
基于Python技术的《红楼梦》文本分析研究
2024-08-11 00:00:00唐明珍李宝
科技风 2024年22期




摘要:随着互联网技术的普及,信息呈指数级增长,如何从大量文本中挖掘有价值的信息一直是文本分析研究的主题。本文使用Python技术对《红楼梦》从基本信息统计、词频云图绘制、人物关系分析、章回聚类分析等方面做可视化分析,挖掘小说文本中隐蔽性信息。与传统文学作品分析方法相比,该数据挖掘的定量分析方法可以高效获取文本文献中有潜在性的信息,具有一定的普适性和应用价值。
关键词:红楼梦;文本分析;Python技术;jieba库;聚类分析
中图分类号:I207.411文献标识码:A
随着计算机技术不断发展,世界上的主要语言都建立了许多对应不同规模和类型的语料库,语料库语言学在近些年也得到了快速发展,并不断趋于成熟、完善。国内Ant Conc、TreeTagger语料库在文本分析方面使用较为广泛,但是这些软件不能对中文文本的研究提供精确支持[1]。随着大数据技术的普及,研究者开始应用数据挖掘等技术解决中文文本分析遇到的问题。数据挖掘技术典型的代表之一就是Python语言的出现,Python相对于其他专用的文本分析软件更具有灵活性[2],可以利用Pyecharts、Networkx等第三方库对文本数据进行可视化分析。
《红楼梦》作为古典四大名著之一,塑造了许多经典人物形象,是五千年文化传统沉淀的百科全书。传统文学作品文本分析主要是发现文学作品的价值,判断小说当中的社会结构与实际社会结构的相似度,而这种分析依靠的是读者自身对文学作品的理解与思考,仅仅采用梳理方式完成,对于文本数据潜在的信息无法探知,采用文本数据挖掘技术正是弥补这一问题的有效手段之一。本研究使用Python数据挖掘技术对《红楼梦》文本潜在信息进行简要可视化分析与展示,有助于读者更好去理解小说的文本内容。
1 《红楼梦》文本基本信息统计
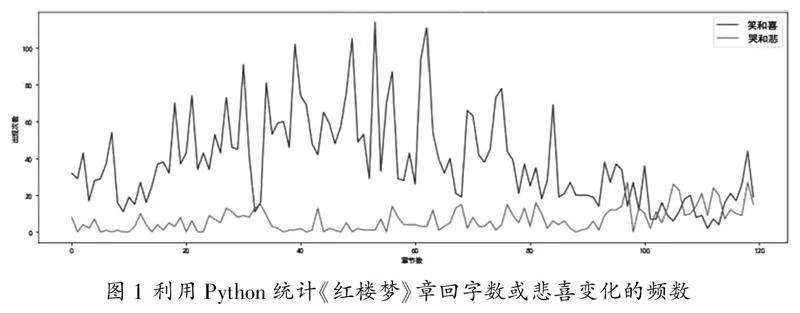
导入“红楼梦.txt”文件数据,首先对数据进行清洗预处理。随后,可以通过编写代码实现提取出自己需要的信息,例如输入相关代码,统计整个文本中出现“笑”或“喜”“悲”或“哭”的频数,如图1所示。通过梳理可以看到,后三十回文中出现的笑和喜明显减少,悲和哭的次数明显增加。可以看到《红楼梦》在后三十回中的人物命运开始逐步走向悲惨,整个作品情感基调出现了转折,不再是前八十回中那些欢快场景描写中的喜,行文思路出现转折,更值得研究者去探究、去思考,符合脂砚斋的批语:“按此回之文固妙,然未见后之三十回,犹不见此之妙。”这样直观统计分析更加清楚明了,让读者了解文章整体思路,便于对文学作品的理解与掌握。
2 《红楼梦》文本词频统计
《红楼梦》整本书字数是731017字,这么多文字中,哪些词语出现的次数多呢?如果单纯依靠读者自己梳理,需要大量的时间去整理。利用Python中第三方jieba库进行分词统计,可以快速梳理出一些词频信息。同时,由于《红楼梦》中人物的各种称谓较多,同一人出现多种称谓,例如“宝钗”“薛宝钗”等称谓指的是同一人。因此,需要研究者将分词后的词语导出来,进行合并或者实体链接。为了更加进一步让读者清楚直观地看到文中出现频率较高的词语,可以借助Python的第三方Wordcloud库完成文本数据分析的云图绘制。通过绘制云图可视化展示,更加清楚直观地展示出高频词汇,具体如图2所示。从绘制出云图结果可以清晰地看到,文中出现频率最高的是宝玉、王夫人(王熙凤的姑姑)、贾母、贾琏、凤姐等词语。云图中字体字号越大,说明其出现频率越高。
3 《红楼梦》文本人物关系分析
一部好的作品大多是塑造了典型的人物形象,在进行文学作品分析研究时,除了要发现文学作品的价值,还需要分析文学作品中人物的关系。优秀的小说中人物社会结构能够反映当时现实世界的特征,同时反映出人物在整个社会网络中关系紧密度、社会地位和主次关系等。《红楼梦》是一本鸿篇巨著,里面出现了900多位人物,重点人物129位,人物关系错综复杂,每个人物各具特色。全书这些人物谁出场最多、人物之间又存在什么样的关系等一直是读者关注的话题。数据挖掘技术可以清晰客观地表现出人物关系网络的真实面貌,例如,林峰等使用社会网络分析法把《红楼梦》文本中出现的主要人物名字位置当做人际关系距离量化指标,采用Pajek软件绘制人物关系网络图[3];李卓宇等将《红楼梦》小说采用复杂网络方法对人物关系进行建模,利用Networkx软件包计算网络指标分析网络的结构特性[4]。本研究选择Python的第三方库Networkx库对数据实现网络建模,该库能够对特性文本进行处理和分析,利用共现关系获取一些人物关键词之间的网络关系。
对《红楼梦》整个文本的社交网络分析后发现,其中人物的社交网络有3240人,如果安排传统的文本研究者把这些人物节点以及之间的关系绘制出来,实现起来是十分艰难的,但利用Python技术可以简单快速地将其呈现出来,输出社交网络结果如图3所示。从图中的节点可以看出,处于中心节点的人物是重要人物,与其他节点的人物交点较多。从图中可以看出宝玉、宝钗、王夫人、贾母、袭人、贾琏等人物处于中心节点,度值相对较大,是整本书的重要人物,处于主要地位,这个分析结果与前面人物热点词频统计结果基本相符。通过社会网络分析也可以看出,这些人物和其他人物均有交互关系,说明整本小说的行文思路基本围绕这些人物展开。同时,可以用其他方式展示文本中人物的社交关系,如图4所示。图中的线代表两个人物之间存在交互关系,其中线越粗代表两者交互场景越多。当然,如果更想进一步了解每个章回中人物关系,可以选择章回中人物文本数据进行分析。
4 《红楼梦》文本各章回聚类分析
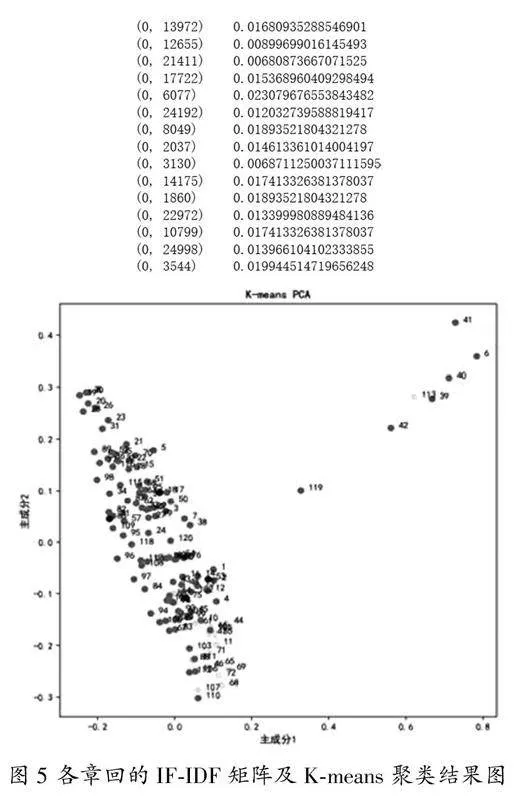
对于任何一个复杂的网络而言,当中的节点会表现出集群的特性。本研究的网络聚类分别采用K-means聚类和层级聚类进行分析探究。K-means聚类在使用过程中需要制定聚类的簇数,然后将样本向量中距离近的点聚类到一组中。在假定要聚类的每个小组中有一个中心点,K-means算法的目的就是找到这些中心点的坐标,使得所有样本向量到其分组中心点的距离平方和最小[5]。对于K-means聚类首先要进行的就是构建语料库,并计算文本文档词的TF-IDF矩阵,如图5左侧所示。随后,采用K-means聚类分析,例如调节聚类的簇为2,对于《红楼梦》章回聚类结果如图5所示。从图中可以看到第六回、第三十九回、第四十回、第四十一回、第四十二回、第一百一十三回等零散分布为一类,其他聚类为一类。回归到文本中,细读文本可以发现,文中对于刘姥姥出场描写恰恰出现在第六回、第三十九回、第四十回、第四十一回、第四十二回、第一百一十三回。其中,第六回为刘姥姥初次进荣国府,主要对刘姥姥人物出场以及进贾府的原因进行描述;第三十九至四十二回,是大家所熟知的内容,主要是以刘姥姥视角描写她初次进大观园的经历,是作者着重描述的部分;第一百一十三回,主要写贾府败落后,刘姥姥再进贾府探亲、救助巧姐等。通过章回的聚类可以帮助读者进一步梳理文本的思路和主线,能够提高文本分析研究的效率。
层次聚类分析是通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。通过层级聚类可以看出聚类的结果呈现多层级,聚类的根节点有两个,和K-means聚类维度为2的结果较为相似。但是除了从根节点看出两个维度外,其他层级聚类结果也可视化展示出来,比K-means聚类呈现效果较好,如图6所示。读者如果需要进一步研究,可以借助聚类后的结果,细读同类章回的内容,寻找其共性特征。
结语
如果读者依靠传统文本研究方法对小说进行分析,每个读者的理解和认知不同,可能得出结果不太一样,出现“千人千面”的现象。同时,由于小说涉及人物、情节等较为复杂,很多读者往往会因为文本太过错综复杂而放弃梳理。Python技术对于文本分析过程不同于人的常规思维,以计算机的思维方式或视角挖掘数据隐含的信息。只要研究分析者采用的方法合理科学,呈现出的数据比人为分析结果更加能体现数据的准确性,能够减少研究者人为在解读文本中出现过度解读的情况。本研究利用Python技术实现了对《红楼梦》小说文本的分析研究,结合jieba、Networkx库对整本小说的文本从基本信息统计、词频统计及词频云图绘制、人物关系分析、章回聚类分析等进行挖
图6 各章回层次聚类结果图
掘,完成了《红楼梦》章回字节数统计和喜悲字数统计图、词频统计云图、人物社交全景图、章回K-means聚类等可视化数据分析。本文所采用的研究方法适合于整个文本,也适合与任何一个章回的分析,通过文本挖掘的可视化分析可以帮助人们更加清晰地理解小说,在小说文本数据分析方面具有普适性。
参考文献:
[1]王天奇,管新潮.语料库语言学研究的技术拓展——《Python文本分析:用可实现的方法挖掘数据价值》评介[J].外语电化教学,2017,177(05):93-96.
[2]肖刚,张良均.Python中文自然语言处理基础与实践[M].北京:人民邮电出版社,2022.
[3]林峰,赵广平,林娜,等.《红楼梦》文本的社会网络结构分析[J].石家庄铁道大学学报(社会科学版),2018,12(01):58-63.
[4]李卓宇,马乐荣,何进荣.基于复杂网络的人物关系建模研究——以《红楼梦》为例[J].现代信息科技,2021,5(03):1-4+8.
[5]巫芯宇.基于FTRM模型和K-means算法的大学生知识付费产品使用行为研究[J].西南大学学报(自然科学版),2021,43(06):195-204.
作者简介:唐明珍(1990—),女,汉族,陕西安康人,硕士,中级职称,研究方向:教学法研究、文本分析研究。
