
基于全局-局部注意力机制和YOLOv5 的宫颈细胞图像异常检测模型
2024-11-03 00:00:00胡雯然傅蓉
南方医科大学学报 2024年7期
关键词:图像处理
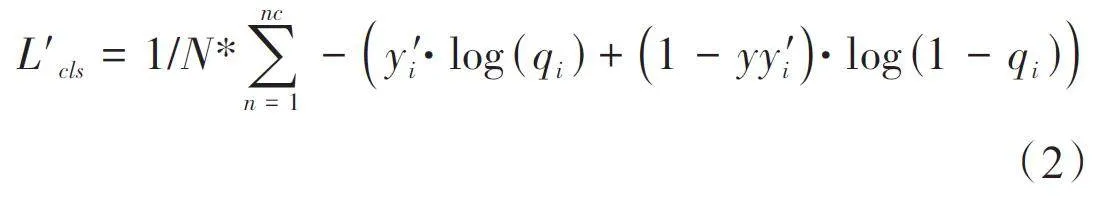

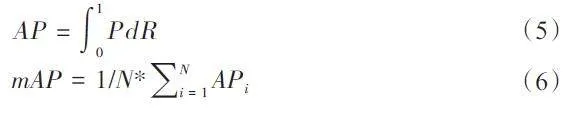

Trans-YOLOv5: a YOLOv5-based prior transformer networkmodel for automated detection of abnormal cells or clumpsin cervical cytology images
Abstract: The development of various models for automated images screening has significantly enhanced the efficiency andaccuracy of cervical cytology image analysis. Single-stage target detection models are capable of fast detection of abnormalitiesin cervical cytology, but an accurate diagnosis of abnormal cells not only relies on identification of a single cell itself, but alsoinvolves the comparison with the surrounding cells. Herein we present the Trans-YOLOv5 model, an automated abnormal celldetection model based on the YOLOv5 model incorporating the global-local attention mechanism to allow efficientmulticlassification detection of abnormal cells in cervical cytology images. The experimental results using a large cervicalcytology image dataset demonstrated the efficiency and accuracy of this model in comparison with the state-of-the-artmethods, with a mAP reaching 65.9% and an AR reaching 53.3%, showing a great potential of this model in automated cervicalcancer screening based on cervical cytology images.
Keywords: cervical cancer screening; YOLOv5; image processing; Transformer
Several two-stage detection approaches (localization followed by classification) based on afaster RCNN[14] have been proposed for abnormal cellidentification. These strategies are implemented bycapturing feature information from different classes ofindividual cervical cells for comparison learning withthe convolutional features generated by faster RCNN[15],by adding an attention mechanism[16], by decomposingthe original detection task into two sub-tasks( single celland cell cluster) and designing a decompose-andintegratehead for more effective feature extraction toallow adaptive comparison of the normal and abnormalcells[17], or by designing a cascaded region of interest(ROI) feature enhancement scheme for exploring thecell-level object-object relationships and the globalimage context[ 18]. Cascade RCNN[19] and mask RCNN[20]were also used in the detection of cervical cells orclumps[21, 22]. But as all these object detection modelsrequire two stages of convolution through the regionproposal network and RCNN, their detection speedremains low.
One-stage detection strategies, as represented bythe You-only-look-once (YOLO) algorithms [23], treatsthe target detection as a regression problem and predictsthe target's position and category all at once, thusresulting in faster detection speeds. Several modifiedYOLO models have been proposed by integrating alightweight classification model [24] or a global contextawareframework[25] for improving the feature extractionnetwork and the loss function[26]. Attempt was also madeto improve the RetinaNet[28] by introducing the patchcorrection network (PCN)[ 27]. These algorithms havesignificantly enhanced the performance of the models,but their detection accuracy and speed still need furtherimprovement. To address these issues, we propose aYOLOv5-based prior transformer network for improvingthe diagnostic accuracy in tasks of multi-classificationidentification of cervical cells or clumps. We enhancedthe deep global information extraction capability byreferencing the cross stage partial networks (CSP) with3 bottleneck transformers (CBT3) in the YOLOv5backbone network, and designed the attention decoupled head (ADH) detection head to improve thelocalization branch's ability to incorporate the texturefeatures after decoupling the detection head to constitutea fusion global-local attention mechanism.
METHODS
Datasets
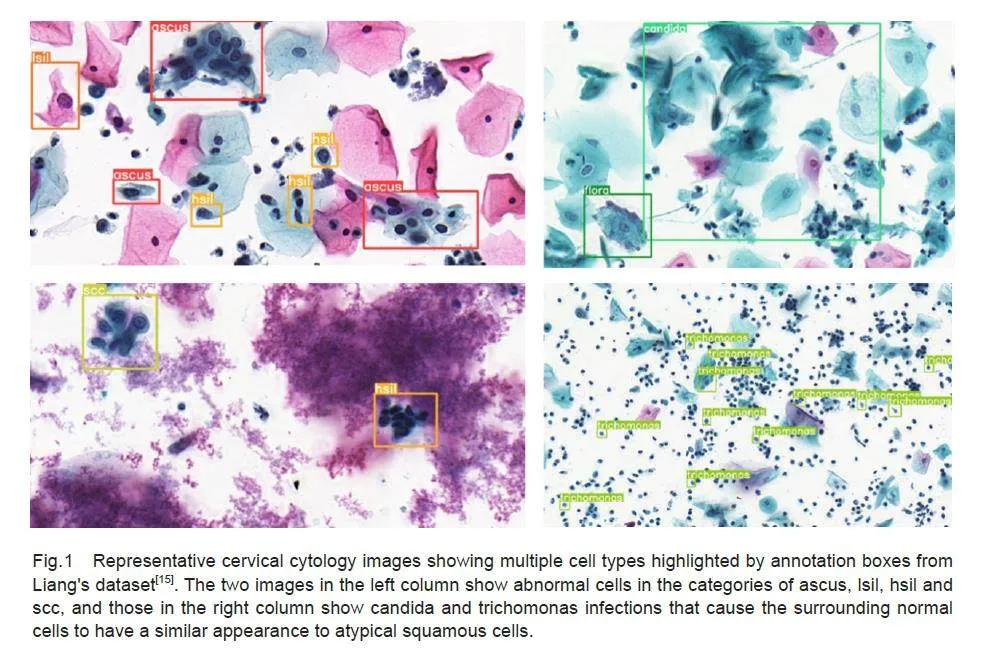
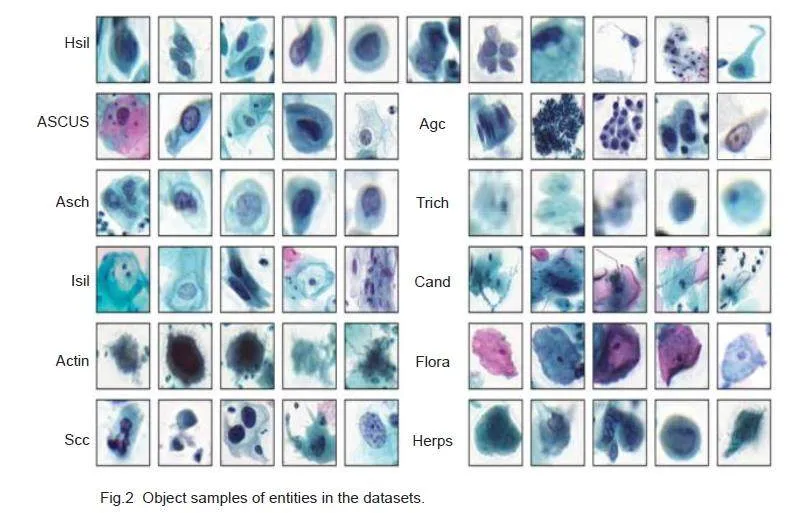
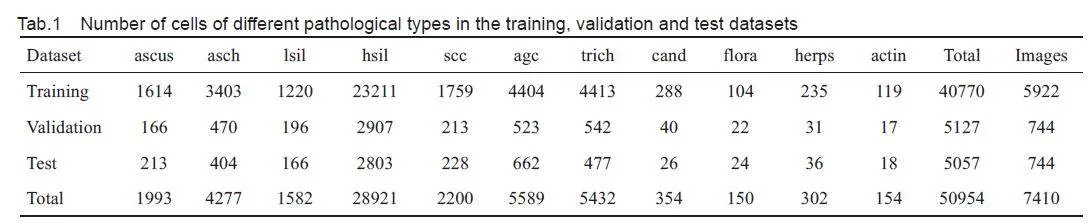
This study was conducted using a publicly availabledataset of cervical cytology images provided by Liang etal[15], which comprises a total of 7410 cervical images,with 50 954 ground-truth boxes in 11 categories ofobjects. These categories include: atypical squamouscells of undetermined significance (ascus), atypicalsquamous cells predisposed to high-grade squamousintraepithelial lesions (asch), low-grade squamousintraepithelial lesion (lsil), high-grade squamousintraepithelial lesion (hsil), squamous-cell carcinoma (scc), atypical glandular cells (agc), trichomonas (trich), candida (cand), flora, herps, and actinomyces (actin). In particular, asch, lsil, hsil and agc representthe 4 pathological types of precancerous lesions ofcervical cancer, while scc is a typical marker formalignant cervical tumors. These 5 cell types are thekey targets in subsequent detection tasks. We dividedthe dataset into training, validation and test sets in an 8∶1∶1 ratio. The example images with annotation boxes areshown in Fig.1, and the details of the dataset are listedin Tab.1.
Data augmentation
Tab. 1 shows that the number of cells differedsignificantly across different categories, for which thedetection models, commonly designed with numerousconvolutional layers to extract more feature information,may lead to overfitting of the data. The annotated imagesof cervical cells (Fig.1) also contain diverse cell typeswith heterogeneous distribution and overlapping cells.Besides using pixel-level data enhancement methodssuch as panning, scaling, flipping, and perspectivetransformations, we also used Mosaic and mixup tosimulate these scenarios to enhance the complexity ofthe image background, thus improving the model'scapacity to detect the target. We also considered theimpact of cell staining and image acquisition equipmenton image quality. As a clinical diagnosis ofabnormalities relies on observation of specificmorphology rather than the color of the stained cells, weperformed data augmentation by adjusting image HSVvalues, applied blurring, and added noise to replicatethe various levels of image quality, which enhanced themodel's ability to extract the texture information.
Label smoothing
The traditional YOLOv5 loss function directly employsone-hot coding while ignoring the similarity between theclasses when calculating the classification loss, but thecervical cell images have a high inter-class and intraclassvisual similarity (Fig.2). The use of hard labels forcomputation drives the model to be overconfident in itspredictions, which leads to over-fitting. To address thisproblem, we invoked label smoothing for regularizationto smooth the hard labels added manually.
y 'i = (1 - ε)y i + ε/ (K - 1) *(1 -y i ) (1)
where yi is the ground-truth one-hot distribution of label i, K the total number of samples, and ϵ a smallconstant. The new label distribution is then substitutedas a criterion for the classification loss.
Finally, the classification loss in the original lossfunction is replaced with L'cls. This treatment not onlyimproves generalization of the model's feature learningfor each cell class during model training, but alsoreduces the interference by noisy labels within thedataset.
Network architecture of Trans-YOLOv5
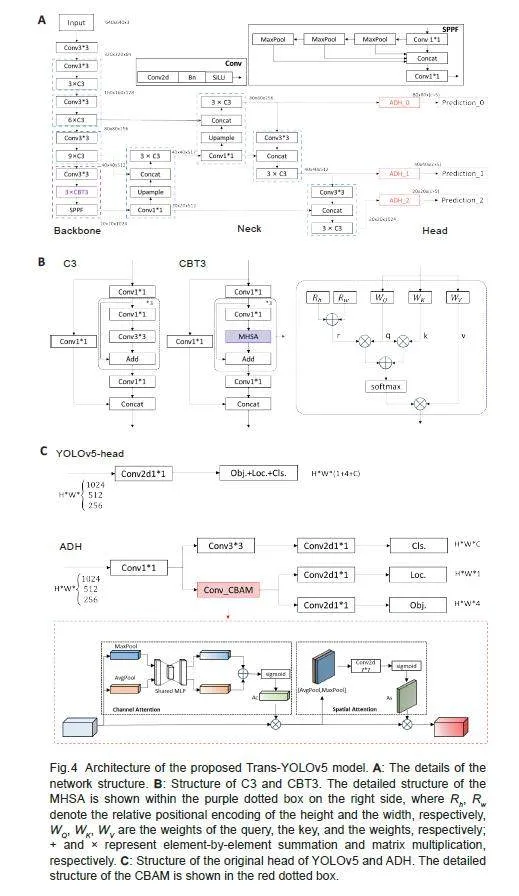
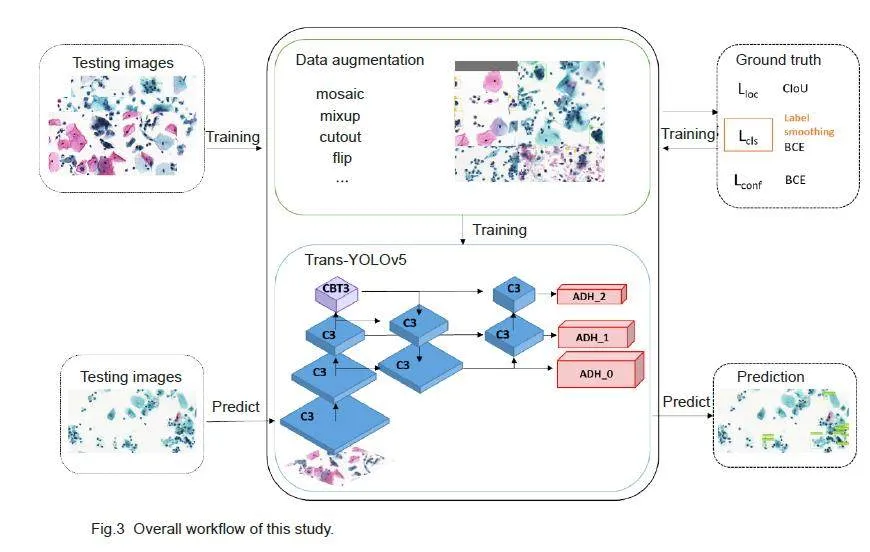
Fig.3 shows the overall workflow of multiclassification ofthe cervical cells using the proposed Trans-YOLOv5network model. Before model training, all the trainingset images were processed with data augmentation andthe model's parameters were fine-tuned based on actuallabels and an improved loss function, and the best-performing model was selected for detection. The modelwas constructed based on the classic YOLOv5, fusingTransformer and self-attention. YOLOv5 is based onCNN with the advantages of parameter sharing andefficient local information aggregation. Clinically, thedetection of abnormal cells requires both observation ofthe entire background environment for localization andreference comparisons between the neighboring cells.The original YOLOv5 head directly employs the samefeature layer for both localization and classificationtasks without considering the specific featurerequirements of these tasks, which may give rise tocontradictory features extracted from the two tasks.Therefore in the Trans-YOLOv5 model, we improved thebackbone and detection headers in YOLOv5 networkarchitecture by using CBT3 instead of the CSPbottleneck with 3 convolutions (C3) in the backbonenetwork for the deepest feature extraction and replacingthe detection head with ADH( Fig.4A).
To design the CBT3, the multi-head self-attention (MHDA) of bottleneck transformer[28] was referenced inthe basic network structure C3 of YOLOv5 (Fig.4B) toenhance the model's ability to acquire globalinformation. MHDA consumes huge computation, andthe feature map from the final stage of feature extractionis much smaller in size and serves as the foundation forthe later PANet. Therefore, we limited the use of CBT3to the last stage of YOLOv5 base model's backbone. Thisapproach enables the entire model to access high-levelinformation that preserves more detailed global featureswhile avoiding excessive computational demands (Fig.4b). CBT3's MHDA introduces positional coding r,which is obtained by summing Rh and Rw (the relativeposition codes for height and width, respectively), andadds more positional information to enhance the model'sability for comparing normal-abnormal and abnormalabnormalcells at different positions in the image.
To address the issue of misalignment stemmingfrom the original head of YOLOv5, which directlygenerates regression predictions (Fig. 4C), ADH wasintroduced in the model, which, instead of conflatingclassification and localization within a single pathway,segregates them into two parallel branches for separateprocessing by a dedicated convolution. Given theintricacies of the localization task, which demandsprecise texture details and boundary delineation, aspecialized detection head was used in the model. Torefine the localization branch further, we incorporated aconvolutional block attention module (CBAM)[29] beforefeature output to enable the fusion of Channel Attentionand Spatial Attention across different levels of thelocalization branch, thus empowering the model to focuson salient image regions while ensuring consistencybetween the two tasks' predictions. The introduction ofADH amalgamates enhanced texture feature informationwith the localization task, and enhances the model'sability to acquire precise target location information.
Experimental settings
Model training was conducted using the followingconfigurations: SGD optimizer with weight decay of0.001, momentum of 0.9, a batch size of 16, an initiallearning rate of 0.0001, and a maximum number oftraining iterations capped at 300. The training images were augmented (Tab. 2) and resized to 640×640 formodel input. If the mAP metrics fail to demonstrateimprovement within 50 subsequent training epochs, thetraining process concludes prematurely even if thecurrent number of training epochs is below 300.
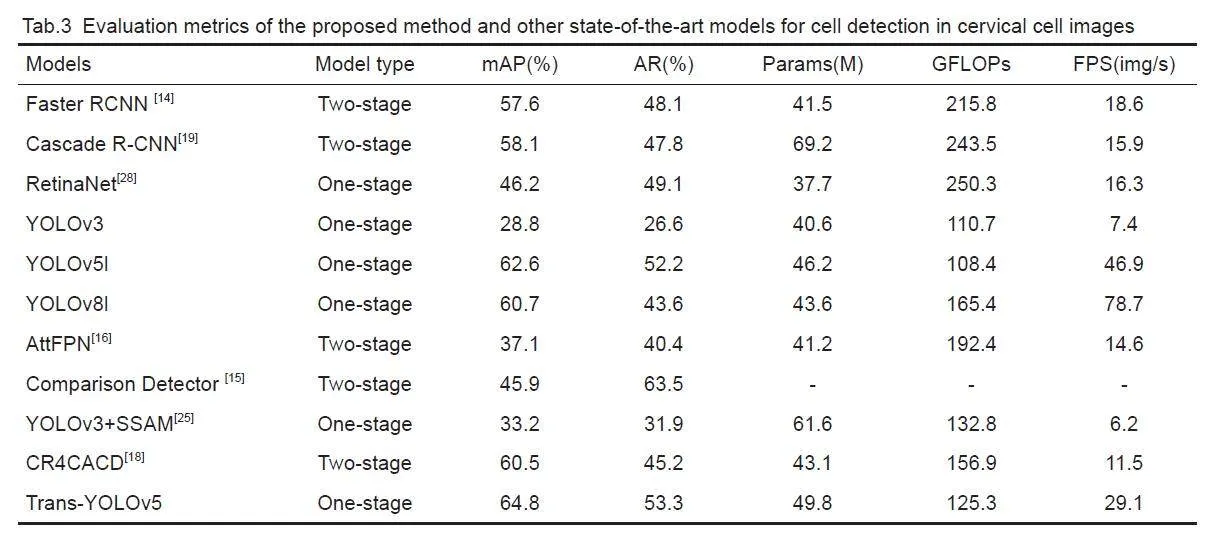
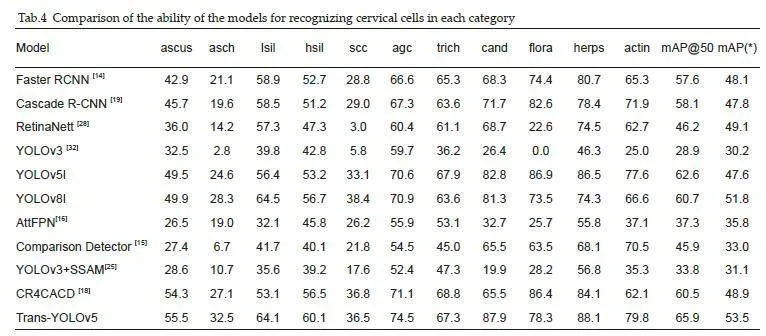
All the experimental results were obtained basedon the divided publicly available dataset provided byLiang et al[15]. We compared the results and modelperformance with Faster RCNN[14], Cascade R-CNN[19],RetinaNet[28], YOLOv3[32], YOLOv5, and YOLOv8,which are representative object detection models, andAttFPN[16], Comparison Detector[15], YOLOv3_SSAM[25],CR4CACD[18], which are state-of-the-art cervical lesiondetection models. These models were trained with thesuggested configurations (including model architecture,hyperparameters, and data augmentation, etc.) using thesame divided data. We used the same data augmentationstrategy for comparison with the known detection head,YOLOX[32], and TSCODE[31] .
Evaluation metrics
We adopted the evaluation metrics used in the PASCALVOC Object Detection Challenge. The accuracy ofobject detection was assessed by calculating theprecision (P) and recall (R) of the detection atdifferent thresholds of the Intersection over Union (IoU), which is defined as the area of intersectionbetween prediction and truth boxes divided by the areaof their union, indicating their closeness. The P and Rare obtained by
P = TP/(TP + FP) × 100% (3)
R = TP / ( TP + FN ) ×100% (4)
TP indicates that the IoU of the predicted boundingbox is above the threshold and correctly categorized. FPimplies that the IoU of the predicted bounding box isbelow the threshold or there is no real target in thepredicted box. FN indicates that there is no predictedreal target. As the CNN object detection model forcervical cells or clumps requires only approximatelocalization, we used APs with a single IoU thresholdedat 0.5. As cervical cell detection is a multicategoricaltask, we computed APs for each category separately.mAP is the average of the APs of all categories (N), andmAP(*) is the average value of AP for the 5 key cellcategories to be detected, namely asch, lsil, hsil, agc,and scc. AR is the recall of the detection results of thefirst 100 prediction frames for each image. AP and mAPare defined as follows:
RESULTS
Comparative experiments
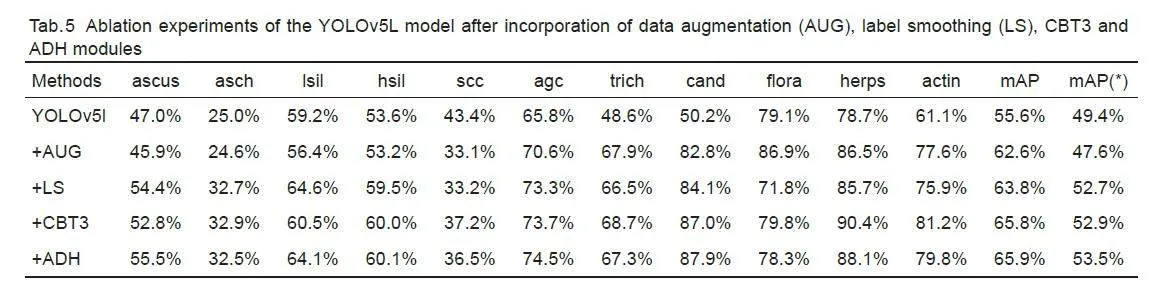
We compared the proposed model with several objectdetection methods and known cervical lesion detectionmethods. Tab.3 lists the evaluation metrics of the modelsand Tab. 4 shows the results of categorization of thecervical cells using these detection models. Comparisonof the models showed that among the two-stage and onestageconvolutional detection models, the YOLOv5lmodel achieved the highest mAP with an AR onlyinferior to that of Comparison Detector, and showed alsogood performance in terms of the parameter count,computation, and detection rate. In the cellclassification tasks, the Trans-YOLOv5 model achievedthe highest accuracy with a mAP of 65.9%.
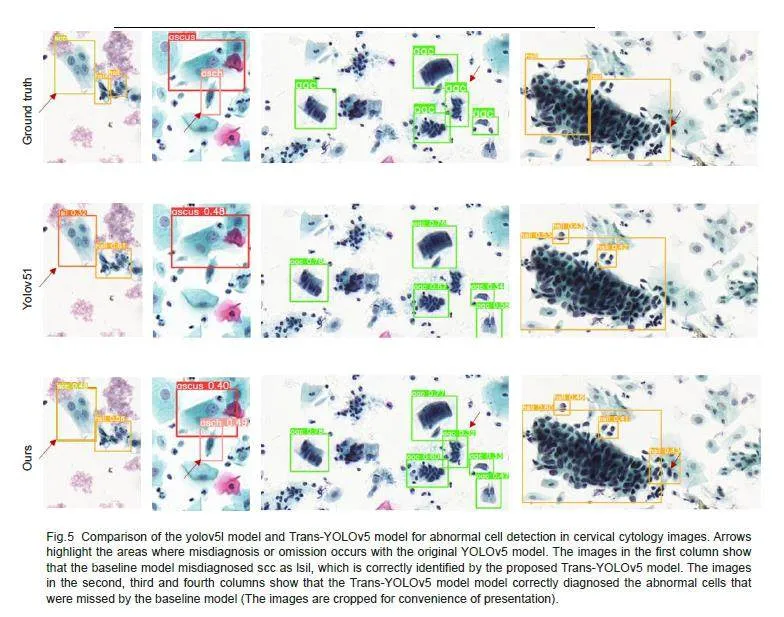
Fig. 5 shows lesion detection results of the basemodel before and after the improvement. The Trans-YOLOv5 model is capable of detecting lesion regionsthat have been missed or wrongly detected by the basicmodel, and can better localize the lesion regions andidentify the cell categories. The results also showed thatcompared with the original annotation of the dataset, theproposed model had a better accuracy and a higherreliability for localizing the abnormal cells.
Ablation study
We performed ablation experiments to assess thecontributions of various components in the model,including data augmentation (AUG), label smoothing (LS), CBT3 and ADH. As shown in Tab. 5, theproposed Trans-YOLOv5 model significantly improvesthe detection performance in terms of AP for differentlesion categories. In particular, for lesion categories witha small number of instances in the dataset (such ascand, herps, and actin), the enhancement in APhighlights the necessity and effectiveness of appropriatedata augmentation methods. Comparison of the resultsbefore and after the incorporation of label smoothingdemonstrates that label smoothing enhances the model'scapacity to distinguish the cancerous cells at differentstages (asch, lsil, hsi, agc, and scc) and improves themAP(*) by 3.3%.
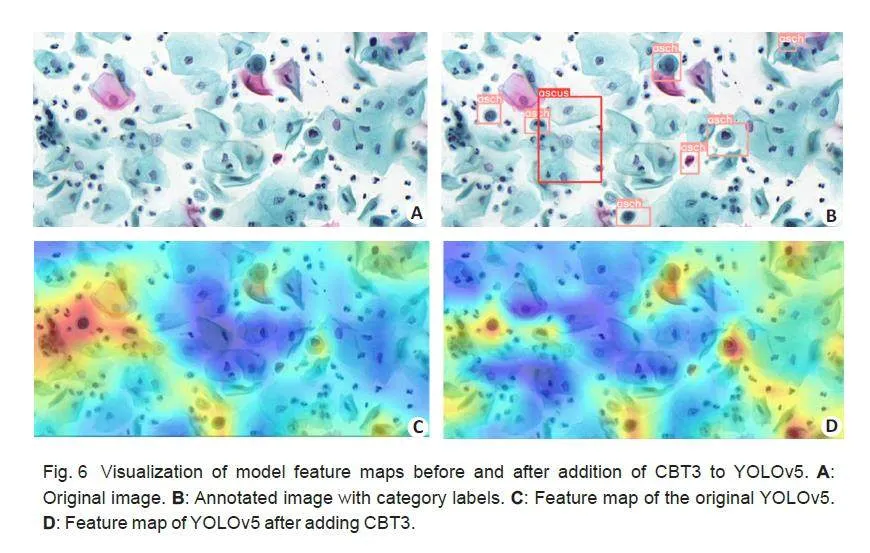
Effect of CBT3
As shown in Tab.5, the incorporation of CBT3 enhancesthe sensitivity of the model to global information,resulting in an improved recall rate of 65.9% and anenhanced ability to recognize cells like asch and scc. Tofurther demonstrate the effectiveness of CBT3, wecompared the feature maps of the basic YOLOv5 modeland the modified model with addition of CBT3 (Fig.6),generated by computing the weight of each feature mapin the last convolutional layer of the backbone networkwith respect to the image category. The weights of eachfeature map are summed, and the weighted sum is thenmapped back to the original image. By comparison, themodel with addition of CBT3 performed more effectivelyin acquiring the feature representations of the samecategory of abnormal cells in the whole image.
Effect of ADH
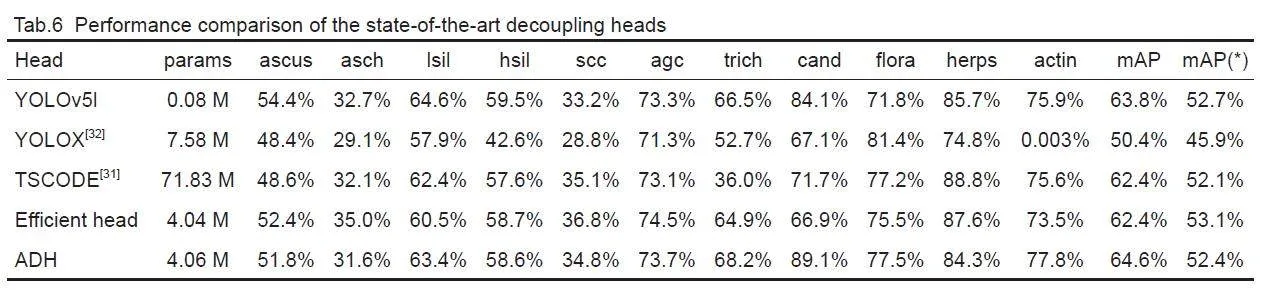
We further compared ADH with the currently availabledecoupling heads. The decoupling heads all have acomplex design of TSCODE[31], which substantiallyincreases the number of model parameters, and thustheir direct application to YOLOv5l can lead to overfitting.We therefore added ADH after the featureextraction network of YOLOv5s. Efficient Head uses oneconvolution for each of the classification and localizationtasks and the parallel branching for feature processing.
Tab.6 shows that the increasing complexity of thehead does not necessarily improve the accuracy.Efficient Head with a simpler structure and lesscomputation is more accurate than the decoupling headsof TSCODE and YOLOX[32]. ADH allows the localizationtask of Efficient Head to obtain more discriminativefeatures of the objects by adding the CBAM attentionmodule to reduce the amount of computation, whichenhances the ability of model to detect cells with lessdata but large within-class size differences (as in thecases of cand and actin).
DISCUSSION
The proposed network model based on the YOLOv5model and global-local attention mechanism improvesthe performance of computer-aided diagnosis of cervicalcytology images. With a much lower consumption ofsystem resources, YOLOv5l achieves a higher accuracythan the two-stage and one-stage detection models. Toavoid overconfidence of the CNN model on some cell types that potentially leads to overfitting, we used dataaugmentation methods and improved labelingdistribution before model training with the cervical cellimages. The incorporation of CBT3 into the backbonenetwork, by taking advantage of the Transformer'sstrength in mining long-distance dependencies, allowsthe model to achieve more accurate localization andclassification of abnormal cervical cells based on thecharacteristic information of the surroundingenvironment. The network structure of the detectionhead is redesigned to decouple the classification andregression tasks, which improves the diagnosticperformance for cancerous cells by exploiting thecapability of the attention mechanism for localizedfeature extraction. The model achieves a mAP of 65.9%in test with a large cervical cytology image dataset,muchhigher than those of the state-of-the-art methods.
In addition, the proposed Trans-YOLOv5 modelwas trained predominantly using abnormal cervical cellimages, and training with more normal images mayfurther enhance its diagnostic ability. Label smoothingrepresents a fixed alteration of the label distribution,and the model can be further improved with moreefficient label assignment strategies by learning therelationships between labels and predictions and thelabels themselves.
REFERENCES:
[1] Bray F, Laversanne M, Sung H, et al. Global cancer statistics 2022:GLOBOCAN estimates of incidence and mortality worldwide for 36cancers in 185 countries[J]. CA Cancer J Clin, 2024, 74(3): 229-63.
[2] Solomon D, Davey D, Kurman R, et al. The 2001 Bethesda System:terminology for reporting results of cervical cytology [J]. JAMA,2002, 287(16): 2114-9.
[3] William W, Ware A, Basaza-Ejiri AH, et al. A pap-smear analysistool (PAT) for detection of cervical cancer from pap-smear images [J]. Biomedical engineering online, 2019, 18: 1-22.
[4] 王嘉旭, 薛 鹏, 江 宇, 等. 人工智能在宫颈癌筛查中的应用研究进展[J]. 中国肿瘤临床, 2021, 48(09): 468-71.
[5] Nayar R, Wilbur DC. The Bethesda system for reporting cervicalcytology: definitions, criteria, and explanatory notes [M]. Springer,2015. 103-285.
[6] Chankong T, Theera-Umpon N, Auephanwiriyakul S. Automaticcervical cell segmentation and classification in Pap smears [J].Methods Programs Biomed, 2014, 113(2): 539-56.
[7] Bora K, Chowdhury M, Mahanta L B, et al. Automated classificationof Pap smear images to detect cervical dysplasia [J]. ComputMethods Programs Biomed, 2017, 138: 31-47.
[8] Arya M, Mittal N, Singh G. Texture-based feature extraction of smearimages for the detection of cervical cancer [J]. IET Comput Vision,2018, 12(8): 1049-59.
[9] Wang P, Wang L, Li Y, et al. Automatic cell nuclei segmentation andclassification of cervical Pap smear images [J]. Biomed SignalProcess Control, 2019, 48: 93-103.
[10]Zhang L, Lu L, Nogues I, et al. DeepPap: deep convolutionalnetworks for cervical cell classification [J]. IEEE J Biomed HealthInform, 2017, 21(6): 1633-43.
[11]Taha B, Dias J, Werghi N. Classification of cervical-cancer usingpap-smear images: a convolutional neural network approach [C].Medical Image Understanding and Analysis: 21st AnnualConference, MIUA 2017, Edinburgh, UK, July 11-13, 2017,Proceedings 21. Springer International Publishing, 2017: 261-72.
[12]Wieslander H, Forslid G, Bengtsson E, et al. Deep convolutionalneural networks for detecting cellular changes due to malignancy [C]. Proceedings of the IEEE International Conference on ComputerVision Workshops. 2017: 82-9.
[13]Jiang P, Li X, Shen H, et al. A systematic review of deep learningbasedcervical cytology screening: from cell identification to wholeslide image analysis[J]. Artif Intell Rev, 2023, 56(Suppl 2):2687-758.
[14]Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-timeobject detection with region proposal networks[J]. IEEE TransPattern Anal Mach Intell, 2016, 39(6): 1137-49.
[15]Liang Y, Tang Z, Yan M, et al. Comparison detector for cervical cell/clumps detection in the limited data scenario[J]. Neurocomputing,2021, 437: 195-205.
[16]Cao L, Yang J, Rong Z, et al. A novel attention-guided convolutionalnetwork for the detection of abnormal cervical cells in cervicalcancer screening[J]. Med Image Anal, 2021, 73: 102197.
[17]Chen T, Zheng W, Ying H, et al. A task decomposing and cellcomparing method for cervical lesion cell detection[J]. IEEE TransMed Imaging, 2022, 41(9): 2432-42.
[18]Liang Y, Feng S, Liu Q, et al. Exploring contextual relationships forcervical abnormal cell detection[J]. IEEE J Biomed Health Inform,2023, 27(8): 4086-97.
[19]Cai Z, Vasconcelos N. Cascade R-CNN: Delving into high qualityobject detection[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition. 2018: 6154-62.
[20]He K, Gkioxari G, Doll'ar P, et al. Mask R-CNN[C]. Proceedings ofthe IEEE International Conference on Computer Vision. 2017:2961-9.
[21]Yi L, Lei Y, Fan Z, et al. Automatic detection of cervical cells usingdense-cascade R-CNN[C]. Pattern Recognition and ComputerVision: Third Chinese Conference, PRCV 2020, 2020, Proceedings,Part II 3. Springer International Publishing, 2020: 602-13.
[22]Ma B, Zhang J, Cao F, et al. MACD R-CNN: an abnormal cellnucleus detection method[J]. IEEE Access, 2020, 8: 166658-69.
[23]Redmon J, Divvala S, Girshick R, et al. You only look once: unified,real-time object detection[C]. Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition. 2016: 779-88.
[24]Xiang, Y, Sun W, Pan C, et al. A novel automation-assisted cervicalcancer reading method based on convolutional neural network[J].Biocybernet Biomed Engin, 2020, 40(2): 611-23.
[25]Liang Y, Pan C, Sun W, et al. Global context-aware cervical celldetection with soft scale anchor matching[J]. Comput MethodsPrograms Biomed, 2021, 204: 106061.
[26]Jia D, He Z, Zhang C, et al. Detection of cervical cancer cells incomplex situation based on improved YOLOv3 network [C].Multimed Tools Appl, 2022, 81(6): 8939-61.
[27]Fei M, Zhang X, Cao M, et al. Robust cervical abnormal cell detection via distillation from local-scale consistency refinement [C]//International Conference on Medical Image Computing andComputer-Assisted Intervention. Cham: Springer Nature Switzerland,2023: 652-61.
[28]Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense objectdetection[C]//Proceedings of the IEEE International Conference onComputer Vision. 2017: 2980-2988.
[29]Srinivas A, Lin T Y, Parmar N, et al. Bottleneck transformers forvisualrecognition[C]//Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition. 2021: 16519-16529.
[30]Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attentionmodule[C]//Proceedings of the European Conference on ComputerVision (ECCV). 2018: 3-19.
[31]Duan S, Zhang M, Qiu S, et al. Tunnel lining crack detection modelbased on improved YOLOv5[J]. Tunnel Underground SpaceTechnol, 2024, 147: 105713.
[32]Song C Y, Zhang F, Li J S, et al. Detection of maize tassels for UAVremote sensing image with an improved YOLOX model[J]. J IntegrAgric, 2023, 22(6): 1671-83.
摘要:目标 建立一种新的基于全局-局部注意机制和YOLOv5的宫颈病变细胞检测模型(Trans-YOLOv5),为准确、高效地分析宫颈细胞学图像并做出诊断提供帮助。方法 使用共含有7410张宫颈细胞学图像且均包含对应真实标签的公开数据集。采用结合了数据扩增方式与标签平滑等技巧的YOLOv5 网络结构实现对宫颈病变细胞的多分类检测。在YOLOv5 骨干网络引用CBT3 以增强深层全局信息提取能力,设计ADH检测头提高检测头解耦后定位分支对纹理特征的结合能力,从而实现全局-局部注意机制的融合。结果 实验结果表明Trans-YOLOv5优于目前最先进的方法。mAP和AR分别达到65.9%和53.3%,消融实验结果验证了Trans-YOLOv5各组成部分的有效性。结论 本文发挥不同注意力机制分别在全局特征与局部特征提取能力的差异,提升YOLOv5对宫颈细胞图像中异常细胞的检测精度,展现了其在自动化辅助宫颈癌筛查工作量的巨大潜力。
关键词:宫颈细胞图像异常检测;YOLOv5;图像处理;全局和局部特征融合
基金项目:国家自然科学基金(82172020)
猜你喜欢
制造技术与机床(2018年12期)2018-12-23 02:40:52
电子制作(2018年18期)2018-11-14 01:48:20
中国公共安全(2017年8期)2017-10-13 08:12:21
中国公共安全(2017年8期)2017-10-13 08:12:20
电气化铁道(2016年4期)2016-04-16 05:59:46
河南科技(2014年1期)2014-02-27 14:04:06
