
多源大数据视角下匹配居民出行需求的城市公交系统设计
2024-12-04 00:00:00万玲
中国新技术新产品 2024年5期

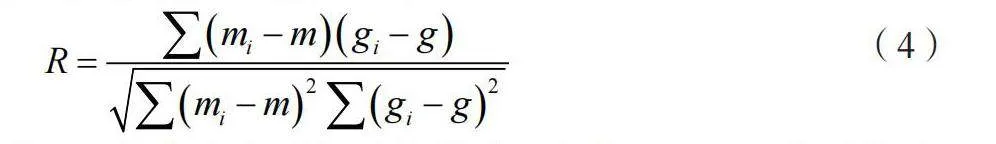

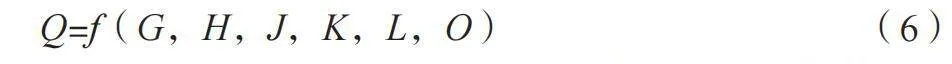

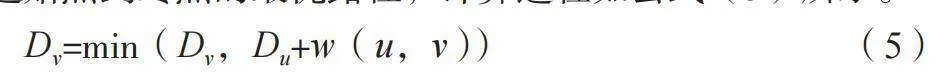
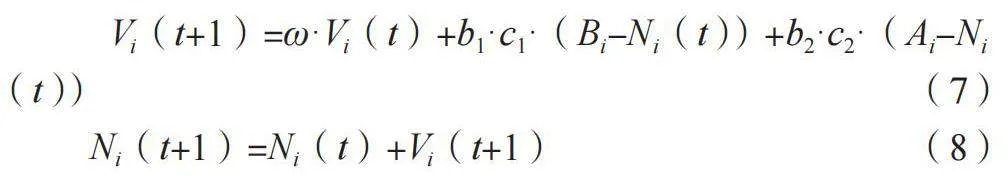
摘 要:本文以多源大数据为基础,设计一种匹配居民出行需求的城市公交系统,有效改善城市居民的出行体验。该系统结合多种大数据技术,对居民出行数据、交通状况数据、现有车辆信息、天气信息进行了综合分析。通过数据采集模块、数据处理模块、需求分析模块、线网规划模块等模块,为公交线路规划、车辆智能化调度、乘客信息服务提供科学依据。通过系统测试表明,该系统性能较佳,具有实际应用价值。
关键词:大数据;出行需求;城市公交
中图分类号:TP 391" " 文献标志码:A
基于大数据技术可以获取大范围、多源的城市交通信息,为城市交通管理提供丰富的数据资源。为了使城市交通智能化,充分利用数据并将其应用于城市交通,需要一个高效的系统来采集、处理、分析基础数据,并针对性地进行线网规划。本文将探究多源大数据视角下匹配居民出行需求的城市公交系统设计方法,搭建城市公交系统总架构。从而使城市公交系统能更好地适应不断变化的城市出行需求,并为城市居民提供更便捷、可持续和舒适的出行选择,推动城市交通领域的进步。
1 匹配居民出行需求的城市公交系统架构设计
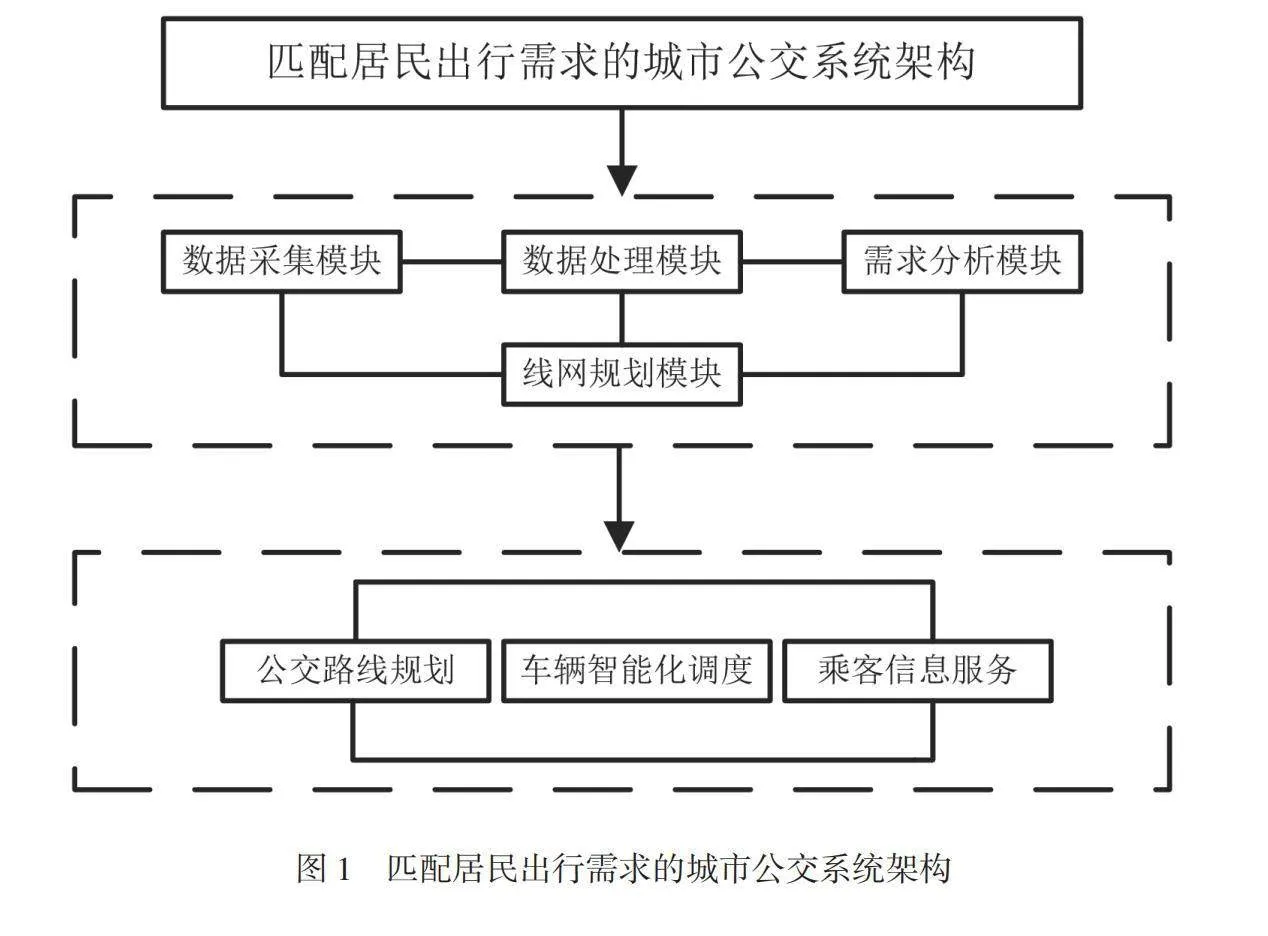
多源大数据视角下,匹配居民出行需求的城市公交系统主要包括数据采集模块、数据处理模块、需求分析模块和线网规划模块。匹配居民出行需求的城市公交系统架构,如图1所示。
该系统通过数据采集模块设计,获取了居民出行数据、交通状况数据、现有车辆信息、天气信息等和居民出行需求相关的数据。通过数据处理模块设计,对采集的数据进行处理和清洗,便于后续简洁、高效地进行需求分析和线网规划[1]。通过需求分析模块设计,对居民出行时间的高峰及低谷、热门出行区域、居民常用出行路径、用户偏好等需求信息进行分析。通过线网规划模块设计,实现城市公交线路的最优规划以及公交车辆运行的自动监控,同时为居民提供实时的公交信息,有效提高城市公共交通的服务水平。
2 系统各模块设计
2.1 数据采集模块
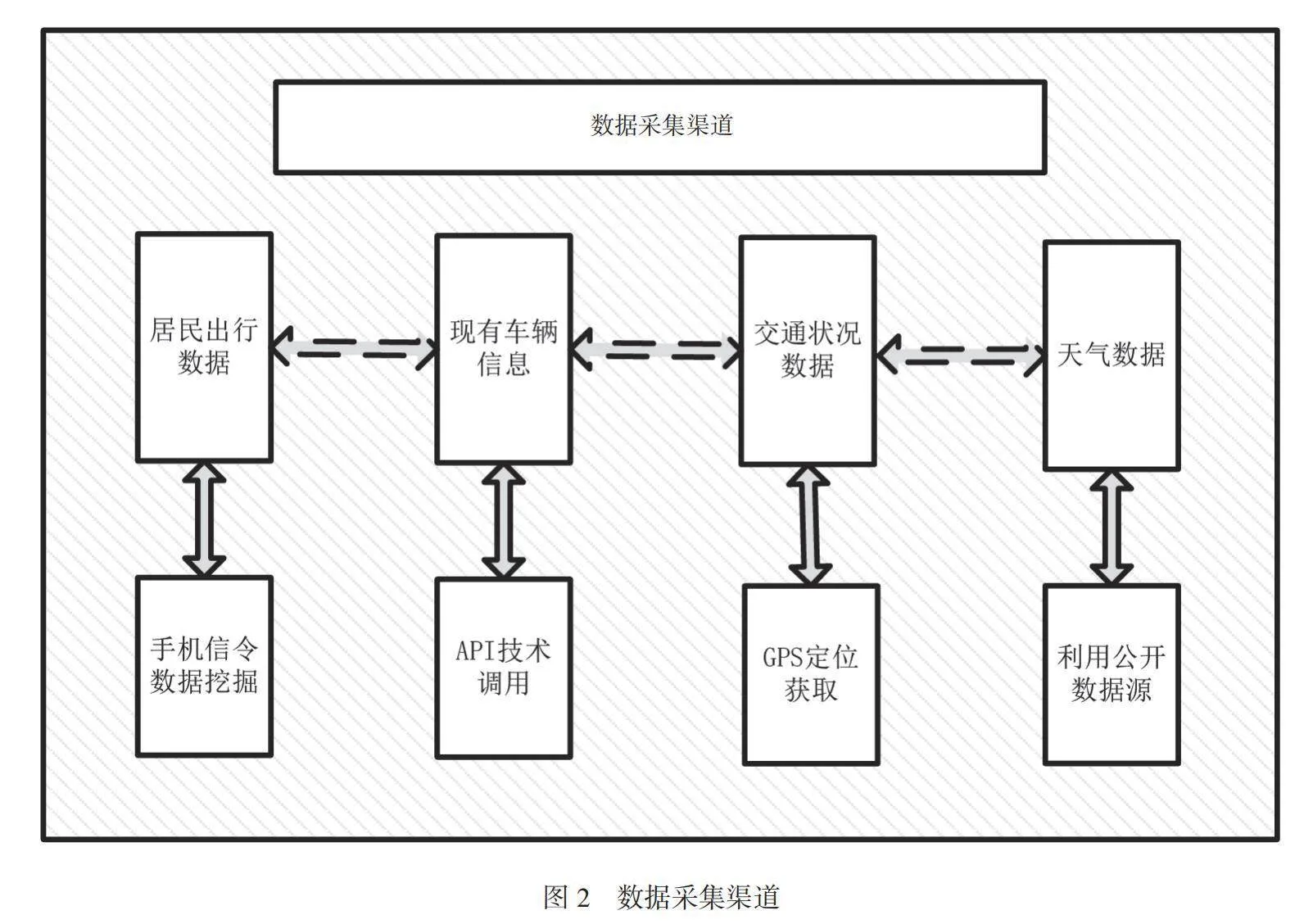
在数据采集模块的搭建过程中,收集与居民出行需求相关的数据,需要明确数据来源,例如居民出行数据(用户出行习惯、常用线路、上下车点等)、交通状况数据(实时交通流量、道路状况、拥堵情况等)、现有车辆信息(公交车辆位置、状态、运行情况等)和天气数据等。分渠道对多来源数据进行采集,如图2所示。
根据API接口的要求,使用Apache Kafka流式数据处理框架,设置数据输入管道,以接收来自不同数据源的实时数据流,并使用Kafka Connect连接不同的数据源和目标节点。配置轻量级的MQTT数据传输协议,用于多个数据源同时传输给多个数据接收端,通过TLS/SSL加密保护数据在传输过程中的机密性,确保数据可以安全地传输到中央系统。在采集节点上设置QoS容错机制,并允许消息重新传输(直到确认接收),以应对网络中断或采集节点故障。使用AWS Elastic Load Balancer负载均衡器,以均衡数据流量并将请求分发给多个采集节点。使用Amazon SQS消息队列系统,作为数据缓冲和分发层,根据负载自动增加或减少采集节点。当数据流量增加时,系统自动启动新的采集节点以处理更多数据,从而提高系统的可用性,减少管理系统资源的复杂性。
2.2 数据处理模块
数据处理是城市公交系统的重要子模块,可对采集的数据进行处理和清洗,其设计确保数据的质量、一致性和可用性,便于后续模块使用。使用Pandas数据处理库,加载采集的原始GPS定位数据,将数据转化为DataFrame格式[2]。通过设定阈值来识别和处理异常值,利用Z-Score方法计算每个GPS坐标的偏差程度,如公式(1)所示。
Z=(X-μ)/σ (1)
式中:Z为统计量,用于衡量数据点相对数据集均值的偏离程度;X为数据点的数值;μ为数据集的均值;σ为数据集的标准差。将偏差超过2标准差的数据标记为异常值,对异常值进行删除或填充操作。使用多元线性回归插补进行缺失值处理,将完整的观测数据作为自变量,而待插补的变量作为因变量,计算过程如公式(2)所示。
Yi=β0+β1x1+β2x2+…+βpxp+εi (2)
式中:Yi为缺失值,即需要插补的变量;x1,x2,…,xp为其他已知特征,用作自变量;β0,β1,β2,…,βp为回归系数,即每个自变量对Yi的影响;εi 为误差项。多次重复迭代,最终整合多次估算的结果,以获得更准确的插补值,为后续的数据分析提供高质量的数据基础。根据分析需求选择和提取与公交系统性能和需求相关的特征,例如载客量、车辆状态、拥堵情况、线路信息、乘客流量等,将需求特征缩放到[0,1],计算过程如公式(3)所示。
(3)
式中:为归一化后的需求特征值;y为原始需求特征值;ymin为需求特征最小值;ymax为需求特征最大值。通过归一化处理,更好地处理特征间的差异,确保不同特征具有相似的尺度和格式。使用Apache Kafka实时捕捉和处理数据流,确保数据的准确性与即时性。将整合后的数据导入MySQL数据库,并建立索引结构,以便于数据管理和访问,为后续的需求分析模块提供高质量的数据基础。
2.3 需求分析模块
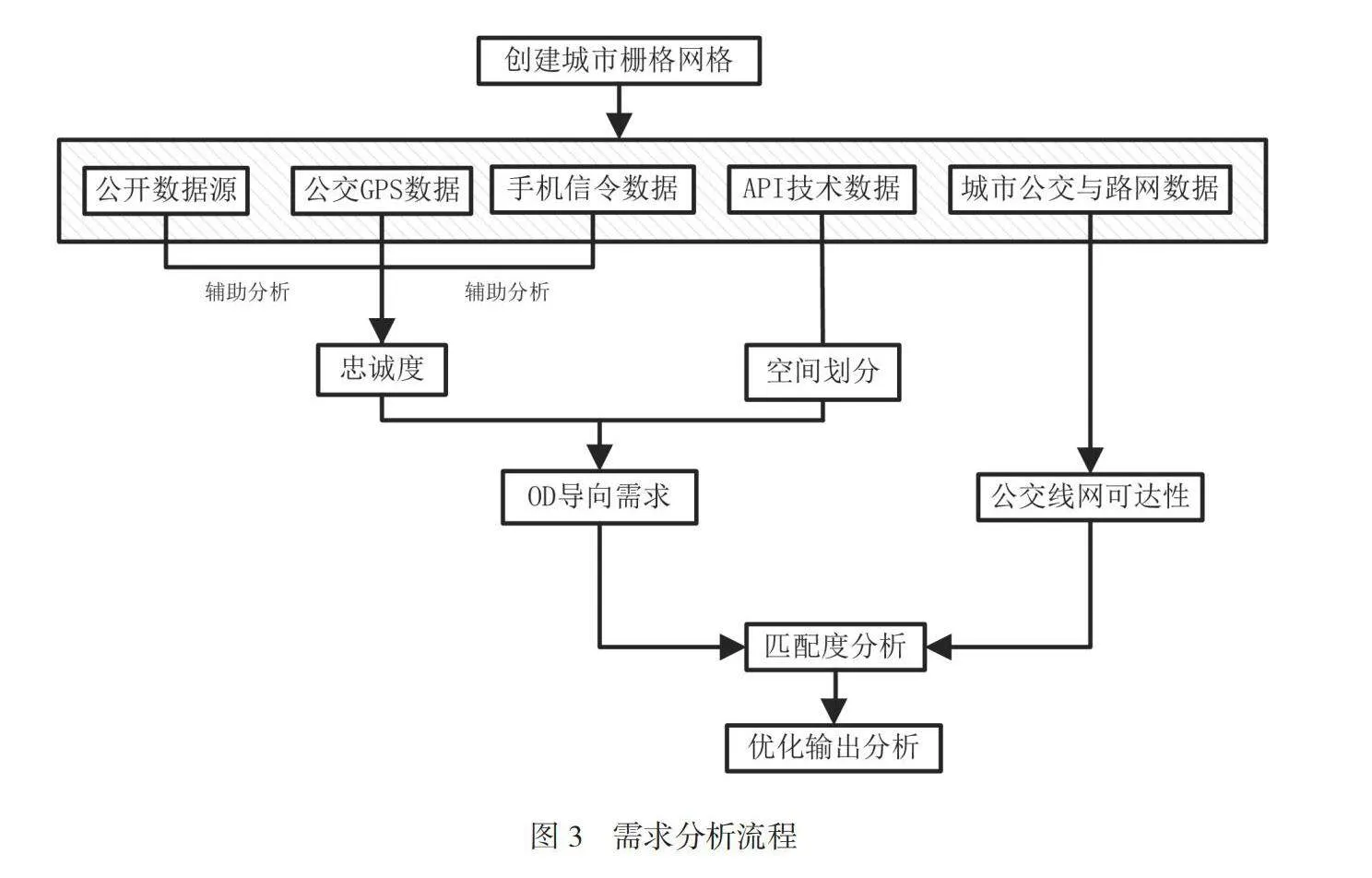
为提高需求分析的精细度,使用ArcGIS创建城市栅格网格,每个栅格单元的边长为500m,并依照不同的行和列,为每个栅格单元分配唯一的编码。通过ArcGIS的空间叠加工具,对出行需求数据中的起点和目的地坐标与栅格单元进行空间叠加,以便统计每个栅格单元内的OD需求数量,即起点和目的地都在同一个栅格内的需求[3]。调用居民移动轨迹数据,对每个居民个体在工作时间段和休息时间段内的活跃度进行分析,将阈值比例设定为0.7,若工作活跃比例>70%,则将该栅格定义为工作空间。反之,则将该栅格定义为居住空间。需求分析的具体流程,如图3所示。
为精确地获取出行需求,使用公开数据源(天气、节假日安排等数据)与手机信令(早高峰和晚高峰时段)进行辅助论证,实时描绘城市居民的出行变化活动,以获得城市居民的OD导向需求。利用Pearson相关系数计算,与公交GPS数据进行耦合性分析,如公式(4)所示。
(4)
式中:R为两个变量间的线性关系程度;mi、gi分别为两个变量的数据点;m、g分别为两个变量的均值。通过计算Pearson相关系数,评估两个变量间的线性相关性。如果R值接近1或-1,就表示变量间存在强烈的关联。如果R值接近0,就表示两个变量间关联较弱或没有线性关系。根据数据关联性分析,获取数据的高重合比例,以评估居民的通勤方式。叠加分析城市居民OD出行需求与公交线网可达性,判断不同栅格间的匹配情况,从而更准确地理解城市居民的出行需求,为公交系统的规划和优化提供有力支持。
2.4 线网规划模块
2.4.1 公交路线规划
在公交线路设计的过程中,利用GPS数据和地图信息构建城市路网模型,其中节点为交叉口或公交站点,边为道路,边的权重为距离、行驶时间或其他成本指标。根据需求分析模块的结果,确定起始点和终点,将其作为算法的输入。考虑交通拥堵、速度限制等实时信息,运用Dijkstra算法计算从起始点到终点的最优路径,计算过程如公式(5)所示。
Dv=min(Dv,Du+w(u,v)) " (5)
式中:Dv为从起始节点到节点v的当前最短距离;Du为从起始节点到节点u的当前最短距离;w(u,v)为从节点u到节点v的边的权重。重复迭代,根据算法的输出,确定经过点和站点位置,获取优化后的线路,以提供高效便利的出行服务。同时,使用地理信息系统(GIS)工具对地图数据进行处理,以辅助线路设计的可视化展示。当设计换乘点时,根据城市出行需求,调取城市GIS数据,将不同交通模式(公共交通、自行车、步行、共享出行等)整合在一起,以便居民能够方便地换乘不同的交通方式,减少等待和换乘时间。利用TransCAD交通模拟工具,对线路进行模拟和评估,计算过程如公式(6)所示。
Q=f(G,H,J,K,L,O) " (6)
式中:Q为线路的综合性能评分;G为等待时间,反映了乘客在车站等待公交车的时间;H为换乘时间,表示乘客在不同线路间的平均换乘时间;J为行程时间,包括等待时间、行驶时间和换乘时间;K为成本,包括运营成本、车辆成本等;L为能源消耗和排放,反映线路的环保程度;O为其他因素,例如乘客满意度、社会影响等。对多项指标进行综合评估,得到线路的综合性能评分Q,从而确保线路的有效性和效率。
2.4.2 车辆智能化调度
自动输入动态数据的分析结果,预测未来乘客集散的高低阶段、公交站点乘客量、车辆运行时长,运用粒子群算法自动生成相应的调度形式,分别计算粒子的位置和速度,如公式(7)、公式(8)所示。
Vi(t+1)=ω·Vi(t)+b1·c1·(Bi-Ni(t))+b2·c2·(Ai-Ni(t)) (7)
Ni(t+1)=Ni(t)+Vi(t+1) " (8)
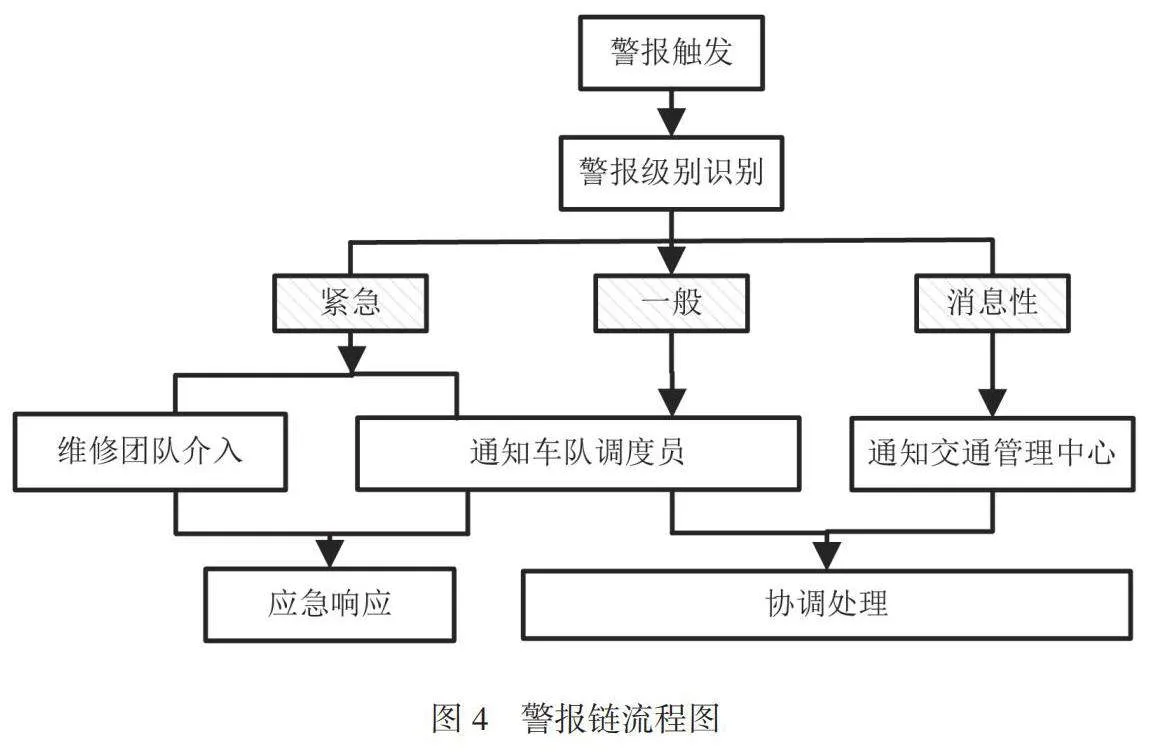
式中:Vi(t+1)为粒子i在下一代的速度;ω为惯性权重,控制了上一代速度对当前速度的影响;b1和b2为加速因子,分别为个体和社会影响的权重;c1和c2为[0,1]的随机数;Bi为粒子i历史上的最佳位置,即之前迭代中找到的最佳调度方案;Ai为整个粒子群中的最佳位置,即之前迭代中找到的最佳调度方案;Ni(t)为粒子i在当前代的位置;Ni(t+1)为粒子i在下一代的位置。通过不断迭代,更新粒子的位置和速度,获取使目标函数最小化的最佳调度方案,并自动生成优化的车辆发车时刻表。基于IoT实时数据,以1h作为时间间隔,调整车辆分配和发车间隔,将额外的车辆分配给高需求或拥挤线路,以更好地匹配乘客流量,减少居民等待时间和改善道路拥挤度。根据车辆故障反馈、未按计划到站、极端恶劣天气等不同情况的紧急性,设置不同的警报级别,分配警报级别为紧急警报、一般警报、信息性警报,将警报机制与监控系统集成,以实现自动触发。基于警报级别,建立明确的警报链,如图4所示。
当出现异常情况时,警报机制能够以高度敏感、精准的方式迅速响应,实时通知相关人员,以便及时采取必要的措施,以保障公共交通系统的安全性。通过建立自动化触发机制,可以有效减少人为操作错误,并显著提升应急响应速度。通过合理设置警报级别,优先处理最紧急的问题,从而最大程度地保证公共交通系统的正常运行。
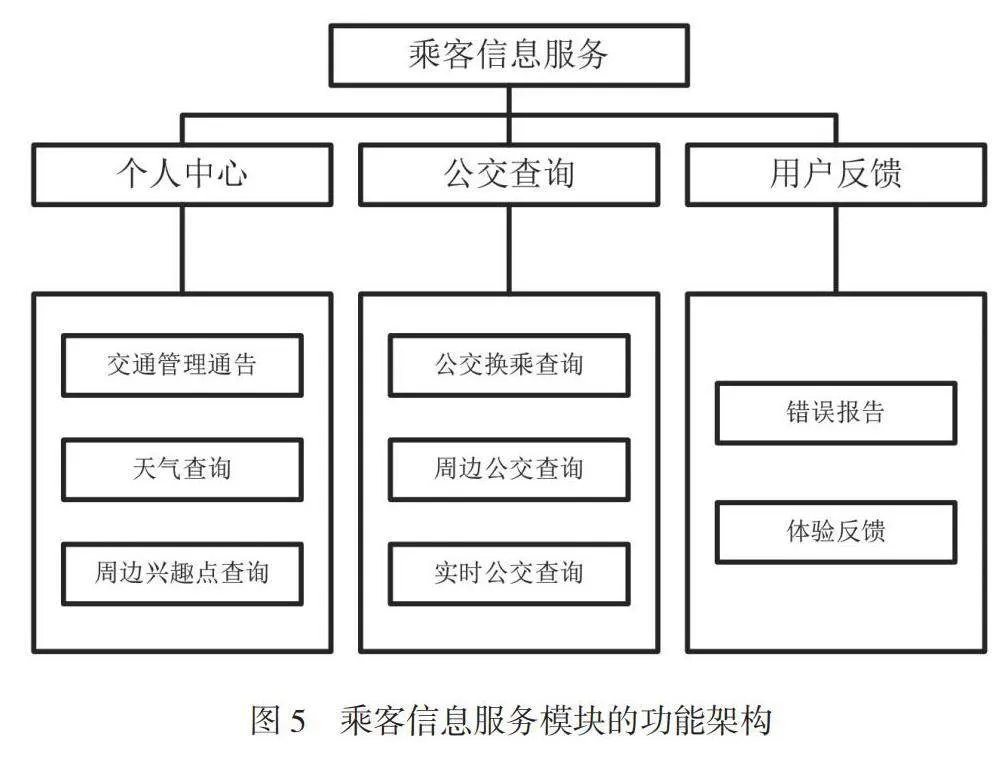
2.4.3 乘客信息服务
在乘客信息服务中,使用Bootstrap框架,并配置Webpack开发环境,创建项目文件和文件夹结构。使用HTML创建页面结构,包括标头、导航、主内容区域、侧边栏等,使用语义标签和元素来增强可访问性。编写CSS页面样式,包括布局、颜色、字体(支持多语言)、动画等,同时遵循响应式设计原则,以保证界面适应不同屏幕尺寸。使用JavaScript添加表单验证、按钮点击事件、动画效果等交互功能,确保用户界面及时响应用户操作。基于前端界面的基本框架设计,乘客信息服务模块的主要功能包括个人中心、公交查询、用户反馈等,其功能架构如图5所示。
通过个人中心(交通管理通告、天气查询、周边兴趣点查询、历史记录)、公交查询(公交换乘查询、周边公交查询、实时公交查询)、用户反馈(错误报告、体验反馈)等子模块的运行,使居民更便捷、清晰地获取有关交通、天气和公交的准确信息,从而提高居民的出行体验。
3 系统测试
3.1 测试准备
本系统使用Intel Core i9-12900K处理器,内存频率为DDR6-6000MT/s,主频为3.8GHz。配置1台Vmware 15 Pro虚拟机,应用Windows 10操作系统,操作系统为Ubuntu 22.04。测试数据集由多源数据构成,包括实时交通数据、用户出行历史数据、城市地理信息数据等,以模拟真实出行需求情况。在测试过程中,须确保虚拟机和外部网络间的连接稳定,以确保数据的实时传输和系统的正常运行。
3.2 测试结果
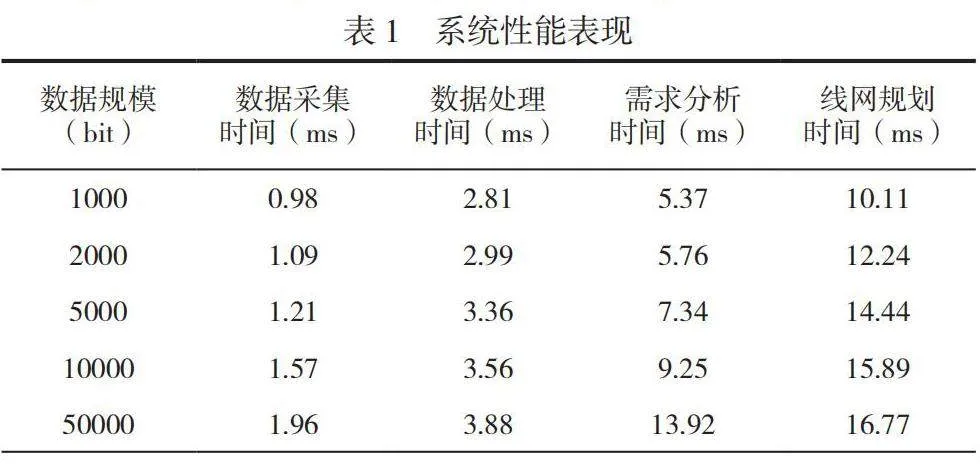
使用1000bit、2000bit、5000bit、10000bit和50000bit等5组不同大小的数据集,测试该系统的大批量数据处理能力,系统性能表现见表1。
由表1可知,在不同规模的数据条件下,该系统的数据采集时间、数据处理时间、需求分析时间和线网规划时间较短,在不同模块的运行过程中均表现较佳。测试结果显示,匹配居民出行需求的城市公交系统具有较高的性能,能够有效提高居民出行体验和城市公共交通的服务水平。
4 结语
通过充分利用多来源的大数据,能够更好地分析和满足城市居民的出行需求,有针对性地优化公交线路规划,提高公交车辆的调度效率,并进行个性化的出行服务设计,从而为城市居民提供更便捷、高效的公共交通系统。通过测试,该系统具备较高的可靠性,在实际应用中能为城市公交领域的改进与优化工作提供支持,具有较为广泛的应用前景。在未来,相关技术人员须进一步改进大数据分析模块的技术流程,使城市公交系统更贴近居民的实际需求。
参考文献
[1]张震,孔令涛,郭向海,等.智能公交系统的大数据平台信息资源规划[J].河南科技,2023,42(5):26-31.
[2]何东,马晓辉,刘国印.大数据技术在智能公交系统的应用[J].智能建筑与智慧城市,2022(7):177-179.
[3]徐猛,刘涛,钟绍鹏,等.城市智慧公交研究综述与展望[J].交通运输系统工程与信息,2022,22(2):91-108.
猜你喜欢
汽车工程学报(2017年2期)2017-07-05 08:13:03
新闻世界(2016年10期)2016-10-11 20:13:53
科技视界(2016年20期)2016-09-29 10:53:22
中国记者(2016年6期)2016-08-26 12:36:20
网络空间安全(2016年3期)2016-06-15 20:27:07
汽车维护与修理(2015年2期)2015-02-28 12:15:54
汽车零部件(2014年8期)2014-12-28 08:18:24
河南科技(2014年22期)2014-02-27 14:18:21
城市道桥与防洪(2014年5期)2014-02-27 07:26:12
