
基于POD与机器学习的综掘工作面流场快速预测算法
2024-12-31 00:00:00金兵张浪李伟郑义刘彦青张逸斌
工矿自动化 2024年10期

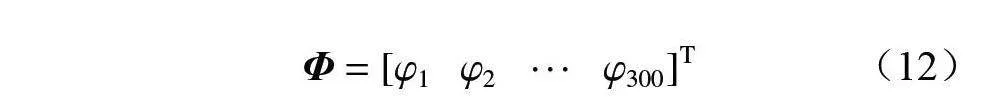







关键词:综掘工作面;粉尘防治;风流场预测;粉尘浓度场预测;本征正交分解;机器学习;支持向量机
中图分类号:TD714.4 文献标志码:A
0引言
据统计,我国尘肺病人数约占职业病总人数的90%,其中煤矿工人占比达50% 以上[1-2]。目前,综掘工作面主要采用混合式通风方式降低粉尘浓度,易导致粉尘局部聚集严重[3]。因此,综掘工作面粉尘防治对于保障煤矿生产作业环境的安全和工人健康具有重要意义[4]。为了保证粉尘防治措施的有效实施,提高防降尘效果,需要快速、准确预测工作面流场变化。
通过计算流体力学(Computational FluidDynamics,CFD)技术与综掘工作面现场监测数据可有效模拟出综掘工作面整体的风流场与粉尘浓度场,但由于CFD 技术计算时间长,难以进行快速预测。采用降阶模型(Reduced Order Modeling, ROM)对高维流场数据进行降维是实现流场快速预测的主要途径[5-6]。在众多ROM 中,本征正交分解(ProperOrthogonal Decomposition, POD)方法被广泛应用于汽车和飞行器流场分析[7-9]、航空工程[10]、流体机械[11]等领域, 取得了较好的应用效果。因此, 本文将POD 方法引入综掘工作面流场预测中,基于少数已知的工况, 使用全阶CFD 模型进行计算, 采用POD 方法提取流场系统的核心模态。通过少量的模态和模态系数有效描述流场系统的主要动态特性,在保证模型准确性和可靠性的同时,大幅降低计算时间成本,提高综掘工作面流场预测效率。
1算法流程
基于POD 与机器学习的综掘工作面流场快速预测算法流程如图1 所示。首先,利用CFD 技术对多种工况下的综掘工作面风流场和粉尘浓度场进行模拟,获得高维度的流场数据。其次,使用POD 方法对高维流场数据进行降维,提取出能够反映流场主要特性的核心模态,并将其分解为基函数模态和模态系数。然后,以各工况的参数为特征,以流场的模态系数为目标,构建并训练机器学习模型。最后,通过训练好的机器学习模型和基函数模态,基于输入的工况参数,实现对目标工况下综掘工作面流场的快速预测。
2综掘工作面数值模拟
2.1数值计算模型
矿井综掘工作面粉尘颗粒在风流作用下的扩散是一个典型的气固两相流动过程,其中风流为连续相,粉尘为离散相。两相流中粉尘颗粒的体积比例远小于10%,粉尘颗粒间碰撞对数值模拟的影响较小[12-13],因此,进行数值模拟时不考虑粉尘颗粒间碰撞带来的影响,此时的风流连续方程为
数值模拟参数的设置主要分为离散相与边界条件2种,分别见表1和表2。
为了获得后续机器学习所需的样本,对表1和表2中质量流率的最大和最小颗粒直径、压风筒和抽风筒的风速设定不同值,通过组合不同参数,总计得到300种综掘工作面降尘措施的工作状态,并进行数值模拟。
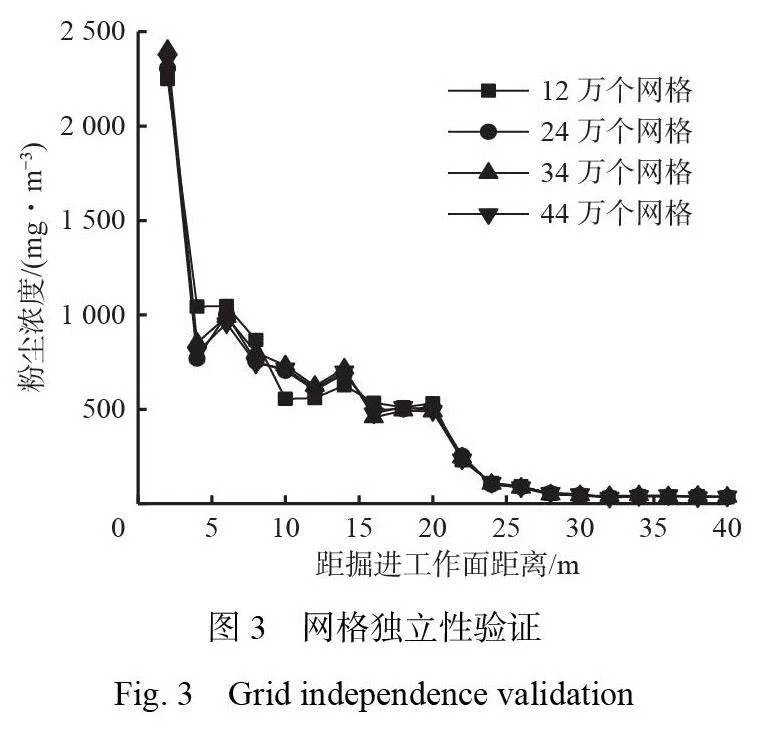
为了确保数值模拟的准确性,选取综掘工作面回风侧行人呼吸带的粉尘浓度作为判断网格独立性的标准。在最大颗粒直径为2×10−4 m、最小颗粒直径为1×10−6 m、压风筒风速为8 m/s、抽风筒风速为10 m/s 的工况下,比较不同网格数量对数值模拟结果的影响,结果如图3 所示。
根据图3数据,12万个网格虽然能够保证基本的模拟结果,但由于粉尘浓度分布存在较大波动,且局部区域的模拟结果与其他网格数量模拟的结果不一致,显示出其难以确保结果的精确性。随着网格个数从24万增加至34 万和44万,粉尘浓度分布的波动逐渐减小,不同网格条件下的浓度曲线更加平滑,显示出模拟精度有所提升,特别是在细节区域的结果更为一致。此外,34 万和44 万个网格的模拟结果与24 万个网格相比差异不显著,表明从24 万个网格开始,模拟精度已达到较为理想的水平。考虑到进一步增加网格数量会显著提高计算成本,因此,选择24 万个网格作为最终计算基础,在确保精度的同时,提高计算效率。
2.3数值模拟效果验证
选取回风侧行人呼吸带中心距工作面5 m 处的实测风速及粉尘浓度,与数值模拟得到的对应值进行比较分析,验证数值模拟结果的准确性,结果见表3。可看出模拟值与实测值的相对误差均在3% 以内,满足模拟值与实测值的相对误差不超过5% 的精度要求,说明数值模拟能够准确反映实际的风流和粉尘分布状况。
3POD重构
3.1POD应用方法
POD方法能够通过CFD软件所获得的大量计算数据,精选出反映流场主要特征的优化基向量模态[19]。针对综掘工作面流场与粉尘浓度场,建立POD模型的步骤如下。
1) 构建样本数据集矩阵。通过综掘工作面CFD模型的数值模拟结果生成样本数据集矩阵。本研究中,风流场或粉尘浓度场不同工况的数据集共同构成一个大小为L×N 的矩阵V,L 为模型网格数量,N 为综掘工作面样本中不同工况的数量。
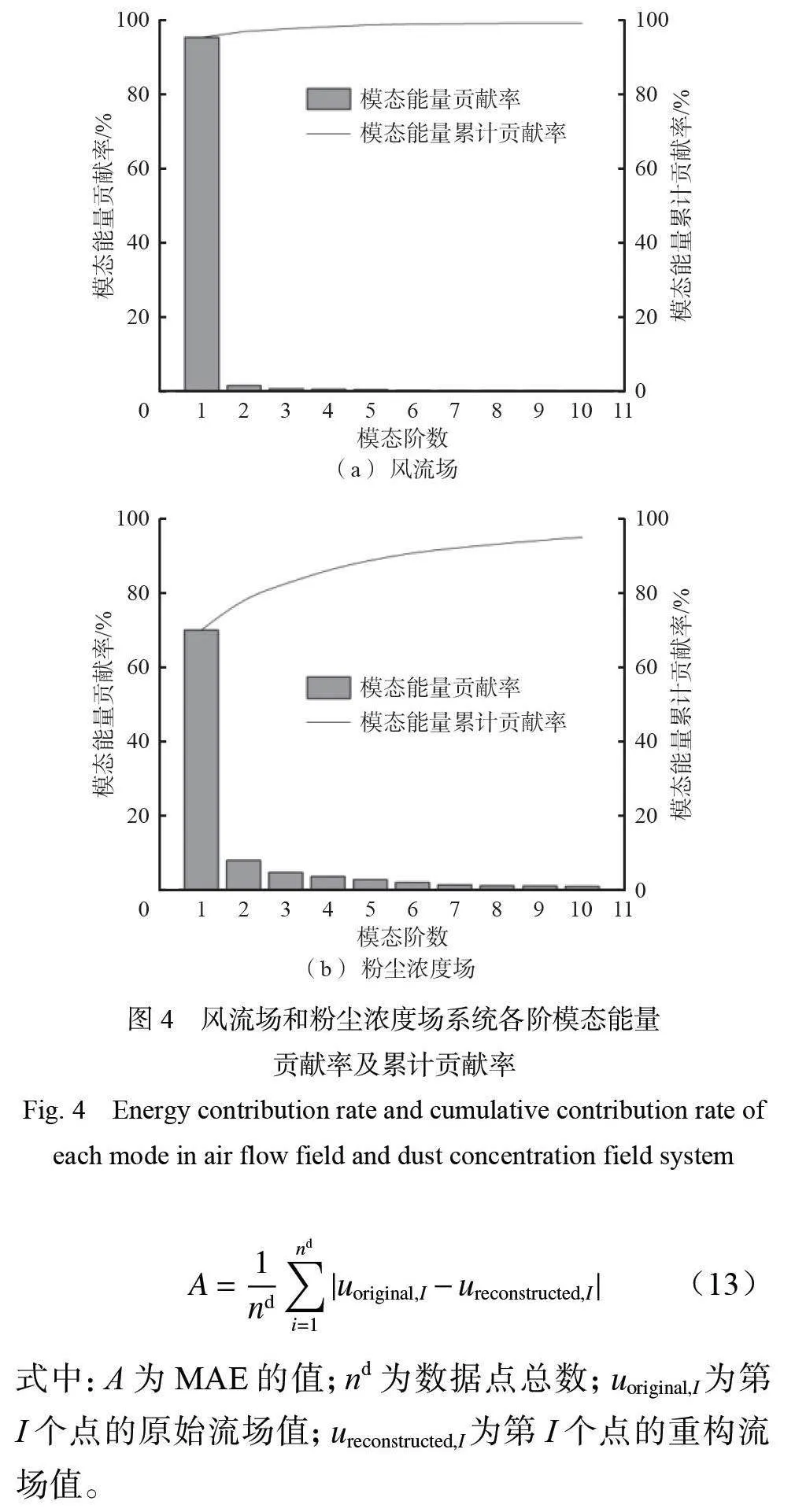
风流场和粉尘浓度场系统各阶模态能量贡献率及模态能量累计贡献率如图4 所示。第1 阶模态在能量分布中占据主导地位,远超过其他模态,尤其在风流场中,第1 阶模态能量占比更为突出。随着模态阶数增加,其包含的能量迅速降低并逐步趋于稳定。当累计模态能量达到总能量的90% 时,继续增加模态对能量累计贡献率的影响相对较小。
为选取合适的基函数模态阶数,对不同阶基函数模态重构的风流场与粉尘浓度场及原流场进行差异评估,评估指标选取平均绝对误差(Mean AbsoluteError,MAE)。
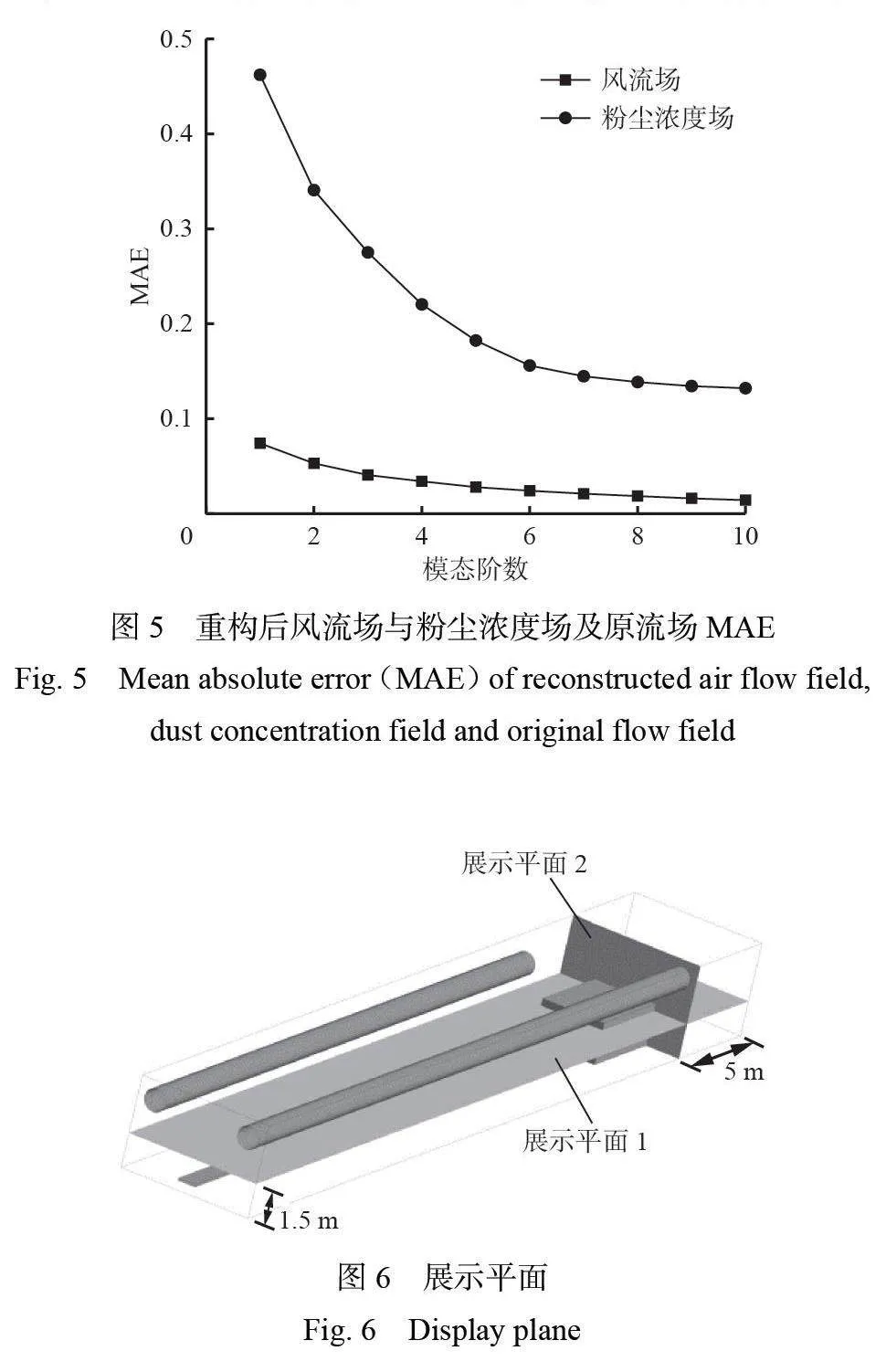
使用不同模态阶数进行重构的风流场与粉尘浓度场及原流场MAE如图5 所示。风流场的前5 阶模态已将MAE 降至0.028,若进一步增加模态,误差减小幅度较小,提升效果不明显,因此选择前5 阶模态即可保证精度与效率平衡。粉尘浓度场的前7 阶模态将MAE 降至0.134 8,7 阶之后误差减小幅度较小,因此选择前7 阶模态即可兼顾精度与计算成本。
3.3模态重构效果验证
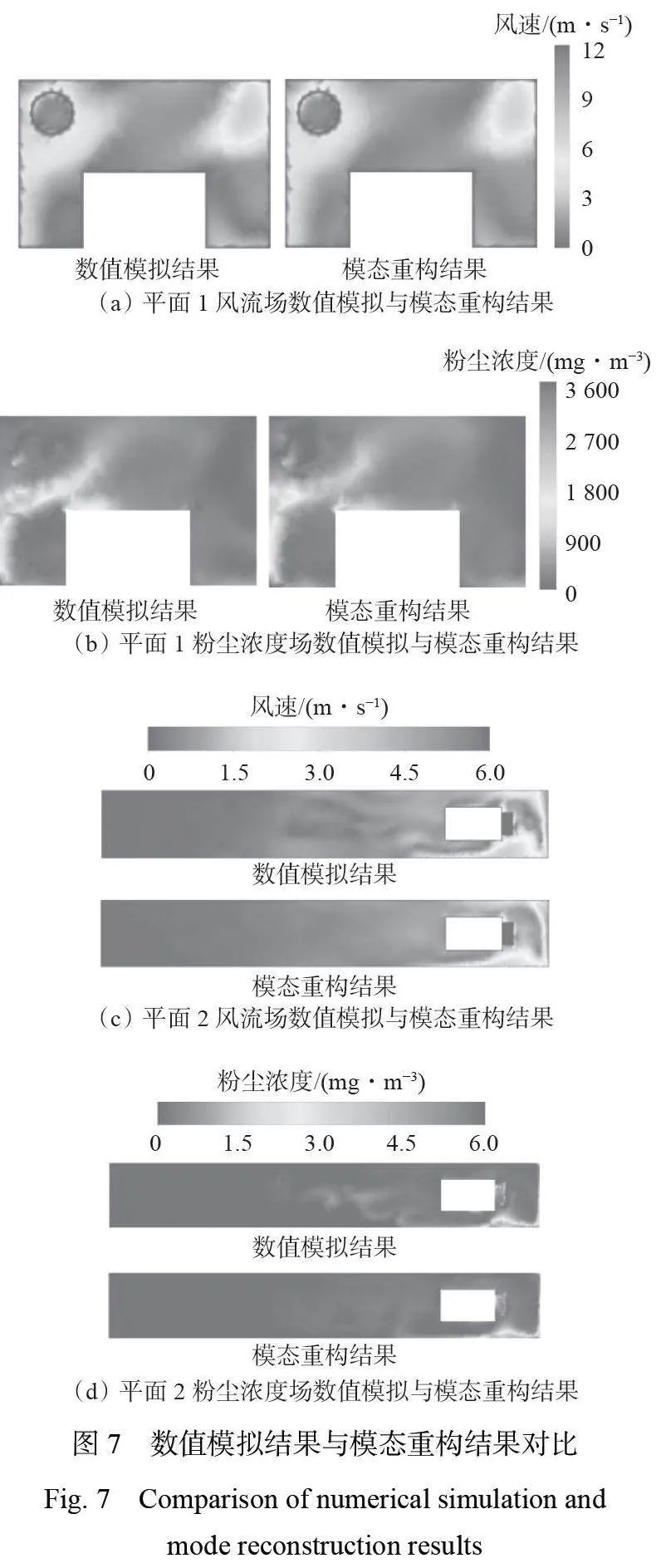
选取以下工况进行模态重构效果验证:质量流率为0.008 kg/s,最大颗粒直径为1×10−4 m,最小颗粒直径为1×10−6 m,压风筒、抽风筒风速为10 m/s。取行人呼吸带高度(1.5 m)处平面作为展示平面1,抽风筒抽出口距工作面5 m 处平面作为展示平面2,如图6 所示。
将平面1、平面2 的风流场与粉尘浓度场数值模拟结果与使用含90% 以上能量的基函数模态进行POD 重构的结果进行对比,结果如图7 所示。可看出,在综掘工作面风流场与粉尘浓度场中,前几阶含能量较高的模态已经涵盖了流场系统的主要特性信息,利用这些模态能够以较高的准确度对样本数据集进行重构。
4基于POD与机器学习的综掘工作面流场快速预测
使用机器学习模型预测风流场前5 阶模态和粉尘浓度场前7 阶模态,得到目标工况下的模态系数后,可结合对应模态快速重构不同工况下的流场数据。
4.1数据准备与机器学习模型选择
通过POD方法对不同参数组合下的数值模拟结果进行降维,得到各个工况下的模态系数,并形成数据集。该数据集共包含300个工况,其中240个工况用于模型训练,其余60 个工况用于模型测试。模型的输入参数为工况参数组合,具有4个维度,输出数据为相应的模态系数。为了降低模型对数据规模的敏感性,采用离差标准化方法将数据范围调整至[0,1],以增强模型的泛化能力。
基于不同机器学习模型的泛化能力与预测能力, 选取支持向量机(Support Vector Machine,SVM) 、随机森林(Random Forest, RF) 及神经网络(Neural Network,NN)进行对比分析[20-23]。为确保这3 种模型能够达到最佳性能,采用贝叶斯优化方法调整参数。由于深度学习模型的参数复杂、训练时间长,尤其在流场预测任务中效率较低,所以本文未选用深度学习模型。
分别采用均方根误差(Root Mean Squared Error,RMSE)和决定系数R2 评价模型的预测精度和预测能力。
3种机器学习模型性能评估指标见表4。在不同流场类型下,各模型训练后的RMSE 数量级相同,其中SVM 的RMSE 相对较小;各模型的R2值相差较大,其中SVM的R2 值明显高于其他模型。因此本文选取SVM 作为模态系数预测模型。
4.2模型预测结果分析
将待预测流场的工况参数输入训练好的SVM 模型中,通过SVM模型预测模态系数,将模态系数与模态进行组合重构,获得综掘工作面风流场或粉尘浓度场预测结果。
选取与模态重构相同的工况(非训练集中工况)进行数值模拟和预测,平面1 与平面2 的风流场与粉尘浓度场数值模拟与预测结果如图8 所示。可看出,2 种结果具有较高的一致性。
针对60种不同工况,计算得到模型各网格预测的风流速度、粉尘浓度与数值模拟结果之间的相对误差分别为0.36 m/s,86.24 mg/m3,表明本文构建的预测模型具有较高的准确性,能够实现对矿井综掘工作面风流场和粉尘浓度场的高精度预测。
4.3模型泛化能力验证
通过交叉验证能够更全面地评估模型在不同数据集上的表现,避免过拟合。采用5 折交叉验证对模型的泛化能力进行验证。将60种不同工况的数据集划分为5 个子集,每次使用其中1 个子集作为验证集,剩余子集作为训练集,重复5次后计算模型的平均RMSE 及标准差,结果见表5。
从表5可看出,SVM在风流场和粉尘浓度场的预测中表现最佳,平均RMSE 均为最低。虽然在风流场中的标准差较高,但由于其较高的准确性,整体误差仍然低于其他模型。RF 的预测性能略逊于SVM,但在风流场中的标准差较小,表明其在不同工况下的预测结果较为稳定。而NN 在2 种流场预测中的RMSE 均为最高,且粉尘浓度场的95% 置信区间较宽,说明其预测结果存在较大的不确定性,难以在不同条件下提供一致的表现。
通过数值模拟软件获得综掘工作面风流场和粉尘浓度场的平均耗时为48 951.6 s,利用本文算法获得综掘工作面风流场及粉尘浓度场的平均耗时为73 s,显著降低了计算所需的时间成本。
5结论
1) 建立了POD重构模型,该模型能够识别综掘工作面风流场与粉尘浓度场的主导特征,使用较少模态进行流场信息重构,且当模态累计能量达到流场系统总能量的90% 以上时,重构结果具备较高准确性,能够满足精度要求。
2) 对于实时变化的工况参数,基于POD与机器学习的综掘工作面流场快速预测算法能够快速准确地预测综掘工作面的风流场和粉尘浓度场。风流场预测结果与数值模拟结果中各网格风流速度的相对误差为0.36 m/s;粉尘浓度流场预测结果与数值模拟结果中各网格的相对误差为86.24 mg/m³。
3) 基于POD与机器学习的综掘工作面流场快速预测算法具有优越的通用性和较低的时间成本,预测综掘工作面风流场及粉尘浓度场的平均耗时为73s,实现了综掘工作面流场快速预测,能够满足综掘工作面降尘设施运行及优化调控的时效性要求。
4) 尽管该算法在综掘工作面流场预测中表现良好,但在更复杂的工况或大规模工业流程中,可能面临工况复杂度增加带来的不确定性。尤其是在具有更复杂边界条件、动态变化更为频繁的大规模流场中,算法的精度和计算效率可能会受到影响。因此,未来研究可考虑如何在更复杂工况下进一步优化该算法,以提升其适用性和扩展性。
猜你喜欢
中国水运(2016年11期)2017-01-04 12:26:47
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
软件导刊(2016年11期)2016-12-22 21:52:38
电子技术与软件工程(2016年20期)2016-12-21 10:21:33
价值工程(2016年32期)2016-12-20 20:36:43
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
价值工程(2016年29期)2016-11-14 00:13:35
科学与财富(2016年28期)2016-10-14 21:19:17
