
基于深度学习算法的企业信息安全风险评估研究
2024-12-21 00:00:00李广鼎
中国新技术新产品 2024年16期



摘 要:本文通过运用深度学习算法,针对企业信息安全领域进行研究。主要目的是构建一个能够有效评估企业信息安全风险的预测模型,以解决当前复杂多变的信息安全挑战。通过选择网络攻击频率、安全资源投入和安全培训投入等指标,建立深度强化学习预测模型。研究结果表明,预测结果与实际值之间的平均绝对误差普遍低于1,说明模型在大多数情况下能够准确预测企业信息安全风险评估结果,迭代次数达到400次后,模型已经达到稳定水平并保持较高的预测精度,在系统测试中表现出良好的泛化能力。
关键词:网络安全;风险评估;深度学习;预测模型
中图分类号:TP 393" " 文献标志码:A
随着信息化技术飞速发展,企业面临越来越复杂和多样化的信息安全威胁。先行研究对信息安全风险的评估和控制也进行了较多研究。唐蔚南[1]探讨了高校信息化安全管理问题与对策。王鹏等[2]提出了一种基于贝叶斯网络的信息系统风险评估模型。耿文莉等[3]提出了一种基于灰色神经网络的云平台大数据安全风险评估模型。李佳玮等[4]将一种改进基因表达式编程算法用于电网信息安全风险评估。沈克等[5]针对工控系统在能源行业面临的严重信息安全问题进行分析,并提出了企业建设安全防护体系目标、防护策略和流程,形成企业工业控制系统安全防御体系。张帆等[6]针对城市轨道交通列车运行控制系统进行信息安全水平评估,并提出了相应的风险管理建议。廖元媛等[7]提出了一种基于贝叶斯推理的信号数据网动态感知方法。郭昊等[8]提出国家电网边缘计算应用安全风险评估模型,并通过漏洞扫描工具和模糊层次分析法对Web应用进行综合评价,实现国家电网边缘计算应用安全风险评估验证。
1 系统信息安全评估与攻击模型
在系统信息安全评估中,外部环境的网络攻击是一个关键考虑因素,也即企业信息安全评估事实上是其应对攻击的能力评估。因为攻击往往会直接影响系统的正常运行,所以相应评估模型依赖于供给模型的建立。
无论是从执行器还是传感器的角度出发,攻击的最终目标通常都是这两类设备。这些设备不仅在系统中扮演重要角色,而且也是信息和物理系统交互的关键节点。因此,在揭示信息物理交互和网络攻击本质特征方面,建立攻击模型并描述受到攻击后的系统状态变得至关重要。
首先,为了简化模型,假设状态转移函数和量测函数都是在线性的情况下,企业的网络信息安全环境状态可以描述为一系列状态向量,如公式(1)所示。
xt+1=Axt+ft+ωt (1)
式中:t为时间;xt+1为更新后状态;xt为更新前状态;A为状态的转移矩阵;ft为控制向量;ωt为状态向量的均值高斯噪声。
由此,网络信息环境中的一切可测度、可控制状态均可表述为一系列状态,其对应物理环境中的传感器和执行器,网络攻击与信息安全即考虑对此类状态及其控制活动的管理能力。
其中,执行器状态对应的控制向量ft如公式(2)所示。
ft=But+δt (2)
式中:B为非零对角矩阵;ut为系统输入;δt为其他附加输入。
传感器状态对应的测量向量zt如公式(3)所示。
zt=Hxt+vt (3)
式中:zt为测量向量;H为系统模型矩阵;vt为测量向量的均值高斯噪声。
其次,考虑这一系统的攻击活动,常见的攻击网络方式包括数据完整性攻击和可用性攻击。以完整性攻击为例,攻击者通常会试图通过注入错误数据来修改量测向量,如公式(4)所示。
zai=zt+ζz (4)
式中:zai为注入错误数据攻击的预期成果(Injection error data attack);ζz为对传感器状态变量zt的注入数据。
而数据可用性攻击,例如Dos攻击则的攻击资源则消耗较少,如公式(5)所示。
zaa=ztdiag(ξz) (5)
式中:zaa为注入错误数据攻击的预期成果(Injection error data attack);ξz为对传感器状态变量zt的注入数据。
以上基于传感器的测量向量考虑攻击模型,在公式(4)、公式(5)的基础上利用公式(2)获得相应控制权,此处不继续列出,仅设攻击活动影响角标为x。
最后,将之整合为攻击消耗的总体概念。
其中,最大消耗如公式(6)所示。
γ=||ζx||0+||ζz||0+||ξx||0+||ξz||0 (6)
式中:γ为攻击的最大消耗;|| ||0为攻击向量非零元数量。
最小消耗如公式(7)所示。
χ=|ζx|+|ζz|+|ξx|+|ξz| (7)
式中:| |为攻击向量中的元素数量。
因此,在特定系统环境条件下,χ为常数,则攻击行为的攻击效率也即最小消耗与最大消耗的比值,事实上依赖于最大消耗。本文也基于此,构建针对特定系统状态下的企业信息安全评估指标,构成安全性评价,即网络攻击获益更低的结果。但在世纪网络信息安全保护中,企业的信息安全水平评估重要性较低,其实时遍历网络节点进行风险评估的成本过高,本文基于此使用深度学习算法,利用有限外部观测变量评估内部系统安全性,以形成深度学习预测模型。
2 深度学习预测模型
2.1 指标选取
本文选择网络攻击频率、安全资源投入和安全培训投入作为预测指标。这3个指标涵盖了企业信息安全管理的不同方面,从网络威胁频率到对抗风险的资源投入和员工培训,通过监测这些指标可以综合评估企业的信息安全状况,帮助企业了解自身所面临的威胁程度以及应对风险的投入程度。
2.2 深度学习
为了构建预测模型,选择深度强化学习方法。首先,定义了一个包含多层神经网络层的结构:输入层、2个全连接层和1个回归层。
其中,输入层(sequenceInputLayer)接收3个特征值作为输入,设为X。全连接层(fullyConnectedLayer)包含64个神经元,并通过权重连接前一层和后一层,分别具有权重矩阵Win和Wout。激活函数(reluLayer)引入非线性性质σ作为激活函数,以增加模型表达能力。回归输出层(regressionLayer)用于回归问题中输出连续值,其预测值为Y。
由此,形成深度学习算法模型,如公式(8)所示。
H=σ(WinX+bin)
Y=σ(WoutX+bout) (8)
式中:bin和bout分别为对应权重矩阵Win和Wout的偏置项。
2.3 性能优化
模型使用Adam优化器进行训练,并设置最大迭代次数为1000次,每次迭代使用批量大小为32。所使用的损失函数如公式(9)所示。
L=(Y-Yture)2 (9)
式中:L为损失函数;Yture为真实标签。
通过不断调整神经网络权重来最小化损失函数,使模型能够更好地拟合训练数据并泛化到未见过的测试数据上。
3 风险评估结果分析
3.1 数据获取
本文为测试算法有效性,使用了企业内部系统维护机会,基于设备调整和流程调整,随机生成了500个不同状态条件下的系统受攻击条件,并利用算法进行安全性评估。对评估结果进行标准化处理,使全部状态的系统安全评分限制在0~10。这些数据将作为目标标签纳入模型,记录对应的网络攻击频率、安全资源投入和安全培训投入等指标,构成数据集。将生成的数据划分为训练集和测试集是机器学习任务中至关重要的一步。选择70%的样本作为训练集,剩余30%作为测试集。
3.2 预测结果对比
整理150份(30%测试集)样本中的预测结果和实际结果对比,其结果如图1所示。
由图1可知,预测安全评分的波幅较小,可能意味模型对整体数据集的拟合效果较好。在实际应用中,这意味即使在面临新样本时,模型也有望表现出相对稳定的预测结果。这种稳定性非常重要,因为信息安全风险并不是静态的,并且企业需要一个能够持续适应变化环境的风险评估工具。考虑预测评分结果极值范围相对较窄,可以理解为模型相对偏向于给出中等水平的安全评分。这种情况可能是因为数据集中大部分样本都处于中等水平,极端情况相对较少,是网络安全动态感知中的常见现象,也表明了该预测模型在大多数情况下都能够给出符合实际情况的评估结果。
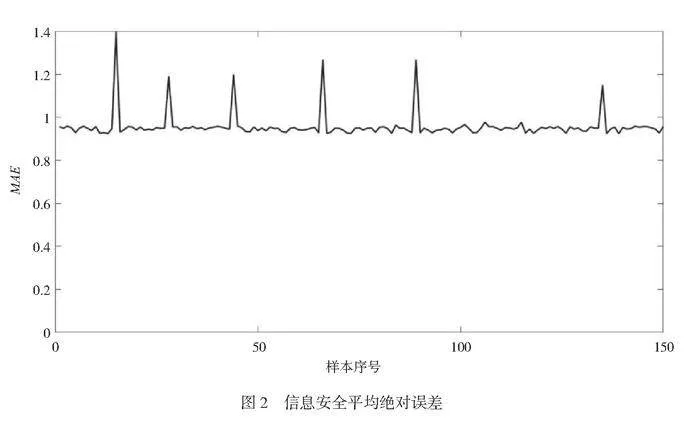
计算其误差水平如图2所示。
由图2可知,在全部测试样本中,预测结果的平均绝对误差(MAE)普遍低于1,表明整体上模型的预测结果与实际值之间的偏差相对较小。这意味大多数样本的预测结果都比较接近真实值,反映了模型在整体数据集上具有良好的拟合效果。
其中,仅有6个显著偏离且MAE较高的样本时,则需要进一步关注这些样本所代表的情况。这些显著偏离的样本可能是场景环境条件组合中的一些特殊情况或者异常情况,可能代表潜在的高风险事件。在信息安全领域,极端情况往往具有更高的风险和影响程度。因此,在未来工作中可以进一步探讨如何在保持整体预测准确性的同时更好地考虑极端情况,并强化在极端条件下的人工风险评估、预警机制介入。
3.3 预测性能分析
整理随迭代次数增长而波动的小批量均方根误差(RMSE)和损失函数数据结果如图3所示。
由图3可知,安全风险评估预测结果与真实值偏差的RMSE在测试初期大幅下降,在迭代50次后即下降至4,意味模型在这个阶段已经取得了较大幅度的改善,并且开始逼近更准确的预测效果。迭代200次后下降至约1.5,表明模型在初始阶段就开始逐渐学习并调整,以更好地拟合数据。这种快速下降可能反映了模型对数据特征的有效学习和适应能力。在迭代400次后已接近于1,迭代450次后保持稳定。这种趋势显示模型在训练过程中逐渐收敛至更准确的预测结果,同时也表明了模型具有良好的泛化能力。同时,在系统测试中,所使用神经网络模型的损失函数也保持相似的下降趋势,在约400代时已经稳定为接近于0。深度学习预测模型在训练过程中具有良好的收敛性和泛化能力,并且取得了较高水平的预测精度。
4 结语
本文聚焦系统信息安全评估与攻击模型的研究。在系统信息安全评估中,外部环境的网络攻击是一个关键考虑因素,企业信息安全评估实质上是其应对攻击能力的评估。基于此,本文选择网络攻击频率、安全资源投入和安全培训投入作为预测指标,并利用深度强化学习方法构建预测模型。由风险评估结果可知,模型对大部分样本都有较好的拟合效果,并且预测结果与实际值之间偏差相对较小。这表明该深度学习预测模型具有良好的泛化能力和预测精度。预测性能分析中发现,在训练过程中模型快速学习并调整至更准确的预测结果,在较小迭代次数后达到稳定水平。这表明该模型具有良好的收敛性和泛化能力,并取得了较高水平的预测精度。
参考文献
[1]唐蔚南.高校信息化安全管理问题与对策——评《网络安全与信息化发展路径研究》[J].中国安全科学学报,2024,34(3):247.
[2]王鹏,徐建良.基于贝叶斯网络的信息系统风险评估研究[J].中国海洋大学学报(自然科学版),2022,52(5):131-138.
[3]耿文莉,高梦瑜.基于灰色神经网络的云平台大数据安全风险评估[J].科学技术与工程,2021,21(28):11932-11937.
[4]李佳玮,吴克河,张波.一种基于小生境遗传算法的电网信息安全风险评估模型[J].电力建设,2021,42(3):89-96.
[5]沈克,周志强,付杨,等.面向石油装备制造企业的工业控制系统信息安全防护方法[J].信息网络安全,2020,(增刊1):107-110.
[6]张帆,步兵,赵骏逸.列车运行控制系统信息安全风险评估方法[J].中国安全科学学报,2020,30(增刊1):172-178.
[7]廖元媛,王剑,田开元,等.基于贝叶斯推理的铁路信号安全数据网信息安全动态风险评估[J].铁道学报,2020,42(11):84-93.
[8]郭昊,何小芸,孙学洁,等.国家电网边缘计算应用安全风险评估研究[J].计算机工程与科学,2020,42(9):1563-1571.
猜你喜欢
商情(2016年43期)2016-12-23 14:23:13
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
经济师(2016年10期)2016-12-03 22:27:54
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
时代金融(2016年23期)2016-10-31 13:25:28
软件工程(2016年8期)2016-10-25 15:47:34
中国科技博览(2016年19期)2016-10-19 12:32:12
大众理财顾问(2016年8期)2016-09-28 13:55:43
商业经济研究(2016年14期)2016-09-14 08:25:44
