
基于知识图谱和数据增强的网络安全信息采集与分析
2024-12-31 00:00:00叶丽珠代丽娜郑冬花修位蓉
电脑知识与技术 2024年33期

关键词:知识图谱;网络安全信息;数据增强;采集与分析
0 引言
随着互联网信息技术的迅速发展,人们获取信息的方式逐渐从书本走向智能化,但随之而来的网络安全问题也日益频繁。因此,对更高层次的网络安全数据进行采集与分析具有重要的实践和理论价值[1]。知识图谱技术是一种通过图结构对客观世界的实体、实体关系和属性进行描述的语义网络,已被广泛应用于医疗、能源和金融等数据采集领域[2]。例如,吴小刚等人[3]基于知识图谱设计了一种新的电网智能调度辅助决策系统,对电网智能调度的时间与频率进行了优化。实验结果表明,该系统能够在较短时间内实现电网的智能调度,提高了电网的调度频率。韩一搏等人[4]为了提升煤矿综采设备的实体识别精度,提出了一种基于联合编码的煤矿综采设备知识图谱构建方法。实验结果显示,该方法对综采设备实体的识别准确率较现有方法提高了1.26%以上。周冰原等人[5]通过知识图谱技术对针灸治疗失语症领域进行了可视化 分 析 ,并 采 用 CiteSpace 6.1. R 2 及 VOSviewer V1.6.16软件对中国知网、万方数据知识服务平台和维普期刊全文数据库中的相关文献进行了数据整理。实验结果表明,知识图谱网络可视化分析得出的频次排名前五位的失语症类型为运动性失语、癔症性失语、经皮质运动性失语、命名性失语和感觉性失语。然而,目前尚未将知识图谱技术应用于网络安全领域的研究。鉴于此,本文针对网络安全的实体抽取与关系分类,引入了基于深度学习的知识图谱补全技术与数据增强方法,并利用预训练模型对数据增强方法进行了改进,提出了一种新型的基于知识图谱和数据增强的网络安全信息采集与分析的方法。
1 知识图谱技术的构建
在网络安全信息的采集过程中,通常会遇到多样化的阻碍,而知识图谱能够利用大数据对异常信息进行追踪溯源,从而应对复杂多变的网络攻击,针对性地减缓攻击,帮助管理者实时感知网络安全态势。同时,知识图谱技术通常需要多个环环相扣的流程与步骤来共同构建,主要包括知识抽取、知识融合和知识加工等三个步骤[6]。知识抽取负责网络数据的实体抽取、关系抽取与属性抽取;知识融合负责网络数据的实体消歧与实体对齐;知识加工则负责网络数据的图谱构建、知识更新与质量评估。通过对网络结构化数据的深度处理,知识图谱技术能够形成结构化的知识体系和高质量的知识集合,从而实现知识的统一管理,契合网络安全信息抽取的需求。网络安全信息的实体抽取模块结构图如图1所示。
由图1可知,该网络安全信息实体抽取模块主要包含变压器双向编码器词嵌入层、双向长短期记忆网络特征提取层、注意力机制层和条件随机场层这4个部分。首先,将网络安全信息输入至变压器双向编码器词嵌入层中,经过数据预处理,将网络安全信息处理为含有目标特征的向量信息。其次,将该向量信息数据输入至双向长短期记忆网络特征提取层中,以捕捉所需的目标特征信息。最后,通过注意力机制层与条件随机场层,输出实体标签。然而,知识图谱的不完整性限制了其进一步开发和应用,知识图谱补全技术是一种可以预测知识图谱中缺失的实体和关系,以保证知识图谱完整性的优秀技术[7]。传统的知识图谱补全方法主要分为三类:基于翻译距离的方法、基于张量分解的方法和基于深度学习的方法[8]。考虑到网络安全信息数据的复杂性,以及为了提高实体抽取的分类性能,研究在网络安全信息的实体抽取模块中引入了基于深度学习的知识图谱补全技术。
2 基于知识图谱和数据增强的网络安全信息采集与分析的方法
网络安全数据样本的标记需要利用专家的专业知识进行,这不仅复杂且耗时巨大[9]。数据增强方法是一种扩充训练数据的方法,通过对训练集进行变换来增加训练集的数量,能够有效提高模型的泛化能力[10]。因此,为了更加简便地对网络安全数据进行标记,研究还引入了数据增强方法来补充训练数据,并通过对训练集知识的实体替换来扩充训练集的数量。实体字典的数学表达式如式(1) 所示。
式(1) 中,Z 代表实体字典,Counter 代表算法,X 与L 分别代表训练集与实体类型。增强句子数学表达式如式(2) 所示。
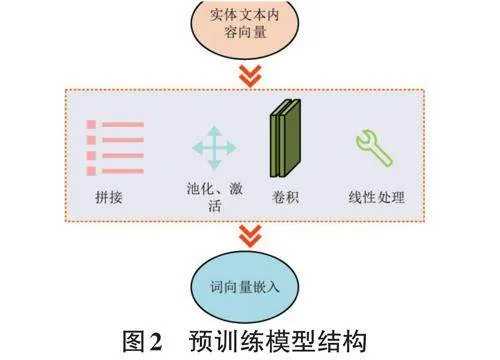
式(2) 中,J 代表增强句子,Augmentation 代表算法,其余代数含义与式(1) 一致。为了获得更具表达能力的实体内容特征,研究还引入了预训练模型对数据增强方法进行改进,提出了一种基于预训练的编码器数据增强方法。预训练模型的结构如图2所示。
由图2可知,在研究所提出的预训练模型中,以卷积神经网络(Convolutional Neural Networks, CNN) 作为核心网络。首先,通过word2vec获得实体内容的词向量。其次,将获得的词向量作为原始数据输入至模型中,经过拼接、池化、激活、卷积与线性处理操作,最终输出可用的嵌入表示。线性处理的表达式如式(3) 所示。
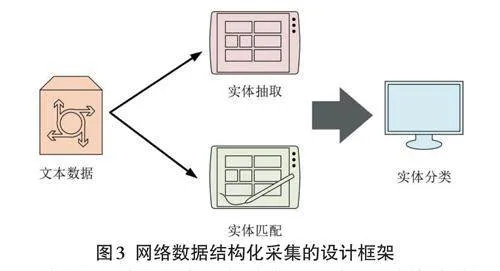
式(3) 中,wemb 代表词向量嵌入,a 与b 代表权重。最终,研究将知识图谱补全技术与改进后的数据增强方法相结合,提出了一种新型的基于知识图谱增强的网络数据结构化采集与知识融合方法。研究所提方法的结构设计图如图3所示。
由图3可知,研究所提出的基于知识图谱增强的网络数据结构化采集与知识融合方法主要由三个部分组成:网络安全信息实体抽取模块、网络安全信息实体分类模块和网络安全信息实体匹配模块。首先,将网络安全数据输入至实体抽取模块,以进行目标数据的采集。其次,将采集的数据输入至实体匹配模块,利用正则表达式对采集到的数据进行匹配。最后,对匹配的数据进行实体分类,从而成功实现网络数据的采集与分析。
3 网络安全信息采集与分析方法的性能测试
3.1 实体抽取性能测试
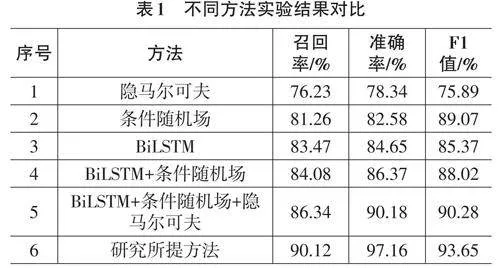
实体抽取是构建网络安全信息采集与分析方法的关键环节。因此,研究选取了CyberMonitor开源仓库和Trendmicro安全公司的网络安全数据作为测试环境。通过数据预处理与文章分句处理后,利用In⁃ ception工具进行网络数据的实体标注和句子筛选。按照6∶2∶2的比例将句子数量划分为训练集、验证集和测试集。操作系统版本选择Ubuntu 7.5.0,GPU选择GeForce GTX 1080 Ti,使用Pytorch框架进行设计实现。不同方法的实体抽取性能对比结果如表1所示。
由表1可知,研究所提出的新型基于知识图谱增强的网络数据结构化采集与知识融合方法的召回率、准确率与F1值分别为90.12%、97.16%和93.65%,均高于隐马尔可夫、条件随机场、BiLSTM、BiLSTM+条件随机场以及BiLSTM+条件随机场+隐马尔可夫方法。与隐马尔可夫方法相比,研究所提方法的召回率、准确率与F1值分别提升了13.89%、18.82%和17.76%。上述数据表明,研究方法在网络安全数据实体抽取方面表现出色。
3.2 实体关系分类性能测试
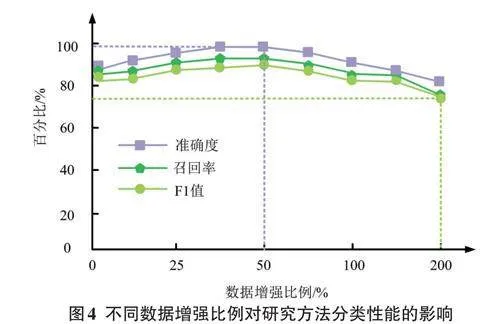
实体关系是实体之间联系的桥梁,对研究提出的网络数据结构化采集与知识融合方法进行实体关系分类性能的测试,能够验证网络安全情报知识图谱关系分类的有效性。因此,研究针对不同的数据增强比例,对网络数据结构化采集与知识融合方法进行了分类性能测试。测试结果如图4所示。
由图4可知,在数据增强比例从0%提升至50% 的过程中,研究所提方法的实体关系分类的F1值、准确率与召回率均在缓慢提升。当数据增强比例达到50%时,本研kyxPjBdluD7tj+A1iBy6RTeuFLT+AfbWUrh7LcrzYuk=究方法的分类效果达到最优,其F1值、准确率与召回率分别为88.37%、99.27% 和90.58%。与没有数据增强的方法相比,本研究方法的F1值、准确率与召回率分别提升了6.07%、9.26%和1.46%。上述数据表明,研究提出的基于知识图谱增强的网络数据结构化采集与知识融合方法在分类方面具有高效性。
3.3 多指标性能测试
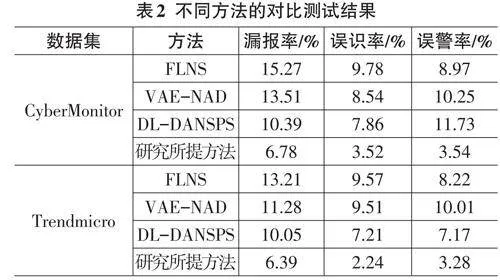
研究最后以漏报率、误识率和误警率为指标,对常用的网络安全信息采集与分析方法进行多指标测试。这些方法包括结合联邦学习驱动的网络安全方法(Federated Learning for Network Security, FLNS) 、变分自编码器网络异常检测方法(Variational Autoen⁃ coder for Network Anomaly Detection, VAE-NAD) 和结合深度学习的动态适应网络安全检测方法(Deep LPeolaircnyi nSgy-stbeamse, dD LD-yDnAaNmSicP SA) 。da测pti试ve 结N果et如wo表rk 2S所ec示ur。
由表2可知,在三类指标的检测中,FLNS感知检测方法的性能表现欠佳,其次为VAE-NAD方法、DLDANSPSDLDANSPS以及研究提出的基于知识图谱增强的网络数据结构化采集与知识融合方法。其中,FLNS感知检测方法的漏报率最低为13.21%,误识率最低为9.57%,误警率最低为8.22%。而本研究提出的新型基于知识图谱增强的网络数据结构化采集与知识融合方法,漏报率最低为6.39%,误识率最低为2.24%,误警率最低为3.28%。由此可知,研究所提的基于知识图谱和数据增强的网络安全信息采集与分析方法具有相对较优的实用性能,更适合于目前阶段的网络安全感知工作。
4 结论
针对现阶段网络安全信息分析存在的困难与挑战,本研究引入了知识图谱技术,并将其与数据增强方法相结合,提出了一种新型的基于知识图谱和数据增强的网络安全信息采集与分析方法。不同方法的实体抽取性能测试结果表明,研究所提方法的召回率、准确率与F1值分别为90.12%、97.16%和93.65%,均高于隐马尔可夫、条件随机场、BiLSTM、BiLSTM+条件随机场以及BiLSTM+条件随机场+隐马尔可夫方法。不同数据增强比例实体关系分类性能的测试结果表明,当数据增强比例达到50%时,本研究方法的分类效果达到最优,其F1值、准确率与召回率分别为88.37%、99.27%和90.58%。与没有数据增强的方法相比,研究方法的F1值、准确率与召回率分别提升了6.07%、9.26%和1.46%。上述实验数据充分证明了本研究方法在网络安全领域中良好的分类能力,为后续网络安全数据的采集与分析提供了一些新的研究方向。然而,研究探讨的数据主要来源于CyberMonitor 开源仓库和Trendmicro安全公司,并不全面,后续可以采集更为全面的数据进行探究,以确保研究的精准性与大范围适用性。
