
基于视觉惯性的动态环境下SLAM方法
2024-11-21 00:00:00赵建成王芳黄树成
江苏科技大学学报(自然科学版) 2024年5期
关键词:光流







摘" 要: 针对传统视觉惯性SLAM在动态环境下则会出现鲁棒性差的问题,提出一种可用于室内的动态环境的视觉惯性SLAM方法.结合室内动态物体的特点,提出了一种基于先验假设的语义信息方法,利用Mask R-CNN现实潜在动态对象识别.为解决语义分割网络短时间内分割图片有限的问题,融合光流估计对未分割图像进行分割预测.最后,通过动态特征点过滤算法实现动态特征点与静态特征点的分离.在基于OpenLORIS数据集进行实验表明,该方法在高动态环境下能够有效提高SLAM系统的定位精度及鲁棒性.
关键词: 视觉惯性;Mask R-CNN;语义分割;光流
中图分类号:TP391""" 文献标志码:A""""" 文章编号:1673-4807(2024)05-051-06
DOI:10.20061/j.issn.1673-4807.2024.05.008
收稿日期: 2023-06-27""" 修回日期: 2021-04-29
基金项目: 国家自然科学基金项目(62276118)
作者简介: 赵建成(1997-),男,硕士研究生
*通信作者: 王芳(1971-),女,副教授,研究方向为自然语言处理.E-mail:huashan3010@163.com
引文格式: 赵建成,王芳,黄树成.基于视觉惯性的动态环境下SLAM方法[J].江苏科技大学学报(自然科学版),202 38(5):51-56.DOI:10.20061/j.issn.1673-4807.2024.05.008.
SLAM method in dynamic environment based on visual inertia
ZHAO Jiancheng, WANG Fang*, HUANG Shucheng
(School of Computer, Jiangsu University of Science and Technology, Zhenjiang 212003, China)
Abstract:To address the problem that traditional vision-inertial SLAM relies on static environments and reduces robustness in dynamic environments, this paper proposes a visual-inertial SLAM method specifically designed for indoor dynamic environments. We introduce a semantic information approach based on a priori assumptions by considering the characteristics of indoor dynamic objects. First, a semantic information method based on a prior assumption is proposed to recognize realistic latent dynamic objects using Mask R-CNN by combining the features of indoor dynamic objects. Second, we incorporate optical flow estimation to predict segmented images to address the time-consuming segmentation problem in a semantic segmentation network and the resulting finite number of segmented images. Finally, dynamic and static features are separated by a dynamic feature filtering algorithm. Experiments on the open vision-inertial dataset OpenLORIS show that this approach can effectively improve the localization accuracy and robustness of SLAM systems in highly dynamic environments.
Key words:visual inertia, Mask R-CNN, semantic segmentation, optical flow
即时定位与建图(simultaneous localization and mapping,SLAM)是通过机器人自身的传感器来感知外部的环境以及自身所处的环境当中的位置,并且能够随着机器人的不断移动通过增量的形式来实现对地图的拼接.但是,当前SLAM系统大部分都是依赖于静态环境,而现实场景当中往往会遇到非静态的场景.这就给机器人的定位建图导航带来了极大的挑战.为了解决SLAM在动态场景中的问题,研究者采用的方法大致有两类:基于几何和基于语义[1].基于几何的方法不需要对图像中的潜在动态对象进行检验,因此具有较好的实现性,但在高动态场景下效果不佳.文献[2]提出了一种基于几何的解决方案,利用两张连续图像之间的IMU的旋转分量将特征分为动态和静态.文献[3]提出一种基于对极几何约束的解决方案,利用动态特征点运动时的投影特性来过滤动态特征点.基于语义分割的方法需要借助分割网络来获取语义信息,在高动态环境下效果较好,但实时性较差.文献[4]提出一种结合深度学习和对极几何约束的方法,用于检测动态目标及背景修补.文献[5]提出一种基于速度不变性的漏检补偿算法的Dynamic-SLAM框架,解决了在语义层面检测动态对象召回率低的问题.
综上所述,当前的SLAM研究主要集中于纯视觉SLAM,而纯视觉SLAM由于采用单一传感器,这导致其在复杂环境下存在鲁棒性较低的问题.此外,随着华为和英伟达等公司推出了高性能的AI计算平台,使得将高性能深度学习网络部署到移动机器人平台变得可行.因此,文中提出了一种适用于室内动态环境的SLAM方法,在VINS-Mono中的特征点提取阶段之前,利用目标检测组件生成图像帧中潜在动态对象的掩膜,并设置相应的掩膜深度.通过将特征点的深度与掩膜深度图进行比较,实现对动态特征点的过滤,从而提高在动态环境下的定位准确性.
1" 视觉惯性SLAM框架
文中采用基于VINS-Mono[6]做为基础框架,在此架构的基础之上增添了目标检测器和深度相机,以便于实现动态目标检测及动态特征点剔除.系统框架如图1.
首先,目标检测器对每个图像帧中存在潜在动态对象进行语义分割.其中动态图像的分割是基于先验的,即在实际的室内环境中是潜在的动态对象或可移动对象,比如:人、狗等.然后,通过光流估计网络,确保每帧图像的掩膜图像生成,在此基础上设置掩膜深度形成掩膜深度图.
其次,测量预处理从RGB图像帧中提取特征点,并通过Kanade-Lucas-Tomasi(KLT)稀疏光流实现对特征点的跟踪.利用特征点的深度值和目标检测器传递的掩膜深度图,完成动态特征点的过滤.
最后,通过引入目标检测和深度信息,能够准确地识别出动态物体并将其从特征点中剔除.这样可以减少动态物体对定位过程的干扰,提高在室内动态环境下单目VINS的定位精度和鲁棒性.通过目标检测器和深度相机的组合,改善了传统单目VINS在动态环境下的性能限制,使其能够更好地适应复杂的室内场景.
2" 目标检测器
2.1" 语义分割网络
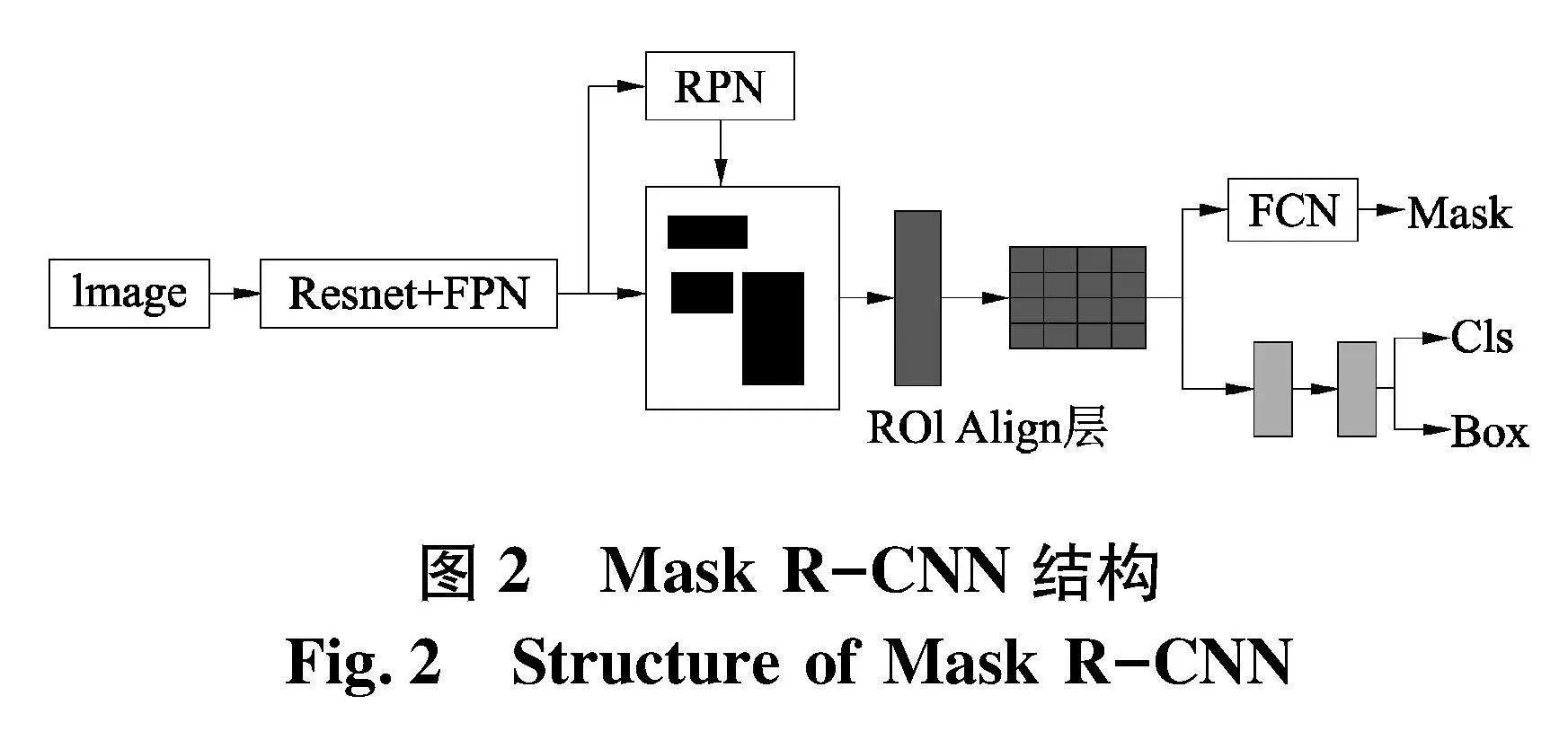
Mask R-CNN[7]是提出的一种二阶段深度学习检测算法,具有检测和分割两项功能,该网络结构如图 由4个部分构成,分别是残差网络(Resnet)和特征金字塔(FPN)构成的主干网络、建议网络(RPN)、兴趣区域(ROI)分类器以及三分支网络(边框回归器、分割掩膜生成网络).
文中针对室内场景,将人、猫和狗等三类潜在动态对象进行了语义分割.其中Mask R-CNN采用了微软公司的MS COCO目标检测数据集进行Mask R-CNN的权重训练.通过Mask R-CNN网络,对每一帧输入图像进行检测,并生成相应的动态目标掩膜图像.图3展示了高动态环境Market_1下的分割结果.
2.2" 光流估计
Mask R-CNN网络存在单帧图像分割较长(约200 ms)和分割失败的问题,因此,引入光流估计网络对掩膜图像进行预测.PWC-Net[8]是一种端到端的光流估计模型,通过PWC-Net网络对输入的图像进行光流估计.则当前图像帧中的像素点坐标(xc,yc)在PWC-Net网络中可表示为:
(xc,yc)=(xp+fx,yp+fy)(1)
式中:fx为前一帧图像到当前图像帧中像素在x轴的位移;fy为前一帧图像到当前图像帧中像素在y轴的位移;(xp,yp)为像素点在前一帧图像中的坐标.
利用前一帧的掩膜图像及当前帧与前一帧的光流信息,并适当膨胀后可实现对掩膜的预测.在PWC-Net网络中,当前图像帧的预测语义Ic(xc,yc)为:
Ic(xc,yc)=Ip(xp+fx,yp+fy)(2)
式中:Ip(xp,yp)为含有语义标签的像素坐标;(fx,fy)为像素在含语义标签的图像帧到当前图像帧中在x轴和y轴的位移.
3" 特征点提取及过滤
3.1" 特征点提取
文中特征点是从RGB图像帧当中提取,由于FAST[9]角点可以通过图片亮度变化来提取局部特征,并且在提取速度和规模方面具有显著优势,因此选用FAST角点作为特征的提取算法.在获取特征点之后,使用KLT稀疏光流算法进行光流追踪.在图5中,检测到的特征点不仅包含多次追踪成功的特征点,也包含当前帧中新检测到的特征点.
3.2" 特征过滤
通过特征检测会包含静态和动态特征点.为实现动态特征点的过滤,提出一种结合掩膜深度的动态特征点过滤算法,即在图像帧掩膜生成的基础上设置掩膜深度,通过对检测到的特征点所对应的深度信息与掩膜对应位置的深度进行比较,然后通过过滤区分出动态特征点和静态特征点.
假设Dk为第k帧掩膜图像的掩膜深度,d为每个像素的掩膜深度,其取值为:
d=0" 掩膜图像中像素值为1的区域dM掩膜图像中像素值为0的区域(3)
式中:dM为相机最大深度值.
将每个检测到的特征点对应的深度信息d与掩膜深度图对应位置的深度值d进行比较,并根据比较结果进行过滤.判定如下:
s.t." 1" d≥d0dlt;d(4)
式中:1为动态特征点;0为静态特征点.
图6中,人物上的特征点,相较图5得到了减少.
4" 视觉惯性里程计
4.1" 基于紧耦合的滑动窗口优化
在系统初始化完成后,需对滑动窗口内的残差项进行优化,其状态向量X定义为:
X=x0,x1,…,xn,xbc,λ0,λ1,…,λm(5)
xk=pwbk,vwbk,qwbk,ba,bw(6)
xbc=pbc,qbc(7)
式中:n为关键帧总数;xbc为惯性检测单元与视觉坐标间的相对位姿;λ为特征点逆深度;m为特征点数目;xk为滑动窗口内第k帧所对应的惯性检测单元状态;ba为加速度偏置;bw为角速度偏置.
对IMU、视觉和边缘化的残差和最小化可实现对滑动窗口项的优化,则目标函数为:
minX ρ(‖Υp-JpX‖2)+∑k∈Iρ(‖Υp(Z^bkbk+1,X)‖2Pbkbk+1)+
∑(f,j)∈cρ(‖Υc(Z^cjf,X)‖2Pcjf)(8)
式中:ρ(·)为鲁棒核函数;P为先验;Z^bkbk+1为滑动窗口内两帧间的IMU测量;Υp为先验残差;Jp为从边缘化后的海思矩阵Hp中恢复的雅可比矩阵;Υp-JpX为边缘化残差;Υp(Z^bkbk+1,X)为滑动窗口相邻两帧间的预积分残差;Υc(Z^cjf,X)为视觉重投影的残差;Pbkbk+1为预积分观测协方差;Pcjf为视觉观测协方差;f为连续追踪的图像特征点;cj为图像帧;Z^cjf为第j个相机坐标系cj对某个视觉特征的三维观测值.
4.2" IMU残差
IMU残差项定义为IMU预积分及实际观测值,其对应公式为:
Υp(Z^bkbk+1,X)=δαXkXk+1δβXkXk+1δθXkXk+1δbaδbw=RXkw(pwXk+1-pwXk+12gwΔtk2-vwXkΔtk)-α^XkXk+1bXkw(vwXk+1gwΔtk-vwXk)-β^XkXk+1
2(qwXk)-1qwXk(γ^XkXk+1)-1xyz
baXk+1-baXkbwXk+1-bwXk(9)
式中:q和p为坐标系转换的旋转量和平移量;γ^为预积分真值;g为重力加速度;b为偏置;α,β,γ为系统的位移,速度和旋转向量.
4.3" 视觉残差
视觉残差投影方程为:
Pcjl=Rcb(Rbjw(Rwbi(Rbc1λlπc-1(u^cilv^cil)+pbc)+pwbi-Rwbj)-pbc)(10)
式中:u^cilv^cil为第l个被观测的特征点在相机归一化平面下的坐标;Ci为第i帧观测的图像;πc-1为相机内参投影矩阵.则对Pcjl归一化,则残差项表示为:
Υc(Z^cjf,X)=Pcjl-πc-1u^cilv^cil(11)
4.4nbsp; 边缘化
设系统状态变量为X={δχr,δχm},δχm为要边缘化的状态量,δχr为边缘化保留的状态量,未优化前的增量方程Hδx=b,则通过高斯牛顿计算,表示为:
[A-BD-1C][δχr]=[br-BD-1bm](12)
式中:A,B,C,D为海思矩阵;δχr为舒尔补结果.将公式记为:Hpδχr=bp,通过将边缘化后的海思矩阵Hp作为先验约束项,恢复得到雅可比矩阵Jp,并从bp中恢复得到先验残差Υp,则可得到边缘化残差Υp-JpX.
5" 实验
5.1" 实验条件
在视觉惯性数据集OpenLORIS-Scene[10]上对所提出的SLAM算法进行实验.OpenLORIS-Scene数据集分包含无动态场景和有动态场景,并且基于真实环境记录,存在较多昏暗和大面积无纹理场景,这有利于评估算法在动态环境下的性能.实验平台为:R9-6900HX处理器(3.3 GHz),RXT3060显卡,16 G RAM,64位Ubuntu18.04操作系统.
5.2" 轨迹精度评估
OpenLORIS数据集在图像方面提供了30帧/秒,分辨率为848×480的彩色、深度及鱼眼图像.在IMU方面,数据集提供了250/62.5 Hz的加速度计和400/200 Hz的重力计.为了确保每一帧图像都可以获得掩膜信息,实验中将OpenLORIS数据集的发布频率改为原值的一半.同时,在4个序列场景中将文中算法与VINS-Mono、PL-VINS和VINS-RGBD[11]进行对比实验.这些场景包括Office1_1序列(无动态场景),Home1_1序列(低动态场景),Cafe1_1序列和Market1_1序列(高动态场景).
采用绝对轨迹误差(ATE)来评估算法的整体误差.其中误差衡量指标为均方根误差(Rmse)、中位数(Median)、平均值(Mean)和标准差(Std).图7展示了各算法在不同场景下的轨迹与真实轨迹比较,图中虚线表示当前序列的真实轨迹.
表1~4是各算法在OpenLORIS数据集中轨迹的绝对误差.通过数据可知,VINS-Mono效果最差,这是由于特征点处理仅有RANSAC误匹配特征点去除.PL-VINS则引入直线特征,在含直线较多的静态环境下可以获得更多的稳定特征点,但在动态目标移动时,导致直线特征位置和形状发生扭曲,增加了准确追踪的难度.VINS-RGBD则利用深度信息辅助选择具一定深度范围内的特征点,排除一些无关的背景或者近距离的噪声点.
文中算法在Cafe1_1和Market1_1序列都有较大提升,其他序列则持平.通过分析,在Office1_1与Home1_1中定位相比VINS-RGBD没有显著提升的原因与场景序列的内容有关.其中,Office1_1和Home1_1序列分别属于无动态/低动态场景,这些场景由于人物较少,导致动态特征点数目过少,对于定位精度影响较少,故没有取得最佳效果.而在后两个序列中,由于场景是高动态环境,动态特征点对定位的效果相比前两个序列影响更大,说明文中算法在高动态序列下对动态特征点的过滤,有效提高了定位精度.故文中算法在高动态环境下的路径轨迹更加精确,有效提高了系统的鲁棒性.
6" 结论
针对室内在动态环境下定位精度差的情况,提出了一种结合语义及光流估计的视觉惯性SLAM方法,得出以下结论:
(1) 利用语义分割网络,实现了对动态对象的检测.并融合光流估计网络,有效改善语义分割网络在较短时间内掩膜分割图像不足的情况.
(2) 添加深度传感器,结合掩膜深度信息的特征过滤算法,根据特征点所对应的深度信息及掩膜深度信息,实现对特征点的静态与动态分离.
(3) 基于OpenLORIS的数据集进行实验,实验结果表明该方法在动态环境下定位精度和鲁棒性都得到有效提升.
参考文献(References)
[1]" 曾庆化,罗怡雪,孙克诚,等.视觉及其融合惯性的SLAM技术发展综述[J].南京航空航天大学学报,2022,54(6):1007-1020.
[2]" KIM D H, HAN S B, KIM J H. Visual odometry algorithm using an RGB-D sensor and IMU in a highly dynamic environment[J]. Robot Intelligence Technology and Applications, 2015, 345:11-26.
[3]" 崔林飞, 黄丹丹, 王祎旻,等.面向动态环境的视觉惯性SLAM算法[J].计算机工程与设计,2022,43(3):713-720.
[4]" BESCOS B, FACIL J M, CIVERA J, et al. Dynaslam: Tracking, mapping, and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters, 2018,3 (4): 4076-4083.
[5]" XIAO L, WANG J, QIU X, et al. Dynamic-slam: Semantic monocular visual localization and mapping based on deep learning in dynamic environment [J].Robotics and Autonomous Systems,2019,117:1-16.
[6]" QIN T, LI P, SHEN S, et al. VINS-Mono:Arobust and versatile monocular visual-inertialstate estimator [J].IEEE Transactionson" Rboticso ,2018,34 (4):1004-1020.
[7]" HE K, GKIOXARI G, DOLLR P, et al. Mask R-CNN[C]∥Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy: ICCV, 2017: 2961-2969.
[8]" 胡毅轩,吴飞,熊玉洁.基于PWC-Net的多层权值和轻量化改进光流估计算法[J]. 计算机应用研究,2022,39(1):291-295.
[9]" 刘亮,王平,孙亮.基于区域灰度变化的自适应FAST角点检测算法[J].微电子学与计算机,2017,34(3):20-24.
[10]" GENEVA P, ECKENHOFF K, LEE W, et al. OpenVINS: A research platform for visual-inertial estimation[C]∥IEEE International Conference on Robotics and Automation(ICRA). Paris,France:IEEE, 2020: 4666-4672.
[11]" SHAN Z Y, LI R J, SCHWERTFEGER S. RGBD-inertial trajectory estimation and mapping for ground robots[J]. Sensors,2019,19(10):2251.
(责任编辑:曹莉)
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
电光与控制(2018年10期)2018-10-13 08:19:00
计算机工程与应用(2015年19期)2015-04-16 08:52:20
中北大学学报(自然科学版)(2014年3期)2014-11-22 02:02:56
中国铁道科学(2014年6期)2014-06-21 06:35:32
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:36
