
基于β-VAE的联邦学习异常更新检测算法
2024-08-15 00:00:00张仁斌崔宇航张子石
计算机应用研究 2024年8期





摘 要:利用自编码器模型检测恶意模型更新的联邦学习框架是一种优秀的投毒攻击防御框架,但现有的基于自编码器的模型存在训练困难、异常检测能力不足等问题。针对以上问题,提出了一种基于β-VAE的联邦学习异常更新检测算法:服务器端通过抑制训练样本的随机属性,生成更稳定的训练数据集,并使用该数据集对β-VAE异常检测模型进行即时训练。利用该模型计算客户端上传的任务模型更新的异常分数,然后根据动态阈值来检测并移除异常更新。通过三个联邦学习任务对算法进行了验证,即在MNIST数据集上使用逻辑回归(logistic regression,LR)模型进行分类、在FEMNIST数据集上使用卷积神经网络(convolutional neural network,CNN)进行分类以及在Shakespeare数据集上使用循环神经网络(recurrent neural network,RNN)进行字符预测。实验结果表明,在多种攻击场景下,该算法下的任务模型相较于其他防御算法都取得了更高的准确率。这表明在非独立同分布场景下,该算法对联邦学习投毒攻击具有良好的鲁棒性。
关键词:联邦学习; 异常检测; 投毒攻击; 防御机制; 深度学习
中图分类号:TP18;TP309 文献标志码:A
文章编号:1001-3695(2024)08-035-2496-06
doi:10.19734/j.issn.1001-3695.2023.11.0553
Algorithm for detecting malicious model updates offederated learning based on β-VAE
Zhang Renbina,b, Cui Yuhanga, Zhang Zishia
(a.School of Computer Science & Information Engineering, b.Anhui Province Key Laboratory of Industry Safety & Emergency Technology, Hefei University of Technology, Hefei 230601, China)
Abstract:The federated learning framework that uses autoencoder model to detect malicious model updates is an excellent defense framework for poisoning attacks. However, the existing autoencoder-based models face several challenges such as training difficulties and limited anomaly detection capability. In view of the above problems, this paper proposed an algorithm for detecting malicious model updates of federated learning based on β-VAE: the central server stabilized the training dataset by suppressing random attributes of the training samples, and used the dataset to train β-VAE anomaly detection model in real time. The model computed the anomaly score of task model updates uploaded by the clients, and then to detect and exclude malicious model updates based on the dynamic threshold of anomaly score. This paper evaluated the performance of the proposed algorithm on three federated learning tasks. Specifically, these tasks include classification on the MNIST dataset using the logistic regression(LR) model, classification on the FEMNIST dataset using the convolutional neural network(CNN) model, and character prediction on the Shakespeare dataset using the recurrent neural network(RNN) model. The experimental results show that, the task model under this algorithm achieves higher accuracy compared to other defense algorithms. This indicates that in Non-IID scenarios, the algorithm exhibits strong robustness against poisoning attacks in federated learning.
Key words:federated learning; anomaly detection; poisoning attack; defense mechanism; deep learning
谷歌提出的联邦学习(federated learning,FL)[1]为数据价值的利用与隐私数据保护的矛盾[2]提供了解决方案。然而,传统联邦学习框架很容易遭受恶意客户端的投毒攻击[3,4],即通过修改本地训练数据集或局部模型来影响全局模型的性能和准确性。对于恶意客户端的攻击,服务器端无法直接阻止或纠正其行为,需要采取其他联邦学习安全保护机制来确保联邦学习系统的安全性和可靠性。研究表明,基于深度学习的异常检测方法可以识别并过滤异常模型更新。然而,异常检测模型的训练过程需要耗费大量的共享数据和算力,这在联邦学习框架下难以实现。为了缓解服务器端对资源的过度依赖,同时增强联邦学习框架的鲁棒性,本文提出了一种基于β-VAE的联邦学习异常更新检测算法。服务器端首先通过降低训练样本的随机性来生成更可控的训练数据集。然后使用该数据集对β-VAE异常检测模型进行即时训练。最后,利用该模型计算客户端上传的模型更新的异常分数,并根据动态阈值识别和移除异常模型更新。
1 相关工作
在联邦学习中,客户端的本地训练数据集是私有的,且服务器端不会直接参与客户端模型的训练过程,因此恶意客户端发起投毒攻击的可能性非常高。投毒攻击主要分为数据投毒和模型投毒:数据投毒通过修改训练数据集,降低模型对某一类数据或全体数据的分类精度;模型投毒则通过直接修改模型参数影响全局模型。实际上,模型投毒比数据投毒更有效[5,6]。
专门针对数据投毒的防御方法有数据清洗[7],通过过滤掉可疑的训练数据点来缓解数据投毒的影响,一些研究[8,9]致力于利用不同的稳健统计模型来改进数据清洗技术。Koh等人[10]的工作指出,更强的数据投毒可能打破数据清洗防御。更普遍的防御方法是服务器端对模型更新进行检测[11,12]。其中一种是基于统计的异常检测方法,Chen等人[13]提出了GeoMed(geometric median)方法,使用局部模型更新的几何中值来生成全局模型。Blanchard等人[14]提出了基于欧氏距离的Krum方法,选择一个与其他局部模型更新最相似的局部模型更新来生成全局模型。虽然这些稳健的统计方法简单且与底层学习系统高度解耦,但是无法消除异常模型对全局模型的影响。另外一种是基于深度学习的异常检测方法,利用神经网络模型识别并移除异常模型更新,保证全局模型的聚合过程不受异常模型更新影响。Zhao等人[15]提出了基于生成对抗网络(generative adversarial network,GAN)的防御策略PDGAN(poisoning defense GAN),PDGAN从模型更新中重建训练数据,并通过生成的数据来审计每个局部模型的准确率,准确率低于预定义阈值的模型将被识别为异常模型,并且异常模型更新将从本轮迭代的聚合过程中移除。由于需要使用局部模型来训练PDGAN,所以这种方法在迭代初期无法检测到异常模型更新。Sattler等人[16]提出了CFL(clustered federated learning)[17]算法的鲁棒性应用,根据模型更新的余弦相似度将更新分为正常模型更新和异常模型更新。该算法仅在IID设置下有效,且需要经过多个轮次才能准确划分模型更新,未被识别的恶意攻击对模型性能的影响在后续几轮中持续存在[11]。Li等人[18]利用变分自动编码器(variational autoencoder,VAE)计算模型更新的异常分数,将大于动态阈值的更新识别为异常更新,并将异常更新从本轮迭代中移除。Gu等人[19]在此基础上进一步考虑每一轮更新的差异,使用条件变分自动编码器(conditional VAE,CVAE)融入时间信息。然而,随着任务模型在训练过程中逐渐收敛,相邻轮次的更新差异逐渐减小,因此使用时间信息作为标签来区分不同轮次的更新并不合适。基于自编码器的异常检测模型中,为了能够准确地区分异常模型和正常模型,通常需要使用大量的共享数据进行耗时的训练,然而在实际部署中,很难满足模型训练过程中对共享数据和计算资源的需求。
综上,针对以上研究方法的不足,且为了缓解服务器端对资源的过度依赖,同时为了增强联邦学习框架的鲁棒性,本文提出了基于β-VAE的联邦学习异常更新检测算法。在共享数据受限的情况下,服务器端首先利用初始化的全局任务模型,降低训练数据集的随机偏差,生成更加稳定的训练数据集。然后使用该数据集对β-VAE异常检测模型进行即时训练,以鼓励其学习正常数据更有效的潜在表示。最后,利用该模型计算客户端上传的模型更新的异常分数,并根据异常分数的动态阈值检测和排除异常更新,使用FedAvg算法[20]对正常更新进行聚合操作,以实现对联邦学习的保护。
2 联邦学习异常更新检测算法
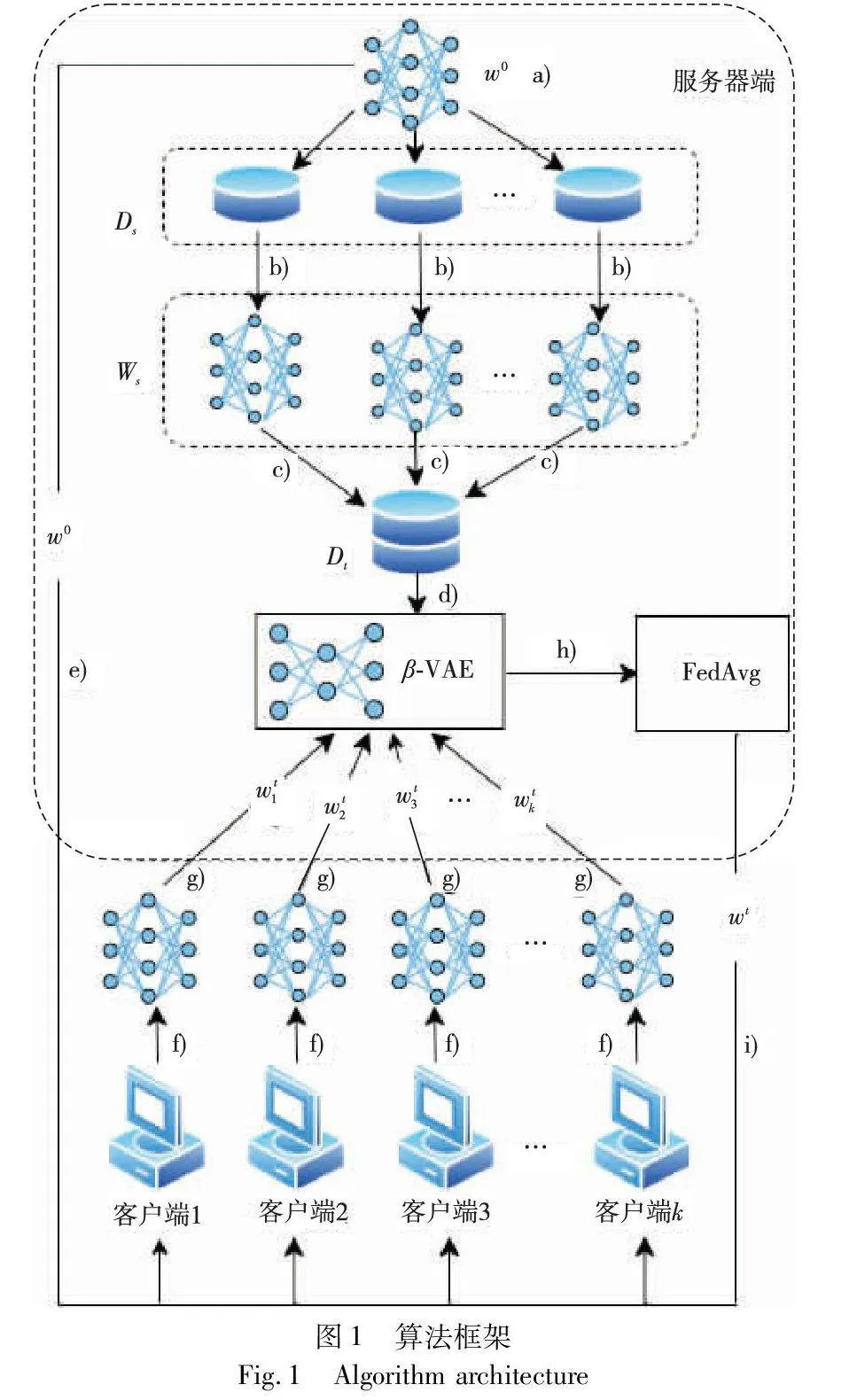
联邦学习框架分为两种:客户端-服务器架构[21]和对等网络架构[22]。本文提出的联邦学习异常更新检测算法是基于客户端-服务器架构设计的,算法框架如图1所示。本文算法包含n个客户端和1个服务器端。服务器端包含少量的共享数据Ds、1个β-VAE异常检测模型和1个全局模型w。共享数据Ds划分为多个非独立同分布数据集,用于训练多个异构的虚拟任务模型。
结合图1,本文算法的流程如下:
a)初始化全局模型w0;
b)使用w0在非独立同分布数据集上训练多个异构的虚拟任务模型,得到模型参数集合Ws;
c)提取集合Ws中每个模型参数的低维代理向量,得到异常检测模型的训练集Dt;
d)对β-VAE异常检测模型进行即时训练;
e)将全局模型w0分发给每个客户端进行迭代训练;
f)客户端k(k=1,2,…,n)根据第t轮迭代的全局模型wt-1,训练本地数据集,获得局部模型wtk;
g)每个客户端将局部模型上传到服务器端;
h)服务器端使用β-VAE异常检测模型识别并移除异常更新;
i)使用FedAvg算法对正常更新进行聚合,将聚合得到的全局模型wt分发给客户端;
j)重复步骤f)~i),直至全局模型收敛。
本文提出的异常检测模型的即时训练方法涉及步骤a)~e),将在2.1节中详细阐述。步骤h)的异常检测过程将在2.2节中详细阐述。
2.1 异常检测模型的即时训练方法
联邦学习中,基于自编码器的异常检测模型的性能,受限于服务器端共享数据的数量和质量。本文试图寻找一种有效的训练方法,在共享数据受限的场景下依然可以训练出性能良好的异常检测模型。对于异常检测模型而言,其关键在于如何准确识别出异常数据。为了实现这一目标,通常会使用异常分数的均值作为动态阈值来区分异常数据和正常数据,在这个过程中,只需要保证异常数据和正常数据在异常分数上具有一定的区分度即可。在无监督学习中,异常检测模型需要从训练数据集中学习正常的行为模式,因此为了提高模型的准确性和泛化能力,应尽量确保训练数据具有更多与正常数据相似的特征。
在本文中,虚拟任务模型和真实任务模型的模型参数将作为异常检测模型的输入数据。由于服务器端持有的共享数据有限,虚拟任务模型无法充分训练以更新模型的大部分参数值,而其中的随机值可能会影响异常检测模型对正常数据潜在表示的学习。针对这个问题,本文试图通过统一虚拟任务模型和真实任务模型的初始化参数,以降低虚拟任务模型之间、虚拟任务模型与真实任务模型之间的随机偏差,从而生成具有高度一致性特征的训练数据集。本文认为,在服务器端共享数据有限的场景下,相同的初始化模型在同一个任务下训练得到的模型之间具有较高的相似度,不同的初始化模型在同一个任务下训练得到的模型之间具有较低的相似度。为了验证这一想法的正确性,在联邦学习框架下,本文使用联邦学习开源的基准数据集LEAF提供的异构MNIST数据集对LR模型进行实验。
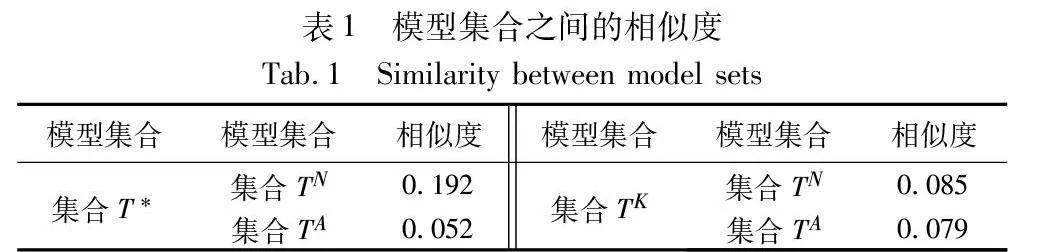
首先,初始化w*和wk(k=1,…,n)共n+1个模型参数。然后,模拟服务器端在小规模测试集上使用w*训练n个正常模型于集合T*={w*i|1≤i≤n},使用wk(k=1,…,n)训练n个正常模型于集合TK={wki|1≤i=k≤n},每个模型训练10轮,接下来,模拟真实客户端在训练集上使用w*训练n个正常模型于集合TN={wNi|1≤i≤n}和n个异常模型于集合TA={wAi|1≤i≤n},每个模型训练100轮。最后,使用式(1)分别计算集合T*、TK与集合TN、TA之间的相似度:
sim(A,B)=1n2∑ni=1∑nj=111+d(ai,bj)(1)
其中:sim(A,B)代表集合A和B的相似度;d(ai,bj)代表模型ai和bj之间欧氏距离,ai∈A且bj∈B,本实验中n=50。
实验结果如表1所示。从表1中可以看出,相比于集合TK,集合T*与TN和TA相似度差异更大。表明集合T*中的模型具有更多可以区分集合TN和TA中模型的特征,这些特征与集合TN中的模型特征更为相似,从而为异常检测模型提供了更有益的学习环境,使其能够更好地学习集合TN中的正常模型的行为E5vujLJRrBzpiWMtRrZCHQ==模式。
因此,在联邦学习中,可以通过使用相同初始化模型参数来减小虚拟任务模型之间的随机差异,生成更稳定的训练数据集。根据以上结论,本文提出一种异常检测模型的即时训练方法。结合图1,异常检测模型的即时训练方法具体流程如下:服务器端在初始化全局模型w0后,使用该模型参数和有限的共享数据训练多个异构的虚拟任务模型,并收集虚拟任务模型参数。为了避免维度过高的问题,采用随机采样的方法提取出模型参数的低维代理向量,并作为训练数据训练异常检测模型。完成训练之后,将w0分发给客户端开始联邦学习的协同训练过程。考虑到共享数据有限,为了防止虚拟任务模型和异常检测模型过拟合,同时减少服务器端的计算量,训练过程只进行若干轮次。此外,由于服务器端获取的共享数据质量无法保证,所以服务器端训练的多个虚拟任务模型应当具有异构性。
基于自编码器的异常检测模型[18,19]在特定的环境和条件下训练完成后,可以重复使用并具有一定的稳定性。然而,当环境和条件发生变化时,该模型的可用性可能会受到影响,并且重新训练模型需要耗费大量的时间和资源。相比之下,本文的训练方法具有即时性和灵活性,在任务模型和相关参数确定后,只需要使用少量的共享数据进行一次简单的训练即可。
由于异常检测模型的训练集是从虚拟任务模型训练初期的参数集中提取的,这可能导致异常检测模型过度拟合任务模型训练初期的参数。联邦学习的协同训练过程在异常检测模型训练完成后开始,随着迭代次数的增加,由于训练数据和学习率等因素的影响,模型参数的变化逐渐增大,使得每一轮的模型参数和训练初期的模型参数相差越来越大,导致正常更新的异常分数逐渐上升。一般情况下,异常更新试图缩小与正常模型的差异,异常更新的异常分数也会随之增长,并不会影响基于动态阈值的分类方法的准确性。
2.2 基于β-VAE的异常检测模型
利用上述训练方法中的数据集生成方式,可以得到与真实客户端的模型更新更相似的虚拟模型更新,在此基础上,使用基于欧氏距离的相似性检测算法来识别异常更新。然而,这种无监督方法在面对高维数据的情况下缺乏效率,并且在识别异常更新中潜在异常因子方面存在难度。为了解决这些问题,本文采用了数据降维技术和特征提取的技术,以有效应对上述挑战。VAE[23]是一个具备数据降维和特征提取功能的无监督神经网络模型,编码器模块将原始数据x投影到低维嵌入z,然后解码器模块从这些低维嵌入重建原始数据。异常数据的重建误差会显著大于正常数据,因而常被用于数据的异常检测[24]。首先,原始数据x通过编码器近似得到后验分布q(z|x)。再选取具有独立特性的高斯分布作为先验分布p(z)~N(0,1),从中采样得到符合后验分布的潜在变量z,即z~q(z|x)。最后将潜在变量z输入解码器近似生成分布pθ(x|z),采样得到重建数据。和θ分别是编码器和解码器的模型参数。VAE的损失函数如式(2)所示。
L(x)=Euclid Math TwoEApq(z|x)[log pθ(x|z)]-DKL(q(z|x)‖p(z))(2)
其中:-DKL(q(z|x)‖p(z))称为KL散度项,反映先验分布p(z)和后验分布q(z|x)之间的相似性,具有独立特性的先验分布p(z),鼓励神经网络学习到可分离的潜在变量表示z,在一定程度上具备了解耦的性能。为了加强模型对数据的有效解耦,Higgins等人[25]提出了β-VAE模型,在VAE的损失函数中增加了一个大于1的超参数β,进一步约束模型对潜在变量的学习,提升解耦性能,鼓励分解更多的潜在表征[26]。β-VAE的损失函数如式(3)所示。
L(x)=Euclid Math TwoEApq(z|x)[log pθ(x|z)]-βDKL(q(z|x)‖p(z))(3)
本文基于β-VAE设计异常检测模型,在联邦学习协同训练开始前,在使用2.1节的数据集生成方式得到稳定的训练数据集上,以式(3)为损失函数,对异常检测模型进行训练。
在模型检测阶段,将客户端上传的模型更新的低维代理向量xtest输入到编码器中并映射到潜在空间得到低维嵌入z,再利用解码器重建出test。对于异常模型更新,β-VAE难以有效地缩小输入xtest和重构输出test之间的误差以及后验分布q(z|xtest)和先验分布p(z)之间的分布距离,因此本文使用损失函数值作为给定模型更新的异常分数。通过计算输入xtest和重构输出的test之间的均方误差(mean square error,MSE),得到重构分数Scorerecon,如式(4)所示。
Scorerecon=MSE(xtest,test)(4)
通过计算后验分布q(z|xtest)和先验分布p(z)之间的KL散度,得到KL分数ScoreKL,如式(5)所示。
ScoreKL=βKL(q(z|xtest)‖p(z))(5)
结合上述两种分数得到最终的异常分数Scoreano。
Scoreano=Scorerecon+ScoreKL(6)
本文将检测阈值设置为所有异常分数的平均值,异常分数高于阈值的更新被视为异常更新。参数β的大小影响着异常检测模型的训练和检测。当增大β时,目标函数中的重建误差项所占的比重减小,而KL散度项所占的比重增大。这意味着模型更加注重优化潜在空间的结构,而不是简单地通过最小化重建误差来学习潜在变量。在检测阶段,高β值一定程度上减弱了重构分数的正常增长对异常分数的影响,解决了使用本文的即时训练方法可能导致的问题。因此,适当增大β的值,对提升算法的鲁棒性和稳定性具有重要作用。
由于修改后的训练目标惩罚了重构质量,高β值可能会导致重构质量的下降[27],但是该模型的主要目标并非仅仅是重建输入数据,而更为关键的是提高对潜在变异因素的辨别能力。
3 实验及分析
3.1 实验设置
本文使用三个训练任务来评价所提算法在非独立同分布场景下对拜占庭攻击和后门攻击的鲁棒性。第一个训练任务是使用LR模型对MNIST数据集[28]进行分类。本文将MNIST数据集分布到100个客户端中,每个客户端只拥有两个标签的样本,以模拟数据非独立同分布的情况。在每一轮通信中,随机选取50个客户端参与聚合,每个客户端使用0.01的学习率训练5轮。第二个训练任务是使用CNN模型对FEMNIST(federated extended MNIST)数据集[29]进行分类。FEMNIST数据集是通过基于不同的手写作者对extended MNIST中的数据进行分区来构建的,每个客户端只拥有一个作者的手写数据,符合数据的非独立同分布。在每一轮通信中,随机选取30%的客户端参与聚合,每个客户端使用0.01的学习率训练5轮。第三个训练任务是使用RNN模型对Shakespeare数据集[1,29]进行字符预测。Shakespeare数据集是由莎士比亚完整作品[30]构建的数据集,每个客户端拥有一个角色的台词数据,符合数据的非独立同分布。在每一轮通信中,随机选取30%的客户端参与聚合,每个客户端使用0.8的学习率训练1轮。
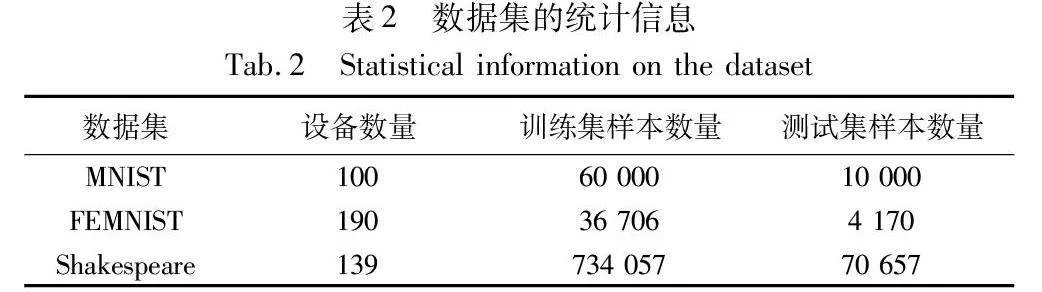
本文使用的实验数据全部来自于联邦学习开源的基准数据集LEAF[29],具体统计信息如表2所示。
在异常检测模型训练阶段,从测试数据集中选取5%的数据用于虚拟客户端的训练,虚拟客户端使用相同的参数配置训练10轮,从模型更新中提取低维代理向量作为异常检测模型的训练数据。使用0.003的学习率和0.000 1的权重衰退值对β-VAE模型训练10轮。攻击者通常需要在攻击成功率和攻击效果之间进行权衡,为了增强攻击效果,异常更新往往需要具备更多或更强的异常因子,以尽可能让全局模型偏离正常模型,但这也会增加被服务器端检测出的风险。例如在同值攻击中,Gu等人[19]将异常模型参数全部设置为100,而正常模型参数往往都较小,以至于这种攻击的攻击效果良好但隐蔽性较差,以此来证明所提算法在防御投毒攻击的优越性并不合适。因此,本实验的同值攻击将异常模型参数全部设置为0,一方面保留异常特征,另一方面加强异常更新的隐蔽性。本文的其他攻击模式与文献[18]中描述的类似。
为了验证所提算法对拜占庭攻击和后门攻击的防御性能,本文采用任务模型的准确率作为实验的主要评价指标。由于后门攻击只针对某些特定的子任务,对主任务的准确率影响较小,所以使用后门攻击的成功率作为额外的评价指标。
3.2 实验结果及分析
将本文算法与经典联邦学习算法FedAvg以及多种联邦学习防御方法进行对比。传统方法包括基于欧氏距离的GeoMed方法和Krum方法。基于自编码器的异常检测方法包括Fedvae[18]和Fedcvae[19]。为确保实验结果的可靠性,本文进行了一系列实验,涉及数据集、攻击方式、防御策略以及恶意客户端占比等多个变量。每个变量均包含多个取值。对于每一组变量取值,都进行了三次独立实验,并以这三次实验结果的均值作为该组变量取值对应的实验结果,以提高实验结果的稳定性和可信度。具体而言,本文考虑了三种拜占庭攻击,分别是噪声攻击、符号翻转攻击和同值攻击。分别在恶意客户端占比为30%和50%两种环境下评估本文算法的性能。除此之外,本文还评估了各种算法在MNIST数据集下面对后门攻击的鲁棒性。实验基于云环境,使用Python 3.7下PyTorch框架进行模型搭建。主要硬件参数为CPU Intel Xeon Platinum 8350 C,内存42 GB,GPU NVIDIA GeForce RTX 3090,12 GB显存。
噪声攻击,恶意客户端将高斯噪声添加到模型参数中,即wk=k+ε,其中k是第k个客户端训练得到的真实模型参数,是一个来自高斯分布的向量。在本实验中,~N(0,0.1)。实验结果如图2所示,在附加噪声攻击下,基于自编码器的异常更新检测算法的性能相近,而本文算法在MNIST数据集和FEMNIST数据集中表现得更好,任务模型准确率平均提升了约0.7%和0.8%,在Shakespeare数据集上的性能略低于Fedvae。GeoMed在三个数据集获得的准确率均优于Fed-Avg和Krum,这表明相较于其他传统算法,GeoMed对噪声攻击具有更强的鲁棒性。
符号翻转攻击,恶意客户端翻转其模型参数的符号,即wk=σk,其中k是真实模型参数,σ是一个常数。在本实验中,σ=-1。实验结果如图3所示,在本文算法下,任务模型获得了更快的收敛速度和更高的准确率。相较于Fedvae,本文算法在MNIST数据集和FEMNIST数据集上的任务模型准确率分别平均提升了约0.3%和3%。在Shakespeare数据集上,Fedvae和Fedcvae的任务模型准确率不稳定,并且只有30%左右,甚至比Krum算法的表现还要差。而Fedcvae在三个深度学习方法中的效果最差,Fedcvae在Fedvae的基础上添加了每一轮的时间信息,试图让自编码器学习到更多知识,但这种方法增强了时间信息对异常分数的影响,减弱了原始数据的重构分数对异常分数的影响,进而降低了异常检测的性能。GeoMed在恶意客户端占比不同的场景下,模型准确率表现出随恶意客户端占比提高而下降的趋势,原因在于恶意攻击者试图移动所有更新的几何中心远离真实的中心。在恶意客户端占比较高的场景下,Krum通过选取与其他模型相似度最高的模型作为全局模型,在一定程度上可以保证模型准确率的稳定性。
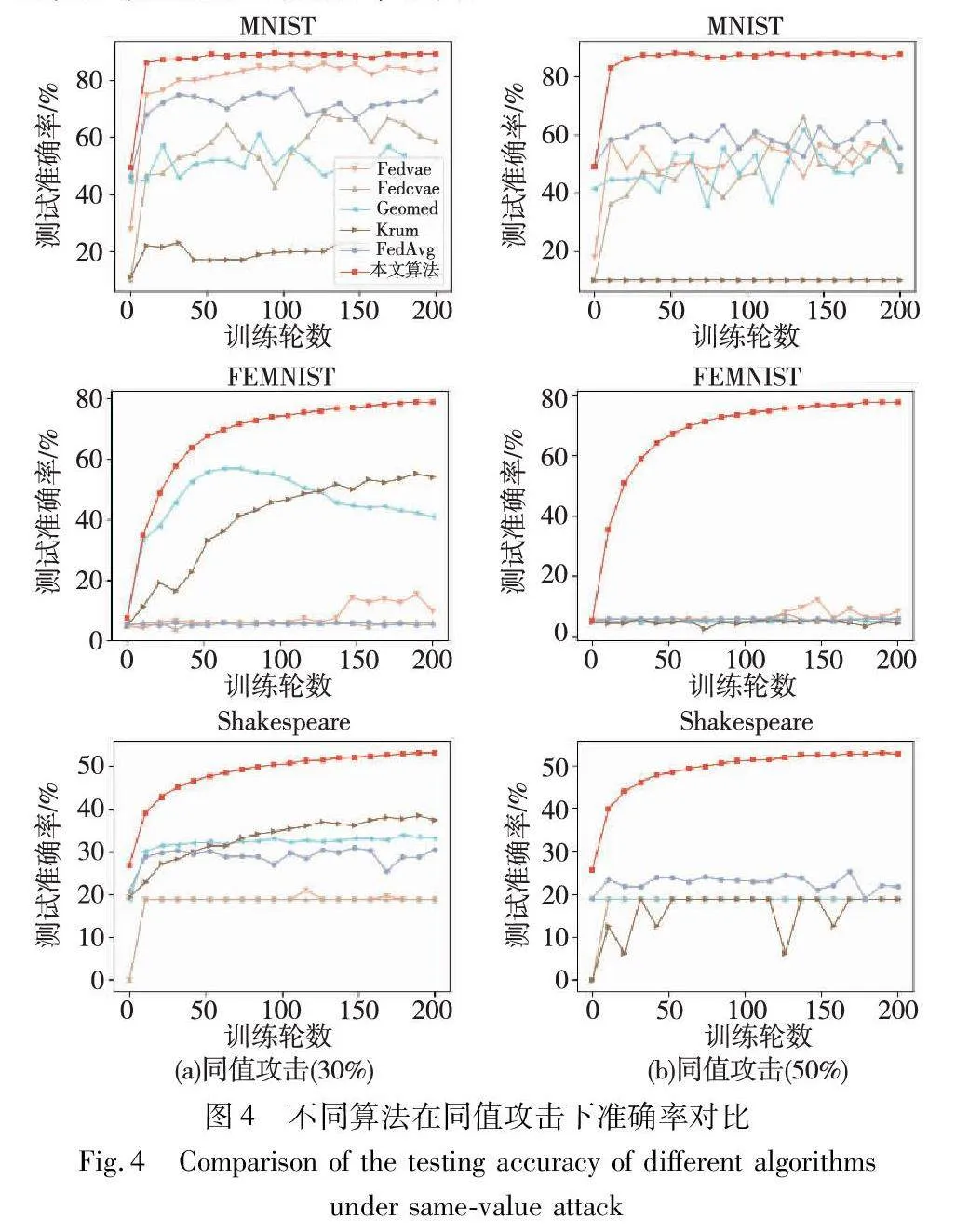
同值攻击,恶意客户端将模型参数直接修改为wk=c1,其中1∈Euclid ExtraaBpd是一个全1的向量,c是一个常数。在本实验中,c=0。实验结果如图4所示,在本文算法下,任务模型依旧获得了稳定的收敛速度和准确率,而Fedvae和Fedcvae在FEMNIST数据集和Shakespeare数据集上的准确率稳定在5%和18%。这是因为在同值攻击中,恶意客户端将模型参数设置为0,则可能出现异常更新反而获得更小的异常分数的情况。在使用基于动态阈值的分类方法进行异常检测时,就会将异常更新判定为正常的更新,将正常更新判定为异常的更新。如果异常检测结果完全错误,那么全局模型的参数将被窜改成0。客户端难以执行模型参数的梯度下降算法,最终导致全局模型发散。在恶意客户端占比为50%的场景下,GeoMed和Krum在FEMNIST数据集和Shakespeare数据集上同样丧失了防御能力,这表明全0的模型更新不仅会使得所有更新的几何中心远离真实的中心,还会增加异常更新与其他模型更新的相似性度量值,导致GeoMed和Krum计算或选择了异常的模型作为全局模型。
后门攻击是一种定向的模型投毒攻击[5]。在后门攻击中,恶意客户端的目标是在保证主任务的准确率的同时,诱导目标子任务的失败。例如,在图像分类任务中,后门攻击通过将标签为“7”的图像错误标记为“5”,导致模型在标签为“7”的图像上的错误分类。但是由于联邦学习的客户端很多,参数聚合时抵消了后门攻击的大部分贡献,这种朴素的后门攻击难以成功植入[6]。本实验使用基于放大模型参数的模型替换攻击,将后门模型的权重按比例增大,提高攻击成功率。在MNIST数据集上的实验结果如图5所示。
如图5所示,在基于自编码器的深度学习算法下的任务模型都获得了较高的准确率和较低的后门成功率,且在本文算法下,任务模型拥有较高的准确率和较快的收敛速度,后门攻击的成功率更低。虽然GeoMed获得较高的准确率,但后门成功率并不稳定,表明GeoMed不能完全消除后门攻击对子任务的影响。Krum无法识别出异常模型更新中隐藏的后门攻击,因此任务模型的后门成功率较高。
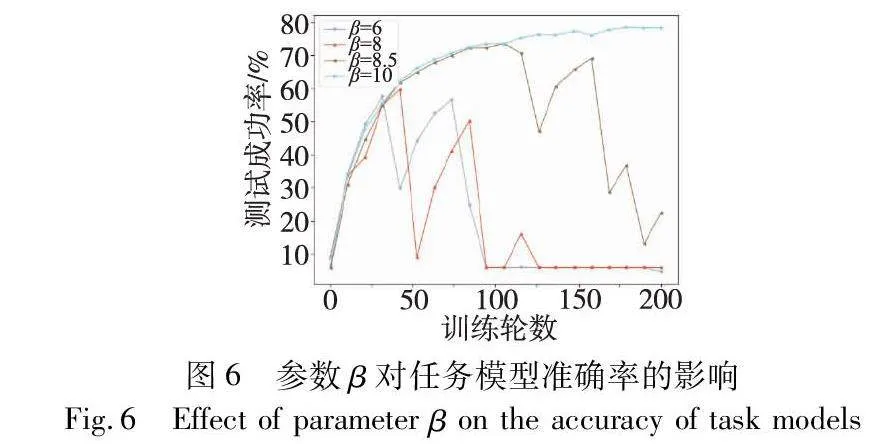
为了探究本文算法中重要参数β的影响,设计算法在FEMNIST数据集上对同值攻击下参数β的影响进行了分析实验。实验结果如图6所示,参数β取值分别为6、8和8.5时,全局模型准确率分别在第30轮、第40轮和第110轮达到第一峰值后骤降,之后缓慢上升到达第二峰值后再次骤降,反复循环,最终生成了如图6所示的峰形折线图。而每次达到的峰值呈现下降趋势,最终降至最低。准确率曲线出现这种走势主要是两个原因叠加造成的:一是本文的训练方法具有一定的局限性,二是同值攻击本身具有特殊的攻击形式。
首先,异常检测模型的训练数据相对于测试数据并不是无偏的,虚拟任务模型只完成了初期的训练,导致异常检测模型过于适应任务模型训练初期的参数。在异常检测阶段,随着迭代次数的增加,正常更新的异常分数缓慢增长。其次,在同值攻击环境下,每一轮迭代的异常更新保持不变,异常分数稳定在一个较高的分数上。最终,正常更新的异常分数呈现上升追赶的趋势,在某一时刻超过异常更新的异常分数,导致这一轮的检测错误率较高,全局模型准确率骤降。下一轮的正常更新的重构分数重新回到较低的值,异常检测模型可以再次准确识别,全局模型准确率缓慢上升。伴随着多次检测失败,正常更新的异常因子逐渐增多,导致全局模型完全被异常更新污染,最终无法收敛。本文通过适当增大参数β的值,试图减少重构分数的正常增长对异常分数的影响,对异常检测模型的即时训练方法进行修正。图6的实验结果也证实了这一方法的有效性,通过逐渐增大参数β的值,曲线的第一次骤降时刻逐渐后延,当β取值为10时,准确率持续上升并保持稳定。这是因为全局模型已经逐渐收敛,正常模型更新的异常分数也趋于稳定,准确率不会再出现骤降的情况。
根据上述分析,适度增大β值可以提高算法的稳定性和鲁棒性。另外,任务模型的复杂度、本地训练的次数等影响模型收敛快慢的因素,也可能会影响β的取值。针对不同的任务模型,β应当如何取值是今后工作需要关注的问题。
4 结束语
本文主要针对现有联邦学习异常检测框架中自编码器模型存在的训练困难以及异常检测能力不足等问题,提出一种新的联邦学习系统异常更新检测算法。本文提出了一种异常检测模型的即时训练方法,通过提高训练数据和测试数据之间的相似度来优化训练数据集,使异常检测模型学习到更有利于正常数据的数据特征。同时,在保证可用性的前提下,有效降低了服务器端对共享数据和算力的需求。为了进一步提高联邦学习框架的鲁棒性,本文利用β-VAE模型优异的特征解耦和分离能力设计了异常检测模型,从而提高了识别变异因子的能力。实验结果表明,相较于各种防御算法,本文算法在任务模型准确率方面表现更佳,验证了本文算法的有效性。未来将考虑针对更复杂的攻击方式设计自适应的防御算法。
参考文献:
[1]McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Proc of the 20th International Conference on Artificial Intelligence and Statistics. San Francisco: Morgan Kaufmann Publishers, 2017: 1273-1282.
[2]Li Li, Fan Yuxi, Lin Kuoyi. A survey on federated learning[C]//Proc of International Conference on Control & Automation. Pisca-taway,NJ: IEEE Press, 2020: 791-796.
[3]Kairouz P, McMahan H B, Avent B, et al. Advances and open problems in federated learning[J]. Foundations and Trends in Machine Learning, 2021, 14(1-2): 1-210.
[4]孙爽, 李晓会, 刘妍, 等. 不同场景的联邦学习安全与隐私保护研究综述[J]. 计算机应用研究, 2021, 38(12): 3527-3534. (Sun Shuang, Li Xiaohui, Liu Yan, et al. Survey on security and privacy protection in different scenarios of federated learning[J]. Application Research of Computers, 2021, 38(12): 3527-3534.)
[5]Bhagoji A N, Chakraborty S, Mittal P, et al. Analyzing federated learning through an adversarial lens[C]//Proc of International Conference on Machine Learning.[S.l.]: JMLR.org. 2019: 634-643.
[6]Bagdasaryan E, Veit A, Hua Y, et al. How to backdoor federated learning[C]//Proc of International Conference on Artificial Intelligence and Statistics. Cambridge, MA: MIT Press, 2020: 2938-2948.
[7]Cretu G F, Stavrou A, Locasto M E, et al. Casting out demons: sanitizing training data for anomaly sensors[C]//Proc of IEEE Symposium on Security and Privacy. Piscataway, NJ: IEEE Press, 2008: 81-95.
[8]Shen Yanyao, Sanghavi S. Learning with bad training data via iterative trimmed loss minimization[C]//Proc of International Conference on Machine Learning.[S.l.]: JMLR.org. 2019: 5739-5748.
[9]Tran B, Li J, Madry A. Spectral signatures in backdoor attacks[C]//Proc of Annual Conference on Neural Information Processing Systems. Amsterdam: Elsevier, 2018: 8000-8010.
[10]Koh P W, Steinhardt J, Liang P. Stronger data poisoning attacks break data sanitization defenses[J]. Machine Learning, 2022, 111(1): 1-47.
[11]Sun Jingwei, Li Ang, DiValentin L, et al. FL-WBC: enhancing robustness against model poisoning attacks in federated learning from a client perspective[C]//Proc of the Annual Conference on Neural Information Processing Systems. Amsterdam: Elsevier, 2021: 12613-12624.
[12]Lu Shiwei, Li Ruihu, Chen Xuan, et al. Defense against local model poisoning attacks to Byzantine-robust federated learning[J]. Frontiers of Computer Science, 2022, 16(6): 166337.
[13]Chen Yudong, Su Lili, Xu Jiaming. Distributed statistical machine lear-ning in adversarial settings: Byzantine gradient descent[C]//Proc of ACM on Measurement and Analysis of Computing Systems.New York:ACM Press, 2017: 1-25.
[14]Blanchard P, El Mhamdi E M, Guerraoui R, et al. Machine learning with adversaries: Byzantine tolerant gradient descent[C]//Proc of Annual Conference on Neural Information Processing Systems. Amsterdam: Elsevier, 2017.
[15]Zhao Ying, Chen Junjun, Zhang Jiale, et al. PDGAN: A novel poisoning defense method in federated learning using generative adversa-rial network[C]//Proc of International Conference on Algorithms and Architectures for Parallel Processing. Cham: Springer, 2019: 595-609.
[16]Sattler F, Müller K R, Samek W. Clustered federated learning: model-agnostic distributed multitask optimization under privacy constraints[J]. IEEE Trans on Neural Networks and Learning Systems, 2020, 32(8): 3710-3722.
[17]Sattler F, Müller K R, Wiegand T, et al. On the Byzantine robustness of clustered federated learning[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ: IEEE Press, 2020: 8861-8865.
[18]Li Suyi, Cheng Yong, Wang Wei, et al. Learning to detect malicious clients for robust federated learning[EB/OL]. (2020-02-01) . https://arxiv.org/pdf/2002.00211.pdf.
[19]Gu Zhipin, Yang Yuexiang. Detecting malicious model updates from federated learning on conditional variational autoencoder[C]//Proc of IEEE International Parallel and Distributed Processing Symposium. Piscataway, NJ: IEEE Press, 2021: 671-680.
[20]McMahan H B, Moore E, Ramage D, et al. Federated learning of deep networks using model averaging[EB/OL]. (2016-02-17) . https://arxiv.org/pdf/1602.05629.pdf.
[21]Konecˇny J, McMahan H B, Ramage D, et al. Federated optimization: distributed machine learning for on-device intelligence[EB/OL]. (2016-10-08) . https://arxiv.org/pdf/1610.02527.pdf.
[22]Feng Siwei, Yu Han. Multi-participant multi-class vertical federated learning[EB/OL]. (2020-01-30) . https://arxiv.org/pdf/2001.11154.pdf.
[23]Kingma D P, Welling M. Auto-encoding variational Bayes[EB/OL]. (2022-12-10) . https://arxiv.org/pdf/1312.6114.pdf.
[24]An J, Cho S. Variational autoencoder based anomaly detection using reconstruction probability[J]. Special Lecture on IE, 2015, 2(1): 1-18.
[25]Higgins I, Matthey L, Pal A, et al. β-VAE: learning basic visual concepts with a constrained variational framework[EB/OL]. (2022-07-22). https://openreview. net/forum?id=Sy2fzU9gl.
[26]Burgess C P, Higgins I, Pal A, et al. Understanding disentangling in β-VAE[EB/OL]. (2018-04-10) . https://arxiv.org/pdf/1804.03599.pdf.
[27]Sikka H D. A deeper look at the unsupervised learning of disentangled representations in β-VAE from the perspective of core object recognition[D]. Cambridge, MA: Harvard University, 2020.
[28]LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[29]Caldas S, Duddu S M K, Wu P, et al. Leaf: a benchmark for federated settings[EB/OL]. (2019-12-09) . https://arxiv.org/pdf/1812.01097.pdf.
[30]Shakespeare W. The complete works[M]. 1836.
