
基于Vision Transformer与迁移学习的裤装廓形识别与分类
2024-12-31 00:00:00应欣张宁申思
丝绸 2024年11期







Recognition and classification of trouser silhouettes based on Vision Transformer and migration learning
摘要:
针对裤装廓形识别与分类模型的分类不准确问题,文章采用带有自注意力机制的Vision Transformer模型实现裤装廓形图像的分类,对于图片背景等无关信息对廓形识别的干扰,添加自注意力机制,增强有用特征通道。为防止因裤型样本数据集较少产生过拟合问题,可通过迁移学习方法对阔腿裤、喇叭裤、紧身裤、哈伦裤4种裤装廓形进行训练和验证,将改进的Vision Transformer模型与传统CNN模型进行对比实验,验证模型效果。实验结果表明:使用Vision Transformer模型在4种裤装廓形分类上的分类准确率达到97.72%,与ResNet-50和MobileNetV2模型相比均有提升,可为服装廓形的图像分类识别提供有力支撑,在实际服装领域中有较高的使用价值。
关键词:
裤装廓形;自注意力机制;Vision transformer;迁移学习;图像分类;廓形识别
中图分类号:
TS941.2
文献标志码:
A
文章编号: 1001-7003(2024)11-0077-07
DOI: 10.3969/j.issn.1001-7003.2024.11.009
收稿日期:
20240304;
修回日期:
20240920
基金项目:
江西省教育厅科学技术研究项目(GJJ2202819)
作者简介:
应欣(1996),女,硕士研究生,研究方向为数字化服装。通信作者:张宁,教授,zhangning@jift.edu.cn。
随着互联网和计算机技术的发展,网购成为新时代下虚拟平台与实物交易的购物模式,其“一键式”购物在为消费者接受和应用的同时,消费者也对各大网购平台的购物满意度要求越来越高。为了提高用户满意度,各大购物网站比如淘宝、京东,目前采用人工输入文本关键字或者搜图等方式搜索商品链接,但是,当消费者需求的商品信息不明确时,这种方式很难短时间触及消费者的真实需求。平台想要快速找到满足消费者需求服装的前提是要根据用户的喜好和风格对服装进行分类,并为每件商品打上标签。但是,对于庞大的服装图像数据,人工标注的分类方法费时费力,且容易受到人为主观因素的影响。因此,亟须研究关于服装可视化分类问题,来提高识别准确率。基于深度学习的算法可以从大规模的服装图像数据中提取出有用的特征[1],进而进行分类,其准确性和速度远远高于传统的人工标注和分类方法,从而缩短消费者检索时间,缩小检索范围,为消费者提供更加精确的结果。
近年来,随着深度学习技术的不断发展,国内外诸多学者都将其应用到服装图像的分类问题上。在基于服装整体分类方面,Liu等[2]提出了一个数据量大且标注完整的服装数据集Deep Fashion,并在此基础上提出了一种新的模型Fashion Net,该模型通过共同预测服装属性和标签来学习服装特征,Deep Fashion数据集后续被很多学者用来作为训练服装分类模型的数据集。包青平等[3]提出了基于度量学习(Metric Learning)的服装图像分类算法,减小同类服装的特征差值,同时增大不同类服装的特征差值,以达到对服装图像做精细分类的目的。Xia等[4]通过在分类层中引入SE(Squeeze-and-Excitation)块,从预训练模型中提取服装图像特征,从而提高迁移学习的性能,进而提高服装的分类准确率。王雅静等[5]提出基于BP神经网络算法的女性服装分类方法,但是没有具体说明服装的分类种类且对比性不足。在服装具体部位等细节分类领域方面,李青等[6]设计一种基于Inception v3算法与迁移学习技术对女衬衫图案进行分类的方法,该方法是对图案的识别,并未考虑到服装的廓形。庹武等[7]为了解决服装图像背景对分类所造成的干扰问题,提出了一种融合SE注意力机制和Inception v3主干网络的分类模型SE-Inception v3,提高了服装袖形的识别及分类效率。吴欢等[8]提出一种基于CaffeNet卷积神经网络模型来提取女裤轮廓信息,但其数据集挑选的只是纯白色背景并且平整摆放的女裤图像,与现有电商平台中模特穿着服装的图像不符。上述研究大多采用卷积神经网络对服装图像分类,但卷积神经网络在对图像特征进行提取时更多的是去关注局部信息,这与消费者在判断服装廓形时需要考虑整体的观念不符合。
本文将裤装廓形作为研究对象,以深度学习技术为手段,以提高裤装廓形识别和分类准确率为目标。为弥补卷积神经网络关注局部信息,全局信息捕捉能力弱的不足问题,结合具有全局感受野的Transformer模型进行迁移学习。针对4种
典型的裤装廓形数据集,采用优化的transformer模型对其进行训练,选取对裤装廓形训练有益的模型权重分配,以提高裤装类型识别率。
1" 样本采集及图像预处理
1.1" 数据采集
本实验在数据集选择上,结合日常生活中常见裤装款式,
按照不同形态裤装廓形,选取阔腿裤、哈伦裤、喇叭裤及紧身裤4类裤装廓形为分类样本。使用Python工具获取来自淘宝、小红书、拼多多及唯品会等各大电商平台上的裤装图片,采集时要确保裤装廓形未被其他物体遮挡,每种类型500张,共计2 000张。为验证后续模型实验效果,选取每种类型50张,共计200张作为测试集。样本均为JPG格式,部分图片数据集如图1所示。
1.2" 数据增强
因为Transformer模型在训练时需采用大量的数据集,为了提升模型鲁棒性,避免数据集过小产生模型过拟合,本文采用数据增强来扩充数据集。
本文使用OpenCV库对原始数据集图片进行处理,通过调整图片的明亮度、添加椒盐噪声和高斯噪声、水平翻转和随机旋转5°对数据集进行增强,每种裤装廓形增加至3 500张图片,总数据集为14 000张图片,其中选取90%(11 200张)作为训练集,20%(2 800张)作为验证集,从中选取每种裤装廓形350张,共1 400张作为测试集。图片处理后的样本实例如图2所示。
1.3" 图片调整处理
根据Vision Transformer模型输入要求,将经过数据增强后14 000张图片集中进行归一化预处理,统一尺寸大小设置为224 mm×224 mm,通过增加padding的方式修改图片,可以在保证图像不变形的情况下较好地匹配模型的输入,确保裤装轮廓特征的有效提取。
2" 构建网络模型
Transformer模型是一种基于自注意力机制的神经网络模型,2017年Google团队提出的全新Transformer[9]模型开启了
其在自然语言处理领域的主导地位,2018年Radford等[10]基于Transformer推出GPT系列的第一代,为后续大语言模型奠定了基础。Transformer模型区别于传统CNN模型,在结构中没有使用卷积结构而是完全基于自注意力机制,能够高效地处理长序列数据。2018年,Parmar等[11]首次将Transformer应用于图像生成。2020年,Dosovitskiy等[12]提出了首个独立使用Transformer进行图像分类的模型Vision Transformer(ViT),得到了比当时最先进的CNN网络更优秀的结果。Vision Transformer中的Transformer模块通常由一个多头自注意力层和一个多层感知机块组成,依靠其自注意力机制捕获各块间的远程依赖关系,并且得益于形状偏置,它们能够专注于图像的重要部分[13]。这显示出Vision Transformer巨大的潜力,Vision Transformer模型在分割、目标检测及图像修复等任务中都有较好的应用。
2.1" 自注意力机制
自注意力机制(self-attention)可以让模型聚焦于输入数据之间的相关性,减少对无关信息的关注程度,相当于人类在观察图片时,注意力主要集中在自己感兴趣的部分。注意力机制通过改变图像某些区域的权重,使模型判断该区域对预测结果更为重要,再通过反向传播算法自动选出图像中的重要信息[14]。本文通过自注意力机制把权重参数聚集到裤装轮廓这一需要重点关注部分,减少背景等无关信息的影响,从而提高分类和识别准确率。自注意力计算过程由式(1)表示,主要分为4个部分完成。
Attention(Q,K,V)=softmaxQKTdkV(1)
1) 将输入的图片按照给定大小分成序列[x1,x2,…,xi],
通过f(x)将输入映射到[a1,a2,…,ai],将[a1,a2,…,ai]通过三个变换矩阵Wq、Wk、Wv得到对应的qi、ki、vi。其中,q代表query,后续和每一个k进行匹配;k代表key,后续被每个q匹配;v代表从a中提取得到的信息,即自注意力。
2) 遍历[q1,q2,…,qi],将其与[k1,k2,…,ki]进行点乘,再除以dk,得到相似度权重。其中,d代表向量k的长度。
score(qi,ki)=QKTdk(2)
3) 对相似度权重进行softmax处理,softmax将各节点输出之和映射到1,从而消除异常值所带来的不良影响。其中,yi为第i个节点的输出值,j为输出节点的个数。
softmax(Oi)=eyi∑ji=1eyj(3)
4) 针对vi的相似度权重,进行加权得到自注意力。
2.2" Vision Transformer模型
Vision Transformer模型主要由3个模块组成。第一个模块是嵌入层,将输入的图片按照给定的大小分成块,对其进行线性映射后将每个块映射到一维向量中,并加上分类向量和位置编码后作为编码器的输入。第二个模块是编码器层,此模块的主要作用是用来提取特征信息,主要包括自注意力机制和多层感知机(MLP)两部分,其中多层感知机(MLP)结构由全连接层、GELU激活函数和Droupout组成。输入的图片经过编码器层后,会形成一系列特征信息,为了将该特征信息转换为我们所需要的结果,采用由全连接层及tanh激活函数所组成的解码器层作为第三个模块,通过对特征进行非线性变换,从而提高模型的泛化能力。Vision Transformer基本结构如图3所示。
2.3" 改进的Vision Transformer模型
本文改进的Vision Transformer模型与原始模型在整体上保持了一致,整体结构如图4所示。原始模型中,输入图像
按照16×16的像素规格分成块,再通过线性映射将每个块映射到一维向量中。为更好地提取图像特征,在模型中引入CNN结构,采用一个卷积核大小为16×16、步距为16、卷积核
个数与原始映射向量长度相同的卷积来实现。在编码层,原始模型采用Dropout方法将部分神经元进行失活,经过预实验表明,DropPath方法会取得更好的效果,因此在改进的Vision Tansformer模型编码层采用DropPath方法。原始模型编码层进行了12次的迭代,这对于ImageNet21K这种庞大且分类多的数据集而言是有效的,但本文仅对裤装廓形进行识别,数据量较小,使用过多层数进行迭代不仅会增加模型的训练时间而且会造成过拟合,因此改进的模型将编码层迭代次数设置为6次。对于解码层,原始模型采用全连接层+tanh激活函数+全连接层组成,本文基于迁移学习方法将其设置为一个全连接层。
2.4" 迁移学习
迁移学习是指将预先学到的知识应用于解决新的问题,其目的是从一个或多个源任务中抽取知识、经验,然后再应用于其他任务[14]。在本文的裤装廓形分类任务中,数据集通过增强后仅有14 000张,这与Vision Transformer模型原训练数据集相比大大不足。为了保障少样本下模型的准确率,通过迁移学习的方法可提高模型的稳定性和泛化能力。先利用大批量的数据集进行模拟训练,提取图片浅层信息,保存模型权重后再迁移到另一个目标任务。
本文首先将Vision Transformer模型在ImageNet21K上进行预训练,获取模型权重,将其应用于裤装廓形分类任务中,如图5所示。再在解码层创建一个新的全连接层(FC)和softmax函数进行分类,对改进部分采用裤装数据集进行重新训练,从而实现模型的快速收敛。
3" 实验结果与分析
3.1" 实验设计
实验环境配置参数:操作系统为Windows 10,运算平台为CUDA12.2,GPU为NVIDIA GeForceRTX 2060 6GB,CPU为Intel(R) Core(TM) i7-9700处理器,Python版本为3.8,Pycharm2022开发工具,实验采用Pytorch深度学习框架。在训练中,实验模型的超参数选用学习率为0.000 1,epoch为120,batch为16,模型优化器为Adam优化器,数据集的图像尺寸为224 mm×224 mm。
3.2" 实验结果分析
3.2.1" 数据集大小对比
表1为经过数据增强后的裤装测试数据集和原裤装测试数据集在基于迁移学习的Vision Transformer模型上训练后的准确率和召回率。由表1可以看出,经过数据增强后,准确率与原来相比有了一定的提升,平均识别精度从93.99%提升到了95.48%,召回率从93.6%提升到98.01%。这是因为原始数据集图像数量较少,复杂的图像背景和不同的肢体姿势会影响模型的判断,通过数据增强后,增加数据集的大小,可以提升模型对多样性图片的学习判别能力。
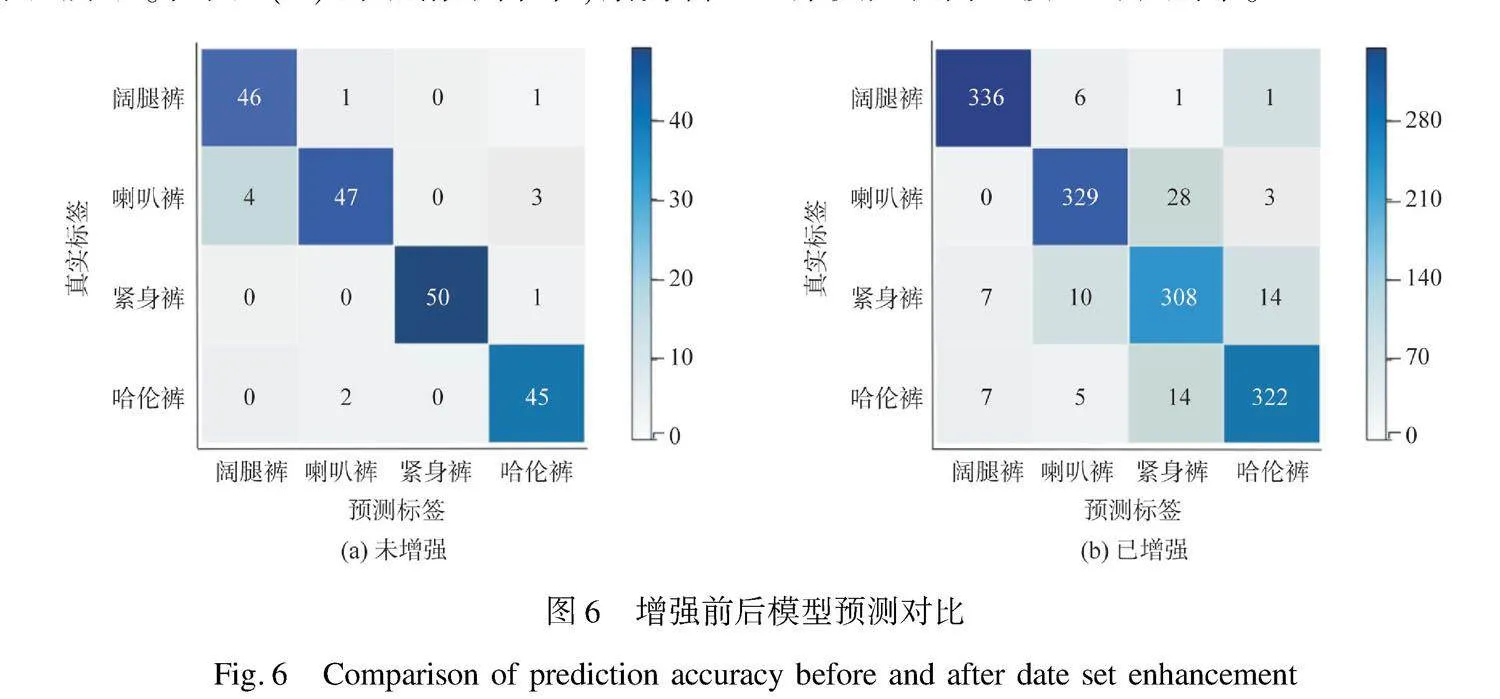
为了进一步评估增强裤装数据集对模型识别任务的影响,在经过对比实验后,通过混淆矩阵来展示增强前和增强后的预测结果,如图6所示。在图6(a)的混淆矩阵中,紧身裤
廓形预测成功率达到100%;在图6(b)的混淆矩阵中,紧身裤廓形预测成功率为97%。这是因为紧身裤贴合人体曲线,相比其他廓形而言受到背景的影响较小,在模型训练中,少量数据集能更快辨别其图像特征。对于其他裤装廓形而言,数据集变大提高了模型的识别率。
3.2.2" 模型对比
本文采用ResNet50、MobileNetV2与Vision Transformer模型进行对比,从而进一步证明Vision Transformer模型在裤装廓形分类上的准确性。在相同的数据集和实验条件下,4种不同模型在验证集上训练的准确率如表2所示,可见MobileNetV2模型的分类准确率最低,其次是ResNet50模型,传统的Vision Transformer模型的分类准确率为95.21%,而改进后的Vision Transformer模型分类准确率达到了97.72%。图7为3种模型在验证集上训练时的准确率变化,可以看出MobileNetV2模型收敛速度较慢,迭代40次左右逐渐收敛,在3种模型中表现效果最差。ResNet50模型的初始识别准确率最高,在迭代20次左右时落后于改进的Vision Transformer模型,改进的Vision Transformer模型迭代20次后逐渐收敛,且此时模型的准确率高于其他两种模型。由上述分析可知,改进后的Vision Transformer模型具有更高的识别准确率,鲁棒性更强,能达到更快更好地对裤装廓形进行分类。
4" 结" 论
本文基于自注意力机制,提出了一种改进的Vision Transformer模型,并采用迁移学习方法将其运用于裤装廓形识别。为了避免模型过拟合,本文对收集的数据集进行了数据增强;为了提高改进Vision Transformer模型的预测准确率,本文在Vision Transformer模型的输入层引入CNN结构,在编码层将DropPath方法替代Dropout,在输出层设置为一个全连接层。然后利用迁移学习在本研究增强后的数据集上训练改进的Vision Transformer模型。实验结果表明:通过数据增强方法可以有效提高模型泛化能力,数据增强前后测试集的平均识别率由93.99%提升到了95.48%;经过4种模型的对比,改进的Vision Transformer模型在验证集上的识别准确率达到97.72%,比MobileNetV2模型高出10%,具有较好的裤装廓形识别能力,在服装款式、服装廓形分类识别方面具有较高的应用价值。
《丝绸》官网下载
中国知网下载
参考文献:
[1]CHOLLET F. Xception: Deep learning with depthwise separable convolutions[C]//Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 1251-1258.
[2]LIU Z, LUO P, QIU S, et al. Deep fashion: Powering robust clothes recognition and retrieval with rich annotations[C]//Conference on Computer Vision and Pattern Recognition (CVPR).
Honolulu: IEEE, 2016: 1096-1104.
[3]包青平, 孙志锋. 基于度量学习的服装图像分类和检索[J]. 计算机应用与软件, 2017, 34(4): 255-259.
BAO Q P, SUN Z F. Clothing image classification and retrieval based on metric learning[J]. Computer Applications and Software, 2017, 34(4): 255-259.
[4]XIA T E, ZHANG J Y. Clothing classification using transfer learning with squeeze and excitation block[J]. Multimedia Tools and Applications, 2023, 82(5): 2839-2856.
[5]王雅静, 宋丹. 基于 BP 神经网络的女性服装款式分类技术研究[J]. 轻工科技, 2020, 36(4): 107-109.
WANG Y J, SONG D. Research on women’s clothing style classification technology based on BP neural network[J]. Light Industry Science and Technology, 2020, 36(4): 107-109.
[6]李青, 冀艳波, 郭濠奇, 等. 基于深度学习的女衬衫图案样式识别分类[J]. 现代纺织技术, 2022, 30(4): 207-213.
LI Q, JI Y B, GUO H Q, et al. Pattern recognition and classification of women’s shirts based on deep learning[J]. Advanced Textile Technology, 2022, 30(4): 207-213.
[7]庹武, 郭鑫, 张启泽, 等. 基于SE-Inception v3与迁移学习的服装袖型识别与分类[J]. 毛纺科技, 2022, 50(10): 99-106.
TUO W, GUO X, ZHANG Q Z, et al. Clothing sleeve recognition and classification based on SE-Inception v3 and transfer learning[J]. Wool Textile Journal, 2022, 50(10): 99-106.
[8]吴欢, 丁笑君, 李秦曼, 等. 采用卷积神经网络CaffeNet模型的女裤廓形分类[J]. 纺织学报, 2019, 40(4): 117-121.
WU H, DING X J, LI Q M, et al. Classification of women’s trousers silhouette using convolution neural network CaffeNet model[J]. Journal of Textile Research, 2019, 40(4): 117-121.
[9]VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//31st Annual Conference on Neural Information Processing Systems (NIPS). California: La Jolla, 2017: 4-9.
[10]JIE Z, PEI K, XING P Q, et al. ChatGPT: Potential,prospects,and limitations[J]. Frontiers of Information Technology amp; Electronic Engineering, 2024, 25(1): 6-11.
[11]PARMAR N, VASWANI A, USZKOREIT J, et al. Image transformer[C]//35th International Conference on Machine Learning (ICML). Sweden: Stockholm, 2018: 4055-4064.
[12]DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C]//The Ninth International Conference on Learning Representations (ICLR). Vienna: OpenReview, 2021: 1-21.
[13]TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers amp; distillation through attention[C]//International Conference on Machine Learning (ICML). California: San Diego, 2021: 7358-7367.
[14]CHEN J Y, ZHANG H W, HE X N, et al. Attentive collaborative filtering: Multimedia recommendation with item-and component level attention[C]//40th International ACM SIGIR Conference on Research and Development in Information Retrieval. Tokyo: SIGIR’17, 2017: 335-344.
Recognition and classification of trouser silhouettes based on Vision Transformer and migration learning
ZHANG Chi, WANG Xiangrong
YING Xina,b, ZHANG Ninga,b, SHEN Sia
(a.School of Fashion Design; b.Nanchang Key Laboratory of Digitization, Jiangxi Institute of Fashion Technology, Nanchang 330201, China)
Abstract:
To improve users’ satisfaction in purchasing clothes on e-commerce platforms, shopping websites currently use manual input text or search pictures to help consumers find clothes. However, it is quite difficult for consumers to find satisfactory clothing in a short time when the information of clothing is not detailed. To quickly find clothing that meets the needs of consumers, shopping websites shall classify clothes according to user’ preferences and styles, and label each item of clothes. However, for huge garment image data, manual annotation classification methods require a lot of time and labour and are susceptible to human subjective factors. Therefore, it is necessary to study the method of quick picture classification using computer networks. The algorithm based on deep learning can extract useful features from large-scale clothing image data, and then classify them with much higher accuracy and speed than traditional manual labeling and classification methods. This shortens consumers’ search time and narrows the search scope, thus providing consumers with more accurate results.
To address the problem of inaccurate classification of pant silhouette recognition and classification models, the Vision Transformer model with self-attention mechanism was adopted to realize the classification of pant silhouette images. Firstly, by adding self-attention mechanism and enhancing useful feature, the interference problem of image background and other irrelevant information on profile recognition was solved. Secondly, the transfer learning method was used to train and verify the profiles of four types of pants, including wide-leg pants, bell-bottom pants, tights and Harem pants. Finally, the improved Vision Transformer model was compared with the traditional CNN model to verify the model effect. In this paper, the CNN structure was introduced into the input layer of the Vision Transformer model, Dropout was replaced by DropPath method at the coding layer, and the output layer was set to a fully connected layer. Then, transfer learning was used to train the improved Vision Transformer model on the enhanced data set of this study. Experimental results show that the method of data enhancement can effectively improve model generalization ability. The average recognition rate of the test set is increased from 93.99% before data enhancement to 95.48% after data enhancement. After comparison of four models, the recognition accuracy rate of the improved Vision Transformer model in the validation set reaches 97.72%, being 10% higher than the MobileNetV2 model.
The model in this paper has a good ability to identify the silhouette of trousers, and has a high application value in the classification and recognition of clothing styles and silhouettes.
Key words:
pant silhouette; self-attention; Vision Transformer; transfer learning; image classification; contour recognition
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
VOGUE服饰与美容(2020年1期)2020-04-17 14:42:25
小资CHIC!ELEGANCE(2018年32期)2018-11-05 09:47:54
小资CHIC!ELEGANCE(2018年17期)2018-06-15 01:29:02
传媒评论(2017年3期)2017-06-13 09:18:10
小资CHIC!ELEGANCE(2017年6期)2017-03-20 16:49:33
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
纺织服装周刊(2015年33期)2015-10-29 02:56:50
丝绸(2014年11期)2014-02-28 14:56:09
大学(2008年8期)2008-09-01 10:23:16
