
融合元图邻域的知识图谱推荐模型
2024-08-15 00:00:00张彬郝利新张国防
计算机应用研究 2024年8期








摘 要:基于知识图谱的主流推荐模型在融合高阶信息时较少考虑源节点与目标节点之间的关系,在复杂网络场景中易引入过多噪声信息进而影响推荐性能。针对此问题提出一种融合元图邻域的知识图谱推荐模型,通过构建并融合元图邻域降低噪声信息的影响,提升推荐性能。首先,基于元图相似度生成源节点的初始相似序列,利用自注意力网络与线性网络对初始序列进行特征增强,以增强后的特征向量组成的集合构造节点的元图邻域。其次,基于用户对各个元图的不同偏好程度设计注意力机制,对所得元图邻域进行卷积聚合,将元图邻域融入源节点,增强源节点的特征表示。最后,以增强后的向量与用户向量的内积作为用户与项目交互的概率,并以此完成推荐。在MovieLens-20M与Last-FM数据集上进行实验,AUC与F1值分别为97.3%和83.1%、94.3%和75.6%,recall@50分别为35.4%与31.7%,其表现优于NGCF、KGCN、LKGR等模型。结果表明,融合元图邻域的知识图谱推荐模型可以有效提升推荐的性能。
关键词:个性化推荐; 知识图谱; 元图; 卷积神经网络; 注意力机制
中图分类号:TP391.3;G353.1 文献标志码:A
文章编号:1001-3695(2024)08-023-2412-07
doi:10.19734/j.issn.1001-3695.2023.12.0610
Knowledge graph recommendation model with integratedmeta-graph neighborhoods
Zhang Bin, Hao Lixin, Zhang Guofang
(School of Cybersecurity & Computer Science, Hebei University, Baoding Hebei 071000, China)
Abstract:Mainstream knowledge graph-based recommendation model rarely consider the relationship between source nodes and target nodes when fusing high-order information, leading to the introduction of too much noise information and thus affec-ting recommendation performance in complex network scenarios. To address this problem, this paper proposed a knowledge graph recommendation model with integrated meta-graph neighborhoods, with the goal of reducing the impact of noise information by constructing and integrating meta-graph neighborhoods, thereby improving recommendation performance. Firstly, the model obtained the initial similar sequence of the source node based on meta-graph similarity. Then, the model enhanced the initial sequence using self-attention networks and linear networks, which resulted in a set of enhanced feature vectors that serve as the meta-graph neighborhoods of the node. Secondly, the model designed an attention mechanism based on the user’s different preferences for each meta-graph to perform convolution and aggregation on the resulting meta-graph neighborhoods. Then, the model integrated the meta-graph neighborhoods into the source node to enhance the feature representation of the source node. Finally, the model used the inner product of the enhanced vector and the user vector as the probability of user interaction with the item, which was then utilized to complete the recommendation. Experimental results on the MovieLens-20M and Last-FM datasets show that the proposed model achieves an AUC of 97.3% and 94.3%, and F1-score of 83.1% and 75.6%, respectively. The recall@50 are 35.4% and 31.7%, respectively. These performance metrics outperform models such as NGCF, KGCN, LKGR, and other models. The results demonstrate that the knowledge graph recommendation model with integrated meta-graph neighborhoods is effective in improving recommendation performance.
Key words:recommendation model; knowledge graph; meta-graph; convolutional neural network; attention mechanism
0 引言
随着互联网技术的高速发展,人类社会进入了信息爆炸时代,同时产生了信息过载问题,个性化推荐作为一种能缓解该问题的方法,在网络服务中发挥着重要作用[1]。传统个性化推荐模型通常存在数据稀疏性和冷启动问题[2~4],利用辅助信息是解决这一问题的有效方式[5]。知识图谱能够整合利用蕴涵丰富知识的辅助信息,将知识图谱用于个性化推荐,可以有效改善推荐效果[6,7]。
在推荐系统中,用户与物品以及它们的属性可以被构建为知识图谱中的节点,用户和物品的交互可以构建为边。如在电影推荐系统中,用户、电影、用户的年龄、性别、地区等属性以及电影的导演、演员、类型等属性可以用知识图谱中的节点表示,用户与电影的交互关系以及各种属性之间的关系等可以用知识图谱中的边信息进行表示。知识图谱推荐模型一般基于嵌入[8~11]、链接关系[12~14]与传播[15~17]等方法进行研究。基于嵌入的知识图谱推荐模型通过知识图谱表示学习方法[18]对知识图谱数据进行预处理,将节点和关系映射到低维向量表示,再将得到的向量应用到各种模型中进行推荐。基于链接关系的知识图谱推荐模型通过挖掘知识图谱中的关系路径信息计算节点相似性来进行推荐。这两种方法都利用知识图谱对传统推荐系统进行了改进,提高了推荐性能,但是对知识图谱的信息利用不够充分。其中,基于嵌入的推荐模型主要学习图谱中的语义表示,很少利用知识图谱中的路径信息;基于链接关系的推荐模型重点关注图谱中节点之间的链接关系,忽略了节点本身的属性信息[19,20]。为充分利用知识图谱中的辅助信息,有学者提出了基于传播的知识图谱推荐模型。此类模型引入向量来表示节点与关系,同时充分利用实体间的链接关系,通过融合邻域节点来丰富自身的向量表示以提升推荐性能。
知识图谱中实体的邻域节点数量众多,且随着跳数的增加呈指数型增长,因此在复杂网络场景中较难有效利用所有的邻域节点信息[21]。现有基于传播的知识图谱推荐模型多采用从邻域中选取若干节点进行融合的方式[22],但在选取邻域节点时较少考虑源节点与目标节点之间的关系,当所选目标节点与源节点之间的语义关系不紧密时,会融入过多的噪声信息,降低源节点语义表示的准确性,进而影响模型性能[23]。
基于元路径的节点相似度是衡量知识图谱中两节点之间关系密切度的一种有效方法[24],因此通过计算基于元路径的节点相似度,筛选与源节点更为密切的节点进行融合,可以有效降低噪声信息的影响。但元路径表示复杂语义的能力较差,无法充分利用知识图谱中丰富的语义信息。元图[14]是定义在知识图谱中具有单一源节点和单一目标节点的有向无环图。相较于只能表示单一路径信息的元路径,它可以表示更为复杂的语义信息,提高对知识图谱所蕴涵信息的利用程度。因此,本文提出了一种融合元图邻域的知识图谱推荐模型,通过计算基于元图的相似度来衡量源节点与目标节点的相关程度,筛选相关度更高的节点构建元图邻域并进行融合,它能有效过滤纷杂的噪声信息,提升了推荐模型的准确度。
1 相关工作
知识图谱能够整合多源异构信息,将丰富的实体关系融合到一个复杂网络,进而发现并计算用户节点和项目节点之间的细粒度关系。相比传统推荐系统,基于知识图谱的推荐系统能够通过图谱内的语义关系和项目链接等信息来挖掘用户与项目之间的潜在关联,实现更加精准的推荐。
1.1 基于嵌入的知识图谱推荐模型
基于嵌入的方法通常通过知识图谱表示学习方法,将知识图谱中的实体节点和关系表示为低维的嵌入向量,再利用得到的向量进行推荐计算。对知识图谱嵌入的典型方法有TransR、TransH等翻译距离模型,其思想是在不同的关系空间刻画头实体和尾实体,存储表达知识图谱结构信息。Zhang等人[8]在TransR的基础上提出了一种基于嵌入的协同过滤模型(collaborative knowledge base embedding,CKE),将知识图谱中的物品进行结构化知识编码,结合文本、图片等特征扩充物品的语义向量。Wang等人[9]利用知识图谱嵌入方法设计了一种端到端的多任务学习框架(multi-task feature learning approach for knowledge graph enhanced recommendation,MKR),该方法通过交叉压缩模块将推荐模块和知识图谱嵌入模块相关联,共享模块中潜在的特征,学习实体间的高阶交互,以完成对用户的推荐。基于嵌入的方法更关注图谱中的语义关系等方面的显式知识,对实体间的多跳关系利用较少,因而在处理复杂关系的推荐任务时会使性能受到限制。
1.2 基于链接关系的知识图谱推荐模型
基于链接关系的方法的基本思想是利用路径的相关算法挖掘用户或者项目之间的语义相似性来增强推荐效果。Yu等人[13]提出了一种具有实体相似性正则化的协同过滤模型(collaborative filtering with entity similarity regularization in heterogeneous information network,Hete-MF),该模型利用包含用户评分和其他相关异构信息构成的知识图谱构建基于矩阵分解[25]的推荐框架。Hete-MF模型使用元路径定义网络模式中实体类型之间的路径,沿着不同元路径发现不同元路径项目之间的相似性,再根据相似性构建相似度矩阵,利用矩阵分解模型进行推荐。针对Hete-MF模型基于元路径的推荐方法只能利用单一路径信息无法挖掘知识图谱复杂语义信息的问题,Zhao等人[14]提出了一种基于元图的异构信息网络推荐融合模型(meta-graph based recommendation fusion over heterogeneous information network,FMG)。FMG模型根据元图获取用户和项目之间的相似度,利用无监督的矩阵分解技术获得用户和项目的潜在向量,最后使用因子分解机技术[26]对从不同相似性矩阵中分解得到的用户项目向量进行融合,利用融合后的用户和项目向量进行推荐。这种由多个元路径组成的元图,可以更充分地挖掘知识图谱中的复杂语义,信息提高推荐系统的性能。使用路径的方式充分且直观地利用了知识图谱的网络结构,但是忽略了用户以及项目自身的语义信息,未能充分利用知识图谱中的语义信息。
1.3 基于传播的知识图谱推荐模型
由于基于嵌入的方法无法利用知识图谱中的结构信息,而基于链接关系的方法忽略了用户及项目自身的特征,有研究者考虑到单一方法的局限性,开始利用基于嵌入与链接关系结合的传播方法进行研究。RippleNet模型[16]是首个基于传播的知识图谱推荐模型,其通过偏好结果进行图嵌入学习,将用户的历史交互项视为知识图谱中三元组的一个种子集合,并沿着知识图谱的链接进行迭代扩展,发现用户的低阶及高阶偏好,以此改善模型性能。Wang等人[17]受到图卷积网络的启发,提出了知识图谱卷积网络推荐模型(knowledge graph convolutional network for recommender system,KGCN)。KGCN设计了一种注意力机制[27]用于描述关系对用户的重要性得分,为给定的用户识别重要关系信息。随后,在项目的邻域实体中采用随机采样的方式选取若干实体。最后,结合得到的权重和选取的邻域实体进行聚合,计算项目节点的嵌入表示进行推荐。黄偲偲等人[28]受传播思想启发,提出了一种结合知识图谱传播特征和提示学习范式的推荐方法,将用户和物品的历史交互作为用户偏好传播的起点,利用知识图谱中的显式知识,逐层向外扩散用户兴趣,建模用户的动态行为信息,以实现对用户的推荐。
基于传播的方法虽然相较于嵌入和链接的方法有了较大的改善,但其在融合知识图谱中的高阶信息时,会因为融入噪声信息使模型性能受限。而元图可以显示建模多跳结构中两节点间的关系,通过基于元图的相似度算法计算相似度,可以筛选语义关系密切的节点。因此利用元图构建邻域,并以元图邻域作为高阶邻域进行融合,可以降低噪声信息的影响,提高模型性能。
2 融合元图邻域的知识图谱推荐模型
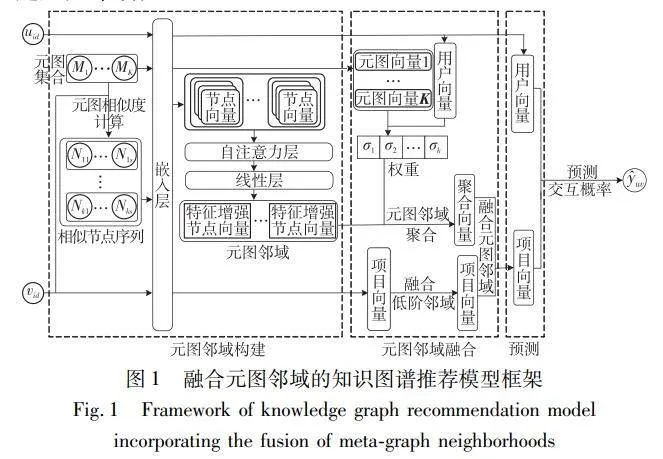
融合元图邻域的知识图谱推荐模型(knowledge graph re-commendation model with integrated meta-graph neighborhoods,IMGN)的框架如图1所示。首先,构建源节点的元图邻域,基于元图相似度得到源节点在各元图条件下的初始相似节点序列,利用自注意力网络与线性网络对初始相似节点序列进行特征增强,以增强后的相似向量构成的集合作为节点的元图邻域。其次,利用卷积神经网络对元图邻域进行聚合,并且在聚合时利用注意力机制捕捉不同用户对不同元图的偏好,将聚合后的向量融入节点向量以增强节点的特征表示。最后,把增强后的节点向量与用户向量的内积作为用户与项目交互的概率,并以此完成推荐。
2.1 基于元图的邻域构建
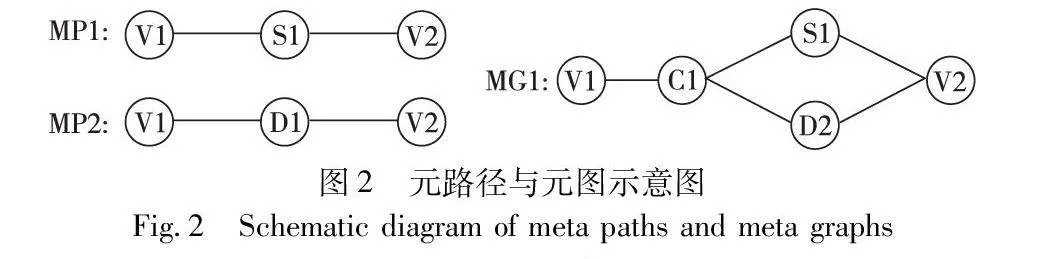
在知识图谱中,元路径是指连接两个节点之间的关系序列,通过元路径可以显示建模节点之间的语义关系。如图2所示,两部电影可以通过两个元路径连接:电影→明星→电影(VSV)和电影→导演→电影(VDV)。两条元路径表示不同的语义信息,VSV表示两部电影有同一个明星出演,VDV表示两部电影有共同的导演。但元路径在表达复杂语义上会受到限制,如元路径不能表示两部电影既有同一个明星,也有同一个导演。因此本文使用元图来挖掘知识图谱中的复杂语义信息。元图[14]是具有单一源节点与目标节点的有向无环图,在知识图谱G=(N,E)中,可以定义一个元图MG=(NM,EM,ns,nt),其中,NMN,EME,ns为源节点,nt为目标节点。如图2所示,元图可以表示两部电影既有同一个明星,也有同一个导演,相较于元路径而言可以表示更复杂的语义信息。因此本文通过计算两节点基于元图的相似度衡量节点之间的关联程度,筛选与源节点关系密切的节点作为初始相似序列,再以自注意力网络对初始相似序列进行语义增强,利用增强后的相似序列构建元图邻域。
2.1.1 基于元图的节点相似度计算
在知识图谱中,两节点之间基于元图的相似度可以通过PathSim算法[24]进行计算。首先通过邻接矩阵计算两节点间基于元图的路径数量,再以源节点到目标节点的路径数量与源节点和目标节点到自身的路径数量之和的比值作为相似度。基于元路径的路径数量通常以邻接矩阵乘积的方式进行计算,在元图网络结构中,源节点和目标节点之间通常由多个分段路径连接而成,分段路径是单一通路即为元路径,分段路径包括多个可达通路即为多路径。图2的元图MG1中,V1→C1部分属于元路径部分,C1→S1→V2与C1→D1→V2属于多路径。因此基于元图的路径数量如下所示:
C=Wvw·Cs(1)
其中:C为基于某个元图的路径数量矩阵,矩阵的行为源节点类型的各个节点,列为目标节点类型的各个节点,矩阵元素cij表示在此元图条件下源节点类型中第i个节点到目标节点类型中的第j个节点之间的路径总数;Wvw表示元图中属于单条元路径部分的路径数量矩阵;CS表示元图中多条路径部分的路径数量矩阵。
Wvw可直接利用两种相邻类型节点之间的计数矩阵相乘[14]。如在路径P=(A1,A2,…,AL)中:
CP=WA1,A2·WA2,A3·…·WAL-1,AL(2)
其中:WAlAl+1为相邻节点类型Al到Al+1的邻接矩阵,定义为
(WAl,Al+1)ij=1 节点Al与Al+1间有连边0 节点Al与Al+1间无连边(3)
CS部分可视为由多个单条路径构成。由于元图表示的语义需同时满足多种条件,所以在元图中节点之间联通的条件为满足所有的路径。故以构成这部分的所有单条路径的哈达玛积表示此部分路径数量:
Cs=∏ Cpi(4)
根据式(1)得到的路径数量矩阵,以源节点到目标节点的路径数量与源节点和目标节点到自身的路径数量之和的比值作为相似度。相似度表示为
s(xi,xj)=2CijCii+Cjj(5)
其中:xi为源节点类型的节点;xj为目标节点类型的节点;s(xi,xj)为两节点之间的相似度。
2.1.2 基于节点相似度与自注意力机制的元图邻域构建
对于源节点i,通过上述相似度计算方法计算源节点与符合元图目标节点类型的节点之间的相似度。设H为知识图谱中某元图M的目标节点类型的节点集合。利用上述相似度计算方法分别计算i与H中每个节点的相似度:
s(i,v1),s(i,v2),…,s(i,vn) vi∈E,i=1,2,…,n
按相似性高低排序,可得到节点i基于元图M的前k个相似节点:
vs1,vs2,…,vsk
由于同一节点在不同元图中侧重的语义不同,与根据元图得到的节点序列中的其他节点有密切关系,如周星驰在序列(周星驰、刘镇伟)中侧重导演的特征,而在序列(周星驰、吴孟达)中侧重演员的特征,故本文采用自注意力机制[29]对上述得到的初始相似序列进行特征增强。以上述k个节点的向量表示作为行构成的矩阵作为原始查询矩阵V,经过线性变换后得到查询Qs、键Ks、值Vs矩阵:
Qs=VWQ,Ks=VWK,Vs=VWV(6)
其中:W为线性变换矩阵的参数。计算查询矩阵与键矩阵转置的乘积,得到初始权重表示矩阵:
E=QsKTs(7)
其中:E为初始权重矩阵;Eij表示序列中节点vi在融合节点vj时的初始权重。对上述初始权重矩阵进行softmax归一化:
Z=softmax(Edk)(8)
其中:Z为归一化后的权重矩阵。之后用权重矩阵和值矩阵相乘:
Vs′=Z·Vs(9)
其中:Vs′即为原节点序列中的节点向量表示在以归一化后的自注意力权重的基础上,融合了序列中其他节点之后的向量表示构成的矩阵,融合后的向量增强了其属于此元图的语义特征。再以一层全连接神经网络将这k个节点融合为一个,记为vmh,即为节点i在元图M条件下的相似向量:
vMi=(w·V′s+b)(10)
知识图谱网络模式是指利用知识图谱中的节点类型与关系类型表示的图结构,从网络模式中抽取相应的节点与关系序列即可作为元图。以节点i的节点类型作为源节点与目标节点从网络模式中抽取相关的L个元图,记作M1,M2,…,ML,在这L个元图条件下,根据上述计算方式可得到节点i的L个相似向量v1i,v2i,…,vLi,分别表示在不同元图下节点i的相似节点。由此可得源节点i的元图邻域为
NBi={v1i,v2i,…,vLi}(11)
2.2 基于卷积神经网络的元图邻域融合
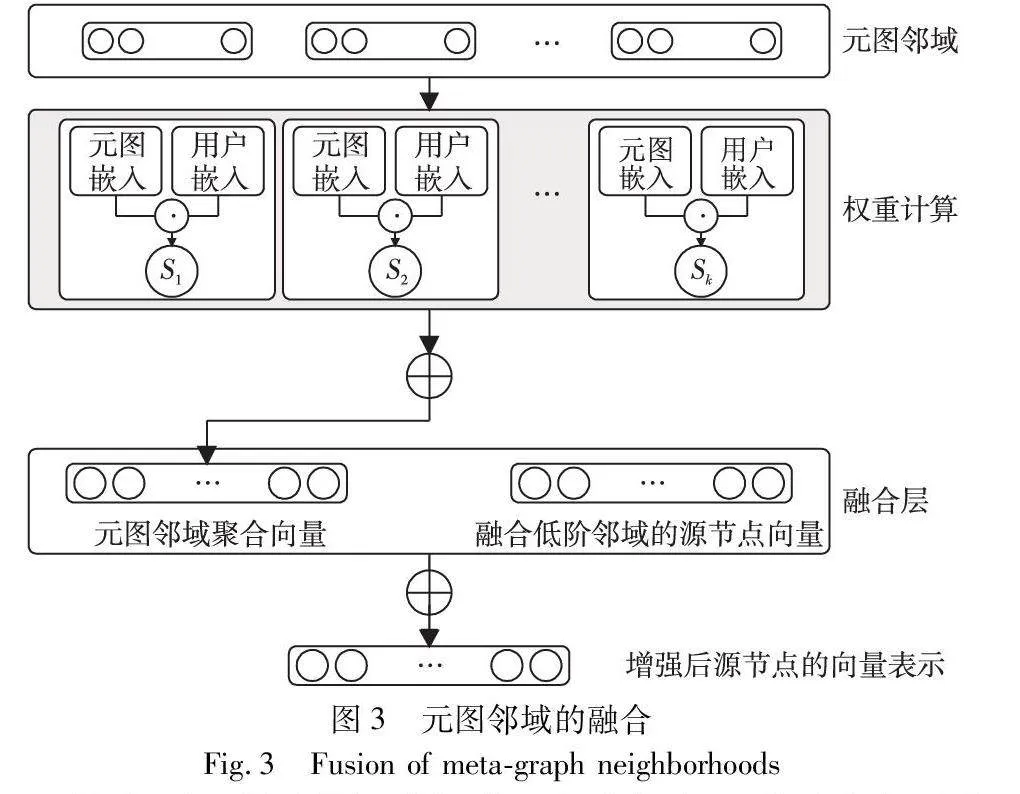
将邻域节点聚合后与源节点进行融合可以更好地表示源节点的特征,获得更多的上下文信息,提高推荐模型的准确性[30]。低阶邻域是与源节点直接相邻的节点构成的邻域,包含一些局部的、比较简单的关系模式,能够提供节点的局部上下文信息,有助于模型捕捉到节点的细粒度特征。元图邻域包含了高层次的语义信息,能够挖掘源节点与高阶节点之间的复杂关系模式,能更好地捕获全局特征。融合低阶邻域和元图邻域可以综合利用不同层次、不同类型的关系模式,从而提升模型的性能。对元图邻域的卷积融合如图3所示。通过卷积神经网络对元图邻域进行卷积聚合,再以聚合后的向量与融合了低阶邻域的源节点向量进行融合增强源节点的语义表示。
首先,对源节点的低阶邻域进行聚合,将源节点的向量表示与聚合后的向量进行融合,获得融合低阶邻域的源节点向量,公式如下:
i=sigmoid(w1×(vi+vnbi)+b1)(12)
其中:i为融合源节点向量与低阶邻域聚合向量后的向量表示;w1为权重系数矩阵;vi为源节点的向量表示;vnbi为源节点的低阶邻域通过卷积神经网络聚合后的向量表示;sigmoid为非线性激活函数;b1为偏置向量。
其次,对元图邻域进行卷积聚合。在卷积过程中由于不同用户对表示不同关系的元图偏好程度不同,如用户A和B喜欢同一部电影,可能A用户喜欢这部电影是因为这部电影是他喜欢的导演的作品,而B用户喜欢这部电影是因为这部电影有他喜欢的演员,需要设计一种注意力机制[31]以区分不同用户对不同元图的喜好程度。以atten(ua,mj)=ua·mj表示用户a对元图j的偏好得分,表示用户对某个元图的偏好程度。其中,ua是用户a的特征向量表示,mj是元图j的向量表示。将用户对不同元图的评分进行归一化表示为
aten(ua,mj)=softmax(atten(ua,mj))=exp(atten(ua,mj))∑mn∈N(x)exp(atten(ua,mn))(13)
其中:aten(ua,mj)表示经过softmax归一化后的用户a对元图j的偏好得分;N(x)是元图表示向量的集合x∈(1,2,…,L)。
以归一化后用户对某条元图的评分为权重对元图邻域表示v1i,v2i,…,vLi进行聚合操作。得到的邻域聚合向量如下:
s(ua,vi)=∑vji∈NBiaten(ua,mj)·vji(14)
其中:s(ua,vi)为以用户a对不同元图的偏好得分为权重,聚合源节点vi的元图邻域所得的聚合向量;NBi为源节点vi的元图邻域;vji为邻域中的向量表示。
最后,将所得的聚合向量与融合低阶邻域初步增强后的源节点向量融合得到进一步增强的节点向量表示,融合方式如下:
vuai=sigmoid(w2·(i+s(ua,vi))+b2)(15)
其中:vuai为源节点vi融合自身与基于用户ua对不同元图的偏好得到的元图邻域聚合向量后的向量表示;sigmoid是非线性激活函数;w2是权重矩阵;i为节点融合知识图谱低阶邻域后的向量表示;b2是偏置向量。通过上述卷积融合,实体的最终表示依赖于源节点自身、知识图谱中的低阶邻域以及元图邻域。由于融合了知识图谱中丰富的语义知识,其表示更加准确。根据上述步骤可得源节点最终的表示:
vuai=sigmoid(w2×(sigmoid(w1×(vi+vnbi)+b1)+s(ua,vi))+b2)(16)
2.3 基于融合后向量的推荐
通过融合元图邻域聚合向量得到语义增强后源节点的向量表示,该向量可用来预测用户与项目之间的交互概率。在矩阵分解算法中,用户向量ui和项目向量vj的内积可以近似于rij,rij为用户与项目vj的交互概率。
rij≈ui·vj(17)
因此,利用上述融合了元图邻域的节点向量的内积来表示用户对项目的预测交互概率。
ui=pred(ui,vj)=ui·vj(18)
损失函数是真实交互行为和预测交互概率之间的平方误差,是算法的最小化目标,定义为
L(θ)=∑rui∈R(ui-rri)2+λ‖θ‖2(19)
其中:rui是实际是否交互,超参数λ防止过拟合,通过控制L2正则化的强度来实现,θ是要训练的参数集。采用随机梯度下降法来最小化损失函数。首先通过求参数的偏导数找到最速下降方向,然后通过迭代法不断地优化参数。利用训练完成的模型得到用户对各个项目的预测交互概率,根据交互概率进行推荐。
3 实验
为了验证所提出模型的推荐效果,基于Red Hat Linux x86_64平台与NVIDIA A100(40 GB显存)图形处理单元(GPU),使用深度学习框架PyTorch,在Python 3.8的环境下设计实验进行性能分析。
3.1 数据集
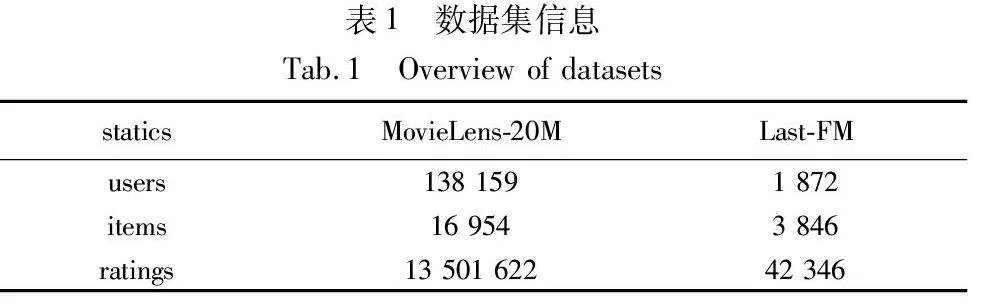
本文的实验基于两个数据集,数据集信息如表1所示。
a)MovieLens-20M数据集。该数据集收集存储了用户对于电影的评分,并带有电影在imdb网站和tmdb网站中的链接。使用数据集中的链接从相关网站上爬取相关数据的附加信息,利用这些信息构建知识图谱。数据集中的用户将电影评分为1~5分的显式评价转换为隐式评价用于模型的输入,将3分设定为一个评分阈值,大于等于3分的评价视为正面评价并在交互列表中将其记为1,余下评分记为0。
b)Last-FM。它是由last.fm发布的数据集,包含接近2 000个用户在last.fm在线音乐平台收听音乐的信息。
3.2 评价指标
本文在进行点击率CTR预测实验时,采用area under curve(AUC)和F1-score两种评价指标;在进行top-K推荐实验时,采用recall@K作为评价指标。
AUC=∑样本i∈正样本ri-P×(P+1)2P×N(20)
F1=2×precision×recallprecision+recall(21)
recall=(∑u∈U|L(u)∩B(u)|)/∑u∈U|B(u)|(22)
其中:AUC表示预测得到正样本的概率大于负样本的概率,P表示正样本数量,N表示负样本数量,对所有样本按照预测值进行从低到高的排序,排序后可以得到每个正样本的序号,用ri表示第i个正样本的序号。F1是精确率和召回率的加权平均值。该值越高,说明模型越稳健。recall表示测试集中用户交互过的项目出现在top-K推荐列表中的比例,U表示用户集,L(u)表示用户u的top-K推荐列表,B(u)表示测试集中与用户交互的项目集。recall值越高,代表推荐系统性能越好。
3.3 对比实验结果及分析
为探究本文模型的性能表现,选取以下推荐模型作为基线模型进行对比实验:
a)NGCF[4]。该模型是一种基于图神经网络的协同过滤模型,通过把用户与项目的交互进行嵌入改善推荐效果。
b)CKE。该模型是一个典型的基于知识图谱嵌入的模型,利用知识图谱中嵌入得到的低维向量表示进行推荐,具有不错的推荐效果。
c)RippleNet。该模型将知识图谱作为额外信息融合到CF推荐系统中,并且首次结合了基于路径和基于嵌入的方法,利用知识图谱对用户潜在的偏好进行表示,进而发现用户的潜在兴趣。
d)KGCN。该模型结合了知识图谱和图神经网络,其核心思想是利用邻域向量扩充当前实体的向量表示,提高了推荐性能,缓解了传统模型冷启动和数据稀疏性问题。
e)LKGR[32]。该模型基于知识增强图卷积网络进行推荐,实现从欧几里德空间到双曲空间的转变,能有效地分层图结构,提升推荐性能。
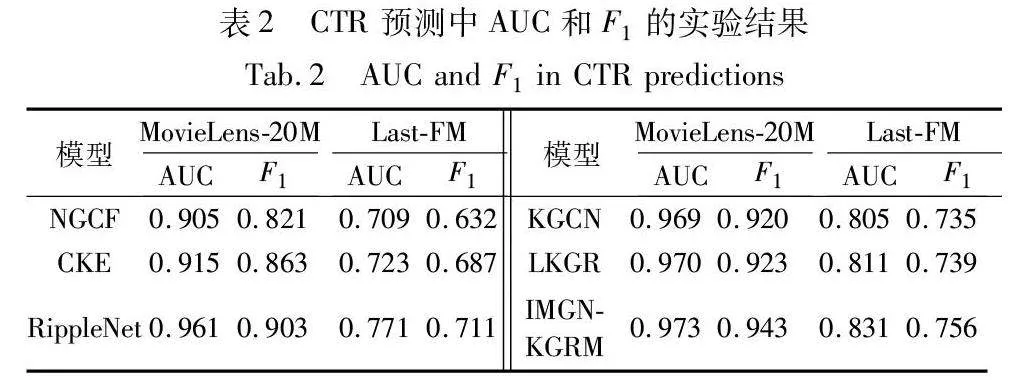
各模型的实验结果如表2与图4所示。结果表明,本文模型在性能上有着最佳表现,AUC与F1值相较于次优的模型在两个数据集上分别提升了0.3%和2.0%、2.0%和1.7%,recall@K值提升了2.5%和3.1%。各模型在MovieLens-20M数据集上的性能指标较Last-FM上更优,这是因为MovieLens-20M数据集的规模更大,较大规模的数据集可以减小随机性带来的影响,包含更多的样本和特征组合,可以帮助模型学习到更多的数据模式和特征表示,提高模型对数据的理解能力,从而提升模型的性能。在本文所选模型中,NGCF的性能表现最差,因为该模型仅利用用户和项目之间的交互关系进行建模,而其他模型则通过知识图谱扩充了用户和项目的表示,通过利用知识图谱中大量的辅助信息获得了更优越的性能。CKE相较于其他基于知识图谱的模型表现较差,该模型只考虑知识图谱中的单跳路径信息,而其他基于知识图谱的模型则考虑了知识图谱中的多跳路径信息,更多跳数的信息挖掘更能充分利用知识图谱中的辅助信息,得到更好的结果。LKGR相较于RippleNet和KGCN,通过将一些异常数据映射到不同空间降低了噪声信息的影响,因此性能有所提升。本文模型表现较LKGR更好,这是因为本文通过元图邻域保证了邻域节点与源节点联系的紧密性,避免引入噪声信息,且通过自注意力网络对元图邻域进行特征增强,进一步提高了对有效特征的利用,进而表现出更优异的性能。
3.4 超参数对模型性能影响的实验结果及分析
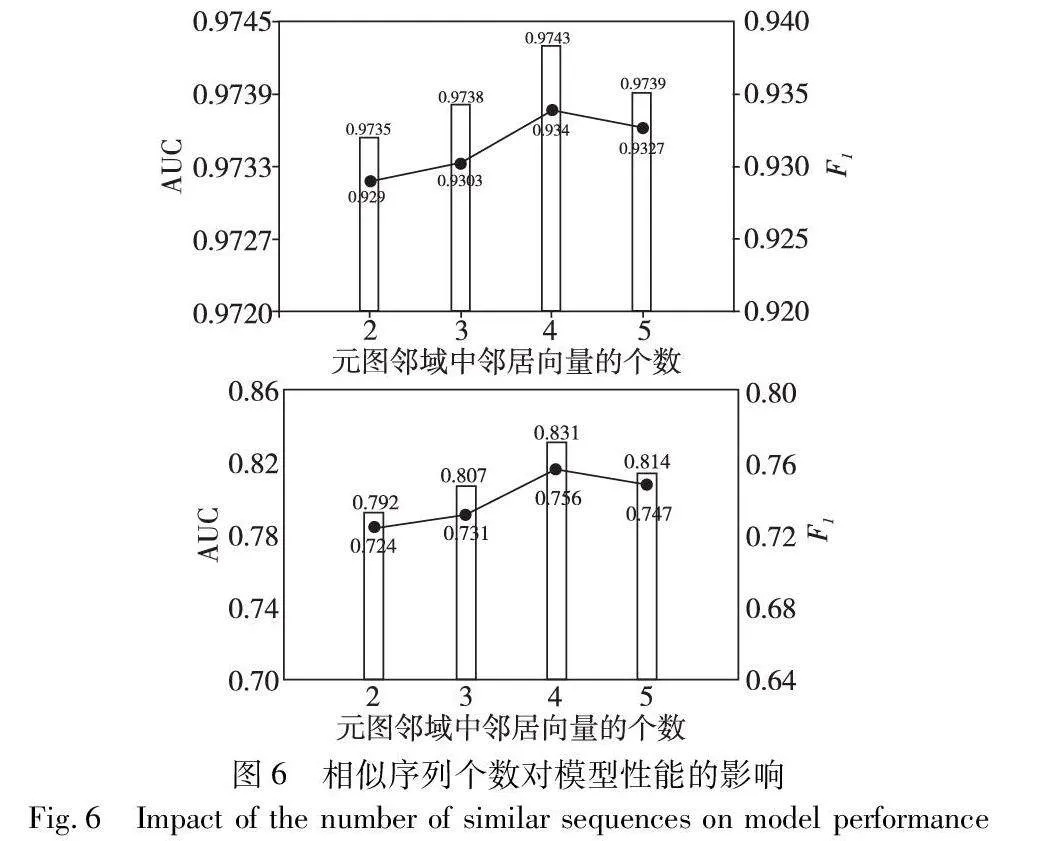
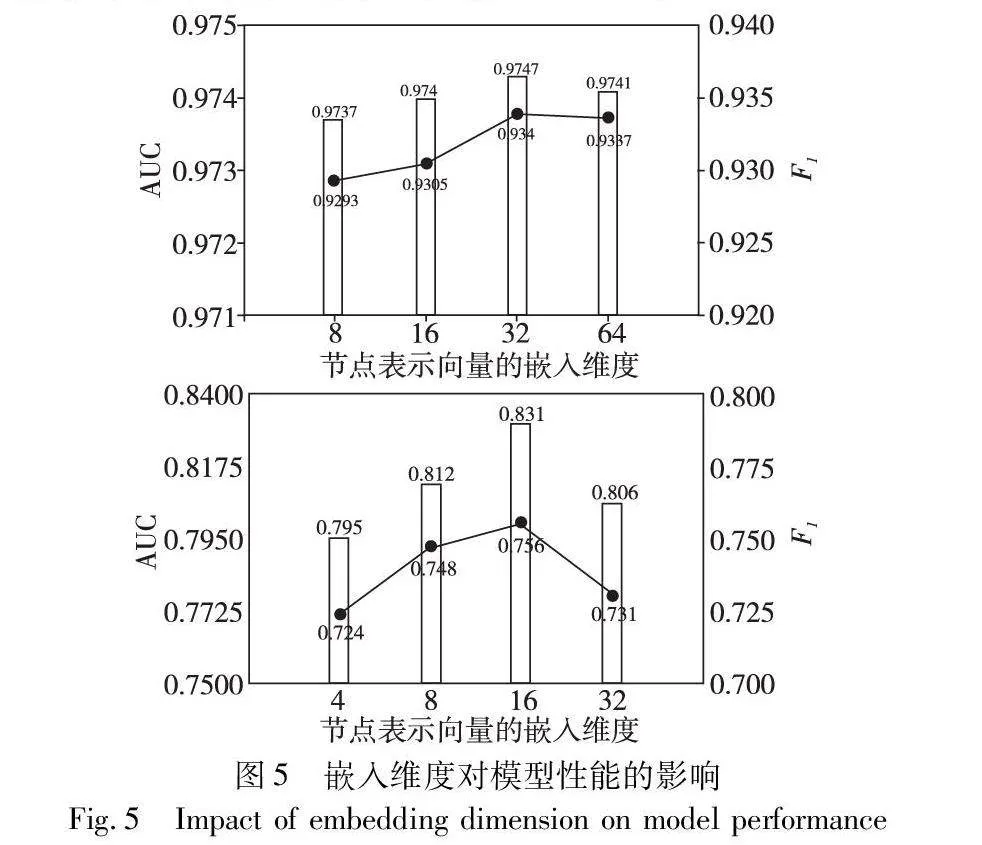
本节对两个重要超参数进行分析,以研究它们对模型性能的影响,分别为表示向量的嵌入维度和基于元图构建的邻域中所选取邻域节点的个数。结果如图5和6所示。
表示向量嵌入维度对模型性能具有较大的影响,图5展示了本文模型基于两种数据集分别在四种嵌入维度上AUC与F1的结果对比,可以看出随着向量嵌入维度的增加,模型性能有所提升,但当嵌入维度进一步增大时,推荐效果反而降低。嵌入维度的大小决定了模型对于实体和关系的表示能力。较高的嵌入维度可以提供更丰富的特征表示空间,使模型能够更好地捕捉实体之间的语义和关系信息。因此,适当增加嵌入维度可能有助于提升模型性能。然而,增加嵌入维度也会增加过拟合的风险,尤其是在数据集规模较小的情况下。在MovieLens-20M数据集上嵌入维度为32时取得最好的结果,在Last-FM数据集上嵌入维度为16时取得最好的结果,这是因为MovieLens-20M数据集的规模较大,可以提取更多的特征。
在基于元图构建邻域时,每个元图的相似序列所选取节点个数也是影响模型性能的重要因素。图6展示了本文模型基于两种数据集在四种不同相似节点个数下的结果对比。从实验结果看出,在选择邻域节点数量为4的情况下,模型取得了最好的性能表现,较低和较多的邻域节点个数都会降低模型性能。增加邻域节点的个数可以提供更多的上下文信息来表示当前节点,从更广泛的邻域中学习到更全面的特征表示,提高模型对节点的理解能力。但当节点个数过多时,也会导致引入冗余信息与过拟合的风险,使得模型性能下降。
3.5 相似序列不同处理方式的实验结果及性能分析
在构建邻域过程中,相似节点序列的不同处理方式对模型性能会产生影响。本文讨论了三种不同相似序列处理方式的不同效果,三种方式分别iwsu0zbmz/U4g/aApMAvPw==为只取相似度最高的节点,对相似节点序列进行归一化求平均,以及本文提到的自注意力机制进行融合。图7展示了在保持其他参数相同的情况下分别以三种方式进行处理后模型的最终结果,其中以自注意力机制进行融合的方式所取得的推荐效果最好,造成该现象的原因是只取相似度最高节点的方式会忽略其他邻居节点的信息,导致丢失部分全局信息。对相似节点序列进行归一化求平均的方式无法充分体现每个节点的贡献,忽略了节点重要性的不同,无法捕捉到更细粒度的特征。自注意力机制处理的方式可以根据节点之间的重要程度和相互影响,动态地调整节点之间的注意力权重,增强节点的特征表示,此种方式能够充分利用全局信息,并灵活地对不同节点进行加权处理,有助于发现节点之间的复杂关系,提高语义表示的准确性,进而提升模型性能。
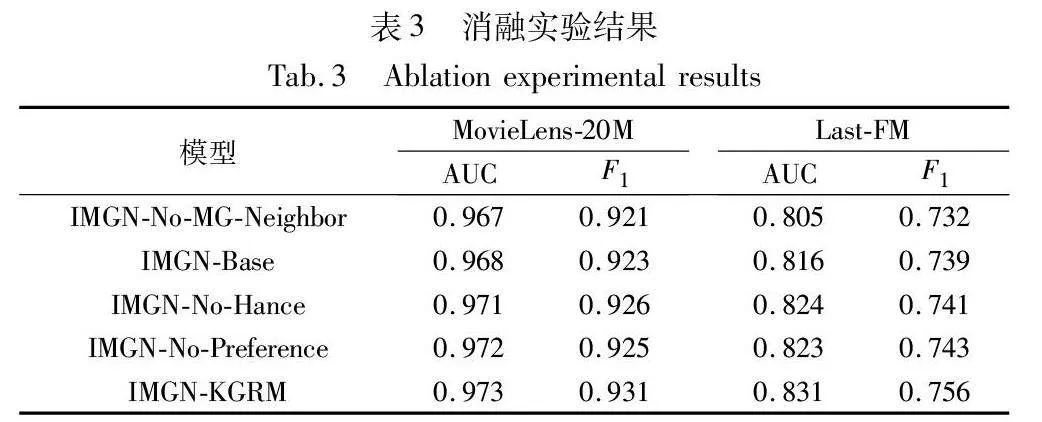
3.6 消融实验
为验证本文模型中各部分的作用,在两种数据集上比较IMGN-KGRM及其他变体的推荐性能,其中变体包括:
a)IMGN-No-MG-Neighbor:只融合节点的一阶邻域增强特征向量表示,不融合元图邻域。
b)IMGN-Base:基本的融合元图邻域模型。在构造元图邻域时只取相似度最高的节点,不用相似序列与自注意力增强特征。在融合元图邻域时以平均权重的方式融合,不考虑不同用户对不同元图的偏好。
c)IMGN-No-Enhance:构造元图邻域时不以相似序列与自注意力机制进行特征增强,融合元图邻域时考虑用户偏好。
d)IMGN-No-Preference:构造元图邻域时取相似序列并利用自注意力机制进行特征增强,融合元图邻域时不考虑用户偏好。
从表3中可以看出,相较于未融合元图邻域的IMGN-No-MG-Neighbor模型,IMGN-Base具有更好的性能,表明使用元图邻域可以有效挖掘知识图谱中的高阶信息,提高模型性能。IMGN-No-Enhance相较于IMGN-Base性能有所提升,表明在构建元图邻域时,以相似度高的节点组成的相似序列进行处理有效地进行了特征增强。IMGN-No-Preference相较于IMGN-Base性能有所提升,表明考虑不同用户对不同元图偏好的重要性。IMGN-No-Enhance和IMGN-No-Preference与IMGN-KGRM之间的对照可以发现,两种方法同时使用的效果要好于单一一种方法的使用。通过此消融实验,说明了IMGN-KGRM各部分之间彼此影响,最终作用于模型整体,对模型的性能提升有积极的贡献。
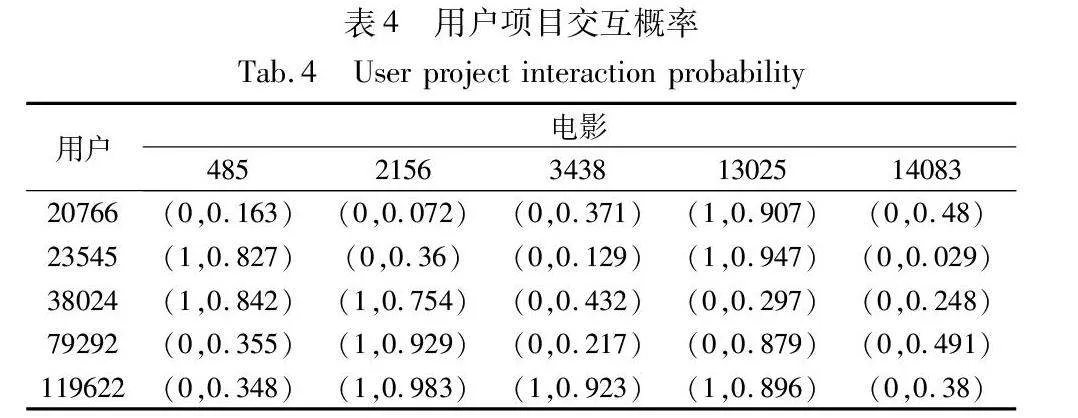
3.7 实例分析
为了直观地分析验证模型的有效性,本文将IMGN-KGRM模型应用到MovieLens-20M数据集上进行案例分析,预测用户对电影的交互概率。首先在MovieLens-20M测试集中随机抽取五个用户与五部电影,id分别为[20766,23545,38024,79292,119622]与[485,2156,3438,13025,14083]。然后,通过模型计算得到用户对电影的交互概率,结果如表4所示,表项内容为用户与电影的真实交互情况(0表示用户与电影未有过交互,1表示用户与电影有交互)与预测的交互概率。由表中数据可知,模型对用户真实交互过的电影的预测交互概率均高于对用户实际未交互过的电影的预测交互概率。由此可见,本文模型能够较为准确地预测用户与电影的交互概率,具有较高的应用性。
4 结束语
本文提出的融合元图邻域的知识图谱推荐模型,在挖掘利用知识图谱中的高阶语义信息时有效减少了噪声信息的影响,更准确地挖掘了知识图谱中的语义信息,提高了模型性能。具体而言,通过基于元图的相似度计算筛选相关度更高的节点,并以自注意力网络对节点进行语义增强的方式构建元图邻域,有效地过滤了噪声信息,提高了信息挖掘的准确性;利用卷积神经网络将源节点与元图邻域进行融合,丰富了源节点的上下文信息,扩展了源节点的语义表示;最后利用融合后的向量完成推荐。实验结果表明,相较于现有的基于知识图谱的推荐模型,本文模型可以有效地提高推荐效果。本文侧重于对项目端的建模而较少考虑用户信息,后续研究拟将用户侧信息引入模型并进行有效利用,以期进一步提高模型的推荐性能。
参考文献:
[1]于蒙, 何文涛, 周绪川, 等. 推荐系统综述 [J]. 计算机应用, 2022, 42(6): 1898-1913. (Yu Meng, He Wentao, Zhou Xuchuan, et al. Review of recommendation system[J]. Journal of Computer Applications, 2022, 42(6): 1898-1913.)
[2]赵凯华,徐建民,鲍彩倩.一个基于信息网络的微博推荐模型[J].河北大学学报:自然科学版,2022,42(4):438-448.(Zhao Kaihua,Xyu Jianmin,Bao Caiqian. A belief network model for microblog re-commendution[J]. Journal of Hebei University:Natural Science Edition, 2022, 42(4): 438-448.
[3]He Xiangnan, Liao Lizi, Zhang Hanwang, et al. Neural collaborative filtering[C]//Proc of the 26th International Conference on World Wide Web.Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2017: 173-182.
[4]Wang Xiang, He Xiangnan, Wang Meng, et al. Neural graph colla-borative filtering[C]//Proc of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press, 2019: 165-174.
[5]Guo Qingyu, Zhuang Fuzhen, Qin Chuan, et al. A survey on know-ledge graph-based recommender systems[J]. IEEE Trans on Knowledge and Data Engineering, 2020, 34(8): 3549-3568.
[6]Cao Yixin, Wang Xiang, He Xiangnan, et al. Unifying knowledge graph learning and recommendation: towards a better understanding of user preferences[C]//Proc of World Wide Web Conference. New York:ACM Press, 2019: 151-161.
[7]张明星, 张骁雄, 刘姗姗, 等. 利用知识图谱的推荐系统研究综述[J]. 计算机工程与应用, 2023, 59(4): 30-42. (Zhang Ming-xing, Zhang Xiaoxiong, Liu Shanshan, et al. Review of recommendation systems using knowledge graph[J]. Computer Engineering and Applications, 2023, 59(4): 30-42.)
[8]Zhuang Fuzhen, Yuan N J, Lian Defu, et al. Collaborative know-ledge base embedding for recommender systems[C]//Proc of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:ACM Press, 2016: 353-362.
[9]Wang Hongwei, Zhang Fuzhen, Zhao Miao, et al. Multi-task feature learning for knowledge graph enhanced recommendation[C]//Proc of World Wide Web Conference. New York:ACM Press, 2019: 2000-2010.
[10]Xin Xin, He Xiangnan, Zhang Yongfeng, et al. Relational collaborative filtering: modeling multiple item relations for recommendation[C]//Proc of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press, 2019: 125-134.
[11]Ye Yuting, Wang Xuwu, Yao Jiangchao, et al. Bayes embedding(BEM) refining representation by integrating knowledge graphs and behavior-specific networks[C]//Proc of the 28th ACM International Conference on Information and Knowledge Management. New York:ACM Press, 2019: 679-688.
[12]何云飞, 张以文, 吕智慧, 等. 异质信息网络中元路径感知的评分协同过滤[J]. 计算机学报, 2020, 43(12): 2385-2397. (He Yunfei, Zhang Yiwen, Lyu Zhihui, et al. Heterogeneous information network-aware rating collaborative filtering[J]. Chinese Journal of Computers, 2020, 43(12): 2385-2397.)
[13]Yu Xiao, Ren Xiang, Gu Quanquan, et al. Collaborative filtering with entity similarity regularization in heterogeneous information networks[EB/OL]. (2013).https://api.semanticscholar.org/CorpusID:14914495.
[14]Zhao Huan, Yao Quanming, Li Jianda, et al. Meta-graph based re-commendation fusion over heterogeneous information networks[C]//Proc of the 23rd ACM SIGKDD International Conference on Know-ledge Discovery and Data Mining. New York:ACM Press, 2017: 635-644.
[15]Sha Xiao, Sun Zhu, Zhang Jie. Hierarchical attentive knowledge graph embedding for personalized recommendation[J]. Electronic Commerce Research and Applications, 2021, 48: 101071.
[16]Wang Hongwei, Zhang Fuzheng, Wang Jialin, et al. RippleNet: propagating user preferencettaYKCJhDJDo31lIAevoGGZmyy+eTXVjWt8qyJBlgyw=s on the knowledge graph for recommender systems[C]//Proc of the 27th ACM International Conference on Information And Knowledge Management. New York:ACM Press, 2018: 417-426.
[17]Wang Hongwei, Zhao Miao, Xie Xing, et al. Knowledge graph con-volutional networks for recommender systems[C]//Proc of World Wide Web Conference. New York:ACM Press, 2019: 3307-3313.
[18]Wang Quan, Mao Zhendong, Wang Bin, et al. Knowledge graph embedding: a survey of approaches and applications[J]. IEEE Trans on Knowledge and Data Engineering, 2017, 29(12): 2724-2743.
[19]常亮, 张伟涛, 古天龙, 等. 知识图谱的推荐系统综述[J]. 智能系统学报, 2019, 14(2): 207-216. (Chang Liang, Zhang Weitao, Gu Tianlong, et al. Review of recommendation systems based on knowledge graph[J]. CAAI Trans on Intelligent Systems, 2019, 14(2): 207-216.)
[20]秦川, 祝恒书, 庄福振, 等. 基于知识图谱的推荐系统研究综述[J]. 中国科学: 信息科学, 2020, 50(7): 937-956. (Qin Chuan, Zhu Hengshu, Zhuang Fuzhen, et al. A survey on knowledge graph-based recommender systems[J]. Scientia Sinica: Informationis, 2020, 50(7): 937-956.)
[21]张波, 赵鹏, 张金金, 等. 基于用户潜在兴趣的知识感知传播推荐算法[J]. 计算机应用研究, 2022, 39(9): 2615-2620. (Zhang Bo, Zhao Peng, Zhang Jinjin, et al. Knowledge-aware propagation recommendation algorithm based on user’s potential interest[J]. App-lication Research of Computers, 2022, 39(9): 2615-2620.)
[22]梁顺攀, 涂浩, 王荣生, 等. 融合重要性采样和池化聚合的知识图推荐算法[J]. 小型微型计算机系统, 2021, 42(5): 967-971. (Liang Shunpan, Tu Hao, Wang Rongsheng, et al. Knowledge graph recommendation algorithm combining importance sampling and pooling aggregation[J]. Journal of Chinese Computer Systems, 2021, 42(5): 967-971.)
[23]朱冬亮, 文奕, 万子琛. 基于知识图谱的推荐系统研究综述[J]. 数据分析与知识发现, 2021, 5(12): 1-13. (Zhu Dongliang, Wen Yi, Wan Zichen. Review of recommendation systems based on know-ledge graph[J]. Data Analysis and Knowledge Discovery, 2021, 5(12): 1-13.)
[24]Sun Yizhou, Han Jiawei, Yan Xifeng, et al. PathSim: meta path-based top-k similarity search in heterogeneous information networks[J]. Proceedings of the VLDB Endowment, 2011, 4(11): 992-1003.
[25]Ding C, Li Tao, Jordan M I. Convex and semi-nonnegative matrix factorizations[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2008, 32(1): 45-55.
[26]Rendle S. Factorization machines with libFM[J]. ACM Trans on Intelligent Systems and Technology, 2012, 3(3): 1-22.
[27]Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[EB/OL]. (2016-05-19). https://arxiv.org/abs/1409.0473.
[28]黄偲偲, 柯文俊, 张杭, 等. 融合知识传播和提示学习机制的推荐模型[J]. 中文信息学报, 2023, 37(5): 122-134. (Huang Cai-cai, Ke Wenjun, Zhang Hang, et al. Incorporation knowledge propa-gation and prompt learning for recommendation[J]. Journal of Chinese Information Processing, 2023,37(5): 122-134.)
[29]Vaswan99b14c5cc96157fccc819744c829e1ca934045412ad4d37b4cf2721ad2130ed0i A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st International Conference onNeural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[30]付峻宇, 朱小栋, 陈晨. 基于图卷积的双通道协同过滤推荐算法[J]. 计算机应用研究, 2023, 40(1): 129-135. (Fu Junyu, Zhu Xiaodong, Chen Chen. Two-channel collaborative filtering recommendation algorithm based on graph convolution[J]. Application Research of Computers, 2023, 40(1): 129-135.)
[31]Chen Jingyuan, Zhang Hanwang, He Xiangnan, et al. Attentive collaborative filtering: multimedia recommendation with item-and component-level attention[C]//Proc of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York:ACM Press, 2017: 335-344.
[32]Chen Yankai, Yang Menglin, Zhang Yingxue, et al. Modeling scale-free graphs with hyperbolic geometry for knowledge-aware recommendation[C]//Proc of the 15th ACM International Conference on Web Search and Data Mining. New York:ACM Press, 2022: 94-102.
