
基于深度半监督学习的小样本金属工件表面缺陷分割
2024-08-15 00:00:00徐兴宇钟羽中涂海燕佃松宜
计算机应用研究 2024年8期







摘 要:针对工业应用场景下缺少缺陷样本的问题,提出了一种仅需要极少缺陷样本的金属工件表面缺陷分割方法。该方法结合了图像生成技术和半监督学习策略,通过利用极少缺陷图像提取的小尺寸缺陷图像来训练缺陷生成模型,然后将生成的缺陷图像嵌入到正常图像中以实现数据增广。其次,采用半监督学习策略训练分割网络,以减小生成数据与真实数据分布之间的差异对模型的不良影响。在真实的金属工件机器视觉检测系统上的验证结果表明,半监督的训练策略提高了分割模型对真实缺陷的泛化能力,所提方法能够在仅使用5张缺陷样本图像的条件下取得较高的分割精度。
关键词:半监督学习;表面缺陷检测;图像分割;小样本;数据增广
中图分类号:TP391.41 文献标志码:A 文章编号:1001-3695(2024)08-042-2540-06
doi: 10.19734/j.issn.1001-3695.2023.10.0560
Deep semi-supervised learning approach for few-shot segmentation of surface defects on metal workpieces
Xu Xingyu, Zhong Yuzhong, Tu Haiyan, Dian Songyi
(College of Electrical Engineering, Sichuan University, Chengdu 610065, China)
Abstract:
In response to the scarcity of defect samples in industrial applications, this paper proposed a method for segmenting surface defects in metal workpieces with only a minimal number of required defect samples. The method combined image gene-ration techniques with a semi-supervised learning strategy. It utilized small-sized defect patches, and extracted from a minimal number of defect images to train a defect generation model. Subsequently, the method integrated these generated defect images into normal images to facilitate data augmentation. Additionally, the method applied a semi-supervised learning strategy to train the segmentation network, aiming to mitigate the adverse effects of differences between generated and real data distributions. The experimental phase involved conducting tests on a real-world computer vision detection system for metal workpieces. The results demonstrate that the semi-supervised training strategy significantly enhances the segmentation model’s generalization ability to real defects. The method achieves high segmentation accuracy using only five defect sample images.
Key words:semi-supervised learning; surface defect detection; image segmentation; few-shot; data augmentation
0 引言
金属工件的生产是一个多因素耦合的复杂过程,由于生产设备的设计不完善或运行过程中受磨损、受潮等因素影响,生产出的工件金属表面可能存在各种类型的缺陷。金属工件表面缺陷影响了工件的强度、疲劳性能,严重的表面缺陷甚至影响工件关联设备的安全运行或降低设备使用寿命。因此,在生产过程中及时检测和分析金属工件的表面缺陷,是提高生产质量和工件可靠性的重要步骤。
在过去的研究中,许多基于传统图像处理的方法被用于金属的表面缺陷检测,包括基于阈值[1]、聚类[2]和频谱[3]等方法。传统的机器学习方法[4]也被应用于金属表面缺陷检测,主要包括特征提取及分类两部分。但是,传统图像处理的方法通常基于人工提取缺陷特征,人力投入较大;另一方面,又容易受到环境变化的影响,泛化能力差[5]。
近年来,基于深度学习的计算机视觉方法被广泛使用于检测工业产品或材料中的缺陷[6]。部分学者基于目标检测模型实现缺陷检测与定位。苏迎涛[7]提出了一种基于显著区域提取和改进型YOLO-V3的缺陷检测方法,实现了金属齿轮加工端表面缺陷的快速检测和定位。张乃雪等人[8]采用基于DETR的编码-解码结构对缺陷类别和位置进行预测,降低了参数量和计算复杂度。此外,部分学者通过语义分割模型实现表面缺陷的像素级检测与分割。王一等人[9]基于U-Net语义分割模型,结合多尺度自适应形态特征提取及瓶颈注意力机制实现了金属工件表面缺陷分割。Wang等人[10]提出一种改进的DeepLabV3+语义分割模型,在网络中引入注意力机制,并将ASPP模块替换为D-ASPP模块,实现了磁柱缺陷的高精度分割。
然而,在多数的实际应用场景中,由于生产的良品率高、产品造价昂贵、不适于在其上人工模拟缺陷等原因,只能收集到极少数的缺陷样本。因此,许多学者开始关注缺少缺陷样本情况下的缺陷检测算法研究。
小样本学习指利用包含少量监督信息的数据实现学习任务[11],主要分为基于度量的元学习方法[12]、基于微调的方法[13]和基于数据增广[14]的方法。目前小样本的图像分割算法研究侧重于从少量支持图像中获得高质量的原型来准确地预测结果,包括PANet[15]、MSANet[12]等方法。许国良等人[16]提出了一种小样本手机屏幕缺陷分割网络,引入了协同注意力来加强支持图像与查询图像之间的特征信息交互。这类方法从有限的支持集中提取实例知识,难以用于分割具有较大类内差异的工业产品缺陷。部分学者通过生成对抗网络(GAN)[17,18]、变分自编码器(VAE)[19]等生成模型生成更多的缺陷数据来扩充训练集,从而提高模型性能[20]。Liu等人[21]使用GAN来评估缺陷图像上的缺陷特征分布并生成缺陷,然后使用生成缺陷构建的数据集来训练Faster R-CNN,实现缺陷检测。然而,该类方法存在生成模型在缺少缺陷样本的情况下难以优化的问题,生成的图像质量低、多样性低,导致生成数据与真实数据间存在分布差异,最终导致分割模型偏向生成数据过拟合。
另一方面,部分学者通过利用半监督学习的方式来进行缺少缺陷样本情况下的缺陷检测任务。Rudolph等人[22]使用了一种归一化流的半监督方法,在使用少量缺陷样本的情况下实现了较好的缺陷像素级定位。半监督结合了监督与无监督的方法,利用少量标注数据训练模型。自训练[23]被认为是半监督学习中熵最小化的一种形式,利用模型自身的预测结果来监督后续训练。Zhu等人[24]首先在标记数据上训练教师模型,然后在大量未标记数据上生成伪标签,展示了自训练在跨域泛化任务上的有效性优于传统的微调方法[25]。部分研究者将自训练与GAN[26]、对比学习[27]等方法结合,实现了高精度的半监督图像分割。
综上所述,本文提出了一种基于深度半监督学习的小样本金属工件表面缺陷分割算法。其主要有以下贡献:
a)针对缺少缺陷样本的工业检测场景,提出了一种仅需极少缺陷样本的缺陷分割框架。所提出的方法结合图像生成和半监督学习的技术,在仅利用5张缺陷样本图像和50张正常样本图像的条件下实现了高精度的缺陷分割。
b)针对生成模型在缺少训练数据的情况下不易优化的问题,提出了一种利用少量缺陷样本和大量正常样本的数据增广方法。该方法采用从原始图像中提取的小尺寸缺陷图像训练DCGAN模型,再将生成的小尺寸缺陷图像随机嵌入正常图像的工件区域。
c)针对生成数据与真实数据之间的分布差异,提出了对增广后的数据采用半监督学习的策略训练分割模型,以削弱模型对生成数据的过拟合。对利用生成模型数据增广后的数据集部分标注后采用自训练的策略进行训练。
1 方法框架
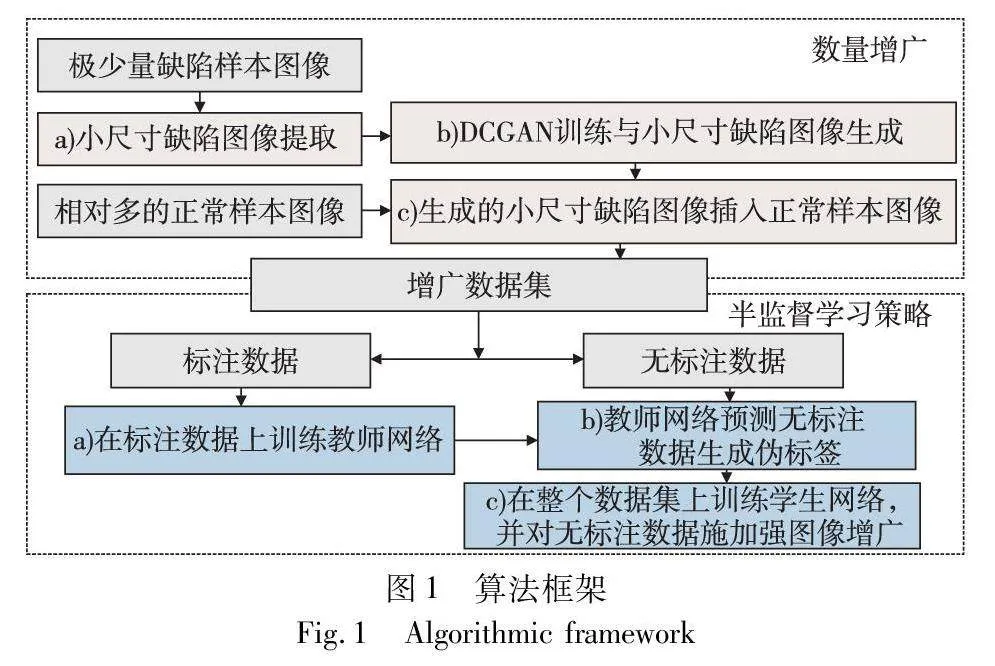
本文方法的整个流程主要由数据增广和半监督学习策略两部分组成,如图1所示。
首先,本文方法利用少量缺陷样本图像和相对多的正常样本图像进行数据增广。为了解决GAN等生成模型在缺少训练数据的情况下难以优化的问题,使用从缺陷样本图像中提取的小尺寸缺陷图像训练DCGAN生成模型,旨在增加训练数据量的同时提高生成缺陷图像的质量。随后,将训练完成的生成模型生成的小尺寸缺陷图像随机嵌入正常样本图像,在保证背景信息真实性的同时充分利用了正常样本数据。
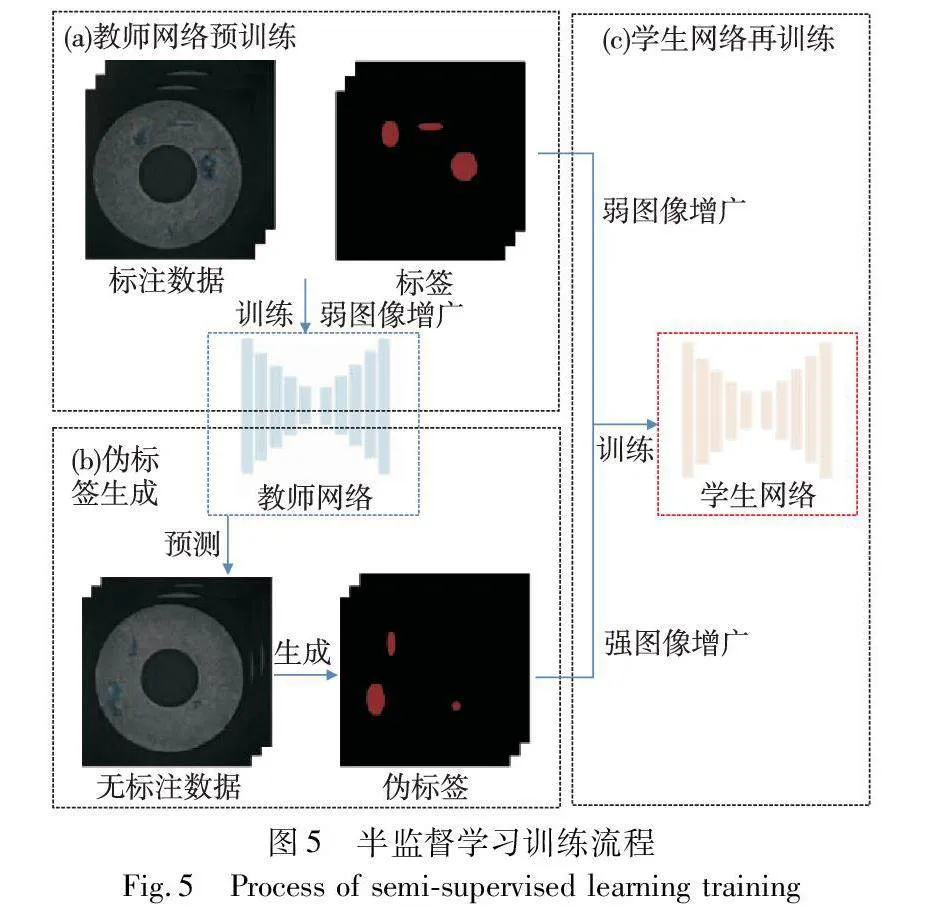
其次,为了应对生成数据与真实数据之间分布差异对分割模型的负面影响,主要是由生成数据训练的分割网络偏向生成数据过拟合的问题,本文提出对生成数据利用半监督学习的策略训练分割网络。具体地,本文方法对上述数据增广方法增广后的增广部分标注后,采用自训练的框架训练分割网络,并在不同阶段施加了不同强度的图像增广。其中,在教师网络训练阶段施加弱图像增广,在学生网络训练阶段对无标注数据施加CutMix在内的强图像增广策略(strong data augmentation,SDA)。
2 数据增广
2.1 生成模型
鉴于可供训练的数据量较少,StyleGAN[28]等复杂度高的模型在训练的过程中不易收敛,通过增广训练集使其收敛容易过拟合,生成的图像多样性差;复杂度过低的模型,如原始的GAN模型,生成的图像质量较差,图像含有噪点且缺陷与背景边界不清晰,与真实的缺陷图像差别较大。各类不同复杂度的生成模型实验结果如图2所示。综上所述,本文方法选择模型复杂度相对较低的DCGAN[29]作为生成模型。
DCGAN是一种无监督的生成式对抗网络,使用了卷积神经网络作为生成器和判别器的架构,能够处理图像中的细节,生成更高质量的图像。本文方法使用的DCGAN模型结构如图3所示。
生成器以随机噪声向量为输入,输出一张图像以模仿真实图像的分布。由5个反卷积层组成,反卷积层之间交替使用批量归一化层和ReLU激活函数,最后一层使用Tanh激活函数来约束生成像素值在-1~1。
判别器以图像为输入,输出判断图像是否为真。由5个卷积层组成,卷积层之间交替使用批量归一化层和LeakyReLU激活函数,最后一层使用sigmoid激活函数输出0~1的概率值。
在对抗训练过程中,生成器和判别器的损失函数均采用交叉熵损失。生成器和判别器的训练交替进行,直到达到预定的迭代次数。
2.2 数据增广流程
在工程实际中,经常只能获得极少量的缺陷样本图像,而没有缺陷的正常样本图像相对容易获取。因此,本文设计了利用少量缺陷样本图像和相对多的正常样本图像的数据增广策略。数据增广的方法如图4所示。
由于缺陷样本图像数量极少,直接用完整工件的缺陷样本图像来训练生成模型会导致网络训练不充分,甚至不收敛。另外,生成的缺陷图像可能会受到背景的影响,使生成的图像具有不同的缺陷特征。考虑到以上问题,本文方法从原始的缺陷样本图像中提取小尺寸缺陷图像作为DCGAN的训练数据。具体地,从分辨率大小为640×640像素的原始缺陷数据图像中人工提取分辨率为64×64的小尺寸缺陷图像,所提取的图像可能不完整覆盖整个缺陷,且图像之间互有重叠区域,旨在增加训练样本和丰富样本多样性。
DCGAN训练完成后,将生成器生成的小尺寸缺陷图像随机插入到正常样本图像中。这样做有利于生成的缺陷图像具有更高的特征一致性,同时保持了图像背景的真实性。具体地,对小尺寸缺陷图像进行随机旋转、随机水平翻转、随机高宽比和随机缩放等基础图像增广操作,以模拟缺陷的不同大小、形状和方向。其次,使用阈值分割筛选出工件区域,以保证缺陷图像能够被插入到工件表面而不是背景区域,使得生成的数据更加真实合理。最后,将基础图像增广后的随机小尺寸缺陷图像嵌入到随机正常样本图像的工件表面随机区域,同时对生成的缺陷图像和待插入区域的边缘进行模糊化处理,使插入的缺陷图片与背景融合得更加自然。
通过批量进行上述操作,构建出了一个由生成的小尺寸缺陷图像和正常数据图像合成的增广数据集,为后续的分割模型提供了更多多样化的训练样本。
3 半监督学习策略
生成模型会引入一些噪声和变化,导致生成数据的分布与真实数据的分布不完全一致。这种分布差异可能会对全监督学习方法产生负面影响,使训练出的模型向生成数据过拟合,无法有效泛化到真实的缺陷上。在半监督学习中,由于没有对整个增广数据集进行标注,可以降低模型对数据分布差异的敏感性,进而提高模型在真实缺陷上的泛化能力。本文方法通过利用半监督训练的方法来缓解分布差异对模型的负面影响,采用了自训练的半监督学习框架,并在后续实验中证明了该方法的有效性。
本文方法将增广数据集随机拆分成两部分:其中一部分进行人工像素级标注,作为标注数据Dl={(Ili,Yli)}Nli=1;另一部分作为无标注数据Du={Iui}Nui=1。标注数据所占比例将在消融实验部分进行探讨。本文方法参考文献[30]设计用于缺陷分割的自训练算法流程,如图5所示。
特别地,在不同阶段分别施加了强、弱两种图像增广策略。本文方法使用的各类图像增广策略如表1所示。
其中,弱图像增广策略包括随机旋转、随机水平翻转、裁剪等。像素级标注的数据通常是宝贵的资源,对标注数据施加的图像增广强度需要慎重考虑,过强的图像增广可能引入更多的噪声和变化,从而使原始标签信息变得模糊和不可靠。较弱的增广策略对图像纹理、特征改变幅度较小,使教师网络能够更好地学习标注数据的细节和边界信息,提高教师网络对无标签数据的预测精度,最终提高半监督方法的性能。
SDA包括弱图像增广的全部策略以及随机模糊、颜色扰动和CutMix[31]。强数据增广策略对图像纹理、特征改变较大,更多差异更大的样本可以提高训练数据的多样性和覆盖范围,从而使模型更好地学习数据的不变性和抗扰动性,从而提高模型的鲁棒性和泛化能力。此外,CutMix方法在保留了CutOut[32]等方法区域性丢弃优势的同时,增广后的图像不会出现非信息像素,削弱了图像混合后的不自然问题,能够进一步提升分割模型的性能。
3.1 教师网络预训练
本文方法对标注数据施加弱图像增广策略,利用标注数据训练教师网络。教师网络训练的损失可以表述为
LT=CrossEntropy(T(Il),Yl)(1)
其中:T表示将图像I映射到教师网络的输VoRHwGJ/uexTAFGyoeey2A==出空间;CrossEntropy表示交叉熵。
3.2 伪标签生成
本文方法利用训练完成的教师网络预测无标签数据Du,预测得到的独热硬标签作为无标签数据的伪标签D^u={(Iui,Y^ui)}Nui=1。首先将无标签数据输入已经训练完成的教师网络中,获得对应的像素级预测结果。随后,应用硬阈值筛选策略,基于像素的预测概率值阈值,过滤掉不可靠的预测结果。最后,每个像素的伪标签转换为独热编码形式。
硬阈值的选择对于自训练生成至关重要,其影响了模型对无标签数据的利用,一般需要由实验测试确定。阈值过低会导致过多错误预测带来的噪声叠加,降低模型分割精度。阈值过高会导致模型在无标签数据上过于保守,只学到与教师网络同质化的信息而难以泛化到真实数据。
3.3 学生网络再训练
在施加弱图像增广的标注数据和施加强图像增广策略的无标注数据上训练学生网络S,训练完成的学生网络将作为最终的分割模型进行精度测试。学生网络训练的损失可以表述为
LS=LlS+λLuS(2)
LlS=CrossEntropy(S(Il),Yl)(3)
LuS=CrossEntropy(S(Iu),Y^u)(4)
其中:LlS为监督损失;LuS为无监督损失;λ为权衡系数,用于调节标注数据和无标注数据在训练时的权重;S表示将图像I映射到学生网络的输出空间。
4 实验与分析
4.1 实验平台
为了获得清晰的工件图像并进行工件的工业检测,本文采用了一种具有多种检测功能的机器视觉检测系统,如图6所示。其中缺陷检测模块的成像系统由1 200万像素高清工业相机、2倍远心镜头、环形白色光源和石英玻璃载物台组成。
成像系统所采集的图片在工控机上完成处理与结果输出。所采用的工控机操作系统为Windows 10,计算机相关参数CPU为Intel CoreTM i7-12700;GPU为NVIDIA GeForce RTX3090 24 GB;64 GB RAM。所使用的模型基于PyTorch深度学习框架搭建神经网络,安装了CUDA V11.3用于GPU加速。
4.2 实验设置
1)实验数据 本文通过上述机械视觉系统采集了5张缺陷样本图像和50张正常样本图像。按照缺陷检测的精度需求,将原始图像放缩为分辨率为640×640的图像用作后续实验。按第2章的数据增广方法,将采集的图像增广为总数量为600张的增广数据集,其中随机选取500张作为训练集,100张作为生成数据测试集。由于在生成图像上的测试结果不能准确衡量模型对真实缺陷的分割效果,本文另外采集了15张缺陷样本图像作为真实数据测试集,用于衡量本方法的真实分割性能。若无特殊说明,本文所有实验精度皆为真实数据集的测试精度。
2)模型选择 半监督算法中的学生网络和教师网络采用相同的分割网络。分割网络模型并非本文方法的主要创新点。在多个分割网络上进行测试之后,最终选择了ResNet50作为Backbone的DeepLAbV3+[33]网络作为分割网络,并集成在了机械视觉系统中。本文所有模型训练均选取50个epoch,采用Adam优化器,batch size设置为4,初始学习率设置为0.001,每10个epoch学习率降低10倍。
3)评价指标 选择交并比(intersection over union, IoU)、精准率(precision)、召回率(recall)和F1得分(F1-score)四个评价指标分析模型的分割性能。
交并比用于度量模型预测的分割结果与实际标签之间的重叠程度,计算公式为
IoU=TPTP+FP+FN(5)
其中:FP表示假阳性结果;TP表示真阳性结果;FN表示假阴性结果;TN表示真阴性结果。
精确率用于度量模型对缺陷类别像素的分类准确性,计算为
precision=TPTP+FP(6)
召回率用于度量模型在捕获所有真实缺陷像素方面的效率,计算公式为
recall=TPTP+FN(7)
F1得分表示精准率和召回率的调和平均数,计算公式为
F1=2×precision×recallprecision+recall(8)
4.3 实验结果
4.3.1 训练策略对分割性能的影响
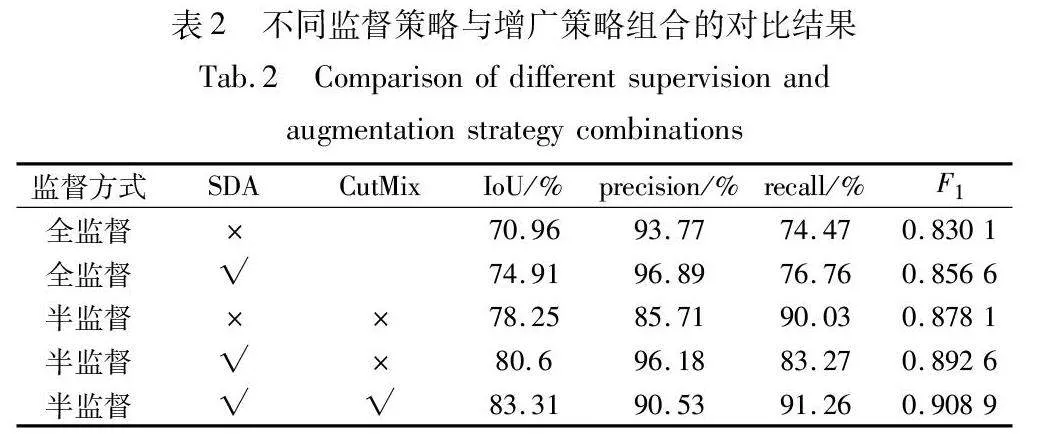
为了验证本文方法的有效性,进行了不同监督方式和不同增广策略组合的对比实验,如表2所示。其中常规的全监督方法和半监督方法在所有训练阶段都仅使用弱图像增广策略。
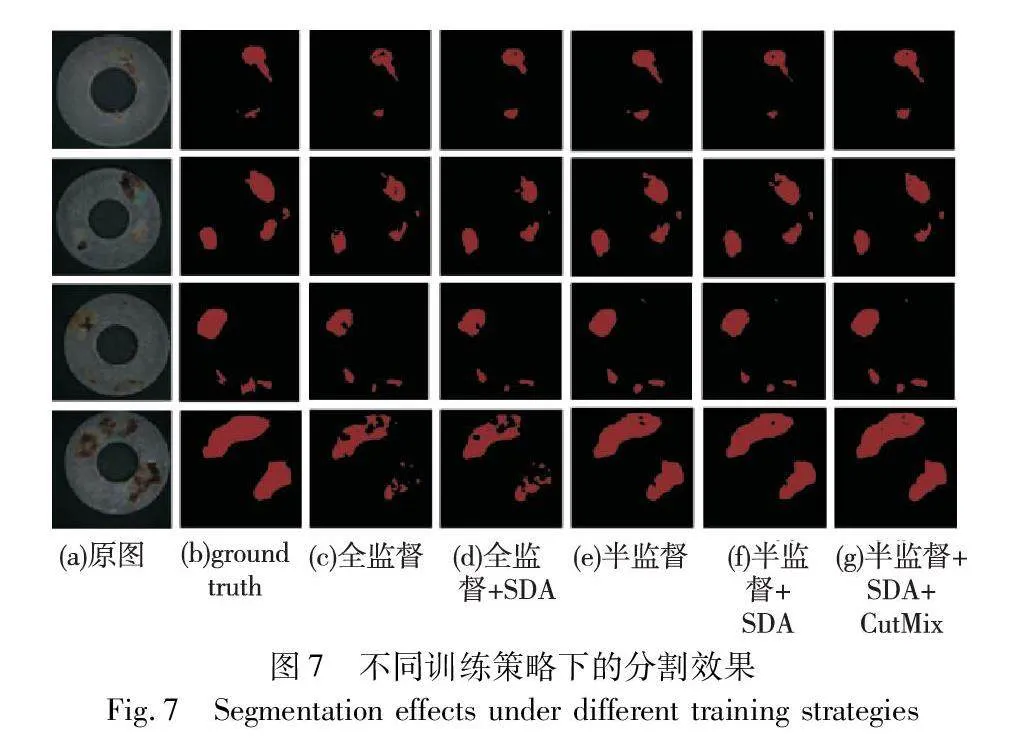
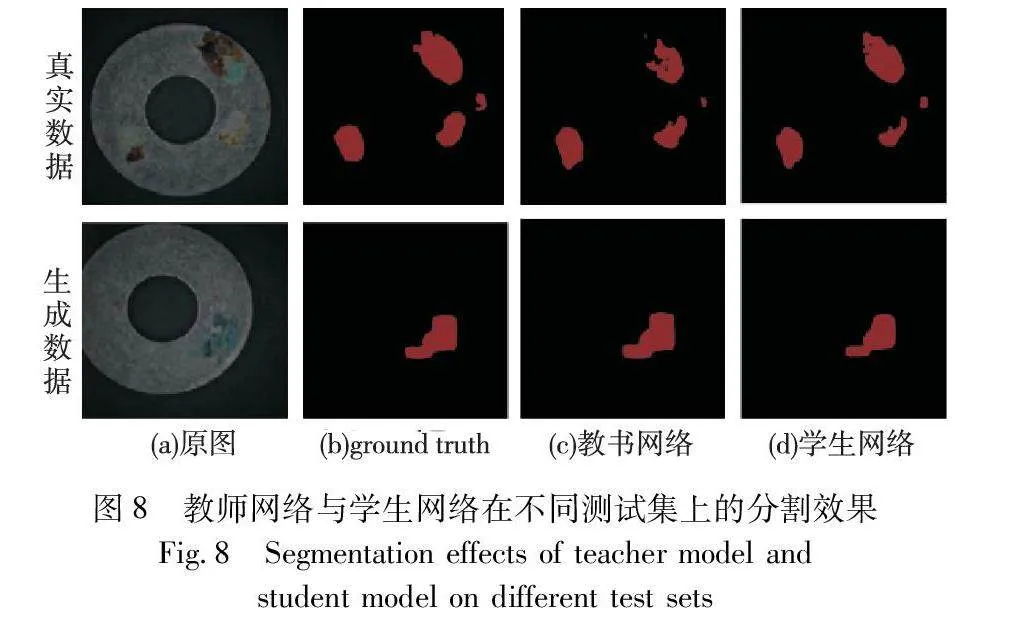
如表2所示,全监督方法下的评价指标除了精确率外,都维持在较低水平。与全监督学习相比,半监督学习可以对生成数据实现更高的分割精度。常规半监督方法比全监督方法的IoU提高了7.29百分点,召回率提高了15.56百分点。得益于半监督训练过程中对无标签数据的训练误差削弱了学生网络训练过程中对生成数据的过拟合,通过半监督学习训练后的分割网络能够更有效地预测缺陷类别。在半监督学习的训练过程中对无标注数据施加更强的图像增广策略,可以有效提高模型性能,在其中添加CutMix增广方法可以进一步提升模型性能。此外,与改变监督方式相比,为全监督学习方法施加强图像增广策略提升甚微,这表明本文方法带来的精度提升不是主要来源于SDA的效果,而是得益于半监督的训练策略。不同训练策略的分割效果及教师网络与学生网络在不同测试集上的分割效果如图7、8所示。
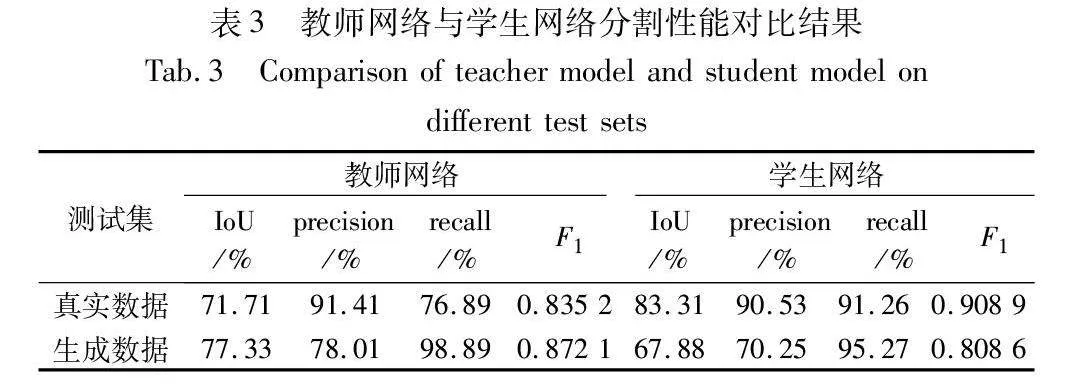
表3展示了1/10比例的半监督方法下,教师网络和学f2cdf80f58b8a1e23f5549167e197f59910acc48a59f42e97ff46e4c6f83130c生网络分别在生成数据测试集和真实数据测试集上的分割精度。仅使用标注数据训练的教师网络对生成数据的检测精度显著高于真实数据,其对生成数据的召回率高达98.89%,而对真实数据的分割精度处于较低水平,表明对生成数据进行全监督学习会导致一定程度偏向生成数据的过拟合。通过部分标签和部分伪标签训练出的学生网络相较于教师网络在真实数据上的分割精度显著提高,IoU提升了11.60百分点,召回率提升了14.37百分点。由上面的数据表明,半监督学习的训练策略有效削弱了模型对于生成数据的过拟合,提高了模型对真实缺陷的泛化能力。
4.3.2 与现有算法对比实验与分析
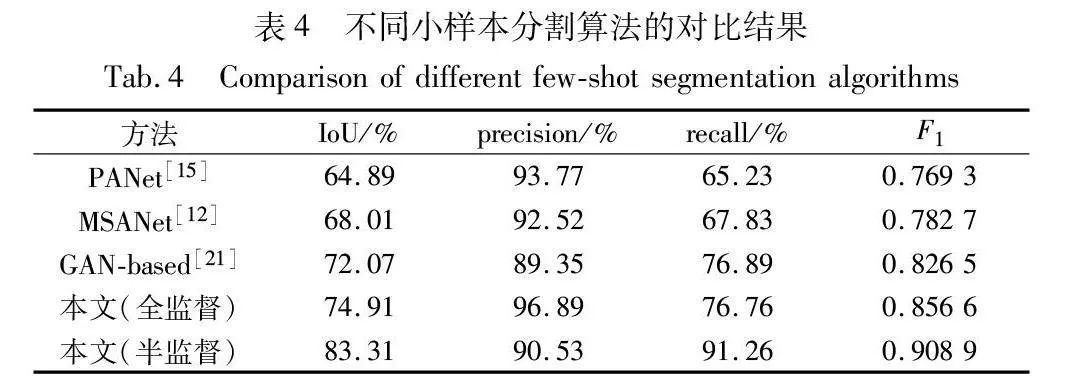
为了证明所提方法的先进性,与现有的小样本分割算法进行了对比实验,所有方法仅采用了前述5张标注的缺陷样本图像作为原始的监督信号。实验结果如表4所示,MSANet、PANet等基于原型对比的度量方法应用于缺陷分割任务时,IoU和召回率较低。支持集所能提供的原型难以泛化到与其差异更大的缺陷样本上,在预测新的缺陷图像时容易漏检。另一方面,基于GAN的数据增广方法在缺乏缺陷数据的情况下效果更佳,但由于生成图像无法充分包含未知的缺陷特征,容易导致网络过拟合。所提方法利用生成模型对缺陷图像进行增广,模拟了缺陷的纹理和形状,并利用半监督的训练策略削弱了过拟合,在维持高精确率的情况下,达到了最高的IoU和召回率。
4.3.3 不同标注数据占比对分割性能的影响
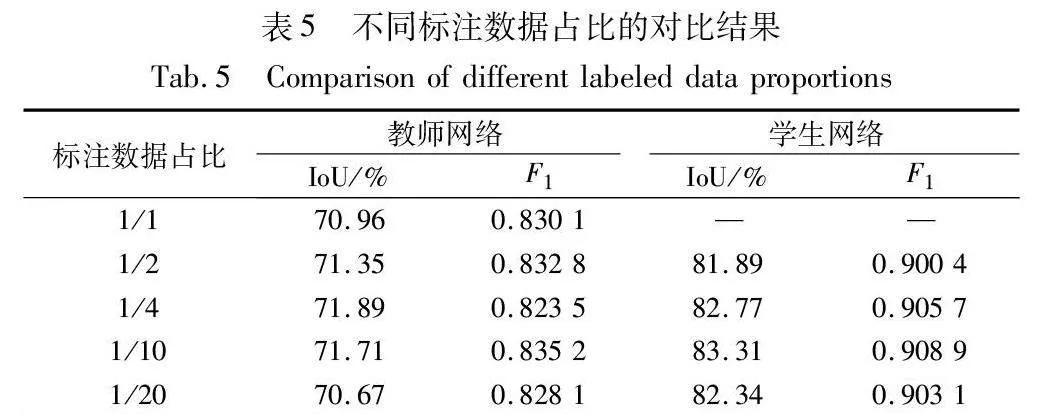
本文进行了四种不同标注数据占比下的半监督实验,与全监督方法的结果对比如表5所示。
由表5可得,从1/20的标注数据占比到全监督的方法,教师网络对真实数据的检测精度都维持在较低水平,显示出一定程度的过拟合。另外,也反映出仅利用图像生成的数据增广方法对模型的分割精度提升有限,当参与监督训练的增广图像达到125张时,教师网络的精度就已经饱和。而对于任意不同比例的半监督算法,训练完成的学生网络对真实缺陷依然拥有较高的泛化能力,IoU保持在80%以上,F1得分保持在0.9以上,模型在标注数据占比为1/10时取得最高精度。
4.3.4 不同分割模型对分割性能的影响
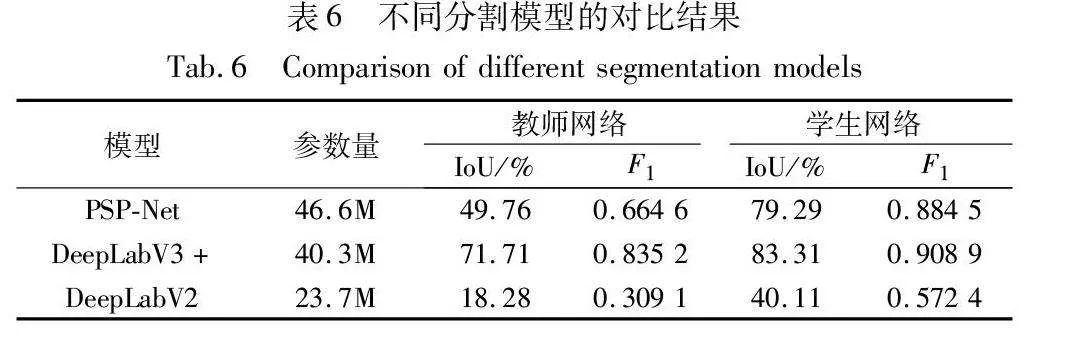
为了证明本文方法在不同分割模型上的通用性,选用了三种主流的语义分割模型进行对比实验。本文选择PSP-Net[33]、DeepLabV3+和DeepLabV2[34]在相同1/10数据标注的数据集条件下进行对比实验,利用各自实验最高分割精度进行对比,如表6所示。
表6的数据表明,使用标注数据训练的三种网络都出现了不同程度的过拟合,经过半监督的训练流程后,分割网络在真实缺陷上的泛化能力得到了不同程度的增强。其中, DeepLabV2模型在仅使用标注数据训练的条件下对生成数据的过拟合尤为严重,对真实缺陷的泛化能力极低,但是在经过半监督的训练过后,IoU提升了21.83百分点,分割精度显著提高。PSP-Net和DeepLabV3+模型参数量相近,都是复杂度相对较高的模型,在全监督或者半监督的教师网络阶段对真实缺陷仍有一定的泛化能力,在通过半监督的训练流程后,泛化能力亦得到了进一步提升。
5 结束语
针对工业场景下缺少缺陷样本的问题,本文提出了一种利用图像生成技术和半监督学习的小样本缺陷分割算法。该算法首先利用极少量缺陷样本图像和相对多的正常样本图像进行数据增广,结合DCGAN生成模型扩充了可训练的数据量;此外,该算法对增广数据集部分标注之后采用自训练的训练策略,并在不同阶段施加不同的图像增广策略,削弱了分割模型对生成数据的过拟合。本文方法在真实的视觉系统上利用金属工件进行了实验。实验表明,该方法能够在仅使用5张缺陷样本图像的条件下满足系统对缺陷的高精度分割需求。通过各种基准测试的对比实验,证明了本文设计的半监督学习训练策略可以改善分割模型对生成数据的过拟合,有效缓解了生成数据与真实数据之间的分布差异对分割精度的影响。
参考文献:
[1]Sharifzadeh M,Alirezaee S,Amirfattahi R,et al. Detection of steel defect using the image processing algorithms [C]// Proc of the 6th International Conference on Electrical Engineering. Piscataway,NJ: IEEE Press,2008: 125-127.
[2]Bulnes F G,Usamentiaga R,García D F,et al. Vision-based sensor for early detection of periodical defects in Web materials [J]. Sensors,2012,12(8): 10788-10809.
[3]Gayubo F,Gonzalez J L,de la Fuente E,et al. On-line machine vision system for detect split defects in sheet-metal forming processes [C]// Proc of the 18th International Conference on Pattern Recognition. Piscataway,NJ: IEEE Press,2006: 723-726.
[4]Ghorai S,Mukherjee A,Gangadaran M,et al. Automatic defect detection on hot-rolled flat steel products [J]. IEEE Trans on Instrumentation and Measurement,2012,62(3): 612-621.
[5]Zhang Yanxi,You Deyong D,Gao Xiangdong,et al. Welding defects detection based on deep learning with multiple optical sensors during disk laser welding of thick plates [J]. Journal of Manufacturing Systems,2019,51: 87-94.
[6]Valente A,Wada C,Neves D,et al. Print defect mapping with semantic segmentation [C]// Proc of IEEE/CVF Winter Conference on App-lications of Computer Vision. Piscataway,NJ: IEEE Press,2020: 3540-3548.
[7]苏迎涛. 基于显著区域提取和改进型 YOLO-V3 的金属齿轮加工端表面缺陷检测方法 [D]. 重庆:重庆大学,2020. (Su Yingtao. Surface defect detection method for metal gear machining based on salient region extraction and improved YOLO-V3[D]. Chongqing:Chongqing University,2020.)
[8]张乃雪,钟羽中,赵涛,等. 基于Smooth-DETR的产品表面小尺寸缺陷检测算法 [J]. 计算机应用研究,2022,39(8): 2520-2525. (Zhang Naixue,Zhong Yuzhong,Zhao Tao,et al. Detection method for small-size surface defects based on Smooth-DETR [J]. Application Research of Computers,2022,39(8): 2520-2525.)
[9]王一,龚肖杰,程佳. 基于改进U-Net的金属工件表面缺陷分割方法 [J]. 激光与光电子学进展,2023,60(15): 1524001. (Wang Yi,Gong Xiaojie,Cheng Jia. Surface defect segmentation method of metal workpiece based on improved U-Net [J]. Advances in Lasers and Optoelectronics,2023,60(15): 1524001.)
[10]Wang Jun,Hou Mengjie,Zhang Ruiran,et al. Magnetic column defect recognition based on DeepLab V3+ [C]// Proc of China Automation Congress. Piscataway,NJ: IEEE Press,2022: 2618-2623.
[11]张睿,杨义鑫,李阳,等. 自监督学习下小样本遥感图像场景分类 [J]. 中国图像图形学报,2022,27(11): 3371-3381. (Zhang Rui,Yang Yixin,Li Yang,et al. Self-supervised learning based few-shot remote sensing scene image classification [J]. Journal of Image and Graphics,2022,27(11): 3371-3381.)
[12]Iqbal E,Safarov S,Bang S. MSANet: multi-similarity and attention guidance for boosting few-shot segmentation [EB/OL]. (2022-06-20). https://arxiv.org/abs/2206.09667.
[13]Nakamura A,Harada T. Revisiting fine-tuning for few-shot learning [EB/OL]. (2019-10-03). https://arxiv.org/abs/1910.00216.
[14]Mehrotra A,Dukkipati A. Generative adversarial residual pairwise networks for one shot learning [EB/OL]. (2017-03-23). https://arxiv.org/abs/1703.08033.
[15]Wang Kaixin,Liew J H,Zou Yingtian,et al. PANet: few-shot image semantic segmentation with prototype alignment [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2019: 9196-9205.
[16]许国良,毛骄. 基于协同注意力的小样本的手机屏幕缺陷分割 [J]. 电子与信息学报,2022,44(4): 1476-1483. (Xu Guoliang,Mao Jiao. Few-shot segmentation on mobile phone screen defect based on co-attention [J]. Journal of Electronics & Information Technology,2022,44(4): 1476-1483.)
[17]Goodfellow I,Pouget-Abadie J,Mirza M,et al. Generative adversarial networks [J]. Communications of the ACM,2020,63(11): 139-144.
[18]He Xiangjie,Chang Zhengwei,Zhang Linghao,et al. A survey of defect detection applications based on generative adversarial networks [J]. IEEE Access,2022,10: 113493-113512.
[19]Doersch C. Tutorial on variational autoencoders [EB/OL]. (2021-01-03). https://arxiv.org/abs/1606.05908.
[20]Chen Jingwen,Chen Jiawei,Chao Hongyang,et al. Image blind denoising with generative adversarial network based noise modeling [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 3155-3164.
[21]Liu Jie,Zhang B G,Li Li. Defect detection of fabrics with generative adversarial network based flaws modeling [C]// Proc of Chinese Automation Congress. Piscataway,NJ: IEEE Press,2020: 3334-3338.
[22]Rudolph M,Wandt B,Rosenhahn B. Same but different: semi-supervised defect detection with normalizing flows [C]// Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Pisca-taway,NJ:IEEE Press, 2021: 1907-1916.
[23]吴仕科,梁宇琦. 基于伪标签自细化的弱监督实例分割 [J]. 计算机应用研究,2023,40(6): 1882-1887. (Wu Shike,Liang Yuqi. PLSR: weakly supervised instance segmentation via pseudo-label self-refinement [J]. Application Research of Computers,2023,40(6): 1882-1887.)
[24]Zhu Yi,Zhang Zhongyue,Wu Chongruo,et al. Improving semantic segmentation via efficient self-training [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2024,46(3): 1589-1602.
[25]Souly N,Spampinato C,Shah M. Semi supervised semantic segmentation using generative adversarial network [C]// Proc of IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2017: 5689-5697.
[26]Wang Yuchao,Wang Haochen,Shen Yujun,et al. Semi-supervised semantic segmentation using unreliable pseudo-labels supplementary material [EB/OL]. (2022-03-08). http://arxiv.org/pdf/2203.03884.pdf.
[27]Karras T,Samuli L,Aittala M,et al. Analyzing and improving the ima-ge quality of StyleGAN [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 8107-8116.
[28]Radford A,Metz L,Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks [EB/OL]. (2016-01-07). https://arxiv.org/abs/1511.06434.
[29]Yang Lihe,Zhuo Wei,Qi Lei,et al. ST++: make self-training work better for semi-supervised semantic segmentation [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2022: 4258-4267.
[30]Yun S,Han D,Chun S,et al. CutMix: regularization strategy to train strong classifiers with localizable features [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2019: 6022-6031.
[31] DeVries T,Taylor G W. Improved regularization of convolutional neural networks with CutOut [EB/OL]. (2017-11-29). https://arxiv.org/abs/1708.04552.
[32]Chen L C,Zhu Yukun,Papandreou G,et al. Encoder-decoder with Atrous separable convolution for semantic image segmentation [C]// Proc of European Conference on Computer Vision. Cham:Springer,2018: 833-851.
[33]Zhao Hengshuang,Shi Jianping,Qi Xiaojuan,et al. Pyramid scene parsing network [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2017: 6230-6239.
[34]Chen L C,Papandreou G,Kokkinos I,et al. DeepLab: semantic image segmentation with deep convolutional nets,Atrous convolution,and fully connected CRFs [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2017,40(4): 834-848.
