
改进DETR的无人机航拍图像沥青路面破损检测算法
2024-10-18 00:00:00李思宏姬书得任赵旭
郑州航空工业管理学院学报 2024年5期
关键词:目标检测



摘 要:针对航拍沥青路面图像数据不足、检测精度低、存在漏检的问题,研究提出一种改进的DETR(Detection Transformer)端到端沥青路面破损检测模型。该模型采用ResNet50提取特征,引入SiLU激活函数提高特征提取能力,并采用多尺度融合特征图保留更多上下文语义信息;在Transformer的Encoder中使用多尺度可变形自注意力机制,加快模型收敛速度;采用CIoU损失函数提高了裂缝检测的准确性。实验结果表明:改进模型的平均精度达83.7%,比DETR模型在精确率上提高7.4%,召回率上提升了10.9%。提出的改进模型可对沥青路面破损进行有效检测,可为航拍图像的沥青路面破损检测提供参考。
关键词:破损检测;可变形自注意力;多尺度融合;CIoU;目标检测
中图分类号:U418,TP751 文献标识码:A 文章编号:1007 - 9734 (2024) 05 - 0050 - 08
DOI:10.19327/j.cnki.zuaxb.1007-9734.2024.05.007
0 引 言
截至2022年,我国高速公路里程已达16.9万公里,沥青路因为具有抗压强度高、寿命长等优点,在高速路中占比超过90%[1]。沥青路面破损检测是路面养护和维护中非常重要的一环。随着运营年限的增加,若不及时修复路面破损会造成更大的危害。
路面破损分为两大类:裂缝破损与坑槽破损[2]。传统的路面破损检测以人工检测为主,该方法存在检测精度低、效率慢、作业时风险系数大的缺点[3]。随着无人机航拍、计算机视觉及深度学习的不断发展,基于航拍图像的方法被广泛应用于沥青路面破损检测[4-6]。无人机通过搭载高清相机、激光雷达、测量模块等,能够应对复杂的道路环境和天气条件,还能高效、准确地获取道路裂缝图像信息,并结合分类算法、语义分割及目标检测等技术进行自动化分析和识别[7-10],可以提高沥青路面破损检出率,保证高速路行车安全。
路面裂缝存在无固定形状、尺寸差异大的特点,是路面破损检测领域的研究重点。对图像进行裂缝检测的方法可分为两类,即图像处理法与深度学习法。张文静将航拍图像预处理、精处理再经过支持向量机分类,实现横向裂缝、纵向裂缝、斜向裂缝的线性分类[11]。Fang等对沥青图像进行阈值去噪、高斯滤波操作,将投影特征和裂纹像素特征经过支持向量机(Support Vector Machines,SVM)处理,完成4种裂缝类型的分类[12]。
以上算法在数据处理时的共性问题是,彩色图像难以用单一算法处理,灰度处理难以将裂缝清晰地从背景中分离[13],深度学习可以直接对彩色图片进行裂缝检测。深度学习可将路面裂缝检测分为图像分类任务、分割任务和目标检测任务。
张伟光等在自建路面裂缝数据集上,运用卷积神经网络(Convolutional Neural Networks,CNN)与多层感知机神经网络模型对路面裂缝进行分类研究[14]。Hong等将医学领域的U-Net算法引入路面裂缝分割中[15],所提出的方法能够有效分割航拍图像中的裂缝。王博对航拍图像路面裂缝检测提出新的目标检测算法[16],在数据集上对横向、纵向裂缝进行分类研究。Luo等提出STrans-YOLOX的路面裂缝检测模型[17],在公开裂缝数据上对路面裂缝进行识别。
沥青路面坑槽检测可分为三类:振动检测法、三维重建法、视觉检测法。振动检测法操作简单但可靠性差;三维重建法检测效果好,但检测范围小、成本高;视觉检测法则具有测量范围广、成本低、灵活度高等优点。坑槽缺陷因目标小、数量少因此成为检测领域的难点。Ozoglu提出用CNN识别振动传感器异常振动数据转的方式,将道路数据转化为像素识别[18]。Vinodhini等在航拍数据集中提出CNN与Transformer相结合的方法,并将卷积网络与动态特征相融合,提高网络的全局搜索能力,所提出的方法优于图神经网络。赵璐璐针对小目标坑槽误检、漏检的问题,在YOLO v7网络中引入SE注意力机制并用EIoU替换原损失函数,改进后网络平均精度提升1.9%[20]。
通过对沥青路面破损检测领域的相关研究分析,发现仍存在以下几个问题:(1)图像处理需要对彩色图像灰度化,受复杂背景环境影响,抗噪性能较差;(2)现有的深度学习模型需要根据不同的路面裂缝进行人工干预,例如需要预先设置先验框;(3)路面破损主要集中在裂缝类型,严重的裂缝会导致坑槽缺陷,受坑槽缺陷图片数量影响仅有少部分学者对路面坑槽进行视觉检测研究。
综上所述,通过对航拍沥青路面破损图像进行进一步研究,扩充航拍坑槽数据图像,本文制作了四种缺陷类型的数据集,提出端到端的目标检测模型,去除掉了先验框和非极大值抑制,改进DETR(Detection Transformer)检测模型,在Resnet50中使用SiLU激活函数、改进多尺度融合特征图、引入多头可变形自注意力机制、替换CIoU损失函数,优化原目标检测算法的性能、保留路面破损浅层语义信息、增强不同尺度破损特征信息的融合、提高小目标坑槽的检测准确率。
1 DETR网络
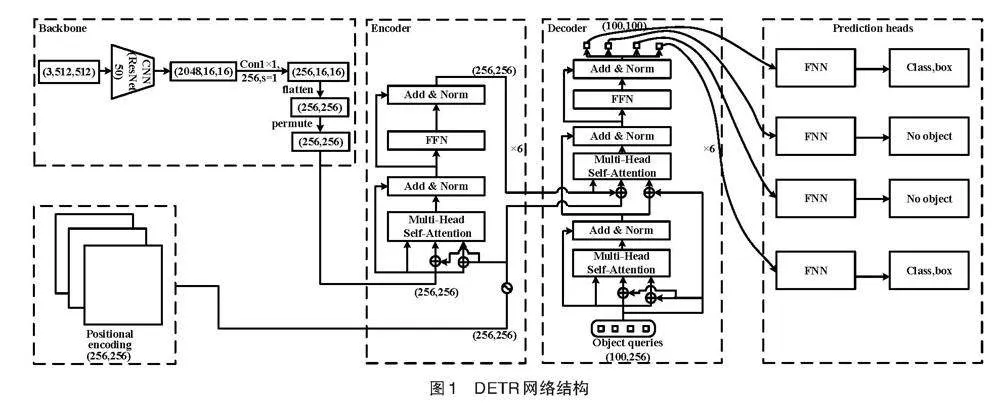
DETR将目标检测看作一个集合预测任务,如图1所示。DETR的网络结构主要由4个模块组成:CNN、位置编码(Positional Encoding)、编码器(Encoder)、解码器(Decoder)和预测头(Prediction Heads)。DETR的预测流程分为4步:首先将输入的图片经过CNN特征提取网络处理后得到特征图,然后将特征图展平为一个带有空间位置编码的序列,与位置编码一起送入编码器中,编码器的输出再加上目标查询结果(Object Query)分别送入解码器中,最后将解码器的输出送入预测头中,即可得到预测框和类别[21]。
1.1" 特征提取网络
1.1.1 ResNet50
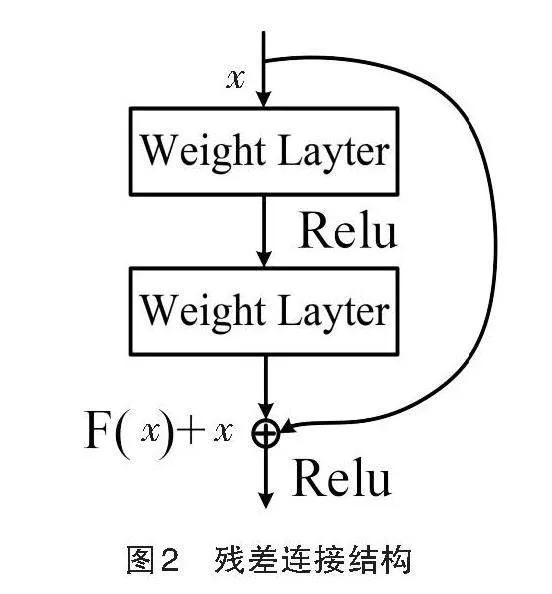
CNN网络主要用于提取特征,但随着网络结构的加深,训练损失的增加将造成精度迅速下降。ResNet网络的深度残差网络结构可以解决CNN网络的退化问题。在ResNet网络中,采用了残差连接来执行恒等映射,残差块的输出被添加到堆叠层的输出中。残差块上一层网络的输出值x通过第一权重层后经过ReLU激活函数进入第二权重层。第二权重层输出后的残差映射F(x)加入输入x的恒等映射,即可得到理想映射F(x)+x,残差结构连接如图2所示。
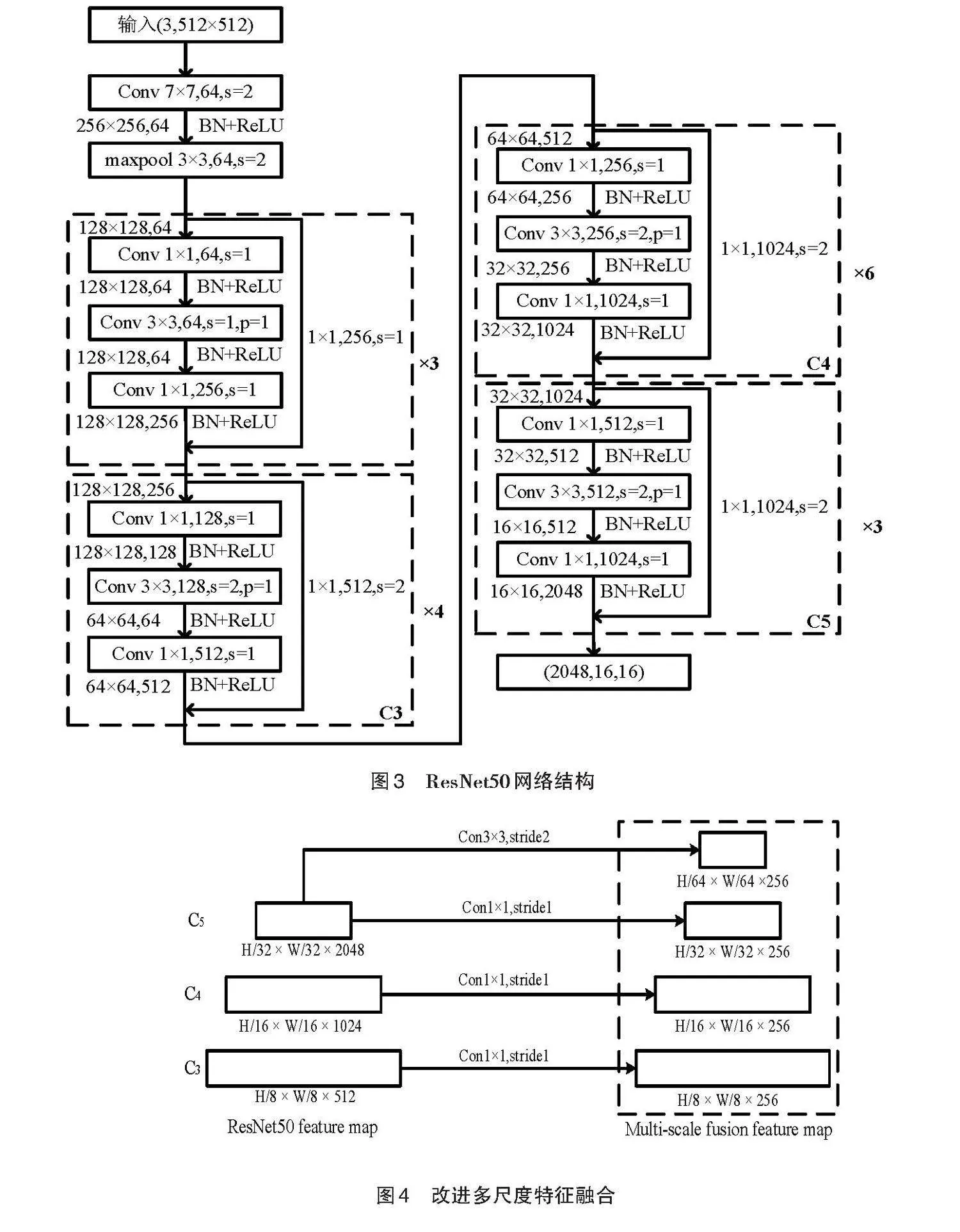
在ResNet的所有网格类型中,ResNet50网络具有比ResNet18、ResNet34更深的网络结构以及比ResNet101更高的执行效率。因此本文采用ResNet50网络来做特征提取,网格结构如图3所示。
在ResNet50网络中,最后一层的输出和位置编码一起传入编码器中,这种方法增大了特征图的感受野,然而降采样的过程会造成过多细节信息的丢失。因此,改进模型引入多尺度信息融合的特征提取方式,如图4所示。通过将ResNet50网络的C3、C4特征图分别经过1×1的卷积,C5阶段的特征图经过1×1及3×3步长为2的卷积得到多尺度融合特征图,改进后的多尺度融合特征图在保留原有感受野的同时保留了更多的细节信息。
1.1.2 引入SiLU
本文所使用的航拍图像的信噪比介于14.35 dB至15.8 dB之间。为提高模型的性能和鲁棒性,在ResNet50网络中引入SiLU激活函数。ReLU函数和SiLU激活函数表达式如(1)(2)所示。
[ReLUx=max0,x] (1)
[SiLUx=x*11+e-x] (2)
从图5可以看出,ReLU函数在输入为负数时会输出0,输入为0时导数不存在,而SiLU函数在整个输入范围内都具有非零输出,导数在整个输入范围内均存在,如图5所示。这意味着SiLU的引入可以在ResNet50网络中改善模型的性能,尤其是在低信噪比或低对比度的情况下。
1.2" 多尺度可变形自注意力机制
DETR模型使用多头注意力机制,在模型训练时需要消耗大量的计算资源。改进模型引入局部注意力机制,采用可变形注意力模块来关注参考点周围的关键采样点,增加了小目标检测的精度并加快模型收敛速度。
改进模型的Transformer由可变形编码器和解码器两个部分组成。Transformer的可变形编码器部分接收输入的图像特征和sin函数的绝对位置编码信息,然后进入一个由多个相同结构的编码器层堆叠而成的循环结构。每个编码器层由多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Neural Network)组成。在每个编码器层中,输入的特征经过自注意力机制进行加权和整合,然后通过前馈神经网络进行非线性变换。最后,将经过前馈神经网络的输出与输入进行残差连接和归一化,得到编码器层的输出。
Transformer模型的核心是自注意力机制,表达式如公式(3)所示。
[MultiHeadAttnzq,x=]
(3)
改进模型提出多尺度可变形自注意力模块对原多头注意力检测模块进行改进,使模型可以有效利用改进后的ResNet50多尺度特征图,改进的多头可变形自注意力定义如公式(4)所示。
[MSDeformAttnzq,pq,x=][m=1MWmk=1kAmqk⋅WmX(pq+∆pmqk)] (4)
式(4)中:zq为输入的原始特征,pq为当前参考点的归一化坐标,x为特征图编号,Wm为多头注意力,m为注意力编号,k为当前采样点编号,K是总采样键数,[Wm]为固定单位矩阵,[∆pmqk]和Amqk表示第m个注意力头中第k个采样点的采样偏移量和注意力权重[22]。
1.3" 损失函数
在DETR模型中,使用GIoU作为定位损失函数,GIoU并未考虑预测框与真实框的中心点与纵横比,因此当预测框与真实框出现包含关系时,会出现退化及收敛慢的现象。
针对GIoU出现的退化现象,改进模型提出CIoU损失函数,以便在检测任务中更准确地反映目标框之间的相似度,CIoU结构如图6所示。CIoU损失是一种用于目标检测的改进型IoU损失函数,相比于传统的IoU损失函数和GIoU损失函数,CIoU损失函数在计算目标框之间的距离时,不仅考虑了目标框之间的中心点距离、目标框的长宽比和重心距离等因素,而且能够更好地区分错位、大小不同的目标框。
CIoU定位损失的公式如(5)(6)(7)所示。
[LCloU=1-LIoU+d2c2+av] (5)
[v=4p2arctanwgthgt-arctanwh]" (6)
[a=v1-LloU+v] (7)
LCIoU代表CIoU损失函数值,LIoU代表真实框与预测框的交并比,d代表真实框中心点与预测框中心点的欧式距离,c代表真实框与预测框最小闭包区域的对角线长度,v是衡量真实框与预测框宽高比一致的参数,wgt、hgt、w、h分别代表真实框的宽度、真实框的高度、预测框的宽度、预测框的高度,a是长宽比一致的权衡函数。
2 实验数据
2.1" 实验数据概况
数据集采用Hong[15]开源的数据图像,采集于2020年1月9日,中国新疆维吾尔自治区喀什地区,无人机的图像分辨率为512×512,飞行高度200米。数据集含扩充后图像2876张,将破损类型划分为4类:横向裂缝、纵向裂缝、斜向裂缝、坑槽,如表1所示。横向裂缝为道路裂缝垂直于行车线的裂缝,纵向裂缝为道路裂缝平行于行车线的裂缝,斜向裂缝指与行车线存在较大角度的裂缝,坑槽是使路面凹陷的缺陷类型。
2.2" 数据增强
以LabelImg软件为标注工具,标注路面破损数据集。实验证明数据增强可以增加深度学习的数据量并提高深度网络的泛化能力。本文采用的数据增强的方法有缩放、翻转、旋转、改变亮度和outcut来模拟过路汽车遮挡的情况,使数据量扩充一倍,增强后的图像如图7所示。破损检测数据集按照7:2:1的比例,划分为训练集、验证集、测试集。
2.3" 模型评价指标
采用IoU gt; 0.5时,精确率(Precision,P)、召回率(Recall,R)、各类别平均精度(Mean Average Precision,mAP)、F1分数(F1 Score,F1)和像素小于32×32的小目标检测精度(AP50:90S)5个指标来评估模型的性能。
精确率P和召回率R的计算如公式(8)(9)所示,精确率为真正例样本占预测结果为正例样本中的百分比,召回率为在全部正例中,被正确预测为真正例的百分比。
[P=TPTP+FP×100%] (8)
[R=TPTP+FN×100%] (9)
TP为检测框和真实框IoU ≥ 0.5的数量,即正确检测到裂缝的数量;FP是检测框和真实框IoU lt; 0.5的数量,即错误检测裂缝的数量;FN为没有检测到裂缝的数量,即漏检的裂缝的数量。
AP表示以召回率R、精确率P为横纵坐标构成的曲线以下部分所围成的面积,各类别精度的均值mAP对应的计算方法如公式(10)所示。
[mAP=1ci=1c01PRdR] (10)
式中:c为图像总类别数,i为检测次数。
F1是多分类问题的最终评价指标,它是精确率和召回率的调和平均数。
[F1=2×P×RP+R] (11)
3 实验与分析
3.1" 实验验证
实验平台在Ubuntu 20.04系统上,硬件设备处理器采用英特尔Core(TM) i9-10900K,内存为16G,图形处理器GPU为NVIDIA GeForce GTX3070显卡,具有8G显存。在试验训练过程中,训练轮数设为300轮,采用AdamW优化器,ResNet50网络学习率为0.00001,主干网络学习率设为0.0001,batches为2。在测试数据集上对DETR及改进模型作纵向对比实验,并与主流CNN算法模型作横向对比实验。
3.2" 消融实验
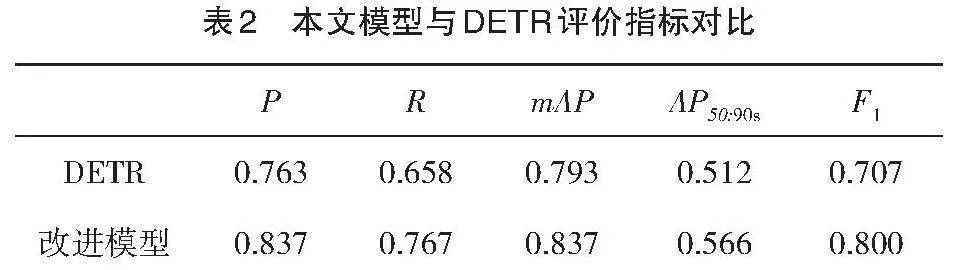
对DETR模型与本文提出的改进模型作对比实验,评价指标如表2所示。
从表2看出,本文提出的模型在采用的评价指标上均优于DETR,其中改进之后的模型在精确率P上提升7.4%,在召回率R上提升了10.9%,平均精度提升了4.4%,小目标检测精度提升了5.4%,F1提升了0.093。
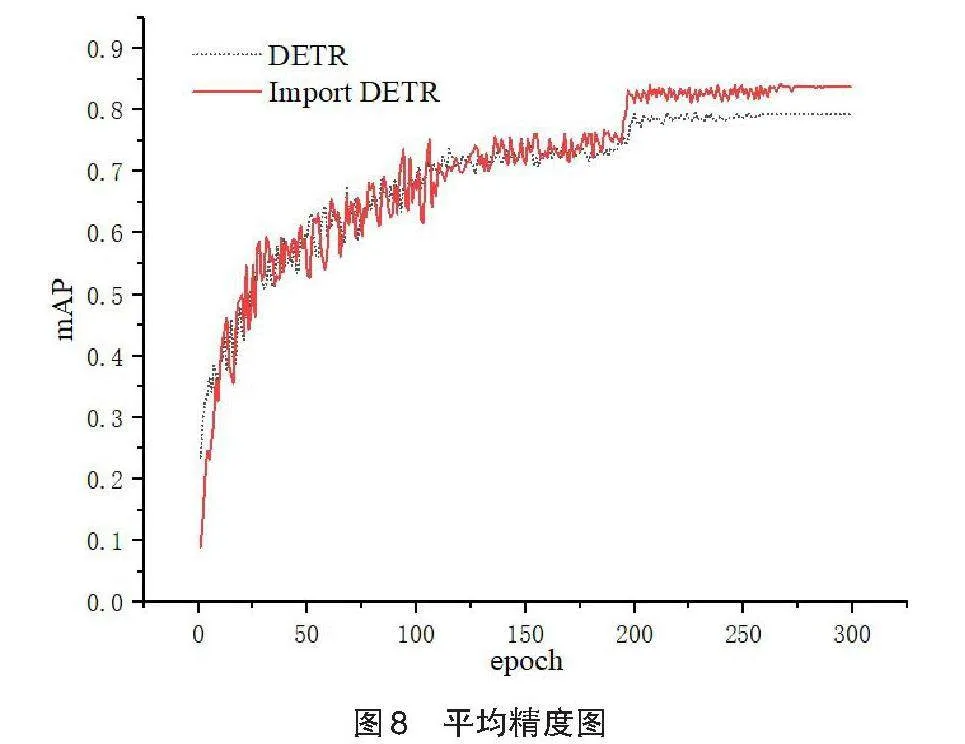
训练平均精度如图8所示,横坐标代表训练轮数,纵坐标代表平均精度。从图中可以看出,DETR模型使用了预训练权重,初始精度远高于改进模型,经过200轮的训练之后,两种模型的精度快速上升,最终改进模型的平均精度比DETR模型高0.044。
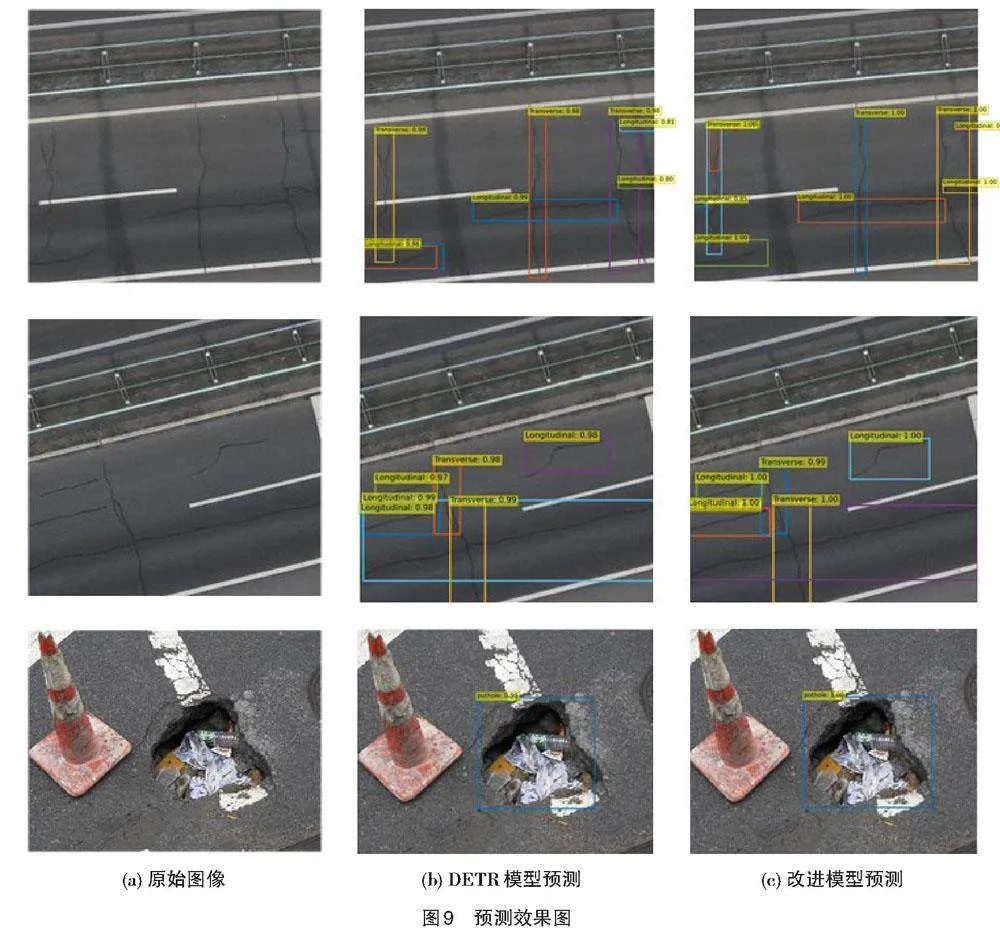
为了直接观察模型的提升效果,在测试集中选取三张典型的图像进行分析,在DETR与本文模型训练权重中选取最优训练权重进行沥青路面破损检测,检测效果如图9所示。
图9中最左侧为航拍原始图像,中间为DETR模型预测效果,右侧为改进之后的模型预测效果。从三张效果图可以看出,两种模型均能正确区分检测类别,改进之后的模型在定位精度上优于原模型。DETR模型在小目标检测上存在漏检的情况,当预测框密集时出现漏检现象。改进之后的模型,将图中的小目标全部检出并无重检、漏检的现象,且在定位上更为精确。
3.3" 算法对比
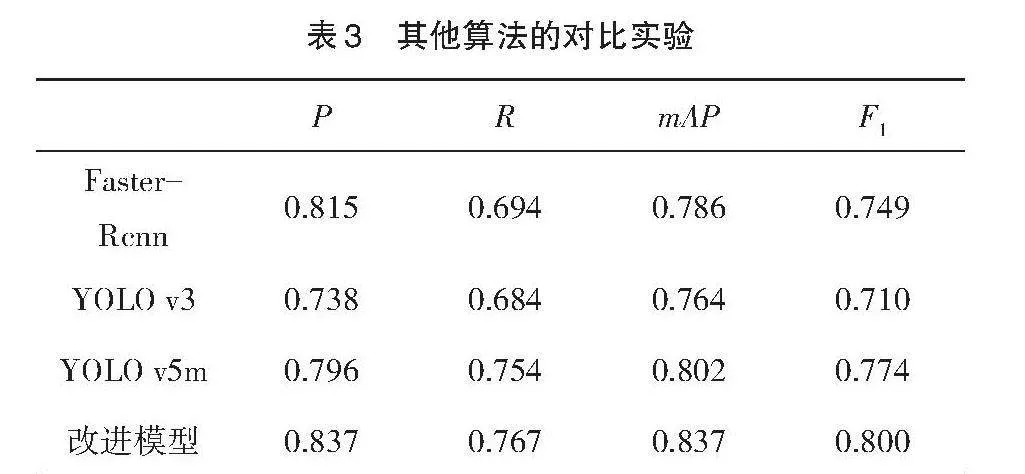
通过对比Faster-Rcnn、YOLO v3、YOLO v5m模型,在裂缝检测数据集上做对比实验。模型对比实验评价指标如表3所示。
由表3可以看出,对比其他三种模型,改进模型同样为最优模型。其中,YOLO v5m模型与改进模型在平均精度上均大于80%,且改进模型的平均精度最高为83.7%,比YOLO v5m、YOLOv3、Faster-Rcnn高3.5%、7.3%、5.1%。在精确率上改进模型的精确率为83.7%,优于YOLO v5m模型的79.6%、YOLO v3模型的73.8%、Faster-Rcnn模型的81.5%。改进模型在召回率上为76.7%,优于YOLO v5m模型的75.4%、YOLO v3模型的68.4%、Faster-Rcnn模型的69.4%。从F1指标中可以看出改进模型最为均衡,改进模型的F1指标为0.800,YOLO v3的F1指标最低为0.710。
4 结 论
本文在航拍的沥青路面图像上进行破损检测研究,对2876张航拍图像使用了数据增强算法,构建了四种检测类别的数据集。在此数据集上提出了端到端的深度学习网络模型,解决了航拍沥青路面破损检测时图像数据不足、检测精度低、存在漏检的问题。实验结果表明,所提出的模型较原DETR模型在平均精度上提升了4.4%,小目标检测精度提升了5.4%,并与Faster-Rcnn、YOLO v3及YOLO v5m模型对比,最终建立了最优的沥青路面破损检测模型。这些结果证明了改进模型的有效性和优越性,为从无人机航拍图像中自动检测沥青路面破损提供了一种可靠的解决方案。
参考文献:
[1]杨燕泽,王萌,刘诚,等.基于语义分割的沥青路面裂缝智能识别[J].浙江大学学报(工学版),2023,57(10):2094-2105.
[2]LIU W,LUO R,XIAO M,et al.Intelligent detection of hidden distresses in asphalt pavement based on GPR and deep learning algorithm[J].Construction and Building Materials,2024,4116:135089.
[3]MUNAWAR H S,HAMMAD A W,HADDAD A,et al.Image-based crack detection methods:a review [J].Infrastructures,2021,6(8):115-143.
[4]ELAMIN A,RABBANY E A.UAV-based image and lidar fusion for pavement crack segmentation[J].Sensors,2023,23(23):9315-9331.
[5]SUJONG K,DONGMAHN S,SOOBIN J.Improvement of tiny object segmentation accuracy in aerial images for asphalt pavement pothole detection[J].Sensors (Basel,Switzerland),2023,23(13):5815-5829.
[6]LI D,DUAN Z D,HU X Y,et al.Automated classification and detection of multiple pavement distress images based on deep learning[J].Journal of Traffic and Transportation Engineering (English Edition),2023,10(2):276-290.
[7]苑玉彬,吴一全,赵朗月,等.基于深度学习的无人机航拍视频多目标检测与跟踪研究进展[J].航空学报,2023,44(18):6-36.
[8]PARK Y,SHIN Y.Applying object detection and embedding techniques to one-shot class-incremental multi-label image classification[J].Applied Sciences,2023,13(18):10468-10489.
[9]THISANKE H,DESHAN C,CHAMITH K,et al.Semantic segmentation using vision transformers:A survey[J].Engineering Applications of Artificial Intelligence,2023(126):106669.
[10]ZOU Z,SHI Z,GUO Y,et al.Object detection in 20 years:a survey [J].Proceedings of the IEEE,2023,111(3):157-276.
[11]张文静.基于无人机影像的道路裂缝类型识别方法研究[D].石家庄:河北师范大学,2020.
[12]FANG H,HE N.Detection method of cracks in expressway asphalt pavement based on digital image processing technology[J].Applied Sciences,2023,13(22):12270-12287.
[13]马晓忠,李雪莹.无人机技术在路面裂缝检测中的应用[J].北方交通,2022(10):29-31.
[14]张伟光,钟靖涛,于建新,等.基于机器学习和图像处理的路面裂缝检测技术研究[J].中南大学学报(自然科学版),2021,52(7):2402-2415.
[15]HE X Y,TANG Z W,DENG Y B,et al.UAV-based road crack object-detection algorithm[J].Automation in Construction,2023(154):105014.
[16]王博.航拍图像路面裂缝检测研究[D].北京:北京理工大学,2017.
[17]LUO H,LI J M,CAI L M,et al.Strans-YOLOX:fusing swin transformer and YOLOX for automatic pavement crack detection[J].Applied Science,2023,13(3):1999-2027.
[18]OZOGLU F,GOKGOZ T.Detection of road potholes by applying convolutional neural network method based on road vibration data[J].Sensors,2023,23(22):9023-9042.
[19]KANCHI A V,KOCILVENNI R A S.Pothole detection in bituminous road using CNN with transfer learning[J].Measurement:Sensors,2024,31:100940.
[20]赵璐璐.基于深度学习的路面坑槽检测研究[D].西安:长安大学,2023.
[21]杜宇峰,黄亮,赵子龙,等.基于DETR的高分辨率遥感影像滑坡体识别与检测[J].测绘通报,2023(5):16-20.
[22]樊嵘,马小陆.面向拥挤行人检测的改进DETR算法[J].计算机工程与应用,2023,59(19):159-165.
责任编校:陈 强,裴媛慧
Improved DETR Algorithm for Asphalt Pavement Damage Detection in UAV Aerial Images
LI Sihong, JI Shude, REN Zhaoxu
(Shenyang Aerospace University,Shenyang 110136,China)
Abstract:Aiming at the problems of insufficient data,low Detection accuracy and missed detection of aerial images of asphalt pavement,an improved DETR(Detection Transformer) end-to-end asphalt pavement damage detection model is proposed.Firstly,the model uses ResNet50 to extract features,introduces the SiLU activation function to improve feature extraction ability,and uses a multi-scale fusion feature map to retain more context semantic information.Secondly,the multi-scale deformable self-attention mechanism is used in the Transformer Encoder to accelerate the convergence speed of the model.Finally,the CIoU loss function is used to improve the accuracy of crack detection.The experimental results show that the average precision of the improved model is 83.7%,which is 7.4% higher than that of the DETR model,and the recall rate is increased by 10.9%.The proposed improved model can effectively detect asphalt pavement damage,which can provide a reference for the detection of asphalt pavement damage in aerial images.
Key words:damage detection; deformable self-attention; multi-scale fusion; CIoU; object detection
收稿日期:2024-04-12
基金项目:面向复杂环境的轮式自主跟随机器人关键技术研究(20230078)
作者简介:李思宏,山东烟台人,硕士,研究方向为航空智能装备试验技术。
姬书得,辽宁沈阳人,教授,主要研究方向为航空智能装备试验技术。
猜你喜欢
科技创新与应用(2016年36期)2017-02-21 18:48:01
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
无线互联科技(2016年7期)2016-05-30 13:57:06
电脑知识与技术(2016年5期)2016-04-14 13:48:16
科技视界(2016年4期)2016-02-22 13:09:19
哈尔滨理工大学学报(2015年5期)2016-01-19 18:06:12
湖南大学学报·自然科学版(2015年10期)2015-11-30 18:52:07
现代电子技术(2015年20期)2015-10-26 22:48:16
