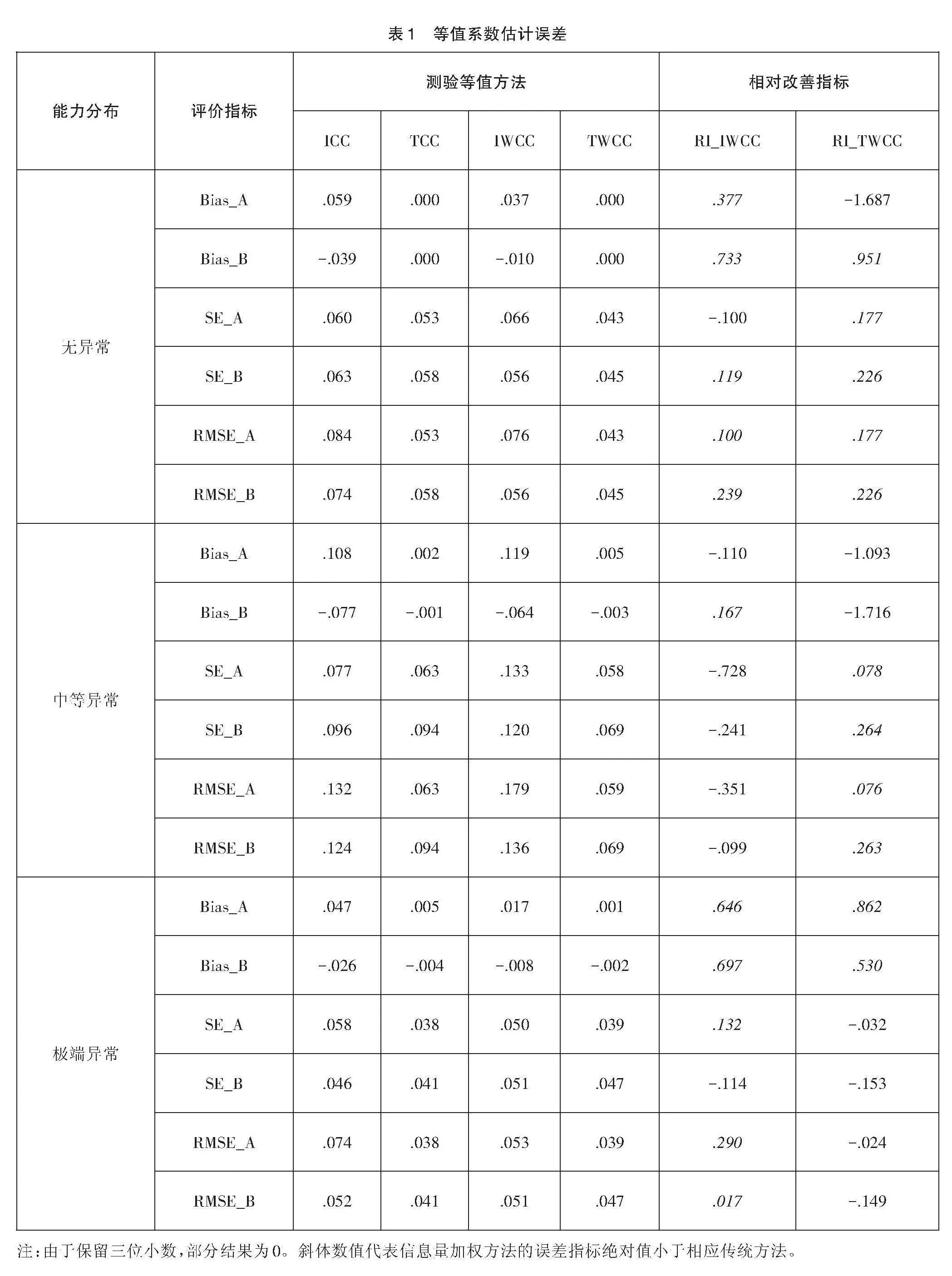
1. 测验等值系数的准确性
表1为测验等值系数估计误差及其RI。总体而言,各测验等值方法的表现均较为优异。SE指标绝对值略高于Bias指标绝对值,表明在IRT测验等值误差中,相较于系统误差,随机误差占比更高。同时,当能力分布为中等异常时,等值系数的Bias指标略高于其余两种能力分布情况,尤其以Bias变化最为明显。除中等异常能力分布的测验等值情境外,IWCC方法的表现略优于对应ICC方法。除极端异常能力分布的测验等值情境外,TWCC方法的表现略优于对应TCC方法。
2.测验等值分数的准确性
图1-图3为三种考生能力分布情况下测验等值分数层面的总误差。与测验等值系数结果类似,在三种能力分布情境中,中等异常能力分布情境下的测验等值分数误差最大,这在ICC与IWCC两种方法的误差最大值处(40-50分与80-90分)尤为明显。同时,在0-30分与95-100分两个分数段,四种测验等值方法的分数误差相差不大。然而,在其余中间分数段,四种方法的等值分数误差存在区别,IWCC与TWCC方法的表现分别优于相应传统方法(中等异常能力分布情况下IWCC方法等值分数误差大于对应传统方法)。而在两种加权方法间,TWCC方法的表现更优。
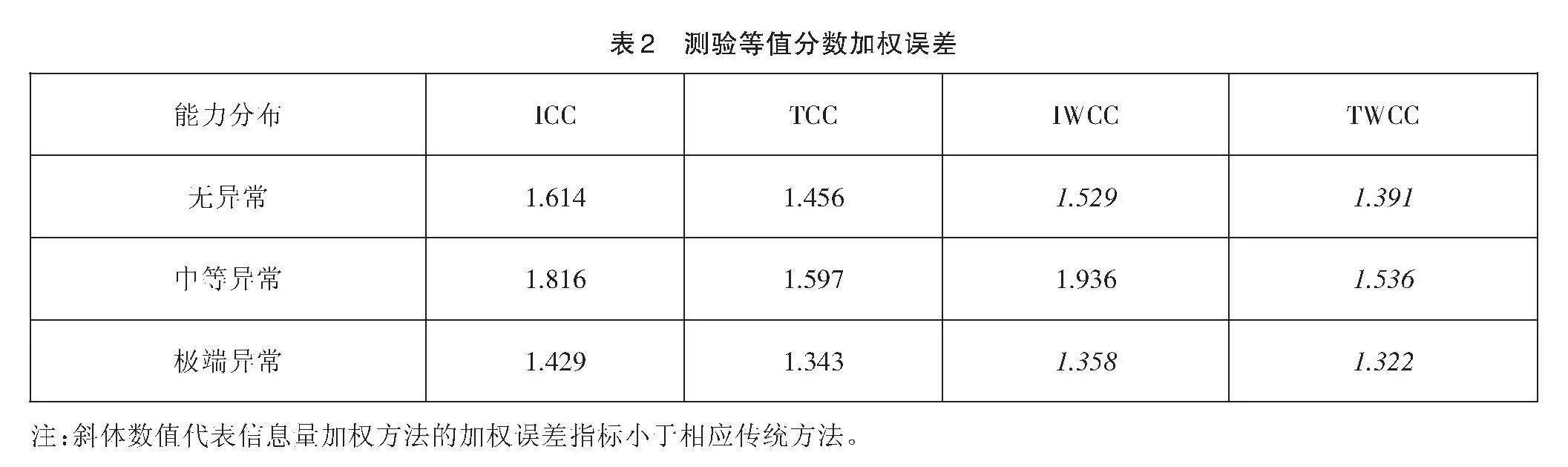
同时,为评估测验等值方法在0-100分数区间的整体表现,表2呈现其加权误差结果。与图1-图3的结果相似,中等异常能力分布情境下的测验等值分数加权误差最大,无异常情境次之,而极端异常情境最小。除中等异常能力分布情境外,IWCC方法的等值分数加权误差低于ICC方法;而在所有条件下,TWCC方法的表现均优于TCC方法。
(二)测验等值的公平性
表3与表4分别为测验等值结果的分类一致性和准确性与其真值间的绝对差异。首先,在三种能力分布情境下,测验等值结果分类一致性与准确性的真值分别达到0.93与0.95,为较高水平,体现出基于IRT开展测评的优势之处。分类误差真值的计算不受能力分布情况影响(详见“1.2分类公平性”),这也在一定程度上验证了本研究模拟流程的准确性。同时,基于各测验等值结果计算出的分类一致性和准确性均较为理想,其与真值的差异不超过0.06。与测验等值准确性分析结果类似,中等异常能力分布测验等值情境下的分类误差结果与真值的差异最大,并且与其他情境下的结果存在较大区别。相较于传统方法,基于两种信息量加权方法的分类误差计算结果并未表现出明显优势。
四、结论与讨论
采用蒙特卡洛模拟方法,基于等值准确性与公平性等指标,探讨能力分布异常对测验等值的影响。
在测验等值准确性角度,中等异常能力情境下,测验等值系数与分数的准确性表现均不如另外两种情境;且在中间分数段,各测验等值结果存在较为明显差异。相较于传统特征曲线方法,信息量加权特征曲线方法表现优异。
在分类一致性与准确性角度,各测验等值结果均较为理想。然而,在中等异常能力分布情境下,测验等值结果的分类误差估计存在较大差异。
研究发现,对于准确性与公平性指标,中等异常能力分布情境下测验等值表现均不如其他情境。同时,在测验分数角度,中间分数段的测验等值结果间也存在较大差异。根据概率分布,在标准正态分布条件下,[-1.1,1.1]区间(模拟研究的中等异常能力情境)大概包括72.87%的考生,而[-3,-1.1]和[1.1,3]区间(模拟研究的极端异常能力情境)大约共包括26.84%的考生。这也就意味着,考生代表性不佳(极端异常)情境下测验等值表现,反而优于代表性适中(中等异常)情境下测验等值表现。推测这主要是因为,相较于中等异常能力情境,在极端异常能力情境中,考生能力分布范围更宽(中等异常为2.2,极端异常为3.6)。无论是传统方法还是信息量加权方法,其测验等值系数的计算均需要求解损失函数[12-14]。而在损失函数中,各能力点的权重一般取相同值(详见“1.1 IRT测验等值方法”相应公式),这也是目前一些主流测验等值软件(包)采用的设定,如equateIRT[32]、plink[33]等。同时,比较了基于均匀分布与正态分布的损失函数所得测验等值系数,结果并未发现明显差异(该结果未在论文中呈现)。因此,测验等值有利于分数区间更广的极端异常条件。而对于能力分布无异常与极端异常两种情境下的结果,无论是在等值系数、测验分数,还是分类一致性与准确性角度,虽然其存在差异,但相较之下并不明显(详见表1-表4、图1与图3)。可见,在测验等值的理论与实践中,当中等能力水平考生群体占比较大时,需注意结果的解读,从多角度确保准确性与公平性。
在本研究中,分类一致性与准确性的真值均达到0.9以上,可间接体现出模拟研究的可靠性。需要说明,对于分类误差指标,本研究采用基于等值估计值与真值的差异绝对值衡量测验等值分类误差。该数值越小,代表分类效果越好,测验的公平性得以保障。但在常见的分类误差研究中,一致性与准确性指标数值越大,代表分类误差越小[18,19]。本研究未采用此种思路,主要是因为基于测验等值结果的分类一致性与准确性并非越高越好,而是要与其真值一致。设想这样一种情况,测验等值后,所有考生均为0或100分。那么,不管如何设定划界分数,分类一致性和准确性均会非常理想(考生被完美分类)。但此种情况与测验等值实际明显不符。故而,本研究计算分类一致性与准确性估计值与真值的相对差异,而非绝对表现,用以衡量各测验等值结果的公平性。
未来可关注多级或混合评分题型测验等值情境下的准确性与公平性。同时,除考生能力分布异常外,在多次测试结果的等值中,题目亦有可能出现漂移、增删等异常情况。后续研究可深入探讨测验等值在题目异常,甚至是考生与题目均存在异常的复杂情境中的准确性与公平性。
参考文献:
[1] Kolen M J,Brennan R L. Test Equating,Scaling,and Linking:Methods and Practices [M]. Springer Science amp; Business Media,2014.
[2] Barrett M D,van der Linden W J. Estimating Linking Functions for Response Model Parameters [J]. Journal of Educational and Behavioral Statistics,2019,44(2):180-209.
[3] He Y,Cui Z. Evaluating Robust Scale Transformation Methods with Multiple Outlying Common Items under IRT True Score Equating [J]. Applied Psychological Measurement,2020,44(4):296-310.
[4] Manna V F,Gu L. Different Methods of Adjusting for Form Difficulty under the Rasch Model:Impact on Consistency of Assessment Results [J]. ETS Research Report Series,2019,(1):1-18.
[5] von Davier M,Yamamoto K,Shin H J,et al.Evaluating Item Response Theory Linking and Model Fit for Data From PISA 2000–2012 [J]. Assessment in Education:Principles,Policy amp; Practice,2019,26(4):466-488.
[6] Andersson B,Wiberg M. Item Response Theory Observed-Score Kernel Equating [J]. Psychometrika,2017,82:48-66.
[7] Depaoli S,Winter S D,Lai K,et al. Implementing Continuous Non-Normal Skewed Distributions in Latent Growth Mixture Modeling:An Assessment of Specification Errors and Class Enumeration [J]. Multivariate Behavioral Research,2019,54(6):795-821.
[8] Ho A D,Yu C C. Descriptive Statistics for Modern Test Score Distributions:Skewness,Kurtosis,Discreteness,and Ceiling Effects [J]. Educational and Psychological Measurement,2015,75(3):365-388.
[9] Zu J,Yuan K H. Standard Error of Linear Observed‐Score Equating for the NEAT Design with Nonnormally Distributed Data [J]. Journal of Educational Measurement,2012,49(2):190-213.
[10] Lai M H,Zhang Y. Classification Accuracy of Multidimensional Tests:Quantifying the Impact of Noninvariance [J]. Structural Equation Modeling:A Multidisciplinary Journal,2022,29(4):620-629.
[11] Setzer J C,Cheng Y,Liu C. Classification Accuracy and Consistency of Compensatory Composite Test Scores [J]. Journal of Educational Measurement,2023,60(3):501-519.
[12] Haebara T. Equating Logistic Ability Scales by a Weighted Least Squares Method [J]. Japanese Psychological Research,1980,22(3):144-149.
[13] Stocking M L. Lord F M. Developing a Common Metric in Item Response Theory [J]. Applied Psychological Measurement,1983,7(2):201-210.
[14] Wang S,Zhang M,Lee W,et al. Two IRT Characteristic Curve Linking Methods Weighted by Information [J]. Journal of Educational Measurement,2022,59(4):423-441.
[15] Lee P,Joo S H,Stark S. Linking Methods for the Zinnes-Griggs Pairwise Preference IRT Model [J]. Applied Psychological Measurement,2017,41(2):130-144.
[16] Köse A,Dogan C D. Parameter Estimation Bias of Dichotomous Logistic Item Response Theory Models Using Different Variables [J]. International Journal of Evaluation and Research in Education,2019,8(3):425-433.
[17] Sen S. Spurious Latent Class Problem in the Mixed Rasch Model:A Comparison of Three Maximum Likelihood Estimation Methods under Different Ability Distributions [J]. International Journal of Testing,2018,18(1):71-100.
[18] Kim S Y,Lee W C. Classification Consistency and Accuracy with Atypical Score Distributions [J]. Journal of Educational Measurement,2020,57(2):286-310.
[19] Park S,Kim K Y,Lee W C. Estimating Classification Accuracy and Consistency Indices for Multiple Measures with the Simple Structure MIRT Model [J]. Journal of Educational Measurement,2023,60(1):106-125.
[20] Lee W. C. Classification Consistency and Accuracy for Complex Assessments Using Item Response Theory [J]. Journal of Educational Measurement,2010,47(1):1-17.
[21] Rudner L M. Expected Classification Accuracy [J]. Practical Assessment Research amp; Evaluation,2005,10(13):1-4.
[22] 陈平,李珍,辛涛,等.标准参照测验决策一致性指标研究的总结与展望[J].心理发展与教育,2011,27(2):210-215.
[23] 宋吉祥,李付鹏,杜海燕,等.试题信息函数对分数等级分类一致性和准确性的影响分析[J].中国考试,2021,(3):22-27.
[24] Furter R T,Dwyer A C. Investigating the Classification Accuracy of Rasch and Nominal Weights Mean Equating with very Small Samples [J]. Applied Measurement in Education,2020,33(1):44-53.
[25] De Ayala R J,Smith B,Norman Dvorak R. A Comparative Evaluation of Kernel Equating and Test Characteristic Curve Equating [J]. Applied Psychological Measurement,2018,42(2):155-168.
[26] Diao H,Keller L. Investigating Repeater Effects on Small Sample Equating:Include or Exclude? [J]. Applied Measurement in Education,2020,33(1):54-66.
[27] Goodman J T,Dallas A D,Fan F. Equating with Small and Unbalanced Samples [J]. Applied Measurement in Education,2020,33(1):34-43.
[28] Kolen M J. Equating with Small Samples(Commentary)[J]. Applied Measurement in Education,2020,33(1):77-82.
[29] Chalmers R P. Mirt:A Multidimensional Item Response Theory Package for the R Environment [J]. Journal of Statistical Software,2012,48(6):1-29.
[30] Lathrop Q N. R Package cacIRT:Estimation of Classification Accuracy and Consistency under Item Response Theory [J]. Applied Psychological Measurement,2014,38(7):581-582.
[31] R Core Team. R:A Language and Environment for Statistical Computing [M]. R Foundation for Statistical Computing,Vienna,Austria,2023.
[32] Battauz M. equateIRT:An R Package for IRT Test Equating [J]. Journal of Statistical Software,2015,68(1):1-22.
[33] Weeks J P. plink:An R Package for Linking Mixed-Format Tests Using IRT-Based Methods [J]. Journal of Statistical Software,2010,35(12):1-33.
The Effect of Ability Distribution Anomalies on Test Linking and Equating from the Perspective of Accuracy and Fairness
Wang Shaojie1" Zhang Minqiang2" Huang Feifei3
1 School of Education,Guangdong University of Education,Guangzhou,Guangdong,510303
2 School of Psychology,South China Normal University,Guangzhou,Guangdong,510631
3 School of Educational Science,Guangdong Polytechnic Normal University,Guangzhou,Guangdong,510665
Abstract:The distribution of examinee abilities is crucial in test linking and equating. This study employs Monte Carlo simulations to investigate the impact of abnormal ability distributions on test linking and equating. The results indicated that the accuracy of test equating was generally satisfactory. Under the condition of moderate abnormal ability distribution,the equating coefficients and score accuracy were inferior to those in other conditions. There were no significant differences in equating score errors at the low and high score ranges. Regarding equating fairness,both classification consistency and accuracy were high. However,in the moderate abnormal ability distribution scenario,the estimated classification errors significantly deviated from the true values. It is essential to address and mitigate the influence of examinee ability distributions on the accuracy and fairness of test linking and equating.
Key words:Ability Distribution,Test Linking and Equating,Accuracy,Fairness
(责任编辑:吴茳)
猜你喜欢
疯狂英语·初中天地(2023年4期)2023-05-18 08:59:38
建材发展导向(2021年10期)2021-07-16 07:13:40
南开管理评论(2021年1期)2021-04-13 01:57:20
新世纪智能(语文备考)(2021年11期)2021-03-08 03:06:12
电脑与电信(2018年12期)2018-03-23 02:37:36
高中生学习·高二版(2016年11期)2016-12-01 20:00:48
疯狂英语(双语世界)(2016年3期)2016-02-27 10:11:55
管理现代化(2016年5期)2016-01-23 02:10:11
中国卫生(2015年3期)2015-11-19 02:53:16
中央民族大学学报(自然科学版)(2014年1期)2014-06-11 01:28:52
