
非均衡数据下制造型企业金融信用风险研究
2025-01-16 00:00:00龙志陈湘州
重庆文理学院学报(社会科学版) 2025年1期


















【摘" "要】 如何有效评估企业金融信用风险状况是当前风险预警领域的研究重点。以我国制造型企业为例,首先通过主成分分析和K均值聚类对企业金融信用风险进行综合打分和等级划分,并深入探究指标重要性;然后使用SMOTE过采样方法解决类别不均衡问题,以提升机器学习模型的预测效果;最后评估各机器学习模型的预测效果,将表现出色的模型作为压力传导模型,通过压力测试分析不同细分行业中企业的抗压能力。研究发现:1)不同信用指标对制造型企业金融信用风险的影响程度存在显著差异,影响最大的是行业偿债能力,影响最小的是企业经营能力;2)在压力测试中,相较于其他模型,MLP模型的整体预测效果最佳,在逐级升压情境下,其PMLP下降幅度和CVMLP上升幅度最小;3)随着压力因素的增加,各细分行业下制造型企业的抗压能力曲线显著下降,若以下降幅度为标准,通用设备制造企业具备较强的抗压能力,而专用设备制造企业的抗压能力较小。研究结果可以帮助利益相关者更有效地评估和管理制造型企业的金融信用风险,降低风险暴露的可能性,促进企业健康发展。
【关键词】 制造型企业;金融信用风险;压力测试;机器学习;非均衡数据
中图分类号:TP183;F274;F832.4文献标志码:A 文章编号:1673-8004(2025)01-0026-20
一、引言
随着全球经济发展向实体经济的回归,制造型企业在经济体系中扮演着至关重要的角色。《中国制造2025》作为国务院部署推进制造业强国战略的重要行动纲领,明确了其战略目标和任务。党的二十大报告也提出要“建设现代化产业体系。坚持把发展经济的着力点放在实体经济上,推进新型工业化,加快建设制造强国、质量强国、航天强国、交通强国、网络强国、数字强国”。然而,制造型企业面临着各种金融信用风险,如资金问题、高融资成本和供应链中断等问题,这可能对企业和金融体系产生严重影响。金融信用风险涉及企业是否能够按时偿还债务、维持健康的财务状况以及在经济压力下的应对能力[1]。金融信用风险具体表现为多种形式,包括违约风险、市场风险和流动性风险等。违约风险与企业的财务健康状况密切相关,金融机构通常会根据企业的财务状况来评估其信用风险水平。若企业的财务状况不佳,可能会被视为高风险客户,这将导致贷款条件更加苛刻,甚至可能面临贷款被拒的风险。尤其是在当前全球金融市场的不确定性和波动性上升的背景下,传统的金融信用风险评估方法可能无法有效应对制造型企业面临的多样化和动态化的风险[2]。因此,采用更灵活高效的方法有效评估制造型企业金融信用风险是一个值得深入研究的重要课题。
压力测试是一种系统性的方法,用于评估金融机构或企业在不同的压力或危机情景下的表现。这种测试旨在模拟各种可能发生的应激情景,包括但不限于金融市场崩盘、经济衰退和自然灾害等,以便更好地理解潜在风险和损失[3]。目前,国内外已开展了一些运用压力测试的金融研究工作。例如,德国的国际合作机构已将水资源压力纳入企业信用风险分析,并进一步将其应用于中美等国家银行的环境风险压力测试。国内的建设银行于2020年声称已开始环境风险压力测试,以火电和化工行业为研究对象,设置了低、中、高三种压力情景,以评估客户评级的变化情况[4]。此外,少数学者还将压力测试应用于碳减排信用风险领域[5]。这些案例表明,压力测试在金融信用风险管理中发挥着关键作用,特别是在面对不确定性和复杂的经济环境时。
近年来,随着科学技术不断发展,机器学习已成为金融机构和企业用于识别、量化和管理风险的有力工具。在金融信用风险评估领域,传统的信用评分模型通常基于历史数据和统计方法,而机器学习则更全面地考虑了大量的非线性关系和因素,并利用大规模数据集更准确地评估企业的信用状况[6]。例如,Abdelmoula[7]应用KNN模型研究了924家企业的信用数据,该模型在信用风险评估方面表现出色;潘永明等[8]通过信息增益模型进行最优特征提取,显著提升SVM模型对企业信用风险的预测能力;Yuan等[9]采用ELDA-RF模型对社交媒体上的公众情绪进行分析,发现公众情绪可显著增强模型对企业信用评级的预测效果。贾颖等[10]将贝叶斯高斯过程(GP)用作XGBoost的超参数优化器,发现 GP优化超参数的方法收敛速度更快,模型对信用风险的预测准确率更高。陈海龙等[11]提出了一种基于BA-SMOTE-FLLightGBM的信用风险预测模型,发现该融合模型具有卓越的违约预测效果。Li等[12]将XGBoost与MLP模型相结合,表明XGBoost特征选择能够显著提升MLP信用风险评估模型的预测准确率。龙志等[13]构建了一种新的融合熵权TOPSIS-FCM-CNN的企业财务风险预警模型,该模型具有很好的预测效果。总体而言,信用风险预警模型正不断得到优化和完善,便于精准地评价企业的信用风险。
综上所述,现有研究通常将压力测试和机器学习分别应用于信用风险分析。然而鲜有研究充分利用二者优势,相互结合并应用于制造型企业金融信用风险预警领域,以便深入分析企业信用风险变化,为利益相关者的投资决策提供有力支持。为此,本文以深证A股2013—2022年制造型企业为例,首先通过主成分分析对信用风险进行评估,运用K均值聚类划分不同风险等级,使用RF等算法和熵值法对指标重要性进行深入分析;其次,采用SMOTE过采样方法解决类别不均衡问题,提升模型在新数据集下的预测效果;再次,进行制造型企业金融信用风险压力测试,以评估各机器学习模型的预测效果,在这一过程中,选择表现出色的MLP模型作为压力传导模型;最后,进行制造型企业金融信用风险抗压能力的测试,对不同细分行业下的制造型企业进行比较分析。
本文在现有研究的基础上将从以下方面获得预期成果:1)有效地将压力测试方法与主流的机器学习模型相融合,应用于制造型企业金融信用风险预警领域,丰富该领域的研究视角和方法;2)解决信用风险预警领域常见的样本类别不均衡问题,并比较不同压力测试下机器学习模型的预测效果,从中选择表现出色的模型,为未来的研究提供有价值的模型选择依据;3)在压力情景不断恶化的实验中,分析不同细分行业下制造型企业的抗压能力,并据此提出相关的金融信用风险防控建议。
二、研究设计
(一)数据来源与样本选择
作为国家经济的重要支柱,制造型企业的信贷措施对于可持续发展至关重要。因此,本文以深证A股2013—2022年制造型企业为例,共计1 987家。在数据处理方面,对原始数据集进行如下操作:1)剔除指标缺失比例大于三分之一的企业样本;2)采用分组均值法填充部分缺失值。最终得到8 254个样本,共1 749家。数据均来源于CSMAR数据库。
借鉴目前已有文献的做法,采用简单随机抽样,将数据集按照7:3的比例分为训练集和测试集。训练集用于机器学习模型的学习和参数调整,而测试集用于评估模型的分类预测性能。实验均在基于Pytorch深度学习框架的PyCharm编程软件上完成。
(二)指标选取
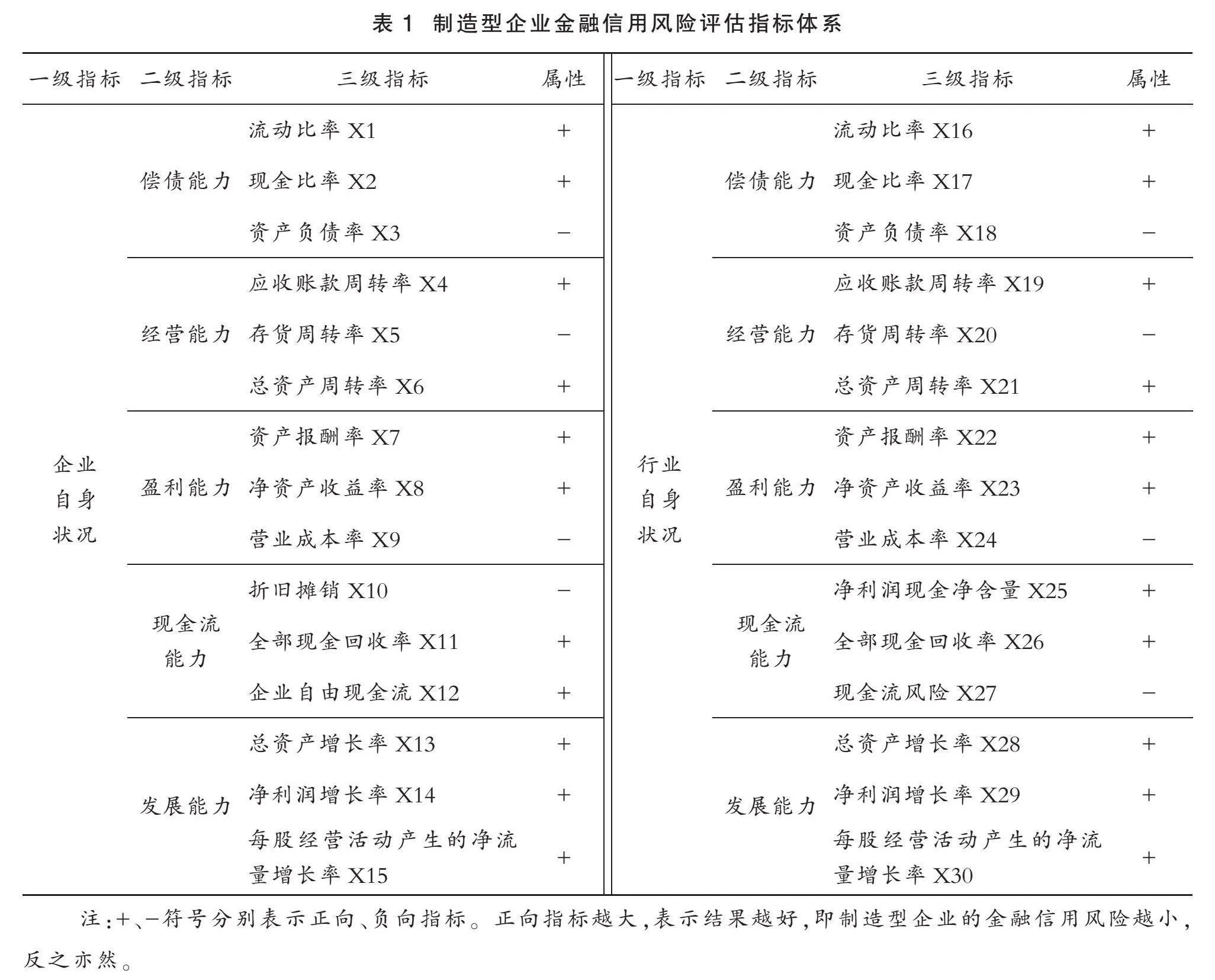
以往研究表明,财务比率指标在企业信用风险评估中具有重要的参考价值[14-17]。但考虑行业竞争程度对企业的潜在影响,可能会对其盈利能力产生不利影响,从而导致偿债能力下降,信用风险增加[13]。因此,本文基于企业和行业自身角度,从偿债能力、经营能力、盈利能力、现金流能力和发展能力这四个方面选取30个信用指标,以全面反映企业的经营绩效、财务风险和信用状况,如表1所示。
(三)基于金融信用风险预警模型的压力测试设计
1.综合评分与等级划分
现有研究中,学者通常采用“是否被ST或*ST处理过”的标准,将企业的信用状况简单归为“好”或“坏”。然而,这与实际情况并不完全相符。此外,这种二分法可能会限制模型为利益相关者提供更加精准的风险管控效用。因此,有必要对企业信用风险进行更细致划分,并建立多类别预测的信用风险评估模型。
基于以上分析,本文首先采用主成分分析法[18](Principal Component Analysis,简称PCA)来计算各制造型企业金融信用风险的综合得分Gi。其中,若综合得分Gi越高,意味着该制造型企业的金融信用风险越低,反之亦然。然后,通过应用K均值聚类[19],对所有制造型企业的综合得分Gi进行相似度分类,将信用风险分为A、B、C、D、E五个等级标签,分别表示信用风险低、较低、中等、较高、高。
2.综合评分与等级划分
不同的信用指标对模型预测结果的影响程度存在显著差异。为更深入地理解各信用指标在整个制造业或者不同信用风险等级企业中的重要性,从而协助各利益相关者制定科学合理的投资决策,需进行详细分析。关于RF、XGBoost和CatBoost集成算法的介绍,详见第3小节。因此,本文采用RF、XGBoost和Catboost集成算法来计算各信用指标的特征重要性。
3.机器学习模型选择
目前在面对多分类问题时,企业信用风险预警模型主要分两类:一是基于统计模型的判别分类方法,包括线性判别分析、Probit回归和Logistic回归等;二是基于机器学习的方法,包括最近邻分类、决策树和支持向量机等。第一类模型通常对输入数据具有较高的要求,如要求数据符合或近似正态分布。而第二类模型可从大量复杂数据中自动学习非线性和非平稳关系,故具备更出色的预测效果。
为了深入探究压力测试中不同模型的预测效果变化,本文选择KNN、SVM(Linear)、SVM(Rbf)、RF、XGBoost、LightGBM、MLP机器学习算法构建信用风险预警模型。KNN通过构建特征向量来进行回归或分类。在给定的测试样本情境下,KNN会利用某种距离度量方法来选择训练集中与之最相近的K个训练样本,然后以这K个“邻居”的信息为依据进行预测;SVM通过在特征空间中寻找最优超平面来解决分类问题。该算法旨在最大化数据样本中支持向量与超平面之间的间隔距离,同时也能借助非线性核函数来处理数据的线性不可分问题。RF、XGBoost和LightGBM为集成算法,它们基于多个决策树模型,通过诸如Bagging等策略方法进行集成学习,以提高分类或回归的性能。MLP作为前馈神经网络模型,由多个神经元层组成,每个神经元层之间实现全连接,通过强大的算法不断优化神经元之间的连接,从而实现信息处理。
4.模型评估指标
本研究中制造型企业金融信用风险预警为多分类问题。因此,采用上述机器学习模型,并观察其在预测效果上的变化。以下是所需的模型评估指标。
1)准确性检验。假设Pi表示第i个模型的企业总识别率,P(j=A,B,C,D,E)表示第i个模型的金融信用风险A、B、C、D、E等级企业样本识别率,Pi表示第i个模型的企业样本识别率的平均水平,其计算公式为:
式中,Pi值越高,表示第i个模型的准确性越高,反之亦然。
2)全面性检验。良好的模型预测效果不仅具备较高的Pi值,还需充分考虑该模型分别对信用风险为A、B、C、D、E等级企业样本的预测效果。假设第i个模型识别率P(j=A,B,C,D,E)的标准差和变异系数分别为σi、CVi,计算公式为:
CVi=σiPi(3)
式中,i=1,2,…,7分别对应KNN、SVM(Linear)、SVM(Rbf)、RF、XGBoost、LightGBM、MLP模型,j=A,B,C,D,E。变异系数CVi值越小,即第i个模型的识别率Pi、P(j=A,B,C,D,E)之间的相对离散程度越小,表明第i个模型对不同信用风险等级企业的预测效果越均衡,模型的全面性越好,反之亦然。
此外,模型性能综合评估原则的重要性排序为:准确性>全面性。
5.制造型企业金融信用风险的压力测试
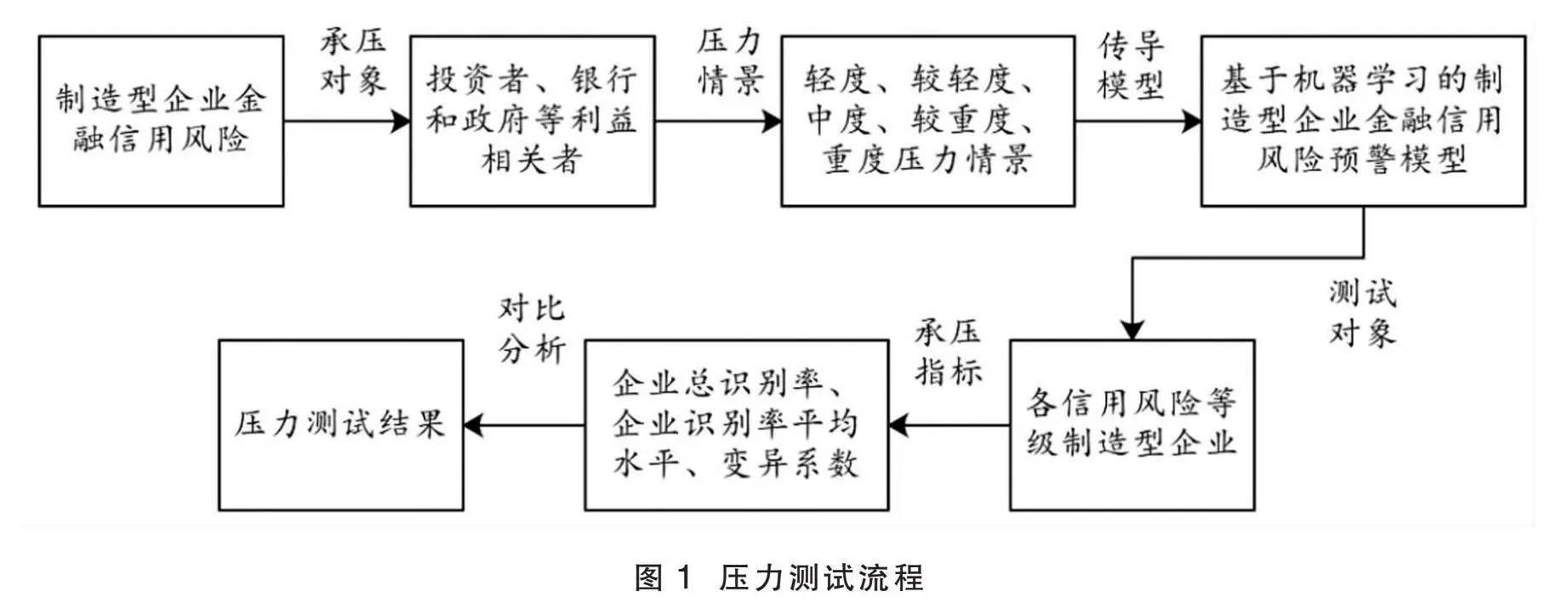
本文基于不同的压力情景,对利益相关者可能面临的制造型企业金融信用风险进行压力测试。压力测试流程如图1所示。
图1" 压力测试流程
1)压力情景构建。借鉴已有文献的研究[5,20-23],本文基于历史数据波动率的方法来定义不同的压力情景。首先,将经过数据预处理的数据集作为基准情景。然后,在基准情景的基础上以百分之五的标准对每个信用指标分别恶化1个、2个、3个、4个、5个百分之五,分别表示轻度、较轻度、中度、较重度、重度压力,共5种定义的压力情景。需要说明的是,本文以“正向指标减去百分之五”来表示“恶化”效果,以“负向指标加上百分之五”来表示“恶化”效果。以重度压力为例,本文用如下公式来代表“恶化”效果:
正向指标恶化效果=X×(1-5×5%)(4)
负向指标恶化效果=X×(1+5×5%)(5)
其中的轻度压力情景被定义为比目前实际情况更具有挑战性但仍有可能发生的温和衰退情景。而重度压力情景则被描述为极端的情况,但仍具备发生的潜在可能性,详细情况如表2所示。
2)压力传导模型建立。压力传导模型通常采用两种方法,即自下而上法和自上而下法。在银行内部,金融风险分析师主要采用自下而上的方法。然而,在金融机构之外,研究人员通常面临着不完整的数据,难以建立完整的数学模型来确定它们之间的逻辑关系。因此,本文选择自上而下的方法。自上而下的压力测试通常由研究者根据相关的知识背景来设定压力情景和关键假设,其需要的人力和物力资源较少。
在研究压力因素对测试指标的影响时,可选择两种方法。一是利用统计模型来建立相应的传导关系,例如自回归模型、Wilson模型等;二是使用机器学习模型对各企业进行压力测试,然而这方面的文献和讨论相对有限。例如,佟孟华等[5]在其研究中采用FM模型来对工业企业的碳减排信用风险进行压力测试。因此,本文依据第二种方法,选择KNN、SVM(Linear)、SVM(Rbf)、RF、XGBoost、LightGBM和MLP模型作为压力传导模型,以开展压力测试。
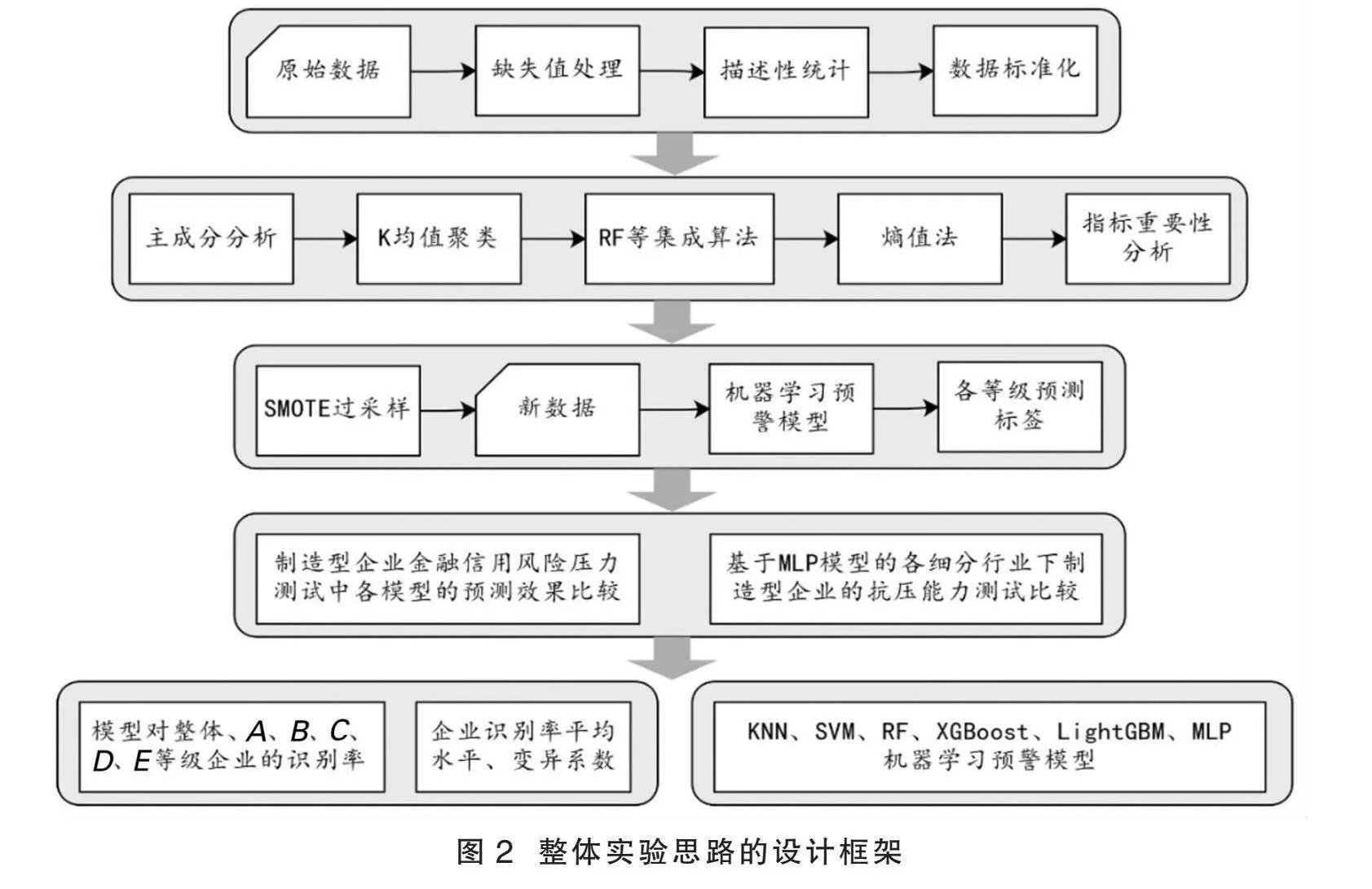
(四)整体设计流程
本文将整体实验思路的研究流程设计成框架图,如图2所示。
三、实证分析
(一)基于PCA的综合评分
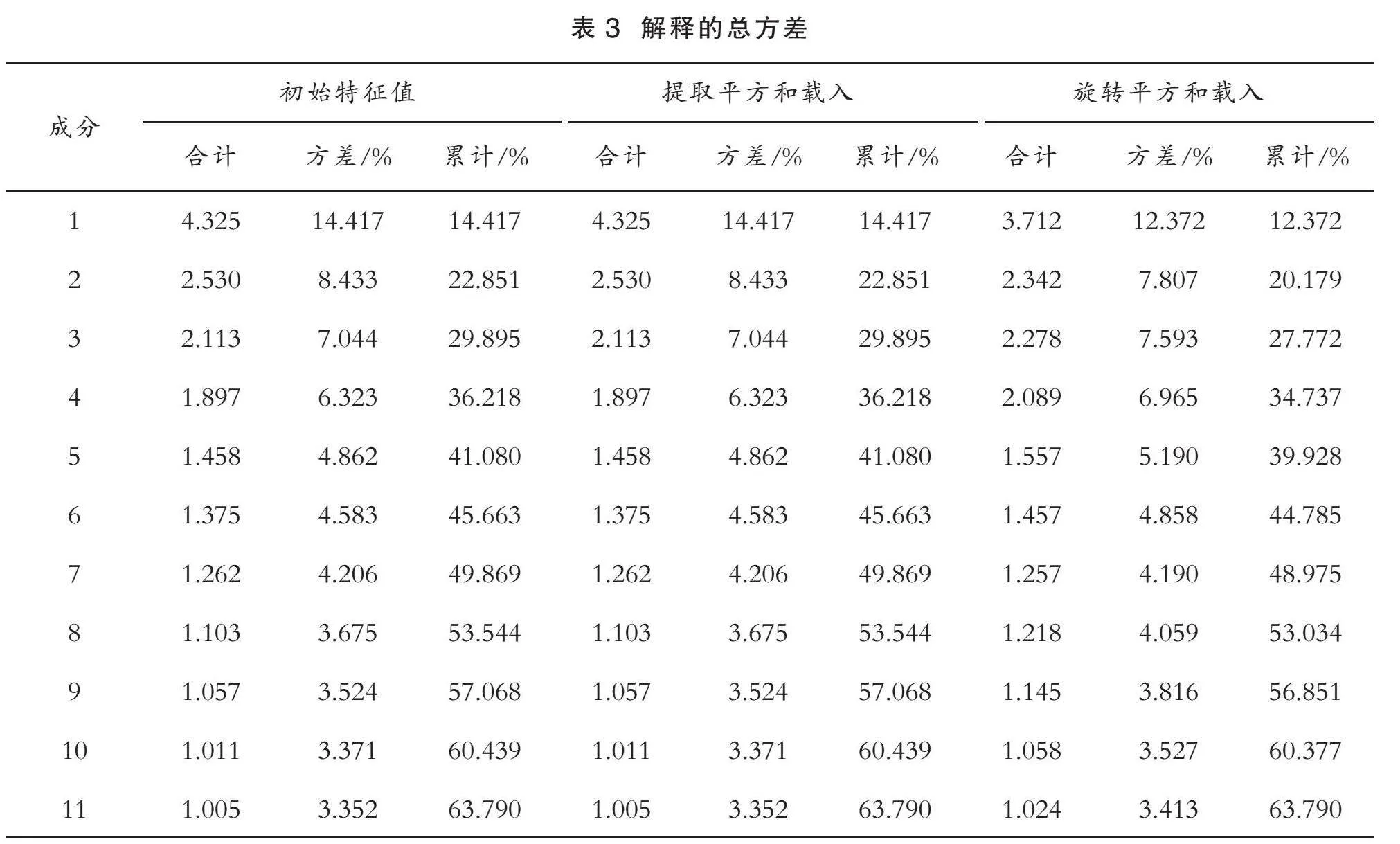
为获得各制造型企业的金融信用风险的综合评分Gi,本文采用PCA进行相关实验。首先,在进行PCA之前,需要对指标数据进行Z-score标准化处理,以消除量纲影响;然后,将其进行KMO和Bartlett球形检验,以判断该数据集是否值得进行PCA实验。KMO和Bartlett球形检验结果显示,KMO样本测度值为0.646且大于0.5,Bartlett球形检验结果中显示p值小于0.05,拒绝原假设,表明本文选取的信用指标间重叠度较高,存在一定的相关性,可从中提取数量较少的主成分因子;最后,对该数据集进行PCA实验,结果如表3所示。
表3报告了各主成分的解释方差的变化情况。由表3可知,根据特征值法,前11个主成分的特征值大于1,并且方差累计贡献率达到63.79%,表明前11个主成分能够较好地代表原来30个信用指标所蕴含的信息。
根据不同的方差贡献率作为主成分的权重,可以计算出各制造型企业的金融信用风险的综合得分Gi:
若综合得分Gi越高,表明该制造型企业的金融信用风险越低,反之亦然。本文将提取的主成分按照贡献权重计算出综合得分Gi,其描述性统计结果如表4所示。
由表4可知:在企业样本75%分位数时,综合得分Gi为-0.161 9,表明至少有3/4的制造型企业金融信用风险表现得分都为负数;均值为-0.002 6,标准差为0.480 2,最小值为-4.215 6,最大值为0.161 9,表明各制造型企业的金融信用风险表现存在明显差异。
(二)基于K均值聚类的等级划分
为获得各制造型企业的金融信用风险的等级标签,本文采用K均值聚类将信用风险划分为A、B、C、D、E共5个等级标签,分别表示信用风险低、较低、中等、较高、高。首先,为验证综合评分Gi在五类制造型企业之间是否存在显著差异,采用ANOVA检验方法对该指标进行显著性检验。检验结果表明,对于综合评分Gi指标,聚类差异性检验结果中p值小于0.05,在该水平下呈现显著性,拒绝了原假设,表明综合评分Gi指标在K均值聚类分析划分后的类别(风险等级)之间存在显著差异,证明了K均值聚类的合理性。
表5报告了经过K均值聚类后各信用风险等级企业的详细分布情况。从表5可以发现,K均值聚类后,各风险等级企业的综合评分Gi的平均分差分别为0.711 5、0.603 0、0.370 2和2.718 5。值得注意的是,风险等级为D和E的制造型企业的平均分差最大,而E等级制造型企业的标准差最高,达到了0.877 7,表明这两类企业间在经营方式和战略目标上存在明显差异,导致了金融信用风险的显著差异。因此,利益相关者应特别关注E等级制造型企业的金融信用风险波动,以作出更为精准的投资决策。
此外在表5中,各信用风险等级企业的数量分布极不均衡。以信用风险等级为C的制造型企业为例,其数量达到3 710 家,而信用风险等级为E的制造型企业仅有16家。这易导致模型在分类预测任务中对C级企业数据过度拟合,对E级企业数据欠拟合,不利于结果分析。为解决这一类别的不均衡问题,本文使用SMOTE过采样算法。
(三)指标重要性分析
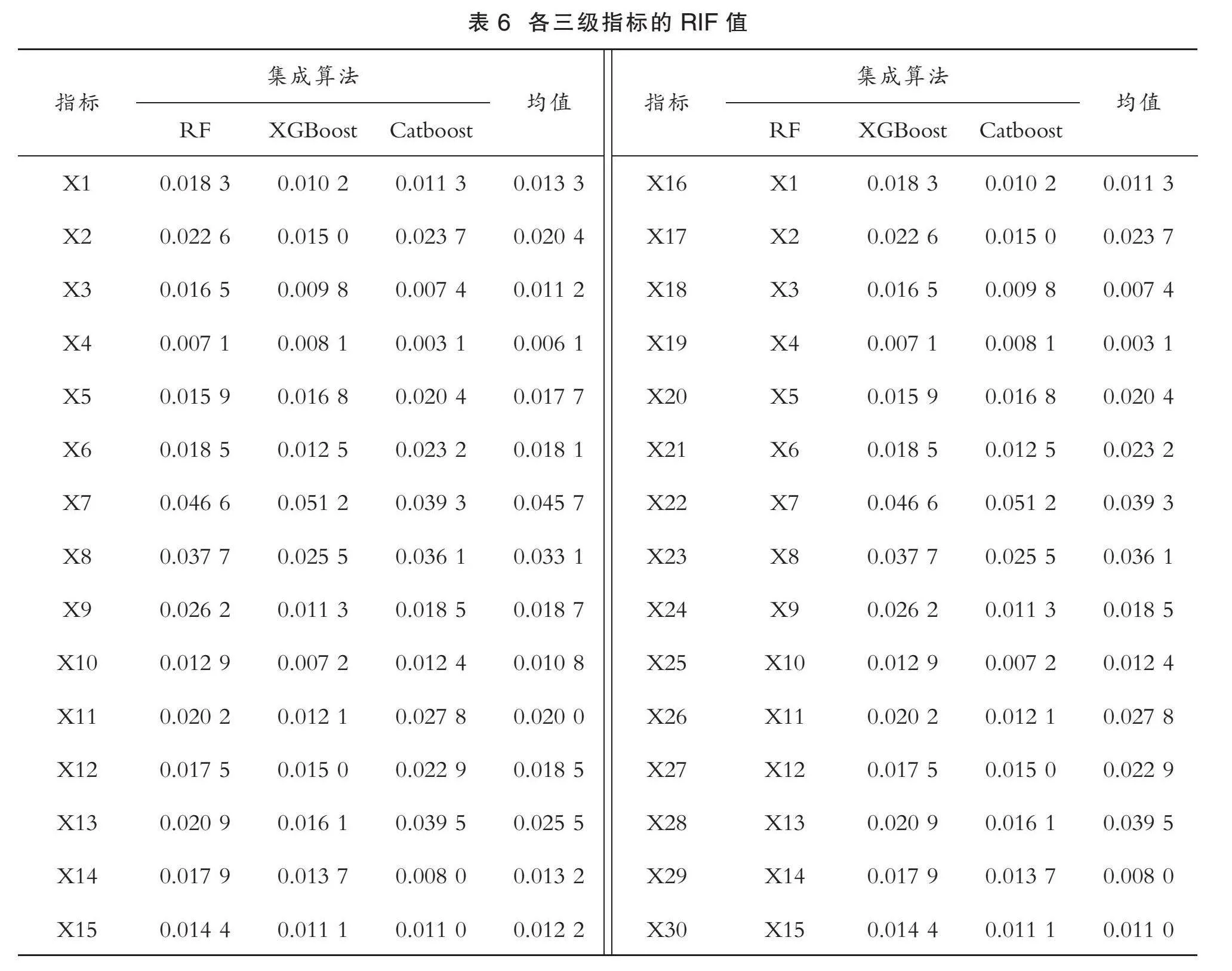
为深入了解制造型企业中的信用风险特征,本文采用RF、XGBoost和Catboost集成算法进行指标重要性分析。RF、XGBoost和Catboost能够基于特征(本文指30个信用指标)被采用于分割节点的次数来生成特征重要性(RFI)[24]。其中,RFI的数值越高,则表示该特征的重要性越高;反之亦然,结果如表6所示。
表6为基于机器学习算法的各三级指标的RIF数据。由表6得知,各个三级指标的RIF存在明显的差异。具体地,RFI值较大的前5个三级指标分别是行业现金比率X17、行业资产负债率X18、行业营业成本率X24、行业流动比率X16、行业资产报酬率X22,RFI值较小的后5个三级指标分别是企业每股经营活动产生的净流量增长率X15、行业全部现金回收率X26、企业资产负债率X3、企业折旧摊销X10、企业应收账款周转率X4。结果表明,X17、X18、X24、X16和X22指标对制造型企业金融信用风险的影响程度较大,而X15、X26、X3、X10和X4指标的影响程度较小。因此,利益相关者应深入厘清各信用指标的重要性,重点关注RFI值较高的信用指标,有助于自身做出更加科学合理的投资决策。
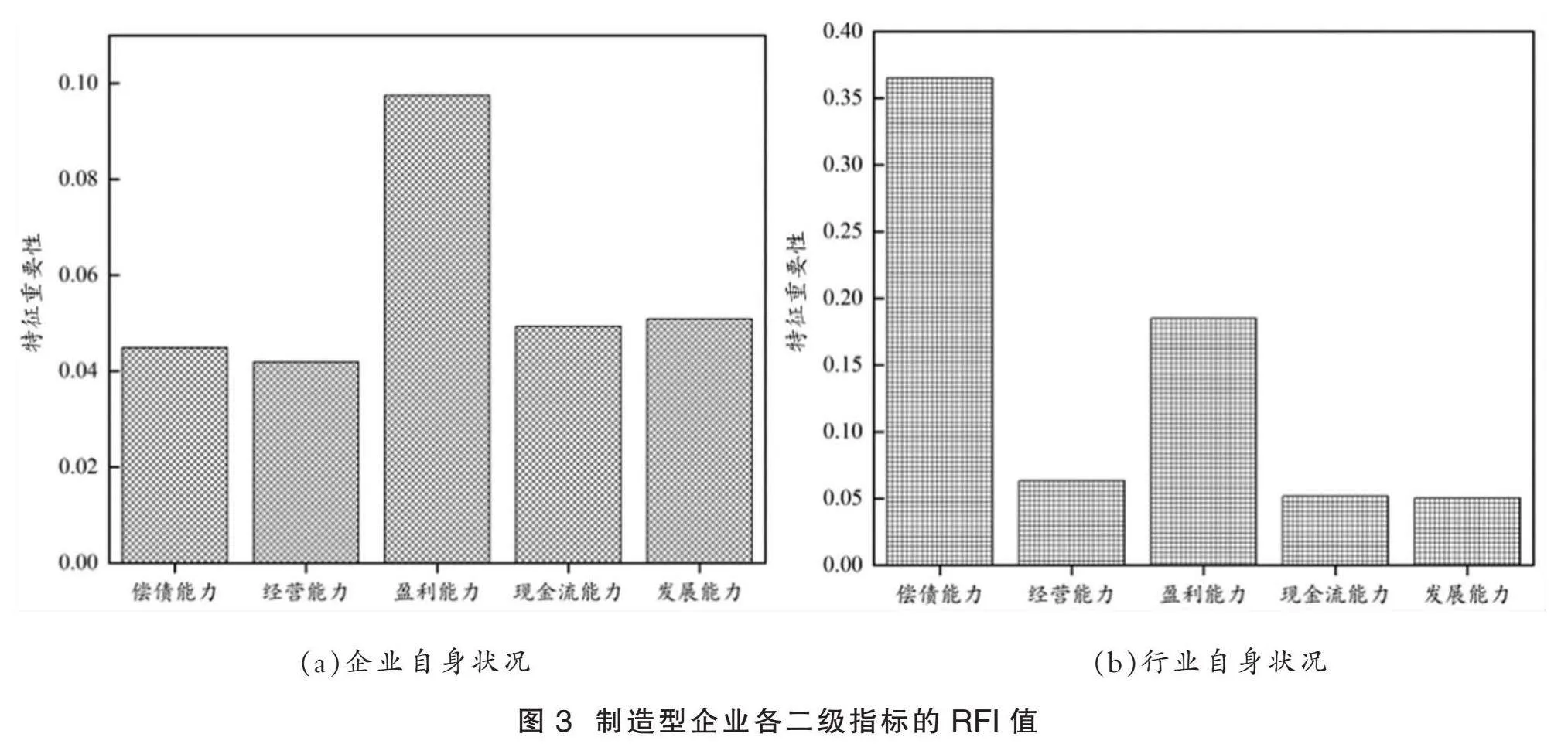
此外,为更加清晰地了解制造型企业各二级指标的RFI值,本文根据表6中的“均值”分别汇总并计算出各二级指标的RFI值,结果如图3所示。
图3显示了制造型企业的各二级指标的RFI大小分布情况,纵坐标表示指标的RIF值。由图3可以发现,“行业自身状况”包含的二级指标整体的RFI值明显高于“企业自身状况”。本文中,按照RFI值从大到小的顺序对各二级指标进行排列:
行业偿债能力>行业盈利能力>企业盈利能力>行业经营能力>行业现金流能力>
企业发展能力>行业发展能力>企业现金流能力>企业偿债能力>企业经营能力
可以看出,在制造型企业金融信用风险预警中,最重要的影响因素是所在行业的整体偿债能力和盈利能力,因为这些因素代表了整个行业的发展前景。可见,金融信用风险的评估不仅依赖于企业自身的经营状况,还需要考虑所在行业的整体盈亏情况,如此才能对制造型企业的金融信用风险进行全面评估。
为不同风险等级的企业准确提供针对性的建议,以探究在不同等级中发挥关键作用的二级指标。因此,本文通过熵值法分析各等级企业金融信用风险的二级指标的权重,如图4所示。
图4显示了在不同风险等级企业下应用熵权法的各二级指标的权重,纵坐标表示指标的权重。发现各二级指标在不同风险等级企业中的权重存在显著差异。例如,在“企业自身状况”中,“盈利能力”在A等级企业中的权重值为0.147 4,而在E等级企业中的权重值为0.037 2,差值为0.110 2,二者大小存在明显差异;在“行业自身状况”中,“发展能力”在E等级企业中的权重值为0.174 9,而在D等级企业中的权重值为0.093 3,差值为0.081 6,二者大小依旧存在较大差距。导致这一结果的原因可能是业务性质,因为不同行业的企业在碳减排信用风险具有不同的业务性质。特别地,某些行业可能对碳减排有着更高的要求,因此特定的指标在这些行业中可能会更加突出。除此之外,还可能受市场条件、企业规模和政策法规等因素影响。这意味着可以为深入的风险评估提供重要线索,有助于不同企业更好地理解和应对其特定背景下的关键风险因素,以制定更具有针对性的风险管理策略和决策。
(四)模型分类预测
1.基于SMOTE的少数类别样本扩充
经K均值聚类后,不同信用风险等级的企业数量分布为A∶B∶C∶D∶E,对应比例为363∶1 303∶3 710∶2 862∶16。显然,A和E等级企业的数量有限,呈现出类别高度不均衡的特点。这类问题易导致机器学习模型出现过拟合现象,即模型过多地拟合B、C和D级企业的数据,而对A和E级企业的数据拟合不足,降低了模型的预测效果。
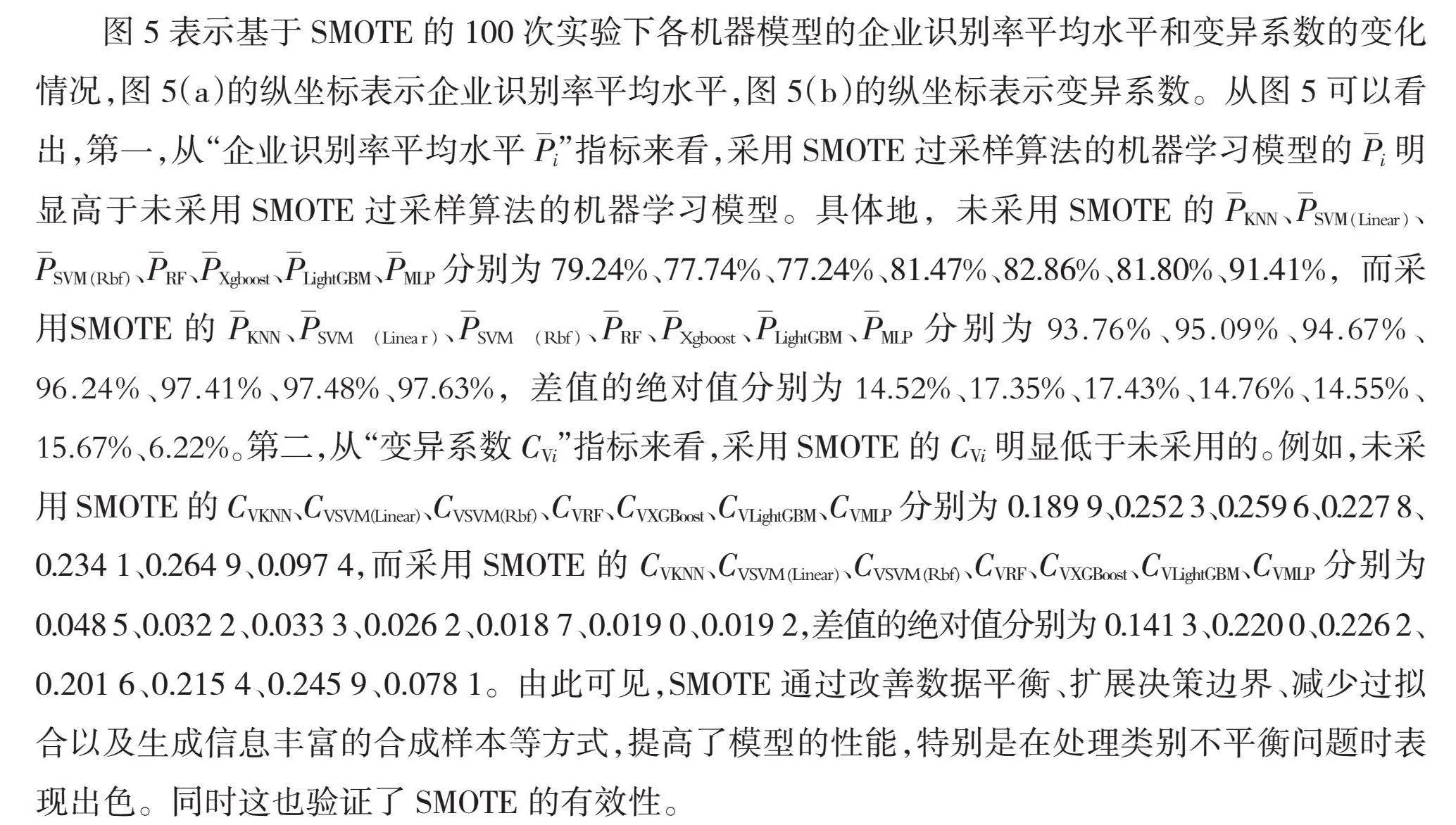
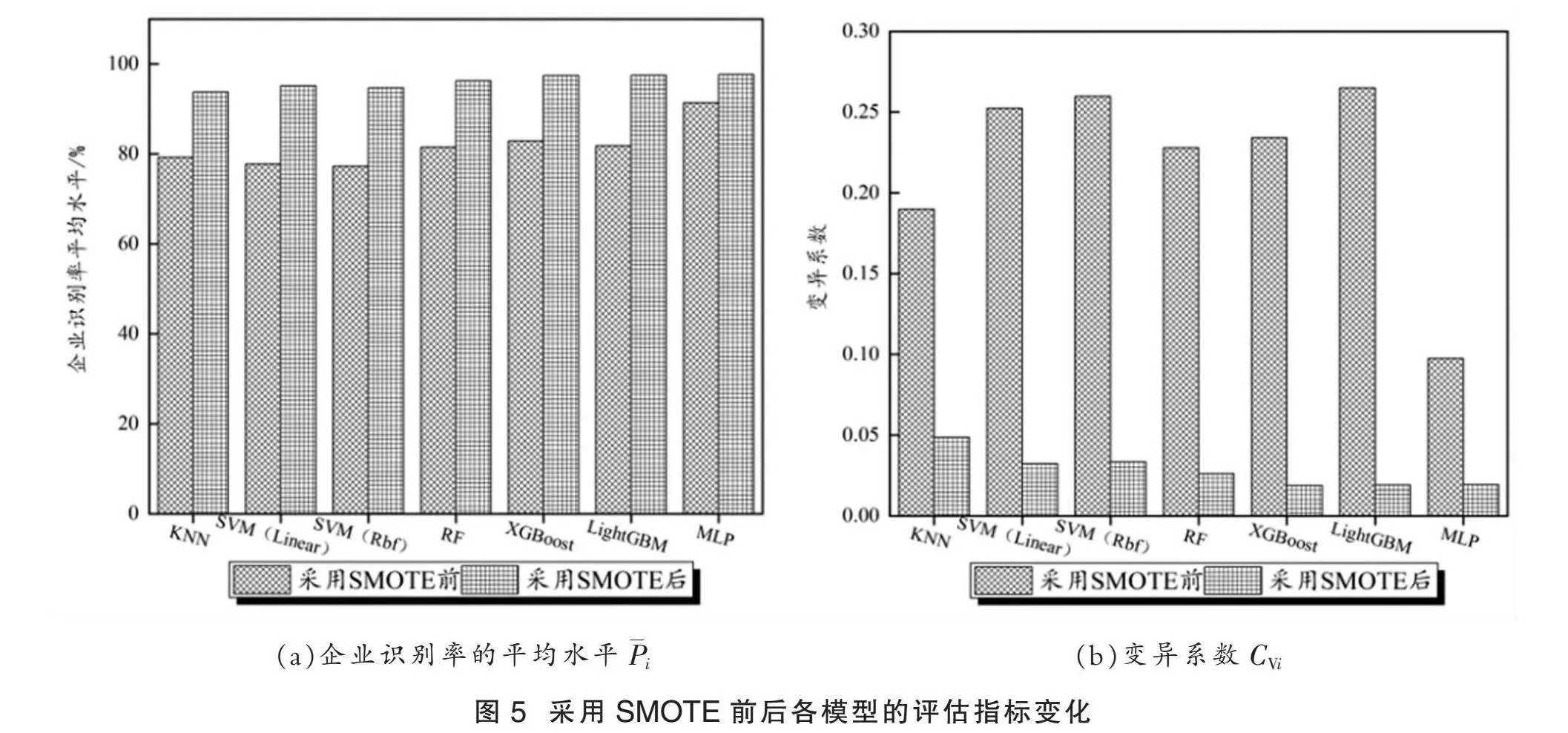
综上所述,为解决样本类别不均衡问题,本文通过SMOTE对少数类别样本进行均衡处理。SMOTE是Chawla 等[25]于2002年提出的,通过生成额外的合成样本来增加少数类别的样本数量,并且能够保持样本的原有分布特征,平衡数据集,从而改善模型的预测性能。同时,相比于欠采样算法,过采样方法更适合在数据集较大、类别不平衡的情况下使用,而欠采样可能会导致信息丢失[26]。为保证模型预测结果的稳健性,取100次实验的均值作为最终结果,如图5所示。
图5表示基于SMOTE的100次实验下各机器模型的企业识别率平均水平和变异系数的变化情况,图5(a)的纵坐标表示企业识别率平均水平,图5(b)的纵坐标表示变异系数。从图5可以看出,第一,从“企业识别率平均水平Pi”指标来看,采用SMOTE过采样算法的机器学习模型的Pi明显高于未采用SMOTE过采样算法的机器学习模型。具体地,未采用SMOTE的PKNN、PSVM(Linear)、PSVM(Rbf)、PRF、PXgboost、PLightGBM、PMLP分别为79.24%、77.74%、77.24%、81.47%、82.86%、81.80%、91.41%,而采用SMOTE的PKNN、PSVM(Linear)、PSVM(Rbf)、PRF、PXgboost、PLightGBM、PMLP分别为93.76%、95.09%、94.67%、96.24%、97.41%、97.48%、97.63%,差值的绝对值分别为14.52%、17.35%、17.43%、14.76%、14.55%、15.67%、6.22%。第二,从“变异系数CVi”指标来看,采用SMOTE的CVi明显低于未采用的。例如,未采用SMOTE的CVKNN、CVSVM(Linear)、CVSVM(Rbf)、CVRF、CVXGBoost、CVLightGBM、CVMLP分别为0.189 9、0.252 3、0.259 6、0.227 8、0.234 1、0.264 9、0.097 4,而采用SMOTE的CVKNN、CVSVM(Linear)、CVSVM(Rbf)、CVRF、CVXGBoost、CVLightGBM、CVMLP分别为0.048 5、0.032 2、0.033 3、0.026 2、0.018 7、0.019 0、0.019 2,差值的绝对值分别为0.141 3、0.220 0、0.226 2、0.201 6、0.215 4、0.245 9、0.078 1。由此可见,SMOTE通过改善数据平衡、扩展决策边界、减少过拟合以及生成信息丰富的合成样本等方式,提高了模型的性能,特别是在处理类别不平衡问题时表现出色。同时这也验证了SMOTE的有效性。
此外,尽管SVM(Rbf)模型在“企业识别率平均水平Pi”上的提升幅度最高、LightGBM模型在“变异系数CVi”上的下降幅度最大,然而,就模型整体的预测效果而言,MLP模型的表现最为出色。这是因为MLP模型具备以下优势:1)在模型反向传播过程中,MLP模型能够利用梯度下降算法来较好地解决各指标的贡献度分配问题[27];2)通过引入激活函数(如Relu函数),MLP模型具有较强的拟合能力,能够逼近现实中任意复杂的非线性函数。考虑到MLP模型具备出色的预测效果,本文将MLP模型选作压力传导模型。
2.基于机器学习模型的金融信用风险压力测试
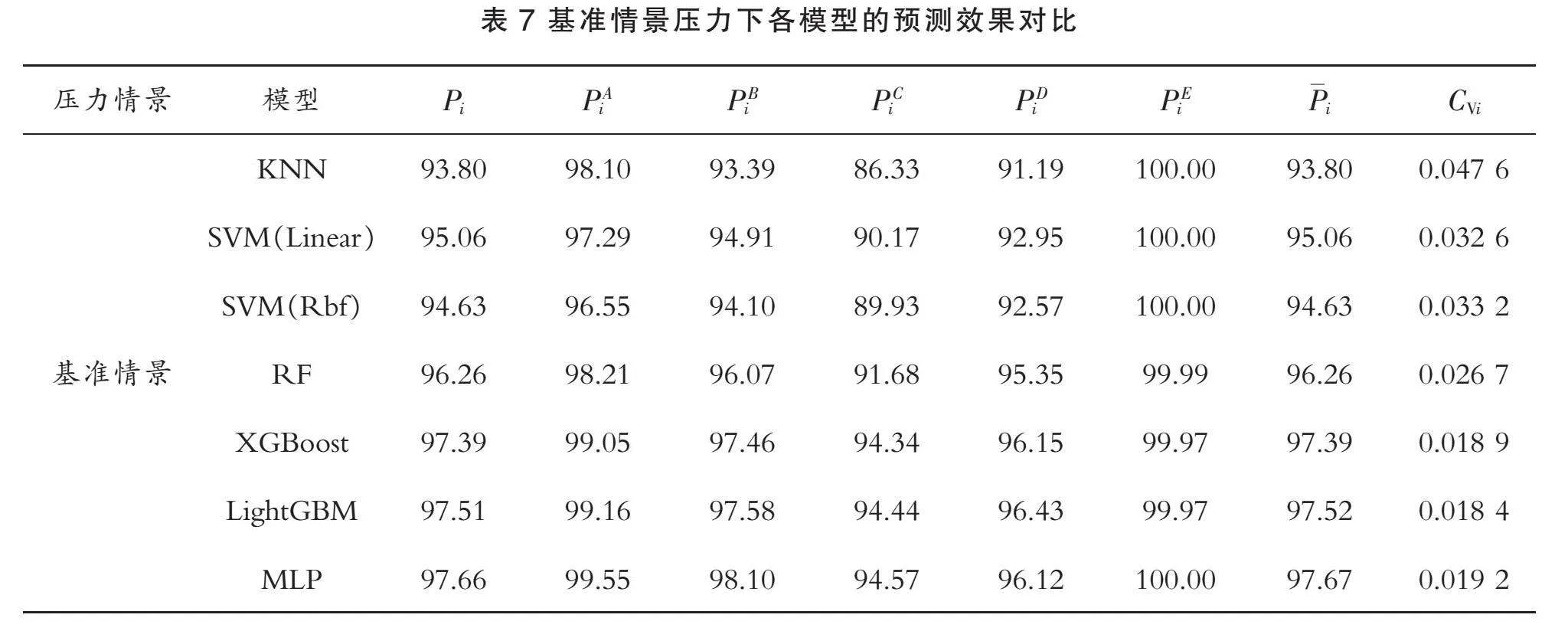
为评估各机器学习模型在制造型企业金融信用风险压力测试中的预测效果,本文设置五种压力情景。具体地,本文以图5中的实验结果作为基准情景,然后再设置其他五种压力情景。具体的压力测试结果如表7至表12所示。
由表7可知,对于模型的准确性,从“企业识别率平均水平Pi”一列看,由大到小进行排序为:
PMLP>PLightGBM>PXGBoost>PRF>PSVM(Linear)>PSVM(Rbf)>PKNN>90%
MLP模型的准确性排名第一,获得最佳的分类效果;对于模型的全面性,已知变异系数CVi越小,数据的相对离散程度越低,即模型的全面性越好。按照CVi由大到小排序为:
CVKNN>CVSVM(Rbf)>CVSVM(Linear)>CVRF>CVMLP>CVXGBoost>CVLightGBM>0.01
本文对变异系数CVi≥0.02的模型不予考虑,则有0.02>CVMLP>CVXGBoost>CVLightGBM>0.01。综上,根据“准确性>全面性”的原则,在基准情景下MLP模型更适用于制造型企业金融信用风险预警领域。
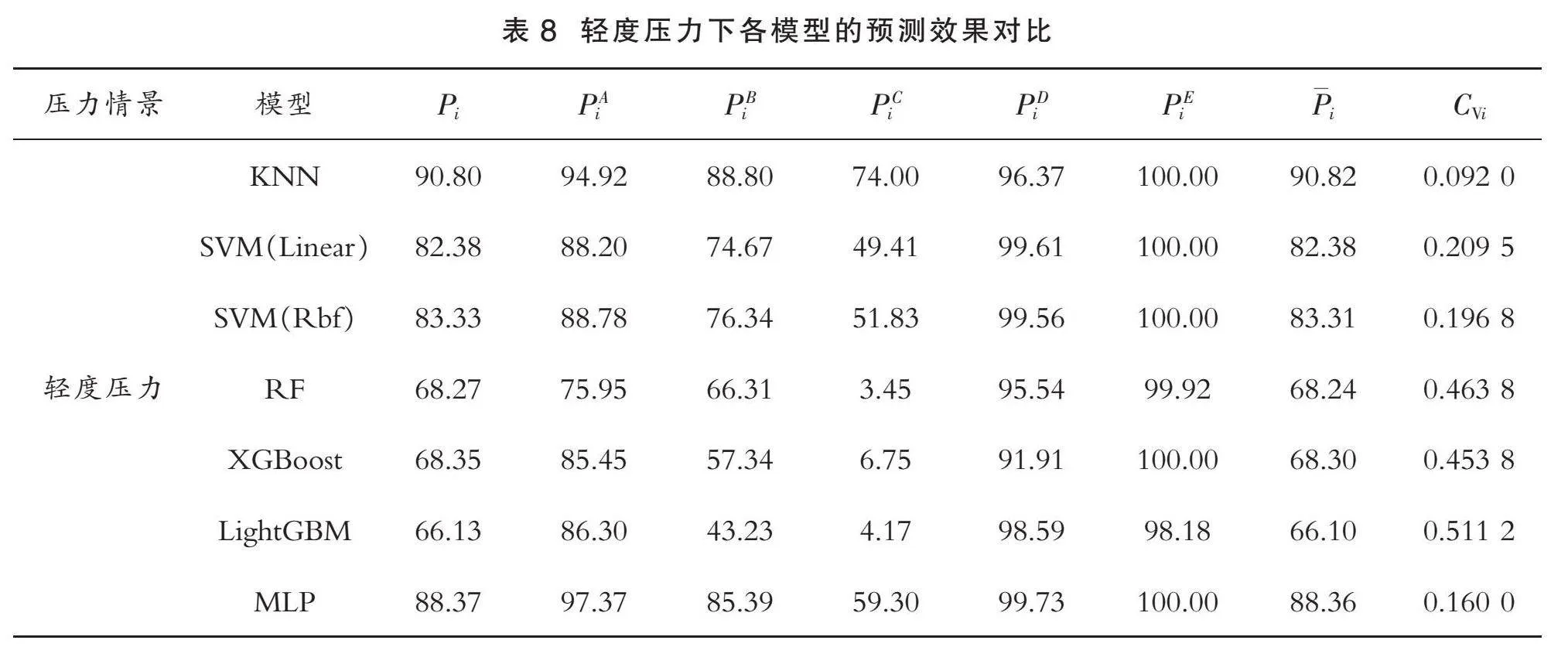
由表8可知,对于模型的准确性,从“企业识别率平均水平Pi”一列看,由大到小进行排序为:
PKNN>PMLP>PSVM(Rbf)>PSVM(Linear)>PXGBoost>PRF>PLightGBM>65%
KNN模型的准确性排名第一,获得最佳的分类效果;对于模型的全面性,已知变异系数CVi越小,数据的相对离散程度越低,即模型的全面性越好。按照CVi由大到小排序为:
CVLightGBM>CVRF>CVXGBoost>CVSVM(Linear)>CVSVM(Rbf)>CVMLP>CVKNN>0.09
本文对变异系数CVi≥0.2的模型不予考虑,则有0.2>CVSVM(Rbf)>CVMLP>CVKNN>0.09。综上,根据“准确性>全面性”的原则,在轻度压力情景下,KNN模型更适用于制造型企业金融信用风险预警领域。
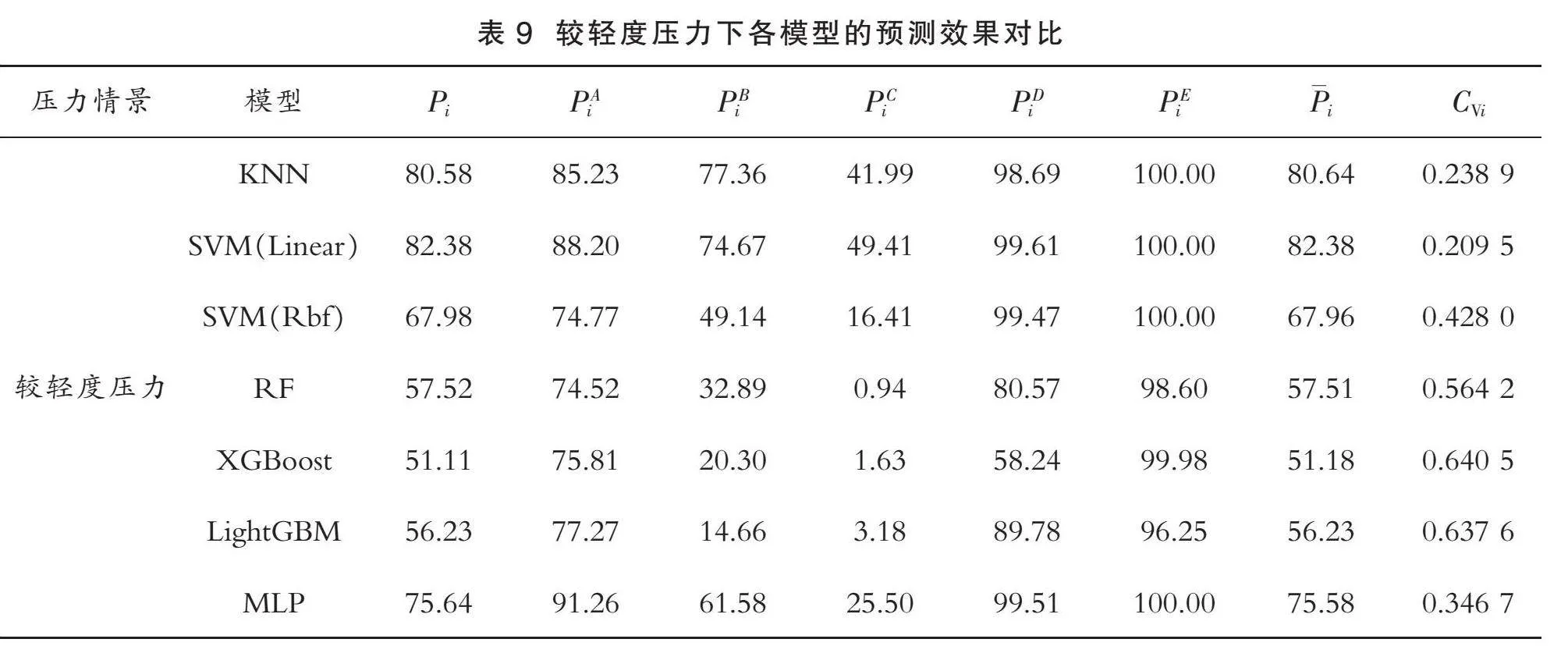
由表9可知,对于模型的准确性,从“企业识别率平均水平Pi”一列看,由大到小进行排序为:
PSVM(Linear)>PKNN>PMLP>PSVM(Rbf)>PRF>PLightGBM>PXGBoost>50%
SVM模型的准确性排名第一,获得最佳的分类效果;对于模型的全面性,已知变异系数CVi越小,数据的相对离散程度越低,即模型的全面性越好。按照CVi由大到小排序为:
CVXGBoost>CVLightGBM>CVRF>CVSVM(Rbf)>CVMLP>CVKNN>CVSVM(Linear)>0.2
本文对变异系数CVi≥0.3的模型不予考虑,则有0.3>CVKNN>CVSVM(Linear)>0.2。综上,根据“准确性>全面性”的原则,在较轻度压力情景下,SVM模型更适用于制造型企业金融信用风险预警领域。
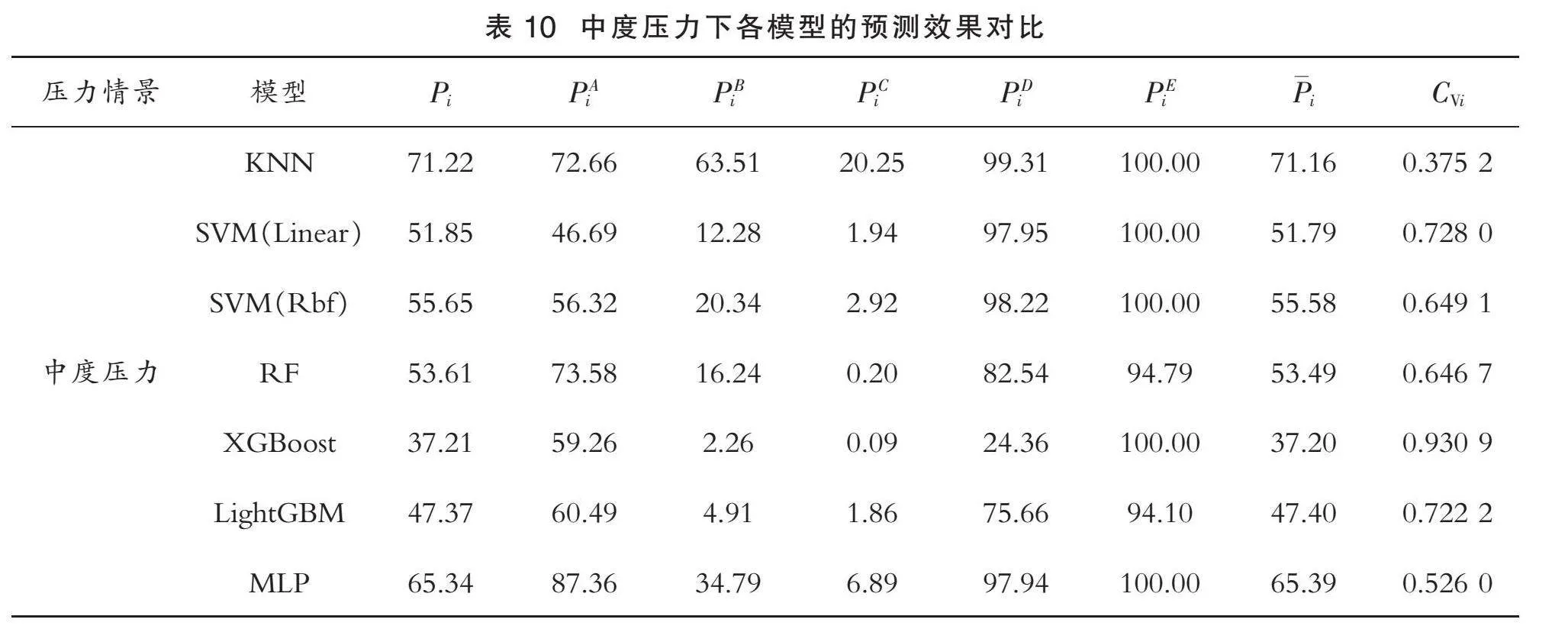
由表10可知,对于模型的准确性,从“企业识别率平均水平Pi”一列看,由大到小进行排序为:
PKNN>PMLP>PSVM(Rbf)>PRF>PSVM(Linear)>PLightGBM>PXGBoost>35%
KNN模型的准确性排名第一,获得最佳的分类效果;对于模型的全面性,已知变异系数CVi越小,数据的相对离散程度越低,即模型的全面性越好。按照CVi由大到小排序:
CVXGBoost>CVSVM(Linear)>CVLightGBM>CVSVM(Rbf)>CVRF>CVMLP>CVKNN>0.3
本文对变异系数CVi≥0.6的模型不予考虑,则有0.6>CVMLP>CVKNN>0.2。综上,根据“准确性>全面性”的原则,在中度压力情景下,KNN和MLP模型更适用于制造型企业金融信用风险预警领域。
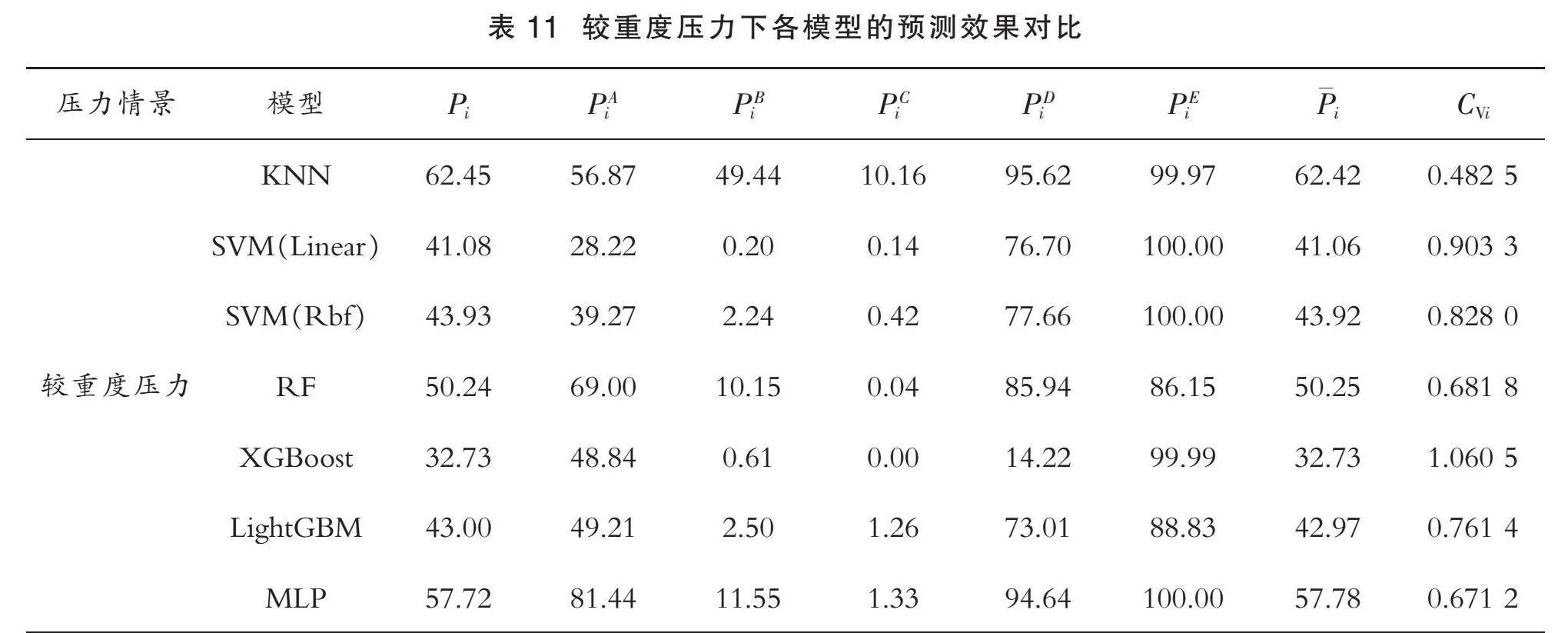
由表11可知,对于模型的准确性,从“企业识别率平均水平Pi”一列看,由大到小进行排序为:
PKNN>PMLP>PRF>PSVM(Rbf)>PLightGBM>PSVM(Linear)>PXGBoost>30%
KNN模型的准确性排名第一,获得最佳的分类效果;对于模型的全面性,已知变异系数CVi越小,数据的相对离散程度越低,即模型的全面性越好。按照CVi由大到小排序:
CVXGBoost>CVSVM(Linear)>CVSVM(Rbf)>CVLightGBM>CVRF>CVMLP>CVKNN>0.4
本文对变异系数CVi≥0.7的模型不予考虑,则有0.7>CVRF>CVMLP>0.4。综上,根据“准确性>全面性”的原则,在较重度压力情景下,KNN模型更适用于制造型企业金融信用风险预警领域。
由表12可知,对于模型的准确性,从“企业识别率平均水平Pi”一列看,由大到小进行排序为:
PMLP>PRF>PKNN>PLightGBM>PXGBoost>PSVM(Rbf)>PSVM(Linear)>30%
MLP模型的准确性排名第一,获得最佳的分类效果;对于模型的全面性,已知变异系数CVi越小,数据的相对离散程度越低,即模型的全面性越好。按照CVi由大到小排序为:
CVSVM(Linear)>CVSVM(Rbf)>CVXGBoost>CVLightGBM>CVMLP>CVRF>CVKNN>0.6
本文对变异系数CVi≥0.8的模型不予考虑,则有0.8>CVMLP>CVRF>CVKNN>0.6。综上,根据“准确性>全面性”的原则,在重度压力情景下,MLP模型更适用于制造型企业金融信用风险预警领域。
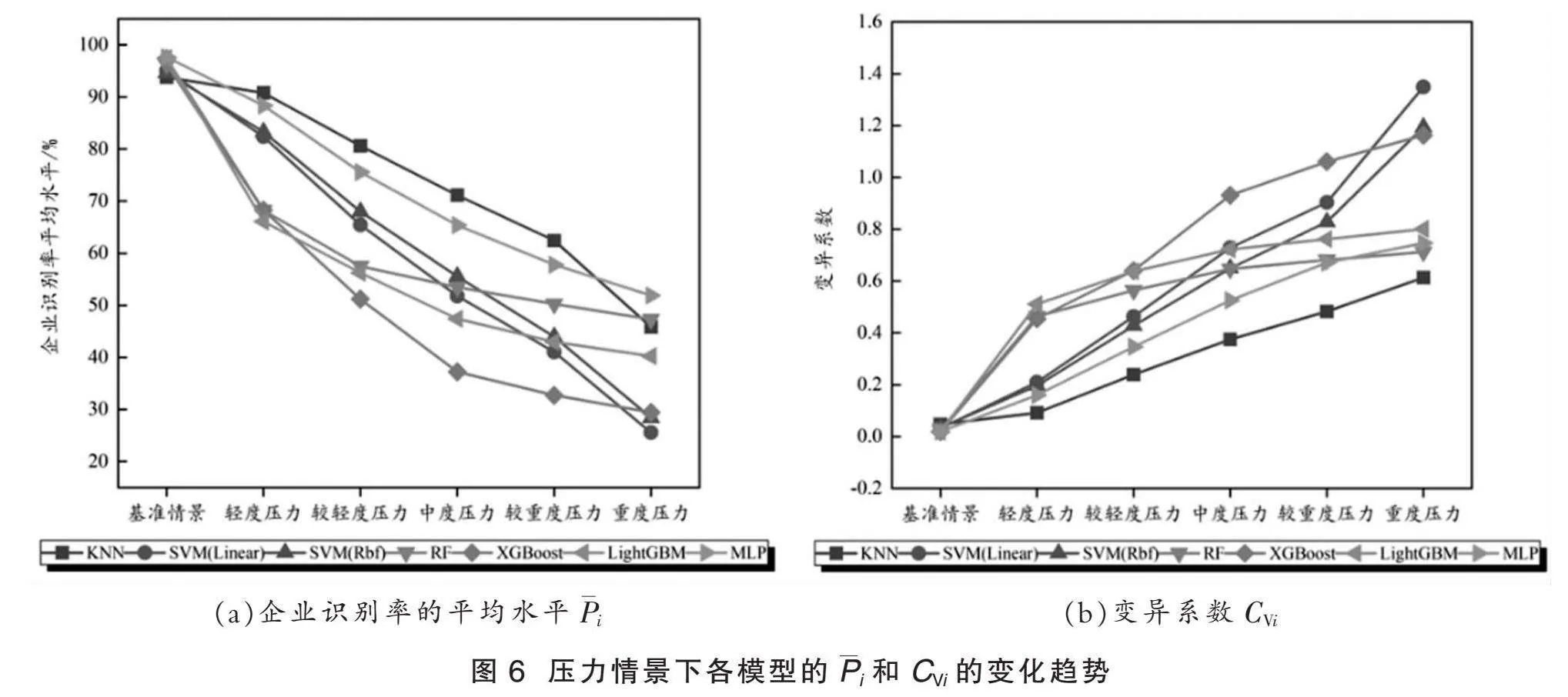
为更直观感受不同压力情景下各模型的企业识别率平均水平Pi和变异系数CVi的变化,本文将上述表7至表12中的Pi和CVi分别绘制成相应的折线图,如图6所示。
图6显示了在不同压力情景下各模型的企业识别率平均水平Pi和变异系数CVi的变化,图6(a)的纵坐标表示企业识别率平均水平,图6(b)的纵坐标表示变异系数。从图6(a)可看出,随着压力由轻度逐渐增加至重度,各模型的企业识别率平均水平Pi出现了不同幅度的下降。值得一提的是, SVM(Linear)模型在这个过程中表现出最大的下降幅度,而MLP模型的下降幅度最小。此外,从图6(b)也可观察到,随着压力的增加,各模型的变异系数CVi的上升幅度存在显著差异。其中,SVM(Linear)模型的CVSVM(Linear)上升幅度最大,而KNN和MLP模型的上升幅度相对较小。出现上述结果的原因可能是SVM(Linear)模型在处理非线性数据时性能相对较差,因此在不断施加压力的情景下,其预测性能受到更大冲击,从而导致PSVM(Linear)明显下降和CVSVM(Linear)明显上升。相反,MLP模型因其包含神经元和激活函数等结构,具备较强的非线性拟合能力,因此在各个压力情景测试下都表现出相对较好的稳定性,其预测效果的下降幅度较小。
综上所述,不同压力情景下的机器学习模型性能变化反映了制造型企业金融信用风险的动态性,以及各模型在应对不同程度风险时的表现差异。其中,基于MLP的制造型企业金融信用风险预警模型在压力测试实验中预测效果表现最佳。上述结论可帮助利益相关者更好地选择和调整模型,以适应不同风险情景下的信用风险评估需求。
(五)进一步分析
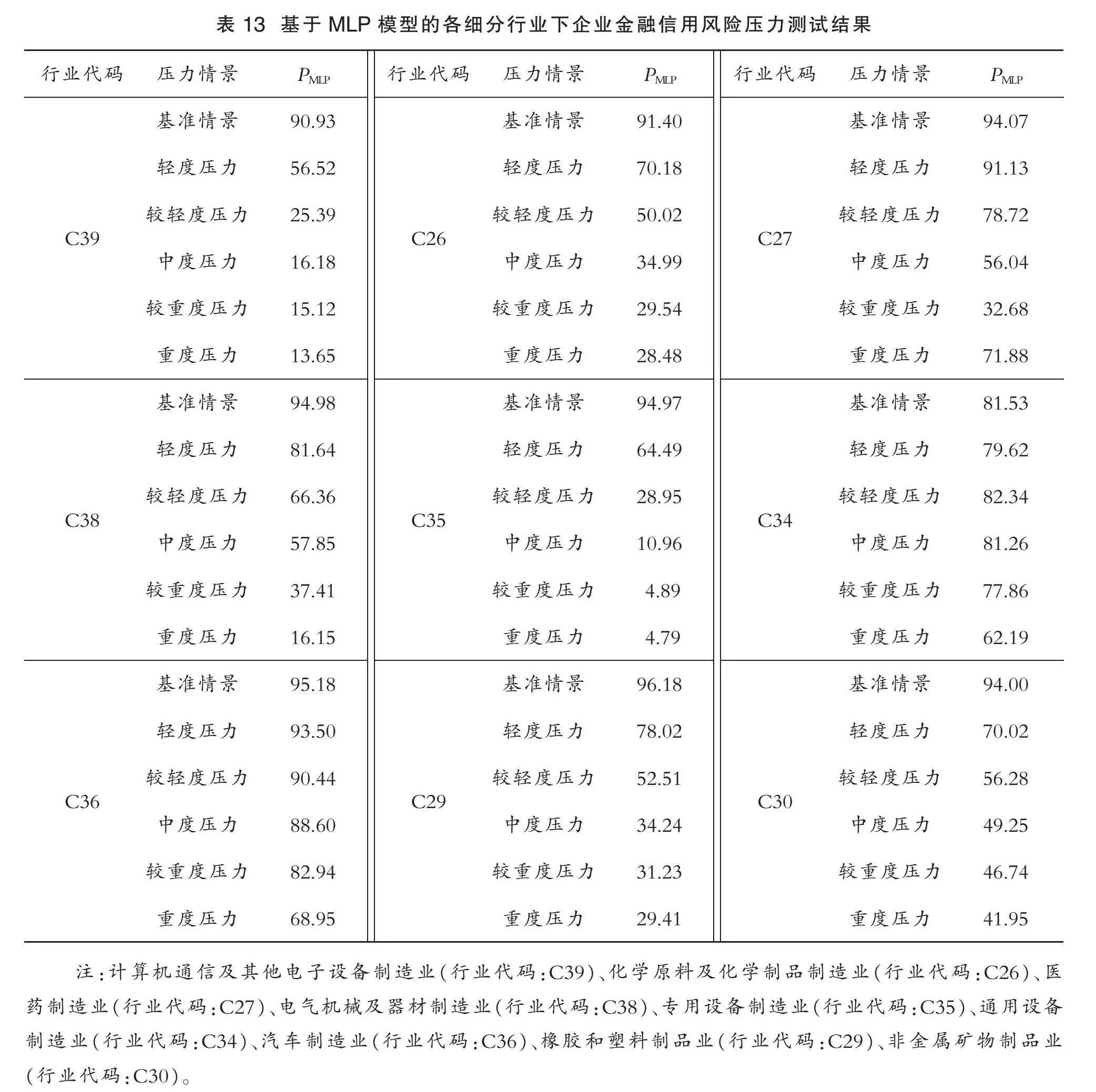
为深入研究不同细分行业中制造型企业的抗压能力,本文进行以下实验。由于经过数据预处理后,各细分行业中的企业样本量有所减少。因此,为保证实验结果的稳健性,本文选取样本量较大的前9名细分行业的制造型企业作为测试集。
考虑到数据获取的不完整性和以上细分行业包含的风险等级标签数量不一致,例如C39行业中包含A、B、C、D、E共5个风险等级标签,而C26行业中仅包含B、C、D共3个风险等级标签。同时,本文参考佟孟华等的研究[5],以MLP模型在压力情景下的企业总识别率PMLP的变异系数CVMLP来反映该细分行业下制造型企业的抗压能力。这是因为抗压能力越强的制造型企业通常能够在面对外部压力和不确定性时维持经营的稳定性和持续盈利。因此,在不同压力情景下,MLP模型的PMLP表现差异较小,即CVMLP值较小。相关的计算公式为:
CVMLP=σMLPPMLP(9)
式中,k∈{轻度,较轻度,中度,较重度,重度},若细分行业的CVMLP越小,则表明该细分行业下制造型企业的抗压能力越强,反之亦然。实验结果如表13所示。
注:计算机通信及其他电子设备制造业(行业代码:C39)、化学原料及化学制品制造业(行业代码:C26)、医药制造业(行业代码:C27)、电气机械及器材制造业(行业代码:C38)、专用设备制造业(行业代码:C35)、通用设备制造业(行业代码:C34)、汽车制造业(行业代码:C36)、橡胶和塑料制品业(行业代码:C29)、非金属矿物制品业(行业代码:C30)。
表13报告了不同压力情景下制造型企业金融信用风险的MLP模型压力测试结果。由表13可以看出,随着压力的不断增加,各细分行业下MLP模型的制造型企业总识别率PMLP随之呈现出不同的下降幅度。以计算机通信及其他电子设备制造业为例,在5种不同的压力情景以及基准情景测试下,PMLP的数值分别为:基准情景90.93%、轻度压力56.52%、较轻度压力25.39%、中度压力16.18%、较重度压力15.12%、重度压力13.65%,对应的差值分别为34.41%、31.13%、9.31%、1.06%、1.47%,可以看出MLP模型的制造型企业总识别率PMLP出现明显的性能下降。这种性能下降的原因可能是随着压力情景的不断加剧,制造型企业面临着更大的金融风险和不确定性。这些风险可能包括但不限于市场不景气、供应链问题以及资金紧张等,干扰了MLP模型对企业信用风险的准确预测,从而导致其性能下降[28]。可见,在制造型企业金融信用风险评估中,需要综合考虑各种因素,以便准确地识别和管理信用风险,特别是在高压力情景下。未来的研究可以探讨如何改进机器学习模型,以提高其在这些压力情景下的预测性能。
为直观了解各细分行业制造型企业在不同压力情景下的抗压能力变化,本文将表13中的PMLP和CVMLP结果用图进行展示,如图7所示。
图7显示了不同压力情景中各细分行业下MLP模型的制造型企业总识别率PMLP和变异系数CVMLP,图7(a)中的纵坐标表示企业识别率平均水平,图7(b)中的纵坐标表示变异系数。从图7(a)可以发现,随着压力的不断增加,各细分行业的PMLP整体上随之呈现下降趋势。值得注意的是,专用设备制造业和计算机通信及其他电子设备制造业的PMLP下降趋势最为明显,通用设备制造业和汽车制造业的PMLP仅表现出较小的下降幅度。此外,由图7(b)将变异系数CVMLP按照由大到小的顺序排序:
由此可以发现,首先是专用设备制造业的C(值为0.973 2)最大,表明该细分行业下制造型企业的抗压能力最弱;然后依次为计算机通信及其他电子设备制造业、橡胶和塑料制品业、化学原料及化学制品制造业、电气机械及器材制造业、医药制造业、非金属矿物制品业、汽车制造业;最后是通用设备制造业的C(值为0.090 1)最小,表明该细分行业下制造型企业的抗压能力最强。
四、结论及政策建议
制造型企业的发展对国家经济发展有着至关重要的作用。基于此,本文从企业与行业自身角度构建了较为全面的制造型企业金融信用风险指标体系。首先,通过PCA评估金融信用风险,采用K均值聚类划分风险等级,使用熵值法分析指标重要性;随后,运用SMOTE解决企业类别不均衡问题,提升模型预测性能;接着,进行金融信用风险压力测试,选定表现优异的MLP模型;最后,测试制造型企业的金融信用风险抗压能力,并进行不同细分行业间的比较分析。主要研究结论如下:
第一,各项信用指标对制造型企业金融信用风险的影响程度存在显著差异。在整体制造业分析中,一级指标“行业自身状况”所包含的二级指标在整体RFI值方面明显高于一级指标“企业自身状况”。注意的是,行业偿债能力是影响信用风险最重要的指标,相反,影响信用风险最小的指标是企业经营能力;在不同风险等级企业分析中,行业偿债能力指标对5个不同风险等级的企业都保持相对较高的权重,而企业经营能力指标在这5个风险等级的企业表现出明显的权重差异。如对于高风险制造型企业,企业经营能力指标的权重较高,而对于低风险制造型企业,企业经营能力指标的权重则较低。
第二,众多机器学习模型中,MLP模型在压力测试中表现出最佳的预测效果。具体而言,在处理非均衡数据、进行基准情景、中度压力和重度压力测试时,相较于其他机器模型,MLP模型均展示出更高的准确性。此外,在逐渐升级的压力情景中,MLP模型的企业识别率平均水平Pi下降幅度最小、变异系数CVi上升幅度也最小。这表明MLP模型能够有效地抵消大部分外部冲击,同时保持较高的预测准确率水平。可见,MLP模型更加适用于制造型企业金融信用风险压力测试实验。
第三,随着压力测试情景的恶化,各细分行业的PMLP呈现出不同的下降趋势。具体而言,依据本文公式(6)的计算结果,在通用设备制造业中,制造型企业的C值为0.090 1,表明其具备较强的抗压能力,而在专业设备制造业中,制造型企业的C值为0.973 2,表明其抗压能力较弱。这一结果可能是因为不同行业具有不同的经济特性和市场环境。例如,通用设备制造企业可能因其广泛的市场和多样化的产品组合而具有较强的抗压能力,使得PMLP保持在一个较高的稳定水平。而专业设备制造企业可能因更依赖特定市场和产品,容易受到市场波动的影响,故表现出较弱的抗压能力,导致PMLP存在明显的下降趋势。
基于上述研究结论,本文提出如下建议:
第一,制定差异化的风险管理策略。制造型企业的金融信用风险与诸多利益相关者的投资资金回报率直接相关。为更有效地管理信用风险,需要根据不同信用风险等级采取不同措施。例如,对于高风险制造型企业,利益相关者应重点关心企业经营能力,并要求其在经营运转、战略决策和财务状况方面进行高质量信息披露,以便投资者详细了解其风险水平,进行科学投资决策。在进行细分行业投资时,利益相关者需充分考虑行业间差异、行业竞争程度和市场前景等因素。例如,投资者可重点对通用设备制造企业进行大量投资,而对专业设备制造企业应谨慎投资,以避免无效投资,造成资金的损失,最大化保障自身合法权益,而企业也应注重高质量发展,重点发展技术密集型产业,完善工业信息化支持环境,推动工业结构转型[29]。
第二,推动机器学习模型在金融风险管理中的应用(如本研究中的MLP模型)具有重要意义。当前,随着互联网技术的快速发展,企业和金融机构积累了大量文本或非文本数据,其中包含丰富的信息和潜在的规律。这些数据可以被用于数据挖掘,通过机器学习模型深入挖掘其中的关联性和趋势性。同时,通过信息共享建立数据联合体或共享平台,可以整合多方数据资源,提高数据的质量和可用性。通过对这些数据的分析和挖掘,可以更全面地了解企业的经营状况和金融风险,为风险评估提供更加可靠的数据支持。
第三,鼓励利益相关者根据具体情况来设置金融信用风险压力测试情景,是提升风险管理有效性的关键一步。有效的压力测试结果有助于银行等金融机构更准确地评估压力因素变化对企业或行业信用风险的影响,从而及时采取相应的风险管理措施。然而,要实现这种有效性,必须合理地设定压力测试情景。现实中,并不存在一种适用于所有情况的通用压力测试情景设定方法。因此,为了实现更精准的压力测试,可考虑增加压力情景的数量以及宏观经济、竞争对手和行业差异等因素,以便根据具体情况设计出全面而有效的压力测试情景。
参考文献:
[1]" "黄益平,邱晗.大科技信贷:一个新的信用风险管理框架[J].管理世界,2021(2):12-21.
[2]" "黄爱华.金融风险预警机制的构建问题刍议[J].重庆文理学院学报(社会科学版),2014(1):106-108.
[3]" "巴曙松,朱元倩.压力测试在银行风险管理中的应用[J].经济学家,2010(2):70-79.
[4]" "杜坤伦,李贤彬,李后强.压力测试机制助力重大风险防控研究——基于金融风险管控的视角[J].财经科学,2020(6):41-50.
[5]" "佟孟华,邢秉昆,赵作伦,等.基于FM模型的工业企业碳减排信用风险预警研究[J].数量经济技术经济研究,2021(2):147-165.
[6]" "刘志惠,黄志刚,谢合亮.大数据风控有效吗?——基于统计评分卡与机器学习模型的对比分析[J].统计与信息论坛,2019(9):18-26.
[7]" "ABDELMOULA A K. Bank credit risk analysis with k-nearest-neighbor classifier: case of tunisian banks[J]. Accounting and Management Information Systems, 2015,14(1):79-106.
[8]" "潘永明,王雅杰,来明昭.基于IG-SVM模型的供应链融资企业信用风险预测[J].南京理工大学学报,2020(1):117-126.
[9]" "YUAN H, LAU R Y K, WONG M C S, et al. Mining emotions of the public from social media for enhancing corporate credit rating[C]//2018 IEEE 15th International Conference on e-Business Engineering (ICEBE).IEEE,2018:25-30.
[10] 贾颖,赵峰,李博,等.贝叶斯优化的XGBoost信用风险评估模型[J].计算机工程与应用,2023(20):283-294.
[11] 陈海龙,杨畅,杜梅,等.基于边界自适应SMOTE和Focal Loss函数改进LightGBM的信用风险预测模型[J].计算机应用,2022(7):2256-2264.
[12] LI Y,STASINAKIS C,YEO W M. A hybrid XGBoost-MLP model for credit risk assessment on digital supply chain finance[J].Forecasting,2022,4(1):184-207.
[13] 龙志,陈湘州.企业财务风险预警模型的构建与检验[J].财会月刊,2023(24):54-61.
[14] 周钰颖.社会责任、财务风险与现金股利稳定性[J].重庆文理学院学报(社会科学版),2019(3):24-31.
[15] 李健,张金林.供应链金融的信用风险识别及预警模型研究[J].经济管理,2019(8):178-196.
[16] 李成刚,贾鸿业,赵光辉,等.基于信息披露文本的上市公司信用风险预警——来自中文年报管理层讨论与分析的经验证据[J].中国管理科学,2023(2):18-29.
[17] 姚爽,高江波,黄玮强.制造业上市公司信用风险预警研究——基于FA-BA-BP神经网络模型[J].财会通讯,2022(12):136-140.
[18] 王正军,王结晶,崔浩哲.基于PCA-BP神经网络的医药企业财务压力测试研究[J].会计之友,2021(16):32-38.
[19] 孙娜.基于K均值聚类分析法的城市房地产投资风险研究[J].企业经济,2014(12):93-97.
[20] 李伟.商业银行系统性金融风险压力测试模拟研究[J].财经问题研究,2018(6):58-65.
[21] 董申,王金玲,陶然,等.商业银行大型集团客户信用风险压力测试——基于蒙特卡洛模拟方法[J].金融监管研究,2019(5):18-29.
[22] 杨云,仲伟周,王佳琪,等.碳达峰情景下碳价对高耗能行业违约风险影响研究——基于高碳省份微观财务数据的视角[J].苏州大学学报(哲学社会科学版),2022(6):126-139.
[23] ZHANG S,ZHANG J,LI X, et al. Estimating the grade of storm surge disaster loss in coastal areas of China via machine learning algorithms[J].Ecological Indicators,2022,136:108533.
[24] 姚定俊,顾越,陈威.基于RF-LSMA-SVM模型的中小微企业信用风险评价研究[J].工业技术经济,2023(7):85-94.
[25] CHAWLA N V,BOWYER K W,HALL L O,et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research,2002,16:321-357.
[26] 李艳霞,柴毅,胡友强,等.不平衡数据分类方法综述[J].控制与决策,2019(4):673-688.
[27] BAESENS B,SETIONO R,MUES C,et al. Using neural network rule extraction and decision tables for credit-risk evaluation[J].Management Science,2003,49(3):312-329.
[28] 马毓璟,孔陇,夏娇.“双碳”背景下重污染行业ESG评价与优化路径研究[J].重庆文理学院学报(社会科学版),2023(4):62-73.
[29] 胡学英,叶国良,高建设.制造业高质量发展目标下中部地区工业竞争力评价研究[J].长江师范学院学报,2022(4):43-55.
责任编辑:吴" "强;校对:罗清恋
Research on Financial Credit Risk of Manufacturing Enterprises Under Unbalanced Data: Based on Stress Testing and Machine Learning
LONG Zhi1,2,CHEN Xiangzhou1,2
(1.Business School, Hunan University of Science and Technology, Xiangtan Hunan 411201, China;
2.Hunan Strategic Emerging Industries Research Base, Xiangtan Hunan 411201, China)
Abstract: How to effectively assess the financial credit risk status of enterprises is the current research focus in the field of risk warning. Taking Chinese manufacturing enterprises as an example, firstly, through the principal component analysis and K-mean clustering to comprehensively score and classify the financial credit risk of enterprises, an exploration was made on the importance of indicators in depth; then, SMOTE oversampling was used to solve the problem of category imbalance in order to improve the prediction effect of the machine learning model; finally, an evaluation was made on the prediction effect of each machine learning model, and taking the model with outstanding performance as the stress transfer model, an analysis was made on the stress resistance of enterprises under different segments through stress testing. The study found that:1)there is a significant difference in the degree of influence of each credit indicator on the financial credit risk of manufacturing companies. For example, the most influential is the industry solvency, and the least influential is the enterprise operating ability;2)in the stress test, compared with other models, the MLP model has the best overall prediction effect, with the smallest decrease in PMLP and the smallest increase in CVMLP;3) with the increase of stress factors, the stress resistance curve of manufacturing enterprises under each sub-sector decreases significantly. Taking the decline as a criterion, the general equipment manufacturing enterprises have stronger stress resistance, while the specialized equipment manufacturing enterprises have smaller stress resistance. The research results can help stakeholders more effectively assess and manage the financial credit risk of manufacturing enterprises, reduce risk exposure, and promote the healthy development of enterprises.
Key words: manufacturing enterprises; financial credit risk; stress testing; machine learning; unbalanced data
猜你喜欢
中国市场(2017年2期)2017-02-28 19:55:41
财会学习(2017年2期)2017-02-10 17:43:24
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
现代企业文化·理论版(2016年19期)2016-12-21 08:20:19
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
商场现代化(2016年22期)2016-10-18 19:44:33
科学与财富(2016年28期)2016-10-14 21:19:17
科教导刊·电子版(2016年10期)2016-06-02 18:04:11
