
智能驾驶中的关键点检测技术
2024-12-20 00:00:00吕纤纤
专用汽车 2024年12期




摘要:智能交通系统和智能驾驶技术的快速发展对车辆姿态信息及三维属性的获取提出了新的要求。探讨了两种主流的多目标关键点检测方法,即基于自顶向下和自底向上方法,并分析了两者在精度和速度方面的表现。然后搭建了一种基于自顶向下的、使用Heatmap+Offsets方法的卷积神经网络车辆关键点检测模型,该模型具有很高的平均精度,且误差较小,在处理角度信息时也具有较高的精确度。
关键词:智能驾驶;关键点检测;姿态估计;车轮关键点;深度学习
中图分类号:U467.4 收稿日期:2024-10-18
DOI:10.19999/j.cnki.1004-0226.2024.12.026
1 前言
智慧交通和智能驾驶有良好的应用前景,成为近年来的研究热点,其中,机器视觉在智能驾驶研发中发挥着重要作用,主要包括场景识别、动静态目标检测、轨迹预测等。机器视觉顾名思义是通过机器来模拟生物视觉,代替人眼实现对目标的分类、识别、跟踪等。但随着智驾技术的发展,机器视觉感知的需求也逐步扩大,在智能感知系统中,准确获取动态目标的三维属性及姿态信息对于提高交通效率和安全性至关重要。
通常,目标检测算法只能输出当前图像中车辆目标的外接2D矩形框、置信度和类别信息,但是无法获取到其朝向和姿态信息,如图1所示。但当智驾感知有更高的要求时,就希望不仅要识别出目标,还要获悉其姿态和三维信息,以便下游做出进一步的判断。
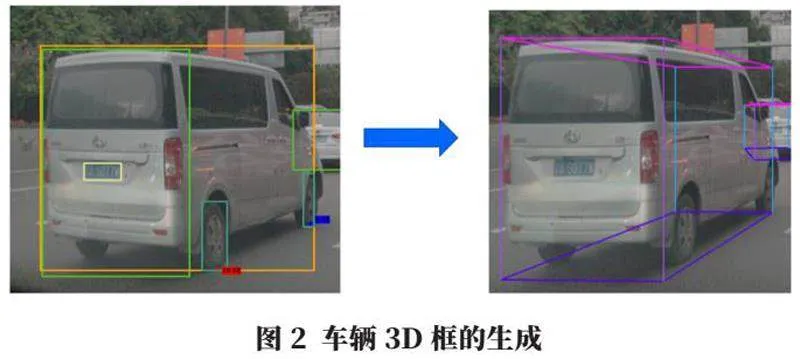
目前的3D检测技术依赖高精度的激光雷达获取真值信息,但由于其成本高昂,限制了其应用普及。另一个思路是通过单目摄像头获取图像,通过检测图像中每辆车近侧前后车轮接地点(车轮与地面相切的切点),再结合全车框、车尾框,生成车辆3D框,从而比较准确地获得车辆当前的朝向和姿态信息,如图2所示。因此关键点检测技术是一个生成3D框和获取目标姿态的折中方法。另外智驾系统中也经常检测骑车人关键点,用于提供骑车人的姿态以及测距测速信息,图3分别展示了车轮角点和骑车人角点,其中序号1表示前轮,序号0表示后轮。
2 关键点检测技术
关键点本质上就是在图像中用一个点表示物体上特定的部位,它不仅是一个点信息或代表一个位置,更代表着上下文与周围邻域的组合关系。常见的关键点有车辆关键点、人体关键点和人脸关键点等,车辆关键点一般用于车辆模型建模、智能驾驶领域等[1];人体关键点可以应用于分析人体的行为动作,还可以应用于VR、AR等[2];人脸关键点则应用于涉及人脸识别的相关应用[3]。
关键点检测技术按照问题场景,可分为“单目标关键点检测”和“多目标关键点检测”[4]。在“单目标关键点检测”中,其研究关键在于如何设计关键点检测算法或模型结构,从而实现准确的关键点检测。而在“多目标关键点检测”中,研究重点不再是具体的关键点检测,而是如何对检测的关键点进行实例化分组,该领域由此也分为基于自顶向下和自底向上的两种解决范式,下面分别介绍这两种方法及优缺点。
2.1 基于自顶向下的多目标关键点检测方法
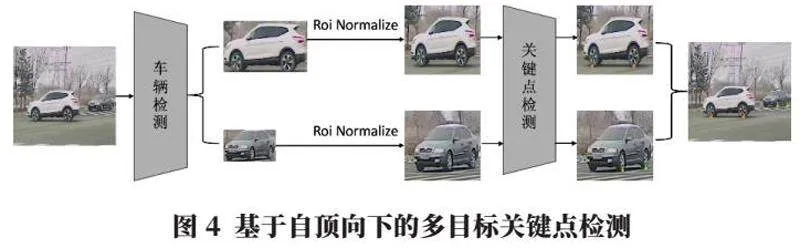
在多目标关键点检测任务中,最自然想到的做法就是先检测出图中所有目标,然后再将目标2D框抠出来,对每一个2D框候选区域内进行关键点检测,这就是自顶向下的方法,即通过先进行全图目标检测,而后进行单目标关键点检测的两阶段网络,将多目标任务转换为单目标任务。
该方法如图4所示,其中包含“车辆检测”和“关键点检测”两个不同的卷积神经网络,前者对车辆目标进行检测提取并将其裁剪成单个车辆目标候选框,之后再通过Roi Normalize方法进行外扩一定区域,包含背景信息,且归一化到相同尺寸下,作为后面“关键点检测”网络的输入,通过两步走实现了多目标关键点检测。
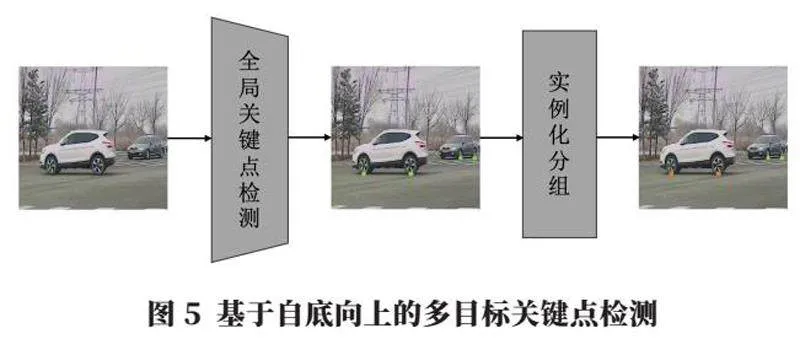
2.2 基于自底向上的多目标关键点检测方法
自底向上的方法与自顶向下相反,其网络设计只有一个网络,直接对整张图进行全局关键点的检测。对于图像中含有多个目标,存在无法区分哪些点属于目标A,哪些点属于目标B的问题,因此还需要在后面接一个实例化分组模块,利用其他辅助信息和后处理将这些关键点按照策略进行实例化分组和匹配。
该方法如图5所示,其中只有“全局关键点检测”一个卷积神经网络,进行不限制实例数量的全局关键点检测,另外会输出额外如分割或实例化编码等辅助信息,最后通过后处理进行实例化分组。
2.3 两种方法的优缺点分析
基于自顶向下和自底向上的两种方法,虽然各有千秋,但总体上可以从精度和速度两方面阐述它们各自的特点。其中,自顶向下的方法思路直观,检测过程易于理解,被大部分人所接受。
由于分两阶段地将多目标场景转换为单目标问题,同时能够利用业界先进的通用目标检测网络,从而能达到更高的精度和更广的应用范围;但相应地,两阶段的流程较为冗余且分阶段训练的成本较大,并且会因为人物数量变多而计算量增大,耗时增加,前序的目标检测效果将会影响后续的关键点检测。
基于“自底向上”的方法过程比较简单,其无论目标多少,都只需要对整张图片进行一次处理,且检测速度不会随着目标的增加而明显降低,但缺点则是会牺牲一些精度。
3 实验内容及结果分析
本文搭建了一种基于普通摄像头的车轮关键点检测模型,通过检测图像内车近侧车轮接地点,进而获取车辆的姿态信息,为智能驾驶提供了一种成本效益更高的解决方案。
3.1 实验内容
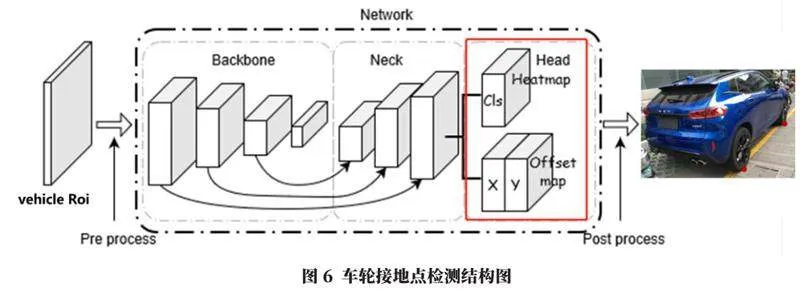
本文基于自顶向下的方法,通过使用Heatmap+Offsets的方式,用卷积神经网络来实现车轮接地点的检测。
Heatmap是指将每一类坐标用一个概率图来表示,对图片中的每个像素位置都给一个概率,表示该点属于对应类别关键点的概率,距离关键点位置越近的像素点的概率越接近1,距离关键点越远的像素点的概率越接近0,具体可以通过函数进行模拟。Heatmap网络在一定程度上给每一个点都提供了监督信息,网络能够较快收敛,同时对每一个像素位置进行预测能够提高关键点的定位精度,典型网络有hourglass[5]、openpose[6]等。
Heatmap + Offsets的方法与上述Heatmap方法不同的是,这里将距离目标关键点一定范围内所有像素点的概率值都赋为1,另外使用offsets(即偏移量)来表示距离目标关键点一定范围内的像素位置与目标关键点之间的关系。
网络整体结构如图6所示,流程如下:
a.模型前处理。先通过目标检测方法预测出车辆2D框的位置,然后外扩一定区域,形成车辆ROI,再对ROI做归一化处理。
b.label生成。heatmap是一个以关键点为中心的圆,半径r为用户指定,heatmap上位于该圆上的值为1,其余值为0;offset是圆上当前点指向关键点的向量。
c.模型输出。将处理后的ROI输入到卷积神经网络中,经过网络提取特征,最后输出heatmap与offset两个head。heatmap的shape为(n,num_kps,h,w),offset的shape为(n,2*num_kps,h,w),其中n为batch_size;num_kps为角点数量(这里取2);h、w为输出feature map的尺寸。
d.模型后处理:先找到heatmap输出的最大值的位置(x,y),并根据这个位置找到offset相对应点处的向量(x_offset,y_offset),预测出最终的输出点位置(x+x_offset,y+y_offset)。
e.根据label值和预测值,计算损失函数,反向传播更新模型参数,直至模型收敛。
本文采用的训练集总共有125 000张图像,训练采用迭代训练策略来优化模型,本文设置总训练步数为float_steps=13 800步,以确保模型能够充分学习训练集的特征;此外,hyqDUABiq767NbxsWN0x7A==为了稳定训练过程并避免过拟合,使用freeze_bn_steps=7 500步冻结了批量归一化(Batch Normalization)层的参数,这意味着在训练的前7 500步中,BN层的参数不会更新,这一策略有助于在训练初期快速收敛,同时在训练后期允许模型参数自由调整以捕捉更复杂的信息。
3.2 实验结果分析
本文采用的评测指标如下:
a.平均精度(AP)。AP是Average Precision的缩写,这一指标衡量了模型在不同置信度阈值下的平均精度,AP值越高,表示模型的整体性能越好。
b.归一化误差(NormError)。该指标通常指的是模型预测值与实际值之间差异的归一化化误差,是衡量模型性能的关键指标之一。
c.角度误差(AngleError)。该指标衡量模型在预测角度方面的准确性。
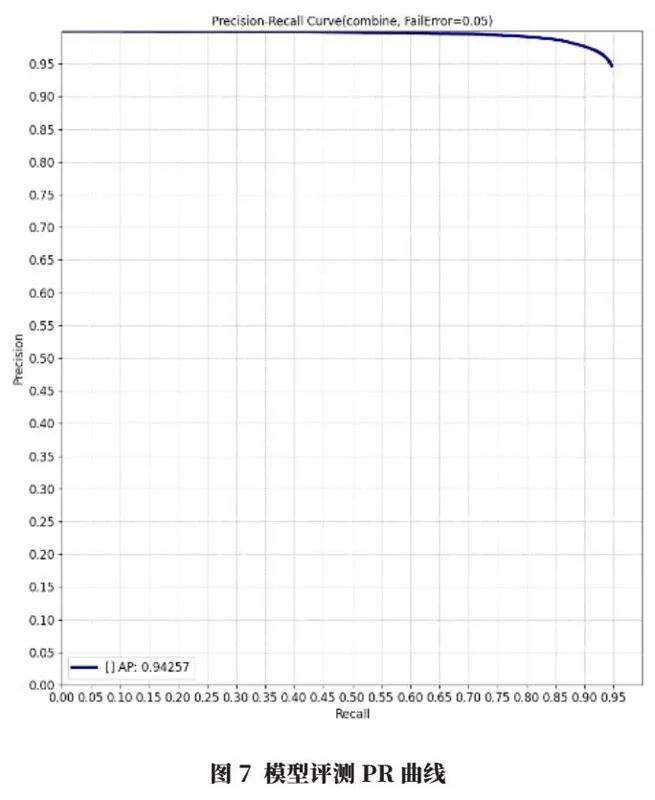
d.PR曲线(Precision-Recall)。该曲线通过绘制不同阈值设置下的精确度(Precision)与召回率(Recall)之间的关系,曲线下的面积能够量化模型的整体性能,值越高表示模型的性能越好。
训练完成后,在4 770张图像评测集上进行评测,评测结果为AP值为0.955,NormError值为0.017,AngleError值为4.75,PR曲线如图7所示。该评测结果表明模型具有很高的平均精度,且误差较小,模型在处理角度信息时也具有较高的精确度。
同时为了获得更直观的视觉感受,本文选取了一些测试图像可视化地来分析车轮接地点检测模型的性能,图8显示了该模型在车辆两点关键点上的检测效果。可以看出,该模型在检测车轮关键点方面效果良好,能够准确识别车辆目标的同时检测出车近侧车轮前后两点接地点。
4 未来工作
对于一些复杂场景和corner case,车轮关键点检测方法还是会有一定局限性,可能出现接地点漏检或位置不准等情况,未来的研究可以集中在解决这些corner case和提高关键点检测的鲁棒性。
下面列举了一些车轮关键点检测的corner case:
a.目标存在遮挡情况造成关键点位置不明显,会导致接地点漏检、检测位置不准。
b.对于一些cut-in场景,会导致目标不完整、车轮缺失,可能造成模型脑补的关键点预测不准。
c.对于大小车车辆重叠的场景,会导致关键点位置检测不准,如图9所示。
5 结语
本文搭建了一种基于自顶向下的、使用Heatmap + Offsets方法的车辆关键点检测模型,通过模型评测定量和定性结果可以看出,其具有很高的精度效果,且误差较小,在处理角度信息时也具有较高的精确度。未来的研究可以集中在解决道路复杂场景和corner case上,需要不断提高关键点检测算法的鲁棒性。
参考文献:
[1].刘军,后士浩,张凯,等.基于单目视觉车辆姿态角估计和逆透视变换的车距测量[J].农业工程学报,2018,34(13):70-76.
[2].汪检兵,李俊.基于OpenPose-slim模型的人体骨骼关键点检测方法[J].计算机应用,2019,39(12):3503-3509.
[3].石高辉,陈晓荣,刘亚茹,等.基于卷积神经网络的人脸关键点检测算法设计[J].电子测量技术,2019,42(24):125-130.
[4].马双双,王佳,曹少中,等.基于深度学习的二维人体姿态估计算法综述[J].计算机系统应用,2022,31(10):36-43.
[5].Newell A,Yang K,Deng J.Stacked hourglass networks for human pose estimation[C]//European Conference on Computer Vision. Springer,Cham,2016:483-499.
[6]Cao Zhe,Tomas S,Shih-En W,et al.Realtime multi-person 2D pose estimation using part affinity fields[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2017:130-138.
作者简介:
吕纤纤,女,1996年生,助理工程师,研究方向为智能驾驶算法。
