
基于大数据技术的生态文明信息服务平台构建
2024-12-21 00:00:00肖贵
中国新技术新产品 2024年16期

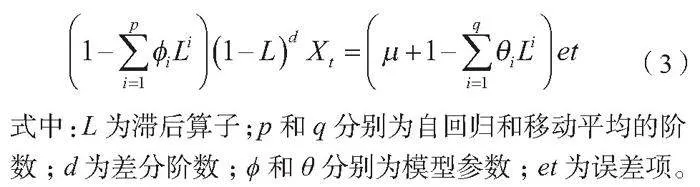


摘 要:随着生态文明建设不断推进,如何有效整合和利用环境数据成为一个重点问题。本文设计并构建了一个基于大数据技术的生态文明信息服务平台,以实现对生态数据的高效采集、存储、处理、分析和可视化,进而为智能决策提供支持。该平台采用Hadoop进行数据存储,利用Spark进行数据处理与分析,并通过D3.js实现数据可视化。试验结果表明,该平台能有效处理大规模生态数据,为用户提供直观的数据展示和决策支持。
关键词:大数据技术;信息服务;生态文明;平台构建
中图分类号:G 251" " " 文献标志码:A
在全球环境治理和可持续发展议题日益重要的今天,生态文明建设不仅是国家战略层面的要求,也是全人类共同面对的紧迫任务。随着科技进步和社会发展,生态环境问题愈加复杂多变,传统的监测手段存在技术限制、数据分散以及处理能力不足等问题,已经难以满足现代高效、精准的环境管理需求。大数据分析可对来自不同源头的海量生态数据进行集成、分析和挖掘,对环境状况进行实时监控和预测,提高决策的科学性和准确性。因此,本文构建了一个基于大数据技术的生态文明信息服务平台,以期打造一个全面、高效且动态的生态环境管理和服务体系。该平台将整合多种信息技术,包括数据采集、云计算、智能分析和可视化展示等。利用该平台,政府和企业能够更好地掌握环境质量变化趋势,公众也能更直观地了解生态环境信息,从而促进全社会的环保意识和参与度。
1 信息服务平台架构设计
本文提出的生态文明建设信息服务平台采用分层架构的设计理念,旨在将复杂的系统功能模块化,以便于管理和维护。整个平台由4个主要层次构成,包括数据采集层、数据存储层、数据分析层和应用层,如图1所示。每一层均采用大数据云计算技术,具有弹性扩展和高可用性,可保证平台稳定运行。
数据采集层是整个平台的数据来源基础,该层部署了多种高效的数据采集技术和设备,包括物联网传感器、遥感卫星图像和地面监测站等。这些设备能够实时收集空气质量、水资源状况、土壤成分以及生物多样性等多维度的生态信息。为了应对不同数据源的格式和协议差异,本文引入了Apache Kafka数据集成工具来处理高吞吐量的数据流,保证数据能及时传输。
数据存储层将Hadoop Distributed File System(HDFS)作为主要存储解决方案,以支持大规模数据的可靠存储和冗余备份。为了提高数据查询的效率,使用NoSQL数据库HBase,以快速随机读写大规模数据集,并提供灵活的数据模型。
数据处理层是平台的核心部分,涉及数据的实际分析和处理工作。该层采用Apache Spark这一高性能计算框架,利用其内存计算的特性来加快数据处理速度,并利用Spark SQL进行复杂的数据分析,MLlib库支持机器学习算法,用以挖掘更深层次的数据价值。
应用服务层是数据处理层与展示层间的桥梁,可封装核心的业务逻辑并提供API接口。该层使用微服务架构设计模式,允许多个独立的服务并行工作,提高了系统的可伸缩性和稳定性。采用RESTful API的方式,不同的客户端(包括移动应用、Web应用等)可以方便地获取后端处理的数据和业务逻辑结果。
2 平台功能模块设计
2.1 数据采集与存储
Apache Kafka是主要数据采集工具,能提供高吞吐量的数据接收和传输能力,对处理来自传感器网络、遥感卫星和其他监测设备的实时数据至关重要。Kafka的设计允许从多个源收集数据流,并将其传输到一个或多个数据处理器或数据存储系统。首先,搭建一个Kafka集群,以支持数据的高并发写入和高可用性。其次,部署Kafka Connectors的生产者客户端,用于连接各种数据源,并将数据推送到Kafka的特定主题(Topic)中。设定每10min采集一次数据,并推送到存储数据库中。
数据存储采用Hadoop分布式文件系统(HDFS)结合NoSQL数据库Apache HBase。HDFS以高度可靠、可扩展和经济高效的方式存储大规模的数据集,将数据被分布在多个物理节点上,从而提供冗余和快速的数据访问。HBase运行在HDFS之上,提供了一个适用于非结构化或者半结构化数据的存储解决方案,可支持稀疏的行存储、多版本并发控制以及列级别的动态列族管理,例如为空气质量监测数据创建储存库,该表包括以下字段:日期(data)、时间戳(timestamp)、地理位置(location)、PM2.5浓度(PM2.5)、一氧化碳浓度(CO)、二氧化硫浓度(SO2)、臭氧浓度(O3)、温度(temperature)以及湿度(humidity)。
在空气质量监测数据存储解决方案中,使用HDFS和HBase组合能够有效处理、分析大量的环境监测数据。但是环境监测数据通常会随时间推移而不断增长,因此可扩展性是设计此类系统的关键考虑因素。HDFS具有强大的数据冗余机制,可将数据块分布在不同的DataNode上,并保证每个数据块的多个副本在某些节点失效的情况下仍具有高可用性(因为单点故障可能导致大量数据不可用,从而影响整体的分析结果和系统的可靠性,所以这对大规模数据集非常重要)。Apache HBase是一个列式数据库管理系统,将HDFS作为其底层的数据存储层。HBase的设计允许快速随机读写大数据集中的个别记录,非常适合处理结构不固定或者需要快速访问的数据,便于在空气质量监测的场景中轻松添加新的监测站点或传感器,甚至未来引入新的监测指标时,也不需要对现有系统进行重大的架构调整。HBase支持高效的列级别压缩和由用户定义的数据块大小,可以进一步优化存储空间和提高查询效率。例如,对于空气质量监测数据,某些字段,例如地理位置可能只需要定期更新,而其他测量值,例如PM2.5浓度可能需要频繁记录。HBase允许这些不同类型的数据拥有各自合适的存储和索引策略。
本文设计的数据储存表将时间和地理位置设为复合主键,能够进行基于时间和地点的快速查询。HBase的列族设计可根据实际需求灵活地增、减监测项,以应对不断变化的监测需求。数据库储存见表1。
为保障数据的安全性和完整性,实施定期备份和灾难恢复计划,使用Hadoop生态系统中的其他工具,例如Apache Hadoop Backup Tool(HBackup)进行数据备份操作,保证在任何硬件故障或意外情况下均能迅速恢复服务。
2.2 数据处理与分析
数据处理与分析模块选用Apache Spark框架,其能提供快速的内存计算能力,非常适合处理大规模数据集。Spark的设计允许用户在分布式环境中进行复杂的数据操作,其容错性设计保证了计算过程的稳定性。为了对生态数据进行有效查询和分析,平台采用Spark SQL组件。Spark SQL可执行类似SQL的查询语句,并利用Spark Catalyst优化器来优化查询计划。Spark SQL还支持多种数据源连接,包括HDFS、Apache Cassandra和Apache HBase等,使平台能够方便地从不同的数据源中读取数据,并进行跨数据源的联合查询和分析。在空气质量监测数据的处理和分析过程中,可以应用Spark SQL执行各种复杂的数据处理任务。例如,编写SQL查询语句来筛选特定时间段内PM2.5浓度超过阈值的数据,或者计算不同地理位置的平均PM2.5浓度,利用Spark SQL强大的数据处理能力来快速生成高质量的分析结果。此外,Spark还提供了丰富的API和库,可以使用Scala、Java或Python等编程语言进行数据处理和分析。并支持机器学习和图计算等高级功能,可以进一步丰富对空气质量监测数据的分析和挖掘。使用Spark MLlib库进行机器学习建模,可预测未来的空气质量趋势,或者使用GraphX库进行图计算,以发现空气质量间的关联关系。
设计过程如下所示。首先,搭建一个Spark集群,包括安装Spark及其Hadoop YARN依赖组件,用于资源管理和任务调度。其次,使用Spark SQL的DataFrame API读取HBase中存储的环境监测数据,并编写SQL语句执行复杂的数据分析操作。对于涉及复杂数学模型和统计方法的分析任务,使用MLlib中的线性回归模型并根据过往数据训练一个预测模型。处理环境监测数据时,使用Spark SQL的DataFrame API或SQL语句进行数据探索性分析,包括计算平均值、最大值和最小值等统计量并进行数据过滤、聚合和排序等操作。例如,要计算区域的平均PM2.5浓度,计算过程如公式(1)所示。
(1)
式中:APM2.5为第i个数据点的PM2.5浓度;n为数据点的总数。
在Spark SQL中,该计算可以通过一个聚合操作实现。再次,利用Spark MLlib库执行机器学习任务,根据空气质量指数选择线性回归模型,从原始数据集中提取有助于模型学习的特征。使用Spark MLlib调整参数以达到最优性能,将模型应用到新的数据集中进行预测,并对模型的准确度进行评估,线性回归的算法如公式(2)所示。
y=θ0+θ1x1+θ2x2+...θnxn (2)
式中:y为目标变量,即空气质量指数;xn为特征变量;θn为模型参数。
所有设计和实施的数据处理与分析流程均能高效地整合到生态文明信息服务平台中,并与数据采集、存储模块无缝对接。整个平台能够以自动化的方式运行,从而为用户提供实时的分析结果,并为决策者提供数据驱动的见解。
2.3 数据可视化与智能决策
构建生态文明信息服务平台的数据可视化与智能决策模块时,采用D3.js和Vue.js技术来开发前端界面,以保证数据的直观展现和用户交互的流畅性。D3.js是强大的数据可视化库,能够将复杂的数据集以各种图表形象地展现出来,Vue.js则以其轻量级和组件化的特点,为平台提供一个灵活、高效的用户界面构建方式。结合D3.js和Vue.js,该信息服务平台能够提供动态的数据展示与实时数据更新功能。监测空气质量的实时数据时,D3.js可以渲染出动态的时间序列图和地图,展现PM2.5、CO、SO2等污染物浓度随时间的变化趋势及其在地理空间上的分布情况。这种直观的可视化方式可使决策者和公众迅速理解、评估当前的空气质量状况。Vue.js的单文件组件(Single File Components)和虚拟DOM(Virtual DOM)技术可利用高效的方式来管理复杂的前端结构,允许开发者将用户界面划分为可重用的组件,每个组件可管理自己的状态和表现。这样的设计可使代码更模块化,易于维护和扩展。Vue.js的响应式数据绑定并组合视图模型,保证了数据处理的高效性和用户界面的流畅反应。
使用Vue.js框架搭建前端结构,涉及单页面应用(SPA)的布局设计、组件化开发以及状态管理。Vuex是状态管理工具,能够在不同组件间共享和管理数据。根据所需展示的数据类型和关系,选择最合适的D3.js图表,其中折线图适合展示时间序列数据,饼图适合展示部分与整体的关系。然后利用D3.js的数据绑定特性,将后端传来的数据动态渲染到图表中。在该过程中需要对数据进行清洗、转换和规整,以便数据能够适应所选图表的输入格式。最后对需要进行深入分析的数据引入人工智能算法,辅助生成智能决策建议。例如,采用ARIMA模型进行时间序列预测,如公式(3)所示。
(3)
式中:L为滞后算子;p和q分别为自回归和移动平均的阶数;d为差分阶数;ϕ和θ分别为模型参数;et为误差项。
将预测结果转化为可视化元素并在Vue.js界面中进行展示,可在地图上用不同颜色标注出未来空气质量可能达到危险水平的地区。并提供智能决策支持,根据数据分析结果自动提出预警和建议。为提高决策支持系统的智能化水平,平台通过集成机器学习模型来预测未来环境变化或识别潜在的环境风险。这些智能分析结果通过D3.js和Vue.js呈现给用户,例如以交互式图表的形式展示预测结果,或者根据模型输出的结果动态调整视图中的警报级别。
3 测试试验
3.1 试验准备
为了评估本文设计的农村生态文明建设信息服务平台在处理大规模数据和实现机器学习算法过程中的性能表现,本文进行了一系列详细的试验准备。该试验旨在测试平台面对模拟使用情境中大规模生态数据时的性能,包括数据处理速度、算法训练时间和系统响应时间。试验过程使用了2台8核64GB内存的云服务器,以保证具备足够的计算资源。为了模拟真实情境,生成了包括数百万条生态数据记录的大规模数据集,其中包括时序性、地理位置信息等复杂性特征。试验过程主要测试内容包括数据处理速度、算法训练时间以及系统响应时间,模拟用户请求,测试平台对数据查询、图表生成和预警响应速度。
3.2 试验结果
平台的测试结果见表2。根据表2数据可知,在大规模数据情境下,数据清洗时间为300ms,特征提取时间为200ms,数据转换时间为230ms,表明该平台随着数据规模增加,数据处理时间呈线性增长,平台在大规模数据处理方面表现较稳定。数据查询的平均响应时间最低为60ms,查询大规模数据时最高90ms,试验结果显示平均响应时间在用户可接受的时间范围内。在实际应用中,这种相对低延迟的响应对用户体验至关重要。为了进一步提升系统的响应性能,可以考虑引入负载均衡、缓存技术等优化手段,保证平台在高并发环境中仍能保持稳定的响应速度。
4 结语
本文设计的基于大数据技术的生态文明信息服务平台采用多种前沿技术,实现了高效的生态数据处理和智能决策支持。整合了Apache Kafka、HBase以及D3.js和Vue.js等技术,具备高效的数据采集、存储、处理与可视化能力。结合ARIMA等先进的时间序列预测模型,该平台还能提供准确的环境质量预测和智能决策建议,辅助管理者进行高效决策。
参考文献
[1]罗远平,刘云花.基于大数据技术的高校融媒体信息服务平台构建[J].信息与电脑(理论版),2023,35(13):22-24.
[2]平淑容.大数据背景下个性化就业信息服务平台模型构建设想[J].中国管理信息化,2023,26(5):181-184.
[3]訾艳情,戴诗琴,马芳洁.农村养殖业销售信息服务平台建设研究——以营田村生猪养殖为例[J].农村实用技术,2022(9):105-107.
[4]刘伟.大数据背景下林业信息服务平台建设研究——评《面向林改的林业信息服务体系及平台构建》[J].林业经济,2022,44(6):104.
[5]冯茂林,董坚峰.大数据环境下的农村信息服务平台建设研究[J].农业图书情报学报,2021,33(7):63-71.
基金项目:2022年衡阳市社科基金项目“乡村振兴战略下新时代衡阳农村生态文明建设研究”(项目编号:2022D022);2022年湖南省教育科学研究工作者协会项目“乡村振兴战略下高校学生服务乡村建设的激励机制及对策研究”(项目编号:XJKX22B308)。
猜你喜欢
东方教育(2016年12期)2017-01-12 20:11:06
商场现代化(2016年29期)2016-12-23 17:57:54
商情(2016年42期)2016-12-23 16:54:52
中国新技术新产品(2016年22期)2016-11-29 04:57:27
新世纪图书馆(2016年9期)2016-11-15 02:09:52
价值工程(2016年29期)2016-11-14 02:28:03
电子技术与软件工程(2016年18期)2016-11-14 01:25:39
科技视界(2016年18期)2016-11-03 22:02:50
电脑知识与技术(2016年21期)2016-10-18 23:30:16
电脑知识与技术(2016年21期)2016-10-18 23:08:26
