
基于区块链的工业物联网隐私保护协作学习系统
2024-08-15 00:00:00林峰斌王灿吴秋新李涵秦宇龚钢军
计算机应用研究 2024年8期

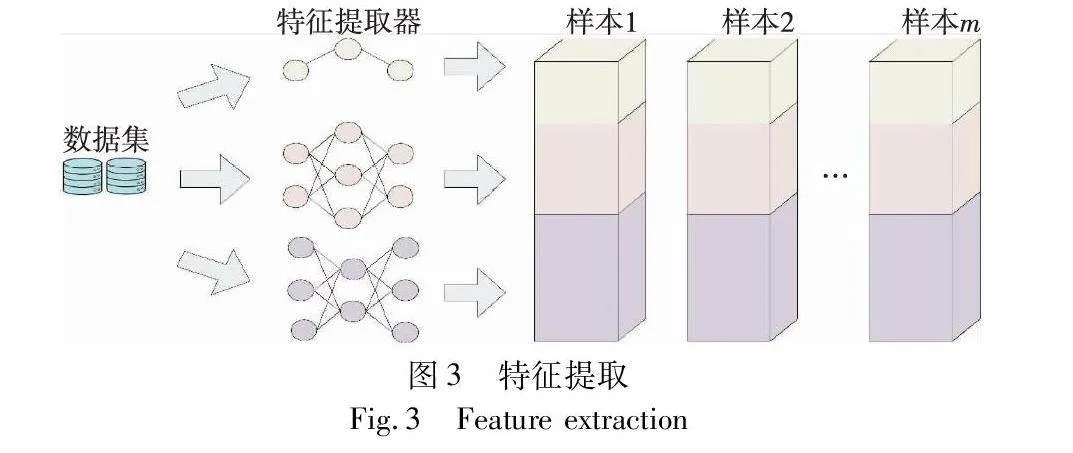







摘 要:为了在保护数据隐私的前提下,充分利用异构的工业物联网节点数据训练高精度模型,提出了一种基于区块链的隐私保护两阶段协作学习系统。首先,使用分组联邦学习框架,根据参与节点的算力将其划分为不同组,每组通过联邦学习训练一个适合其算力的全局模型;其次,引入分割学习,使节点能够与移动边缘计算服务器协作训练更大规模的模型,并采用差分隐私技术进一步保护数据隐私,将训练好的模型存储在区块链上,通过区块链的共识算法进一步防止恶意节点的攻击,保护模型安全;最后,为了结合多个异构全局模型的优点并进一步提高模型精度,使用每个全局模型的特征提取器从用户数据中提取特征,并将这些特征用作训练集训练更高精度的复杂模型。实验结果表明,该系统在Fashion-MNIST和CIFAR-10数据集上的性能优于传统联邦学习的性能,能够应用于工业物联网场景中以获得高精度模型。
关键词:区块链; 工业物联网; 隐私保护; 协作学习; 联邦学习; 分割学习
中图分类号:TP311 文献标志码:A
文章编号:1001-3695(2024)08-004-2270-07
doi:10.19734/j.issn.1001-3695.2023.11.0572
Blockchain based Industrial Internet of Things privacyprotection collaborative learning system
Lin Fengbin1, Wang Can1, Wu Qiuxin1, Li Han1, Qin Yu2, Gong Gangjun3
(1.School of Applied Science, Beijing Information Science & Technology University, Beijing 100192, China; 2.Institute of Software, Chinese Academy of Sciences, Beijing 100190, China; 3.Beijing Engineering Research Center of Energy Electric Power Information Security, North China Electric Power University, Beijing 102206, China)
Abstract:To make full use of heterogeneous nodes data from IIoT to train high-accuracy models while protecting data privacy, this paper proposed a privacy-preserving two-stage collaborative learning system based on blockchain. Firstly, it used a grouped federated learning framework to divide participating nodes into different groups based on their computing power. Each group trained a global model suitable for its computing power through federated learning. Secondly, it introduced split learning to enable nodes to collaborate with mobile edge computing servers to train a larger scale model, and used differential privacy technology to further protect data privacy. It stored trained models on the blockchain, and used the consensus algorithm of the blockchain to further prevent attacks from malicious nodes and protect the security of the model. Finally, to combine the advan-tages of multiple heterogeneous global models and further improve model accuracy, it used the feature extractor of each global model to extract features from user data, and used these features as training datasets to train a higher accuracy complex model. Experimental results show that the performance of system on Fashion-MNIST and CIFAR-10 datasets is better than the performance of traditional federated learning. It is suitable for obtaining high-accuracy models in IIoT scenarios.
Key words:blockchain; Industrial Internet of Things(IIoT); privacy protection; collaborative learning; federated learning; split learning
0 引言
得益于智能传感器在工业生产中的应用以及5G技术的快速发展,大量分布在工业设备上的数据可以被实时记录、跟踪和共享,这正是目前受到学界广泛关注的工业物联网技术(IIoT)。现如今工业物联网已成为工业4.0发展的主要驱动力。借助工业物联网,传统的工业已经逐渐转向智能化发展。这种智能化发展离不开工业物联网设备生成的海量数据的支持,如何合理利用这些数据已成为当前研究热点。近年来,随着机器学习研究的深入,海量数据可以用来训练高质量的机器学习模型以提供预测服务。目前,机器学习技术已应用于设备故障检测、轴承剩余使用寿命预测、工业物联网中的网络流量预测[1~3]等工业场景。然而,数据通常以小规模形式分布在数千个工业物联网设备中。为了获得高精度模型,传统的机器学习框架需要将这些分散的数据收集到中心服务器进行数据预处理和模型训练。由于这
些数据往往包含敏感信息,当中心服务器受到攻击时,大量隐私数据会被泄露,用户隐私无法得到保障,这导致用户不愿意共享本地数据。因此,使用人工智能技术的企业越来越关注其数据的隐私和安全。此外,政府还出台了相关法律法规,限制隐私数据在数据市场的流通。这些因素导致了“数据孤岛”现象的出现。在保护数据安全和隐私的前提下打破数据壁垒,已成为机器学习应用于工业物联网的重大挑战。
鉴于上述问题,本文设计了一种基于区块链的隐私保护协作学习系统。该系统主要分成两个阶段进行:在第一阶段中进行了分组联邦学习并引入了分割学习,将模型分割成客户端模型和MEC(mobile edge computing)端模型,由客户端和MEC服务器共同完成模型的训练;在第二阶段中,利用各组联邦学习全局模型的前若干层作为特征提取器提取本地数据集的特征,并将这些特征用于训练一个更高精度的复杂模型,以应对在联邦学习过程中存在的性能损失问题[4]。本文对协作学习过程中可能存在的数据隐私泄露问题引入了差分隐私技术进一步保护工业物联网节点数据的隐私性,并使用区块链技术实现了去中心化的协作学习方案,避免了中心式服务器可能存在的单点故障问题。
1 预备知识
1.1 联邦学习和分割学习
联邦学习作为一种协作学习方案最早由Google于2016年提出[5]。与传统的机器学习框架不同,联邦学习的过程中,信息通过模型参数在服务器和节点之间传输,可以有效减少网络流量,并在一定程度上保护数据隐私。在联邦学习中,中心服务器将全局模型分发给所有参与节点,这些节点使用各自的数据集在本地完成模型的训练。完成本地训练后,本地模型参数由节点上传回中心服务器并在服务器上聚合以更新全局模型。服务器将更新后的全局模型参数重新下发给参与节点,开始下一轮迭代。经过多次重复迭代步骤,最终得到具有良好性能的机器学习模型。
分割学习也是一种协作学习方案,在分割学习中,深度学习模型的网络结构被分成两部分并分布在不同的节点上,以便计算能力较低的客户端和计算能力较高的服务器可以共同训练复杂的深度学习模型。参与分割学习的客户端使用本地数据集完成模型前半部分的前向传播过程,然后将中间层的输出发送到服务器。在服务器上,接收到的数据用于模型后半部分的前向传播。然后服务器计算模型后半部分的反向传播,并将中间层的梯度发送给客户端,以完成模型前半部分的反向传播过程。模型前半部分和后半部分的参数分别在客户端和服务器上更新。利用高算力服务器的计算资源,可以让算力较低的客户端训练更大的模型。本文将联邦学习和分割学习相结合应用于工业物联网场景中,使得低算力的工业物联网设备能够完成联邦学习模型的训练。
1.2 区块链
区块链是由所有参与节点维护的分布式账本。区块按照其生成的时间顺序连接,每个区块包含前一个区块的哈希值、交易时间和其他信息。区块链具有可追溯、去中心化、难以窜改的特点[6]。如果区块链中的某些节点受到恶意攻击,其余节点仍然可以正常运行,这使得区块链系统具有鲁棒性。由于区块链所具有的特性,本文系统采用区块链记录协作学习过程当中产生的模型参数以及数据特征,并实现了去中心化的协作学习方案。
2 相关工作
联邦学习作为一种热门的协作学习技术,受到了各界的广泛关注。研究人员提出了各种框架来进一步优化联邦学习。Duan等人[4]证明了联邦学习过程中,节点数据的异构性会导致模型性能下降,并提出了名为Astraea的联邦学习框架来提高模型性能。Xu[7]提出了一种新颖的模型聚合框架,通过每个客户端模型生成的伪样本来训练联邦学习的全局模型,从而提高聚合的效率和全局模型的准确性。Duan等人[8]在服务器上使用重要性加权方法聚合模型参数,该框架通过减少局部模型和全局模型之间的差异来提高联邦学习模型的性能。Guo等人[9]设计了一种轻量级联邦学习系统,该系统通过仅聚合模型关键部分的参数来减少通信量。
分割学习作为另一种协作学习技术首次由Gupta等人[10]提出,他们分析了分割学习方案在多客户端环境下的优势。Wang等人[11]将分割学习中模型的划分问题转换为最小代价图搜索问题,从而实时为节点分配最佳决策以提高分割学习的效率。Ha等人[12]强调了分割学习是解决节点数据异构性和保护数据隐私的有效技术,并分析了其在医疗领域应用的可行性。Vepakomma等人[13]提出了多种分割学习方案,以应对不同场景的需求。Abuadbba等人[14]指出在分割学习过程中存在隐私泄露的情况,并提出了两种隐私保护方案。
联邦学习和分割学习都有其优点和一些应用限制。因此,一些研究人员试图结合两者的优势来构建新的分布式学习框架。Duan等人[15]综述了两者所具有的独特优势和局限性,并对未来联邦学习与分割学习相结合的新型分布式学习架构提出了一些构想。Turina等人[16]提出了一种混合分布式学习框架,实现了联邦学习和分割学习的互补,并采用差分隐私技术来保护数据隐私。Thapa等人[17]提出了分割联邦学习框架,显著减少了联邦学习过程所花费的时间,同时保证了模型的准确性。然而,上述研究依赖于具有中心服务器的联邦学习,在这种架构下系统的鲁棒性较低。
使用区块链代替中心服务器节点进行协作学习可以提高整个系统的鲁棒性,许多研究人员已经在这方面进行了研究。Feng等人[18]提出了异步联邦学习模型,并使用区块链代替中心节点。该框架可以有效防止恶意节点的投毒攻击,提高本地模型更新的有效性。Zhang等人[19]提出了一种基于区块链的去中心化联邦学习框架,用于工业界硬件故障检测,并利用激励机制激励用户参与学习,使联邦学习过程中有足够的数据可用。Li等人[20]使用区块链代替联邦学习框架的中心服务器,并提出了一种新颖的共识委员会机制,以降低全局模型被恶意攻击的风险,并提高共识算法的有效性。Yi等人[21]设计了一个基于区块链的联邦学习激励框架,通过Stackelberg博弈以最大化服务器效益并保证用户获得奖励的公平性。Singh等人[22]将基于区块链的联邦学习安全架构应用于智能医疗场景,并分析了该框架的性能。Zhao等人[23]提出了一种基于区块链的联邦分割学习框架,将模型一部分的计算卸载到算力更高的MEC服务器上,提高本地模型训练的效率,并采用差分隐私技术保护用户数据的安全。在联邦学习过程当中参与者无须上传本地数据,一定程度上避免了数据隐私的泄露。然而现有攻击方法仍然可以通过模型恢复部分数据,因此模型的保护成为联邦学习过程中必不可少的一部分。本文和文献[16,17,21,24~26]都采用了差分隐私技术来保护模型的隐私。
3 系统设计
本文提出的系统整体架构如图1所示。该系统主要由任务发起者、客户端和区块链三个部分组成。首先,任务发起者提出两阶段协作学习任务,具有相关数据集的工业物联网节点可以选择作为客户端加入协作学习任务。每个客户端进入与其计算能力相匹配的分组,每组分别进行各自的联邦学习。完成分组联邦学习阶段后,每个客户端从区块链中获取所有组的客户端模型,利用这些客户端模型从本地数据集中提取特征,这些特征经过拼接之后将会被上传到区块链。最后,任务发起者从区块链上获取到数据集的拼接特征,并在具有高算力的云计算平台上训练最终的复杂模型。
3.1 任务发起者
任务发起者是一个与各工业物联网设备相连的服务器,它可以访问区块链和云计算服务器。任务发起者发起协作学习任务以获得高精度的模型。由于不同客户端之间算力的异构性,在传统的未分组联邦学习架构中,若全局模型较为复杂,则小算力节点将无法进行模型训练,那么这些节点的数据无法被应用于联邦学习,从而影响模型的泛化能力。如果采用简化的全局模型,虽然可以利用这部分节点的数据,但由于模型复杂度不够,其精度可能无法达到要求。因此在协作学习第一阶段当中,任务发起者根据各个客户端节点的算力对其进行分组,不同组使用不同复杂度的模型进行联邦学习,既不浪费高算力节点的算力,又能充分利用低算力节点的数据;然后在第二阶段中利用这些模型提取数据特征并进一步训练高精度模型。为了方便客户端获取模型,任务发起者为这些模型配置初始参数并将其存储在区块链上。完成分组联邦学习任务后,每个客户端使用所有组全局模型的特征提取器来提取其本地数据集的特征,并将其上传到区块链。在第二阶段中,任务发起者从区块链中获取所有客户端数据的特征,这些特征用于在具有高计算能力的云服务器上训练更高精度的复杂模型。图2记录了两阶段协作学习任务的完整流程。最终,任务发起者获得所有组的特征提取器和高精度的复杂模型。对于实际应用中的测试样本,任务发起者使用这些特征提取器提取特征,然后将其输入复杂模型中以获得预测结果。
3.2 客户端
每个客户端都是一个工业物联网设备,存储可用于机器学习模型训练的数据集。工业物联网设备的计算能力较低,导致训练时间较长。为了提高联邦学习的效率并使得工业物联网节点能够训练更大规模的模型,由客户端与MEC共同完成本地模型的计算。由于MEC服务器存在信息泄露和被攻击的风险,每个客户端在上传特征之前都需要添加拉普拉斯噪声,以保护本地数据的隐私。客户必须通过以下步骤才能完成协作学习任务:
a)客户端将自己的设备信息发送给任务发起者,申请加入协作学习任务。然后任务发起者按照每个客户端的算力将其分成多组联邦学习。每个客户端使用区块链来获取其对应组的全局模型的初始参数。
b)每个客户端与其对应的MEC服务器交互(一个MEC对应一个客户端),完成本地模型的训练。客户端用于本地训练的模型将分成客户端模型和MEC端模型两个部分。客户端和MEC服务器分四个阶段执行本地模型的前向和后向传播。
(a)客户端使用本地数据集完成客户端模型的前向传播,得到中间层的输出特征后为其添加上拉普拉斯噪声扰动,并连同相应的标签上传到MEC服务器。
(b)MEC服务器利用接收到的特征完成MEC端模型的前向传播过程并计算损失。
(c)MEC服务器执行反向传播并更新MEC端模型上的参数,中间层的梯度将被发送到客户端。
(d)客户端接收MEC服务器返回的梯度,完成客户端模型的反向传播和参数更新。
c)客户端将模型参数上传到区块链,并由区块链中的“见证人”对其进行两阶段验证,通过验证的客户端模型参数才能被采用,并用于全局模型的聚合更新。
d)客户端上传本地数据集的特征。当所有组的联邦学习完成后,每个客户端从区块链下载所有组的特征提取器用于提取本地数据集的特征。如图3所示,由不同特征提取器提取的样本特征将被拼接起来。考虑到数据特征仍存在数据隐私泄露的风险[27],为了保护数据隐私,客户端应给特征添加差分隐私噪声。最后,客户端将添加了噪声的特征上传至区块链。
3.3 区块链
本文采用联盟链来记录每个分组联邦学习过程中的全局和本地模型以及第一阶段得到的数据特征。在联盟链中采用了一种高效的共识协议,称为DPoS(delegated proof of stake)。由于只有部分被选为见证人的节点拥有记账权,所以区块验证的速度较快。见证人根据随机算法打乱后得到记账顺序。一旦见证人生成了新的区块,就必须将其传递给其余见证人进行验证,并且只有超过四分之三的见证人验证通过后,该区块才能被添加到区块链中。在本文系统中,见证人的主要职责包括验证节点的交易、生成和验证新的区块。在分组联邦学习中,交易验证需要分两个阶段完成。首先,见证人验证交易的数字签名,以确保是由授权节点发出交易;然后通过Multi-KRUM算法验证模型的有效性。由于区块的大小限制,模型参数和数据特征无法完整存入一个区块中。为此,本文引入星际文件系统(inter planetary file system,IPFS)来实现链下存储。IPFS是一个分布式文件存储系统,其每个文件都有一个唯一地址。在本文系统中,当客户端或任务发起者需要将模型参数或数据特征上传至区块链时,首先要将其上传到IPFS上获取对应的文件地址,随后将该地址进行数字签名后上传到区块链,并由见证者对数字签名进行验证,通过验证的地址才会被写入区块中。当客户端或任务发起者需要从区块链获取模型参数或数据特征时,先从区块链获得文件的IPFS地址,随后通过该地址从IPFS获取模型参数或数据特征。这种链下存储机制可以突破区块的大小限制并显著降低区块链的存储负载。
在区块链上运行所提系统的过程如下:首先,任务发起者生成不同复杂度的初始全局模型并将其上传到区块链,参与分组联邦学习的客户端基于区块链获取的全局模型参数进行本地模型训练;随后,这些模型参数由见证人进行两阶段验证后用于全局模型参数的聚合,更新后的全局模型参数将被写入新的区块中并使用Gossip协议将新区块广播给其余见证人,其余见证人检查区块的有效性后,新区块将被添加到区块链中,在分组联邦学习阶段结束时,每个客户端从区块链中获取所有组的特征提取器用于提取本地数据集的特征,这些数据集特征被拼接后上传到区块链;最后,任务发起者从区块链上获取特征用于在具有高算力的云服务器上训练高精度的复杂模型。设联邦学习组数为K,全局迭代(global epoch)次数G,本地迭代(local epoch)次数L,每个本地迭代的批次数B,本地训练的学习率r。该系统的算法如算法1和2所示。
算法1 基于区块链的隐私保护两阶段协作学习系统
输入:K,G。
输出:f1G,f2G,…,fKG,W。
任务发起者为K个不同复杂度的模型初始化参数p10,p20,…,pK0,并上传到区块链
for each group k in parallel do
for global epoch g=1,2,…,G do
for each client c of group k in parallel do
从区块链上下载pkg-1
pk,cg←clientUpdate(pkg-1) //见算法2
上传pk,cg到区块链
end
见证者执行Multi-KRUM算法(见3.5节)获取可信的客户端集合Ckg和不可信客户端集合Ukg
pkg←1Ckg∑c∈Ckgpk,cg
end
end
for each client c∪Kk=1∪Gg=1Ukg in parallel do
从区块链上下载p1G,p2G,…,pKG并使用它们的前若干层f1G,f2G,…,fKG作为特征提取器
客户端使用所有特征提取器从每个样本s中提取特征并添加拉普拉斯噪声后得到x1s,x2s,…,xKs
将特征x1s,x2s,…,xKs拼接起来得到xs
将所有xs上传到区块链
end
任务发起者下载所有客户端样本的xs并训练最终的复杂模型W
return f1G,f2G,…,fKG,W
算法2 clientUpdate
输入:p,L,B,r。
输出:本地更新后的p。
将p拆分为客户端模型w和MEC端模型m
//在每个客户端及其对应的MEC服务器上运行
for each local epoch l=1,2,…,L do
for each batch b=1,2,…,B do
在客户端上进行前向传播
给中间层添加差分隐私噪声(见3.4节)并传给MEC服务器
在MEC服务器上进行前向传播
在MEC服务器上进行反向传播
m←m-rmloss //更新MEC端模型参数
将中间层梯度传给客户端
在客户端上进行反向传播
w←w-rwloss //更新客户端模型参数
end
end
p←(w,m)
return p
3.4 差分隐私
如果一个随机算法M对于任意两个相邻的数据集D与D′(D与D′中仅有一条记录不同)满足
Pr[M(D)∈S]≤eε Pr[M(D′)∈S]+δ(1)
则随机算法M满足(ε,δ)差分隐私。Pr[·]表示概率;S表示随机算法M的所有可能输出的集合。如果δ=0,则该算法满足ε差分隐私,也称为严格差分隐私。ε是隐私保护预算,ε越小,对于数据的隐私保护性越强,但同时数据的可用性也就越低;ε越大对于数据施加的隐私保护性越弱,数据的可用性也就越高。
基于差分隐私的定义,满足差分隐私的算法使得数据库中信息的变化不会对算法的输出产生很大的影响。因此,即使获得了大量的输出信息,差分隐私也使得攻击者很难推断出原始的用户数据。差分隐私受到了各行业的关注,例如Google利用差分隐私开发了名为RAPPOR的隐私工具[28],在保护用户隐私的前提下收集用户数据。
本文在分割学习和上传客户端数据特征过程中都是通过在模型的中间层特征中添加拉普拉斯噪声来实现差分隐私机制(见算法1和2)。由于差分隐私机制的后处理特性[23],最终模型仍然可以满足差分隐私机制[29]。具体地,客户端在上传模型的中间层特征之前需要添加尺度参数为λ=Δf/ε、均值为0的拉普拉斯噪声,其中Δf是特征取值的范围。
3.5 Multi-KRUM算法
本文通过Multi-KRUM算法筛选出可信客户端的模型参数与不可信客户端的模型参数。Multi-KRUM算法使用欧氏距离来衡量两个模型参数之间的距离。记第k组第g轮联邦学习中第i个客户端上传的模型参数为pk,ig,区块链中的见证者记录与其最接近的T-P-2个模型参数,记为Nk,ig。其中T表示总的模型数量,P表示需要拒绝的模型数量。将这T-P-2个模型参数与pk,ig距离的平方相加作为pk,ig的离群度,记为dk,ig。dk,ig定义如下:
dk,ig=∑j∈Nk,ig‖pk,ig-pk,jg‖2(2)
离群度最小的T-P个模型参数对应的客户端作为可信客户端集合Ckg,其余P个模型参数对应的客户端作为不可信客户端集合Ukg。
4 实验
4.1 实验准备
实验中使用的设备是一台配备Intel i7-12700H CPU(2.70 GHz)、GeForce GTX 3070Ti GPU和32 GB RAM的笔记本电脑。目前Fashion-MNIST和CIFAR-10常被用于检测工业物联网中联邦学习系统的性能[30],因此本文采用这两个数据集进行实验。Fashion-MNIST数据集包含7万个样本,共有10个类别,每个样本都是28×28大小的灰度图像,将其中5万、1万、1万个样本分别用作训练集、验证集和测试集。CIFAR-10数据集包含6万个样本,共有10个类别,每个样本都是32×32大小的RGB图像,将其中4万、1万、1万个样本分别用作训练集、验证集和测试集。实验共模拟了10个工业物联网设备节点。考虑到工业物联网中设备的数据量不同,且大多数设备数据量较小,本文进行以下实验配置:10个客户端中有5个客户端为小型数据集拥有者,3个客户端为中型数据集拥有者,另外2个客户端是大型数据集拥有者。在实际应用中,拥有大型数据集的客户端往往拥有更多的计算资源。因此,拥有小型、中型、大型数据集的客户端对应拥有小型、中型、大型的算力。从而本文对于小型、中型、大型数据集的客户端分别构建了具有小型、中型、大型全局模型的分组联邦学习。
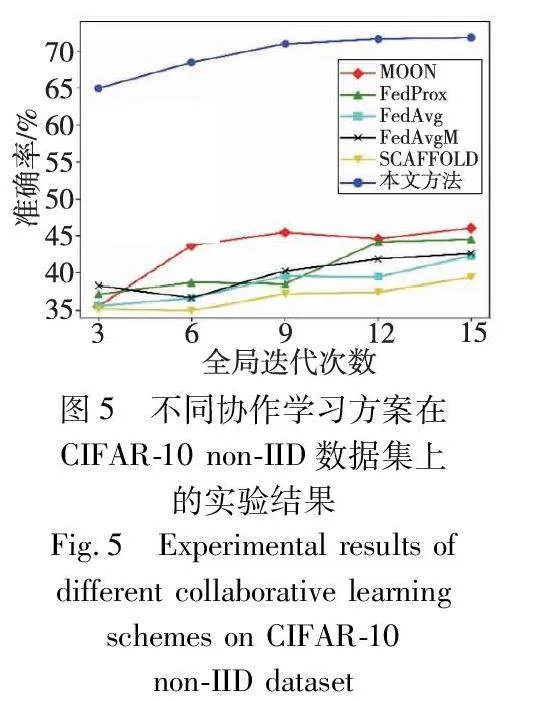
本实验分三部分,第一部分对本文系统与现有流行的联邦学习算法MOON[31]、FedProx[32]、FedAvg[5]、FedAvgM[33]、SCAFFOLD[34]进行对比实验。第二部分验证使用分组联邦学习框架的优势,为此设计了三个对比实验,每个实验都使用未分组的传统联邦学习框架。在对比实验Ⅰ中,使用的全局模型是一个小模型,它使得所有客户端都能够参与联邦学习。在对比实验Ⅱ中,采用的全局模型是中等模型,由于低算力的客户端无法满足计算要求,所以只有中、高算力的客户端才能参与实验Ⅱ。在对比实验Ⅲ中,使用的全局模型是一个大模型,只有高算力的客户端才能满足本次实验的计算要求。为了对比的公平性,在实验Ⅰ、Ⅱ和Ⅲ中的联邦学习后都增加了复杂模型训练环节。第三部分验证本文系统在不同分布数据集下的性能表现、Multi-KRUM算法的有效性以及研究相似特征对复杂模型性能的影响。
为了模拟客户端之间异构数据量的情况,两个数据集按照表1进行划分。对于所有实验,数据集分为10个部分,每个部分对应一个客户端。在独立同分布(independent and identically distributed,IID)数据集中,每个客户端(即数据集拥有者)拥有全部10个类别的数据。在非独立同分布(not independent and identically distributed,non-IID)数据集中,每个小数据集拥有者拥有3个类别的数据,所有小数据集的类别总数为6;每个中数据集拥有者拥有6个类别的数据,所有中数据集的类别总数为8;每个大数据集拥有者都拥有全部10个类别的数据。
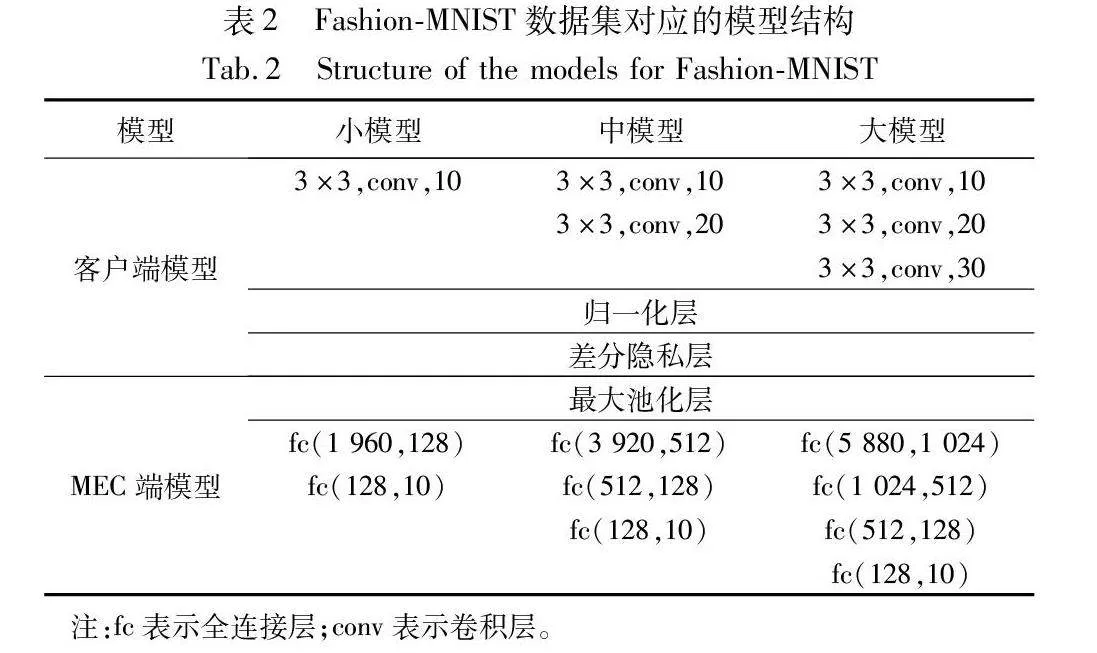
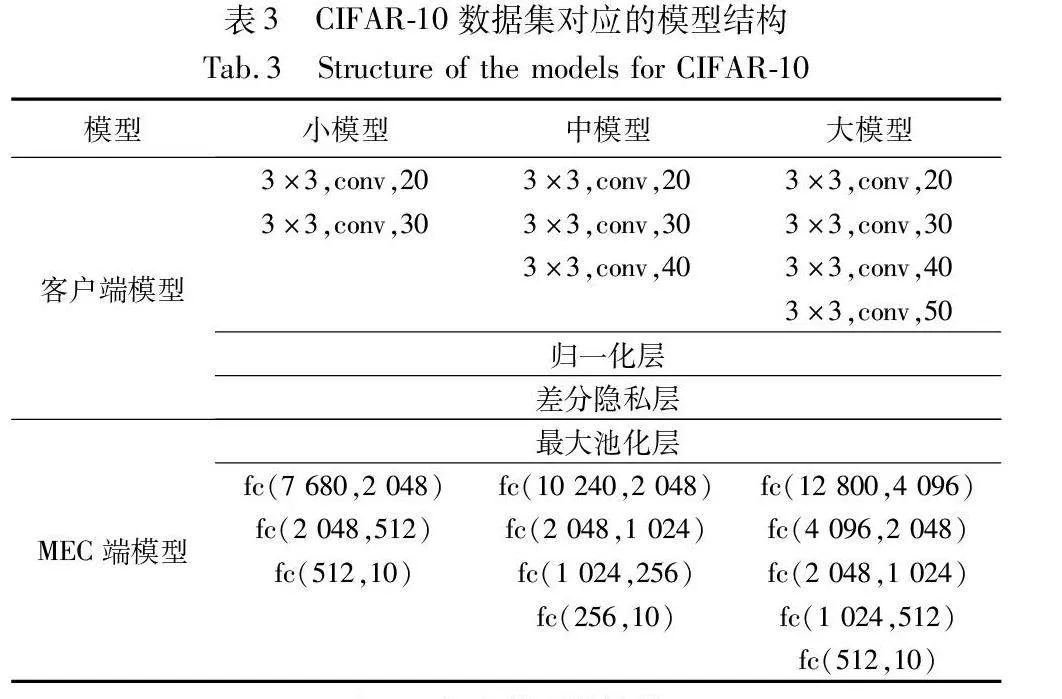
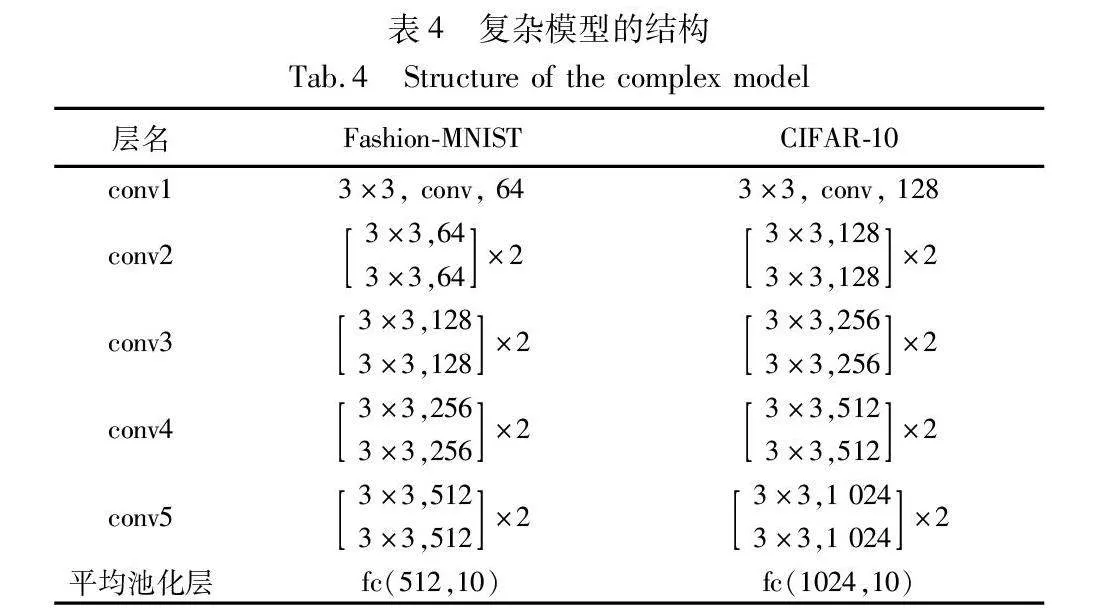
小模型、中模型和大模型都是CNN模型。Zagoruyko等人[35]提出神经网络的宽度和深度影响其复杂度,通过调整两者的大小可以获得不同复杂度的模型。为此,本文通过改变卷积层数、通道数、全连接层数以及每层神经元数来生成不同复杂度的全局模型。通常,全连接层的参数数量远大于卷积层,这使得全连接层占用更多的计算资源。为了减少客户端的计算量,客户端模型主要由CNN的卷积层组成,且本实验在特征提取阶段也将各组联邦学习全局模型的卷积层部分用作特征提取器。MEC服务器负责CNN的全连接层的计算。此外,最后一个卷积层提取的特征由归一化层[19]修改,使得特征的范围限制在[-N-1,N-1],其中N表示批次大小(batch size)。这些特征的敏感度为2N-1,隐私预算ε设置为2。差分隐私层向每个特征添加均值为0、尺度参数为λ=2N-1/2的拉普拉斯噪声,以满足差分隐私机制。最后,本文使用修改后的ResNet-18作为复杂模型,基于从所有客户端数据集中提取的特征进行训练。表2和3记录了实验中两个数据集所对应的小模型、中模型、大模型的整体结构,而表4记录了复杂模型的结构。在分组联邦学习阶段,将学习率设置为0.005,将批次大小设置为32,并将所有客户端的本地迭代次数设置为5。在复杂模型训练阶段,将学习率设置为0.01,将批次大小设置为32,并根据验证集准确率采用早停策略。
4.2 实验结果
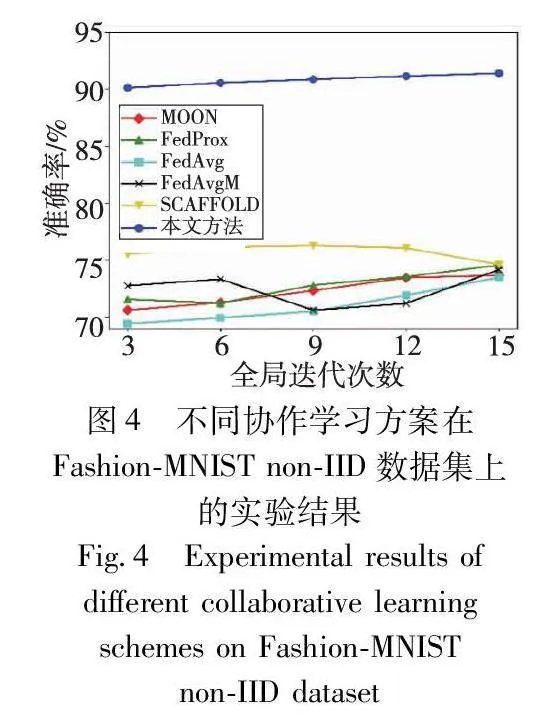
本文系统在Fashion-MNIST与CIFAR-10数据集上的实验结果如图4~12所示。在图4和5中记录了第一部分实验的结果,对比了本文方法和当前主流的一些联邦学习方案在使用全部客户端时的测试集准确率。实验结果表明,在两种非独立同分布的数据集下,本文设计的协作学习方案在相同的全局迭代次数下都具有更好的表现。相对于目前的联邦学习架构,本文设计的两阶段学习方案,在第一阶段中能够使不同客户端训练不同复杂度的模型,在第二阶段中能利用联邦学习模型提取的特征进一步训练复杂模型,从而获得更高精度的模型。
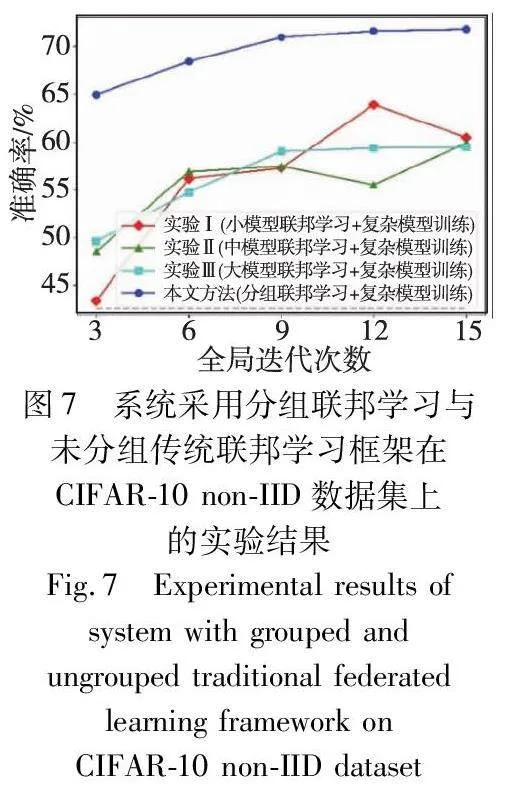
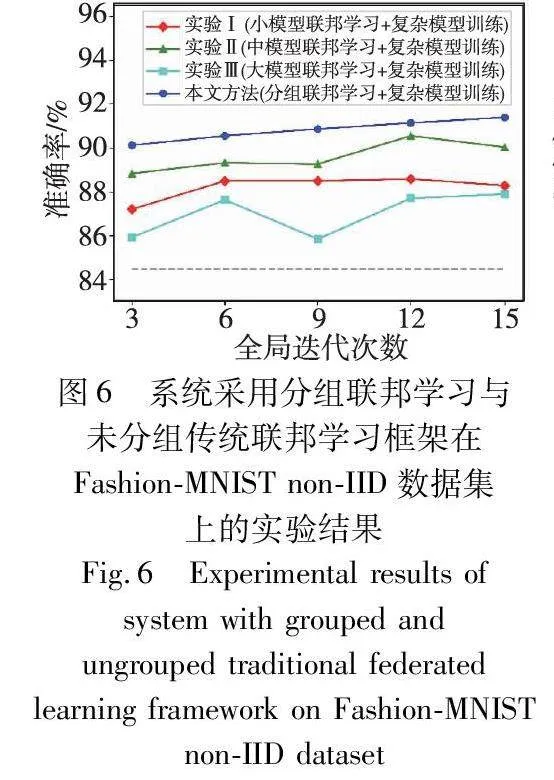
图6和7展示了第二部分实验的结果。可以看到,分组联邦学习框架得到的复杂模型准确率高于所有未分组的传统联邦学习框架。这一结果进一步证实在传统联邦学习中,尽管相对较小的模型可以利用计算能力较低的节点的数据,但小模型的特征提取器无法提取足够好的数据集特征用于后续复杂模型的训练;另一方面,使用更大的模型就无法利用所有节点的数据,因此也会影响最终复杂模型的能力。
此外,为了验证框架中第一阶段进行联邦学习获取特征提取器的必要性,本文还进行了如下对比实验:不使用分组联邦学习中的特征提取器,直接使用添加了拉普拉斯噪声的数据作为训练第二阶段复杂模型的特征。该实验在Fashion-MNIST数据集上的准确度为84.48%(图6中的灰色虚线),在CIFAR-10数据集上的准确度为42.62%(图7中的灰色虚线)。这些结果表明,从分组联邦学习中获取的特征提取器对于复杂模型达到更高的准确率是必要的。
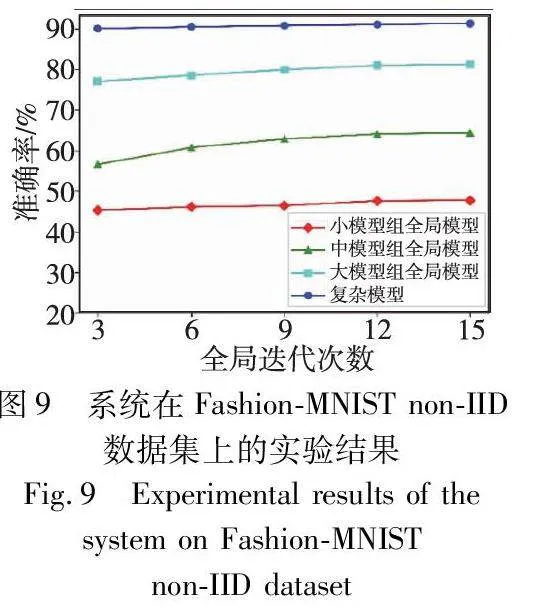
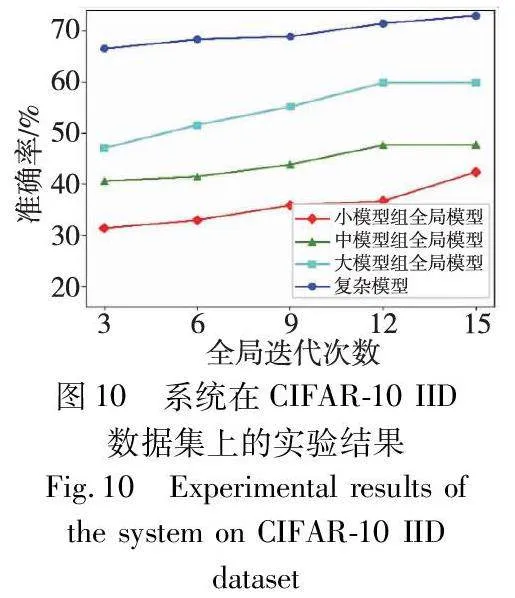
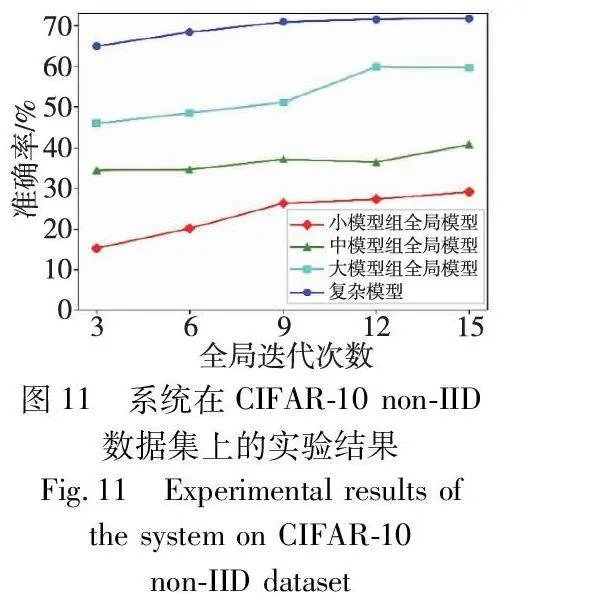
在图8~11中记录了第三部分实验的结果,展示出本文系统在Fashion-MNIST和CIFAR-10数据集上的每组全局模型以及复杂模型的准确率表现。从图中可以看出,该系统获得的复杂模型在IID和non-IID数据集上都达到了较高的准确率,显著优于每个分组联邦学习模型,从而可以有效解决联邦学习中的性能损失问题。此外,随着每组联邦学习的全局迭代次数的增加,每个全局模型的准确率逐渐提高,复杂模型的准确率也随之提高。这表明,第一阶段中训练更充分的CNN模型的卷积层具有更好的特征提取能力,这有助于第二阶段训练的复杂模型达到更高的准确率。
此外,为了测试Multi-KRUM算法对抗投毒攻击的有效性,实验中将其中一个小数据拥有者设置为恶意攻击者,该客户端始终提供与全局模型参数相同分布的随机值组成的恶意模型参数。如图12所示,当系统中采用Multi-KRUM算法时,最终的复杂模型的准确率得到显著提高。这表明Multi-KRUM算法可以识别恶意攻击者上传的恶意参数,从而提高本文系统的鲁棒性。
最后,验证了相似特征对复杂模型性能的影响。由于不同组的联邦学习模型使用的数据不同,模型结构不同,所以不同组的特征提取器不会提取出完全相同的特征。但由于所有组的学习任务相同,其特征提取器可能会提取出相似特征。本文进一步研究了删除相似特征对于复杂模型性能的影响。具体地,经过3轮全局训练后,使用各组联邦学习模型的特征提取器提取客户端的数据特征并拼接起来作为样本(图3)。随机抽取一定数量的样本,并针对每一个特征(即通道),将这些样本在该特征上的特征图拉直为一个向量作为该特征的表示向量,基于表示向量使用K-means算法和欧氏距离对特征进行聚类。对每个类选择与其他特征距离之和最短的一个特征作为该类的代表。对所有样本只保留这些代表特征,然后用于复杂模型的训练。表5展示了在Fashion-MNIST non-IID数据集上不同代表特征数量(即类别数k)所对应的复杂模型的准确率。
实验结果表明,删除相似特征会导致部分信息的丢失,从而影响复杂模型的精度。尽管保留这部分的特征可能会增加模型训练过程中的计算量,但在算力允许的情况下使用这部分特征能够使得复杂模型具有更高的精度。综上所述,针对节点的异构性,本文系统采用分组联邦学习框架,能够允许不同客户端采用不同架构的模型,使不同客户端的算力资源能够得到充分利用。该系统在IID和non-IID数据集上都具有良好的性能,因此可以在节点高度异构的工业物联网中提供智能计算服务。
5 结束语
针对如何在保护数据隐私的前提下高效利用工业物联网中的数据,本文将区块链与协作学习技术相结合,设计了一个基于区块链的隐私保护两阶段协作学习系统。该系统首先在异构节点上使用分组联邦学习、分割学习技术完成特征提取器的训练;随后用其提取的特征训练更为复杂的高精度模型;使用差分隐私技术保护了数据在传输过程中可能存在的泄露问题;使用区块链技术,实现了去中心化的协作学习以及对于客户端上传的模型可溯源、不可窜改;结合IPFS技术实现了区块链的链下存储,有效降低区块链的存储负载;模型的聚合由区块链中的见证者们执行,结合Multi-KRUM算法保护了系统不受恶意节点的攻击。实验结果表明,该系统在数据、算力异构的工业物联网场景下能够训练出高精度的模型,并有效保护了数据的隐私。未来,将使用实际的工业物联网设备数据来测试本文系统,以验证其实用性。同时,将继续探索节点划分的更优方案。
参考文献:
[1]Huang Huakun, Ding Shuxue, Zhao Lingjun, et al. Real-time fault detection for IIoT facilities using GBRBM-based DNN[J]. IEEE Internet of Things Journal, 2019, 7(7): 5713-5722.
[2]Ren Lei, Sun Yaqiang, Wang Hao, et al. Prediction of bearing remaining useful life with deep convolution neural network[J]. IEEE Access, 2018, 6: 13041-13049.
[3]Wang Ranran, Zhang Yin, Peng Limei, et al. Time-varying-aware network traffic prediction via deep learning in IIoT[J]. IEEE Trans on Industrial Informatics, 2022, 18(11): 8129-8137.
[4]Duan Moming, Liu Duo, Chen Xianzhang, et al. Self-balancing federa-ted learning with global imbalanced data in mobile systems[J]. IEEE Trans on Parallel and Distributed Systems, 2020, 32(1): 59-71.
[5]McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Proc of the 20th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale:PMLR,2017: 1273-1282.
[6]潘雪, 袁凌云, 黄敏敏. 主从链下的物联网隐私数据跨域安全共享模型[J]. 计算机应用研究, 2022, 39(11): 3238-3243. (Pan Xue, Yuan Lingyun, Huang Minmin. Cross-domain sharing model of loT privacy data under master-slave chain[J]. Application Research of Computers, 2022, 39(11): 3238-3243.)
[7]Xu Mulin. FedPS: model aggregation with pseudo samples[C]//Proc of International Conference on Knowledge Science, Engineering and Management. Cham: Springer, 2021: 78-88.
[8]Duan J H, Li Wenzhong, Lu Sanglu. FedDNA: federated learning with decoupled normalization-layer aggregation for non-IID data[C]//Proc of Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Cham: Springer, 2021: 722-737.
[9]Guo Jialin, Wu Jie, Liu Anfeng, et al. LightFed: an efficient and secure federated edge learning system on model splitting[J]. IEEE Trans on Parallel and Distributed Systems, 2021,33(11): 2701-2713.
[10]Gupta O, Raskar R. Distributed learning of deep neural network over multiple agents[J]. Journal of Network and Computer Applications, 2018, 116: 1-8.
[11]Wang Song, Zhang Xinyu, Uchiyama H, et al. HiveMind: towards cellular native machine learning model splitting[J]. IEEE Journal on Selected Areas in Communications, 2021, 40(2): 626-640.
[12]Ha Y J, Yoo M, Lee G, et al. Spatio-temporal split learning for privacy-preserving medical platforms: case studies with COVID-19 CT, X-ray, and cholesterol data[J]. IEEE Access, 2021, 9: 121046-121059.
[13]Vepakomma P, Gupta O, Swedish T, et al. Split learning for health: distributed deep learning without sharing raw patient data[EB/OL]. (2018-12-03)[2024-01-09]. http://arxiv.org/abs/1812.00564.
[14]Abuadbba S, Kim K, Kim M, et al. Can we use split learning on 1D CNN models for privacy preserving training?[C]//Proc of the 15th ACM Asia Conference on Computer and Communications Security. New York: ACM Press, 2020: 305-318.
[15]Duan Qiang, Hu Shijing, Deng Ruijun, et al. Combined federated and split learning in edge computing for ubiquitous intelligence in Internet of Things: state-of-the-art and future directions[J]. Sensors, 2022, 22(16): 5983.
[16]Turina V, Zhang Zongshun, Esposito F, et al. Federated or split? A performance and privacy analysis of hybrid split and federated learning architectures[C]//Proc of the 14th International Conference on Cloud Computing. Piscataway, NJ: IEEE Press, 2021: 250-260.
[17]Thapa C, Arachchige P C M, Camtepe S, et al. SplitFed: when fede-rated learning meets split learning[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 8485-8493.
[18]Feng Lei, Zhao Yiqi, Guo Shaoyong, et al. BAFL: a blockchain-based asynchronous federated learning framework[J]. IEEE Trans on Computers, 2021, 71(5): 1092-1103.
[19]Zhang Weishan, Lu Qinghua, Yu Qiuyu, et al. Blockchain-based federated learning for device failure detection in industrial IoT[J]. IEEE Internet of Things Journal, 2020, 8(7): 5926-5937.
[20]Li Yuzheng, Chen Chuan, Liu Nan, et al. A blockchain-based decentralized federated learning framework with committee consensus[J]. IEEE Network, 2020, 35(1): 234-241.
[21]Yi Zhenning, Jiao Yutao, Dai Wenting, et al. A Stackelberg incentive mechanism for wireless federated learning with differential privacy[J]. IEEE Wireless Communications Letters, 2022, 11(9): 1805-1809.
[22]Singh S, Rathore S, Alfarraj O, et al. A framework for privacy-preservation of IoT healthcare data using federated learning and blockchain technology[J]. Future Generation Computer Systems, 2022, 129: 380-388.
[23]Zhao Yang, Zhao Jun, Jiang Linshan, et al. Privacy-preserving blockchain-based federated learning for IoT devices[J]. IEEE Internet of Things Journal, 2020, 8(3): 1817-1829.
[24]Zhao Ping, Huang Haojun, Zhao Xiaohui, et al. P3: privacy-preserving scheme against poisoning attacks in mobile-edge computing[J]. IEEE Trans on Computational Social Systems, 2020, 7(3): 818-826.
[25]康海燕, 冀源蕊. 基于本地化差分隐私的联邦学习方法研究[J]. 通信学报, 2022, 43(10): 94-105. (Kang Haiyan, Ji Yuanrui. Research on federated learning approach based on local differential privacy[J]. Journal on Communications, 2022, 43(10): 94-105.)
[26]徐晨阳, 葛丽娜, 王哲,等. 基于差分隐私保护知识迁移的联邦学习方法[J]. 计算机应用研究, 2023, 40(8): 2473-2480. (Xu Chenyang, Ge Lina, Wang Zhe, et al. Federated learning method based on differential privacy protection knowledge transfer[J]. Application Research of Computers, 2023, 40(8): 2473-2480.)
[27]Hitaj B, Ateniese G, Perez-Cruz F. Deep models under the GAN: information leakage from collaborative deep learning[C]//Proc of the 24th ACM SIGSAC Conference on Computer and Communications Security. New York: ACM Press, 2017: 603-618.
[28]Erlingsson U, Pihur V, Korolova A. RAPPRO: randomized aggrega-table privacy-preserving ordinal response[C]//Proc of the 21st ACM SIGSAC Conference on Computer and Communications Security. New York: ACM Press, 2014: 1054-1067.
[29]Dwork C, McSherry F, Nissim K, et al. Calibrating noise to sensi-tivity in private data analysis[C]//Proc of the 3rd Theory of Cryptography Conference. Berlin: Springer, 2006: 265-284.
[30]Chen Junbao, Xue Jingfeng, Wang Yong, et al. Privacy-preserving and traceable federated learning for data sharing in industrial IoT app-lications[J]. Expert Systems with Applications, 2023, 213: 119036.
[31]Li Qinbin, He Bingsheng, Song D. Model-contrastive federated lear-ning[C]//Proc of IEEE/CVF conference on computer vision and pattern recognition. Piscataway, NJ: IEEE Press, 2021: 10713-10722.
[32]Li Tian, Sahu A K, Zaheer M, et al. Federated optimization in hete-rogeneous networks[EB/OL]. (2018-12-14)[2024-01-09]. http://arxiv.org/abs/1812.06127.
[33]Hsu T M H, Qi Hang, Brown M. Measuring the effects of non-identical data distribution for federated visual classification[EB/OL]. (2019-09-13)[2024-01-09]. http://arxiv. org/abs/1909. 06335.
[34]Karimireddy S P, Kale S, Mohri M, et al. SCAFFOLD: stochastic controlled averaging for federated learning[C]//Proc of the 37th International Conference on Machine Learning.[S.l]: JMLR.org, 2020: 5132-5143.
[35]Zagoruyko S, Komodakis N. Wide residual networks[EB/OL]. (2016-05-23)[2024-01-09]. http://arxiv. org/abs/1605.07146.
