
基于多源数据的智慧资助方法研究
2024-12-31 00:00:00张波
电脑知识与技术 2024年33期
关键词: 智慧资助;资助对象识别;支持向量机;多源数据融合
0 引言
学生资助工作是学生工作的重要组成部分,准确地识别资助对象是实现“精准资助”的前提和基础,也是资助工作的重点和难点。现实资助工作中,由于学生数量众多且情况各不相同,常出现资助对象识别不准确的情况。
目前,学生资助普遍采用是学生先申请再进行人工审核的传统模式。具体操作办法是让学生填写申请表格,辅导员及学校资助工作人员再通过佐证核实、个体访谈、数据比对、民主评议、名单公示等方式进行资助对象的确定以及后续的资助工作[1]。传统资助模式高度依赖学生申请和人工审核,存在流程烦琐、耗时长、资助对象识别准确率难以保证的缺点。随着信息技术的发展,各学校陆续建设了包含资助信息管理功能的学工系统。资助工作由过去的线下申请审核逐渐转向线上办理,但办理流程和资助对象识别方式并未发生实质变化。“隐性贫困”和“虚假贫困”一直是资助对象识别过程中需要克服的难题,严重影响了资助工作的质量[2]。“隐性贫困”指的是应当获取资助的困难学生在实际资助工作中未获取资助。“隐性贫困”主要是由于学生对资助政策不了解或心理因素等原因导致未主动申请或申请后在资助审核过程中未被认定为资助对象。“虚假贫困”指的是不应接受资助的普通学生在实际工作中被错误认定为资助对象。“虚假贫困”主要是由于学生提供的佐证信息不实或资助工作人员工作经验不足等原因导致的。为了避免“隐形贫困”和“虚假贫困”,传统资助模式下需要多次宣传动员,让学生根据实际情况积极申请,同时也需要经验丰富的资助工作人员多角度仔细审核,需要耗费大量的时间及人力资源才能保证资助对象识别的准确率。
近年来,包括智慧资助在内的智慧校园建设工作不断推进,部分学校开始将大数据、人工智能等技术应用到学生资助工作上,提出了多种利用学生一卡通消费记录、校园活动记录等校园动态数据识别资助对象的方法[3]。这类方法不依赖学生的主动申请和资助工作人员的逐层审核,简化了资助工作流程,保护了学生的隐私,提高了资助工作的效率。但随着外卖就餐、网络购物越来越高,支付宝、微信等第三方支付平台使用率越来越频繁,当下相当比例的学生会进行网络消费,校内消费也有部分通过微信、支付宝等第三方支付平台实现。相较于过去学生的消费行为主要依赖校园一卡通在校内产生,这些网络消费及第三方支付平台难以在一卡通数据上体现。缺少了这些数据统计,单从校园一卡通数据来看,这部分学生容易被误判为需要资助的困难学生,导致“虚假贫困”现象的产生。依靠校园一卡通及校内活动记录的智慧资助方法为了保证资助对象检测的准确性,往往需要获取学生的网络购物、外卖就餐、第三方支付等动态信息作为辅助。现实工作中及时准确获取这些校外动态信息的难度较大,对于学校的校外动态信息获取能力提出了较高要求。
1 理论基础与特征选择
本文提出了一种不依赖学生申请和人工审核的智慧资助方法,利用学生基础信息、国家资助系统推送、历史资助、勤工助学等容易获取的数据实现资助对象的识别。在这些数据中选择与学生家庭经济情况相关性较高的特征设计支持向量机分类器,再利用设计的分类器将学生分为“资助对象”和“普通学生”两类人群,实现资助对象的识别。
1.1 支持向量机
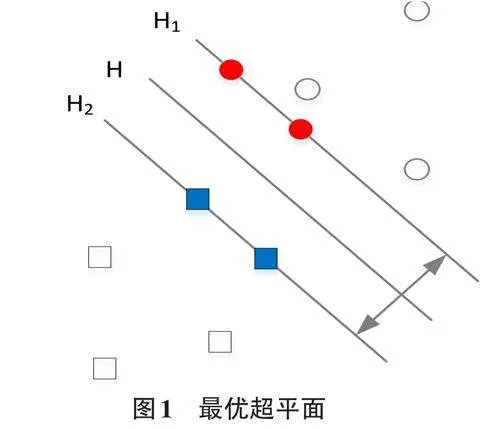
支持向量机(support vector machine,SVM) 是基于统计学习理论和结构风险最小化原理的监督式机器学习方法,主要用于分类和回归分析。如图1所示其基本原理是通过构造一个最优的超平面来将两类数据分开。其核心问题是获取便于实现分类的超平面,实现正例与负例之间的隔离边缘最大化,从而有助于实现更好地识别与分类。
对于实际应用过程中更常见的非线性可分的问题,SVM一般通过将多类问题转换成便于分类的二分类的方式来实现求解。在这个过程中不需要进行复杂的运算,而是利用如线性核、高斯函数核、多项式核等核函数将输入数据从原始空间映射到更高维度的特征空间,从而寻找一个线性可分的超平面,可以实现复杂计算过程有效的简化,因此具备较强的解决复杂模式的能力,使用较多的几种核函数如下列公式所示[4]:
SVM训练过程中不直接拟合所有数据点,而是主要关注对决策边界影响大的支持向量。这一特点使SVM模型对于噪声和异常值相对鲁棒。实际工程应用中SVM在小样本、非线性、高维模式识别的诸多问题上效果出众,已被广泛应用于智慧资助等各类分类应用中。相较于其他模式识别算法,支持向量机由于结构简单,也具有运算速度较快的优点。基于支持向量机的这些优点和校内资助数据特点,本文选择支持向量机分类器用于资助对象的识别和分类工作。
1.2 数据源及分类特征选择
本文在选择数据源时主要考虑数据准确及数据易获取两个要素。数据准确可以减少后续算法的误差,保证资助对象检测的准确性。数据易获取则有利于算法在实际工作中的应用和推广,各个学校的资助发展水平并不一致,很多学校暂不具备及时准确获取学生的网络购物、外卖就餐、第三方支付等校外动态信息的能力。恰当的分类特征选择在支持向量机中起着至关重要的作用,可以提高模型分类性能同时减少噪声影响。本文在基于源数据的分类特征选择时主要考虑与家庭情况的相关性,并尽可能地减少数据冗余、减少数据的维度。本着以上原则,主要的数据来源及特征选择如下:
1) 学生基础信息
各学校在学生录取及入学时都会进行学生基础信息的统计,该信息在校期间也会进行及时的更新及维护。基础信息中学生父母的职业、家庭条件等信息与学生是否需要资助有较高的相关性。同时,由于基础数据涉及多部门使用,该项数据各学校都较容易获取且数据准确。鉴于此,本文选择学生基础信息中的“家庭背景”作为分类器训练的特征之一,“家庭背景”根据父母职业及困难信息登记分为“困难”和“普通”两类。
2) 全国学生资助管理信息系统
全国学生资助管理信息系统是由国家资助中心建立的一个覆盖全学段的资助管理系统,该系统实现了与国务院建档立卡系统、民政部低保系统、中国残联残疾人信息管理系统的信息共享。该系统会定期给各学校推送国务院建档立卡系统、民政部低保系统、中国残联残疾人信息管理系统共享的信息供学校资助工作人员参考。在实际工作中发现国家资助系统推送的学生,除学籍异动等个别情况,经核实后绝大部分都是需要资助的。国家系统是否推送与学生是否需要资助有较高的相关性。实际接受资助的学生中有部分并不是国家资助系统推送的学生,但国家资助系统推送的学生绝大部分都是最终接受资助的学生,同时该项信息是由国家资助系统推送,数据准确且获取容易。鉴于此,本文选择全国学生资助管理信息系统中的“国家资助系统推送”作为分类器训练的特征之一。
3) 历史资助数据
在国家资助中心的指导下各学校都根据实际情况建立了符合政策要求的“奖、助、贷、减、补、勤”学生资助体系。实际资助工作中,各学校大多会以学年或学期进行家庭情况的评定,即每学年或每学期重新评定困难学生并在评定基础上给予资助。由于家庭情况变化等原因,会出现上个资助周期是资助对象的学生因家庭条件好转导致在新周期不再是资助对象,也会出现原本不是资助对象的学生在新周期因为家庭突发变故而变为资助对象。同一学生在校期间的家庭经济情况会发生变化,但实际工作中发现这种变化占学生总人数的比例不大。上个资助周期是否接受资助,特别是助学金、学费减免这类金额较大的资助与新的资助周期是否为资助对象有较高的相关性。资助工作由于涉及资金发放,各学校都会对实际发生的资助数据做好记录并存档,这项数据准确同时获取容易。考虑到“奖、助、贷、减、补、勤”中的奖学金与学生家庭情况相关性不大,勤工助学由于情况特殊单独作为一个特征统计。鉴于此,本文对“奖、助、贷、减、补、勤”中除去奖学金及勤工助学部分的资助金额进行求和来计算“历史受助金额”,并作为分类器训练的特征之一。
4) 勤工助学数据
勤工助学作为高校“奖、助、贷、减、补、勤”资助体系的重要部分,具有将扶贫与扶志相结合的特点,区别于其他直接发放或减免资金的资助项目,勤工助学需要学生付出相应劳动才能拿到报酬[5]。每月最多480 元的劳动报酬对于在校学生来说能在一定程度上解决基本生活问题。原先不是资助对象的学生在突发家庭困难后往往会通过申请勤工助学岗位等手段解决生活问题。由于需要付出相应劳动才能获取报酬,部分家庭条件好转的学生如无自我锻炼的需求往往不会再选择勤工助学岗位。实际资助工作中发现勤工助学岗位的申请变动及工作时长与是否需要资助具有较大的相关性,同时学生处的这项数据准确且获取容易。鉴于此,本文选择勤工助学数据中的“勤工助学申请变动及工作时长”作为分类器训练的特征之一。
2 算法设计与实验分析
2.1 数据获取与预处理
本着准确易获取的原则,从国家资助平台、校内学工平台获取原始数据。在原始数据中选择家庭背景、国家资助系统推送、历史受助金额、勤工助学变动及金额作为特征进行分类。这些不同来源的数据格式不同,为了提高数据的质量和可用性在数据分析使用前需要进行预处理,预处理的质量直接影响到后续分析的准确性和可靠性。
原始数据需要进行数据清洗和填充并将异构数据转换为统一格式的数据。去除数据中如姓名、学号、身份证号等重复记录的冗余数据,便于将维度较高的特征数据转换为低维度的特征数据。在基础信息统计及录入时会有少量信息缺失值以及异常值的出现,可根据数据情况采取删除、插补等方法进行处理。为了避免某些特征因为数值过大或过小而在模型中占据主导地位,将不同量纲的数据转化到同一尺度进行归一化处理,并按实际资助工作经验设计特征权重。
2.2 支持向量机分类器训练
支持向量机的训练集主要用于支持向量机分类器的训练,测试集是未参与过训练的部分数据,用来测试评估分类器的性能。选择安徽工业经济职业技术学院2022级共4 000名学生的数据进行实验,通过数据清洗等预处理后删除了221例数据,选择3 779例数据进行实验。按照数据集和测试集约占总数80% 和20%的比例进行划分,从实验数据中选择2 979例数据用于产生支持向量机分类器的训练样本集,剩下800例数据用来测试算法的整体性能。
以2023年学校审核通过并已完成资助的结果为标准,将训练数据集的数据标记生成“普通学生”和“资助对象”两个训练样本集,提取预处理过的数据的家庭背景、国家资助系统推送、历史受助金额、勤工助学变动及金额作为特征进行训练,生成支持向量机分类器。
2.3 实现分类与结果分析
将测试数据分成四组,每组200例数据,进行算法的分类性能测试。以2023年学校审核通过并已完成资助的信息作为准确结果,统计本文所提资助算法的检测效果。采用召回率(Recall) 、虚警率(False Alarm) 、准确率(Accuracy) 来衡量智慧资助算法的性能。其中召回率的定义为检测学生中被正确识别为需资助的学生占真实需要资助学生的比例,取值范围在0到1之间,比例越高说明“隐形贫困”的学生占学生总数比例越少,算法性能越好。虚警率的定义为被识别为需资助的学生中不是真实需要资助的学生的比例,取值范围在0到1之间,比例越低说明“虚假贫困”的学生占学生总数比例越少,算法性能越好。准确率表明算法正确识别的学生占学生总数的比例,体现算法的总体检测能力,取值范围在0到1之间,越高说明算法整体性能越好。召回率、虚警率、准确率的计算公式如下[6]:
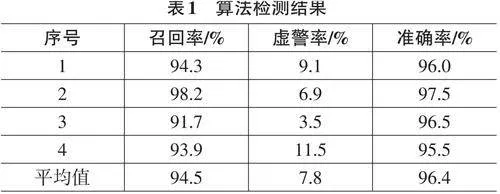
式中:TP为智慧资助算法正确识别的需资助学生的数量,FN为被智慧资助算法误判的需资助学生的数量,FP为被智慧资助算法误判为需资助学生的普通学生数量,TN为智慧资助检测算法正确识别的普通学生的数量,N为学生总数。表1为算法的测试结果。
由表1可见,对于四组测试数据,本文提出的基于支持向量机的智慧资助算法均能实现有效检测。平均召回率为94.5%, 即被算法正确识别为需资助的学生占真实困难学生的比例较高,接近最大值1,证明能够有效避免“隐形贫困”。平均虚警率为7.8%,即被算法错误识别为困难学生中的普通学生的比例较低,接近最小值0,证明算法能够有效避免“虚假贫困”现象。平均检测准确率为96.4%,接近最大值1,证明算法整体检测准确率较高。
3 结论
本文设计的智慧资助方法利用“资助对象”与“普通学生”在基础信息、国家资助系统推送、历史资助、勤工助学方面的特征差异,采取支持向量机实现资助对象的分类。实验结果表明,方法具有较高的检测准确率,能够在一定程度上减少“隐性贫困”与“虚假贫困”现象,从而助力实现“精准资助”。相较于传统的学生资助方法,在不依赖学生申请和人工审核的条件下能够实现有效的资助对象检测,在实现较高检测准确率的同时简化了资助对象的识别流程,提升了识别效率。相较于利用学生一卡通消费记录、校园活动记录等校园动态数据的智慧资助方法,本文方法使用的源数据更容易获取,不涉及校外动态信息,适应性更强。本文算法在对资助对象的进一步细化分类上并没有涉及,同时检测准确率方面也还有进一步提升空间,后续研究将重点针对这两点不足进行完善。
