
基于解纠缠表示学习的人脸反欺骗算法
2024-08-15 00:00:00周毅岩石亮张遨岳晓宇
计算机应用研究 2024年8期











摘 要:针对现有人脸反欺骗模型面对不同应用场景识别精度低、泛化性能不佳的问题,引入解纠缠表示学习,提出一种基于解纠缠表示学习的人脸反欺骗方法。该方法采用U-Net架构和ResNet-18作为编/解码器。首阶段训练中,通过输入真实样本使得编码器仅学习到真实样本相关信息。第二阶段,构建对抗性学习网络,输入不具标签的样本,将预训练的编码器输出和新编码器输出进行特征融合,由解码器重建图像,在鉴别器中与原始图像进行对抗训练,以实现特征的解耦。模型与一些经典人脸反欺骗方法相比,有着更好的检测性能,在OULU-NPU数据集的数个实验中,最低的检测错误率仅为0.8%,表现优于STDN等经典检测方法。该人脸反欺骗方法通过分阶段训练的方式,使得模型在对抗性训练中获得了相比端到端模型更具判别性的特征表示,在欺骗特征图输出阶段采用多分类策略,减小了不同的图像噪声对分类结果的影响,在公开数据集上的实验验证了算法的有效性。
关键词:人脸反欺骗; 解纠缠表示学习; 多分类; 域泛化
中图分类号:TP311 文献标志码:A
文章编号:1001-3695(2024)08-036-2502-06
doi:10.19734/j.issn.1001-3695.2023.11.0554
Face anti-spoofing algorithm based on disentangled representation learning
Zhou Yiyan, Shi Liang, Zhang Ao, Yue Xiaoyu
(School of Computer Science, Jiangsu University of Science & Technology, Zhenjiang Jiangsu 212114,China)
Abstract:To solve the problems of low recognition accuracy and poor generalization performance of existing face anti-spoofing models in different application scenarios, this paper adopted the idea of disentangled representation learning and proposed a face anti-spoofing method based on disentangled representation learning. This method adopted U-Net architecture and ResNet-18 as the encoder-decoder. In the first stage of training,it inputted real samples so that the encoder only learned information related to real samples. In the second stage, this paper built an adversarial learning network, inputted samples without labels, feature fusion of the pre-trained encoder output and the new encoder output, reconstructed the image by the decoder, and performed adversarial training with the original image in the discriminator to achieve feature decoupling. Compared with some classic face anti-spoofing methods, the model paper achieved better detection performance. The lowest detection error rate in several experiments on the OULU-NPU data set is only 0.8%, which is better than classic detection methods such as STDN. The face anti-spoofing method used staged training to enable the model to obtain a more discriminative feature representation than the end-to-end model in adversarial training. It adopted a multi-classification strategy in the deception feature map output stage to reduce the impact of different image noises on classification results, and experiments on public data sets verified the effectiveness of the algorithm.
Key words:face anti-spoofing; disentangled representation learning; multiclass classification; domain generalization
0 引言
随着人脸识别技术在各行各业中被广泛应用,如何防止人脸识别系统被伪造的图像攻击[1]得到了业界的广泛关注。对人脸识别系统的攻击类型通常包括打印人脸图像、播放视频回放、佩戴成本更高的3D面具。为了解决上述手段对人脸识别系统的攻击,许多人脸反欺骗方法应运而生,主要包括了传统机器学习方法和基于深度学习的方法[2]。传统的机器学习方法利用局部特征提取方式,如LBP(local binary pattern)[3]、HOG(histogram of oriented gradient)[4]提取的手工特征作为图像的特征纹理,并使用支持向量机等经典分类器进行二元分类。基于动态特征的人脸反欺骗方法使用诸如眨眼[5]、嘴巴运动和头部运动[6]等动态线索来检测打印欺骗攻击。但基于动态特征的人脸反欺骗方法在面对面具剪洞或者化妆等攻击类型时很容易失效。传统机器学习的方法无法应对越来越多样的攻击类型。
随着深度学习的发展,许多研究引入了神经网络作为特征提取工具,并将基于深度学习方法的人脸反欺骗简述为二元分类问题[7]。Yang等人[8]利用 LSTM(long short term memory),将时间信息作为辅助监督,使用SASM(spatial anti-spoofing module)模块提取不同的维度特征,获得了不错的效果。Yu等人[9]构建的中心差分卷积网络在卷积算子上作出创新,网络对提取欺骗人脸样本特征取得了很大成效。刘伟等人[10]将CNN(convolutional neural network,CNN)与LBP和多层离散余弦相融合,先将图像进行LBP和多层DCT(discrete cosine transform)处理,再经过CNN提取特征图像并分类。深度学习方法对比机器学习方法在性能方面具有优越性,但上述方法在面对同一数据库时识别率通常较好,面对跨数据集测试时则表现出较大的不稳定性。为了有效地学习更具有判别性的特征,研究人员还采用了辅助监督的方法,如深度信息[11]、反射方法[12]。Liu等人[13]建立了CNN-RNN(convolutional neural networks-recurrent neutral network)框架,利用深度图和rPPG(remote photoplethysmography)信号进行辅助监督。文献[14] 将欺骗人脸分解为欺骗噪声和真实人脸信息,利用噪声作分类。辅助监督方法有助于提取更具判别性的特征,但人脸反欺骗模型性能还取决于具有一致目标的辅助监督任务。此外,现有的辅助信息可能不适合所有的攻击类型。在研究中,不可能定义所有辅助信息来对人脸反欺骗模型进行训练,其关键是使模型学习真实人脸和伪造人脸的区分本质,以避免网络对训练数据的过度拟合。解纠缠表示学习是将模型的潜在表示分离为可解释部分的有效方法,进一步提高了模型的鲁棒性。例如文献[15,16]通过融合端到端架构中的特征,使用对抗性训练来获得解纠缠表示。文献[17] 构建了CSM-GAN(covered style minin-generative adversarial network)框架,设置风格生成器和对抗性风格鉴别器形成生成对抗性网络,利用风格转移技术实现人脸反欺骗。Zhou等人[18]提出一种域自适应生成对抗式网络,通过域内频谱混合来扩展目标数据分布,减少了域内差距。这类依靠生成对抗网络的方法,普遍对生成器和鉴别器存在很大程度依赖,其生成器鉴别器的稳定性将在很大程度上影响获取解缠的特征表示效果。
针对上述问题,本文提出了一种解纠缠表示学习的人脸反欺骗算法;采用分阶段训练的方式使得编码器在一阶段学习到真实样本特征,从而使得模型在后续的对抗性训练中保持足够的稳定性;输入不具有标签的图像,经过解码器的图像重建后,构建对抗性训练使得模型获得具有判别性的解纠缠特征表示;在欺骗特征图输出阶段,采用多分类策略,弱化环境多样性的影响,使得模型识别率进一步上升。
1 相关工作
1.1 解纠缠表示学习
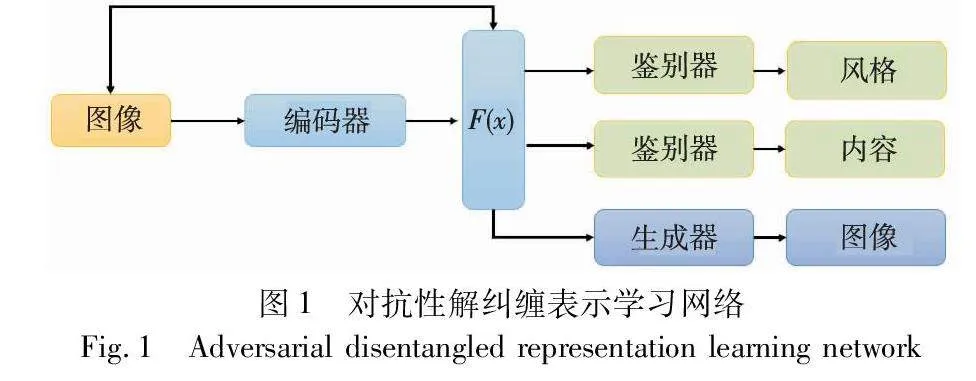
解纠缠表示学习是一种无监督的学习方法,核心思想是将模型提取的图像特征进行进一步分离,使得深度学习模型学习到对于人脸反欺骗任务更为有效的判别性特征。基于对抗性的解纠缠表示学习网络如图1所示,编码器、生成器和鉴别器构成网络主干。编码器网络输出特定的特征表示,并作为生成器的输入,生成器生成与输入具有一致风格的图像。编码器和内容鉴别器的任务具有一致性,得到风格鉴别器输出后,进行极大化或者极小化优化,使得鉴别器(风格)和编码器进行对抗性学习。根据风格鉴别器与输入图像的标签的匹配,进行生成器的训练,以生成对应风格的图像。为了学习分离耦合特征,将生成对抗式训练和解纠缠表示学习进行组合。因此,网络目的是对耦合特征表示的对抗训练。网络融合了不同风格图像,使得所获得的特征表示对合成保留内容的图像具有包容性,而且对风格变化具有排斥性,这种对耦合的特征表示进行分离的对抗性训练有利于提升模型的分类性能 [19]。
1.2 多分类研究
由于攻击媒介的多样性,导致了模型在学习不同攻击类型时存在不同模式的图像噪声。打印样本图像由于打印设备与纸张材质问题,通常出现颜色不均、人脸面部细节丢失;因为播放设备的影响,重放视频攻击样本通常出现摩尔纹,偶有反光、过度曝光现象。真实人脸图像呈现的色彩均衡、细节清晰; OULU-NPU数据集的真实人脸、打印人脸、重放人脸三种样本类型由图2展示。由图可见,三种类型样本如上所述,出现相对应的差异 [20]。
2 算法
本文假设每个欺骗样本都由其对应的真实信息和相关欺骗信息所组成。真实图像和欺骗图像的真实信息部分是相关联的,获得具有判别性的解耦特征是模型区分欺骗样本的关键。为了获得具有显著区分性的特征表示,本文提出了一种基于解纠缠表示学习的人脸反欺骗算法。模型结构如图3所示。
在第一阶段训练中,真实信息网络仅仅学习到与真实样本相关的特征信息。本文E-live为基于U-Net[13]框架Encoder编码器,真实样本经过E-live编码器编码后输出特征表示FL, FL∈Euclid ExtraaBp512,FL仅与真实样本相关。在第二阶段训练中,解纠缠模块(disentangled module)采用第一阶段预训练的E-live作为固定的编码器,采用对抗学习的方式对提取解纠缠进行特征表示,解纠缠模块输出特征表示FS,FS∈Euclid ExtraaBp512,FS作为输入在多分类模块(multi-classification module)中再次进行处理,得到两种类型的欺骗特征图,并利用特征图进行分类决策。
2.1 预训练
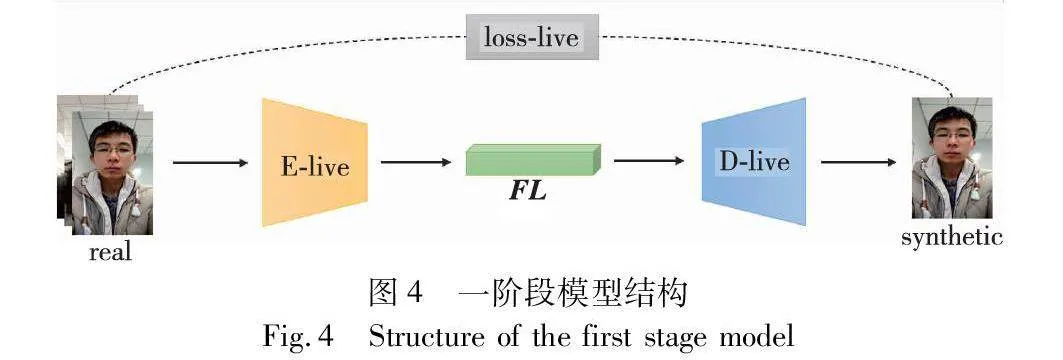
在第一阶段,只输入真实样本,使得Encoder-Decoder模型只学习到真实样本的特征参数,编码器E-live与D-live是自动编码解码器,输入真实样本后,经过编码器E-live,输出特征表示FL,FL经过解码器进行解码得到重建图像。这一训练阶段使用Loss MAE(mean absolute error,MAE)函数约束模型提取真实特征、重建真实人脸图像。图4为一阶段模型结构图。
图中real代表输入的真实样本数据,synthetic为解码器输出的重建图像,FL代表图像经过编码器编码后的特征表示。本阶段主要用于获取E-live模块在训练中得到的权重参数。
设X表示真实样本训练数据,D为D-live解码器。真实特征网络可以产生输出syn=D-live(E-live(X))。损失函数为
Lr=EX~PX(syn-X)(1)
其中:syn为合成样本;X为真实样本。
该模型只从真实样本中学习信息,所以得到的权重参数只与真实样本相关,经Encoder提取的所有特征都看做是真实特征。
2.2 解纠缠表示学习
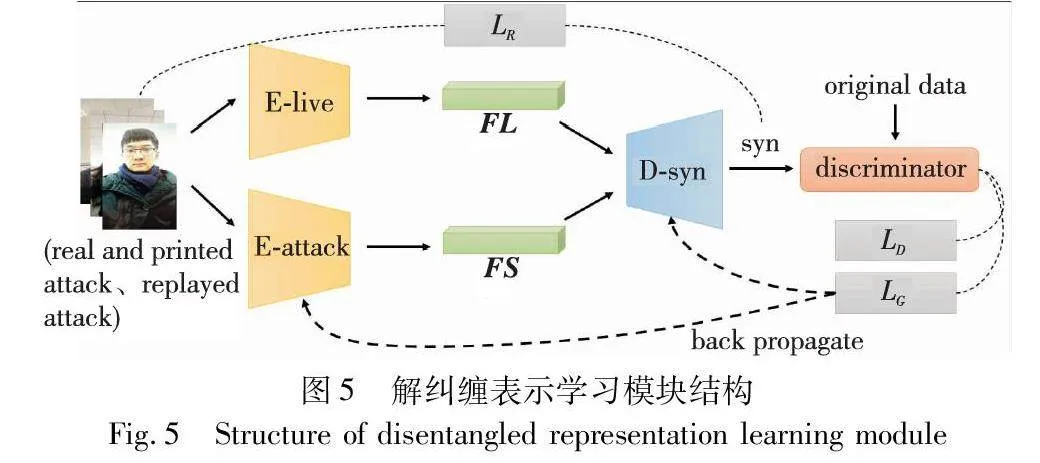
在第二阶段,使用真实样本、打印攻击样本和重放攻击样本作为训练数据。分别采用编码器E-attack与E-live对训练样本进行编码,E-live在第一阶段训练完毕,没有学习到关于欺骗图像的任何信息,可以专注于提取与攻击样本具有共性的、可被识别为真实样本的特征。图5为解纠缠表示学习模块。
特征表示FL为E-live所编码的特征向量,使用Element-wise Addition方法合并两种特征表6dad9d51343e7064e7f47c0753a2f9570095b2ce24dffcffd85679b9a7002ac5示FL与FS。E-attack与D-syn分别为基于U-Net[13]框架的编码器与解码器。D-syn接收合成的特征表示进行解码,输出合成图像Syn,Syn与原始数据经过鉴别器D(discriminator)进行对抗学习,使得E-attack提取更具欺骗性的特征表示FS。
实验使用回归损失LR和生成对抗式损失函数来约束与原始数据X相似的输出Syn。本文将生成的数据Syn和原始数据X作为鉴别器D的输入,它将对输入样本进行鉴别。通过上述过程,从而将具有区分性的欺骗特征从无关特征中剥离提取。
LGen=EX~PX[(D(Syn)-1)2](2)
LDis=EX~PX[(D(X)-1)2]+EX~PX[(D(Syn)2](3)
损失函数LR由下式给出:
LR=EX~PXSyn-X22 (4)
2.3 多分类的欺骗特征图输出
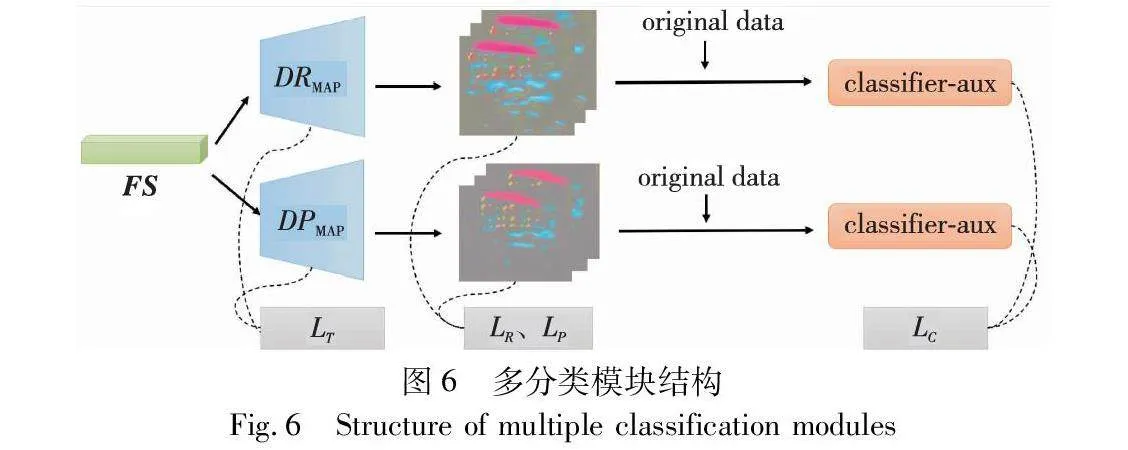
在欺骗特征提取模块中,将解纠缠模块中经过解纠缠处理的欺骗特征作为解码器DPMAP与DRMAP的输入来生成不同类别的欺骗特征映射。图6为多分类模块结构。
解纠缠过程中编码器E-attack经过类似生成对抗式学习后,所编码的特征表示FS更具有欺骗性,用FS作为输入,使用双解码器DRMAP与DPMAP进行解码,分别获得打印欺骗特征图与重放欺骗特征图。Classifier-aux作为二元分类器,分别输入欺骗特征图叠加原始数据。分类器仅对解码过程起辅助监督作用。
损失函数LT用于最小化真实人脸图像的欺骗映射,并将真实数据和欺骗数据耦合的特征分开,将更能区分攻击样本的欺骗特征剥离出来。本文在解码器的最后三层中应用了损失函数LT。LT由两部分组成:
LT=LH+LN(5)
其中:损失LN计算所有有效三元组的三元组损失,并对正值的三元组进行平均化。
LN =1N∑Ni=1max(‖fai+fpi‖22-‖fai-fni‖22+α,0)(6)
其中:fai、fpi、fni分别表示第i三元组的锚样本、正样本和负样本的特征向量;N表示三元组的数量;α是预设的边距常量。本文选定真实样本特征向量作为锚样本。
在LH的计算中,对于每个fai,本文设置具有最大欧氏距离的一组(fai,fpi)作为正值。正样本索引j选自L且j≠i,其中L表示当前批次中所有真实样本的集合。对于每个fai,找出具有最小欧氏距离的一组(fai,fnk)为负值。欺骗样本索引k选自N,N表示当前批次中所有欺骗样本的集合。T表示三元组的数量。m是预定义的边距常量。对于每个三元组(fai,fpi,fni),本文计算每个三元组的损失,然后取其平均值:
LH =1T∑Ti=1max(max‖fai-fpj‖22-min‖fai-fnk‖22+m,0)(7)
其中:j∈L,k∈N。经过DRMAP与DPMAP解码后生成两类型特征图,分别命名为欺骗特征图RMAP和PMAP,为使欺骗特征图的类型得到区分,本文使用LP与LR来帮助训练解码器将特征分流,并在分流过后使用Lc利用鉴别器进行辅助训练,目的在于增强区分性。本文使用损失函数LP与LR来使得欺骗特征得到分流:
LP=EX~PX‖RMAP-IPrint‖1(8)
LR=EX~PX‖RMAP-IReplay‖1(9)
其中:IPrint,IReplay为对应样本标签。Classifier-aux是一种二值分类器,用来辅助加强解码器对真实样本与欺骗样本的区分性。本文将欺骗特征图与原始数据重叠,与原始数据分别作为辅助分类器的输入。分类器Classifier-aux的损失Lc由下式给出:
Lc = 1N∑Ni=1zi ln qi+(1-zi)ln qi(10)
其中:N是样本数量;zi是二进制标签;qi是分类器预测值。
2.4 训练测试
加权计算上述损失函数的总和作为第二训练阶段的最终损失,由式(11)给出:
LR=λ1LLrecon+λ2LGen+λ3LT+λ4LR+λ5LP+λ6Lc(11)
其中:λ1、λ2、λ3、λ4和λ5是与上述损失函数相关联的权重,在实验中,它们的值分别被设置为4、1、3、3、3、4。训练完成时,计算生成的RMAP与PMAP各自平均值作为欺骗分数,利用欺骗分数作三分类决策。在测试阶段,将输入测试数据得到的两种分数与原有的两种欺骗分数进行对比,差值较大的作为分类结果。在测试阶段,需要使用编码器E-attack和解码器DPMAP与DRMAP。
2.5 网络结构和实现细节
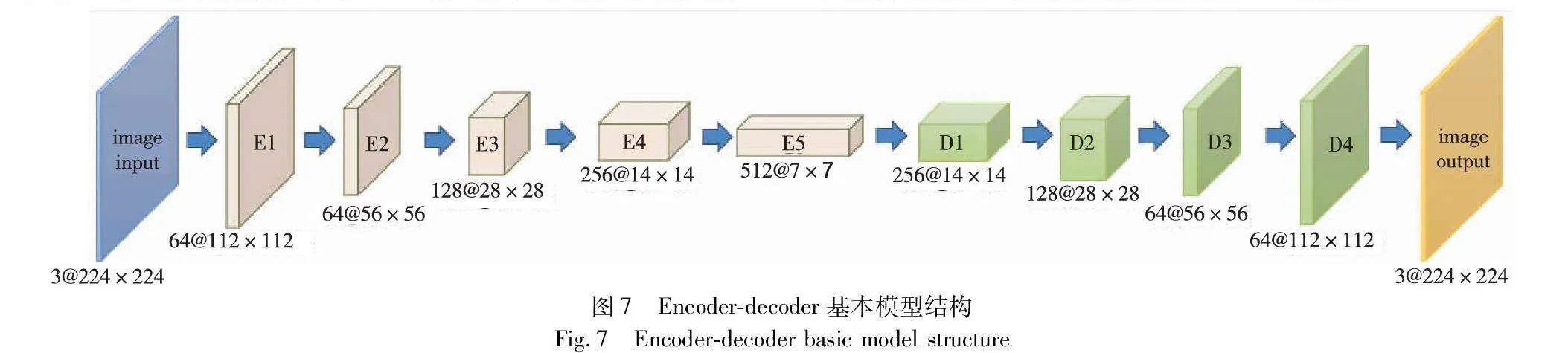
本文方法的编码器和解码器的基本结构框架如图7所示,本文基于U-Net[21]架构进行了模型的设计。在预训练阶段,本文采用基于ResNet-18[21]的0~4层作为编码器,接着进行下采样。解码器与编码器结构对应,而对每一层的特征图采用双线性插值法上采样,在解码器的最后一层设置Tanh激活函数来获得输出图像。在对抗性训练阶段,为了获得判别性特征表示,对预训练的编码器停止更新参数。将两编码器输出的特征表示进行合成,因为两编码器输出相同规格的特征表示,考虑到后续重建图像,选择逐元素相加的方式将特征表示叠加。由于解码器得到的是经过叠加的特征表示,需要对解码器进行相应的调整,本文在与基本模型结构相同的基础上,增加一次上采样,使得解码器输出和原始图像具有相同规格的合成图像,进而通过鉴别器完成对抗性训练。在欺骗特征图获取时,与基本模型结构相同,采用四个解码块组成的解码器进行欺骗特征图的输出,在使用分类器辅助监督时,为了获得更好的监督效果,采用相乘方式进行原始数据与特征图叠加。
3 实验设计与分析
3.1 数据库
基于OULU-NPU和CASIA-FASD、Replay-Attack三种数据集,本文设计了一系列实验对打印攻击和重放攻击两种常见的欺诈人脸攻击方式进行训练和测试。
1)OULU-NPU数据集[22] 该数据集由芬兰奥卢大学和中国西北工业大学研究人员共同创建,包括20个训练集、20个测试集和15个验证集。数据集共有4 950个视频,这些视频由不同的6种设备所拍摄。共设置了4种不同的光照背景条件,即跨光照环境实、跨攻击制作设备实验、跨数据采集设备实验、跨所有条件实验。图8分别展示了真实样本与打印攻击样本、重放视频攻击样本三种类型。
2)CASIA-FASD 该数据集由Zhang等人[23]创建,其中包含20个训练集和30个测试集,每个集合包含一个人的真脸和攻击,共50个人。其中,每个人的集合中均包括3个不同光照、不同角度的真脸,以及弯曲攻击、剪洞攻击和视频共9个攻击。图9展示了三种攻击的示意图。
3)Replay-Attack 该数据集是Chingovska等人[24]在2012年提出的。该数据集分为训练集、验证集和测试集,每种集合均包括真脸和攻击。为了增加分类识别提高难度,本数据集的攻击类型分为手持和固定。图10为Replay-Attack样本示意图。
3.2 评价指标
本文选择了五个常用的指标来评估FAS任务的性能:攻击呈现分类错误率(attack presentation classification error rate,APCER)、真实分类错误率(bona fide presentation classification error rate,BPCER),平均分类错误率(average classification error rate,ACER)、等错误率(equal error rate,EER)、模型评价指标(area under curve,AUC)。上述指标除AUC外,其余数值越低,代表模型表现越优秀。AUC描述二分类器分类能力,X轴为FPR(false positive rate),Y轴为TPR(true positive rate)构成一条曲线下面积。即随机选取正样本和负样本,正样本预估概率大于负样本预估概率的概率。AUC数值越大,说明模型性能越好。上述指标数值越低,说明网络性能越好。
APCER=FPTN+FP,BPCER=FNFN+TP,APCER=APCER+BPCER2
其中:TP表示模型把正样本预测为负样本的数量;TN表示模型把正样本预测为负样本数量;FP为模型把负样本预测为正样本的数量;FN为模型把正样本预测为负样本的数量[18]。
3.3 实验配置
本文首先对数据进行预处理,即视频重采样。本文对视频进行图像采样,采样率为每3帧保存一幅图像。裁剪图像使用Dlib[25]的人脸目标检测算法来对每张图像进行裁剪,将所有裁剪区域的大小都调整为224×224。最后,对数据集进行重采样,以保持真实图像和两种攻击图像的比例为1∶1∶1。
训练阶段,采用Adam[26]作为优化算法,初始学习率为5E-4,训练Batch大小为32。模型分为一个两阶段的训练过程,本文在第一阶段训练了10个Epoch的真实样本来获取权重参数。在第二阶段,将预先训练好的编码器E-live加载为固定的编码器,以进一步训练解缠模块。对于训练中所使用的数据集,解纠缠模块的损失函数可以在大约10个Epoch之后收敛。
本文的实验硬件为NVIDIA GeForce GTX 4060(8 GB),框架为基于Python 的PyTorch框架。
3.4 实验结果
3.4.1 模块间对比实验
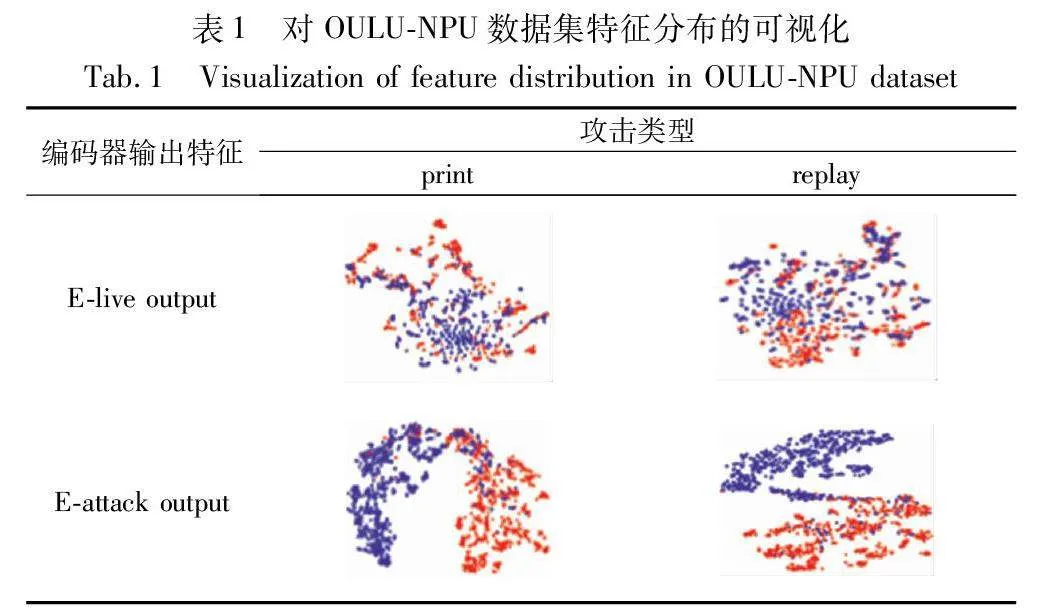
为了验证解纠缠原理中假设图像存在具有区分性的真实特征与欺骗特征,实验在OULU-NPU数据集上采集样本,通过t-SNE[27]提取真实特征FL和欺骗特征FS的特征分布并进行可视化,真实样本和欺骗样本的FL高度重叠,而相比之下,两者的FS有明显区别。可视化分布如表1所示。
其中,蓝色表示真实样本特征分布,红色则表示欺骗样本的特征分布(见电子版)。实验对模型的两个编码器E-live和E-attack的输出特征FL和FS进行特征分布的可视化,以证明本文的多分类解纠缠表示学习策略是合理的。本文采用OULU-NPU数据集,从测试集中随机选择1 000个真实样本和1 000个欺骗类型样本。如表1所示,由E-live所输出的特征分布不具明显界限,说明其提取到的特征不具有区分性,属于欺骗无关特征。而由E-attack所输出的显示,其特征分布具有明显界限,模型提取到了具有区分性的欺骗特征。
3.4.2 数据集内部测试
分别在OULU-NPU、CASIA-FASD和Replay-Attack数据集上进行数据集内部的训练和测试,实验结果如表2~4所示。采用基于解纠缠表示学习的人脸反欺骗方法在上述四种数据集的不同评价指标下,与其他的人脸反欺骗方法相比具有优越性。不同类型的欺骗样本的特征信息存在明显共性,采取多分类策略增加了解纠缠模型对不同欺诈样本类型的关注度,提升了对打印样本攻击和视频重放样本攻击的共性欺骗信息学习,深化了模型对欺骗特征的解耦程度,提升了检测任务的识别率。
如表2所示,在OULU-NPU的数据集分别基于四个实验条件与其他优秀方法进行了对比,其中粗体表示本文在该项获得了最优结果。本文分别在跨所有条件实验、跨攻击制作设备实验、跨光照环境实验条件下获得了最优结果。对比STDN方法,在实验1中,本文方法APCER指标降低了0.3%,BPCER则下降了0.2%,说明本文采用分阶段训练、三元组函数辅助监督,有效地提升了模型性能。
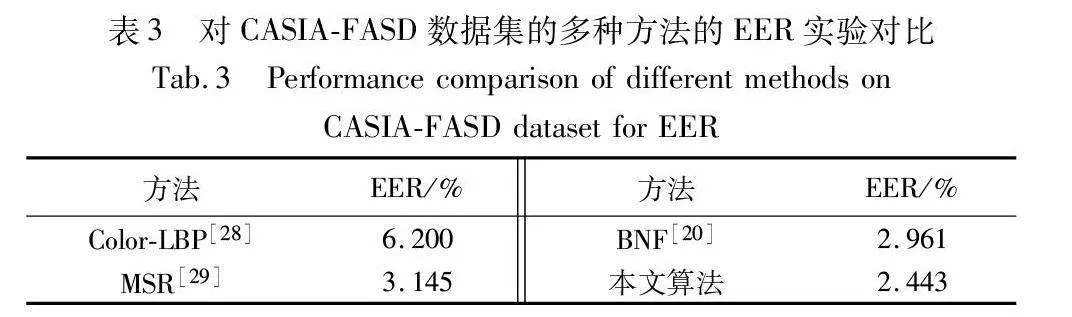
表3为本文方法与其他优秀人脸反欺骗方法在CASIA-FASD数据集的内部测试。在EER指标表现上,与BNF相比,其具有一定优势。
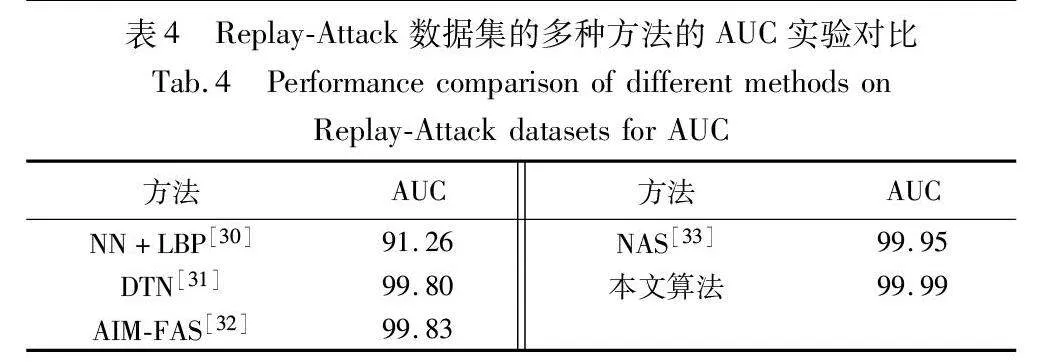
表4为基于解纠缠表示学习的人脸反欺骗方法与其他方法在Replay-Attack数据集上的AUC指标对比。由表可见,本文方法在AUC指标上表现优秀,获得了99.99。相比其他方法,在Replay-Attack数据集上,基于解纠缠表示学习的人脸反欺骗方法表现更为优异。
3.4.3 跨数据集测试
为了进一步研究基于解纠缠表示学习的人脸反欺骗方法的泛化能力,本文在CASIA-FASD、Replay-Attack数据集上设计了交叉训练与测试,实验结果如表5所示。可以看出,与其他方法相比,采用基于解纠缠表示学习的人脸反欺骗方法,模型泛化性能得到了改善。
表5为本文算法与其他近年来人脸反欺骗方法在CASIA-FASD、Replay-Attack数据集上进行的实验结果对比与分析。经过在CASIA-FASD数据集训练,在Replay-Attack数据集进行测试,实验结果显示,本文算法相比BNF的EER错误率有了一定下降,表明解纠缠表示学习方法相比其他不对特征进行解耦的算法,在鲁棒性方面具有一定优势;其次,安排测试集与训练集进行交换,得出的实验结果显示,本文方法的EER错误率仍然最低。实验结果证明了采取多分类策略的解纠缠表示学习方法的有效性。
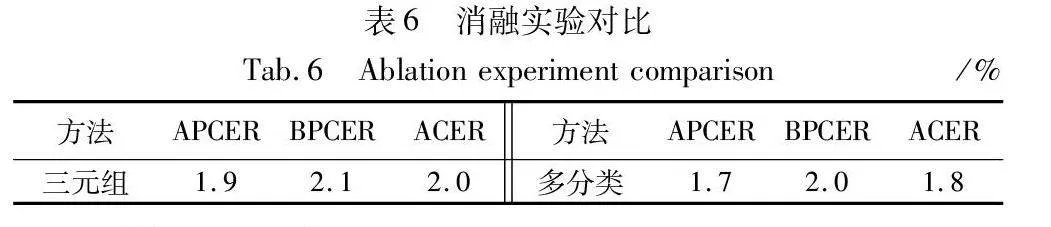
3.5 消融实验
在OULU-NPU数据集基于跨光照环境条件下进行消融实验, 分别为去除三元组损失辅助监督、 去除多分类进行实验。
从表6可知,本文三元组函数约束对解纠缠表示学习过程起到推动作用,同时,多分类策略对模型欺骗特征图输出起到了一定的作用。
3.6 特征图可视化
本文设置实验对解码器的输出分别进行可视化,以描述具体如何检测欺骗攻击。实验使用OULU-NPU数据集测试模型,生成的欺骗特征图如图11所示。
从图11的真脸欺骗特征图可以看出,对于真实人脸,网络所输出欺骗特征图几乎空白,对于打印攻击和重放攻击的特征图,则出现了有明显网络重点关注的区域,意味着其欺骗系数较大。
4 结束语
本文提出了基于解纠缠表示学习的人脸反欺骗算法,通过对一般对抗性解纠缠学习表示网络的改进,采取分阶段训练方式,使得模型在经过与真实人脸特征解耦的过程中稳定地获得了更有效的判别性特征信息,深化了模型的解耦程度;多分类策略降低了环境因素对检测任务造成的不利影响。经过对实验结果进行对比与分析,验证了基于解纠缠表示学习的人脸反欺骗算法的有效性。
参考文献:
[1]张帆, 赵世坤, 袁操, 等. 人脸识别反欺诈研究进展[J]. 软件学报, 2022, 33(7): 2411-2446. (Zhang Fan, Zhao Shikun, Yuan Cao, et al. Research progress of face recognition anti-spoofing[J]. Journal of Software, 2022, 33(7): 2411-2446.)
[2]卢子谦, 陆哲明, 沈冯立, 等. 人脸反欺诈活体检测综述[J]. 信息安全学报, 2020, 5(2): 18-27. (Lu Ziqian, Lu Zheming, Shen Fengli, et al. A survey of face anti-spoofing[J]. Journal of Information Security, 2020, 5(2): 18-27.)
[3]黄子轩. 基于混合纹理的人脸活体检测算法设计与实现[D]. 武汉:华中科技大学, 2023. (Huang Zixuan. Design and implementation of face anti-spoofing algorithm based on mixed texture[D]. Wuhan: Huazhong University of Science and Technology, 2023.)
[4]刘航. 基于Haralick和HOG特征的人脸活体检测[J]. 计算机与网络, 2020, 46(15): 53. (Liu Hang. Face liveness detection based on Haralick and HOG features[J]. Computers and Networks, 2020, 46(15): 53.)
[5]郭华. 基于视频的人脸活体检测研究[D]. 北京:北方工业大学, 2021. (Guo Hua. Research on face anti-spoofing algorithm based on video[D]. Beijing: North China University of Technology, 2021.)
[6]Singh A K, Joshi P, Nandi G C. Face recognition with liveness detection using eye and mouth movement[C]//Proc of International Conference on Signal Propagation and Computer Technology. Pisca-taway, NJ: IEEE Press, 2014: 592-597.
[7]陈俊廷. 基于深度信息辅助监督的活体人脸检测算法研究与应用[D]. 济南:济南大学, 2022. (Chen Junting. Research and application of face anti-spoofing algorithm with depth supervision[D]. Jinan :Jinan University, 2022.)
[8]Yang Xiao, Luo Wenhan, Bao Linchao, et al. Face anti-spoofing: model matters, so does data[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 3502-3511.
[9]Yu Zitong, Qin Yunxiao, Li Xiaobai, et al. Multi-modal face anti-spoofing based on central difference networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ: IEEE Press, 2020: 2766-2774.
[10]刘伟, 章琬苓, 项世军. 基于LBP-MDCT和CNN的人脸活体检测算法[J]. 应用科学学报, 2019, 37(5): 609-617. (Liu Wei, Zhang Wanling, Xiang Shijun. Face anti-spoofing based on LBP-MDCT and CNN[J]. Journal of Applied Science, 2019, 37(5): 609-617.)
[11]高文龙. 基于图像与深度信息融合的人脸识别研究[D]. 沈阳:东北大学, 2020. (Gao Wenlong. Face recognition based on image and depth information[D]. Shenyang: Northeastern University, 2020.)
[12]Kim T, Kim Y H, Kim I, et al. BASN: enriching feature representation using bipartite auxiliary supervisions for face anti-spoofing[C]//Proc of IEEE/CVF International Conference on Computer Vision Workshops. Piscataway, NJ: IEEE Press, 2019: 494-503.
[13]Liu Yaojie, Jourabloo A, Liu Xiaoming. Learning deep models for face anti-spoofing: binary or auxiliary supervision[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018: 389-398.
[14]Jourabloo A, Liu Y, Liu X. Face de-spoofing: anti-spoofing via noise modeling[C]//Proc of European Conference on Computer Vision. Cham:Springer, 2018: 290-306.
[15]Zhang K Y, Yao Taiping, Zhang Jian, et al. Face anti-spoofing via disentangled representation learning[C]//Proc of the 16th European Conference on Computer Vision. Cham:Springer, 2020: 641-657.
[16]Liu Yaojie, Stehouwer J, Liu Xiaoming. On disentangling spoof trace for generic face anti-spoofing[C]//Proc of the 16th European Confe-rence on Computer Vision. Cham:Springer, 2020: 406-422.
[17]Wu Yiqiang, Tao Dapeng, Luo Yong, et al. Covered style mining via generative adversarial networks for face anti-spoofing[J]. Pattern Recognition, 2022, 132: 108957.
[18]Zhou Qianyu, Zhang K Y, Yao Taiping, et al. Generative domain adaptation for face anti-spoofing[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2022: 335-356.
[19]陈莉明, 田茂, 颜佳. 解纠缠表示学习在跨年龄人脸识别中的应用[J]. 计算机应用研究, 2021, 38(11): 3500-3505. (Chen Liming, Tian Mao, Yan Jia. Application of disentangled representation learning in cross-age face recognition[J]. Application Research of Computer, 2021, 38(11): 3500-3505.)
[20]黄新宇, 游帆, 张沛, 等. 基于多分类及特征融合的静默活体检测算法[J]. 浙江大学学报:工学版, 2022,56(2): 263-270. (Huang Xinyu, You Fan, Zhang Pei, et al. Silent living body detection algorithm based on multi-classification and feature fusion[J]. Journal of Zhejiang University: Engineering Science, 2022,56(2): 263-270.)
[21]Feng Haocheng, Hong Zhibin, Yue Haixiao, et al. Learning genera-lized spoof cues for face anti-spoofing[EB/OL]. (2020). https://arxiv.org/abs/2005. 03922.
[22]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 770-778.
[23]Zhang Zhiwei, Yan Junjie, Liu Sifei, et al. A face antispoofing database with diverse attacks[C]//Proc of the 5th IAPR International Conference on Biometrics. Piscataway, NJ: IEEE Press, 2012: 26-31.
[24]Chingovska I, Anjos A, Marcel S. On the effectiveness of local binary patterns in face anti-spoofing[C]//Proc of International Conference of Biometrics Special Interest Group. Piscataway, NJ: IEEE Press, 2012: 1-7.
[25]King D E. Dlib-ml: a machine learning toolkit[J]. The Journal of Machine Learning Research, 2009, 10: 1755-1758.
[26]Kingma D, Ba J. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30). https://arxiv.org/abs/1412.6980.
[27]Van der Maaten L, Hinton G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9(11):2579-2605.
[28]Boulkenafet Z, Komulainen J, Hadid A. Face anti-spoofing based on color texture analysis[C]//Proc of IEEE International Conference on Image Processing. Piscataway, NJ: IEEE Press, 2015: 2636-2640.
[29]Chen Haonan, Hu Guosheng, Lei Zhen, et al. Attention-based two-stream convolutional networks for face spoofing detection[J]. IEEE Trans on Information Forensics and Security, 2019, 15: 578-593.
[30]Xiong Fei, AbdAlmageed W. Unknown presentation attack detection with face RGB images[C]//Proc of the 9th IEEE International Conference on Biometrics Theory, Applications and Systems. Piscataway, NJ: IEEE Press, 2018: 1-9.
[31]Liu Yaojie, Stehouwer J, Jourabloo A, et al. Deep tree learning for zero-shot face anti-spoofing[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 4675-4684.
[32]Qin Yunxiao, Zhao Chenxu, Zhu Xiangyu, et al. Learning meta mo-del for zero-and few-shot face anti-spoofing[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2020: 11916-11923.
[33]Yu Zitong, Wan Jun, Qin Yunxiao, et al. NAS-FAS: static-dynamic central difference network search for face anti-spoofing[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2020, 43(9): 3005-3023.
[34]Boulkenafet Z, Komulainen J, Hadid A. Face spoofing detection using color texture analysis[J]. IEEE Trans on Information Forensics and Security, 2016, 11(8): 1818-1830.
