
融合语义信息的视觉惯性SLAM算法
2024-08-15 00:00:00何铭臻何元烈胡涛
计算机应用研究 2024年8期










摘 要:
针对传统SLAM算法在动态环境中会受到动态特征点的影响,导致算法定位精度下降的问题,提出了一种融合语义信息的视觉惯性SLAM算法SF-VINS(visual inertial navigation system based on semantics fusion)。首先基于VINS-Mono算法框架,将语义分割网络PP-LiteSeg集成到系统前端,并根据语义分割结果去除动态特征点;其次,在后端利用像素语义概率构建语义概率误差约束项,并使用特征点自适应权重,提出了新的BA代价函数和相机外参优化策略,提高了状态估计的准确度;最后,为验证该算法的有效性,在VIODE和NTU VIRAL数据集上进行实验。实验结果表明,与目前先进的视觉惯性SLAM算法相比,该算法在动态场景和静态场景的定位精度和鲁棒性均有一定优势。
关键词:动态物体;语义概率;位姿估计;视觉惯性SLAM
中图分类号:TP242 文献标志码:A 文章编号:1001-3695(2024)08-041-2533-07
doi: 10.19734/j.issn.1001-3695.2023.09.0556
Visual inertial SLAM algorithm with semantic information fusion
He Mingzhen, He Yuanlie, Hu Tao
(School of Computer, Guangdong University of Technology, Guangzhou 510006, China)
Abstract:
Aiming at the problem that the positioning accuracy of traditional SLAM algorithm decreases due to the influence of dynamic feature points in dynamic environment, this paper proposed SF-VINS which fused semantic information. Firstly, it incorporated the PP-LiteSeg semantic segmentation network into the front-end of system based on the VINS-Mono algorithm and removed the dynamic feature points according to the results of semantic segmentation. Then, it constructed the semantic probability error constraint with the pixel semantic probabilities and employed adaptive weights for feature points in the backend. Based on these modifications, this paper proposed a new BA cost function and an optimization strategy for camera extrinsic para-meters to improve the accuracy of state estimation. Finally, this paper conducted experiments on the VIODE and NTU VIRAL datasets to validate its effectiveness. The experimental results show that the proposed algorithm has advantages in terms of positioning accuracy and robustness in both dynamic and static scenes compared with state-of-the-art visual-inertial SLAM algorithms.
Key words:dynamic objects; semantic probability; pose estimation; visual inertial SLAM
0 引言
随着视觉技术和硬件水平的发展,同步定位和建图(simul-taneous localization and mapping,SLAM)技术已经在机器人上广泛应用[1],特别是在无GPS信号的环境中尤为重要[2]。传统的视觉SLAM算法在静态环境中已有较好的定位和建图效果,但在面临动态环境时,物体的运动会导致图像特征点的跟踪失败或误匹配,从而影响SLAM算法的表现[3]。而惯性传感器不受动态环境的影响,可与视觉传感器结合使用,获得更可靠的位姿[4]。如Bloesch等人[5]提出ROVIO算法,其前端利用图像块像素强度误差进行特征跟踪,后端使用EKF融合惯性信息和视觉信息进行优化。Leutenegger等人[6]提出的OKVIS算法的后端使用滑动窗口非线性紧耦合优化,实现了双目惯性里程计。Qin等人[7]提出的VINS-Mono具有回环检测功能,是一个基于滑动窗口优化的紧耦合单目视觉惯性SLAM系统。Campos等人[8]提出的ORB-SLAM3在ORB-SLAM2[9]的基础上融合了惯性传感器信息,并且适用于单目、双目、RGB-D相机、视觉惯性多种模式的数据输入,突破了传统视觉SLAM算法的定位精度。但如果在高动态环境中,视觉信息的误差会变大,加入惯性传感器的效果就会大打折扣。
随着深度学习和神经网络的发展,研究人员试图结合神经网络对SLAM算法进行优化。如DS-SLAM[10]配备了一个在独立线程中运行的实时语义分割网络,再加上移动的一致性检查方法,使其能够过滤出场景中的动态部分。DynaSLAM[11]用多视图几何和深度学习来检测运动物体,并进行了背景重绘。DM-SLAM[12]结合了Mask R-CNN[13]、光流和对极约束来判断异常值,并检测先验动态对象的特征点是否有大量移动,避免出现因删除所有先验动态对象特征点而导致没有特征点的情况。AD-SLAM[14]利用对极约束来判断当前环境的动态级别,并使用累积运动概率来应对低动态场景和使用语义分割网来应对高动态场景,从而提高系统的鲁棒性和定位精度。STDyn-SLAM[15]同样使用了语义分割网络、光流法和几何约束来消除动态物体,并且能够重建剔除动态物体后的三维场景。
但上述这些方法都仅仅只是简单地剔除掉动态特征点,当动态物体占据相机大部分视场,则无法被神经网络正确识别,导致系统无法剔除掉这些特征点。目前大多数SLAM算法都会采用RANSAC[16]算法或鲁棒核函数[17]来降低异常值的影响,如果环境中仅有少数的动态特征点,这些方法确实能起到一定作用。但如果图像中大多数特征点都属于移动物体,这些方法所起的作用就十分有限,从而极大地影响了状态估计的准确性。因此一些研究人员尝试结合IMU并降低相机部分的优化权重进行位姿估计,以提高算法在动态环境中的鲁棒性。如DVI-SLAM[18]根据对极几何约束检测动态点,并添加视觉信息自适应权重因子,提高了系统的鲁棒性。Song等人[19]提出了一个鲁棒的BA函数,它可以利用IMU预积分估计的先验姿态来消除动态对象特征点的影响。但这类方法始终会将动态点加入到后端优化中,并且直接使用视觉权重因子会影响实时外参估计的准确性。此外,一些研究尝试将语义信息融合到后端优化中来提升定位精度,如Lianos等人[20]提出了语义重投影误差,该误差对齐两帧之间特征点的语义标签,增强了数据关联性,从而减少轨迹漂移。SDVO[21]结合了直接法的光度误差和语义概率误差,构造出新的误差函数,该函数具有更好的凸性,在优化迭代中有着更稳定的性能。但是这类方法如果直接应用在动态场景中,同样会受到动态物体的影响,鲁棒性不强。
综上所述,仅在前端剔除动态点或者仅在后端利用语义信息形成数据关联来提升定位精度的方法依然存在一些缺陷,并且不能够充分地利用场景中的语义信息;而如果直接采用降低相机部分优化权重的策略来提高算法在动态环境中的鲁棒性,会影响实时外参估计的准确性。因此,为充分地利用语义分割网络得到的信息,本文针对室外的动态场景和静态场景,使用单目相机和惯性传感器,在VINS-Mono算法的基础上进行改进,提出了一种将语义信息融入前后端的视觉惯性SLAM算法SF-VINS。本文的主要工作如下:
a)将实时语义网络与前端模块融合,筛选提取到的特征点,避免动态特征点参与后端优化。
b)提出了一种结合光流法的重投影误差和语义概率误
差的后端优化方法,从而提升算法在静态环境和动态环境中的准确性和鲁棒性。
c)为每个特征点分配动态权重,并优化了外参估计策略,能有效降低离群点对状态估计的影响。
本文使用VIODE[4]和NTU VIRAL[22]数据集对SF-VINS算法进行测试,并与STDyn-SLAM、ORB-SLAM3和DynaVINS算法作比较。
1 视觉惯性SLAM算法框架
SF-VINS的算法框架是基于VINS-Mono进行构建的,如图1所示,共包含特征点提取和跟踪模块、系统初始化模块和后端优化模块三大模块。本文着重对特征点提取和跟踪模块和后端优化模块进行了优化改进。在特征点提取和跟踪模块中,提取特征点时设置语义掩膜,以避免在动态物体上提取特征点,并在跟踪过程中根据语义分割结果剔除动态特征点匹配对。在后端优化模块中,利用语义网络输出的语义概率来构造语义概
率误差约束项,以限制状态估计,并根据每个特征点的误差总和大小对特征点进行加权,最终结合先验误差、视觉重投影误差、IMU误差和语义概率误差进行系统状态估计,得到每一帧的位姿信息和每一个特征点的空间位置。
2 动态特征点剔除
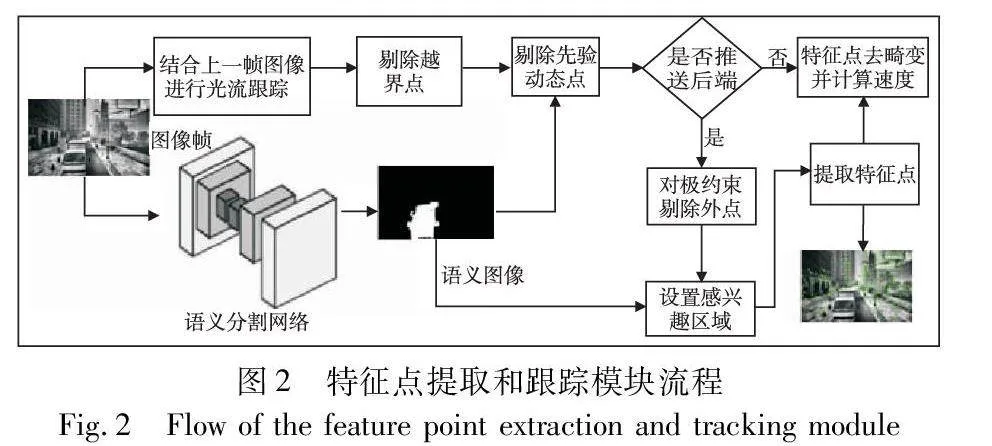
对于VINS-Mono算法,动态特征点的匹配会导致错误的数据关联,从而影响位姿估计的准确度。而静态特征点相比动态特征点对位姿估计具有着更强的鲁棒性,因此本文在前端根据语义分割网络输出的语义标签形成语义掩模,进而在静态物体上提取特征点,用于后端优化中的位姿估计。本文使用在Cityscapes数据集[23]上训练的实时语义分割网络PP-LiteSeg[24]作为语义信息的来源,该网络是一个轻量级的图像语义分割模型,由PaddlePaddle深度学习框架开发团队提出,该网络采用了编解码器架构,使用灵活和轻量级解码器、统一注意力融合模块和简单金字塔池化等轻量级网络结构,并对模型进行了多个细节优化,兼顾了网络推理的实时性和准确性,并有一定的泛化能力,适合与SLAM算法一起使用。训练后的网络能够对室外场景出现的道路、建筑、植被、天空、汽车、行人等34类物体进行像素级语义识别。特征点的提取和跟踪流程如图2所示。
以下是需要被推送到后端图像的前端处理流程:
a)特征点提取和跟踪模块读入一帧新图像后,送进语义分割网络获得像素级语义图像;
b)使用该帧的原图像结合上一帧图像的特征点进行光流跟踪;
c)剔除跟踪后落在图像外的特征点匹配对;
d)剔除先验动态物体上的特征点匹配对;
e)利用对极约束剔除外点;
f)根据配置文件中的特征点最小距离设置特征点均匀分布掩膜;
g)结合语义掩膜和特征点均匀分布掩膜生成感兴趣区域;
h)利用上一步生成的感兴趣区域,使用good_feature_to_track算法[25]提取新的特征点,供下一帧的光流跟踪使用。
这样便实现了特征点的均匀分布以及防止在动态物体上提取特征点。最后再计算该帧提取和跟踪到的特征点速度以及对其进行去畸变的操作。通过这些处理步骤,特征点提取和跟踪模块能够更加稳定地跟踪静态目标并提高算法的鲁棒性。图3(a)为原始图像帧;图3(b)是经语义分割网络预测得到的动态区域图,白色区域即为动态区域;图3(c)为原本提取和跟踪到的特征点分布图,三角形特征点表明该特征点落在静态区域,圆形特征点表明该特征点落在动态区域;图3(d)为使用语义掩膜后的特征点分布图,可看出结合语义掩膜来提取特征点后,并没有特征点落在行驶车辆上。
大部分语义SLAM算法采用先提取特征点再剔除的策略,这种策略会导致特征点数量的下降,而本文算法结合语义掩膜来避免在动态区域上提取特征点,能让每帧图像都拥有足够数量的静态特征点用于位姿估计,从而保证位姿估计的准确性。
3 后端非线性优化
3.1 语义概率误差
由于特征点会随着相机视角、尺度、光照的变化而发生变化,相比之下,特征点的语义信息不会受上述因素的影响,例如上一帧标记为A类的点投影到当前帧后,应该落在当前帧中对应的A类区域。因此,可以将这种语义不变性应用到数据关联中,建立起连续图像帧之间的语义信息约束[20]。本文构建语义概率误差约束项的假设是:某特征点经过位姿变换后,该特征点在前后两帧的语义概率保持不变。从PP-LiteSeg网络的推理结果中,可以得到每一帧关于不同物体的语义概率图,而由于建筑类物体在实际环境中相对固定不动,且在室外场景中常见,可作为语义概率对齐的参照对象,所以本文选择关于建筑类的语义概率图来构造语义概率误差约束项。
如图4所示,相机在两个位置对同一空间点P进行观察,假设空间点P被相机帧i观测到并落在了相机帧i的第k个特征点,对应的像素坐标为pki,该特征点经过相机的估计位姿转换后,落在相机帧j的像素坐标为kj。
假设经过位姿转换后,特征点的语义概率不变,则定义语义概率误差为
esemi, j,k=S(kj)-S(pki)(1)
其中:S(·)表示某个像素坐标在对应相机帧中的语义概率。
为了得到空间点P在第j帧相机系下的估计像素坐标,首先需要获得空间点P在第j帧相机系下的空间坐标kj。为了说明,先进行一些符号定义,记世界坐标系下第i帧的旋转和平移为Rwbi和twbi,第j帧的旋转和平移为Rwbj和twbj,外参为Rbc和tbc,空间点P在第i帧相机系下的坐标为Pki。
由于本文算法使用IMU坐标系作为基准,所以需要经过多次转换才能将空间点P从第i帧的相机系重新投影到第j帧的相机系。具体的转换过程如下:首先通过外参Rbc和tbc将空间点坐标从第i帧的相机系转换到第i帧的IMU系;再用第i帧的估计位姿Rwbi和twbi,从第i帧的IMU系转换到世界系下;之后利用第j帧估计位姿的逆旋转RTwbj和逆平移tbjw,从世界系转换到第j帧的IMU系;最后再通过外参转换得到空间点P在第j帧相机系下的空间坐标P^kj。化简后的转换公式如下:
P^kj=X′Y′Z′=RTbcRTwbjRwbiRbcPki+
RTbc(RTwbj((Rwbitbc+twbi)-twbj)-tbc)(2)
得到空间点P在第j帧相机系下的空间坐标后,再通过相机内参将空间点投影到像素平面上即可获得像素坐标,投影关系为
u=fxX′Z′+cx
v=fyY′Z′+cy(3)
其中: fx和fy表示相机焦距;cx和cy表示相机主点位置。
为最小化语义概率误差,即最小化式(1),需要提供语义概率误差对各个优化变量的雅可比。定义优化变量为
Ψki, j=[Rwbi,twbi,Rwbj,twbj,λk]T(4)
其中:λk为特征点pki在第i帧的逆深度。则语义概率误差对优化变量的雅可比可通过链式求导法则得到
esemi, j,kΨki, j=S(kj)kj·kjP^kj·P^kjΨki, j(5)
假设估计像素坐标(u,v)处的语义概率值对像素坐标的雅可比为
S(kj)kj=[nx ny](6)
其中:nx为估计像素点在语义概率图中x方向上的梯度;ny为估计像素点在语义概率图中y方向上的梯度。
假设估计像素点附近3×3区域的语义概率为
Au,v=S(u-1,v-1)S(u,v-1)S(u+1,v-1)S(u-1,v)S(u,v)S(u+1,v)S(u-1,v+1)S(u,v+1)S(u+1,v+1)(7)
则可采用算子式(8)与Au,v进行卷积运算,得到估计像素点(u,v)处的语义概率值对像素坐标的雅可比。
Nx=-303-909-303,Ny=-3-9-3000393(8)
即
S(kj)kj=[Au,vNx Au,vNy](9)
其中:表示卷积运算。如果遇到语义概率图像的边缘没有左右像素的情况,本文将超出边界的像素值设置为0,即在图像外圈进行“零填充”,确保雅可比计算的正确性。
根据式(3),易得第j帧的估计像素坐标kj对估计空间点坐标P^kj的雅可比,如式(10)所示。
kjP^kj=fxZ′0-fxX′Z′20fyZ′-fyY′Z′2(10)
而估计空间点坐标P^kj对各个优化变量的雅可比如式(11)所示。
P^kjΨki,j=P^kjRwbiP^kjtwbiP^kjRwbj
P^kjtwbj
P^kjλk=RTbcRTwbjRwbi[Pki]×RTbcRTwbj
RTbc[Pbj]×
-RTbcRTwbj-1λkRTbcRTwbjRwbiRbcPki(11)
其中:前两项分别为估计空间点坐标对第i帧IMU在世界系下旋转向量和平移向量的偏导数;第三和四项分别为第j帧IMU在世界系下旋转向量和平移向量的偏导数;最后一项为估计空间点坐标对该特征点在第i帧相机系下逆深度的偏导数;[·]×表示将括号中的向量反对称化,假设有某向量v=[v1 v2 v3],则
[v]×=0-v3v2v30-v1-v2v10(12)
通过链式求导法则,将原本需要求解的雅可比矩阵分解成三个不同的雅可比矩阵,分别求出这三个雅可比矩阵后再进行连乘,即可得到原本的雅可比矩阵,从而可以使用非线性优化算法来进行状态估计。
3.2 特征点加权
当某个动态物体在相机图像中不完整,或者占据了相机图像大部分面积时,语义网络将无法正确地识别该动态物体,因此仅在特征点提取和跟踪模块中剔除先验动态特征点,不足以降低动态物体给算法所带来的影响,尽管鲁棒核函数同样可以抑制外点,但其效果有限。而惯性传感器的测量值不受动态物体的影响,如果使用特征点自适应权重,当动态物体出现时,动态特征点的权重会降低,能够使估计结果更偏向于IMU。因此本文方法使用特征点自适应权重,除了在动态场景下能够让估计结果更偏向于IMU,还能降低语义分割网络无法识别的动态点的权重,从而使状态估计的结果更加精确。
本文对每个特征点赋予不同的权重,如果特征点的匹配误差越大,权重越低,从而降低匹配误差大的特征点在后端优化中的影响。根据文献[19,26]提出的BR对偶性,通过最小化式(13)的误差,可得到每个特征点的最优权重。
ρ(wi,rvisi)=w2i∑j∈f(pi)‖rvisi, j‖2+αR2(wi)+βM2(wi)(13)
其中:rvisi, j为重投影误差,在此优化问题中为常数;α和β为常系数;R(wi)为正则化项,如式(14)所示。正则化项可令误差越高的特征点,权重越接近于0,反之权重越接近于1。
R(wi)=1-wi(14)
M(wi)为动量项,如式(15)所示,如果不设置动量项,当相机快速运动时,重投影误差会突然增大而造成特征点权重快速降低,设置动量项能使权重的变化更加平缓。
M(wi)=ti(i-wi)(15)
其中:ti为该特征点权重之前的优化次数,该特征点权重优化次数越多,证明它被更多的相机帧观测到,因此该特征点的权重要处于一个相对平稳的状态;i为该特征点上一次的权重。
在设置权重时,本文先将特征点的重投影误差固定住,当作常数因子,因此上述问题可转换成一个一元二次方程。为简要说明,记某个特征点的重投影误差总和为Ri,易得当式(13)取最小值时,权重应为
wi=α+2itiβRi+α+tiβ,i∈(0,1](16)
从式(16)可得,特征点的权重被控制在0和1之间,当特征点的重投影误差越小,则权重越接近于1,表明越信赖该特征点。相反地,当特征点的重投影误差越大,则权重越接近于0,间接抑制了该特征点在后端优化中的负面效果。而通常动态特征点的重投影误差较大,因此该方法能有效消除离群点对状态估计带来的影响。
3.3 紧耦合的视觉惯性语义联合优化算法
后端模块优化的是整个滑动窗口里面所有的状态量,状态向量为
χ=[x0,x1,…,xn,xbc,λ0,…,λm]
xk=[pwbk,vwbk,qwbk,bbka,bbkg]T k∈[0,n]
xbc=[pbc,qbc](17)
其中:xk为第k个图像帧对应的IMU状态,包括在世界系下IMU的平移pwbk、速度vwbk、旋转qwbk、加速度计零偏bbka和陀螺仪零偏bbkg;xbc包括了相机到IMU的旋转qbc和平移pbc;λi为第i个特征点的逆深度;n为关键帧数量;m为滑动窗口中观测到的特征点总数。
本文后端采用基于滑动窗口的非线性优化方法,固定窗口大小,当新的一帧图像到来时会边缘化旧的图像帧,因此还需要考虑先验误差。通过最小化各个模块的误差总和,来优化滑动窗口中所有的状态量,从而融合了视觉信息、语义信息和IMU信息。综上,本文构造的误差函数如式(18)所示,包含了先验误差、IMU预积分误差、视觉误差和语义概率误差四部分。
minχ‖rp-Jpχ‖2+∑i∈B‖rb(bibi+1,χ)‖2+
λ∑(i, j)∈F‖rs(cij,χ)‖2+∑(i, j)∈Fρ(‖ωirf(cij,χ)‖2)
(18)
其中:rp表示先验误差;Jp为边缘化后留下的先验信息;rb表示IMU预积分误差;bibi+1表示IMU观测;λ表示语义概率误差的优化权重;rs表示语义概率误差;ρ(·)表示鲁棒核函数;cij表示语义概率观测;rf表示视觉误差;cij表示视觉观测。
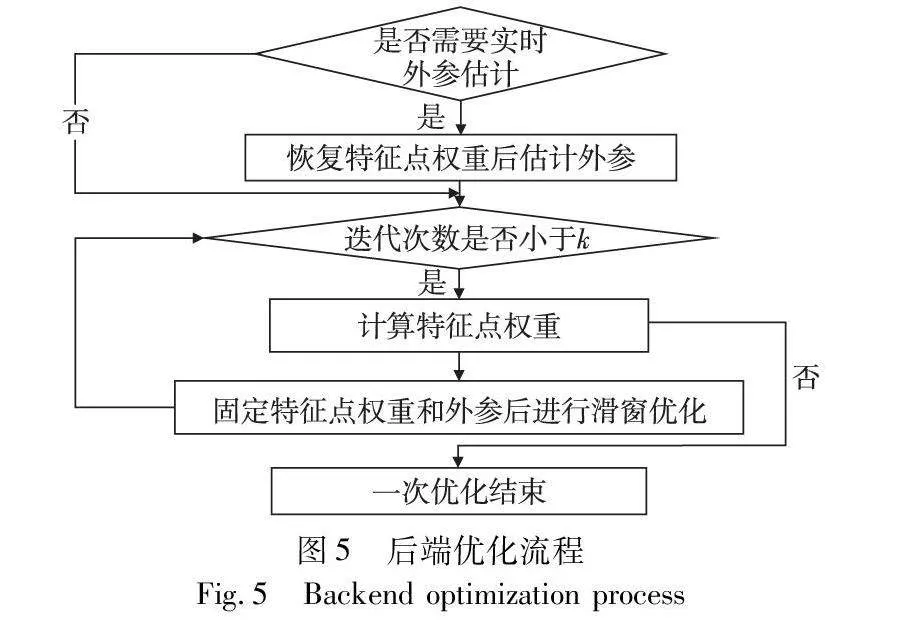
值得注意的是,在没有准确外参或外参可能实时变化的情况下,需要实时地将视觉信息和IMU信息进行对齐来估计外参。由于使用了特征点自适应权重,会使视觉权重整体下降,而实时外参估计需要完整的视觉信息和IMU信息,降低视觉权重会导致实时外参估计受到较大的影响,使得轨迹发生严重漂移。因此本文在需要实时估计外参xbc时,假设滑动窗口内所有帧的外参保持不变,先不改变特征点的权重,使用式(18)对外参进行一次估计得到固定外参T,然后使用固定外参T和动态特征点权重再进行迭代优化。一次完整的后端优化流程如图5所示。首先恢复视觉权重,即将特征点权重设置为1,再联合IMU数据估计得到本次滑动窗口优化的固定外参,然后根据上一轮的视觉误差最小化式(13)后,获得每个特征点的权重,接着再根据式(18)进行优化,如此迭代k次后获得最终的状态估计结果。这样便可以避免出现因降低视觉权重而影响外参估计的问题,同时也保证了动态特征点权重的效果,提高了算法的鲁棒性。
4 实验与分析
本文的实验环境为装有INTEL I7-7700K CPU、 NVIDIA GTX 1080TI GPU、16 GB内存和Ubuntu 18.04系统的台式主机。语义分割网络采用经过Cityscapes数据集训练的PP-LiteSeg模型,并使用paddle deployment inference工具将PP-LiteSeg模型集成到SF-VINS算法中。
本文实验具体分为三部分。首先在具有动态环境的VIODE数据集上测试,用来评估算法在动态环境中的定位精度;其次在具有静态校园环境的NTU VIRAL数据集上测试,验证算法在不经过网络训练且静态的场景下的鲁棒性;最后对算法进行消融实验,更好地体现出不同模块所起的作用。为了保证公平,所有对比算法和SF-VINS的实验结果均在同一平台上进行测试,且每个序列至少运行三次并取中位数作为最终结果。实验使用绝对轨迹误差(absolute trajectory error, ATE)来评估算法效果,即比较估计位姿和真实位姿的欧几里德距离的均方根差、中位数、平均数以及标准差。
4.1 VIODE数据集
VIODE数据集使用了一个四旋翼无人机作为载体,其搭载了两个摄像头和一个惯性传感器。city_day包括四个有着城市白天环境的图像序列,其场景包含了高大的建筑和树木,city_night包括了与city_day相同环境下的四个夜间图像序列,但无人机的轨迹和动态物体的轨迹不同于city_day。各序列的名称后缀none到high表示序列中包含动态物体的程度。
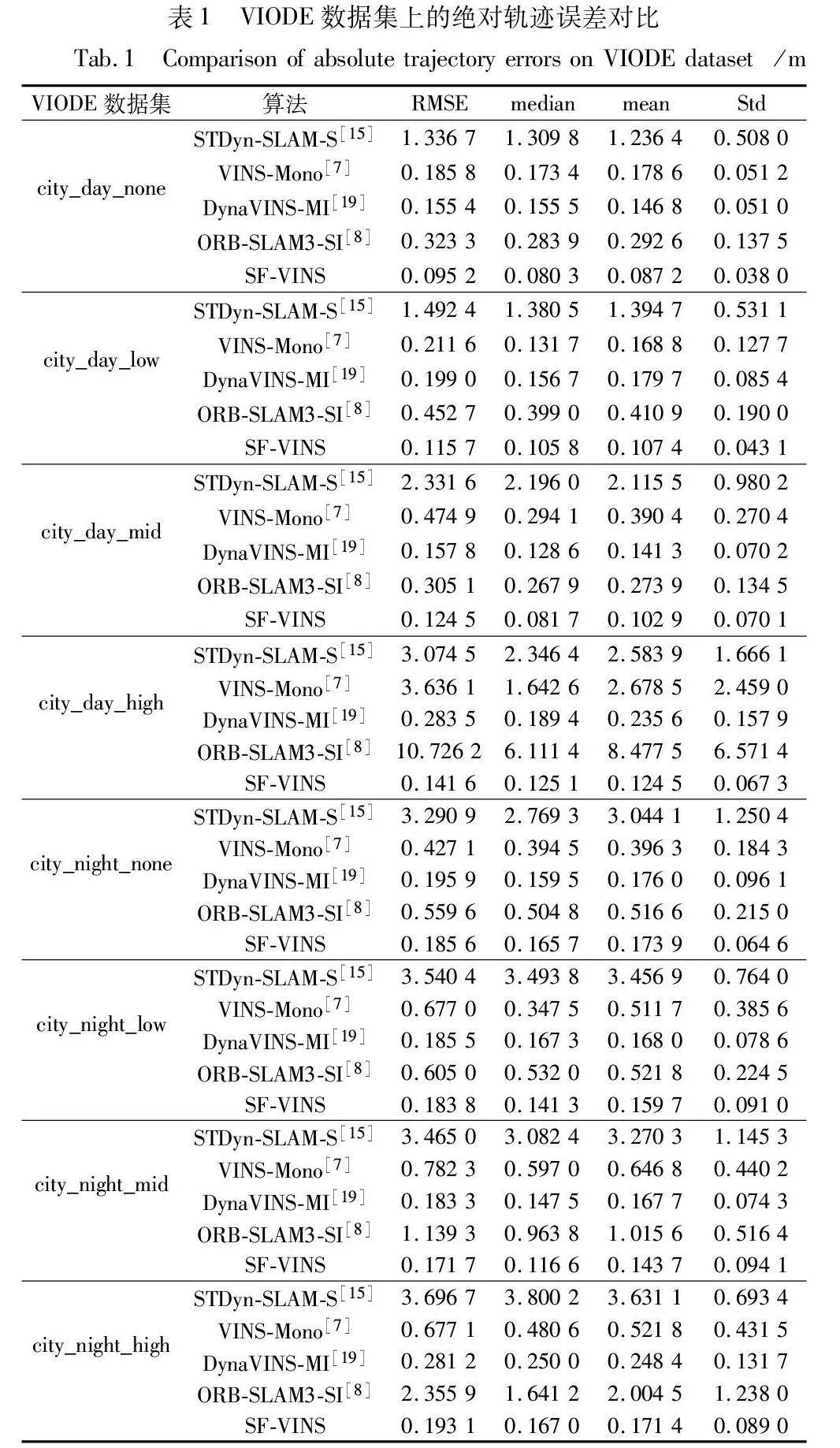
本文仅使用左摄像头数据和惯性传感器数据进行实验。表1为SF-VINS与STDyn-SLAM双目、VINS-Mono单目惯性、ORB-SLAM3双目惯性、DynaVINS单目惯性四个算法的对比实验结果。
从表1的八个序列对比结果可得,SF-VINS仅使用单目相机和惯性传感器作为输入,但大部分的估计轨迹均比上述四个算法的定位精度更高、误差更低。对比不同动态物体程度的序列,其他对比算法的轨迹误差会随着动态物体的增多而会有显著的上升,但SF-VINS的误差变化处于相对平稳的趋势,STDyn-SLAM虽然同样使用了动态点剔除算法,但由于缺失惯性传感器的辅助,仅使用了双目摄像头作为数据来源,导致算法受环境的影响较大,这从侧面证明了惯性传感器在动态环境中的重要性。DynaVINS由于没有在前端剔除动态点,仅在后端降低了离群点的影响,这样依然会将有噪声的数据纳入到后端优化中,因此DynaVINS在最高动态序列中所受的影响较大。而且注意到,即使在静态序列city_night_none和city_day_none中,得益于新的BA优化函数,SF-VINS相比于VINS-Mono同样有不小幅度的提升,说明SF-VINS在动态环境和静态环境中均表现出了良好的性能,具有更好的鲁棒性。
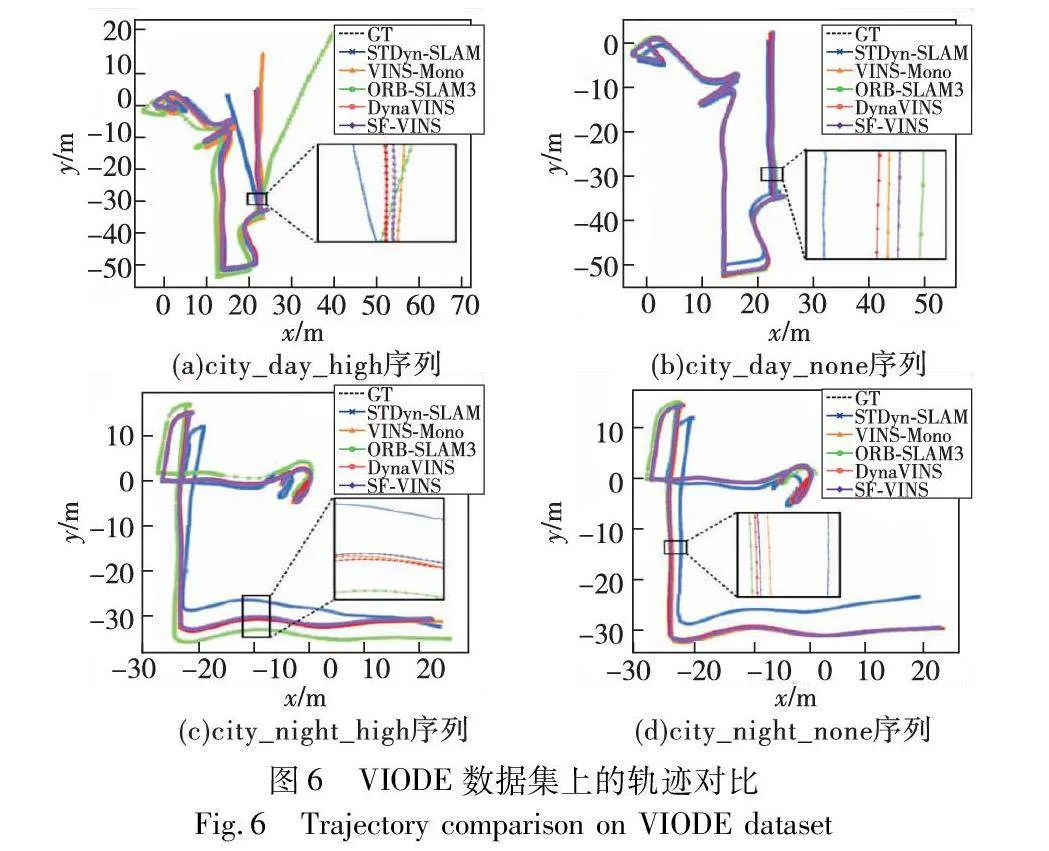
图6是上述五种算法在city_day_high、city_day_none、city_night_high、city_night_none四个序列上的估计轨迹与真实轨迹的对比,为方便对比,所有轨迹投影在xy平面上并进行局部放大。可看出SF-VINS估计的轨迹更接近于真实轨迹,并且优于其他四种算法。而且注意到在图6(a)的city_day_high序列中,VINS-Mono和ORB-SLAM3估计的轨迹偏移较大,这是因为在序列的后半段,有一辆行驶中的汽车占据了相机的大部分视场,导致该路段中几乎所有特征点都落在了动态物体上,严重影响了视觉信息的准确性。VINS-Mono和ORB-SLAM3算法并未能够有效地处理这种情况,因此轨迹发生了较大的漂移。而SF-VINS在剔除掉先验动态点的同时,降低了离群特征点的权重,弥补了在前端模块中仅删除先验动态点的缺陷,并将语义概率误差纳入后端优化中,为状态估计提供了更强的约束,因此没有发生较大的轨迹漂移,即使在高动态环境下依然有较好的定位精度。
4.2 NTU VIRAL数据集
NTU VIRAL数据集是南洋理工大学使用多传感器采集的一个SLAM数据集,包括两个三维激光雷达、两个相机、多个惯性传感器,数据采集于南洋理工大学校园内的某些场景。该数据集同样仅使用左摄像头数据和单个惯性传感器数据进行实验。本文在NTU VIRAL数据集中选取具有较多建筑场景的三个序列进行测试,都为静态序列。其中Sbs_01序列是在校内的一个开放广场上采集的,附近有一些低层建筑,Eee_01和Eee_02序列同样是在校内采集,该区域四面都是高大的建筑。需要注意的是,由于NTU VIRAL数据集使用无人机采集数据,快速运动过程中可能会出现外参变化的情况,所以该数据集要求算法能够对外参进行实时估计,否则无法稳定跟踪。而由于STDyn-SLAM算法在NTU VIRAL数据集上尺度估计不准确,无法稳定跟踪,所以在该数据集上不加入该算法进行测试。表2为SF-VINS与VINS-Mono单目惯性、ORB-SLAM3双目惯性、DynaVINS单目惯性三种算法的对比实验结果。
从表2对比结果可得,SF-VINS的实验结果在三个序列上的定位精度都要优于其他对比算法。在Sbs_01序列中,由于大部分特征点都处于较远的位置,ORB-SLAM3无法稳定跟踪特征点,导致轨迹发生严重漂移,而另外两个序列也存在小部分特征点处于较远位置的片段,所以ORB-SLAM3在三个序列中的轨迹误差都比较高。DynaVINS降低了视觉权重,影响了外参的实时估计,导致定位精度下降。而SF-VINS在三个序列上都很好地估计了变化的外参,并没有发生定位精度下降的问题,且在没有训练过的校园建筑场景中,相比VINS-Mono依然有13%~40%的性能提升,表明SF-VINS具有一定的泛化能力。从图7各个轨迹的对比可看出,SF-VINS的估计轨迹最接近真实轨迹。
4.3 消融实验
本文在两个数据集中挑选三个具有代表性的序列进行消融实验,以验证各个模块在不同场景下所起的作用。在表3中VINS+SEG表示只加入前端剔除先验动态特征点模块,VINS+NBA表示只使用新的BA代价函数,VINS+SEG+NBA表示同时使用前端剔除先验动态特征点模块和新的BA代价函数。
从表3中city_day_high和city_night_high序列的实验结果可知,仅加入SEG模块虽然能够提高一些定位精度,但如果场景中存在无法识别的动态物体或者动态物体占据了相机大部分视场时,此时SEG模块的作用相对有限;而如果仅使用新的BA代价函数,虽然也能一定程度地提高定位精度,但无可避免地将动态点纳入了后端优化中,影响了状态估计的准确性;同时使用SEG模块和新的BA代价函数,能够将特征点集中在先验静态物体上,并同时能够为状态估计提供更强的约束以及降低离群点对状态估计的负面影响。而在Sbs_01序列中动态特征点模块并没有起到正向作用,反而因为语义网络的误分类而误删了某些特征点,导致定位精度有略微下降,因此在静态环境中,起主要作用的是新的BA代价函数。
4.4 实时性评估
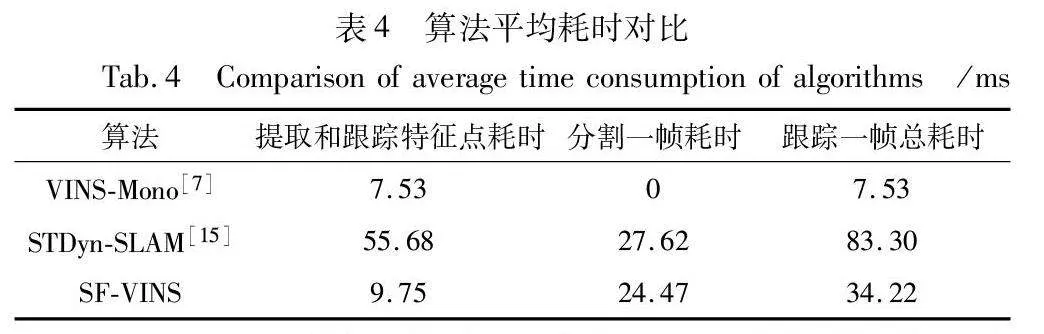
为了验证SF-VINS的实时性,并且为排除机器差异的影响,以下算法均在同一平台进行测试。以VIODE数据集中的city_night_high序列为例,该序列的图像分辨率为752×480,而本文测试的所有序列的图像分辨率均为752×480,且该序列包含高动态场景。因此,选择这个序列来比较SF-VINS和其他算法的实时性和精度具有一定的代表性。各算法每部分的平均耗时如表4所示。
SF-VINS由于添加了语义分割网络部分,并在提取和跟踪特征点时构建语义掩膜,所以相比VINS-Mono算法的总耗时有所增加,但依然有约29 fps的跟踪性能,基本满足实时性要求。对比同样使用语义分割网络的STDyn-SLAM,本文算法在各个部分的耗时都要低,因为本文使用的分割网络比STDyn-SLAM使用的SegNet的推理速度更快,而且SF-VINS采用光流法跟踪特征点,每张图像只需提取150~250个特征点即可,而STDyn-SLAM采用特征点法进行跟踪,每张图像需要提取上千个特征点,增加了不少耗时。结合表1定位精度的测试结果,并综合速度上的考虑,SF-VINS在动态环境和静态环境中的定位精度和鲁棒性均有一定优势,并且满足了实时性的要求。
5 结束语
本文提出了一种融合语义信息的单目视觉惯性SLAM算法SF-VINS,相比一些仅在前端剔除动态特征点的算法,SF-VINS将语义信息融合到后端优化,提供了更强的约束,并且采取特征点加权的策略降低了潜在动态点对系统状态估计的影响。而通过动态数据集VIODE和静态数据集NTU VIRAL验证了SF-VINS在动态环境和静态环境下具有更好的鲁棒性,且对比最新的视觉惯性SLAM算法,SF-VINS的定位精度更高。但所提算法仍有一些不足:由于加入了语义分割网络和更多的优化约束项,算法的实时性相比VINS-Mono有所降低;语义概率误差的准确性依赖于前端语义分割网络的效果,若语义分割网络的效果不佳,会使分割连续帧的效果不稳定,导致语义概率误差不准确,从而影响系统的状态估计。因此在未来的工作中,可采取更轻量级且泛化性能更强的语义分割网络,并改进后端优化策略,保证算法精度的同时提高实时性。更进一步地,可通过语义信息,构造出语义地图,给系统提供更精确的定位信息和场景理解。
随着人工智能的发展,SLAM算法不应只是针对场景的表面计算,更应该像人类一样试图理解当前场景的意义,这有助于SLAM算法具有更高的可靠性并应用于更广泛的场景。
参考文献:
[1]Cadena C,Carlone L,Carrillo H,et al. Past,present,and future of simultaneous localization and mapping: toward the robust-perception age[J]. IEEE Trans on Robotics,2016,32(6): 1309-1332.
[2]Urzua S,Munguia R,Grau A. Vision-based SLAM system for MAVs in GPS-denied environments[J]. International Journal of Micro Air Vehicles,2017,9(4): 283-296.
[3]高兴波,史旭华,葛群峰,等. 面向动态物体场景的视觉SLAM综述[J]. 机器人,2021,43(6): 733-750. (Gao Xingbo,Shi Xuhua,Ge Qunfeng,et al. A survey of visual SLAM for scenes with dynamic objects[J]. Robot,2021,43(6): 733-750.)
[4]Minoda K,Schilling F,Wuest V,et al. VIODE: a simulated dataset to address the challenges of visual-inertial odometry in dynamic environments[J]. IEEE Robotics and Automation Letters,2021,6(2): 1343-1350.
[5]Bloesch M,Omari S,Hutter M,et al. Robust visual inertial odometry using a direct EKF-based approach[C]// Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway,NJ: IEEE Press,2015: 298-304.
[6]Leutenegger S,Lynen S,Bosse M,et al. Keyframe-based visual-inertial odometry using nonlinear optimization[J]. International Journal of Robotics Research,2014,34(3): 314-334.
[7]Qin Tong,Li Peiliang,Shen Shaojie. VINS-Mono: a robust and versatile monocular visual-inertial state estimator[J]. IEEE Trans on Robotics,2018,34(4): 1004-1020.
[8]Campos C,Elvira R,Rodríguez J J G,et al. ORB-SLAM3: an accurate open-source library for visual,visual-inertial and multi-map SLAM[J]. IEEE Trans on Robotics,2021,37(6): 1874-1890.
[9]Mur-Artal R,Tardós J D. ORB-SLAM2: an open-source SLAM system for monocular,stereo,and RGB-D cameras [J]. IEEE Trans on Robotics,2017,33(5): 1255-1262.
[10]Yu Chao,Liu Zuxin,Liu Xinjun,et al. DS-SLAM: a semantic visual SLAM towards dynamic environments[C]// Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway,NJ: IEEE Press,2018: 1168-1174.
[11]Bescos B,Fácil J M,Civera J,et al. DynaSLAM: tracking,mapping,and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters,2018,3(4): 4076-4083.
[12]Cheng Junhao,Wang Zhi,Zhou Hongyan,et al. DM-SLAM: a feature-based SLAM system for rigid dynamic scenes[J]. ISPRS International Journal of Geo-Information,2020,9(4): 202.
[13]He Kaiming,Gkioxari G,Dollár P,et al. Mask R-CNN[C]// Proc of International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2017: 2961-2969.
[14]王富强,王强,李敏,等. 基于动态分级的自适应运动目标处理SLAM算法[J]. 计算机应用研究,2023,40(8): 2361-2366. (Wang Fuqiang,Wang Qiang,Li Min,et al. Adaptive moving object processing SLAM algorithm based on scene dynamic classification[J]. Application Research of Computers,2023,40(8): 2361-2366.)
[15]Esparza D,Flores G. The STDyn-SLAM: a stereo vision and semantic segmentation approach for VSLAM in dynamic outdoor environments[J]. IEEE Access,2022,10: 18201-18209.
[16]Fischler M A,Bolles R C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated carto-graphy[J]. Communications of the ACM,1981,24(6): 381-395.
[17]Li Xuelong,Lu Quanmao,Dong Yongsheng,et al. Robust subspace clustering by Cauchy loss function[J]. IEEE Trans on Neural Networks and Learning Systems,2019,30(7): 2067-2078.
[18]崔林飞,黄丹丹,王祎旻,等. 面向动态环境的视觉惯性SLAM算法[J]. 计算机工程与设计,2022,43(3): 713-720. (Cui Linfei,Huang Dandan,Wang Yimin,et al. Visual inertial SLAM algorithm for dynamic environment[J]. Computer Engineering and Design,2022,43(3): 713-720.)
[19]Song S,Lim H,Lee A J,et al. DynaVINS: a visual-inertial SLAM for dynamic environments[J]. IEEE Robotics and Automation Letters,2022,7(4): 11523-11530.
[20]Lianos K N,Schonberger J L,Pollefeys M,et al. VSO: visual semantic odometry[C]// Proc of European Conference on Computer Vision. Cham: Springer, 2018: 234-250.
[21]Bao Yaoqi,Yang Zhe,Pan Yun,et al. Semantic-direct visual odometry[J]. IEEE Robotics and Automation Letters,2022,7(3): 6718-6725.
[22]Nguyen T M,Yuan Shenghai,Cao Muqing,et al. NTU VIRAL: a visual-inertial-ranging-lidar dataset,from an aerial vehicle viewpoint[J]. The International Journal of Robotics Research,2022,41(3): 270-280.
[23]Cordts M,Omran M,Ramos S,et al. The cityscapes dataset for semantic urban scene understanding[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 3213-3223.
[24]Peng Juncai,Liu Yi,Tang Shiyu,et al. PP-LiteSeg: a superior real-time semantic segmentation model[EB/OL]. (2022-04-06). https://arxiv.org/abs/2204.02681.
[25]Shi Jianbo,Tomasi C. Good features to track[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,1994: 593-600.
[26]Black M J,Rangarajan A. On the unification of line processes,outlier rejection,and robust statistics with applications in early vision[J]. International Journal of Computer Vision,1996,19(1): 57-91.
