
基于FastText的藏文新闻文本分类的研究
2024-12-31 00:00:00明玛卓玛高定国胡心龙旦增
电脑知识与技术 2024年33期
关键词:深度学习;藏文新闻;文本分类;FastText;性能比较
0 引言
随着信息技术的快速发展,新闻信息呈现出爆炸式增长的趋势,特别是在多语言环境下,文本分类技术的应用显得尤为重要。藏文新闻文本数量众多,其文本分类不仅关乎藏族地区信息的有效传播,还对促进藏族文化的传承与发展具有重要意义。藏文新闻文本分类旨在将海量的藏文新闻文本按照不同的主题或类别进行划分,以便用户快速浏览和筛选感兴趣的内容。在新闻推荐和舆情分析等领域,藏文文本分类发挥着至关重要的作用。
目前,藏文文本分类方法主要包括传统机器学习方法和深度学习方法。采用传统机器学习方法解决藏文文本分类问题已有不少研究。贾会强[1]在深入研究藏文语言特性及其语法结构后,系统探索了藏文文本的向量空间表示模型,并成功运用KNN算法进行了藏文文本分类研究。王勇[2]以朴素贝叶斯算法为核心,设计并实现了一个高效的藏文文本分类器。王莉莉[3]提出了一种基于集成多个分类器的藏文文本分类模型,融合了卷积神经网络、循环神经网络、长短时记忆网络以及双向长短时记忆网络等深度学习模型。苏慧婧[4]等的工作以词特征为基础,运用信息增益算法优化特征向量维度,并结合KNN模型实现了稳定的分类性能。
早期研究[1-4]在藏文文本分类上虽有所成效,但受限于无法深入捕捉文本语义,分类精度受限。随着深度学习技术的兴起,研究者们开始探索其在藏文文本分类中的应用,以期提升分类的精度和效率。近年来,随着深度学习在自然语言处理领域的深入发展,越来越多的研究聚焦于如何利用深度学习技术提升藏文文本分类的性能。Qun等人[5]显著推动了藏文文本分类领域的研究,首先构建了TNCC数据集,并应用CNN和LSTM模型,证明了神经网络在藏文文本分类上的优势。他们发现LSTM在短文本分类上优于CNN 和N-gram,而神经词袋模型在长文本上表现更佳。Li 等人[6]通过自建数据集测试多种深度学习模型,发现藏文词组在分类效果上优于音节。李艾琳[7]采用朴素贝叶斯分类器对Web舆情中的藏文文本进行了分类研究。此外,为了捕捉文本的上下文信息,研究者们还广泛采用了基于N-gram的藏文词和音节的文本分类方法。这些方法在逻辑回归、AdaBoost等常用分类模型中也得到了应用,进一步丰富了藏文文本分类的研究领域。Yan等人[8]在藏文新闻语料处理上进行了创新,他们首先进行了预处理,并基于藏文的词汇和语法结构特性,构建了一个藏文音节表。通过将音节嵌入每个藏文文本中,实现了每个音节到固定数值向量的转换。这种方法为整个藏文语料生成了向量化表示,这些表示被用作循环神经网络模型的输入。实验结果充分展示了循环神经网络模型在藏文文本分类任务中相较于传统机器学习方法的优势。
尽管已有研究在藏文文本分类领域取得了显著成果,但模型性能依然具有提升空间。针对当前方法中模型泛化能力不强、对特定类别文本分类效果不佳等问题,本研究采用公开数据集,通过对比研究不同深度学习模型在藏文文本分类任务中的性能,探索提升分类准确率的方法。
1 文本分类方法研究
1.1 文本分类模型的选择
文本分类作为自然语言处理(NLP) 领域中的一项基础任务,其重要性不言而喻。然而,藏文文本分类面临独特挑战,如复杂的语法、词汇含义和表达方式,以及文本数据的稀缺性和质量问题。具体来说,藏文与其他语言在表达习惯上的差异增加了文本分类的难度,而缺乏大规模、高质量的标注数据集则限制了深度学习等先进技术的应用。此外,藏文文本中可能存在的噪声和冗余信息也对分类性能构成了挑战。
在藏文新闻文本分类中,采用了基于n-gram[9]的特征表示方法。这种方法将文本视为由词和n-gram 组成的序列,并使用随机初始化的词向量来表示这些元素,从而将文本数据转换为模型可以理解的数值形式。FastText模型在处理这种表示时具有显著优势,因为它能够同时考虑词级和n-gram级别的特征,从而更全面地捕捉文本的语义信息。通过结合n-gram特征表示方法和FastText模型,为藏文文本分类提供了一种有效的解决方案。
1.2 FastText 模型的介绍
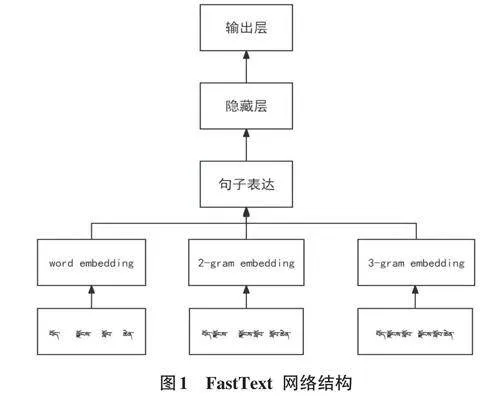
FastText在进行文本分类或情感分析时会生成词的嵌入(embedding) ,即embedding 是FastText 类别的产物。因此,在项目的运行入口文件run.py中,当选择的深度神经网络是FastText时,embedding会再次初始化为随机值。FastText和Word2Vec的CBOW模型框架非常相似,FastText也只有三层:输入层、隐藏层、输出层。输入层接收多个词向量表示的单词,输出层则是一个特定的标签,隐藏层对多个词向量进行叠加平均。FastText模型的主要三个层次包括:
1) 输入层。FastText的输入是多个单词及其ngram特征,这些特征用于表示单个文档并进行embed⁃ding。
2) 隐藏层。对输入的n-gram特征进行处理。
3) 输出层。输出层是文档对应的类标,主要思想是将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量进行SoftMax[10]多分类。Fast⁃Text在输入时将单词的字符级别的n-gram向量作为额外的特征;在输出时采用分层的SoftMax。如图1所示,以“བབོད་ལྗོབོངས་སློབོབ་ཆེཆེན་”(西藏大学)句子为例,其包含了3 个embedding层(为了区分词嵌入、2-gram嵌入和3-gram嵌入,示例中标注了3个嵌入层,实际上可以合并为一个),嵌入层后面是一个隐藏层即全连接层,输入为嵌入向量的均值,最后是输出层,也是一个全连接层进行类别分类。
2 实验
2.1 实验的数据集
为了验证所选模型的有效性,本文使用了李果等人[12]提供的公开数据集TNEWS。该数据集包含12种不同类别的藏文新闻文本标题,是藏文文本分类研究的重要资源。将TNEWS数据集按8∶1∶1的比例划分为训练集、验证集和测试集,以用于模型的训练和评估。
2.2 实验的环境配置
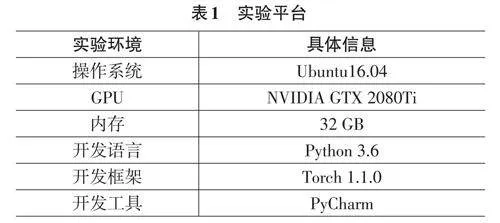
本文实验平台的相关配置如表1所示。
2.3 实验的设计
1) DPCNN:深度卷积神经网络模型,通过堆叠多个卷积层来提取文本的特征。
2) TextCNN:基于卷积神经网络的文本分类模型,通过卷积操作来捕捉文本的局部信息。
3) TextRCNN:递归卷积神经网络模型,结合了卷积神经网络和循环神经网络的优点。
4) TextRNN:基于循环神经网络的文本分类模型,能够捕捉文本的序列信息。
5) TextRNN_Att:在TextRNN 基础上引入注意力机制,使模型能够关注文本中的关键部分。
这些模型在文本分类任务中表现出色,并且具有不同的网络结构和特点。选择这些模型的原因是它们能够代表不同类型的文本分类方法,并且可以与FastText模型进行比较,以评估FastText模型在藏文新闻文本分类任务中的性能。
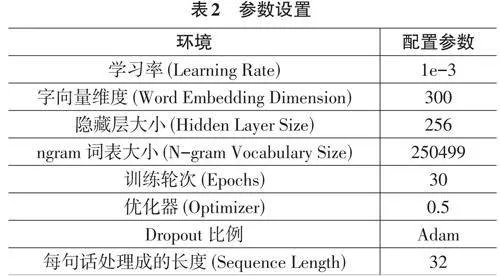
2.4 实验参数设置
本文实验平台的相关参数设置如表2所示。
2.5 实验结果分析
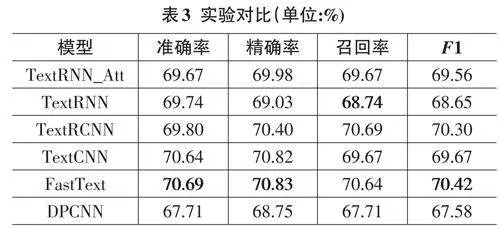
在相同的实验条件下,本文利用TNEWS数据集对所选模型进行了训练和测试。实验结果表明,Fast⁃Text模型在关键指标上均优于基准模型,具体结果如表3所示。
表3展示了各模型在准确率、精确率、召回率和F1分数上的性能对比。通过对比可以看出,FastText 模型在各项指标上均取得了较优的表现。特别是与DPCNN 模型相比,FastText 模型在准确率上提高了2.9%,在F1 分数上提高了2.8%,这进一步验证了FastText模型在藏文新闻文本分类任务中的有效性。
在本文的藏文文本分类任务中,我们评估了Tex⁃tRNN_Att、TextRNN、TextRCNN、TextCNN、FastText 和DPCNN六种模型的性能。实验结果显示,FastText和TextCNN在准确率上表现较好,其中FastText在精确率和F1分数上略占优势,显示出其在处理藏文文本时的有效性。TextRCNN也取得了接近的性能,表明其结合RNN 和CNN 的特性在文本分类任务中的潜力。相比之下,TextRNN和TextRNN_Att的性能略低,而DPCNN在本任务中表现最差。
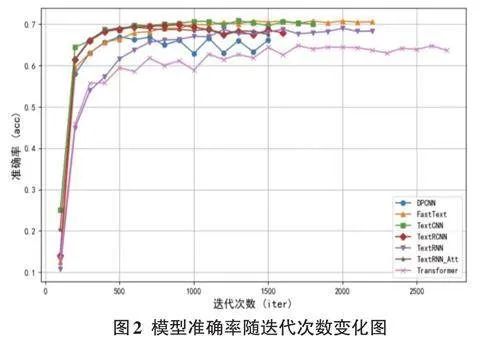
为了更直观地展示这些模型在训练过程中的性能变化,本文绘制了曲线图来反映准确率、精确率、召回率和F1分数随迭代次数的变化趋势,如图2所示。
如图2所示,这些曲线图不仅清晰地呈现了各模型在不同迭代次数下的性能差异,还提供了关于模型收敛速度和稳定性的重要信息。通过这些曲线图,可以更深入地理解各模型在藏文文本分类任务中的表现。
3 结论
藏文新闻文本分类非常重要。为了更好地进行藏文文本的分类,本文探讨了FastText模型的结构及其在藏文新闻文本分类中的应用方法,并通过实验与几种模型进行了比较。实验结果显示,FastText模型在藏文新闻文本分类任务中取得了优异的性能,在准确率、召回率和F1值等指标上均优于其他基准模型。这表明FastText模型能够有效地捕捉文本的语义信息,并且具有较好的泛化能力,适用于藏文新闻文本的分类。
