
考虑商品互补替代关系和序列模式的推荐算法
2024-09-30 00:00:00任志波戎秀玲宋欣欣
河北大学学报(自然科学版) 2024年5期
关键词:个性化推荐






摘" 要:用户真实的购买场景中,购物不仅仅看兴趣,当下以及未来需求也很重要,而现有大部分推荐方法研究的是挖掘用户近期兴趣,较少从商品间的关系来研究用户潜在需求.为了提高推荐算法准确性,丰富推荐种类,本文将商品互补替代关系特征和购买先后序列模式融入到推荐算法中,提出一种考虑商品互补替代关系和购买序列模式来研究用户潜在需求的推荐算法,该算法在亚马逊公开数据集Grocery上进行验证,并与相关算法进行对比,结果表明所提算法在命中率HR(hits ratio)和归一化折损累计增益NDCG(normalized discounted cumulative gain)指标上均得到有效的改进.
关键词:互补搭配;序列模式;个性化推荐
中图分类号:N32""" 文献标志码:A""" 文章编号:10001565(2024)05055110
DOI:10.3969/j.issn.10001565.2024.05.012
Recommendation algorithm considering complementation, substitution relation and sequence pattern of goods
REN Zhibo1,RONG Xiuling1,SONG Xinxin2
(1.Comprehensive Experiental Center, Hebei University, Baoding 071002, China;
2.Dancing College, Xinjiang Arts University, Urumchi 830000, China)
Abstract: In the real purchasing scenario of users, shopping is not only based on interests, but also on current and future needs. However, most of the existing recommendation methods focus on mining users recent interests, and rarely study users potential needs from the relationship between products. In order to improve the accuracy of the recommendation algorithm and enrich the types of recommendation, this paper integrates the characteristics of commodity complementary substitution relationship and purchase sequence pattern into the recommendation algorithm, and proposes a recommendation algorithm that considers the commodity complementary substitution relationship and purchase sequence pattern to study the potential needs of users. The algorithm is verified on Amazon public data set Grocery. Compared with the relevant algorithms, the results show that the proposed algorithm is effectively improved in hits Ratio HR(hits ratio) and normalized discounted cumulative gain (NDCG).
Key words: complementary pairing; sequence mode; personalized recommendations
现有个性化推荐算法在电商平台应用时,多关注用户的购买历史、浏览评论记录、社会关系等,例如姜久雷等[1]提出的融合信任度的神经网络推荐算法;冯兴杰等[2]提出的利用深度学习提取评论的优势提取用户和商品的一般偏好,并进行特征融合来提升推荐效果的推荐算法;于健等[3]提出的挖掘用户社交关系中显性和隐性朋友信息,并利用注意力机制获取基于社交关系的用户表征进行推荐的算法,这些推荐算法经过验证
收稿日期:20230913;修回日期:20240604
基金项目:
河北省社会科学基金资助项目(HB19Q011)
第一作者:任志波(1971—),男,河北大学教授,博士,主要从事个性化推荐算法、数据挖掘方向研究.E-mail:renzhibo@hbu.edu.cn
通信作者:宋欣欣(1998—),女,新疆艺术学院助教,主要从事个性化推荐算法方向研究.E-mail:1244879013@qq.com
都能一定程度上有效提高推荐准确性,它们挖掘以用户特征为中心的信息使用,向用户推荐的是与其兴趣相似的用户近期浏览的商品,认为这是用户的兴趣所在.然而根据这样的算法推荐往往存在可能会向用户频繁推荐不再需要的商品,甚至用户逐渐接收到的都是自己或周围朋友已经购买的相似的商品,想要寻找新的个性的商品反而变得困难.提高推荐算法准确性,增加推荐项目丰富度是推荐算法领
域的研究热点.考虑推荐与用户已购买的物品存在一定属性关系的商品,尤其是商品间的互补替代关系,这是非常值得关注的一个研究方向.商品搭配推荐是一种新的个性化推荐方法,它从消费者行为中提取信息,丰富了推荐种类,比相似推荐的准确性更高.有关产品搭配推荐的方法最早可以追溯到2000年Han等[4]提出的频繁项集挖掘,通过购买历史记录挖掘频繁一起购买的商品组合,生成搭配关系,最成功的经典案例就是“尿布”和“啤酒”.随后,Ma等[5]通过深度学习系统深入分析了不同元素商品间的可搭配程度,以大量搭配图片数据库为支撑,同调研各大电商平台可搭配单品推荐方式,形成搭配推荐.2019年,Ma等[6]提出将电商平台记录中的用户“共同购买”和“共同浏览”的历史记录分别作为功能相互补充的商品和相互替代的商品,然后利用监督学习算法识别商品间的关系从而做出推荐.
同时,商品购买和使用会有一种先后关系,这种顺序关系可以用序列模式表示,向用户推荐相应的物品.许多领域的个性化推荐中都已经用到了序列模式.如Mishra等[7]在2015年就提出顺序信息在决定用户兴趣方面起着重要作用,并基于用户网页浏览序列和内容相似性进行信息个性化推荐;Salehi等[8]使用学习者获取材料的历史顺序模式,发现访问材料的潜在模式,并将其运用于推荐;2019年阿里巴巴的Zhou等[9]提出了DIN模型的演化版本DIEN.在推荐算法中加入序列模式优化推荐结果,可以避免倾向于向购买了鼠标的用户推荐电脑,向买了高级课程的用户推荐入门课程等无效推荐.
在前人研究的基础上,本文综合了文献[10-12]的研究,在图神经网络学习用户项目图、社交关系图特征进行推荐的基础上增加了利用TransE算法学习商品互补替代关系图特征,将用户购买互补替代品的时间变化影响以权重的形式加入项目特征的学习中,得到了更为准确的项目关系特征向量表示,通过数据挖掘得到商品购买先后顺序的二项序列模式,对推荐结果进行重新分配权重计算,得到了更优的推荐列表,避免推荐用户不需要的商品,最后通过实验验证模型两方面改进相比前人算法取得了更好的结果.
1" 预备知识
1.1" 图神经网络推荐算法
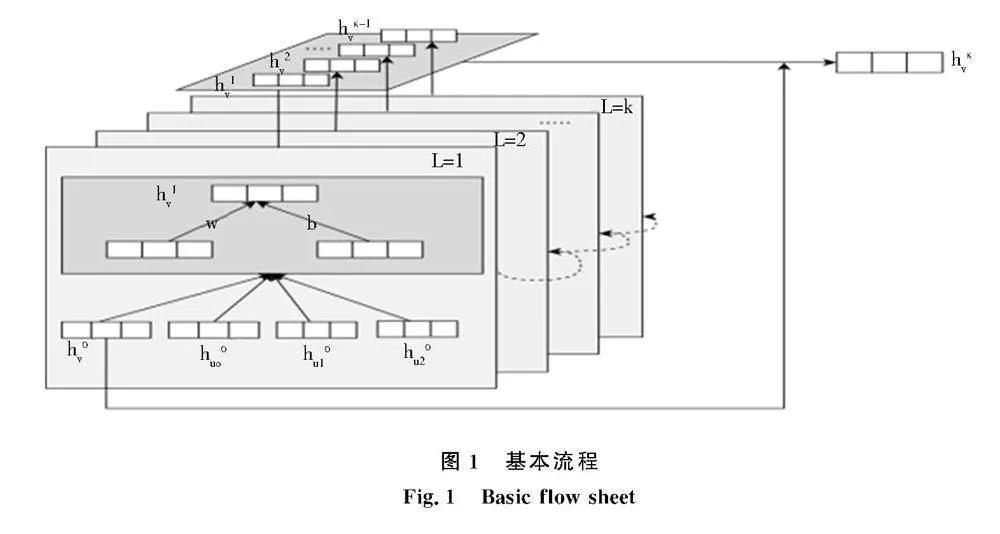
图神经网络(graph neural networks,GNN)是能够学习图数据的深度网络,其主要思想是通过神经网络不断迭代,让图中每个节点都包含整个图所有节点的特征信息.每个节点每一次迭代都会将邻接节点的信息更新到目标节点信息上,这些节点信息就通过转换聚合后在图上进行传播,即使是最边缘的节点的信息也能更新到每个节点上[13].对于节点如何获取它的所有邻居节点的信息,最基本的想法就是采用平均法.基本流程如图1所示.
具体表达如下:
hkv=xvk=0
σ(Wk∑u∈N(v)hk-1u|N(v)|+Bkhk-1vk>0,(1)
其中:xv表示图嵌入技术将图转换到低维空间得到的节点初始特征;hkv表示节点v在当前(第k层)的特征向量;hk-1v为上层神经网络节点的嵌入特征向量;N(v)是节点u的邻居节点v的集合;σ是激活函数;Wk、Bk是图神经网络的权重和偏置.
1.2" TransE算法
在实际中,不同图网络的边往往会蕴含不同类型的关系,Bordes等[14]在2013年提出TransE算法,该算法解决了图上不同关系数据节点(multi-relational data)的处理学习问题,是一种典型的知识图谱的嵌入技术.具体来说,TransE算法将图结构视为许多个三元组实例(head、relation、tail)集合,图结构中关系的向量表示被认为是头实体向量到尾实体向量的翻译.通过不断调整h、r、t即(head、relation、tail)的向量表示,使head向量和relation向量之和尽可能接近tail向量,即满足h+r=t.如图2所示.
TransE训练算法通过定义一个距离d (x,y)来表示2个向量之间的距离,一般情况下,会取L1或L2范数来衡量它们的靠近程度.对一个正确的三元组(h,r,t)来说,其距离d(h+r=t)越小越好,相反对于一个错误的三元组(h′,r,t′)来说距离d(h′+r=t′)越大越好,因此给出目标函数
min∑(h,r,t)∈s∑(h′,r,t′)∈s′[margin+d(h+r,t)-d(h′+r,t′)]+,
(2)
其中:margin是一个常量,代表正负样本之间的距离;[x]+表示取0和x间的较大者;d(h+r,t)代表正样本得分;d(h′+r,t′)代表负样本得分.通常添加约束以促进训练并避免过度拟合:‖h‖≤1,‖r‖≤1,‖t‖≤1.最后使目标函数(损失函数)值最小化,即正负样本分数之间的差距大于margin即可.
2" 考虑商品互补替代关系和购买序列模式的推荐算法
在FAN等[12]提出的利用图神经网络分别从社交关系和用户项目评分两方面学习用户特征和物品特征的基础模型上,加入利用TransE算法学习商品关系图得到具有物品互补替代关系特征的物品向量,对物品特征进行补充,通过评分预测模型对物品特征和用户特征进行评分预测初步得到推荐列表,最后通过挖掘的二项序列模式优化推荐结果.
2.1" 基础特征模型
从利用图神经网络和多层感知器(MLP)来学习用户项目图和用户社交关系图,到将特征信息聚合到用户特征和项目特征中,得到最终用户特征向量hi、项目特征向量Zv的基本模型如图3所示.由于学习特征过程相似仅以用户项目空间的用户特征学习为例,表达式如下:
hIi=σ(W·Aggreitems({hvi,v∈C(i)})+b),(3)
hvi=pv(svgiv),(4)
其中用户在项目空间中的特征向量最终为hIi,C(i)表示用户打分的items集合,σ是非线性激活函数,Aggreitems是聚合函数.表示2个向量间连接运算,pv表示多层感知机.sv表示项目嵌入向量,giv表示评分嵌入向量,hvi表示在用户项目空间中学习到包含对物品喜好程度的用户的特征表示.
用户对不同商品的兴趣程度不同,因此采用注意力机制使用户感兴趣的商品被赋予更高的权重,从而对用户的向量特征hIi学习做出更大的贡献.用户对不同商品的兴趣特征向量hvi连同用户的初始嵌入ui作为注意力网络函数的输入,通过训练和softmax函数归一化得到每个商品的注意力权重得分βiv,具体可以表示为
hIi=σ(W∑v∈c(i)βivhvi+b),(5)
βiv=exp(β*iv)∑v∈c(i)exp(β*iv),(β*iv=WT2·σ(W1·[hviui]+b1)+b2).(6)
2.2" 基于商品互补替代关系图的特征模型
考虑根据商品间的“共同购买”、“共同浏览”关系,将大多数人共同购买的商品当作互补品推荐,同时浏览的商品当作替代品推荐.在构建商品关系图时,首先筛选出用户至少购买过M次的商品,对数据进行预处理,减少数据稀疏性、数据噪声的影响,以避免冷启动问题,其次,在寻找具有互补关系的产品时,考虑到具有互补关系的产品更容易被共同购买或共同使用,只保留一起购买至少N次的具有不同功能的产品,这也能减少其他因素带来的随机性和噪声影响.每个产品都由一个d维隐藏向量表示,该向量将在模型训练过程中学习和更新.
2.2.1" 购买关系物品的时间函数确定
在进行推荐时与已购商品具有互补替代关系的商品随时间推移对目标项目推荐造成的影响是不能忽视的.购买时间推移造成的影响变化也因关系不同而不同.为了简单和高效的考虑时间推移的影响,只考虑用户历史购买序列中最新的关系项,时间函数fr可以直接表示为[11] fr(Sut,t,i)=∑r∈Rkir(Δtr),(7)
其中,Δtr表示与当前待推荐商品有关系r(互补c或替代s)的商品的购买时间距离最近一次购买记录的时间间隔大小.如果购买历史序列中没有与之有关系的商品购买记录,假设时间间隔为无限大(即Δtr=+∞).时间函数随时间接近零,此时相应的关系嵌入将不起作用.
时间函数的变化趋势是人为设定的,可以看作是对模型的一种人为干预.设计时需要考虑随着时间的推移购买不同关系商品的实际变化特性.例如,如图4所示,互补商品的购买预期具有较短的购买间隔,因此短期内与购买记录中的商品具有互补作用的商品在其商品嵌入向量中应该具有正的加权作用,并且这种积极影响会随着时间的推移而减弱.替代商品短期内推荐的影响极有可能会是消极的,很多时候用户短期内并不需要另一种具有类似功能的产品,在使用一段时间后,用户可能希望在产品使用寿命到期前及时更换具有相同功能的新产品,此时加权推荐替代品的影响有望由负转正[11].
因此,将互补关系的时间函数设计为具有正初始值并且衰减得较快的形式,使用均值为零的正态分布作为其时间函数;将替代关系的时间函数则设计为2个相反的正态分布作为其时间函数,表达式分别为
Kic(Δt)=N(Δt|0,σzic),(8)
Kis(Δt)=-N(Δt|0,σ2is1)+N(Δt|uzis,σxis2),(9)
其中N(Δt|0,σzic)是关于Δt的标准正态分布,均值为0,-N(Δt|0,σzis1),是短期约束(负面),叠加N(Δt|μ,σzis2)的是终身提升(正面).σzic、σzis1是正态分布的标准差.这里的参数σ与z(i)有关,z(i)表示项目i的类别.
2.2.2" 商品关系空间的物品特征
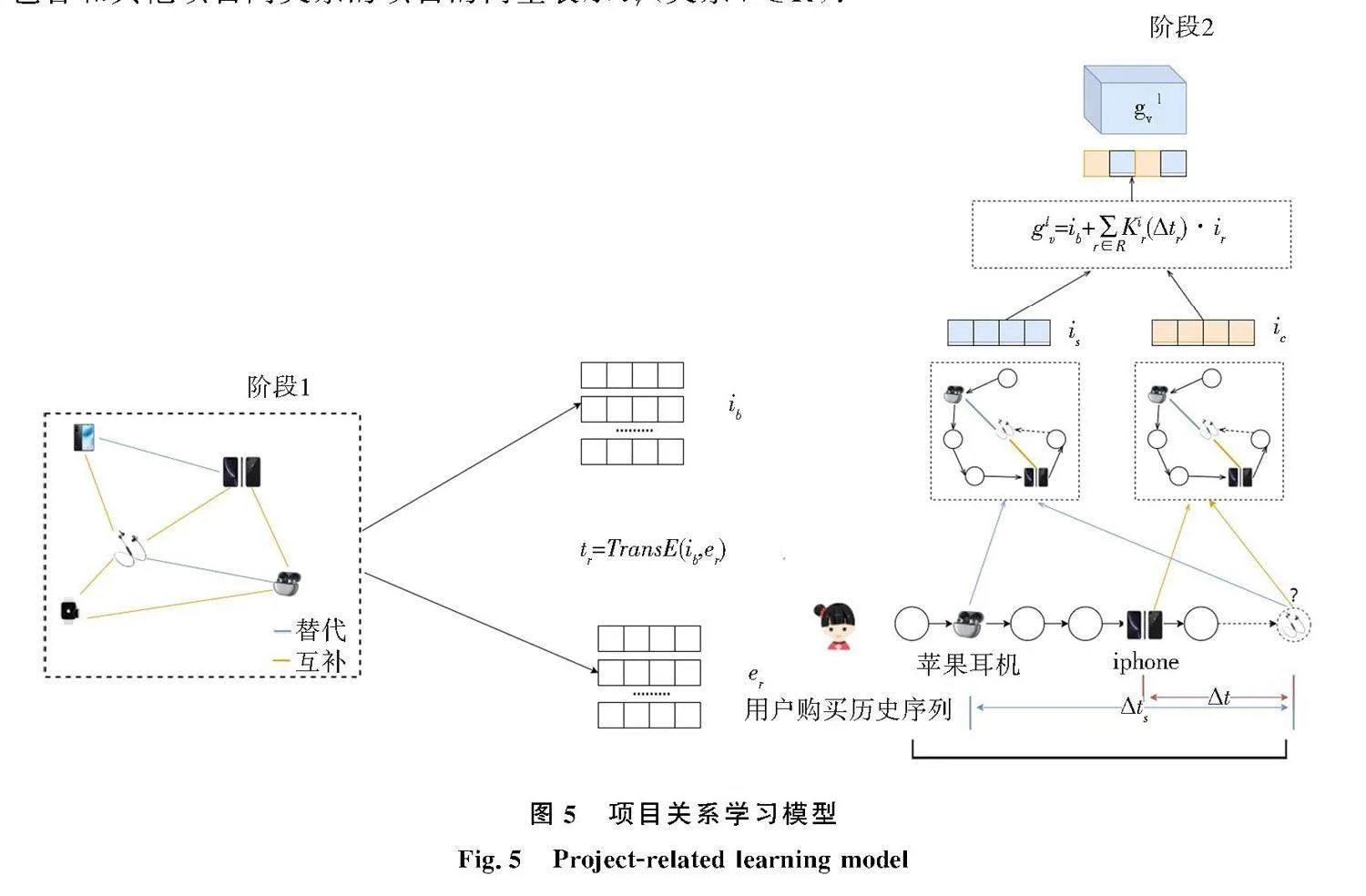
要得到商品关系空间的某物品特征,需要在商品关系网络图上将与目标商品有关系的邻居商品的特征进行聚合.三元组可以用来表示图中项目之间的互补和替代关系信息(i,r,j),其中i和j表示不同的项目,r表示它们之间的关系类型.例如,(AirPods,complementary,iPhone)表示AirPods和iPhone的互补关系.
如图5,首先从商品关系图中学习每个项目的基本项目表示和包含关系特征的项目表示.基本项目表示是对物品的固有特征进行编码,因此用项目初始化向量ib来表示物品初始嵌入,然后使用translation函数来获得包含和其他项目间关系的项目的向量表示ir(关系r∈R).
ir=TransE(ib,er),(10)
其中er是r∈R的关系嵌入.
根据不同的购买序列加权关系商品时间特性函数Kir(Δtr)得到项目关系空间的项目嵌入,具体表示如下:
glv=ib+∑r∈RKir(Δtr)·ir.(11)
2.3" 考虑关系商品购买时的先后序列模式
2.3.1" 评分预测模型
贝叶斯个性化排序(BPR)是一种过去广泛使用的矩阵分解方法[16],将推荐问题转化为排序问题,根据可观测到的正样本,从未观测到的数据中随机抽取与其对应的实例作为负样本,最后用于隐式反馈推荐.相较于传统的矩阵分解方法,BPR模型利用用户的显式行为和隐式行为之间的排名,效果相对突出.通过其进行推荐时,每个用户和商品都有一个k维的特征向量,将用户特征向量hi和物品特征向量gv和zv代入计算得到评分,计算方法如下:
p′iv=hTi(ωgv+(1-ω)zv)+bi+bv.(12)
将得到的用户向量和项目向量表示分别进行线性内积操作,考虑到包含商品购买互补替代关系的商品向量gv的影响作用和包含用户本身兴趣的商品特征zv影响不同,且希望关系商品的特征影响更突出,因此本文引入一个权重ω来调整其影响机制,公式中bi、bv分别为每个用户、每个商品的偏差向量.最后可以根据预测分数p′iv对候选项目进行排序.
为了学习推荐模型中的参数,可以通过反复训练,对排序损失函数进行如下优化[17],其中σ表示sigmoid函数,对每个训练实例随机抽取一个负项jSut.
L=-∑u∈U∑Nui=1logσ(p′iv-p′jv).(13)
将商品关系特征学习的模型与原本的基础模型进行组合后进行评分预测,得到最终的考虑商品互补替代关系的推荐算法模型如下图6所示.
2.3.2" 基于二项序列模式优化推荐结果
考虑到根据商品关系推荐时可能会存在向购买了鼠标的用户推荐电脑、向购买了高级课程的用户推荐入门课程的问题,利用Apriori关联算法[15]对商品的购买顺序进行挖掘,得到用户购物的常见序列模式,根据这些序列模式对前文推荐模型的推荐结果进行加权重排,优化推荐结果,避免向用户推荐不需要的产品.
从公开的亚马逊购物记录中挖掘购物的二项序列模式.公开数据中包括商品v、购买商品v的用户i以及购买时间.挖掘算法的步骤如下:
1)设定最小支持度为minsup,最小置信度为minconf.
2)计算产品支持度ci:计算购买每种产品的用户数量.购买产品i的用户数即为产品支持度,i∈1,2,…,M,其中i为产品类型,共有M种产品.
3)计算购买每种产品的用户数量.ci等于购买产品i的用户数量.
4)查找频繁一项集:如果ci>minsup,则第i个商品包含在频繁一频繁L1中,否则不进入L1.
5)寻找频繁二项集:将L1中的物品成对组合,ji计算先买i再买j的用户数量和先买j再买i的用户数量,如果cij和cji中仅有一个大于minsup,则对应的ij或ji组合进入频繁二项集L2.否则,不进入L2.
6)构造二项序列模式:根据各个频繁二项集ij的组合,计算候选二项式序列模式i→j或j→i的支持度conf(i→j)=cijcj.如果conf(i→j)>minconf,则将i→j添加到二项式序列模式集Sp中.否则,该序列模式不进入Sp.
7)根据二项序列模式对推荐结果进行加权重排,得到最终的TopN推荐列表.如果所选推荐项存在二项序列模式,则判断候选推荐商品是模式中的前一项还是最后一项.例如二项序列模式为A→B,待推荐商品为B,则候选推荐商品为后者,假设此时用户购买了A,则推荐B的权重增加符合二项序列模式的购买规律.如果待推荐物品为A,则候选推荐物品为序列模式的前件.假设用户已购买了B,则A的推荐权重应该按照二项序列模式降低,若用户没有购买B则说明A是根据用户近期兴趣推荐,而不是根据用户历史购买记录推荐,权重保持不变.因此,如果是后件,就加大推荐权重;否则,考察用户历史记录是否购买了后件,购买了则降低推荐权重,初始权重为1,经过加权计算和重新排序,最终得到TopN推荐列表.
8)向用户推荐TopN商品.
3" 实验数据及结果分析
3.1" 实验数据及环境
为验证算法有效性,实验数据采用亚马逊提供的开放数据集中的杂货和食品购买数据(Grocery),其中不仅包括用户交易记录和交易时间,还有用户的共同购买(also_buy)和共同浏览(also_view)记录以及用户对项目的评分记录.下表1中列出了数据集的详细信息.
实验采用Python语言编程,通过深度学习框架Pytorch搭建神经网络.实验环境为Intel(R) Core(TM) i3-7100U CPU@2.40GHz 处理器和4GB内存,Windows10 64位操作系统.
3.2" 实验效果分析
为充分证明本文算法的有效性,设计横向对比和纵向对比实验.纵向对比即算法自身参数对算法效果的影响.需要考虑的参数有:权重系数分析ω、嵌入维度分析.横向对比即将本文算法与BPR[16]、GMF[18]、GRU4Rec[19]、NARM[20]、CFKG[21]、DeepSoR[22]、GraphRec[12]分别进行对比.
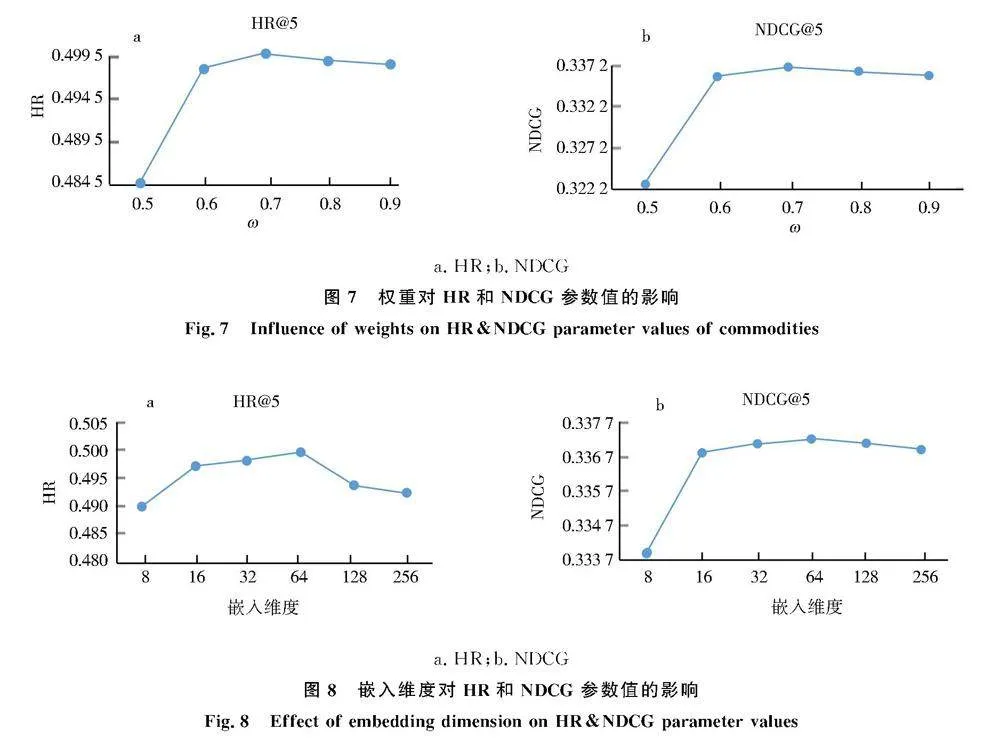
如图7对参数ω分别取[0.5,0.6,0.7,0.8,0.9]进行测试.当ω=0.7 时模型的命中率(HR)和归一化折现累积增益(NDCG)均取得最大值,表明在模型其他参数不变的情况下,ω=0.7时算法推荐效果最好.如图8取嵌入维度为[8,16,32,64,128,256]进行测试,取64时性能最好.
从全部的数据集中随机选择70%的数据集作为训练集,剩余30%的数据作为测试集,为避免单一实验结果不够稳定可靠的问题,所提出的模型最终的实验结果通过多次随机划分数据集、重复实验评估后取平均值得到,并与其他模型的结果进行了比较,实验结果如表2所列.
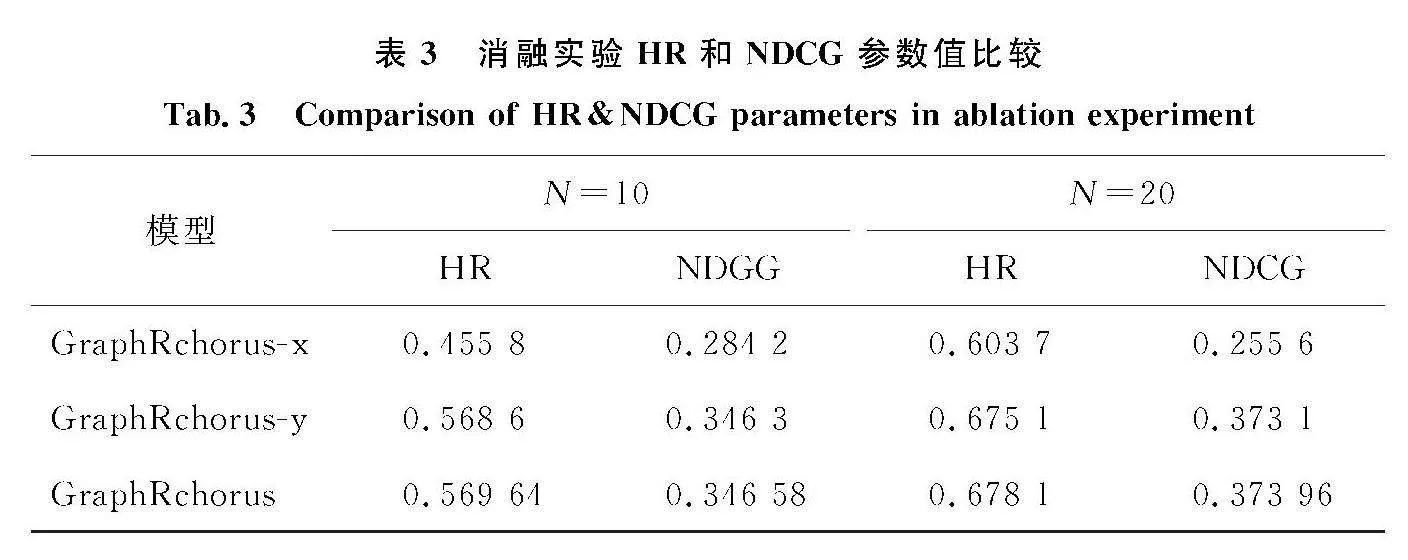
从实验结果可以看出,本文提出模型的稳定性较好,且不同类型的推荐算法显示出明显的性能差距.上述模型中BPR和GMF学习了用户项目基础的交换特征;GRU4Rec和NARM算法在学习用户项目特征时考虑了用户购买顺序;CFKG算法仅学习了物品之间各种关系的信息进行推荐;DeepSoR、GraphRec都基于神经网络结构学习了用户评分信息和社交信息图.通过表3中的实验结果可以看出,对比其他算法,本文算法GraphRChors综合考虑了用户社交信息、商品属性关系和用户购买顺序,推荐效果要优于其他模型的推荐效果,这可以说明,在推荐算法中考虑商品互补替代关系和购买序列模式可以大大提高推荐的准确率.
最后,为了测试本文算法中物品特征学习部分和推荐列表是否优化2方面改进对算法最终的推荐效果的影响进行了消融实验,实验结果如表3所示,其中GraphRchoru-x模型只加了带有序列模式优化推荐结果的改进,而GraphRchoru-y模型是仅加入了商品互补性替代性关系特征的改进模型.
可以看出,同时进行2项改进的GraphRchoru算法效果最好,表明这2个改进均可以提升推荐算法性能,且将加入物品关系特征的学习和进行推荐列表优化的改进相结合,可以更大程度地提升推荐算法的性能.
4" 总结
本文提出的考虑商品互补替代关系和购买序列模式的算法,主要在现有推荐算法上考虑如何增加用户购物需求方面的推荐以及如何尽量避免频繁向用户推荐不感兴趣的商品问题进行研究,在以往仅考虑加入图神经网络学习用户项目图、社交关系图特征进行推荐的算法基础上补充了利用TransE算法学习商品互补替代关系图特征的部分,丰富了推荐结果种类,且最终推荐时通过挖掘得到的商品购买二项序列模式对推荐结果进行了重新分配权重计算,再次优化了推荐列表,避免推荐用户不需要的商品,改善了推荐算法整体推荐的效果,为推荐算法研究提供了一个新的思路.未来可以进一步研究如何自适应地估计不同关系的时间演化效应,并尝试设计更合适的方法来紧密集成项目关系建模和推荐;也可以增强对于用户的收藏、加购等行为,以及对项目同类别、标签、品牌、价位等隐性特征数据的充分学习利用,可能可以进一步提高算法的性能.
参" 考" 文" 献:
[1]" 姜久雷,潘姿屹,李盛庆.融合信任度的神经网络推荐算法[J].计算机应用与软件, 2023, 40(8): 274-282, 311. DOI: 10.3969/j.issn.1000-386x.2023.08.043.
[2]" 冯兴杰,生晓宇.基于图神经网络与深度学习的商品推荐算法[J].计算机应用研究, 2021, 38(12): 3617-3622. DOI: 10.19734/j.issn.1001-3695.2021.05.0183
[3]" 于健,赵满坤,高洁,等.基于高阶和时序特征的图神经网络社会化推荐算法研究[J].计算机科学, 2023, 50(3): 49-64. DOI: 10.11896/jsjkx.220700108.
[4]" HAN J W, PEI J, YIN Y W. Mining frequent patterns without candidate generation[C]//Proceedings of the 2000 ACM SIGMOD international conference on Management of data. Dallas Texas USA. ACM, 2000: 1-12. DOI: 10.1145/342009.335372.
[5]" MA Y H, JIA J, ZHOU S P, et al. Towards better understanding the clothing fashion styles: a multimodal deep learning approach[J]. Proc AAAI Conf Artif Intell, 2017, 31(1): 38-44. DOI: 10.1609/aaai.v31i1.10509.
[6]" MA W Z, ZHANG M, CAO Y, et al. Jointly learning explainable rules for recommendation with knowledge graph[C]//The World Wide Web Conference. San Francisco CA USA. ACM, 2019: 1210-1221. DOI: 10.1145/3308558.3313607.
[7]" MISHRA R, KUMAR P, BHASKER B. A web recommendation system considering sequential information[J]. Decis Support Syst, 2015, 75: 1-10. DOI: 10.1016/j.dss.2015.04.004.
[8]" SALEHI M, NAKHAI KAMALABADI I, GHAZNAVI GHOUSHCHI M B. Personalized recommendation of learning material using sequential pattern mining and attribute based collaborative filtering[J]. Educ Inf Technol, 2014, 19(4): 713-735. DOI: 10.1007/s10639-012-9245-5
[9]" ZHOU G R, MOU N, FAN Y, et al. Deep interest evolution network for click-through rate prediction[J]. Proc AAAI Conf Artif Intell, 2019, 33(1): 5941-5948. DOI: 10.1609/aaai.v33i01.33015941.
[10]" 李杰,杨芳,徐晨曦.考虑时间动态性和序列模式的个性化推荐算法[J].数据分析与知识发现, 2018, 2(7): 72-80. DOI: 10.11925/infotech.2096-3467.2017.0857.
[11]" 余皑欣,冯秀芳,孙静宇.结合物品相似性的社交信任推荐算法[J].计算机科学, 2022, 49(5): 144-151. DOI: 10.11896/jsjkx.210300217
[12]" BORDES ANTOINE, USUNIER NICOLAS, GARCIA-DURAN ALBERTO, et al. Translating Embeddings for Modeling Multi-relational Data[C]//Advances in neural information processing systems. 2013: 2787-2795.
[13]" AGRAWAL R, IMIELIN'SKI T, SWAMI A. Mining association rules between sets of items in large databases[C]//Proceedings of the 1993 ACM SIGMOD international conference on Management of data. Washington D.C. USA. ACM, 1993: 207-216.DOI: 10.1145/170035.170072.
[14]" WANG C Y, ZHANG M, MA W Z, et al. Make it a chorus: knowledge- and time-aware item modeling for sequential recommendation[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Virtual Event China. ACM, 2020: 109-118. DOI: 10.1145/3397271.3401131.
[15]" RENDLE S, FREUDENTHALER C, GANTNER Z, et al. BPR: Bayesian personalized ranking from implicit feedback[J]. Proc 25th Conf Uncertain Artif Intell UAI 2009, 2009: 452-461.
[16]" WANG C Y, ZHANG M, MA W Z, et al. Modeling item-specific temporal dynamics of repeat consumption for recommender systems[C]//The World Wide Web Conference. San Francisco CA USA. ACM, 2019: 1977–1987. DOI: 10.1145/3308558.3313594.
[17]" HE X N, LIAO L Z, ZHANG H W, et al. Neural collaborative filtering[C]//Proceedings of the 26th International Conference on World Wide Web. Perth Australia. Republic and Canton of Geneva, Switzerland: International World Wide Web Conferences Steering Committee, 2017: 173–182. DOI: 10.1145/3038912.3052569.
[18]" HIDASI B, KARATZOGLOU A, BALTRUNAS L, et al. Session-based recommendations with recurrent neural networks[EB/OL]. 2015: arXiv: 1511.06939. http://arxiv.org/abs/1511.06939
[19]" LOYOLA P, LIU C, HIRATE Y. Modeling user session and intent with an attention-based encoder-decoder architecture[C]//Proceedings of the Eleventh ACM Conference on Recommender Systems. Como Italy. ACM, 2017: 147–151. DOI: 10.1145/3109859.3109917.
[20]" ZHANG Y F, AI Q Y, CHEN X, et al. Learning over knowledge-base embeddings for recommendation[J]. arXiv E Prints, 2018: arXiv: 1803.06540. DOI: 10.48550/arXiv.1803.06540
[21]" FAN W Q, LI Q, CHENG M. Deep modeling of social relations for recommendation[J]. Proc AAAI Conf Artif Intell, 2018, 32(1): 1-5. DOI: 10.1609/aaai.v32i1.12132.
(责任编辑:孟素兰)
猜你喜欢
软件(2016年4期)2017-01-20 09:44:28
东方教育(2016年8期)2017-01-17 19:47:27
软件导刊(2016年11期)2016-12-22 21:40:40
电脑知识与技术(2016年27期)2016-12-15 19:46:14
电脑知识与技术(2016年27期)2016-12-15 19:41:16
商(2016年34期)2016-11-24 16:28:51
中国科技博览(2016年21期)2016-11-14 18:27:30
电脑知识与技术(2016年22期)2016-10-31 20:12:44
中国科技博览(2016年18期)2016-10-19 06:43:40
商(2016年16期)2016-06-12 09:07:08
