
基于大数据分析的油源对比初试
2024-12-31 00:00:00沈东义
电脑知识与技术 2024年33期

关键词:大数据分析;油源对比;生物标志化合物;石臼坨凸起;机器学习
0 引言
油源对比是油气运移示踪及成藏过程研究的重要基础,对于多源供烃构造,油气来源的厘定,还是准确计算油气资源量的前提[1-3]。目前油源对比主要通过对比原油与烃源岩抽提物中生物标志化合物参数的相似性来实现,常用生物标志化合物参数甾萜烷、类异戊二烯烷烃、芳烃等参数等,如C27-C28-C29甾烷相对含量、姥鲛烷(Pr) 和植烷(Ph) 比值、伽马蜡烷/C30藿烷。除生标参数之外,原油与烃源岩抽提物的族组分或单体烃同位素组成,油源中微量元素组成,以及孢粉化石等,也常用于油源对比工作[1,4-5]。由此可见,可用于油源对比的参数种类繁多,比值类参数更是可随意组合而成。但是,由于传统的油源对比工作是通过人工分析来完成,只能选择有效的参数进行分析。受地化参数多解性的影响,仅有个别参数进行人工对比,难以得到可靠的结论,特别是多源供烃的地区,不同的研究者选用不同的参数,可能会得到不同结论[6]。
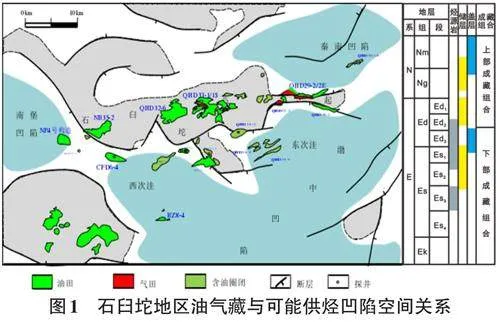
基于大数据分析的机器学习,是一种基于对数据进行表征学习的方法,它使用多层网络,能够学习抽象概念,同时融入自我学习,逐步抽象出相关概念,从而形成理解,并最终做出判断与决策[7-9]。通过构建具有一定“深度”的模型,可以让模型来自动学习好的特征表示(从底层特征,到中层特征,再到高层特征),从而最终提升预测或识别的准确性[10-11]。由此可见,机器深度学习可以解决目前油源对比中存在的参数应用不全、参数适用性难以把握等问题。对于已经获得一定数量分析样本的含油气盆地,可以通过机器深度学习的技术,完成油源来源的精确分析。渤海湾盆地石臼坨凸起被秦南、渤中、南堡3个生烃凹陷围绕,具有多源供烃的地质条件[12-14]。近40年的油气勘探和研究工作,积累了丰富的原油和烃源岩分析资料,是基于数据分析开展油源对比的理想地区。如图1所示为石臼坨地区油气藏与可能供烃凹陷空间关系。
1 研究思路和方法
为了实现基于大数据学习的油源对比,首先需要基于成藏背景分析,综合各类地化和成藏信息,给出已发现油气和潜在烃源岩的亲源关系,为模型训练提供样本。在此基础上,构建可供训练的样本集,并在亲源关系的约束下进行算法训练与建模。具体包括:数据库建立与数据预处理、特征工程、降维、聚类、深度模型训练等。同时进行智能模块研发和应用,形成油源对比软件和工具,实现油源对比的标准化和智能化,提高油源对比的工作效率和准确性。具体的思路如图2。
2 已发现油气来源分析
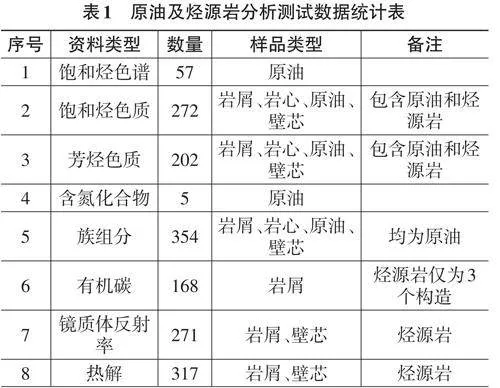
石臼坨凸起位于渤海湾盆地海域中西部,为一长期发育的古隆起,是周边秦南、渤中、南堡等生烃凹陷油气的长期运移指向区[15-16]。秦南、渤中、南堡3个生烃凹陷均发育沙三、沙一、东营组3套烃源岩,因此石臼坨地区存在9个潜在供烃源岩[17-19]。原油和烃源岩抽提物中的生物标志化合物,是来源于生物体的特征化合物,在地质演化过程中保留生物信息(碳骨架)的化合物,它们在原油中的含量或相对比值能够指示母质来源、生成环境及成熟阶段等信息,是进行油源对比的基础,也是本次进行大数据分析的特征向量。本次研究共收集整理了1646组原油及烃源岩分析测试数据,其中烃源岩生物标志化合物测试数据(包括饱和烃甾萜烷、芳烃两大类)110组,原油(包括原油和油砂抽提物)生物标志化合物测试数据162组,其他为有族组分、有机碳、热解等(表1) 。其中用于油源对比分析的资料主要是272组生物标志化合物分析数据,有族组分、有机碳、热解等数据主要用来判别烃源岩的有效性。
利用上述数据,在烃源岩有效性分析的基础上,采用地质-地球化学综合分析的方法,厘定了已发现油气的来源及烃源岩贡献比例。具体工作流程如下:1) 构造位置确定供烃凹陷,即根据已发现油气的构造位置,确定可能的供烃凹陷。按照这一思路,洼陷与斜坡带的油气,均为单凹供烃,而凸起高点的油气可能为两凹或三凹供烃。2) 储集层位判断供烃层段,即根据油气储集的层段,确定潜在的供烃层段,其中沙河街组油气为单一烃源岩供烃,而东营组及以上层段储集的油气,可能为多层段烃源岩供烃。3) 油源关系助对比:即下部或直接对接的烃源岩供烃有效,沙三段充注能力最强。
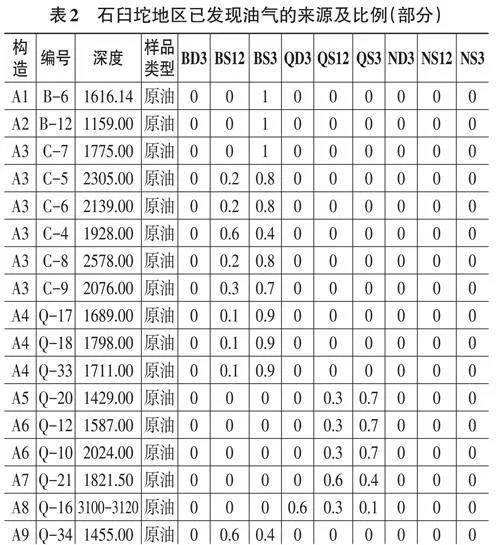
在上述地质分析的基础上,结合地化参数,完成了石臼坨凸起162个原油/油砂样品的来源和油源比例,对比结果(部分)如表2。
以本次厘定亲源关系的烃源岩、原油(含油砂抽提物,下同)样品为研究对象,通过数据集的构建与特征分析,完成了地球化学特征参数的降维。在此基础上,利用分类和回归分析算法,构建了多个油源对比模型,并进行了优选与应用。
3 数据集的构建与特征参数预处理
烃源岩抽提物和原油中含有多种生物标志化合物,利用它们的含量与比值,可以提取出多个油源对比参数,这些参数构成了烃源岩和原油的特征值,即样品的特征向量。基于大数据分析的油源对比,需要烃源岩和原油样品具有相同的特征参数(向量)。但是,由于分析仪器或样品本身差异,常常导致某一化合物及与其相关参数的缺失,使得样品之间的特征参数不一致。因此,首先需要建立数据集并对数据进行预处理。
3.1 数据集的构建
本次研究共提取了161个烃源岩抽提物和原油的特征向量,其中饱和烃化合物58个,包括正构烷烃、异戊二烯类烷烃、甾萜烷烃;饱和烃比值58个,包括Pr/Ph、Ts/Tm、伽马蜡烷/C31升藿烷等。芳香烃化合物38 个,包括苯、菲、萘、芴及其系列化合物;芳香烃比值参数7个,包括MNR、ENR、MP1等。272个烃源岩抽提物与原油中生物标志化合物相对含量,均来源于渤海某油田的饱和烃和芳烃的色谱、色质分析资料,化合物比值由笔者计算获得,涵盖了目前常用的母质来源、生成环境、成熟阶段等油源对比参数。
为了方便数据检索、分类计算等,在数据集建立时,还保留了样品的井号、所属构造、采样层段、样品类型等信息。
3.2 数据预处理和特征工程
在基于大数据分析的机器学习中,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。油源对比所用数据,来自烃源岩抽提物和原油样品的测试分析,在模型训练前需要对测试结果进行分析,并优选/构建特征向量,即进行数据预处理和降维,以便最大限度地从原始数据中提取特征以供算法和模型使用。针对样品分析数据的特点,本次数据预处理工作,是对数据进行审核,去除异常值,剔除未检测到的化合物,以及与之有关的参数,并对各参数进行标准化处理。除此之外,还开发了特征向量关联性分析工具,以实现对样本库缺失数据进行智能算法填充。
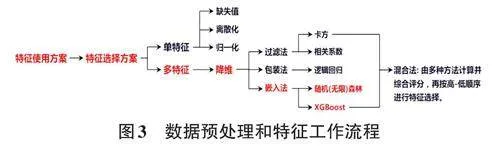
从色谱、质谱分析资料获得的161个参数,对油源来源的指示作用不同。为了从中提取最具来源特征的参数,以供后续算法和模型的使用,需要开展特征工程。在本次研究中,笔者开发了一种混合了过滤法、嵌入法和包装法的特征选择算法,该混合法由6个具体算法组成,先由6个算法分别计算特征重要性,然后综合评分,再从高分到低分顺序进行特征选择,如图3所示。
4 数据集的构建与特征参数预处理
4.1 烃源岩智能聚类
油源对比通过比较已发现油气与潜在烃源岩的相似性以确定油气来源。为了准确厘定一个研究区已发现原油的来源,首先需要明确该地区各潜在烃源岩的特征,即给出烃源岩标签。烃源岩抽提物是原地滞留的原油,可以用来表征烃源岩特征。本次研究采用智能聚类算法处理了110个烃源岩抽提物样品的特征参数,自动给出烃源岩标签。算法模型公式如下所示:
其中:xi、si 为第i 个参数(特征),wi、ai 为第i 个特征的权重。
函数f (w ) i xi 为不同烃源岩之间的离散程度,该值越大越能表征油源特征。
函数g (a ) i si 为同一烃源岩不同样品之间的离散程度,该值越小越能表征油源特征。
4.2 算法与模型训练
利用经过预处理及降维后的数据,采用分类和回归的大数据分析算法,完成了油源对比算法研究,在KNN、SVM、MLP(神经网络)等众多分类和回归算法的实验基础上,优选出了随机森林分类、XGBoost分类,以及随机森林回归、XGBoost回归等算法。
在模型构建过程中,笔者根据烃源岩抽提物和原油地化参数的示源意义与样本数据的缺失情况,优选生物标志化合物等进行模型训练与评估,并在模型训练中加入了网格搜索法进行模型与参数的优化。在模型的训练和优化过程中,可进一步得到该优化模型的特征选择结果,以便地质人员对模型预测结果进行解释。
本次研究中,优选出两类模型,即随机(无限)森林模型和XGBoost模型。从模型的训练结果看,随机(无限)森林模型平均绝对误差 (MAE)为0.105,Test_MAE为 0.0274,(训练)准确率为 97.26%,(实际)准确率为 72.23%。XGBoost 模型MAE 为 0.1067,Test_MAE为 0.000237283,(训练)准确率为 99.98%,(实际)准确率 69.87%。
4.3 深度模型的应用
为验证模型的实际应用效果,利用随机森林、XG⁃Boost等分类和回归算法模型,对未参与训练的5个原油样品进行了来源分析(样品来自CFD11-3E-3d 井)。油源分析结果表明,这5个油源均源自渤中凹陷,其中以沙三段烃源岩供给为主,贡献比为60.0%-79.7%;次为沙一段烃源岩供给,贡献比为13.3%~23.3%;东三段烃源岩的贡献小于10%。该结果与地质-地球化学分析结果相一致。
5 结束语
大数据分析油源对比,有效改善了传统依赖人工经验分析的工作模式,大大地减少了人工收集资料和综合预测的成本。通过模块研发和应用,将减少80% 科研数据收集时间,油源对比预测的效率预计提高近60%。需要指出的是,由于样品数量和分析成本的限制,能够获得并用于机器的数据有限。另外,每一个样品均含有多个特征向量,且受多种地质因素的影响,使得它们在示源中的作用发生改变,从而增加了机器学习的难度。因此,在下一阶段研究中可以考虑如何提升样本的质量,样本的质量决定了算法的评估效果。另外,可以将如何提升算法的准确性作为下一步研究的重点。
