
尺度适应性感受野的船舶目标检测方法
2024-08-15 00:00:00罗芳李家威何道森
计算机应用研究 2024年8期














摘 要:
现有船舶目标检测算法大部分只是基于传统目标检测算法的优化改进,没有考虑船舶具有尺度长宽比例的外观特性,在多尺度目标检测中出现漏检误检问题。为了解决此问题,在YOLOXs基础上,提出一种尺度适应性感受野的船舶检测方法(SAF-YOLOX)。首先,对主干网络提取的不同特征层通过构建双向特征金字塔进行特征融合,增强每个尺度下的特征描述力;同时,设计自适应特征强化模块,抑制不同尺度的特征融合引入的冗余信息,弱化背景信息;然后在预测时,采用多路并行感受野的检测头,利用具有适应目标大小以及比例的感受野提取目标尺度适应性特征信息进行预测;最后,采用先筛选再分配的收敛感知策略,根据网络的收敛状态动态地分配样本,保证检测速度的同时提高检测精度。实验结果显示,所提方法在大型海事监控数据集SeaShips和MCShips上的平均检测精度分别达到93.21%和92.34%,与传统YOLOXs相比,分别提高了1.01%和1.09 %。实验结果证明,所提方法利用尺度适应性感受野能实现多尺度船舶目标的高精度检测。
关键词:船舶目标检测;YOLOX;尺度自适应;特征强化;分配策略
中图分类号:TP391.41 文献标志码:A 文章编号:1001-3695(2024)08-039-2521-07
doi: 10.19734/j.issn.1001-3695.2023.10.0558
Ship object detection based on scale-adaptive receptive field
Luo Fang1, Li Jiawei1, He Daosen2
(1.College of Computer Science & Artificial Intelligence, Wuhan University of Technology, Wuhan 430063, China; 2. Dept. of Supply Chain & Information Management, Hang Seng University of Hong Kong, Hong Kong 999077, China)
Abstract:
The existing ship object detection algorithms mostly rely on optimized improvements based on traditional object detection algorithms, without considering the scale and aspect ratio characteristics of ships, leading to issues such as missed detections and false detections in multi-scale object detection. To address this, the paper proposed a scale-adaptive receptive field ship detection method(SAF-YOLOX) based on YOLOXs. Firstly, it extracted different feature layers by the backbone network, which were fused by constructing a bidirectional feature pyramid, improving feature representation at various scales. Simultaneously, it designed an adaptive feature enhancement module to suppress redundant information introduced by the fusion of features at different scales, thereby attenuating background information. During the prediction phase, it employed a multi-branch parallel receptive field detection head, utilizing receptive fields adapted to target sizes and proportions for extracting scale-adaptive feature information. Additionally, it implemented a convergence-aware strategy, dynamically selecting and allocating samples based on the network’s convergence state. This strategy ensured improved detection accuracy while maintaining detection speed. Experimental results demonstrate that the proposed method achieves an average detection accuracy of 93.21% on the SeaShips dataset and 92.34% on the MCShips dataset. When compared to traditional YOLOXs, the method exhibits an improvement of 1.01% and 1.09%, respectively. The experimental results confirm that the proposed method, utilizing scale-adaptive receptive fields, can achieve high-precision detection of multi-scale ship targets.
Key words:ship object detection; YOLOX; scale adaptation; feature enhancement; assign policies
0 引言
经过近十年的发展,基于深度学习的目标检测日趋成熟,但是多尺度目标检测仍面临着挑战,近年来诸多研究模拟人类视觉的感受野[1]来提升多尺度目标检测性能。Liu等人[2]在inception的基础上加入了空洞卷积,通过具有不同空洞率的卷积核得到不同大小的感受野,以提取具有更多上下文信息的目标特征; Zhao等人[3]设计金字塔池化模块(pyramid pooling module,PPM),利用全局平均池化将不同感受野的特征进行融合,增强了有效感受野的大小; Dai等人[4]根据当前需要识别的目标进行感受野动态调整,提出可变形卷积以获得更准确的感受野;彭晏飞等人[5]利用不同大小、不同尺度的感受野来捕捉目标的上下文信息,丰富目标的特征信息,强化小目标检测;李坤亚等人[6]利用不同感受野与注意力机制结合来融合目标全局特征信息,建立通道与全局特征图各像素间的全局依赖关系,以抑制冗余信息的干扰。上述研究利用不同大小感受野的特征进行特征融合,提取更多的全局信息有助于多尺度目标的检测。但对于多尺度船舶目标检测而言,不同类别的船舶因其外观形状大多是细长型,而不同特征层下其感受野大多是长方形,因此这些方法不能很好地匹配船舶外型尺寸,并且对小目标而言会引入更多背景信息,造成检测效果不好。例如,从图1(图中黄色标注是矩形整数感受野,红色标注非整数感受野)不同特征图下目标的感受野中可以看出,图1(a)20×20特征图中船舶目标①、②、③的感受野大小分别是6×5、 6×2、4×2,在图1(b)10×10特征图中船舶目标①、②、③的感受野大小分别是3×3、3×2、2×1,利用正方形卷积核获取的感受野与实际船舶目标外型存在偏差;再者,如果固定用长方形整数卷积核生成的感受野可能不能完全匹配船舶目标尺寸,导致提取的特征包含过多的干扰信息,例如在图1(b)10×10特征图下黄色标注区域中目标船舶①、②、③的整数感受野包含了多余的背景冗余信息,其目标前景的真正有效区域是红色标注区域,即非整数感受野。另外,同一尺度目标的感受野具有明显的变化,如果只利用一个固定感受野的检测头处理特征层,无法适应目标的比例变化,例如在图1(a)20×20特征图中,目标船舶①、②感受野大小分别是6×5、6×2,用一个感受野6×5的检测头处理该特征层,对于船舶目标①能够较好地提取特征并预测,但是对于目标船舶②则会引入过多的背景信息,不利于目标的预测。
为了提升多尺度船舶目标检测性能,使检测头中感受野与船舶目标的外型及尺度大小相适应,本文构建了一个尺度适应性感受野的船舶目标检测网络,以解决传统的目标检测网络采用固定感受野无法有效捕捉不同尺度的船舶目标,而导致的目标漏检问题。为此,设计一个多路并行感受野的检测头,通过引入多路并行感受野,利用与目标大小尺度更匹配的感受野来提取目标特征信息,提高船舶目标检测精度。为了避免特征融合后带来的冲突信息和背景信息对多路并行感受野的检测头造成干扰,本文设计了自适应特征强化模块,利用通道和空间自适应融合的机制,抑制冲突信息,使得前景信息得到强化,同时减弱背景信息的影响,从而提高目标检测的准确性。
此外,引入多路并行感受野的检测头有助于更好地捕捉不同大小目标的特征信息,但同时可能增加了网络的复杂性。因此本文设计了收敛感知分配策略,根据网络复杂性和收敛程度自适应地计算和分配正样本个数,以优化网络的训练过程,解决复杂性问题并加速网络的收敛。
1 本文方法
本文基于YOLOXs[7]构建尺度适应性船舶检测网络,如图2所示。首先,为了增强每个尺度下的特征描述力,对主干网络提取的不同特征层通过构建双向特征金字塔进行特征融合[8];接着,为抑制不同尺度的特征融合引入的冗余信息,提出自适应特征强化模块,以弱化背景信息;然后在预测时,采用多路并行感受野的检测头,利用具有适应目标大小以及比例的感受野的卷积核对特征层P2~P4进行解耦处理,利用目标尺度适应性特征信息进行预测;另外,多路并行感受野的检测头增加了网络的复杂性,为了保证检测速度的同时提高检测精度,采用先筛选再分配的收敛感知策略,根据网络的收敛状态动态地分配样本。
1.1 自适应特征强化
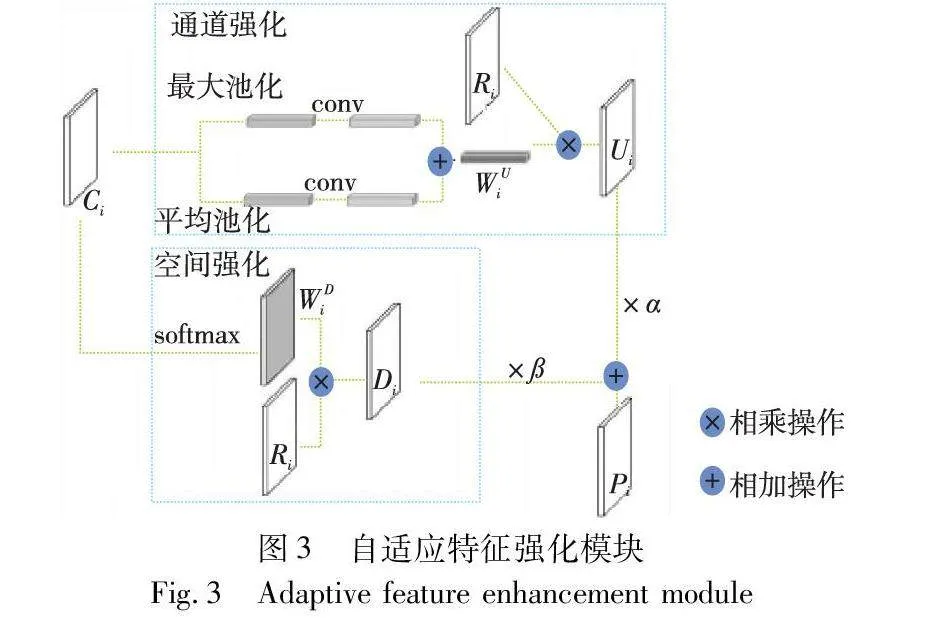
特征金字塔[9]用于融合不同尺度大小的特征,然而不同尺度的特征具有不可忽视的语义差异,将不同尺度的特征直接融合可能引入大量的冗余信息、冲突信息,这样会造成目标前景弱化,降低多尺度表达的能力。为了抑制不同尺度冗余信息、冲突信息,同时强化前景信息、弱化背景信息,获得包含更多目标前景信息的特征图,以便于后续检测,本文设计自适应特征强化模块,利用主干网络特征来指导融合后的特征层进行特征强化,分别通过通道强化和空间强化得到特征图U和D,如图3所示。
在通道强化模块中采用平均池化和最大池化相结合的方式来聚合图像的全局空间信息。将主干网络输出的不同层特征图Ci(i=2,3,4)和特征金字塔输出的三种尺度的特征层Ri(i=2,3,4)作为输入,采用平均池化和最大池化相结合的方式来聚合图像的全局空间信息,并利用sigmoid函数归一化后得到WUi(i=2,3,4),如式(1)所示。
WUi=sigmoid[AvgPool(Ci)+MaxPool(Ci)](1)
其中:WU i代表特征融合前Ci中不同通道输入的相对权重值,越大表示具有更大的响应,将它们与输入相乘,响应大的输入将被放大,响应小的被抑制,与输入相乘得到通道强化的特征图Ui(i=2,3,4),如式(2)所示。
Ui=WUiRi(2)
空间强化模块利用 softmax 函数将Ci (i=2,3,4)特征图在空间上归一化,以提高模型的泛化能力,得到特征图中每个点关于其他所有位置的相对权重WDi(i=2,3,4),如式(3)所示。
WDi=softmax(Ci)(3)
然后将WDi与Ri(i=2,3,4)分别相乘,得到空间特征强化特征图Di(i=2,3,4), 放大目标特征并抑制背景噪声,如式(4)所示。
Di=WDiRi(4)
其中:WDi为空间自适应权重,前景目标区域的响应较大,将会获得更大的权重,反之背景区域获得的权重较小。
为了权衡两者比重,设计自适应参数α、β,通过网络训练梯度回传自动调整大小,其中α+β=1。强化后的特征如式(5)所示。
P=α×U+β×D(5)
1.2 检测头优化
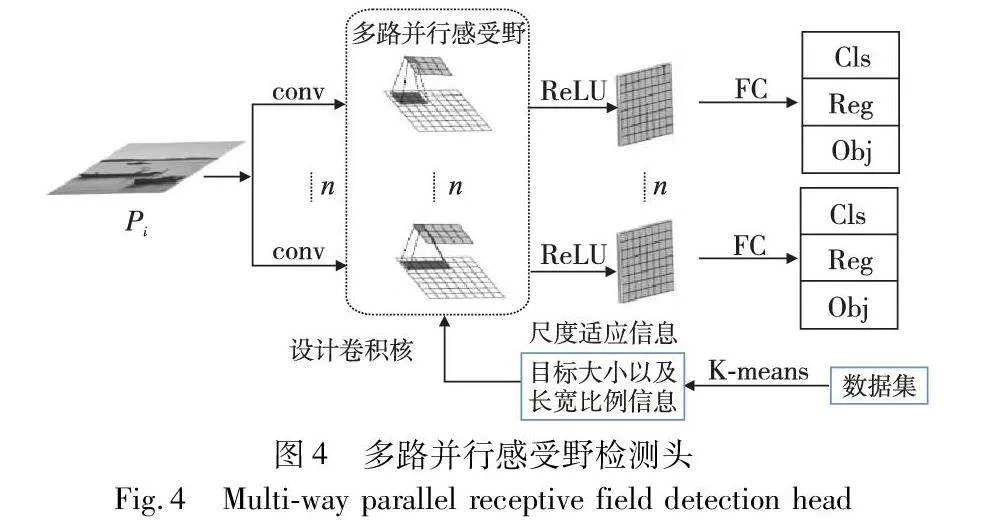
目前,在检测头中通常采用1×1、3×3卷积核,或者是全连接神经网络,这种方式获得的感受野大小是固定的,不一定与检测目标的尺寸匹配。目标检测时,预测所用的感受野大小取决于网络最后一层,即由检测头中卷积核感受野的大小决定,为了获取匹配目标尺寸的感受野,本文对检测头进行了优化,如图4所示,设计多路并行感受野的检测头,利用多路并行的尺度适应性感受野分别对特征层进行特征提取并预测。
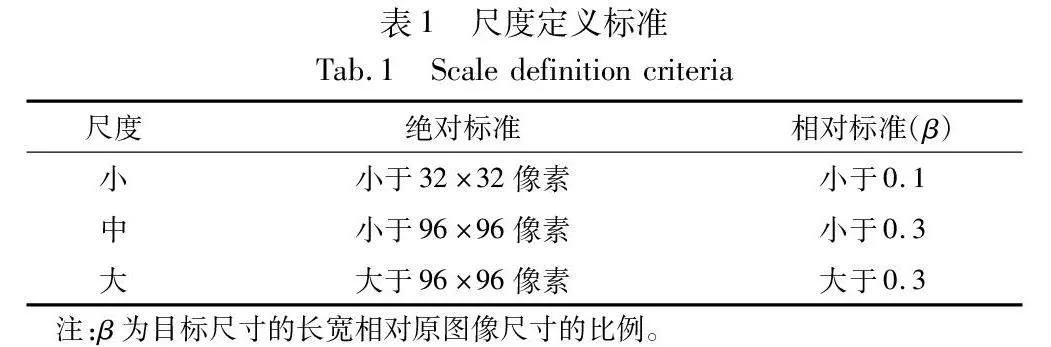
该模块在同一特征层下,利用n条并行支路分别进行预测,其中每一路设置具有不同尺度适应性感受野的卷积,再利用激活函数得到具有适应目标尺度的特征图,最后利用全连接层输出该特征层下目标的预测结果。关于每一支路尺度适应性感受野的确定,本文借鉴基于Anchor[10]的目标检测算法中的Anchor选取方式。首先统计数据大中小目标的数量,其中大中小目标的定义如表1,同时考虑基于相对尺度和基于绝对尺度两个标准,然后根据统计数量确定大中小目标数量比值约数来作为聚类的类别个数,利用K-means[11]分别对大目标、中目标、小目标进行聚类。由于网络输入的尺度为640×640,本文将数据集图片resize成640×640,然后将resize后的真实框信息进行聚类,最后根据聚类结果确定不同尺度感受野的大小。
以SeaShips数据集为例,大中小目标的数量比值约为4∶2∶2,即在大中小尺度下n值分别为4、2、2,表2是三种尺度下真实框的聚类结果,可以得出在不同尺度下和同一尺度下都有明显的长宽比例变化,由此可见利用尺度适应性感受野来提取目标特征更有利于预测。
根据不同尺度的真实聚类框,按照特征层相较于原图的缩放比例计算得到尺度适应性感受野。以小尺度下目标的真实聚类框大小12×45、19×86为例,按照缩放比例8计算在小尺度特征层上对应框的大小为1.5×5.63、2.4×10.75,本文将这个计算结果作为处理小尺度特征层中多路感受野的并行检测头中感受野的大小。
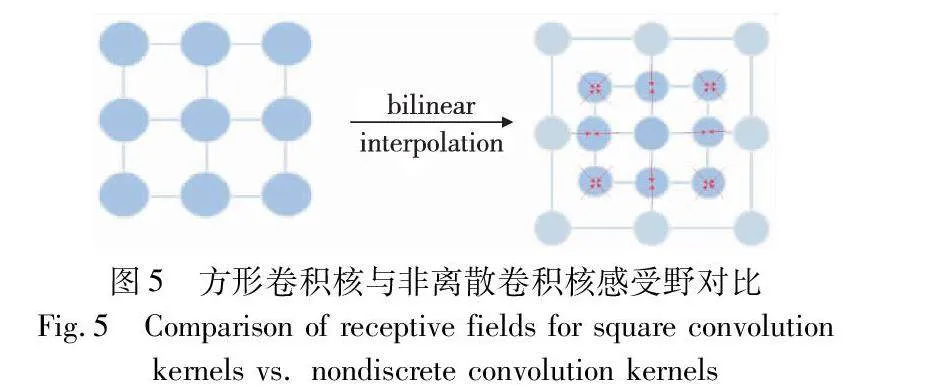
由此本文提出了非离散卷积核实现尺度适应性感受野,对特征点采用双线性插值进行逼近,并利用相应的变换矩阵进行非整数卷积的实现。与整数矩形内核的对应CNN相比,训练需要大约相等的计算量。
以感受野大小为(2.6,2.4)卷积核为例介绍非整数卷积核。如图5所示,3×3标准正方形核的感受野可以表示为S={(-1,1),(0,1),(1,1),(-1,0),(0,0),(1,0),(-1,-1),(0,-1),(1,-1)}。通过将输入特征图I∈Euclid ExtraaBpH×W与步幅为1的核W∈Euclid ExtraaBpk×k进行卷积,得到一个输出特征图O∈Euclid ExtraaBpH×W,其在每个坐标j处的值如式(6)所示。
Oj=∑s∈SWsIj+s(6)
非整数卷积核感受野大小为(2.6,2.4),感受野R表示为 R={(-0.7,0.8),(0,0.8),(0.7,0.8),(-0.7,0),(0,0),(0.7,0),(-0.7,-0.8),(0,-0.8), (0.7,-0.8),相应的卷积变为如式(7)所示。
Oj=∑s∈S,r∈RWsIj+r(7)
由于非整数的感受域包含分数位置,所以使用双线性插值来近似矩形感受野内的相应采样值,如式(8)所示。
It=∑s∈SB(s,t)Is(8)
其中:t表示矩形感受野中的任意(分数)位置;B(·,·)是双线性插值的变换矩阵。最终得到公式为
Oj=∑s∈S,r∈RWs(∑s∈SB(s, j+r)Is)(9)
由于变换矩阵B是固定系数矩阵,所以在原始内核W上进行操作可以替换感受野中的偏移,从而使训练与具有标准方形内核的对应CNN相比,花费了等效的时间。
本文提出的尺度适应性感受野与传统检测头中感受野大小相比,都能较好地适应目标的大小,提取的前景目标信息占比更多,更好地进行目标的检测。 如图6所示,蓝色框表示传统检测头感受野,黄色框表示本文多路并行感受野检测头感受野(参见电子版),针对80×80和20×20特征层中的三个船舶目标,其中大目标船舶在20×20特征层中检测,小目标船舶在80×80特征层中检测,传统检测头的感受野(YOLOXs中5×5,蓝色标注)与本文设计的尺度适应性感受野的适应性进行对比,其中尺度适应性感受野(黄色标注)大小在图6(a)(b)中分别是(1.5×6.65)、(2.4×10.75)。
1.3 分配策略优化
由于多路并行感受野的检测头使预测分支增加,导致预测网络复杂性增加,造成网络预测框成倍输出,样本分配过程中的计算量增加。为了解决上述问题,本文采用初筛-再分配策略,首先对输出的预测框按照置信度进行初步筛选,选择置信度较高的1/3数量的预测框作为分配候选框,然后利用分配策略对分配候选框进行正样本分配,该方式不仅保证了分配过程的计算量,在一定程度上也保证了预测框的质量,筛选更好的样本进行网络的训练,然后进行再分配策略。
在分配策略中,simOTA[7]通过top-k策略为每个真实框分配正样本,避免了OTA[12]使用Sinkhorn-Knopp算法求解最优传输问题带来的25%额外的训练时间开销,但是simOTA中top-k策略中的m值是固定的,没有根据网络收敛情况和网络复杂性进行动态调整,其中m值表示与真实框的IoU值的前m个预选框,k表示这m个IoU值之和,并向下取整。通过实验发现m值的大小会影响训练结果,不同的网络复杂度对不同m值反应不同,且simOTA策略在训练前期的动态k值大多为1,只有一个正样本参与训练,导致训练速度缓慢。为了保障网络每个分支都能得到很好的训练,应该提高标签的正样本个数。
考虑上述问题,本文设计收敛感知分配策略,在m值计算过程中考虑网络的复杂性以及收敛性信息,进一步实现正样本数量的动态调整。其中关于动态m值的确定,以mAP反映网络收敛程度,mAP的变化曲线一般是快上升,慢收敛。在网络收敛性快速上升阶段,通过增加m值增加样本数量,自适应地快速提升网络能力,在网络的收敛速度下降时,网络进入收敛阶段,为了避免网络振荡,应该减少样本数量以保证样本质量。
网络的复杂性决定m值的上界和下界,m值在(min、max)变化,初始m值较小,min、max可以根据网络分支(复杂性)的多少决定,本文选用m初始值为10,min值为10,max为40。
算法1 收敛感知分配策略
输入:锚集合A;图像中目标真实框的注释G。
输出:分配方案Π*。
M ←|G|,N←|A|
(i, j)←get_in_boxes_info (G,A) /*利用中心先验原理确定第i个真实框对应的第j个预测框*/
ml← get_ml(ΔmAPl-1) //计算第l代的m
I← get_IoU(i, j) //计算每个真实框和候选框之间的IoU值
k← get_k(ml,I) //计算每个真实框的k值
cost(i, j)← FocalLoss(Pclsi,Gclsj)+IoULoss(Pboxi,Gboxj) /*计算每个真实框与候选框的代价(损失)*/
(i*, j*)← get_assignments(cost,k) /*取损失最小的前k个候选框作为真实框的正样本*/
return (i*, j*)
动态m值的计算方式如式(10)所示。
ml=ml-1-2 ΔmAPl-1<0
ml-1-10<ΔmAPl-1<a
ml-1+2ΔmAPl-1>a (10)
其中:ΔmAPl-1是验证集第l-1与l-2代mAP值的差值; ml是第l代m的值;α为ΔmAP阈值,描述网络收敛的快慢,本文取值为0.005,当ΔmAP大于该值,说明网络在上升阶段,小于该值则说明网络处于逐渐收敛阶段。
2 实验设置及结果分析
本文实验基于PyTorch深度学习框架,硬件设备为Intel i7-12700K处理器,12核20线程,主频3.6 GHz,GPU RTX 3080Ti的工作站。
2.1 实验配置设置和评价指标
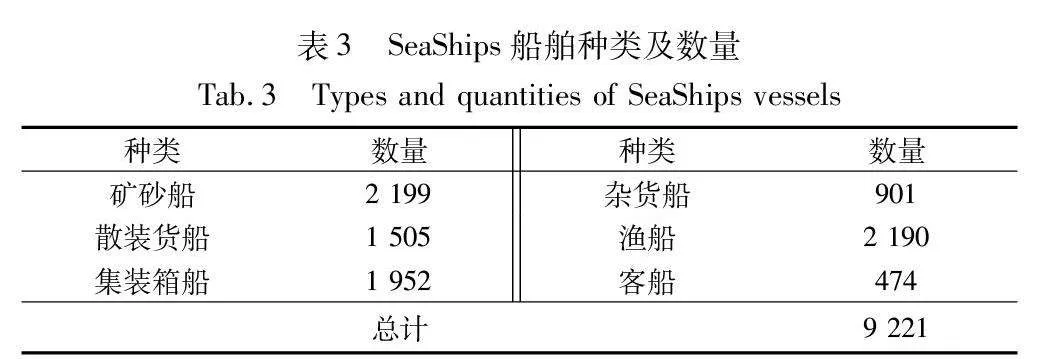
本文选用大型海事监控数据集SeaShips[13]以及McShips[14]进行实验以评估方法性能。SeaShips如表3所示,六种不同种类的船舶具有不同的尺寸大小。为了进一步验证模型的适用性,本文还选取西北工业大学公开用于船舶检测的McShips数据集,如表4所示。与SeaShips相比, McShips包含军用类型的船舶,并且具有同一类别尺度变化、不同类别尺度变化等特点。
本文实验使用召回率(recall)、精确率(precision)、平均准确率(AP)和均值平均精度(mean average precision,mAP)等目标检测常用指标来评价实验效果。召回率为所有真实目标中模型预测正确的目标比例,如式(11)所示。精度为模型预测的所有目标中,预测正确的比例,如式(12)所示。mAP 为所有类别的AP的平均值,如式(14)所示。
recall=TPTP+FNR(11)
precision=TPTP+FP(12)
其中:TP表示正样本中预测为正样本的数量;FP表示负样本中预测为正样本的数量;FN表示正样本中预测为负样本的数量。
AP=∫10P(R)d(R)(13)
mAP=∑Ni=1 APiN(14)
本文网络模型训练时,批量大小设置为 8,在SeaShips和McShips数据集上的训练批次分别是100和150,初始动量0.937,学习率下降方式Cos,初始学习率设置为1E-2,学习率1E-4,衰减率设置为 0.000 1,网络没有使用预训练权重,训练集图像被等比例缩放至640×640输入网络。
2.2 验证实验结果分析
2.2.1 非离散卷积合理性验证
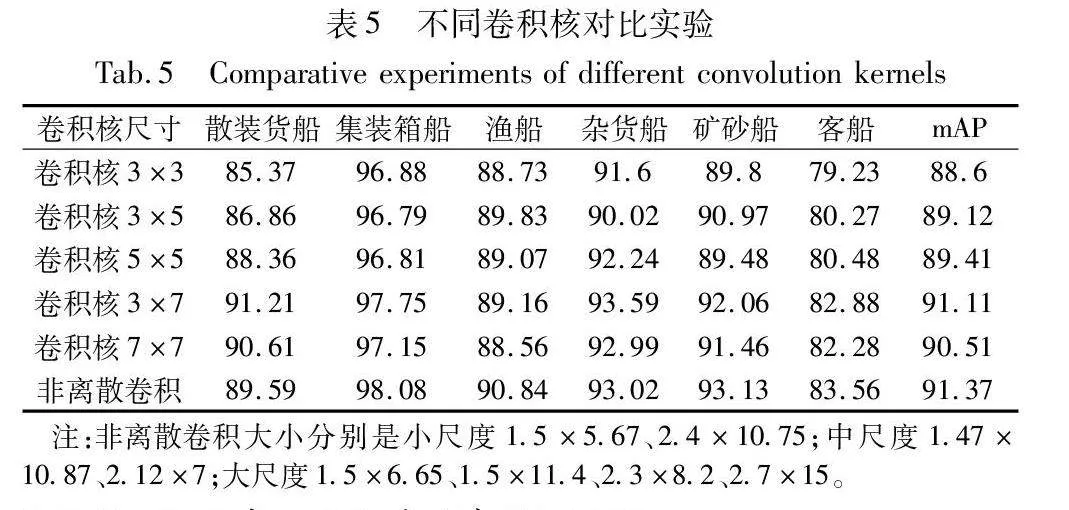
为了验证本文提出的尺度适应性船舶目标检测的效果,基于SeaShips数据集设置不同形状以及尺寸的卷积核进行实验。实验结果如表5所示,较大的方形卷积核检测的准确度较高,采用不同比例的矩形卷积核提高检测精度的效果更明显,并且大小为3×7卷积核相较于3×3、5×5、7×7的卷积核具有更明显的提升效果,初步验证矩形卷积核对船舶检测的有效性。本文的非离散卷积虽然在散装货船和杂货船的预测上稍逊色于3×7的卷积核,但是在其他类别的船舶检测上都有明显优势,进一步说明非离散卷积能够更好地适应船舶尺寸以及长宽比例,更好地进行船舶的预测。
2.2.2 收敛感知分配策略有效性验证
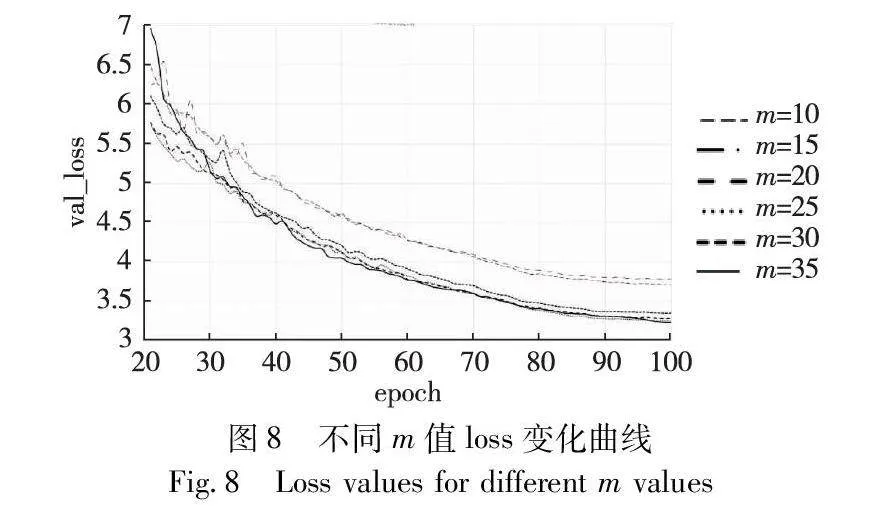
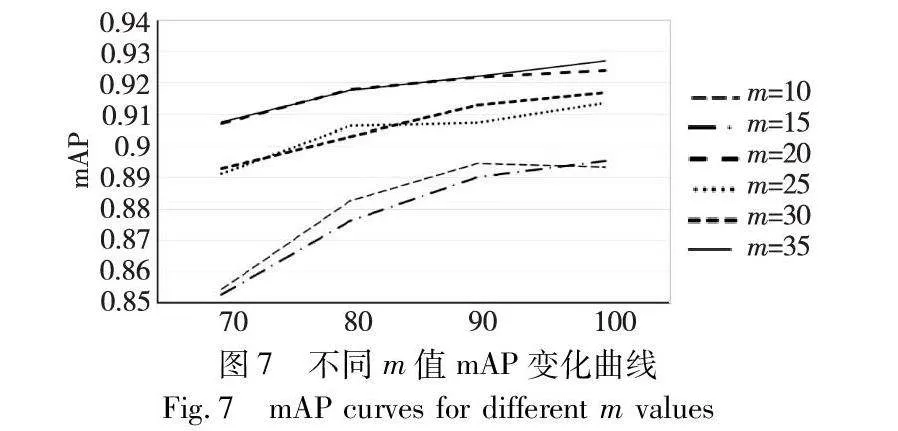
因simOTA匹配策略中的m值是固定的,本文提出收敛感知分配策略对m动态取值,以适应不同的网络复杂度。基于SeaShips数据集,利用simOTA对m分别取10、15、20、25、30,以及采用收敛感知分配策略dynamic_m分别进行实验。图7是不同m值下epoch在70~100的mAP变化折线,图8是m的不同取值在验证集的损失折线。从实验结果看出,不同m值下网络的收敛整体趋势一致,但是收敛程度以及收敛快慢有明显区别。通过对比发现,本文提出的收敛感知分配策略,在mAP上与m=20最好情况相比提高了0.21百分点,许多类别的预测准确率都能达到最好水平,而且从mAP变化折线以及损失变化折线可以看出,本文提出的收敛感知分配策略收敛速度较快,说明其对提高训练速度以及精度具有一定作用,并且可以有效减少调参这一工作。
2.3 不同数据集对比实验结果分析
为了证明本文方法的有效性,将其与Faster-RCNN[15]、SSD[16]、YOLOv3[17]、YOLOv7[18]、YOLOv8、YOLOXs、IMP-YOLOv5七种经典目标检测方法在数据集SeaShips和McShips上进行实验对比。
Faster R-CNN为经典区域建议双阶段检测方法,通过区域建议网络生成候选框再进行船舶分类和边界框回归。SSD、YOLOv3、YOLOv7、YOLOv8、YOLOXs为经典单阶段检测算法,SSD通过在多尺度特征层上进行目标检测,有效提高了小尺寸目标的检测精度;YOLOv3和YOLOv7通过引入锚框机制,进一步提高目标回归率;YOLOXs和YOLOv8使用无锚框机制,提高模型运算速度的同时保持检测精度。其中,YOLOX模型选取m值的最优结果m=20进行实验对比,IMP-YOLOv5[6]结合不同感受野与注意力机制来融合目标全局特征信息,对小目标检测进行增强。SAF-YOLOX为本文算法。
2.3.1 基于SeaShips数据集实验对比
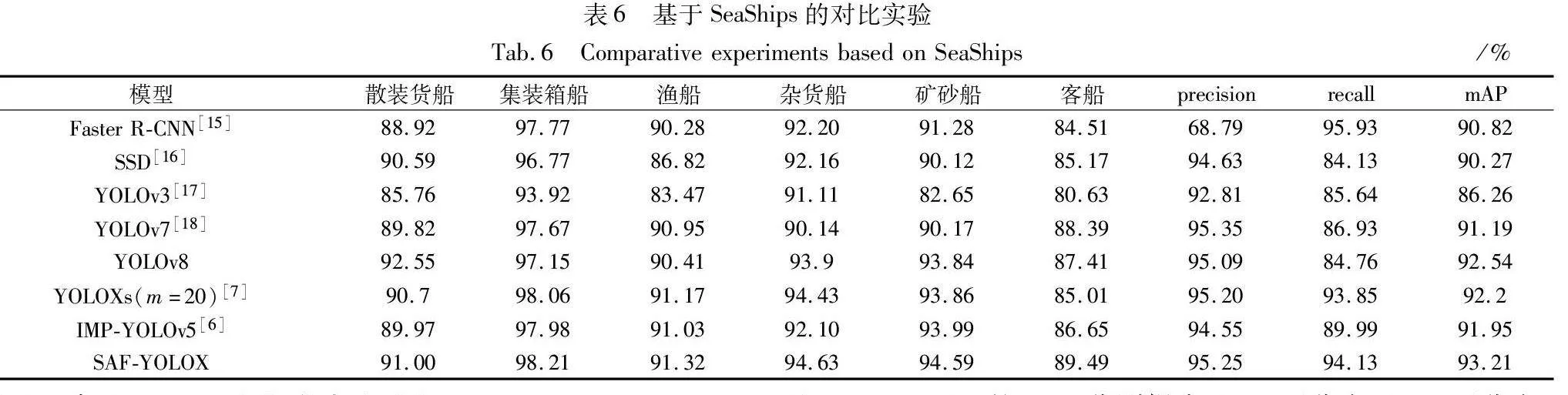
如表6所示,SAF-YOLOX在数据集SeaShips上的mAP达到了93.21%,优于其他七种方法。与双阶段Faster R-CNN对比,SAF-YOLOX虽然召回率低于其1.8百分点,但是在准确率上有明显提升,在precision和mAP上分别提高了26.46百分点和2.39百分点。与单阶段基于锚框机制的检测方法如SSD、YOLOv3、YOLOv7、YOLOv8相比,SAF-YOLOX在mAP上分别提高2.94百分点、6.95百分点、2.02百分点和0.67百分点;与具有最优m值的YOLOXs方法相比,SAF-YOLOX在mAP上提高1.01百分点。在所有类别上均能取得最好的检测准确度,说明基于感受野的角度,通过适应目标大小、长宽比例的感受野获取更准确的特征具有可行性。此外,与IMP-YOLOv5[6]相比,SAF-YOLOX检测性能更优。综上所述,本文方法可以有效处理SeaShips数据集中各种尺度船舶的检测问题,有效提高船舶检测精度,可以应用于实际场景。
2.3.2 基于McShips数据集实验对比
不同方法在McShips数据集的对比实验结果如表7所示。
本文方法得到最高的mAP,达到92.34%。与双阶段Faster R-CNN对比,SAF-YOLOX保证与其相当的召回率条件下,在precision和aVUa5TpE3bUANz4wXjzAuFUxfoVSDAIXACNVska1MwY=mAP上分别提高了43.25百分点和9.75百分点。与经典单阶段检测方法(SSD、YOLOv3、YOLOv7、YOLOv8)相比,SAF-YOLOX的mAP分别提高6.53百分点、6.22百分点、3.93百分点和1.46百分点。与具有最优m值的YOLOXs方法相比,SAF-YOLOX检测精度提高1.09百分点,对于样本尺度大小、形状等变化较大的民用船,检测精度提高了1.78百分点,进一步说明了本文思路的可行性。此外,与IMP-YOLOv5相比,SAF-YOLOX同样具有优势。综上所述,本文方法可以有效处理McShips数据集中民用船和军用船的检测问题,有效提高了模型的泛化能力。
2.4 消融实验
为了验证本文的自适应特征强化模块、多路并行感受野检测头、收敛感知分配策略的作用,在SeaShips数据集上设计消融实验,如表8所示。其中 “√” 表示选择该模块。
采用基础YOLOXs模型(简称方法a)的mAP为88.6%,与方法a相比,引入了自适应特征强化模块后,mAP提高了0.61百分点;引入了多路并行感受野检测头,mAP提高了2.77百分点;引入了收敛感知分配策略,mAP提高了2.81百分点。由此说明三种改进方法都促进了模型检测性能的提升。
为进一步验证模块的互相促进作用,对包含不同模块的方法进行对比实验,结果表明,组合不同模块的方法的其性能优于只包含其中一个模块的方法,验证了SAF-YOLOX中的各模块互相促进能提升多尺度船舶检测性能。其中,包含自适应特征增强、多路并行感受野检测头和收敛感知分配策略的本文方法表现最好,与方法a相比,mAP提高了4.61百分点,说明利用多路并行感受野检测头能够较好地提升多尺度目标检测的效果,并且自适应特征强化模块和收敛感知分配策略能够进一步促进多路并行感受野检测头发挥作用。
在McShips数据集进行消融实验同样也验证了SAF-YOLOX的有效性。综上所述,本文方法考虑目标真实的大小、长宽比例信息,从感受野角度出发,设计的具有大小、长宽比例感知多路并行感受野的检测头对处理多尺度的目标检测问题具有一定作用,多路并行感受野的检测头通过非离散卷积核获得更加准确的感受野,提取更加合适的目标特征,提高了多尺度船舶的检测精度;并且,考虑网络复杂程度以及网络收敛程度的收敛感知分配策略,可以更合理地确定正样本的数量,减少一定的调参工作。
2.5 定性分析
2.5.1 特征热力图对比
特征热力图中有温度的区域表示模型对目标的关注区域,特征热力图9中(a)是原始图片,(b)则是YOLOXs检测的特征热力图,(c)为SAF-YOLOX检测的特征热力图,其中图(a)最右边图片的分辨率是70×80,其他图片的分辨率是1080×1920。从图9可以看出SAF-YOLOX检测的特征热力图范围更广,形状规则性更强,更适应于物体本身的形状特征。说明SAF-YOLOX提取的特征更多,能更好地进行目标预测,SAF-YOLOX可以提取到更好的目标特征,对于大目标可以提取目标更多的前景信息,对于分辨率差的图片中的小目标能够提取更多的目标特征进行预测。
2.5.2 不同场景目标检测对比
图10、11为不同检测方法在不同场景下检测船舶的结果。在多尺度船舶的场景(图10),SAF-YOLOX既检测出大尺寸船舶,又成功分类和定位出小尺寸的船舶,对多尺度船舶目标的感知能力较强。两阶段检测模型的Faster R-CNN和一阶段检测模型中的SSD、YOLOv3均存在漏检的情况。虽然YOLOXs、YOLOv7、YOLOv8在检测大尺度的船舶目标时置信度较高,但是对于小目标的检测置信度和定位不好,YOLOv7、YOLOv8在小目标预测准确度方面低于SAF-YOLOX,且YOLOXs存在误检,并且SAF-YOLOX与IMP-YOLOv5相比在小中目标的检测上置信度高于该算法。综上所述,本文模型在存在图像分辨力较差的小目标、多尺度复杂场景中均比其他模型检测效果更佳,可以较好地处理船舶行驶中各种复杂场景,具有更强的准确性和鲁棒性。
在船舶图片分辨率较低的小目标场景(图11)中,对于一阶段检测算法,具有anchor框的YOLOv3、YOLOv7存在漏检情况,不具有anchor框的YOLOXs、YOLOv8同样出现漏检情况,两阶段Faster R-CNN算法也不能正常检测出船舶目标;从图11(a)和(g)的对比可以看出,虽然SSD和IMP-YOLOv5能检测出船舶,但是置信度低于SAF-YOLOX,由此证明本文引入自适应特征强化模块以及具有目标大小、长宽比例适应的感受野,对分辨率较低场景的目标具有较好的分类和定位能力。
3 结束语
为了解决多尺度船舶目标检测问题,使得模型检测在同类别和不同类别船舶目标的多尺度场景下都能有较好的提升,本文考虑船舶目标大小、长宽比例问题,以及不同尺度特征直接融合可能引入的大量冗余信息、冲突信息,先利用特征强化,获得包含更多目标的前景信息,弱化冗余信息、冲突信息以及背景信息的特征图;再从感受野的角度出发,依照目标的大小、长宽比例信息,设计与其适应的感受野,对不同的特征图采用多路并行感受野的检测头,获取更准确的特征进行预测。为了获得更准确的感受野,本文提出非离散卷积核,实现非整数的感受野;并且本文在SimOTA分配策略的基础上,考虑网络预测头的复杂程度,以及网络的收敛程度等问题,提出收敛感知分配策略。通过在SeaShips和McShips数据集上的定量和定性对比实验,证明本文模型在同类别和不同类别多尺度变化场景下都具有良好的准确性和鲁棒性。在未来工作中,进一步将模型进行知识蒸馏,轻量化模型,以及可以从有效感受野的角度进一步优化对于目标的特征提取,以达到更优的应用效果。
参考文献:
[1]Araujo A,Wade N,Jack S. Computing receptive fields of convolutio-nal neural networks[J]. Distill,2019,4(11): e21.
[2]Liu Songtao,Huang Di. Receptive field block net for accurate and fast object detection[C]// Proc of the 15th European Conference on Computer Vision. Berlin: Springer-Verlag,2018: 385-400.
[3]Zhao Hengshuang,Shi Jianping,Qi Xiaojuan,et al. Pyramid scene parsing network[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2017: 6230-6239.
[4]Dai Jifeng,Qi Haozhi,Xiong Yuwen,et al. Deformable convolutional networks[C]// Proc of IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2017: 764-773.
[5]彭晏飞,赵涛,陈炎康,等. 基于上下文信息与特征细化的无人机小目标检测算法[J]. 计算机工程与应用,2024,60(5): 183-190. (Peng Yanfei,Zhao Tao,Chen Yankang,et al. UAV small object detection algorithm based on context information and feature refinement[J]. Computer Engineering and Applications,2024,60(5): 183-190.)
[6]李坤亚,欧鸥,刘广滨,等. 改进YOLOv5的遥感图像目标检测算法[J]. 计算机工程与应用,2023,59(9): 207-214. (Li Kunya,Ou Ou,Liu Guangbin,et al. Target detection algorithm of remote sensing image based on improved YOLOv5[J]. Computer Engineering and Applications,2023,59(9): 207-214.)
[7]Ge Zheng,Liu Songtao,Wang Feng,et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. (2021-08-06). https://arxiv.org/abs/2107.08430.
[8]毛琳,李雪萌,杨大伟,等. 金字塔频率特征融合目标检测网络[J]. 计算机辅助设计与图形学学报,2021,33(2): 207-214. (Mao Lin,Li Xuemeng,Yang Dawei,et al. Pyramid frequency feature fusion object detection networks[J]. Journal of Computer-Aided Design & Computer Graphics,2021,33(2): 207-214.)
[9]Lin T Y,Dollár P,Girshick R,et al. Feature pyramid networks for object detection[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2017: 2117-2125.
[10]Ribeiro M,Singh S,Guestrin C. Anchors: high-precision model-agnostic explanations[C]// Proc of the 32nd AAAI Conference on Artificial Intelligence and the 30th Innovative Applications of Artificial Intelligence Conference and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence. Palo Alto,CA: AAAI Press,2018: article No.187.
[11]Yuan Chunhui,Yang Haitao. Research on K-value selection method of K-means clustering algorithm[J]. Multidisciplinary Scientific Journal,2019, 2(2): 226-235.
[12]Zheng Ge,Liu Songtao,Wang Feng,et al. OTA: optimal transport assignment for object detection[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2021: 303-312.
[13]Shao Zhenfeng,Wu Wenjing,Wang Zhongyuan,et al. SeaShips: a large-scale precisely annotated dataset for ship detection[J]. IEEE Trans on Multimedia,2018, 20(10): 2593-2604.
[14]Zheng Yitong,Zhang Shun. McShips: a large-scale ship dataset for detection and fine-grained categorization in the wild[C]// Proc of IEEE International Conference on Multimedia and Expo. Piscataway,NJ: IEEE Press, 2020: 1-6.
[15]Ren Shaoqing,He Kaiming,Girshick R,et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2017,39(6): 1137-1149.
[16]Liu Wei,Dragomir A,Dumitru E,et al. SSD: single shot multibox detector[C]// Proc of European Conference on Computer Vision. Cham: Springer,2016: 21-37.
[17]Redmon J,Farhadi A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08). https://arxiv.org/abs/1804.02767.
[18]Wang C Y,Bochkovskiy A,Liao H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway,NJ: IEEE Press,2023: 7464-7475.
