
数据要素的赋能机制与企业全要素生产率提升
2024-12-17 00:00:00史丹郑玉
改革 2024年11期





摘 要:将数据要素引入生产函数,可产生巨大的生产力效应,但数据要素能否以及如何影响企业全要素生产率仍有待深入研究。利用国家级大数据综合试验区设立的准自然实验,运用2010—2022年中国A股制造业上市公司数据和双重差分模型,揭示数据要素对企业全要素生产率的影响机理。研究发现:数据要素能够显著提升企业全要素生产率;在作用机制上,数据要素主要通过创新赋能、营运赋能和投资赋能促进企业全要素生产率提升;异质性分析发现,数据要素对企业全要素生产率的提升效应在数据开放程度高、数据应用场景丰富、数据法治建设完善、数据安全保障强的地区更显著。
关键词:数据要素;赋能机制;企业全要素生产率;国家级大数据综合试验区
中图分类号:F124 文献标识码:A 文章编号:1003-7543(2024)11-0001-16
全要素生产率是新质生产力的重要衡量指标[1],被认为是发展新质生产力的重要抓手。但研究发现,自2000年以来,中国全要素生产率增速进入快速下降通道,并于2010年进入负增长阶段[2]。因此,研究如何提升企业全要素生产率,赋能企业高质量发展,是发展新质生产力的内在要求。区别于资本、劳动等传统要素边际成本递增、边际收益递减的特征,数据要素具有非损耗性,从而可以突破资源约束,使其同时具有边际成本递减和边际收益递增的特征[3-4]。那么,数据要素能否激发企业高质量发展的活力,扭转企业全要素生产率下降的趋势,实现企业发展“量、质”统一?中国于2016年分两批设立国家级大数据综合试验区,为数据要素集聚和共享提供了载体,可以看作释放数据要素价值的准自然实验,为数据要素生产率效应的发挥提供了绝佳的实验机会。在大力培育新质生产力、塑造发展新动能的背景下,研究数据要素对企业全要素生产率的影响,具有重要的理论价值和现实意义。
现有研究从理论和实证两个层面关注数据要素对企业全要素生产率的影响:一是从理论层面分析数据要素影响企业全要素生产率的机理。数据要素通过降低不确定性[5]、优化资源配置[6]、赋能业务流程[7]、推动商业模式和决策范式变革[8],改进企业全要素生产率。二是从实证层面检验数据要素对企业全要素生产率的影响。郑玉[9]认为,数据要素通过缓解要素市场发展滞后引致的市场扭曲来促进企业全要素生产率提升。史丹和孙光林[1]研究发现,数据要素通过数字化变革和创新改进企业全要素生产率。Bajari等[10]证实,数据要素能够精准识别消费需求,助力企业生产计划的柔性调整。上述研究为本文提供了丰富的理论素材,有别于已有文献,本文的贡献在于:一是丰富了数据要素对企业全要素生产率影响机制的探讨。数据要素在企业全要素生产率改进中究竟扮演何种角色,一直是学术界关注的热点问题。本文认为,创新是企业获取竞争优势的动力,营运是企业产品生产和服务创造的主要环节,投资是企业生产和发展的必要手段。已有研究从创新视角考察数据要素影响企业全要素生产率的内在逻辑[1],本文进一步从营运赋能、投资赋能等方面拓展了数据要素影响企业全要素生产率的内在机理,丰富了相关的实证检验。二是深化了数据保护和应用场景在数据要素影响企业全要素生产率中的异质性作用。数据开放程度涉及数据供给数量和质量,数据应用场景关乎数据需求广度和深度,数据法治建设、数据安全保障影响数据要素开放共享的意愿和积极性。分析数据保护和应用场景的异质性影响,是对数据要素价值创造作用的有益补充。
一、理论分析与研究假说的提出
(一)数据要素对企业全要素生产率的影响
随着算力和算法的发展,以及数据留痕技术的应用,海量数据被收集、存储、加工,逐渐从单一碎片化的低密度低价值数据转化为多维块状的高密度高价值数据[5,7]。多维高密数据与其他生产要素相互融合,可缓解信息不对称引致的市场失灵[11],产生精准、即时、网络以及预期经济效应[12],赋能企业全要素生产率提升。具体而言:第一,数据要素满足了企业对信息的精准性需求。在工业经济时代,企业对消费者信息、供应链信息以及其他关键生产资源信息的搜寻主要采用“人找数据”的方式,信息搜寻范围窄、结果模糊、成本高,增加了信息匹配难度。然而,在数字经济时代,数据经过自动收集、有效传输和高质量处理,形成“千人千面”的精准数据,这种方便、快捷的搜寻方式,节约了搜寻成本,提高了信息匹配效率,推动了企业全要素生产率提升。第二,数据要素满足了企业对信息的即时性需求。生产、管理、营销、投资等环节对数据的时效性要求较高。算力是计算能力、运算速度的保障,算法则是模型设定和数据筛选的基础,二者共同为数据驱动决策提供支撑。算力和算法通过剔除掉历史数据和时效性弱的数据,过滤掉冗余度高的数据,对数据进行充分的“优化”和“去噪”,使数据质量和数据价值得到倍增,满足了企业对数据的即时性需求[5],有助于全面提升企业全要素生产率。第三,数据要素满足了企业对信息的网络化需求。为实现供需的快速响应、高效交互和精准匹配,企业对高质量网络化的海量数据产生较高的需求[12]。来源广泛、信息量大的网络化数据具有更大的使用价值,更能发挥数据驱动创新的价值,促进企业全要素生产率提升。第四,数据要素满足了企业对信息的预期性需求。市场经济充满不确定性,理性决策有助于企业抓住稍纵即逝的机会,提高决策效率。通过数据挖掘和数据分析,形成可诊断、可预期的高质量数据[13],缓解企业决策者的认知局限,形成理性预期,支持企业开展精准决策和有效决策,提高企业的资源配置效率和全要素生产率。由此,提出假说1:
H1:数据要素正向影响企业全要素生产率。
(二)创新赋能、营运赋能和投资赋能的中介作用
数据要素的创新赋能机制有助于改进企业全要素生产率。一方面,数据要素加速了创新资源的流通和融合。“数据+算力+算法”形成的数据生产力,使数据要素与传统技术要素加速融合[5],将传统技术要素转化为可编码的技术知识,以数据要素的形式存在、流动,打破企业边界、区域分割、地缘限制,拓宽知识整合的时空约束。创新主体间通过数字平台进行创意交互、研发协同、创新资源共享,降低研发信息搜寻成本,增强研发信息的整合范围。不同领域的技术相互赋能、彼此融合,有利于新技术的产生。企业对新技术的触达,以及多元化技术知识的外延,能够显著增强企业创新的复杂性、新颖性和广泛性,加快企业将新知识新技术应用于新领域的速度。数据要素与资本、劳动等传统生产要素的融合,可以实现要素间优势互补,促进企业创新能力的提升和全要素生产率的改进[5]。另一方面,数据要素提高了研发创新的精准性。数据要素驱动了企业创新全流程、全环节的数字化改造,实现全流程的可视化、可调整、可监控,降低研发不确定性风险,提高市场研判的准确性,缩短技术研发周期,帮助企业抓住稍纵即逝的创新机会,提高研发创新成功的概率[14]。数据要素提高了产业链上下游协同创新的积极性以及上下游企业知识的互补性,有利于聚焦产业链前沿技术领域的“卡脖子”问题,促进对关键核心技术的协同突破,直接推动企业全要素生产率提升。此外,高质量创新还需要巨额投入作为支撑[15],数据要素能够减少市场摩擦,降低融资成本,提高融资规模,更好地支撑企业开展高质量的研发创新活动。基于此,提出假说2a:
H2a:数据要素通过创新赋能机制,正向影响企业全要素生产率。
数据要素的营运赋能机制有助于改进企业全要素生产率。第一,数据要素缓解了企业内部的营运摩擦。数据要素有效联结创意设计、研发创新、生产制造等企业价值链环节,提高各环节的信息透明度,加强部门间交流,促进部门间信息共享和关键资源调剂[16-17],降低系统与系统、生产与库存、组织与员工等之间的“摩擦”与“冲突”[12]。第二,数据要素降低了企业外部的营运摩擦。数据要素有效减少了企业与供应商、企业与客户、企业与投资者间的信息孤岛问题[16,18],降低了资源要素的搜寻成本和交易匹配成本[19],规避了交易对象的机会主义行为[20]和产生的额外交易费用[21],减少了低效交易对生产资源的挤占[22],促进了经营目标优化[23],可支持企业高质量生产[24]。可以说,数据要素能够基于价值链全流程进行资源要素的优化配置,将资源要素配置到最需要的领域,实现全环节的激励相容、和谐共生[12],这些都是企业营运能力增强和全要素生产率改进的关键[24]。由上述理论分析,提出假说2b:
H2b:数据要素通过营运赋能机制,正向影响企业全要素生产率。
数据要素的投资赋能机制有助于改进企业全要素生产率。一方面,数据要素提升了企业的投资质量。投资是企业生产和发展中最频繁、最关键的经济活动之一。企业投资决策质量直接关系到资源配置质量,对企业全要素生产率产生直接影响。大数据能够拓宽投资信息来源渠道,提升投资信息透明度,增强企业对投资信息的甄别能力[25-26]。在数据要素赋能下,企业不仅可以及时获取供应商的原材料及中间品种类、质量等信息,还可以准确定位供应链变化及发展趋势[11],提高采购投资质量;在数据要素驱动下,有效缩短了企业与市场的距离,加强了企业与消费者的交互,提高了企业对市场需求的研判能力,从而根据市场走势挖掘投资机会,驱动投资资金流向高收益、低风险领域[5],优化投资质量。另一方面,数据要素提升了企业的投资效率。在数据要素驱动下,投资活动更加透明,降低了投资活动中的监督成本和由此引致的效率损失[27]。在数据要素驱动下,代理问题引致的可操控空间大幅减少,监督成本骤然下降,投资效率得到明显提高[26]。此外,在数据要素驱动下的投资具有实时化、透明化等特征,可以实时监控投资完成情况和投资实施效果,优化投资流程,推动投资效率提升。由此,得到假说2c:
H2c:数据要素通过投资赋能机制,正向影响企业全要素生产率。
(三)数据开放程度、数据应用场景、数据法治建设和数据安全保障的异质性作用
为深入探究数据要素对企业全要素生产率的影响机理,本文进一步分析数据保护和应用场景在数据要素影响企业全要素生产率中的异质性作用。
数据应用场景涉及获取数据资源的广度和深度,以及下游的应用需求激励等方面,在数据应用场景更丰富的情景下,数据要素对企业全要素生产率的影响将更显著。具体而言:第一,数据开放程度越高,数据要素对企业全要素生产率的影响越大。在数据开放程度高的地区,企业能够获取种类更丰富、使用价值更大的数据资源,高质量的数据资源在企业间非排他性地流通、共享和使用[28],不仅能够显著促进前沿技术的溢出和扩散[29],发挥技术优势,促进产品创新、工艺创新和流程优化,提高产品质量和企业全要素生产率[5]。与此同时,企业之间高效共享使用数据资源,提高了企业对市场需求、供应商能力以及投资风险等的评估效率[18],从而增强了数据要素对企业全要素生产率的提升作用。第二,数据应用场景越丰富,数据要素对企业全要素生产率的影响越大。数据应用场景是下游的应用环节,为数据要素提供了需求激励[29]。数据应用场景能够赋予数据要素不同的价值和用途。广泛、丰富的数据应用场景和数据应用需求能够使数据要素的价值得到更大程度的释放。比如,高新技术企业在缺乏抵押品的情况下申请银行信用贷款,银行通过大数据对企业的信誉和还款能力进行评估和推断,可以使企业较快地获得这笔资金,从而促进企业高质量发展。这便是数据应用场景助力高新技术企业增强融资能力、促进其改进企业全要素生产率的例子。据此,提出假说3a:
H3a:在数据应用场景更丰富的地区,数据要素对企业全要素生产率的促进作用更显著。具体而言,数据开放程度越高、数据应用场景越丰富,数据要素对企业全要素生产率的提升作用越显著。
数据保护涉及数据的隐私保护、数据的安全完整等方面,在数据保护程度更高的地区,数据要素对企业全要素生产率的影响更显著。具体而言:第一,数据法治建设越完善,数据要素对企业全要素生产率的影响越大。数据要素具有资产属性,需要完善的法律制度加以保护;同时,数据要素的收集、加工以及交换等各个环节也离不开法律制度的支撑作用[29]。完善的数据法律保护体系缓解了数据要素市场的条块分割、违规交易以及不完全契约等问题[30],推动高质量数据资源的开放和共享,促进企业以更低的交易成本获取更高质量的数据要素[31],不断增强数据要素对企业全要素生产率的促进作用。第二,数据安全保障越强,数据要素对企业全要素生产率的影响越大。在数据要素的交易和共享过程中,存在数据泄露、数据滥用和攻击等风险。在数据安全得不到保障的情况下,高质量数据要素的供给不足,获取高价值数据要素的难度增大、成本增高,不利于充分激发数据要素的应用价值[29],不利于发挥数据要素对企业全要素生产率的促进作用。基于上述分析,提出假说3b:
H3b:在数据保护程度更高的地区,数据要素对企业全要素生产率的促进作用更显著。具体而言,数据法治建设越完善、数据安全保障越强,数据要素对企业全要素生产率的提升作用越显著。
二、研究设计
(一)模型设定
为考察数据要素对企业全要素生产率是否具有激励效应,设定如下基准回归模型:
TFPit=β0+β1TreatPostit+φControlsit+ηj+μi+γt+εit(1)
模型(1)中的变量下标i、t分别代表企业、年份。企业全要素生产率(TFP)分别采用LP法、OP法、FE法测度。数据要素(TreatPost)借鉴史丹和孙光林[1]的研究,如果公司所在地设立国家级大数据综合试验区,在设立当年及以后年份取值为1,否则取值为0。β1衡量了数据要素对企业全要素生产率的激励效应,如果β1显著为正,则表明数据要素在激励企业全要素生产率提升方面是有效的。控制变量(Controls)主要包括:销售增长率(Sale_gr)、资本结构(Lev)、公司规模(Size)、资产利润率(Roa)、现金流(Cflow)、股权性质(Soe)、人力资本(Humcap)、公司年龄(Age)、第一大股东持股比例(Top1)、董事会规模(Board)。此外,借鉴史丹和孙光林[1]的研究,本文还控制了省份层面的城镇化(Urban)、经济发展水平(Rgdp)以及政府干预(Gov)。ηj、μi、γt以及εit分别代表行业、城市、时间固定效应以及随机误差项。
(二)数据来源与变量定义
1.数据来源
国家级大数据综合试验区名单来自国家发展和改革委员会官网。其他数据来自国泰安(CSMAR)数据库、CNRDS数据库。由于制造业与非制造业在技术创新、生产过程、投资管理等方面具有显著的行业结构差异,同时创新、营运、投资赋能机制均与制造业具有密切的关系,因而本文选取更具标准化和可比性的制造业上市公司作为研究对象。考虑到2016年2月设立贵州试验区,2016年10月分别设立京津冀、珠江三角洲、上海、河南、内蒙古、重庆以及沈阳试验区,因而本文选取2010—2022年中国A股制造业上市公司为样本。此外,本文对连续变量在1%水平上进行Winsor(缩尾)处理。
2.变量定义
全要素生产率(TFP)。借鉴鲁晓东和连玉君[32]以及郑玉[9]的研究,分别采用LP法、OP法、FE法测算企业全要素生产率。
数据要素(TreatPost)。借鉴刘传明等[33]、史丹和孙光林[1]的研究,若企业所在城市设立国家级大数据综合试验区,在设立当年及以后年份取1,否则取0。
机制变量。一是创新赋能。借鉴张杰和郑文平[34]、黄先海和高亚兴[35]的研究,分别采用专利知识宽度、专利被引量测度企业创新情况。其一,专利知识宽度采用发明专利IPC分类号大组层面的赫芬达尔-赫希曼指数(HHI指数)衡量,公式为KnowWidthit=1-ratio,ratioijt表示大组分类号为j的专利占企业当年全部专利的比重,KnowWidthit的值越高,代表专利知识宽度越大;其二,专利被引情况采用每个公司每年所有发明专利的平均被引次数的自然对数衡量。二是营运赋能。借鉴李万利等[36]的研究,分别采用固定资产周转率、存货周转率衡量企业的营运能力。三是投资赋能。借鉴张耀伟等[37]的研究,采用Richardson[38]投资期望模型的残差衡量企业的投资情况。残差绝对值越大,代表投资质量越差,投资效率越低。
异质性变量。一是数据开放程度。借鉴戴魁早等[29]、彭远怀[24]的研究,采用复旦大学数字与移动治理实验室构建的中国省级开放数林指数衡量,按照是否高于样本中位数将样本分为数据开放程度高、低两组。二是数据应用场景、数据法治建设和数据安全保障。借鉴戴魁早等[29]的研究,分别采用《中国大数据发展报告No.5》中2020年的场景应用指数、《中国大数据发展报告No.6》中2020年的数字法治指数和《中国大数据发展报告No.5》中2020年的大数据安全指数衡量,并按照是否高于样本中位数将相应样本分为高、低两组。
控制变量。考虑到公司的财务状况、治理结构以及地区经济特征均可能对企业全要素生产率产生影响,借鉴彭远怀[24]、郑玉[9]以及史丹和孙光林[1]的做法,主要控制如下变量:公司层面包括销售增长率(Sale_gr)、资本结构(Lev)、资产利润率(Roa)、现金流(Cflow)、公司规模(Size)、股权性质(Soe)、人力资本(Humcap)、公司年龄(Age)、第一大股东持股比例(Top1)、董事会规模(Board);地区层面包括城镇化(Urban)、经济发展水平(Rgdp)、政府干预(Gov)。
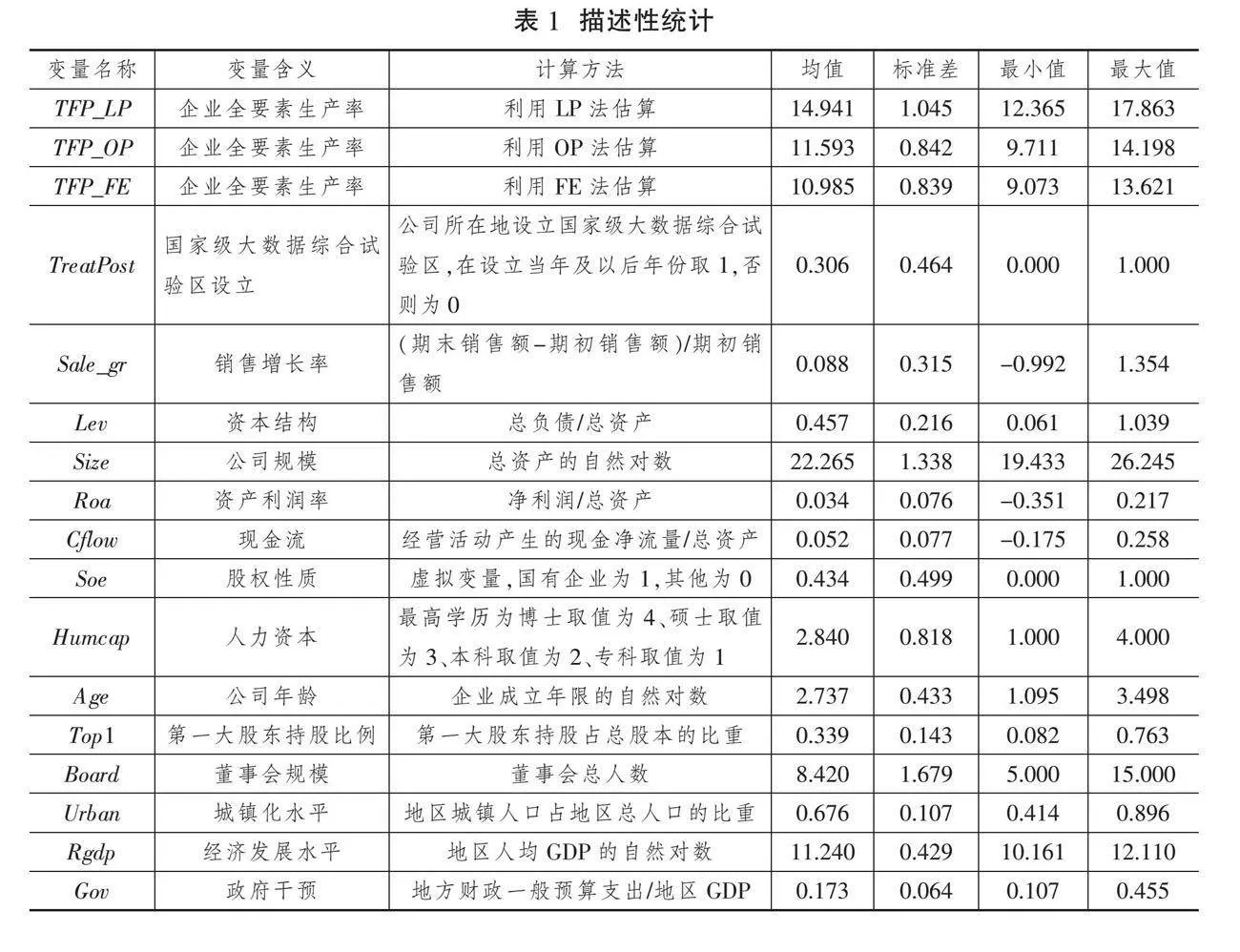
变量定义及描述性统计如表1所示。
三、实证结果与分析
(一)基准回归结果
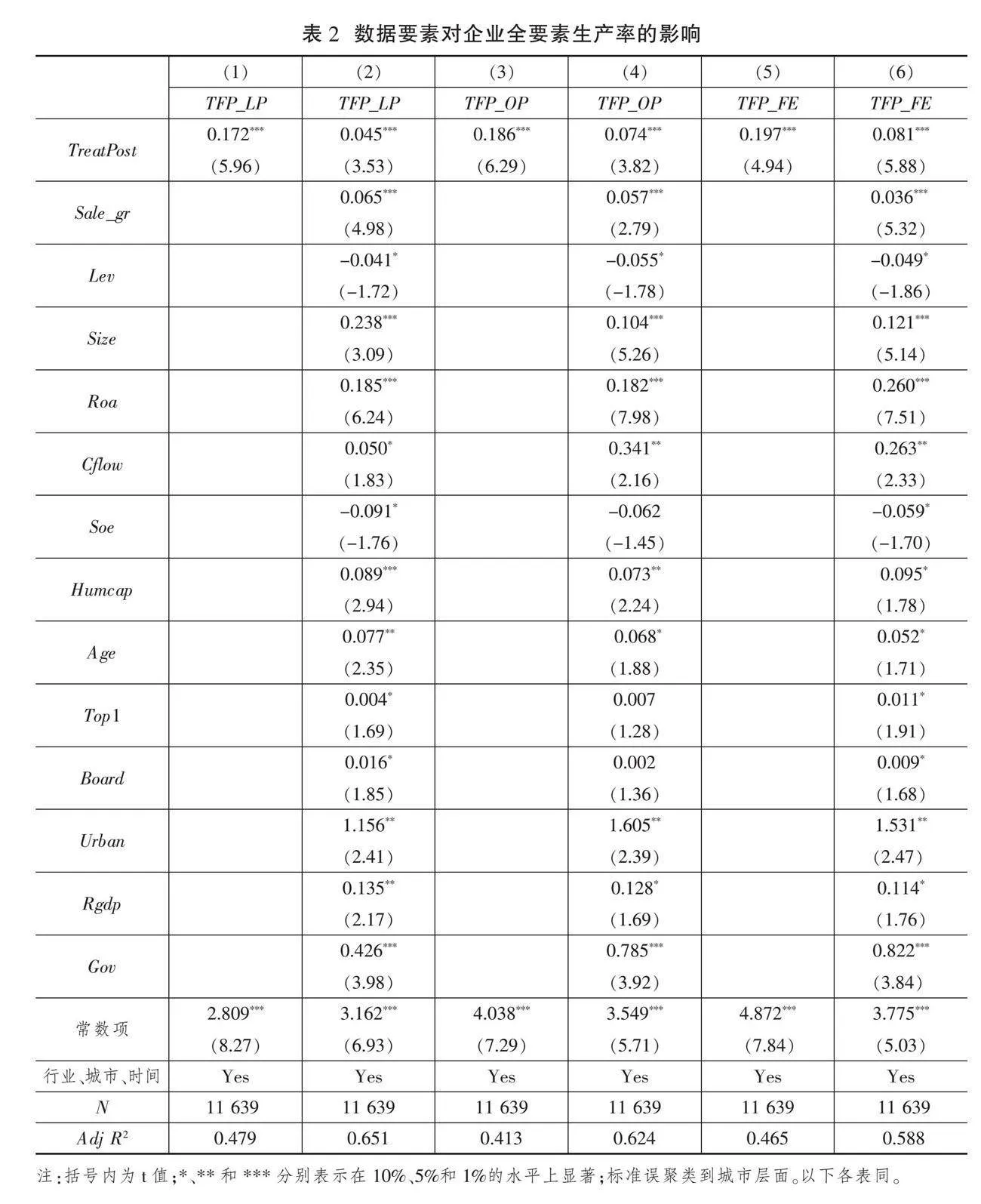
表2(下页)是本文的基准回归结果。其中,列(2)为采用LP法测算企业全要素生产率的回归结果,数据要素的回归系数为0.045(t=3.53),表明设立国家级大数据综合试验区后,试验区内的企业全要素生产率将显著提高4.5%,数据要素赋能企业全要素生产率提升的效果明显;列(4)为采用OP法测算企业全要素生产率的回归结果,数据要素的回归系数为0.074(t=3.82);列(6)为采用FE法测算企业全要素生产率的回归结果,数据要素的回归系数为0.081(t=5.88)。无论被解释变量企业全要素生产率采用哪种测算方式,关键解释变量数据要素的回归系数均在1%水平上显著为正,表明数据要素在提升企业全要素生产率方面具有重要作用。由此可见,国家级大数据综合试验区建设通过数据要素集聚效应,提高了上下游企业之间的信息透明度,增强了企业的营运效率和管理效率,进而为企业全要素生产率的提升提供了强劲动力,假说H1得到验证。
(二)稳健性检验
1.动态效应分析
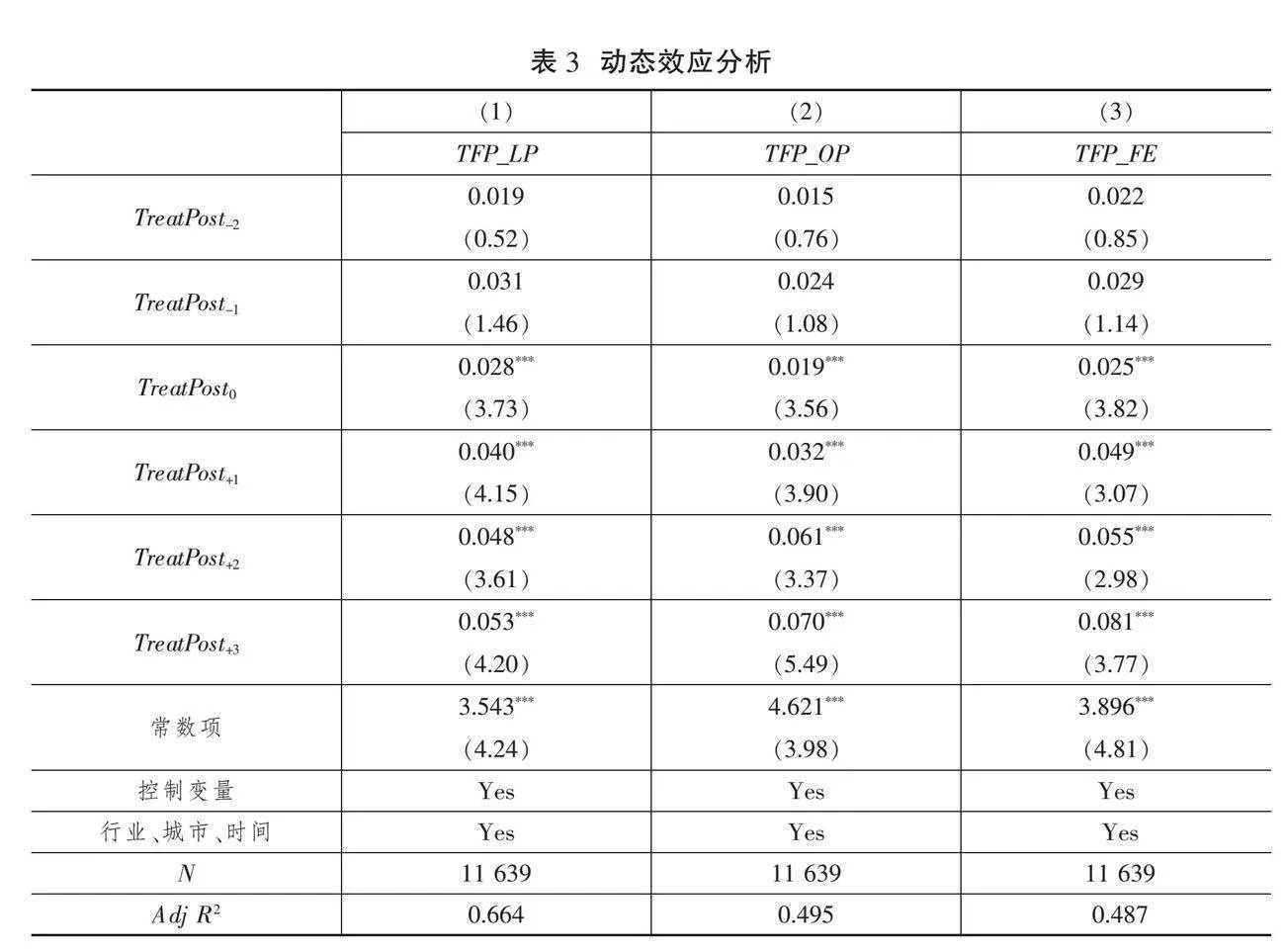
为检验试验区设立之前实验组和对照组企业在企业全要素生产率发展方面是否具有相同趋势,借鉴Beck等[39]、于亚卓等[40]以及郑玉[14]的研究,采用回归法来验证共同趋势假设,构建如下检验模型:
TFPit=β0+∑T∈{-2,-1,0,1,2,3} βTTreatPostiT+φControlsit+ηj+μi+γt+εit(2)
表3(下页)为共同趋势检验结果,其中TreatPost-2、TreatPost-1的回归系数均不显著,表明设立国家级大数据综合试验区之前,实验组和控制组的企业全要素生产率具有共同发展趋势。而在设立国家级大数据综合试验区后二者的发展趋势开始呈现显著差异:数据要素的回归系数均在1%水平上具有显著性。由此可见,共同趋势成立,动态效应分析也在一定程度上验证了本文研究结论的稳健性。
2.安慰剂检验
为排除未被观测到的因素可能产生的潜在影响,采用LP法测算企业全要素生产率,并基于实际的试点时间和虚拟的试点城市进行安慰剂检验[14,41-42]。图1呈现了500次自抽样的回归系数及相应的P值。横、纵坐标虚线分别表示10%的显著性水平和基准回归中数据要素对应的回归系数值。由图1可知,安慰剂检验的系数值在零点附近近似服从正态分布,且较大比例的系数值落在10%的置信区间外,表明假说H1中的核心结论稳健可靠。
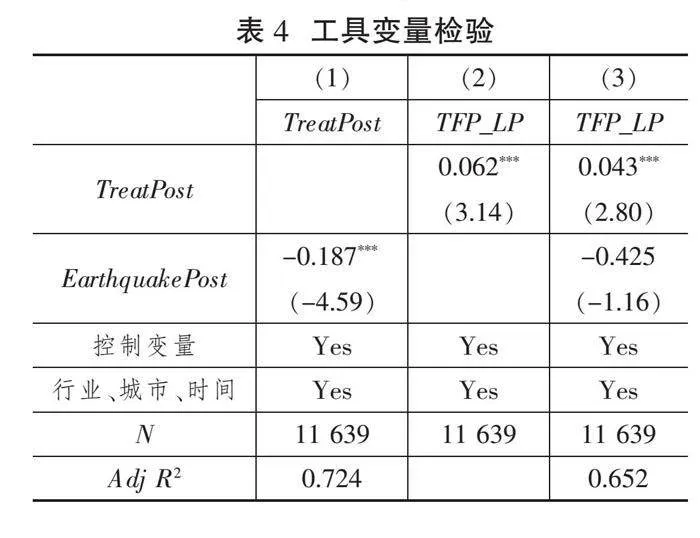
3.工具变量法
理论上,如果存在其他与国家级大数据综合试验区空间选址类似的其他区位导向性政策,仍然可能会影响实证结果,从而无法体现国家级大数据综合试验区对企业全要素生产率的净影响。对此,本文借鉴孙伟增等[43]的研究,采用工具变量法以排除其他不可观测因素的干扰,以解决国家级大数据综合试验区选址的内生性问题。具体而言,稳定的地质条件与国家级大数据综合试验区选址具有紧密的关系,而地质条件与企业全要素生产率没有直接关系,因而满足工具变量使用条件。为此,本文从国家统计局网站整理了2004—2015年各省份7级以上地震次数(Earthquake),并与表征政策实施年份的Post变量相乘,得到EarthquakePost,作为模型(1)中内生解释变量TreatPost的工具变量。
表4为工具变量两阶段最小二乘法(2SLS)的回归结果,其中,在列(1)第一阶段回归中,工具变量的系数显著为负。该实证结果表明,越易发生地震的地区,该地区的地质稳定性越差,越不可能设立国家级大数据综合试验区。在列(2)第二阶段回归中,数据要素的回归系数为0.062(t=3.14),表明核心结论具有稳健性。列(3)进一步将工具变量加入模型(1),发现控制国家级大数据综合试验区表征的数据要素后,工具变量对企业全要素生产率的影响不再显著,满足排他性要求。
4.其他稳健性检验
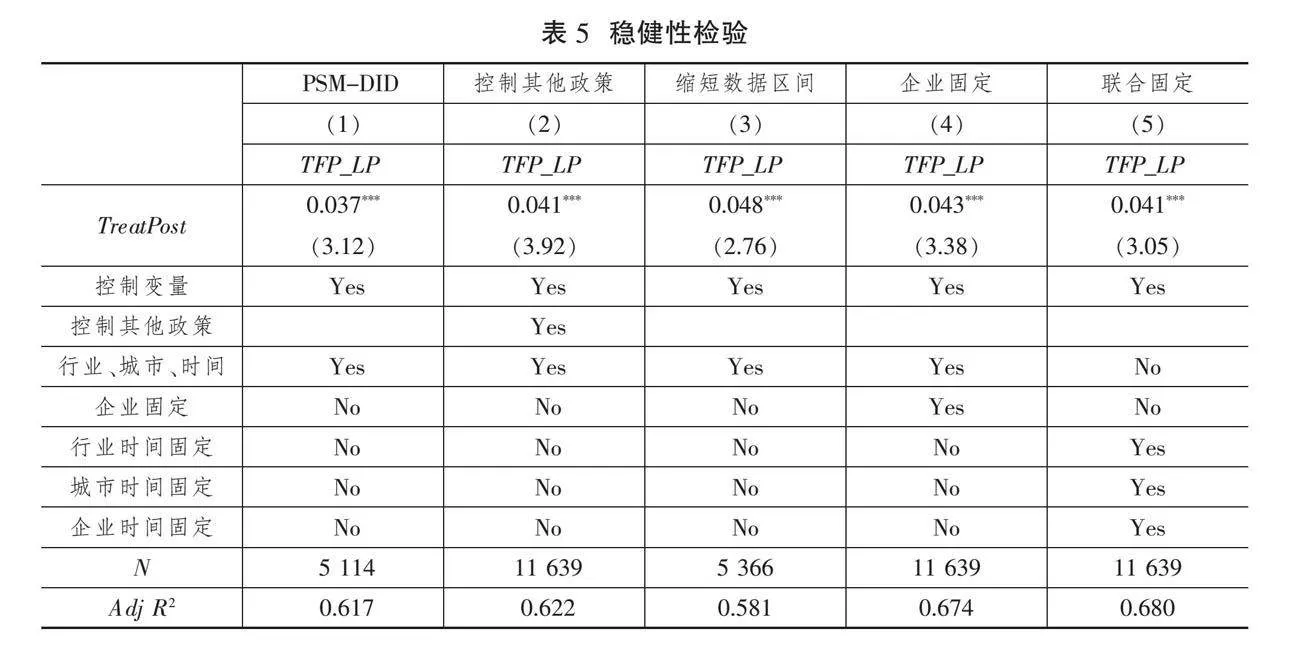
首先,采用PSM-DID方法估计。设立国家级大数据综合试验区来自政府前瞻性布局,因而设立国家级大数据综合试验区作为外部性政策冲击能够有效避免反向因果引致的内生性问题。然而,国家级大数据综合试验区的设立可能存在样本自选择问题。为此,本文采用PSM-DID方法进行稳健性检验。具体而言,首先采用PSM法为实验组企业配对特征相近的控制组企业,然后采用DID方法对倾向得分匹配(PSM)后的样本进行回归。表5(下页)列(1)显示,在PSM-DID回归中数据要素的系数为0.037(t=3.12);回归结果表明,相较于所在地未设立国家级大数据综合试验区的企业,试验区内企业全要素生产率大致高出3.7个百分点。由此可知,控制样本自选择性偏误后,设立国家级大数据综合试验区对企业全要素生产率提升具有显著的激励作用。
其次,控制其他政策。郑玉[14]认为,入选“宽带中国”试点城市,会使数字基础设施建设水平得到显著提升,在一定程度上发挥了数据要素集聚功能,因而本文控制“宽带中国”战略试点政策对回归结果的影响;2019年10月20日,福建省、四川省、广东省、浙江省、重庆市以及河北省(雄安新区)等6个国家数字经济创新发展试验区启动创建工作,因而亦需控制该政策对回归结果可能产生的潜在影响。列(2)呈现了排除这两项政策干扰后的回归结果,数据要素的回归系数为0.041(t=3.92),表明排除其他政策干扰后,数据要素对企业全要素生产率的正向影响依然未发生改变。
再次,缩短数据区间。长数据区间易受其他干扰因素影响[14,40],鉴于国家级大数据综合试验区分两批分别于2016年2月和10月批复设立,本文将数据区间缩短为2014—2019年,列(3)呈现了缩短数据区间后的回归结果,数据要素TreatPost的回归系数为0.048(t=2.76),研究结论与前文无差别。
最后,加入多维固定效应。为增强实证结果的稳健性和准确性,本文借鉴彭远怀[24]、侯晓辉和王腾宇[44]、Giroud等[45]的研究,在基准回归的基础上,加入多维固定效应缓解估计偏误。具体而言,列(4)在原来控制行业、城市、时间固定效应的基础上,进一步控制企业固定效应;列(5)则将列(4)中的行业、城市、企业、时间固定效应替换为“行业×时间”固定效应、“城市×时间”固定效应、“企业×时间”固定效应。可以看出,列(4)使用多维固定效应后,研究结论保持稳健;列(5)使用高维固定效应后,数据要素的影响效应依然显著。上述系列稳健性检验表明假说H1中的核心研究结论具有稳健性。
(三)作用机制的识别
理论分析表明,数据要素通过创新赋能、营运赋能和投资赋能推动企业全要素生产率提升。为此,本文借鉴Baron和Kenny[46]、郑玉[47]的研究,在模型(1)的基础上,构建模型(3)和模型(4)检验创新赋能、营运赋能和投资赋能的中介效应:
Mediatorit=β0+β1TreatPostit+φControlsit+ηj+μi+γt+εit(3)
TFPit=β0+β1TreatPostit+β2Mediatorit+φControlsit+ηj+μi+γt+εit(4)
其中,Mediatorit为中介变量,模型(3)用于考察数据要素对中介变量的影响,模型(4)用于考察中介变量在数据要素影响企业全要素生产率中的中介作用。
1.创新赋能机制分析
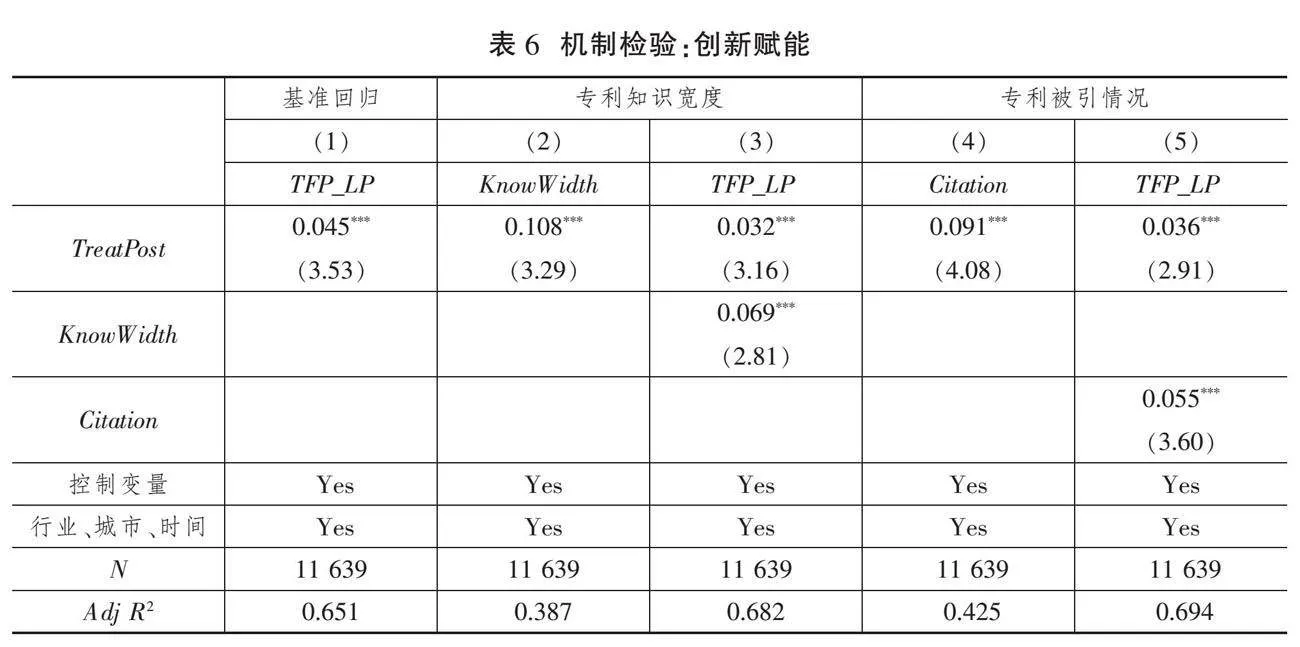
表6(下页)报告了创新赋能中介效应的检验结果。通过模型(1)的检验,在列(1)的回归结果中,数据要素(TreatPost)对被解释变量企业全要素生产率(TFP)的回归系数显著为正,表明数据要素有助于提升企业全要素生产率。根据模型(3),在列(2)和列(4)的结果中,数据要素(TreatPost)对中介变量专利知识宽度(KnowWidth)和专利被引情况(Citation)的回归系数均显著为正,表明数据要素对企业创新具有显著的激励作用。由模型(4),得到列(3)和列(5)的检验结果中,中介变量专利知识宽度(KnowWidth)、专利被引情况(Citation)对企业全要素生产率(TFP)的回归系数均显著为正,且数据要素(TreatPost)对企业全要素生产率(TFP)依然具有显著的正向影响,但回归系数较列(1)的基准回归结果有所降低。由此可见,数据要素通过创新赋能,提高企业的创新水平和新产品开发能力,助力企业全要素生产率提升。至此,假说H2a中数据要素通过创新赋能而提升企业全要素生产率的理论假说得到验证。
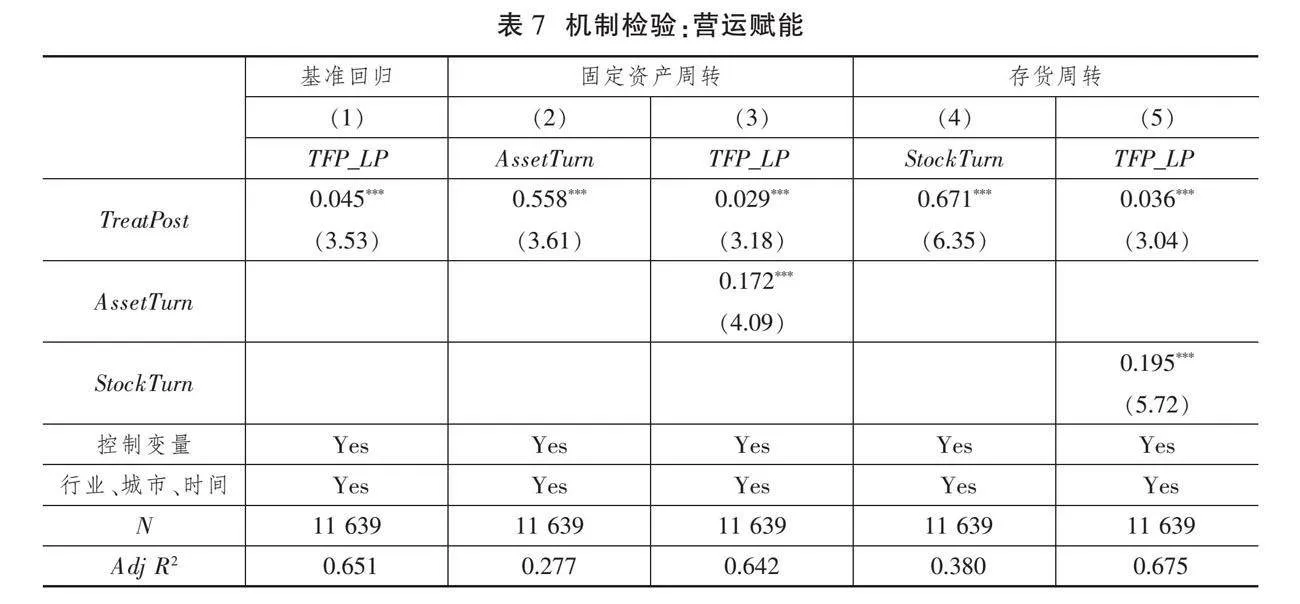
2.营运赋能机制分析
表7(下页)报告了营运赋能中介效应的检验结果。模型(1)的回归结果如列(1)所示,数据要素(TreatPost)的回归系数显著为正。根据模型(3),在列(2)和列(4)的结果中,数据要素(TreatPost)对中介变量固定资产周转率(AssetTurn)和存货周转率(StockTurn)的回归系数均显著为正,说明数据要素能够优化资产配置,提高以固定资产、存货为代表的资产周转率和资产营运效率。由模型(4)的实证结果列(3)、列(5)可知,中介变量固定资产周转率(AssetTurn)、存货周转率(StockTurn)对企业全要素生产率(TFP)的回归系数均显著为正,且数据要素(TreatPost)对企业全要素生产率依然具有显著的提升作用,但回归系数较列(1)的基准回归结果有所降低。综上可见,数据要素通过营运赋能,提高企业对资产的营运能力,助力企业全要素生产率提升。至此,假说H2b中数据要素通过营运赋能而提升企业全要素生产率的理论假说得到实证支持。
3.投资赋能机制分析
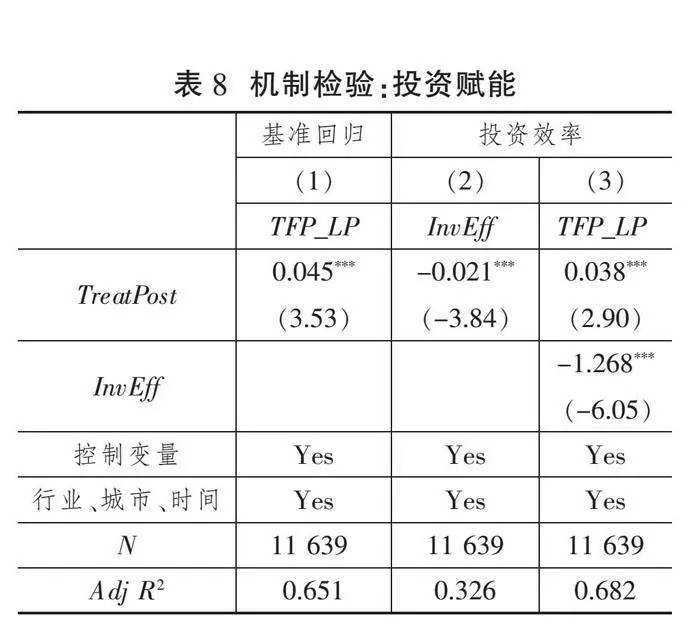
表8(下页)为投资赋能的中介效应检验结果。模型(1)的实证检验结果如列(1)所示,数据要素(TreatPost)对被解释变量企业全要素生产率(TFP)的回归系数显著为正。模型(3)的回归结果呈现在列(2)中,数据要素(TreatPost)对中介变量投资效率(InvEff)的回归系数显著为负,说明数据要素能够提高企业投资效率,抑制低效率和低质量投资问题。根据模型(4),列(3)的中介变量投资效率(InvEff)对企业全要素生产率(TFP)的回归系数显著为负,且数据要素(TreatPost)依然在1%水平上对企业全要素生产率具有积极的正向影响,但回归系数较列(1)的基准回归结果有所降低。这表明数据要素的投资赋能机制有助于企业全要素生产率提升。假说H2c通过实证检验。
(四)异质性检验
为深入理解数据要素与企业全要素生产率提升之间的因果关系,本文分别分析数据开放程度、数据应用场景、数据法治建设和数据安全保障在数据要素影响企业全要素生产率中的异质性作用。
1.数据开放程度
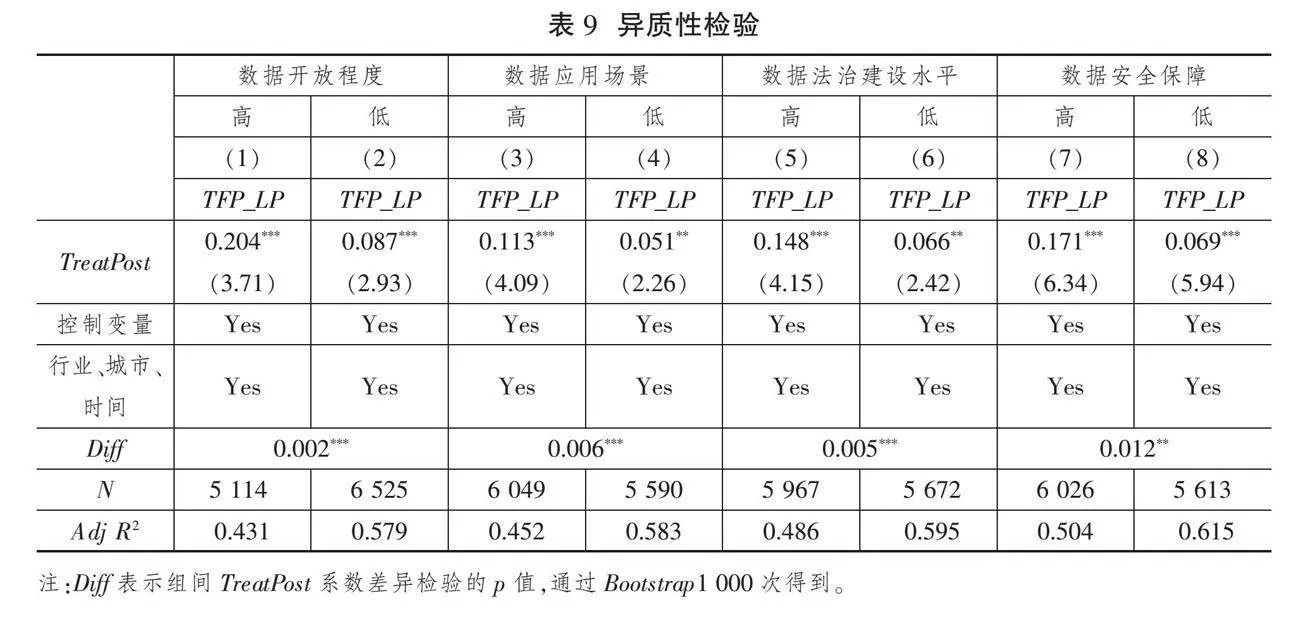
数据开放程度越高,数据集聚效应越大,数据要素价值也越高,因而能够更好地发挥数据的生产要素作用,增强数据要素对企业全要素生产率的提升效应。由此可见,数据开放程度越高,数据要素对企业全要素生产率的赋能作用越大。为此,本文根据数据开放程度进行异质性检验,表9列(1)、列(2)呈现了相关异质性检验结果。对比列(1)和列(2)可知,在数据开放程度更高的地区,数据要素对企业全要素生产率的提升作用更大,假说H3a通过实证检验。
2.数据应用场景
数据应用场景越丰富,对数据要素的需求越强,数据要素的潜在作用越大。数据应用场景通过拓宽数据要素的作用渠道、提升数据要素的作用空间来促进企业全要素生产率提升。为此,根据数据应用场景进行异质性检验,检验结果如表9列(3)、列(4)所示。对比列(4)范围较窄的数据应用场景,列(3)中丰富的数据应用场景更有利于发挥数据要素的作用。因此,数据要素对企业全要素生产率的提升作用在高数据应用场景中更易发挥和体现,假说H3a得到验证。
3.数据法治建设
加强数据法治建设能够营造良好的数据交易环境,促进数据要素的合法获取、正常使用和顺畅流通,加速消除数字鸿沟,更好地增强数据要素对企业全要素生产率的提升效果。为此,根据数据法治建设进行异质性检验,检验结果如表9列(5)、列(6)所示。对比列(6)中较低的数据法治建设水平,列(5)中较优的数据法治建设环境更有利于增强数据要素对企业全要素生产率的促进作用。这说明,数据法治建设水平越高,越有利于发挥数据要素对企业全要素生产率的提升作用,实证检验结果与假说H3b的理论预期相符。
4.数据安全保障
防止数据在使用过程中被篡改和损坏,保证数据的真实、有效和完整,是有效发挥数据要素作用的关键。为此,本文根据数据安全保障水平进行异质性检验,检验结果如表9列(7)、列(8)所示。对比列(7)和列(8)可以看出,在较好的数据安全保障环境中,更有利于发挥数据要素对企业全要素生产率的促进作用。该结论表明,强化数据安全保障,提供安全的数据要素交易环境,有助于强化数据要素对企业全要素生产率的促进作用,这为假说H3b通过检验提供了经验证据。
四、研究结论与政策建议
本文基于数字经济理论和微观经济理论,构建了数据要素影响企业全要素生产率的理论模型,利用国家级大数据综合试验区设立这一准自然实验和2010—2022中国A股制造业上市公司样本进行实证检验,得到如下研究结论:第一,数据要素促进了企业全要素生产率提升。本文研究证实,以国家级大数据综合试验区设立为代表的数据要素有效促进了企业全要素生产率提升。第二,数据要素通过创新赋能、营运赋能和投资赋能促进企业全要素生产率提升。本文从创新赋能、营运赋能、投资赋能视角揭示了数据要素影响企业全要素生产率的中介机制。其一,数据要素能够集聚创新资源,提高企业的创新水平,通过创新赋能助力企业全要素生产率提升和高质量发展;其二,数据要素能够优化营运流程,规避营运资产错配,通过营运赋能助力企业全要素生产率提升;其三,数据要素能够甄别投资机会,规避投资风险,提高投资质量,通过投资赋能助力企业全要素生产率提升。第三,数据要素对企业全要素生产率的影响在异质性的数据开放程度、数据应用场景、数据法治建设、数据安全保障下,存在显著差异。实证研究表明,在数据开放程度更高的地区、在数据应用场景更丰富的地区、在数据法治建设水平更高的地区以及在数据安全保障更强的地区,数据要素对企业全要素生产率的促进作用更明显。
根据上述结论,提出如下政策建议:
第一,持续发挥数据要素价值,增强数据要素对企业全要素生产率的提升作用。一方面,数据要素价值的发挥涉及算力、算法等多项数字技术,因而需要加强数字技术研发投入,弥补数字技术人才缺口,促进数据要素价值更好实现;另一方面,数据积累到一定程度,易引发“赢者通吃”“路径锁定”等现象,因而应加强对大型数字平台的反垄断监管,避免对制造业企业产生不利影响。
第二,充分利用创新、营运和投资三方面因素的赋能机制,持续助力企业全要素生产率提升。就创新赋能而言,企业应加强与外部创新主体的合作,开展联合创新和开放式创新,加速信息获取和知识融合,促进企业创新能力提升;就营运赋能而言,企业应加强营运流程的数字化管理,降低信息滞后引致的“牛鞭效应”,优化库存管理,快速响应市场,增强供应链灵活性,降低“断链”风险;就投资赋能而言,企业应增强风险防控意识,加强对投资风险的监测,提高对投资机会的感知能力,利用数据挖掘和分析技术,提高投资效率。
第三,关注数据保护和应用场景的差异,进一步释放数据要素对企业全要素生产率的提升潜能。首先,促进数据要素开放,推进数据资源互联互通,构建全国统一的数据要素市场,有效发挥数据要素生产力效应;其次,构建丰富的应用场景,丰富数据的赋能空间,同时引导数据要素流向战略性新兴产业和未来产业,构建现代化产业体系;最后,加强数据保护和数据治理,建立规范的数据联通规则和完善的数据保护制度,以打破数据孤岛、促进数据要素流通。 [Reform]
参考文献
[1]史丹,孙光林.数据要素与新质生产力:基于企业全要素生产率视角[J].经济理论与经济管理,2024(4):12-30.
[2]陈彦斌,陈伟泽.潜在增速缺口与宏观政策目标重构——兼以中国实践评西方主流宏观理论的缺陷[J].经济研究,2021(3):14-31.
[3]王静田,付晓东.数字经济的独特机制、理论挑战与发展启示——基于生产要素秩序演进和生产力进步的探讨[J].西部论坛,2020(6):1-12.
[4]史丹.数字经济条件下产业发展趋势的演变[J].中国工业经济,2022(11):26-42.
[5]李海舰,赵丽.数据成为生产要素:特征、机制与价值形态演进[J].上海经济研究,2021(8):48-59.
[6]戚聿东,刘欢欢.数字经济下数据的生产要素属性及其市场化配置机制研究[J].经济纵横,2020(11):63-76.
[7]白永秀,李嘉雯,王泽润.数据要素:特征、作用机理与高质量发展[J].电子政务,2022(6):23-36.
[8]陈国青,任明,卫强,等.数智赋能:信息系统研究的新跃迁[J].管理世界,2022(1):180-196.
[9]郑玉.数字经济、要素市场扭曲缓解与企业全要素生产率[J].经济体制改革,2024(1):88-96.
[10] BAJARI P, CHERNOZHUKOV V, HORTACSU A, et al. The impact of big data on firm performance: An empirical investigation[J]. AEA Papers and Proceedings, 2019, 109(5): 33-37.
[11] ACEMOGLU D, RESTREPO P. Automation and new tasks: How technology displaces and reinstates labor[J]. Journal of Economic Perspectives, 2019, 33(2): 3-30.
[12] 李海舰,赵丽.数据价值理论研究[J].财贸经济,2023(6):5-20.
[13] 谢康,夏正豪,肖静华.大数据成为现实生产要素的企业实现机制:产品创新视角[J].中国工业经济,2020(5):42-60.
[14] 郑玉.数字基础设施建设对企业创新影响机理探究——基于“宽带中国”战略试点准自然实验的实证检验[J].中央财经大学学报,2023(4):90-104.
[15] BHATTACHARYA U, HSU P H, TIAN X, et al. What affects innovation more: Policy or policy uncertainty?[J]. Journal of Financial and Quantitative Analysis, 2017, 52(5): 1869-1901.
[16] 沈国兵,袁征宇.企业互联网化对中国企业创新及出口的影响[J].经济研究,2020(1):33-48.
[17] 田秀娟,李睿.数字技术赋能实体经济转型发展——基于熊彼特内生增长理论的分析框架[J].管理世界,2022(5):56-73.
[18] MAGALHAES G, ROSEIRA C. Open government data and the private sector: An empirical view on business models and value creation[J]. Government Information Quarterly, 2020, 37(3): 101248.
[19] 许宪春,任雪,常子豪.大数据与绿色发展[J].中国工业经济,2019(4):5-22.
[20] 李唐,李青,陈楚霞.数据管理能力对企业生产率的影响效应——来自中国企业—劳动力匹配调查的新发现[J].中国工业经济,2020(6):174-192.
[21] 夏杰长,刘诚.行政审批改革、交易费用与中国经济增长[J].管理世界,2017(4):47-59.
[22] 钱雪松,康瑾,唐英伦,等.产业政策、资本配置效率与企业全要素生产率——基于中国2009年十大产业振兴规划自然实验的经验研究[J].中国工业经济,2018(8):42-59.
[23] GHASEMAGHAEI M, CALIC G. Assessing the impact of big data on firm innovation performance: Big data is not always better data[J]. Journal of Business Research, 2020, 108: 147-162.
[24] 彭远怀.政府数据开放的价值创造作用:企业全要素生产率视角[J].数量经济技术经济研究,2023(9):50-70.
[25] VIAL G. Understanding digital transformation: A review and a research agenda[J]. The Journal of Strategic Information Systems, 2019, 28(2): 118-144.
[26] 陈德球,胡晴.数字经济时代下的公司治理研究:范式创新与实践前沿[J].管理世界,2022(6):213-240.
[27] 袁淳,肖土盛,耿春晓,等.数字化转型与企业分工:专业化还是纵向一体化[J].中国工业经济,2021(9):137-155.
[28] JONES C I, TONETTI C. Nonrivalry and the economics of data[J]. American Economic Review, 2020, 110(9): 2819-2858.
[29] 戴魁早,王思曼,黄姿.数据交易平台建设如何影响企业全要素生产率[J].经济学动态,2023(12):58-75.
[30] 赵云辉,张哲,冯泰文,等.大数据发展、制度环境与政府治理效率[J].管理世界,2019(11):119-132.
[31] 尹华容,王惠民.隐私计算的行政法规制[J].湖南科技大学学报(社会科学版),2022(6):93-101.
[32] 鲁晓东,连玉君.中国工业企业全要素生产率估计:1999—2007[J].经济学(季刊),2012 (2):541-558.
[33] 刘传明,陈梁,魏晓敏.数据要素集聚对科技创新的影响研究——基于大数据综合试验区的准自然实验[J].上海财经大学学报,2023(5):107-121.
[34] 张杰,郑文平.创新追赶战略抑制了中国专利质量么?[J].经济研究,2018(5):28-41.
[35] 黄先海,高亚兴.数实产业技术融合与企业全要素生产率——基于中国企业专利信息的研究[J].中国工业经济,2023(11):118-136.
[36] 李万利,潘文东,袁凯彬.企业数字化转型与中国实体经济发展[J].数量经济技术经济研究,2022(9):5-25.
[37] 张耀伟,陈世山,曹甜甜.董事会断层与差异整合机制对投资决策质量的联合效应研究[J].南开管理评论,2021(2):94-107.
[38] RICHARDSON S. Over-investment of free cash flow[J]. Review of Accounting Studies,2006,11(2-3): 159-189.
[39] BECK T, LEVINE R, LEVKOV A. Big bad banks? The winners and losers from bank deregulation in the United States[J]. The Journal of Finance, 2010, 65(5): 1637-1667.
[40] 于亚卓,张惠琳,张平淡.非对称性环境规制的标尺现象及其机制研究[J].管理世界,2021(9):134-147.
[41] LI P, LU Y, WANG J. Does flattening government improve economic performance? Evidence from China[J]. Journal of Development Economics, 2016, 123: 18-37.
[42] 朱乾隆,石晓平,马贤磊,等.数字经济发展对工业用地利用效率的影响——基于国家级大数据综合试验区的准自然实验[J].中国土地科学,2023(11):41-51.
[43] 孙伟增,毛宁,兰峰,等.政策赋能、数字生态与企业数字化转型——基于国家大数据综合试验区的准自然实验[J].中国工业经济,2023(9):117-135.
[44] 侯晓辉,王腾宇.“用脚投票”还是“用手投票”:机构投资者持股与公司欺诈[J].经济管理,2024(7):168-189.
[45] GIROUD X, LIU E, MUELLER H. Innovation spillovers across U.S. tech clusters[Z].NBER Working Paper, No.32677, 2024.
[46] BARON R, KENNY D. The moderator-mediator variable distinction in social psychological research: Conceptual, strategic, and statistical considerations[J]. Journal of Personality and Social Psychology, 1986, 51(6):1173-1182.
[47] 郑玉.政府补贴的创新效应——兼论不同类型创新的最适补贴区间[J].经济经纬,2020(4):142-149.
Empowerment Mechanism of Data Elements and Improvement of Total Factor Productivity of Enterprises: Evidence from the National Big Data Comprehensive Pilot Zone
SHI Dan ZHENG Yu
Abstract: The introduction of data elements into the production function will generate significant productivity effects, but whether and how data elements can affect enterprise total factor productivity still requires further research. Using a quasi natural experiment established in the national big data comprehensive pilot zone, this study uses data from Chinese A-share manufacturing listed companies from 2010 to 2022 and a difference in differences model to reveal the impact mechanism of data elements on enterprise total factor productivity. Research has found that data elements can significantly improve enterprise total factor productivity. In terms of mechanism, data elements mainly promote the improvement of enterprise total factor productivity through innovation empowerment, operational empowerment, and investment empowerment. Heterogeneity analysis found that the effect of data elements on improving enterprise total factor productivity is more significant in regions with high data openness, rich data application scenarios, sound data rule of law construction, and strong data security guarantees.
Key words: data elements; empowerment mechanism; enterprise total factor productivity; national big data comprehensive pilot zone
基金项目:国家社会科学基金项目“‘卡脖子’技术对产业链现代化的阻滞机理及治理模式研究”(21BJY061);中国社会科学院重大项目“中华民族工业文明的形成演进及驱动力研究”(2023YZD054);中国社会科学院工业大数据联合实验室项目(2024SYZH007);中国社会科学院学科建设“登峰战略”资助项目(DF2023YS24)。
作者简介:史丹,中国社会科学院学部委员,中国社会科学院工业经济研究所研究员;郑玉(通信作者),郑州轻工业大学经济与管理学院副教授,中国社会科学院工业经济研究所进修教师。
