
基于强化学习选择策略的路径覆盖测试数据生成算法
2024-08-15 00:00:00刘超丁蕊朱雨寒
计算机应用研究 2024年8期







摘 要:面向路径覆盖的测试是软件测试的重要方法之一。如何快速生成高质量测试数据使其满足路径覆盖要求,一直是研究热点问题。为解决现有智能优化方法运行时间长、探索过程不稳定以及生成测试用例冗余的问题,提出一种基于强化学习思想的选择策略,用于以路径覆盖为准则的测试数据生成中。通过将可执行路径定义为智能体状态,算法每一轮迭代更新后的数据选择定义为智能体动作,并将奖励函数与状态变化关联,在状态更新过程中使用贪心策略来引导输入数据不断向未获取状态变异更新,以此不断选择能够覆盖新可执行路径的数据,从而实现对待测程序所有执行路径覆盖的目标。实验结果表明,与其他算法相比,所提策略的运行时间和迭代次数明显降低,同时覆盖率快速提高。结合理论分析可以得出结论:所提策略在实际运用中能够有效实现路径覆盖并提高测试数据生成效率。
关键词:测试数据生成; 路径覆盖; 强化学习; 选择策略
中图分类号:TP311 文献标志码:A
文章编号:1001-3695(2024)08-031-2467-07
doi:10.19734/j.issn.1001-3695.2023.11.0592
Algorithm for path coverage test data generation based onreinforcement learning selection strategy
Liu Chaoa, Ding Ruib, Zhu Yuhana
(a.School of Mathematics & Science, b.School of Computing & Information Technology,Mudanjiang Normal University, Mudanjiang Heilongjiang 157000, China)
Abstract:Path-coverage oriented testing is a crucial method in software testing, and the rapid generation of high-quality test data to satisfy path coverage requirements has been a persistent research challenge. To address issues such as long running times, unstable exploration processes, and the generation of redundant test cases in existing intelligent optimization methods, this paper proposed a selection strategy based on the reinforcement learning paradigm applied to test data generation with path coverage as the criterion. By defining executable paths as the state of the intelligent agent, it defined the data selection after each iteration update as the agent’s action. It associated the reward function with state changes, and employed a greedy strategy during the state update process to guide input data towards continuous variations in unexplored states. This iterative selection process aimed to continuously choose data that covered new executable paths, thereby achieving the goal of covering all execution paths of the target program. Experimental results demonstrate that compared to other algorithms, the proposed strategy significantly reduces running times and iteration counts while achieving notable improvements in coverage. Theoretical ana-lysis supports the conclusion that the proposed strategy effectively realizes path coverage and enhances the efficiency of test data generation in practical applications.
Key words:test data generation; path coverage; reinforcement learning; selection strategy
0 引言
软件测试是保障软件质量的重要方法。其对软件进行大量的测试,用来发现软件中可能存在的缺陷和错误[1]。当下对软件行业的统计结果显示,关乎软件测试的花费成本很高,往往能占整个项目开发的一半[2]。而软件测试的核心在于生成有效的测试数据,用来满足规定的测试充分性准则。因此,如何高效地生成测试数据,就具有重要的现实意义和经济价值[3]。
面向覆盖的测试数据生成方法通过覆盖待测软件的需要满足测试要求,是经典的测试数据生成方法。路径覆盖作为面向覆盖的最基本充分性准则之一,其要求选取足够多的测试数据,使待测程序的每条可达路径都至少执行一次。可以将问题描述为:对于给定程序的目标路径,需要在程序的输入空间里寻找或生成能够覆盖目标路径的测试数据[4]。
对于测试数据生成,传统优化算法方面,Goschen等人[5]利用遗传规划方法来进行自动化软件测试,动态地生成输入值来探索给定软件的输入域,从而实现更好的路径覆盖。Sun等人[6]将分布式代理引导进化优化与测试用例生成相结合,以提高程序中路径覆盖测试的测试用例生成效率。Zhang等人[7]提出覆盖引导的模糊测试生成测试数据,以此来检测软件运行中的缺陷和故障。Potluri等人[8]提出了一种混合群智能方法,将粒子群、蜜蜂群和萤火虫、布谷鸟算法结合,以优化测试覆盖率,从而高效地生成测试数据。Damia等人[9]提出基于群的遗传算法,采用全新的适应度函数来更新种群,实现测试数据的生成。丁蕊等人[10]提出关键点路径表示法来计算理论路径的数目,从覆盖难易程度上对路径进行分类,并使用遗传算法来生成难覆盖路径的测试数据。钱忠胜等人[11]提出一种结合关键点与路径相似度的多种群多覆盖策略,来提高测试数据生成效率。Kumar等人[12]针对测试数据自动生成问题,提出了一种蚁群优化负选择算法,对生成的数据进行细化,以此来提高测试数据质量。虽然传统的优化算法能够有效地生成测试数据,但是其受搜索能力以及更新速度等因素限制,容易陷入过早收敛,并且由于其缺乏并行性,在大规模路径覆盖或者复杂程序的测试数据生成问题中,存在计算时间过长、生成测试数据效率不高的问题。
在测试数据生成问题中,执行路径受到输入数据、内部结构变化等因素影响,构成了一个动态的环境。同时,路径覆盖问题中需要探索全局最优解,测试数据的生成要考虑长期目标,而不是局部最优解,这些都需要在高维度的决策空间中进行搜索。强化学习[24]作为利用智能体与环境的交互进行学习以达成回报最大化或实现特定目标的方法,在面向复杂程序的测试时,以动态环境为基础,通过奖励函数,在动态环境中展现出比其他智能优化算法更好的环境适应性和灵活性。同时,强化学习具有一个长期的奖励导向功能,能够高效地处理高维度的决策问题,与其他智能优化算法相比,能够更好地探索全局最优解,不易陷入局部最优。
在强化学习方面,曹静[13]提出一种基于强化学习的智能化测试用例生成方法,通过强化学习模型建立测试智能体Xbot,将测试用例生成问题转换为多步决策优化问题,以此来快速生成测试用例。Spieker等人[14]使用一种基于强化学习的方法Retecs,其根据数据持续时间、上次执行时间和失败历史来选择测试用例,提供了一种更轻量级的学习方法,证明了强化学习能够在持续集成和回归测试中进行有效的自动化自适应测试用例选择。Esnaashari等人[15]提出一种模因算法,将强化学习作为遗传算法中的一种局部搜索方法,以此来提高测试数据生成速度。Reddy等人[16]提出一种基于表格策略的强化学习方法RLCheck,将随机选择问题形式化成多样化引导问题,通过RLCheck方法生成有效的测试数据。Cˇegiň等人[17]提出一种基于强化学习的测试数据生成方法,通过奖赏函数对每一组测试数据形成的覆盖率提供一个奖励,同时将测试函数主体添加到强化学习算法中,根据被测函数的复杂度推断个体尝试次数,再利用神经网络对奖励进行训练,以此达到路径的完全覆盖或满足给定的尝试次数。Kim等人[18]使用强化学习取代元启发式算法,将被测软件重构为强化学习环境,构建了GunPowder框架,利用深度神经网络训练一个双深度Q-Networks智能体,通过实验验证了其在分支路径覆盖上的可行性。Harries等人[19]提出一种用于功能软件测试的强化学习(RL)框架DRIVE,并提出Batch-RL方法进行Q学习,用图神经网络对状态-动作值函数进行建模,证明此框架可以用自动化的方式触发所需的软件功能,能够高效地测试具有大范围测试目标的软件。Tsai等人[20]提出了DeepRNG框架,其主要通过在框架里增加深度强化学习代理来提高软件的测试数据生成效率。王立歆[21]提出了一种基于分层强化学习的混合测试算法LCCT,采用马尔可夫决策过程作为上层控制,模糊测试方法作为决策补充来测试数据。Pan等人[22]提出了一种基于强化学习方法的Q-Testing,使用一种好奇心驱动的策略来探索被测程序,该策略利用已访问过的部分状态来引导测试转向不熟悉的程序区域。Pan等人[23]提出一种将可测性分析与强化学习相结合的方法,利用强化学习方法来大大缩减测试数据生成的时间,并提高代码覆盖率。综上,强化学习算法通过将数据生成过程转换成与环境的交互学习过程,能够避免算法陷入过早收敛。同时,智能体通过自主探索解空间,充分利用计算资源,能够提高测试数据生成的效率。但现有的强化学习算法在面对路径覆盖的测试数据生成研究中仍面临一些挑战,如探索过程不稳定、测试用例赘余等问题。
为了应对上述挑战,本文研究基于强化学习算法的路径覆盖测试数据生成方法,提出强化学习选择算法(reinforcement learning selection algorithm,RLSA),将强化学习思想融入面向路径覆盖的测试数据生成中。在测试数据生成问题中,首先以待测程序的动态环境为基础,定义智能体的状态及动作,将待测程序的可执行路径定义为状态,将每一轮更新的数据选择定义为动作,通过这种定义方式,极大地减少了无效数据的产生,降低了生成冗余测试数据的可能性;然后,将贪心策略与Q学习方法相结合,设计基于环境反馈Q值学习的贪心选择策略,用确定性的动作选择来提高智能体学习的稳定性和效率,以此避免随机性探索时可能造成的探索过程不稳定问题,实现测试数据生成的全局性;最后,利用奖励函数引导智能体在高维度的决策空间选择最优决策,使得智能体能够快速地生成覆盖所有可执行路径的数据,以此来提高算法的效率。
1 相关知识及定义
强化学习[24]是利用智能体与周围环境的感知来获取最大奖励值,并基于此来寻找最优化策略的方法过程。本文将强化学习的寻优过程应用到程序结构上,先将程序结构抽象成控制流图,再利用智能体对环境的感知交互来作出决策,最后根据决策方法不断迭代,从而实现目标。对应于软件测试数据生成问题,下面定义在强化学习中智能体学习时涉及的相关概念及条件。
1.1 控制流图
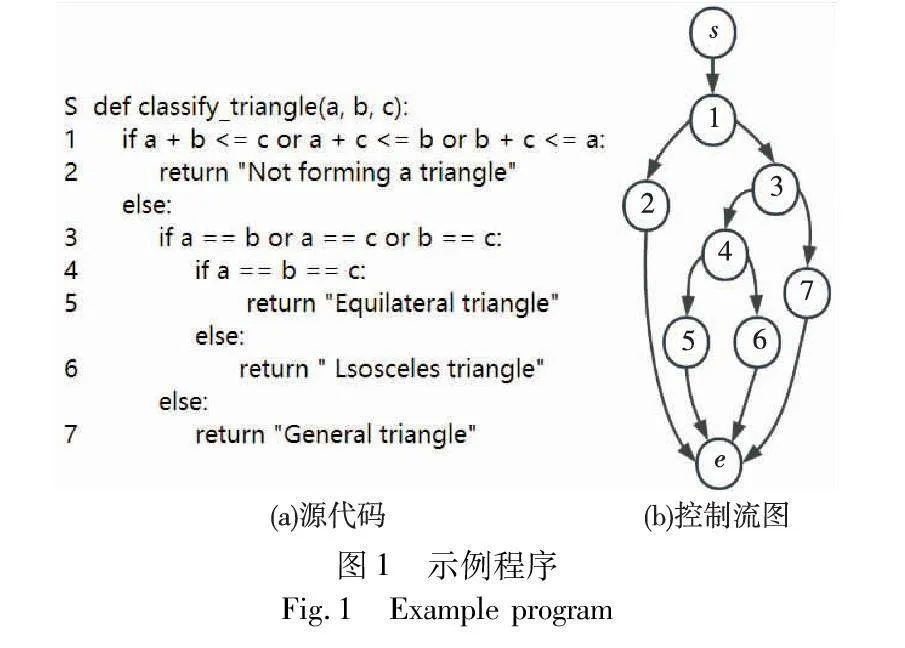
在待测程序中,控制流图是一个表示程序执行流程的有向图G=〈V,W,s,e〉,也对应着强化学习中智能体的整体学习环境。如图1所示,其中节点表示程序的基本块,边表示基本块之间的跳转关系。记V={V1,V2,…,Vn}为有向图的节点集,W={W1,W2,…,Wn}为有向图的边集,有Wjk=〈Vj,Vk〉,s和e分别为程序输入的入口和出口。以图1为例,有V={s,1,2,3,4,5,6,7,e},Ws1=〈s,1〉。
1.2 执行路径及其数目计算
执行路径是程序入口节点开始到出口节点的一条路径,其通过节点的序列进行表示,如图1中“〈s,1,3,7,e〉”就是一条由节点序列组成的执行路径。对于可执行路径的数量,利用节点、兄弟节点以及分支节点数目计算,以图1为例,其计算方式如下所示:路径数目=兄弟节点+节点×[分支节点×(分支子节点+分支子节点)+兄弟节点],M=②+③×[④×(⑤+⑥)+⑦],将所有节点代入数值1,得路径数目为4。
1.3 状态空间
对于状态空间X={x0,…,xi,…},其中每一个状态点xi都是对待测程序的一条可执行路径的描述,状态空间为所有可执行路径的集合。以图1为例,其状态空间为X={〈s,1,2,e〉,〈s,1,3,4,5,e〉,〈s,1,3,4,6,e〉,〈s,1,3,7,e〉}。
1.4 动作空间
对于动作空间A={a0,a1,a2,…,ai,…},每一个动作ai都是对新一轮更新后的数据进行选择行为的刻画。以图1程序为例,初始输入的数据为t,新一轮对输入数据t进行更新操作后产生的数据为t1,t2,t3,…,动作a0=〈t,t1〉,a1=〈t1,t2〉。例如图1中,若输入数据为(a,b,c),进行更新后产生的数据为(a1,b1,c1),(a2,b2,c2),动作a0=〈(a,b,c),(a1,b1,c1)〉,a1=〈(a,b,c),(a2,b2,c2)〉。
1.5 奖励函数
奖励函数R与测试数据所要达成的目标相关。对面向路径覆盖的测试数据来说,奖励函数影响着智能体的决策。因此需要对智能体的不同动作赋予不同的奖励值,在每一轮更新的数据中,若这些数据中能够执行之前未通过的新路径,那么给智能体一个正向奖励,否则没有奖励。具体如式(1)表示。
R=iR if data have new iR path(s)
R=0else(1)
以图1为例,若初始数据集(a,b,c)更新后的数据为(a1,b1,c1),相较初始数据集多执行了一条新路径,则更新后的数据(a1,b1,c1)获得奖励R=1。
2 基于强化学习的测试数据生成方法
本文研究利用强化学习思想提高测试数据生成效率的方法,从而快速实现待测程序的路径覆盖目标。在强化学习中,智能体是在与环境的交互中获得信息的,在基于强化学习的路径覆盖测试数据生成中,智能体需要使用策略来进行状态-动作的选择,从而生成覆盖路径的测试数据。为此,提出了一种学习策略来进行智能体的模型训练,利用确定性的状态-动作选择来加速智能体的学习过程,同时简化计算过程。
2.1 建立基于强化学习的测试数据生成模型
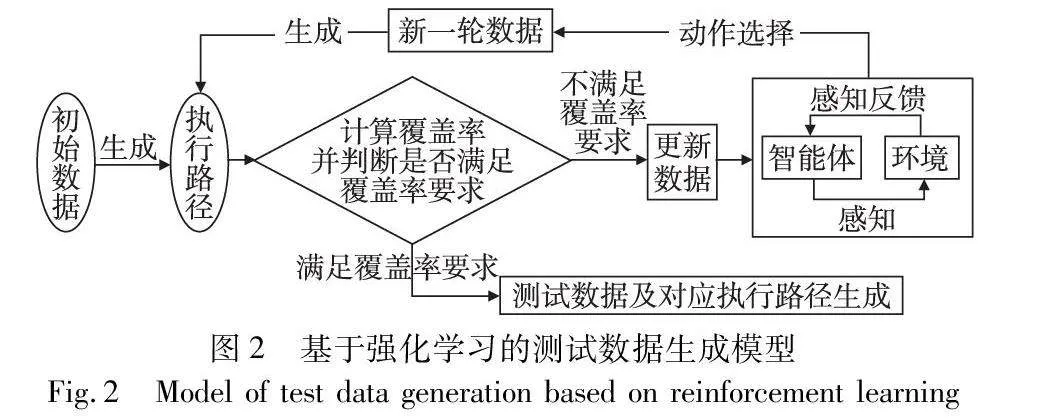
在本文提出的基于强化学习的测试数据生成模型中,首先对初始数据集中覆盖的路径进行覆盖率计算。若满足覆盖率要求,初始数据集即为满足要求的测试数据;若不满足覆盖要求,则利用强化学习方法更新数据,生成新的初始数据集。循环迭代,直到满足覆盖率要求输出数据。其具体的模型运行过程如图2所示。
本文目标是生成覆盖所有路径的数据,即生成的测试数据能覆盖待测程序的所有可执行路径。本文策略将贪心算法与Q学习算法相结合,用贪心选择替换原本探索过程中的概率选择。通过贪心算法,使得强化学习智能体更倾向于选择当前Q值最高的动作,通过累积的Q值来引导智能体决策,促使算法能够更快地收敛,并得到一组优质的测试数据。同时,贪心算法和Q学习的结合能够减少很多在概率探索过程中的不必要尝试,更有针对性地选择未覆盖的可执行路径,使得生成的测试数据更有可能覆盖未被探索的可执行路径,从而提高测试数据的质量,提高算法的运行效率,让智能体能够快速选择出优质数据,实现待测程序可执行路径的全覆盖。
具体实现思路如下:首先,通过控制流图,得到所有可执行路径的数目,同时将每一条可执行路径都定义为智能体的一种状态;然后,根据随机方法生成初始输入数据,利用智能体转换获得初始状态集合,当这个初始状态集合为状态空间X的真子集时,说明有可执行路径未被覆盖,通过变异、随机扰动等方式更新初始输入数据,并生成多组更新后的数据,以此来增加未覆盖的可执行路径选择概率;接着进行更新数据的奖励函数值设定,在这些新生成的数据中,若有数据发现了初始数据集未覆盖的执行路径,则智能体对这组数据选择赋予正向奖励值,反之无奖励值;最终,智能体将奖励值最大的数据替换为新的初始数据集,继续迭代,直到智能体的状态覆盖整个状态空间,即覆盖了待测程序的所有可执行路径。其更新以及动作选择的模型如图3所示。
2.2 基于强化学习的测试数据生成模型实现
强化学习选择策略的具体行为如下。在整个策略的具体行为上,首先通过分析待测程序控制流图结构,计算出待测程序所有的可执行路径集合P以及对应的完整状态空间X。随机生成初始数据集t0后,通过智能体转换环境信息,获得初始数据集t0当前覆盖的可执行路径p0,并得到初始状态空间X0、初始动作空间A0,并设置初始Q0值为0。接下来,对X0与X进行比较。若X0X,则说明初始数据集t0未能完全覆盖待测程序执行路径;若X0=X,则说明初始数据集t0已经完全覆盖待测程序执行路径,此时t0即为符合条件的测试用例。
下面说明在更新过程中,强化学习选择策略的具体实现:当初始数据集未能完全覆盖待测程序可执行路径时,强化学习选择策略将Q学习与贪心方法相结合来指导智能体进一步探索学习,通过对数据集ti中各重复覆盖可执行路径的数据ti,j进行m次变异、扰动操作δ,使得智能体向下探索生成新数据集为ti,jδ={ti,j1,ti,j2,…,ti,jm},由智能体动作空间A的定义,此时智能体的动作集为{ai,jk=〈ti,j,ti,jδ〉|k=1,2,…,m},同时动作空间更新为Ai+1=Ai∪{ai,jk}。再根据上述奖励函数R的定义,给予新数据集中不同数据对应的奖励值iR,通过贪心策略选择新数据集ti,jδ中具有最大奖励值的数据ti,jk,即有R(ti,j,ti,jk)=max R(ti,j,ti,jδ),同时更新状态空间Xi+1以及数据集ti+1,并生成对应的执行路径pi+1。在更新好数据集及状态空间后,再通过强化学习选择策略来更新Q值,使其不断地引导智能体决策,更新公式如下:
Qi+1=(1-α)Qi+α(iRi+γ×max Q(x,a))(2)
其中:Qi+1为新数据集ti+1的Q值;α为智能体学习效率;Qi为当前数据的Q值;iRi为所做动作的奖励;γ为折扣因子;max Q(x,a)为新状态下能获取的最大动作奖励。最后将更新后的数据ti+1作为新的数据集,重复上述过程,不断向下进行探索迭代,直到生成覆盖所有执行路径的数据并输出结果。
2.3 算法伪代码分析
算法1 强化学习选择策略
输入:随机生成的被测程序的一组测试数据。
输出:一组能够覆盖所有路径的测试数据及各测试数据对应的路径。
1 function R(olddata,newdata)
2 if newdata have new iR path(s)
3 return iR //返回奖励值
4 end if
5 return 0
6 end function
7 main RLSA(X,P)
8 t0=random(data),t0,j∈t0 //数据域中随机生成数据集
9 t0→p0 //由数据生成对应路径
10X0=Xt0,A0=At0,Q0=0
11for i=0 to N do
12 if XiX then
13 T=ti,jδ //变异、扰动生成下一代数据集
14 ai,jk=〈ti,j,T〉
15 Ai+1=Ai∪{ai,jk}
16 iRi=max R(ti,T)
17 ai,jk→ti,jk∈T|iRi //选择奖励最大的数据
18 (ai,jk,ti,jk)→xi,jk
19 Xi+1=Xi∪{xi,jk} //更新状态空间
20 ti+1=(ti\{ti,j})∪{ti,jk}
21 ti+1→pi+1
22 Qi+1=(1-α)Qi+α(iRi+γ×max Q(x,a))
23 end if
24 return datas=models(ti+1)
25 return paths=models(pi+1)
26 ; if Xi==X then
27 break
28 end if
29 end for
在上述代码中,首先定义算法的奖励函数(第1行),通过判断新数据是否涵盖新的可执行路径,以此来赋予不同的奖励值(第2~5行)。接下来,指定算法策略(第7行),随机生成初始数据集(第8行),由初始数据得到已覆盖的路径情况(第9行)、初始状态空间、动作空间以及Q值(第10行)。然后执行本文算法的循环更新过程(第12~29行)。通过比较初始数据集状态空间与整个待测程序状态空间的包含关系来判定是否生成新数据,若此时初始状态集合为待测程序状态空间集合真子集(第12行),则通过变异、扰动等方式对重复覆盖路径的数据进行更新(第13行),然后更新动作集(第14行)以及动作空间(第15行),再通过最大奖励值(第16行)进行动作选择更新数据(第17行),以及更新数据对应的状态集(第18行)和状态空间(第19行),之后更新数据集(第20行)、对应的路径(第21行)以及Q值(第22行)。最后,重复迭代上述过程,直到更新后数据集的状态空间等于待测程序状态空间或满足迭代终止条件,输出此时的测试数据(第24行)以及其对应的可执行路径(第25行)。
2.4 时间复杂度分析
本文算法每次更新Q值表时需要进行的计算量与状态数目及动作数目相关。具体来说,对于一个有n条可执行路径的程序,其状态数为n,记每一次动作选择的数目为m,其中m不超过算法设定的最大变异数。在每次更新Q值表时,需要计算所有状态下可能的动作奖励,每个动作的奖励需要进行m次计算。又由于每次训练都需要进行状态的更新,所以总的计算量为O(N(nm)),其中N表示迭代次数。
3 实验分析
为验证本文方法在路径覆盖率方面的性能和可靠性,选择随机方法(RA)、传统优化算法中的遗传算法(GA)、改进的粒子群算法(PSO)[25]、TOGA算法[26]、GPSGA算法[27]和(RLSA),以及在不同的探索率下的强化学习Q-learning算法在两个基准程序以及两个工业程序上进行实验对比,以检验本文算法是否具有更高的测试数据生成效率。本文所对比的几种算法进行测试数据生成时,在全局搜索以及在处理复杂结构方面都有较好的表现,具有较好的寻优能力。所有的程序在Python 3.8软件环境下运行,Windows 10操作系统,机器主频是2.80 GHz,内存为16 GB。通过对比实验旨在回答下面几个问题:
问题1 本文方法的数据生成效率是否优于一些现有的优化方法?
问题2 本文方法在覆盖率方面是否优于一些现有的优化方法?
问题3 贪心探索策略在本文方法中是否优于其他探索策略?
3.1 测试程序以及参数
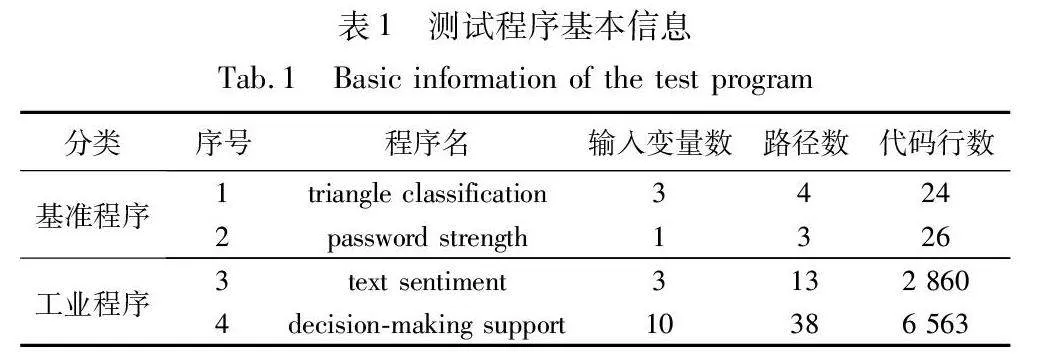
本文使用的测试程序基本信息以及相关的实验参数如表1和2所示。其中:triangle classification和password strength程序都是传统软件测试中常用的基准程序,其程序逻辑简单,可以适应多种不同的测试环境,以满足不同条件下的测试;text sentiment和decision-making support都是在现实生活中被广泛应用的工业程序,具有一定的现实场景,能够证明所提的测试策略在实际应用中的性能和可靠性。
3.2 实验结果与分析
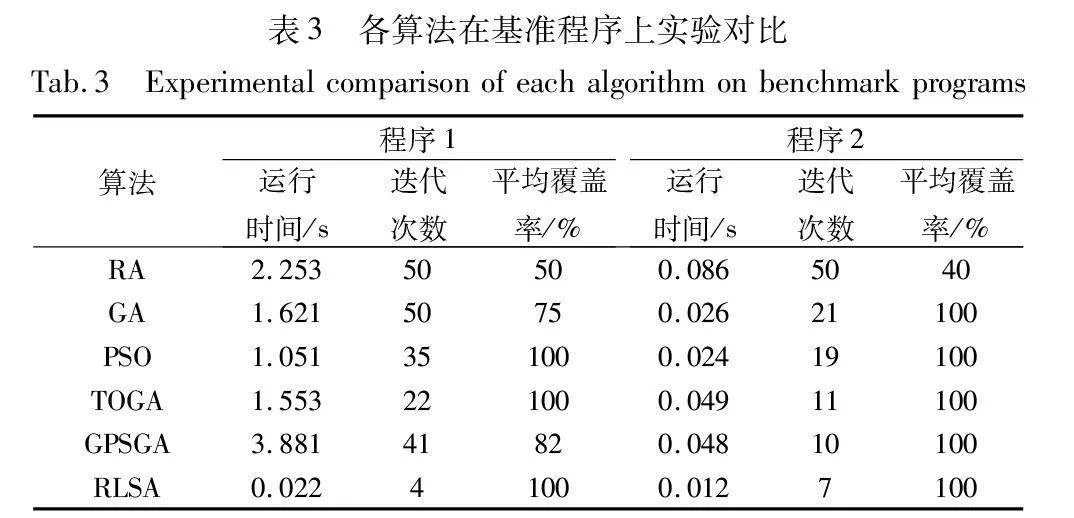
为了降低单次实验造成的结果误差,将6种算法在测试程序上运行20次,取其平均值作为对比数据。表3为6种算法在两个基准测试程序中的运行时间、迭代次数以及多次运行后平均覆盖率的结果比较。
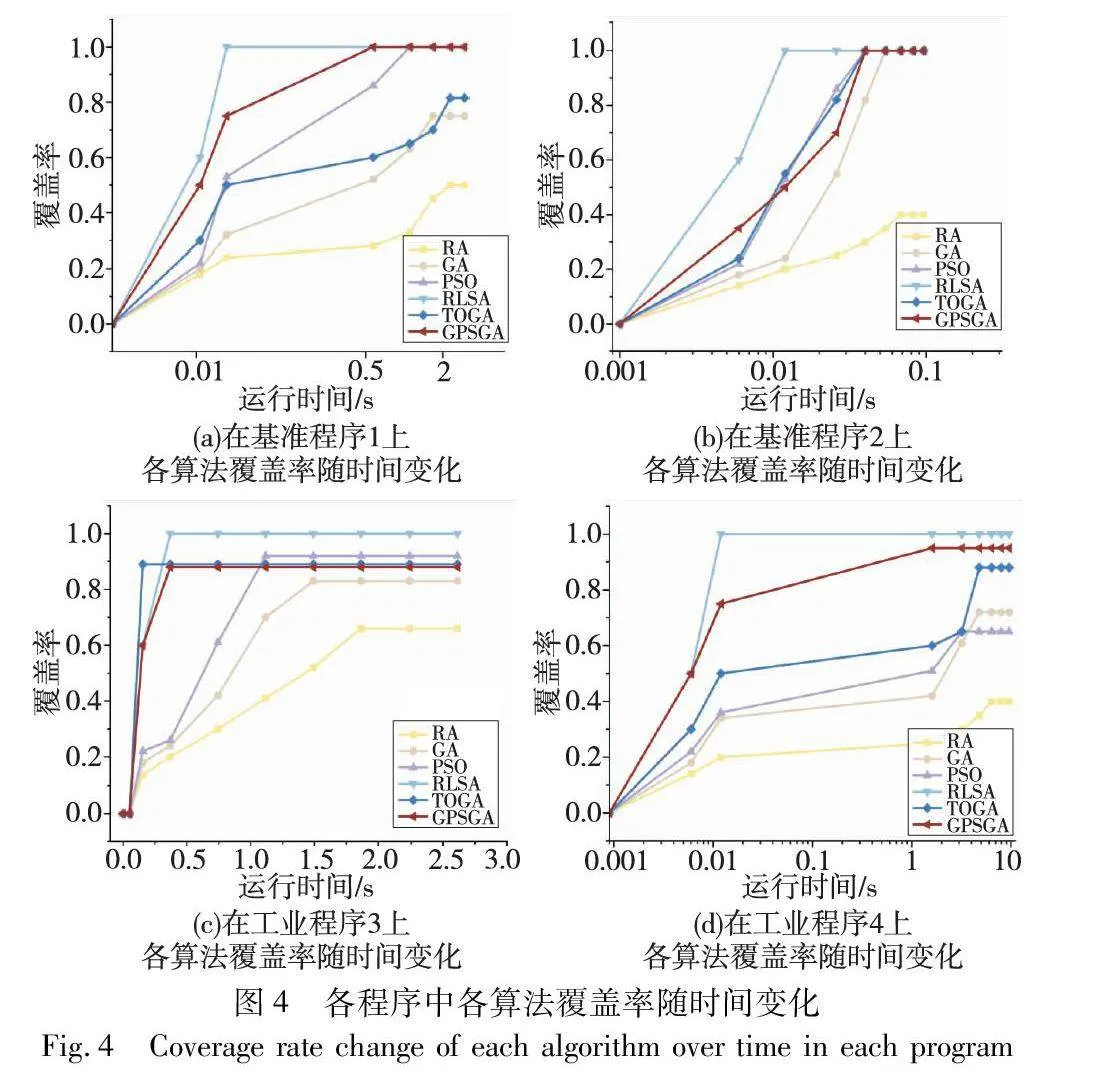
从表3中可以看出,在基准程序1中,RA的随机选择导致其运行时间最长,改进后的PSO算法凭借其较快的收敛速度使其运行时间相对较少,而RLSA运行时间少于其他所有算法,这是因为RLSA通过贪心策略进行选择,提高算法计算速度的同时,一定程度上和其他算法相比减少了选择范围;在迭代次数方面,在这两个基准程序中,RLSA算法也都远少于其他的优化算法以及随机方法,这是因为强化学习策略有较强的适应性,能够快速适应问题及环境找到最优解;在覆盖率方面,在基准程序1中,RLSA策略以及改进后的PSO、TOGA算法都能够成功找到覆盖所有可执行路径的测试数据,并且在一定程度上优于GA、GPSGA以及随机方法。这是因为它们在全局搜索方面都进行了相应的优化,都能够跳出局部最优。与此同时,RLSA策略在两个基准程序上都可以使用较少的运行时间来覆盖待测程序的可执行路径,且都具有较好的覆盖率。这是因为RLSA策略是通过将待测程序的可执行路径作为状态空间中的元素,这样能够更快地通过奖励函数的引导提高路径的覆盖率。图4表示算法在各程序中随时间变化的覆盖率。图4(a)为程序1的运行时间与覆盖率变化关系,其中RLSA策略可以最早达到100%覆盖;图(b)为程序2的运行时间与覆盖率变化关系,其中RLSA策略同样可以最早达到100%覆盖,RLSA策略相对于其余策略可以达到100%覆盖,并且运行时间最短、效率更高。
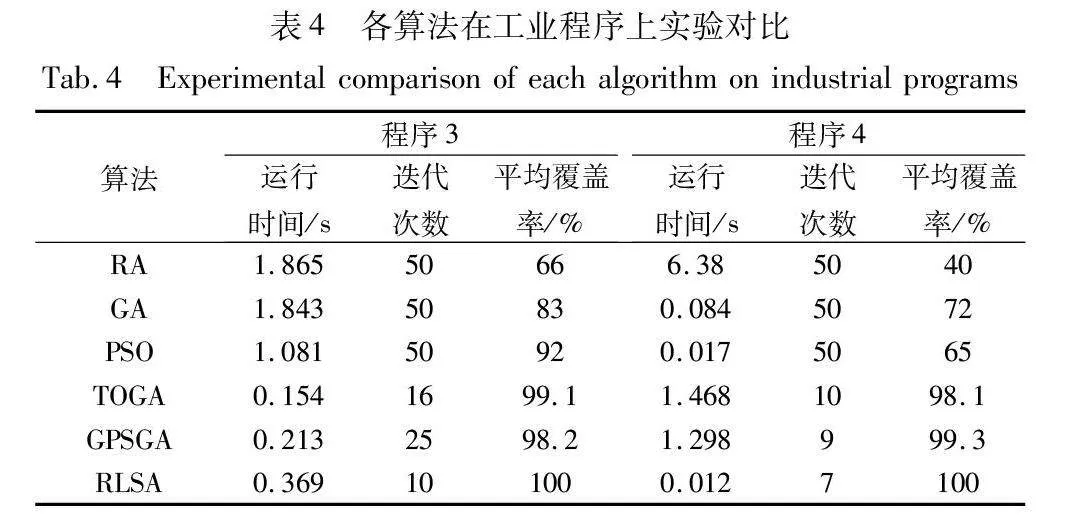
表4为6种算法在两个工业测试程序中的运行时间、迭代次数以及多次运行后平均覆盖率的结果比较。
从表4中可以看出,在text sentiment(程序3)程序的实验中,RLSA策略在运行时间上优于RA、GA和PSO算法,进一步说明强化学习选择策略在智能程序上的适用性;在迭代次数方面,RLSA也有着较好的性能,说明在数据生成方面强化学习选择策略也有较好的收敛速度;在覆盖率方面,RLSA能够成功找到覆盖所有可执行路径的测试数据,高于TOGA以及PSO算法。在decision-making support程序(程序4)实验中,在运行时间方面,RLSA远低于RA、TOGA以及GPSGA,这是因为RLSA在面对复杂结构时,能够高效地在高维度决策空间中选择最优策略;迭代次数方面,RLSA依然具有优势;在覆盖率方面,RLSA覆盖率为100%,TOGA和GPSGA也有较高的覆盖率,而其他算法覆盖率则较低,这是因为在面对复杂的程序时,其他算法在高维度空间决策方面能力较差,而TOGA策略使用反向学习提高未覆盖路径的搜索效率,GPSAG通过保留佳点集中的优秀个体来提高搜索精度,RLSA策略利用奖励函数不断引导智能体自主学习探索未知状态,增加智能体在复杂程序中的探索范围和搜索效率,以此来实现更好的路径覆盖。因此,对于工业程序,RLSA算法在覆盖率方面仍然保持着较好的性能。图4(c)为程序3的运行时间与覆盖率变化关系,其中只有RLSA策略达到100%覆盖;图(d)为程序4的运行时间与覆盖率变化关系,同样只有RLSA策略可以达到100%覆盖,其余算法都未达到100%的覆盖,说明RLSA策略在覆盖率方面显著优于其他方法。
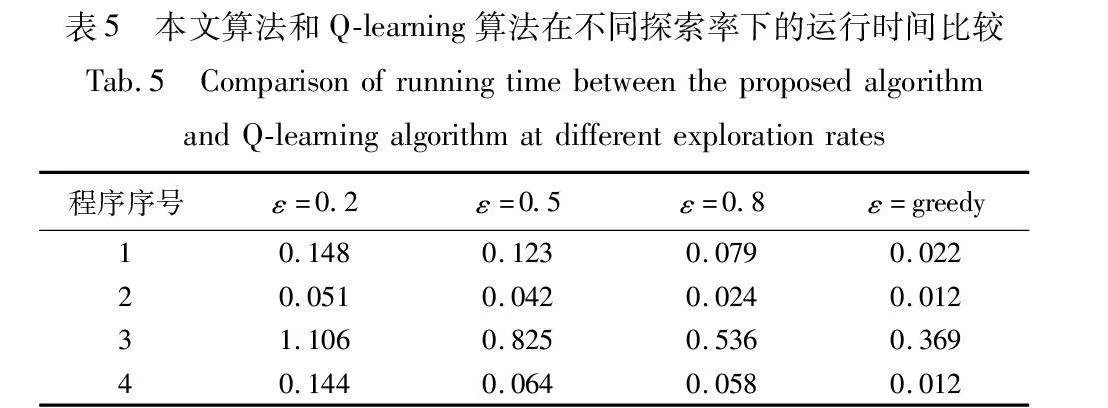
本文所提策略中使用贪心策略,相比于强化学习方法中原本的概率选择方法,生成的测试数据能够更好地覆盖此前未覆盖的可执行路径,较好地提高测试数据的生成效率。表5为强化学习选择策略和其他使用不同探索率的强化学习Q-learning算法在运行4种待测程序后的运行时间比较。
从表5中可以看出,对于面向路径覆盖的测试数据生成问题,强化学习算法探索率ε和被测程序的运行时间呈正相关。而本文贪心策略能够实现最高的探索率,使得强化学习选择策略能够实现最短的运行时间。这是由于可执行路径的确定,在RLSA中,将可执行路径作为动作的选择,每一次动作更新都是对未被覆盖路径的选择,每一次智能体向前探索时,都会优先选择未被探索的可执行路径,以此来极大地缩短运行时间,而概率选择方法缺少搜索精度,效率会明显低于贪心策略。图5是在不同探索率下的强化学习Q-learning算法和本文算法在待测程序上的运行时间比较。
3.3 算法稳定性分析
通过分析RLSA对以上效率、覆盖率、迭代次数影响的实验,得出RLSA算法在性能方面有较好的优势。为进一步分析RLSA策略的稳定性,将RLSA与TOGA、GPSGA等算法进行稳定性对比。由于RLSA的最大迭代次数为50,所以仅选择上述实验分析中迭代次数少于50次的算法进行稳定性对比。
下面重点分析RLSA、GPSGA、TOGA算法的稳定性。对各算法种群迭代次数进行统计分析,选取基准测试程序和工业测试程序分别对比被测程序在各算法上种群迭代次数,为避免结果的随机性,使用各算法在被测程序上执行5 000次的迭代次数数值来分析算法稳定性。迭代次数统计结果使用带有正态曲线的箱线图进行展示,箱线图用来表现一组种群迭代次数数据的离散程度,正态曲线可以展示数据的分布情况。箱线图由上至下依次表示异常值、上限、上四分位数(Q3)、中位数、下四分位数(Q1)、下限。采用上四分位数和下四分位数之差(IOR=Q3-Q4)表示统计数据的稳定性,即箱线图中箱子的高度,箱子高度越高说明数据离散程度越大,反之离散程度越小。
如图6所示,RLSA与GPSA、TOGA算法对应箱线图的中位数值明显低于其余算法的中位数值。在程序2中,RLSA策略的中位数值略低于TOGA和GPSGA,是因为强化学习思想需要有强化和学习的过程,所以RLSA策略会存在少量的迭代学习过程,而在测试程序1、3、4中,RLSA策略优势明显,均小于其余算法。从4个被测程序整体看,RLSA策略的迭代次数均保持在10代左右。
从箱线图中的IQR值来看,RLSA策略在4个测试程序中的IQR值均小于其余算法的IQR值,这说明RLSA策略的稳定性优于GPSGA和TOGA。
对比箱线图中的上四分位线,4个被测程序中,除被测程序2以外,RLSA策略均明显低于其余算法,其中被测程序4的优势不明显,其余被测程序中,RLSA策略均明显优于其余算法。从正态曲线看出,RLSA的数据分布离散程度最小,异常值较少,数据分布情况相比于其余算法较密集。总体来说,RLSA策略比传统算法和GPSGA、TOGA算法优势明显,RLSA的覆盖率、效率、稳定程度均高于其余算法。
综上,通过已得到的实验结果以及相关分析,逐一回答了之前的问题:
对于问题1:基于强化学习选择算法的测试数据生成方法能够更好地提高测试数据生成效率,因其通过合理的状态定义以及高效的选择策略,使得本文方法的测试数据生成效率优于传统的优化算法。
对于问题2:与传统的优化方法相比,基于强化学习选择算法的测试数据生成方法提高了路径覆盖率,并具有更好的稳定性。
对于问题3:与其他探索策略相比,基于贪心的探索策略在本文方法中具有更好的性能。
4 结束语
本文提出了一种基于强化学习的测试数据生成方法RLSA,通过贪心策略的强化学习方法来实现高效率的测试数据生成。同时,提出一种新的状态表示方式,并设计新的动作选择方式为强化学习策略提供指导,避免了使用强化学习方法生成测试数据时造成的大量赘余,提高了生成的测试数据的质量。实验表明,RLSA在迭代次数、运行时间以及路径覆盖率上优于现有的一些方法。
未来,将通过优化数据更新方式来进一步改善状态空间遍历情况,以期能够进一步减少智能体训练时间。同时,对于贪心策略在一些程序中可能产生的测试数据生成效率不高的问题,将继续优化智能体在探索和利用方面的性能,以此增强算法的普适性,进一步提高测试数据生的成效率。
参考文献:
[1]乔梦晴, 李琳, 王颉, 等. 基于遗传规划和集成学习的恶意软件检测[J]. 计算机应用研究, 2023, 40(3): 898-904. (Qiao Mengqing, Li Lin, Wang Jie, et al. Malware detection based on genetic programming and ensemble learning[J]. Application Research of Computers, 2023, 40(3): 898-904.)
[2]张威楠, 孟昭逸, 熊焰, 等. 基于异质信息网络的安卓虚拟化程序检测方法[J]. 计算机应用研究, 2023, 40(6): 1764-1770. (Zhang Weinan, Meng Zhaoyi, Xiong Yan, et al. Detection method of Android virtualization program based on heterogeneous information network[J]. Application Research of Computers, 2023, 40(6): 1764-1770.)
[3]Anand S, Burke E K, Chen T Y, et al. An orchestrated survey of methodologies for automated software test case generation[J]. Journal of Systems & Software, 2013, 86(8): 1978-2001.
[4]单锦辉, 姜瑛, 孙萍, 等. 软件测试研究进展[J]. 北京大学学报: 自然科学版, 2005, 41(1): 134-145. (Shan Jinhui, Jiang Ying, Sun Ping, et al. Research advances in software testing[J]. Journal of Peking University: Natural Science Edition, 2005, 41(1): 134-145.)
[5]Goschen J, Bosman A S, Gruner S, et al. Genetic Micro-programs for automated software testing with large path coverage[C]//Proc of IEEE Congress on Evolutionary Computation. Piscataway, NJ: IEEE Press, 2022: 1-8.
[6]Sun Baicai, Gong Dunwei, Yao Xiangjuan, et al. Integrating DSGEO into test case generation for path coverage of MPI programs[J]. Information and Software Technology, 2023, 153: 107068.
[7]Zhang Wenxi, Sakamoto K, Washizaki H, et al. Improving fuzzing coverage with execution path length selection[C]//Proc of IEEE International Symposium on Software Reliability Engineering Workshops. Piscataway, NJ: IEEE Press, 2022: 132-133.
[8]Potluri S, Ravindra J, Mohammad G B, et al. Optimized test cove-rage with hybrid particle swarm bee colony and firefly cuckoo search algorithms in model based software testing[C]//Proc of the 1st International Conference on Artificial Intelligence Trends and Pattern Recognition. Piscataway, NJ: IEEE Press,2022: 1-9.
[9]Damia A, Esnaashari M, Parvizimosaed M. Automatic test data ge-neration based on the prime path coverage criterion: a grouping-based GA approach[EB/OL]. (2023-04-12). https://doi.org/10.21203/rs.3.rs-2796131/v1.
[10]丁蕊, 董红斌, 张岩, 等. 基于关键点路径的快速测试用例自动生成方法[J]. 软件学报, 2016, 27(4): 814-827. (Ding Rui, Dong Hongbin, Zhang Yan, et al. Rapid test case generation method based on critical path[J]. Journal of Software, 2016, 27(4): 814-827.)
[11]钱忠胜, 祝洁, 朱懿敏. 结合关键点概率与路径相似度的多路径覆盖策略[J].软件学报,2022, 33(2): 434-454.(Qian Zhong-sheng, Zhu Jie, Zhu Yimin. Multi-path coverage strategy combining key point probability and path similarity[J]. Journal of Software, 2022, 33(2): 434-454.)
[12]Kumar G, Chopra V. Automatic test data generation for basis path testing[J]. Indian Journal of Science and Technology, 2022, 15(41): 2151-2161.
[13]曹静. 基于强化学习的Web API功能测试用例生成研究[D]. 上海:东华大学, 2021. (Cao Jing. Research on Web API functional test case generation based on reinforcement learning[D]. Shanghai: Donghua University, 2021.)
[14]Spieker H, Gotlieb A, Marijan D, et al. Reinforcement learning for automatic test case prioritization and selection in continuous integration[C]//Proc of the 26th ACM SIGSOFT International Symposium on Software Testing and Analysis. New York:ACM Press, 2017: 12-22.
[15]Esnaashari M, Damia A H. Automation of software test data generation using genetic algorithm and reinforcement learning[J]. Expert Systems with Applications, 2021, 183: 115446.
[16]Reddy S, Lemieux C, Padhye R, et al. Quickly generating diverse valid test inputs with reinforcement learning[C]//Proc of the 42nd ACM/IEEE International Conference on Software Engineering. Pisca-taway, NJ: IEEE Press, 2020: 1410-1421.
[17]Cˇegiň J, Rástocˇny K. Test data generation for MC/DC criterion using reinforcement learning[C]//Proc of IEEE International Conference on Software Testing, Verification and Validation Workshops. Pisca-taway, NJ: IEEE Press, 2020: 354-357.
[18]Kim J, Kwon M, Yoo S, et al. Generating test input with deep reinforcement learning[C]//Proc of the 11th International Workshop on Search-Based Software Testing. Piscataway, NJ: IEEE Press, 2018: 51-58.
[19]Harries L, Clarke R S, Chapman T, et al. Drift: deep reinforcement learning for functional software testing[EB/OL]. (2020-07-16). https://arxiv.org/abs/2007.08220.
[20]Tsai C Y, Taylor G W. DeepRNG: towards deep reinforcement learning-assisted generative testing of software[EB/OL]. (2022-01-29). https://arxiv.org/abs/2201.12602.
[21]王立歆. 基于分层强化学习的自动化软件测试技术研究[D]. 沈阳:辽宁大学, 2022. (Wang Lixin. Research on automated software testing technology based on hierarchical reinforcement learning[D].Shenyang: Liaoning University, 2022.)
[22]Pan Minxue, Huang An, Wang Guoxin, et al. Reinforcement lear-ning based curiosity-driven testing of Android applications[C]//Proc of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. New York:ACM Press, 2020: 153-164.
[23]Pan Zhixin, Mishra P. Automated test generation for hardware trojan detection using reinforcement learning[C]//Proc of the 26th Asia and South Pacific Design Automation Conference. Piscataway, NJ: IEEE Press, 2021: 408-413.
[24]张汝波, 顾国昌, 刘照德, 等. 强化学习理论, 算法及应用[J]. 控制理论与应用, 2000, 17(5): 637-642. (Zhang Rubo, Gu Guochang, Liu Zhaode, et al. Reinforcement learning: theory, algorithms, and applications[J]. Control Theory & Applications, 2000, 17(5): 637-642.)
[25]Jaiswal U, Prajapati A. Optimized test case generation for basis path testing using improved fitness function with PSO[C]//Proc of the 13th International Conference on Contemporary Computing. New York:ACM Press, 2021: 475-483.
[26]Cheng Mengfei, Ding Rui, Huo Tingting, et al. A hyper-heuristic algorithm for test data generation[C]//Proc of the 6th International Conference on Big Data Research. New York:ACM Press, 2022: 26-31.
[27]程孟飞, 丁蕊. 基于佳点集遗传算法的多路径覆盖测试用例生成[J]. 计算机与数字工程, 2022, 50(9): 1940-1944. (Cheng Mengfei, Ding Rui. Multi-path coverage test case generation based on optimal point set genetic algorithm[J]. Computer and Digital Engineering, 2022, 50(9): 1940-1944.)
