
基于BERT模型的网站敏感信息识别及其变体还原技术研究
2024-11-30 00:00:00符泽凡姚竟发滕桂法
现代电子技术 2024年23期





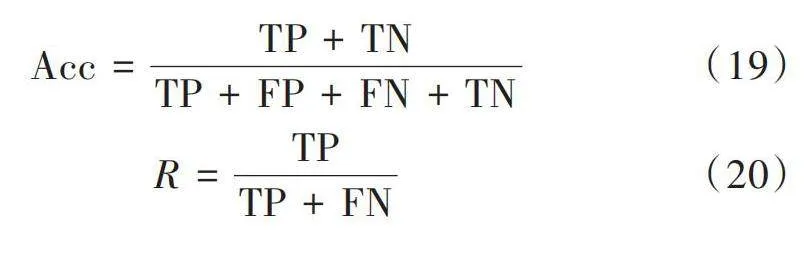


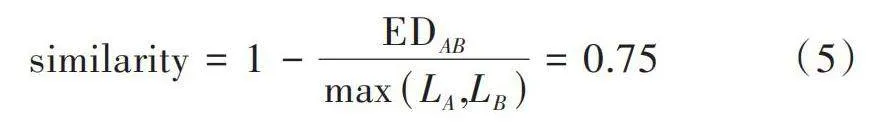







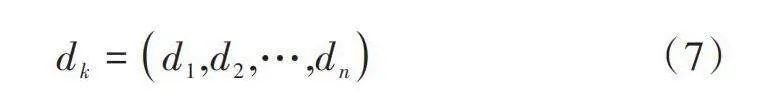






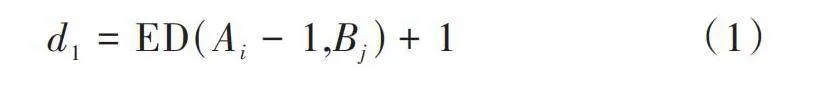



摘" 要: 针对各类网站为了避免被检测到敏感信息,网站内的文字常采用变体词对敏感词词库进行规避。为解决这一问题,文中提出一种基于BERT模型结合变体字还原算法的网站敏感信息识别的方法。该方法将针对文本中的变体词进行还原,通过采用BERT模型对文本内容进行向量化,并将其输入由BiLSTM层和CNN层构成的模型进行训练,从而实现对网站内敏感信息及其变体词的识别。实验结果显示,变体词还原的正确率较高,通过BERT模型获取的文本向量在文本分类任务中表现出色。与其他模型相比,BERT⁃BiLSTM⁃CNN模型在网站敏感信息识别任务中表现出更高的准确率、召回率和[F1]值,呈现明显的提升。文中模型为变体词还原问题和敏感信息识别领域提供了参考和支持,具有一定的实际应用价值。
关键词: 网站; 敏感信息; 变体词; BERT; 双向长短期记忆网络; 卷积神经网络
中图分类号: TN711⁃34; TP391.1" " " " " " " " " 文献标识码: A" " " " " " " " " " "文章编号: 1004⁃373X(2024)23⁃0105⁃08
Research on website sensitive information identification and variant restoration technology based on BERT model
FU Zefan1, YAO Jingfa2, 3, TENG Guifa1, 4, 5
(1. College of Information Science and Technology, Hebei Agricultural University, Baoding 071001, China;
2. Software Engineering Department, Hebei Software Institute, Baoding 071000, China;
3. Hebei College Intelligent Interconnection Equipment and Multi⁃modal Big Data Application Technology Research and Development Center, Baoding 071000, China;
4. Hebei Digital Agriculture Industry Technology Research Institute, Shijiazhuang 050021, China;
5. Hebei Key Laboratory of Agricultural Big Data, Baoding 071001, China)
Abstract: In view of the rapid development of the network and the decreasing cost of website establishment, to avoid detection of sensitive information, variant words are frequently utilized within texts of various types of websites, so that the sensitive word databases can be evaded. Therefore, this study proposes a method for identifying website sensitive information based on a BERT (bidirectional encoder representation from transformers) model combined with a variant word restoration algorithm. In this method, the variant words within the texts are restored, the text content are vectorized by the BERT model and then inputted into a model composed of BiLSTM (bi⁃directional long short⁃term memory) layer and CNN (convolutional neural network) layer for training, so as to achieve the identification of sensitive information and its variant words within websites. Experimental results demonstrate a high accuracy in variant word restoration, and the text vectors obtained by the BERT model exhibit excellent performance in the tasks of text classification. In comparison with the other models, the BERT⁃BiLSTM⁃CNN model demonstrates higher accuracy rate, recall rate, and [F1] score in the task of identifying sensitive information on websites, which indicates a significant improvement. The proposed model provides reference and support for variant word restoration and the field of sensitive information identification, possessing a certain practical application value.
Keywords: website; sensitive information; variant word; BERT; BiLSTM; CNN
0" 引" 言
随着网络和经济的发展,互联网用户的增多,个人网站的创建成本大幅降低,网站数量日益增长。我国发布的《中华人民共和国网络安全法》对保护隐私信息、追查敏感信息及维护国家信息安全等方面提出了严格要求。为更准确、高效地识别网络敏感信息,研究者们进行了大量研究,提出了多种方法,包括基于敏感词匹配的网络敏感信息识别、基于传统机器学习的网络敏感信息识别和基于深度学习的网络敏感信息识别[1]。这些研究提供了主要的思路和方向,为当前的网络信息安全和网站内容管理等领域提供了理论依据,对于网站内可能存在的敏感信息的识别提供了技术支持。
另一方面,网站内的内容书写相较于正式的板书更为随意,其中会掺杂着大量的网络用语,对于变体字的使用也较为频繁。为了避免和躲避网络监管的审查和检测,部分网站内的文本内容会采用大量的变体字进行规避,通过变体字躲避网络监管的敏感词词库的检测。而中文汉字的多变性和谐音也阻碍了更好地检测出网站内可能存在的敏感信息。对于变体字的还原和识别成为敏感信息识别和检测的重要课题之一。
以上问题的出现有碍于对网站内容的管理和敏感信息的识别检测。针对这些问题,本文引入变体词还原算法对变体词进行还原,并且通过构建BERT⁃BiLSTM⁃CNN语言模型对网站内可能存在的敏感信息识别任务进行训练,主要工作如下。
1) 对变体词进行识别和还原:由于变体词形式较为多变,如拼音、缩写、添词、删词等形式均在当今互联网网站中以组合的形式出现,这使得敏感词词库难以通过简单的匹配检测出文本中可能包含的敏感信息。因此,在对敏感信息进行检测和识别之前需要对变体词进行识别,将其还原为原来的词语,为后续的敏感信息检测工作提供语料。
2) 训练语言模型以识别变体字和敏感信息:通过采用BERT模型对文本内容进行向量化。BiLSTM用于捕获文本的上下文信息,CNN则可以通过使用不同尺寸的卷积核对待测文本的语义信息进行提取。实验结果表明,该模型在变体词和敏感信息的识别任务上对比其他模型表现更优。
1" 相关工作
当前对于互联网网站的敏感信息识别的主要研究方法大体可以分为以下三类。
1) 基于敏感信息匹配原则,通过构建敏感词词库和相应的词典,根据词典中对应的敏感词进行敏感信息的检测以及后续的分类识别。如文献[2]通过人工构建敏感信息词库的方式,根据敏感词在语料中的频率计算文本信息的敏感度,从而实现对互联网中存在的敏感信息的识别。此类方法依赖于敏感词库和词典的构建,同时整体算法的最终效果也与敏感词词库和词典的质量相关。需要消耗一定的人力和时间专注于敏感词词库的维护。此类方法在面对突发事件和专项行动任务时,对于新出现的个别敏感词无法进行精确的识别,从而导致时效性较差。
2) 基于传统的机器学习的敏感信息识别,通过特征提取的方式实现了对于敏感信息的识别检测。如文献[3]从敏感信息特征中提取出支持向量,对支持向量机进行训练,通过这种方法提高网络敏感信息识别的检测速度以及其准确性。文献[4]从舆情特征信息词中提取出包含的舆情敏感信息,研究舆情敏感信息与突发事件情景之间的关系,通过生成映射函数的方法提高网络敏感信息不同情景的分类效果。
3) 基于深度学习的敏感信息识别。在机器学习的基础上,通过引入深度学习算法和神经网络,以弥补机器学习在语义信息和语境判断方面的不足。如文献[5]使用深度学习的方法,对于舆情中含有敏感信息的部分进行识别和筛查,以发现网络中含有敏感信息的部分。文献[6]通过BERT模型方法和语义分析方法相结合,对新闻的风险水平进行评估,实现了网络新闻敏感信息识别和敏感程度计算。
在中文变体字研究方面,文献[7]通过分析汉字的结构和读音等特征,针对词的简称、拼音和拆分三种变体形式提出了一种中文敏感词变形体的识别方法。文献[8]则构建了概率模型,研究敏感词中的拼音、缩写等变形体的特征对变体词识别并且实现了变体词的还原。
2" BERT⁃BiLSTM⁃CNN模型构建
2.1" 模型设计
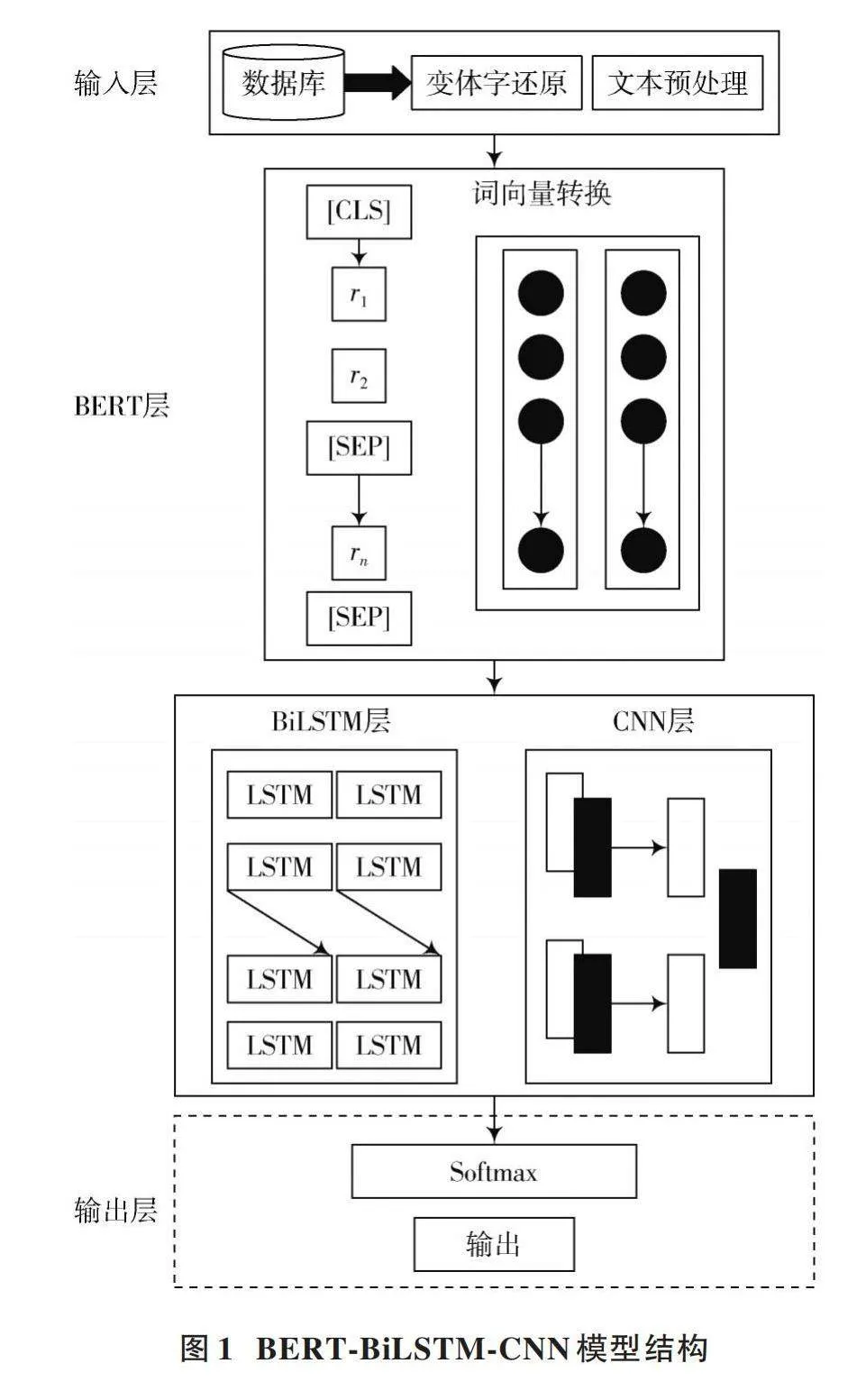
本文通过结合BERT模型和BiLSTM(双向长短期记忆)网络以及CNN(卷积神经网络)来构建BERT⁃BiLSTM⁃CNN模型。整个模型结构分为五个主要部分,分别是输入层、BERT层、BiLSTM层、CNN层以及最后的输出层。在输入层处输入待检测的网站文本内容,通过变体词的还原算法对需要检测的文本内容进行变体字的检测与还原,将含有变体词的文本转换成普通待检测的文本。规定输入的文件格式为csv文件,并且字段与规定字段相匹配。通过BERT层对文本内容进行预处理,并且进行词向量转换。由BERT层进入BiLSTM层和CNN层后,对网站文本内容的深层语义特征进行提取,最后在文本输出部分输出文本内容检测结果。具体模型结构如图1所示。
2.2" 变体词还原算法
针对网站文本内容中可能出现的填词、少词、改词、拼音、缩写等变体形式,本文采用一种基于编辑距离(Edit Distance)的变体字相似度匹配算法。
首先根据匹配算法通过构建的敏感词词库在文本内容中检索出所有含敏感词的文本,将文本认定为敏感信息并不参与接下来的变体字还原工作。基于编辑距离的算法主要依靠与变体词和还原后的词之间的编辑距离进行相似度的判断。编辑距离本质是操作步数,当一个字符串转化为另一个字符串时需要通过一定的步数进行转换,编辑距离为所需的最少操作步数。例如原词的汉字排列为“我爱你”,进行变体后的变体词为“我你爱”。将“我爱你”替换为“我你爱”需要进行2次替换修改操作,则最小编辑距离[d]=2。替换过程如图2所示。
在针对不同的变体形式中,编辑距离的计算公式也有所不同。假设有两个字符串[A]和[B],其句子长度分别为[LA]和[LB] ,则计算公式如下:
当进行增加操作时:
[d1=ED(Ai-1,Bj)+1] (1)
当进行删除操作时:
[d2=ED(Ai,Bj-1)+1] (2)
当进行修改操作,常出现使用拼音或缩写进行替换,出现拼音缩写的变体字分为部分为缩写、全部为缩写、部分由拼音组成、全部由拼音组成等四种情况[9],例如词语“六合彩”的拼音缩写可能是:LHC、6合彩、liu合彩、liuhecai等情况,此时编辑距离的计算公式为:
[d3=ED(Ai-1,Bj-1)," " "Ai=BjED(Ai-1,Bj-1)+1," " "Ai≠Bj] (3)
若同时存在多种状态,则取上述三种状态中的最小值作为最小编辑距离。因此,可以得到一个状态转换方程:
[EDAiBj=max(LA,LB)," " LA=0LB=0minED(Ai-1,Bj)+1,ED(Ai,Bj-1)+1,ED(Ai-1,Bj-1)," nbsp; "Ai=BjED(Ai-1,Bj-1)+1," " "Ai≠Bj] (4)
得到最小编辑距离后,通过最小编辑距离计算两个句子或是词语之间的相似度,当相似度达到一定阈值时,判断为存在变体词并且通过敏感词词库内的敏感词对其进行还原操作。
例如存在句子[A]为“今天气温适宜,适合去打球,也适合旅游。”;存在句子[B]为“今天气温正常,适合去玩,也适合去旅游。”则它们的最小编辑距离为[d]=5。由此可以计算其相似度,计算公式如下:
[similarity=1-EDABmax(LA,LB)=0.75] (5)
两个句子具有75%的相似程度,因此可以判断两个句子类似为同一句话,其表达的意思相同。变体词同理,通过计算变体词和敏感词词库中的词的最小编辑距离,可以获得变体词和敏感词之间的相似度,当相似度大于75%时,可以判断该变体词的还原形式为敏感词词库中的敏感词,则包含有该变体词的文本信息判断为敏感信息。75%的阈值可以随实际情况而调整,例如当遇到长句时,可以适当下调相似度阈值,放在错漏潜在的包含敏感信息的句子中。
2.3" BERT预训练模型
中文文本处理与英文有所不同,中文需要考虑到词和字的区别。在自然语言处理的语言模型里,BERT系列语言模型效果表现良好。相较于OpenAI的GPT与ELMo这两个较为主流的语言模型, BERT采用双向Transformer作为编码器[10]。BERT系列语言模型包含有根据任务的大小提供可以选择的base和large版本,对应参数如表1所示。
BERT模型主要分为两个阶段:用于使用无标签数据进行训练的预训练阶段(pre⁃training)和用于增加输出层后的微调阶段(fine⁃tuning)。在预训练阶段进行预训练任务时,会调用模型内的多个Encoder结构,由多个Encoder堆叠而成从而实现预训练任务,如图3所示。
BERT预训练模型的主要部分为双向Transformer编码器,主要核心技术和思想为自注意力机制。其思想是计算一句话中每一词与所有词的相互关系,并利用相互关系调整每个词的权重来获得新的表达,表示在词本身语义的基础上还包含与其他词的关系,可以实现一词多义的区分[11]。
对于每个注意力头,计算公式为:
[Attention(Q,K,V)=SoftmaxQKTdkV] (6)
式中:[Q]为查询矩阵;[K]为键矩阵;[V]为值矩阵。键矩阵[K]中的每一个向量维度都是以[dk]来表示:
[dk=d1,d2,…,dn] (7)
由于在词向量转化过程中,为防止在最终实验计算过程中词向量维度过高导致词向量维度膨胀带来的计算问题,公式中对词向量维度进行开平方的计算操作。这样做的目的是使Softmax归一化指数函数的结果更加稳定,以便接下来在梯度反向传播过程中模型能够更加容易地获取平衡的梯度[12]。
BERT模型具有两个预训练任务,分别为掩码语言模型(Masked Language Model, MLM)任务和NSP任务,通过这两个任务完成对于文本内容特征的学习。其中,MLM是BERT及其变体中最重要的预训练任务,它模拟了双向上下文推理能力[13]。
在MLM学习方法中,80%采用[mask]token标记,10%采用随机选取一个词来代替[mask]token,10%保持不变,即用句子中的原始token,如表2所示。
2.4" BiLSTM层
长短期记忆(LSTM)网络由Hochreiter于1997年首次提出。与RNN相比,LSTM增加了一个“门”结构,可以控制信息的丢弃或添加,以控制信息的遗忘和记忆[14]。LSTM网络结构控制信息的传递主要依托于遗忘门(forget gate)、输入门(input gate)和输出门(output gate)。
通过[t]-1时刻内的hidden state [ht-1]来计算遗忘门[ft],输出门[it],输入门[ot]的结果,计算公式如下所示:
[ft=σ(wfxt+ufht-1+bf)] (8)
[it=σ(wixt+uiht-1+bi)] (9)
[ot=σ(woxt+uoht-1+bo)] (10)
通过[t]-1时刻内的hidden state [ht-1]来计算候选值[ct]和[ct]的值,计算公式如下所示:
[ct=tanh(wcxt+ucht-1+bc)] (11)
[ct=ft⋅ct-1+it⋅ct] (12)
最终根据输出门[ot]和[ct]计算外部状态[ht]。
[ht=ot⋅tanh(ct)] (13)
本文采用的LSTM在前后两个方向上提取更多的特征。前向和后向LSTM接收前一层的输出,并分别从左到右和从右到左进行处理[15],计算公式如下所示:
[LLSTM=LSTM(wiEi)," " i∈[0,t]] (14)
[LLSTM=LSTM(wiEi)," " i∈[t,0]] (15)
最终双向LSTM模块连接起来,整个LSTM模块接收BERT模块处理后的向量化输入,将文本中的正向和逆向语句的序列状态信息输出至下一个模块。BiLSTM层结构如图4所示。
在前向的LSTML输入文本后,将会按照文本内容依次得到向量{[hL0],[hL1],[hL2],…,[hLn]},并且同样对后向的LSTMR依次输入文本,按照文本内容依次得到向量{[hR0],[hR1],[hR2],…,[hRn]}。通过这种方式就可以得到前后双向的长短期记忆网络所提供的向量,最后将前向和后向的向量进行拼接,得到[n]×2的向量矩阵:{[[hL0,hRn]],[[hL1,hRn-1]],[[hL2,hRn-2]],…,[[hLn,hR0]]}。由于前后向量的方向相反,所以前向LSTM的第一个向量即[L0]对应着后向LSTM的第[n]个向量即[Rn],其他向量以此类推。最终得到向量组[{h0,h1,h2,…,hn}]。
最终输出结果为如下公式所示:
[LLSTM=[LLSTM,LLSTM]] (16)
2.5" CNN层
在文本处理中,对句子做分词处理,得到词向量数据,然后将词向量数据输入到CNN的卷积层,使用卷积核对其做卷积操作,得到新的特征矩阵[16]。卷积核在向量矩阵[T]中通过上下滑动的方式进行特征的提取,利用不同大小的卷积核的向量矩阵滑动进行卷积。卷积层是CNN的主要构建块,该层通过将数据与[N]个随机生成的过滤器进行卷积来计算语义向量上的卷积函数[17],从而形成维度大小为[(n-h+1)×1]的特征矩阵,计算公式如下所示:
[c=[c1,c2,…,cn-h+1]] (17)
卷积层文本特征表示公式如下所示:
[ci=f(Wi⋅T+b)] (18)
CNN层的输入层接受来自BiLSTM层的上下文语义信息对特征词进行判断。模型选用了有别于传统卷积在图像处理中所使用的二维卷积,而是选择更适合处理文本序列的一维卷积作为模型的卷积核[18]。经过卷积层[a]后,数据经过最大池化层处理,然后进入卷积层[b]进行高维特征学习。在二次卷积层处理后,增加平均池化层,使模型更平滑,防止过拟合现象。最终输出的CNN层结构如图5所示。
CNN层处理特征词步骤如下。
1) 获取上一层即BiLSTM层的信息,其中每条数据具有相同的维度(256,128)。
2) 将数据输入到一维卷积层[a]中进行处理。其中的卷积核大小为3、维度为64。
3) 生成的向量进入大小为3的最大池化层进行处理,最终将向量压缩为(84,64)。
4) 接入到一维卷积层[b]中学习高维特征。其中的卷积核大小为3,由于要进行高维特征学习,其维度上升为128。
5) 通过平均池化层将数据拉长变为一维的数组形式。
6) 最终使用Sigmoid为激活函数在全连接层生成判定值。通过该值判断特征词属于何种类型,从而进行文本分类。
3" 实验分析
3.1" 实验环境与设置
本实验采用同一套设备和同一数据集,对不同的模型进行训练后,进行对照实验从而判断效果最佳的模型。实验所用设备的软件和硬件的版本以及具体型号如表3所示。
本实验基于PyTorch框架,并且选择了使用CUDA进行GPU加速模型的训练。实验中所需要的环境配置以及版本号如表4所示。
在训练过程中,模型采取统一参数。经过测试,在相同参数的情况下各个模型的训练时间大约都控制在30 min。参数配置为:词向量维度为768,batch_size为128,PAD_size为32,epochs次数为3次,学习率为5×10-5。本文实验中使用到的数据集数量较多,故上调了batch大小和学习率,并且当连续训练超过1 000个batch后模型效果仍未提升,则会提前终止训练,以减少资源和时间的浪费。同时,认定此时的模型参数已达到最佳状态。表5为模型的详细参数设置。
3.2" 数据收集与处理
本文所涉及的实验数据并非来自第三方的公开数据集,而是由个人及团队有针对性地收集和处理的。研究与河北省保定市国家互联网信息办公室进行合作,数据收集对象为河北省保定市及其下属县级市区域内的网站。通过由河北省保定市互联网信息办公室提供的名单,使用网络爬虫针对保定市区域内的互联网网站进行文本信息的爬取。网络爬虫所使用的框架为Scrapy框架。Scrapy架构由引擎、调度器、下载器、数据分析与数据管道五方面构成[19]。在爬取策略方面选择广度优先,优先遍历网站内的全部子页面。
在数据收集的过程中,采用网络爬虫方式,共爬取10 370家网站,其中政府类型的网站为27家。
在与保定市互联网信息办公室沟通合作后,由保定市互联网信息办公室提供敏感词列表,基于国家对网络信息安全风险防控与治理的主要焦点问题,结合《中华人民共和国网络安全法》《网络信息内容生态治理规定》和《互联网信息服务管理办法》的相关内容[20]进行单独敏感词词库的构建。
敏感词列表内的敏感词进行了敏感词类型分类,并且对每一个敏感词类型都添加了相对应的标签,最后统计每个敏感词类型内所含敏感词的数量。敏感词词库信息如表6所示。
在文本预处理阶段,首先需要对语料文本进行分词处理。将收集到的原始文本内容进行分词处理后,使用基于匹配原则的方法识别出文本内包含有上述敏感词词库内的敏感词文本,并且通过查找敏感词对应的标签找到其对应的敏感词类型。
在中文文本环境下的分词领域内,jieba(结巴)分词的分词效果较为优秀,并且可以提供多种不同的分词模式以适配所需要的分词效果。分词模式选择全模式分词,可以做到尽可能地将全部的词切分出来。在分词过程中,如果文本中包含有自定义词典内的词,则认为该文本包含有所需识别的敏感词。
数据集内的文本格式为[label,text],如:[7,开云体育竞技]。将全部数据集以6∶2∶2的比例分配为训练集(Train)、测试集(Test)和验证集(Val),最终获得数据集信息如表7所示。
3.3" 实验结果与分析
实验选择准确率、召回率以及[F1]数值作为评判标准,其计算公式分别如下所示:
[Acc=TP+TNTP+FP+FN+TN] (19)
[R=TPTP+FN] (20)
[F1=2TP2TP+FP+FN] (21)
式中:TP(True Positive)和FN(False Negative)为在正样本的情况下被正确识别为正样本和被错误识别为负样本的情况;FP(False Positives)和TN(True Negative)为在负样本的情况下被错误识别为正样本和被正确识别为负样本的情况。
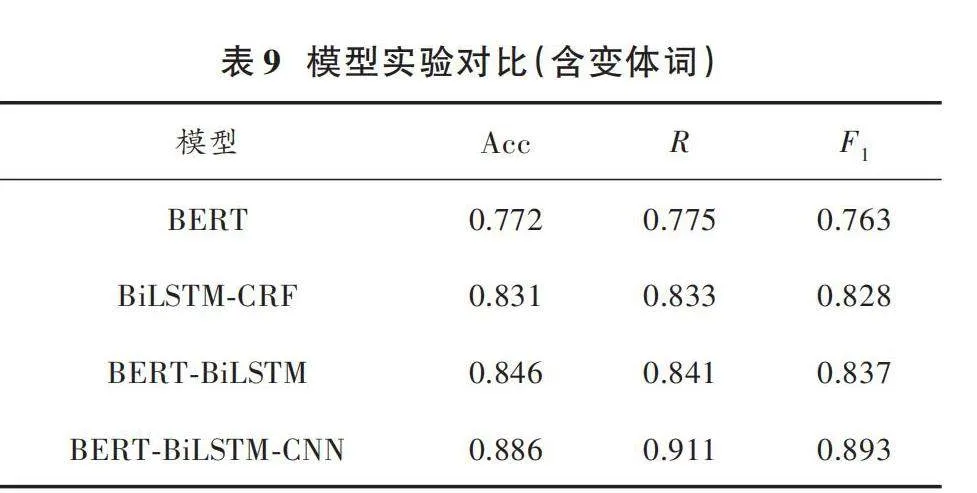
实验分为两组:不包含变体词组和包含变体词组,两组实验采用相同的实验环境和配置,以及相同的对照组模型。实验最终结果如表8、表9所示。
根据上述两组实验结果得出:在对于网站内的敏感信息(不含变体词)进行识别任务中,与其他模型相比,本文提出的基于BERT⁃BiLSTM⁃CNN模型在此类任务中表现得更为出色,其性能指标在数值上有明显提升。其准确率可以达到95%以上,召回率达到95%,[F1]值达到96%。在第二组实验中,考虑到变体词的干预,其他模型的准确率普遍下降,而本文采用的基于编辑距离的变体词还原算法准确率仍可达到88%以上,召回率达到91%,[F1]值达到89%。实验结果表明,BERT模型所获取的文本向量在任务中表现良好。而基于BERT⁃BiLSTM⁃CNN模型在网站文本敏感信息的检测和识别任务上的表现优于其他模型,准确率、召回率、[F1]值都有显著提升。当面对通过变体词隐藏敏感信息的情况时,本文方法仍能保持较高的准确率,有效解决了网站中可能存在的敏感信息及其变体形式的识别问题。
综上所述,本文提出的基于BERT⁃BiLSTM⁃CNN模型的网站文本敏感信息及其变体识别的方法能够更好地完成对网站内可能存在的敏感文本信息进行识别,并且可以较为优秀地针对敏感信息可能出现的变体形式进行还原。对当前日益增多的网站内可能存在的敏感信息和对其变体形式识别困难的问题提供了较为有效的解决方法。
4" 结" 语
本文从当前网络中日益增多的网站数量导致网站内文本内容频繁出现敏感信息的问题出发,着重分析和研究了有关区域内网站上的文本内容中敏感信息部分的相关检测和分类技术,提出了一种基于BERT模型的网站敏感信息识别及变体还原方法。通过变体词还原算法将变体词进行还原后,使用深度学习的方法,将BERT语言模型与双向长短期记忆神经网络和卷积神经网络结合,充分发挥各网络模型的优势。目前在针对互联网网站内存在的敏感信息识别任务中,不单局限于使用一种单一模型来解决问题,例如多任务学习与CNN网络结合[21]、使用TF⁃IDF改进聚类算法 [22]等多种模型和算法融合的方法来解决问题,其融合实验结果相较于单一模型有明显提升。多模型融合也会是未来将要着重研究的方向。
在日后的工作和研究中,敏感词词库仍然有待优化和提升。针对更多形式的变体词,如拆字、谐音词、生僻字或是带有emoji的词组等形式的变体词需要更多的还原方法。
注:本文通讯作者为姚竟发。
参考文献
[1] 吴树芳,杨强,侯晓舟,等.基于SSI⁃GuidedLDA模型的引导式网络敏感信息识别研究[J].情报杂志,2023,42(11):119⁃125.
[2] 杜智涛,谢新洲.利用灰色预测与模式识别方法构建网络舆情预测与预警模型[J].图书情报工作,2013,57(15):27⁃33.
[3] LI W P, WU H Y, YANG J. Intelligent recognition algorithm for social network sensitive information based on classification technology [J]. Discrete and continuous dynamical systems⁃S, 2019, 12(4/5): 1385⁃1398.
[4] 陈祖琴,蒋勋,葛继科.基于网络舆情敏感信息的突发事件情景分析[J].现代情报,2021,41(5):25⁃32.
[5] 邓磊,孙培洋.基于深度学习的网络舆情监测系统研究[J].电子科技,2022,35(12):97⁃102.
[6] 李瀛,王冠楠.网络新闻敏感信息识别与风险分级方法研究[J].情报理论与实践,2022,45(4):105⁃112.
[7] 付聪,余敦辉,张灵莉.面向中文敏感词变形体的识别方法研究[J].计算机应用研究,2019,36(4):988⁃991.
[8] WANG A B, KAN M Y. Mining informal language from Chinese microtext: Joint word recognition and segmentation [C]// Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACL, 2013: 731⁃741.
[9] 路松峰,郑召作,周军龙,等.融合变体字还原和语义分析的敏感信息检测[J].湖北大学学报(自然科学版),2023,45(6):879⁃887.
[10] WANG Z N, JIANG M, GAO J L, et al. Chinese named entity recognition method based on BERT [J]. Computer science, 2019, 46(S2): 138⁃142.
[11] LI Y C, QIAN L F, MA J. Early detection of micro blog rumors based on BERT⁃RCNN model [J]. Information studies: Theory amp; application, 2021, 44(7): 173⁃177.
[12] 綦方中,田宇阳.基于BERT和LDA模型的酒店评论文本挖掘[J].计算机应用与软件,2023,40(7):71⁃76.
[13] CUI Y M, CHE W X, LIU T. Pre⁃training with whole word masking for Chinese BERT [C]// IEEE/ACM Transactions on Audio, Speech, and Language Processing. New York: IEEE, 2021: 3504⁃3514.
[14] LI X Y, RAGA R C. BiLSTM model with attention mechanism for sentiment classification on Chinese mixed text comments [J]. IEEE access, 2023, 11: 26199⁃26210.
[15] KAUR K, KAUR P. BERT⁃RCNN: An automatic classification of APP reviews using transfer learning based RCNN deep model [EB/OL]. [2023⁃01⁃24]. https://doi.org/10.21203/rs.3.rs⁃2503700/v1.
[16] 胡任远,刘建华,卜冠南,等.融合BERT的多层次语义协同模型情感分析研究[J].计算机工程与应用,2021,57(13):176⁃184.
[17] KAUR K, KAUR P. BERT⁃CNN: Improving BERT for requirements classification using CNN [J]. Procedia computer science, 2023, 218: 2604⁃2611.
[18] 江魁,余志航,陈小雷,等.基于BERT⁃CNN的Webshell流量检测系统设计与实现[J].计算机应用,2023,43(z1):126⁃132.
[19] 刘多林,吕苗.Scrapy框架下分布式网络爬虫数据采集算法仿真[J].计算机仿真,2023,40(6):504⁃508.
[20] 李洁,周毅.网络信息内容生态安全风险:内涵、类型、成因与影响研究[J].图书情报工作,2022,66(5):4⁃12.
[21] 孟旭阳,徐雅斌.社交网络中的敏感内容检测方法研究[J].现代电子技术,2019,42(15):72⁃78.
[22] 孟彩霞,陈红玉.基于TF⁃IDF改进聚类算法的网络敏感信息挖掘[J].现代电子技术,2015,38(24):44⁃46.
作者简介:符泽凡(2000—),男,河北保定人,硕士研究生,研究方向为自然语言处理。
姚竟发(1983—),男,河北衡水人,博士研究生,讲师,硕士生导师,研究方向为大数据与人工智能。
滕桂法(1963—),男,河北衡水人,博士研究生,教授,博士生导师,主要从事人工智能应用技术研究。
猜你喜欢
科技创新与应用(2016年35期)2017-02-21 19:16:50
计算机应用(2016年12期)2017-01-13 20:26:21
现代营销·学苑版(2016年10期)2016-12-12 14:39:33
职工法律天地·下半月(2016年9期)2016-11-30 10:55:28
科教导刊(2016年26期)2016-11-15 20:54:05
数字技术与应用(2016年9期)2016-11-09 23:30:46
软件导刊(2016年9期)2016-11-07 22:20:49
文艺生活·下旬刊(2016年10期)2016-11-03 01:16:58
软件工程(2016年8期)2016-10-25 15:47:34
中国科技博览(2016年18期)2016-10-19 10:37:23
