
一种面向机器视觉感知的暗光图像增强网络
2024-07-31 00:00:00冯欣王思平张智先焦晓宁薛明龙
计算机应用研究 2024年6期






摘 要:低光照等恶劣环境下的目标检测一直都是难点,低光照和多雾因素往往会导致图像出现可视度低、噪声大等情况,严重干扰目标检测的检测精度。针对上述问题,提出了一个面向机器视觉感知的低光图像增强网络MVP-Net,并与YOLOv3目标检测网络整合,构建了端到端的增强检测框架MVP-YOLO。MVP-Net采用了逆映射网络技术,将常规RGB图像转换为伪RAW图像特征空间,并提出了伪ISP增强网络DOISP进行图像增强。MVP-Net旨在发挥RAW图像在目标检测中的潜在优势,同时克服其在直接应用时所面临的限制。模型在多个真实场景暗光数据上取得了优于先前工作效果并且能够适应多种不同架构的检测器。其端到端检测框mAP(50%)指标达到了78.3%,比YOLO检测器提高了1.85%。
关键词:低光图像增强; 机器视觉; RAW图像; ISP处理
中图分类号:TP391.41 文献标志码:A
文章编号:1001-3695(2024)06-045-1910-06
doi:10.19734/j.issn.1001-3695.2023.08.0404
Dark light image enhancement network for machine vision perception
Abstract:Target detection in adverse conditions such as low illumination has always been a challenging. The factors of low light and fog can lead to reduced visibility and increased noise in images, significantly disrupting the precision of object detection. To address these issues, this paper proposed and integrated a low-light image enhancement network for machine vision perception, MVP-Net, with the YOLOv3 object detection network to construct an end-to-end enhancement detection framework, MVP-YOLO. MVP-Net employed inverse mapping network technology to transform conventional RGB images into pseudo-RAW image feature space and introduced a pseudo-ISP enhancement network, DOISP, for image enhancement. The objective of MVP-Net is to harness the potential advantages of RAW images in object detection while overcoming the limitations encountered in their direct application. The model has outperformed previous works on multiple real-world low-light datasets and is adaptable to detectors with various architectures. Its end-to-end detection framework achieves a mAP(50%) metric of 78.3%, an improvement of 1.85% over the YOLO detectors.
Key words:low-light image enhancement; machine vision; RAW images; ISP processing
0 引言
暗光目标检测是目标检测算法在暗光环境的具体应用。近年来,依靠大规模高质量的数据集,目标检测算法发展取得了巨大成功,但在实际应用场景中,低光和多雾等因素往往会导致图像出现可视度低、噪声大、伪影等情况,给现有的目标检测方法带来巨大挑战,严重干扰目标检测方法的检测性能,减慢了其在产业界的落地步伐,如夜间自动驾驶、夜间无人机搜寻等。
为了提高检测算法在暗光场景的检测性能,常用的做法是在检测算法前面加入图像增强算法,使暗光图像恢复到正常光照效果。传统的图像增强算法主要包括基于直方图均衡化的图像增强算法[1]和基于Retinex[2]理论的图像增强算法[3]。传统的图像增强算法主要基于固定的图像调整规则实现增强。虽然在实验数据集上有较好的效果,但是泛化能力较差,针对不同图像场景需要手动调整参数,并且需要大量的CPU计算,特别是对于高分辨率的图像,这可能会导致较高的计算复杂性和时间开销。伴随深度学习在各行业的蓬勃发展,Lore等人[4]将自编码器结构引入到暗光图像增强网络中,为深度学习模型应用于暗光图像增强等任务提供了参考范例。Shen等人[5]根据Retinex理论设计了由光照亮度网络和色彩网络构成的复合增强网络,并且提出了结合感知损失和风格损失来优化模型训练,使得增强图像更自然逼真。Fan等人[6]将传统图像增强理论小波变换引入M-Net,利用半小波注意力块增强网络提取特征的能力。
尽管以深度学习为基础的图像增强方法在诸多方面,如图像亮度恢复、模型泛化性等,表现优异,然而其训练过程却不可避免地依赖于大规模配对数据集。特别是制作大量配对的暗光图像的数据成本高昂,构成了其应用所面临的重要挑战。Jiang等人[7]提出了一种无监督对抗生成网络暗光增强模型EnlightenGAN,在一定程度上解决了配对数据集制作成本高昂的问题,但是面对高分辨率的图像样本,其容易出现棋盘效应。
近年来,基于深度学习的低光图像增强方法取得了巨大的进展,但是仍然面临一些问题,如增强后图像出现色彩饱和度下降,提高亮度的同时也提升了图像噪点,影响后续检测性能。得益于RAW图像的成像优势,一些学者开始将RAW图像引入到低光图像增强领域。RAW是没有经过图像信号处理器(image signal processor,ISP)处理的图像[8],具有更广阔的色彩空间范围,能够捕捉到最原始、最完整的图像信息。Chen等人[9]建立了第一个RAW图像低光图像数据集并且提出了基于RAW的低光图像增强网络,在噪声抑制和改善色彩饱和度方面明显优化基于RGB图像的低光图像增强网络。但由于RAW图像的内存需求大,边缘设备难以访问RAW图像,且在数据存储和传输过程中可能会出现RAW图像的数据丢失,所以在实际工业场景中难以使用,并且现有主流的低光图像增强方法[4~7,9~11]是面向人眼视觉进行优化设计的,恢复的图像不一定适用于面向机器视觉(目标检测精度等指标)设计的模型。若直接将暗光恢复方法拿来在暗光检测场景应用,不仅训练烦琐,还可能会对目标检测等高级视觉任务造成一定程度的误导。
针对上述问题,本文提出了一种面向机器视觉感知的低光图像增强网络(machine vision-based pseudo-RAW enhancement network,MVP-Net)。为了充分利用RAW信息,MVP-Net引入了逆映射网络。近年来,一些研究学者提出了逆映射网络F将RGB图像Ii恢复到对应的RAW空间It,称为伪RAW图像。如Cui等人[10]提出的逆映射网络,这种逆映射网络可以避免直接使用RAW图像带来的内存限制问题。伪RAW图像比RGB图像具有更多的特征信息[8,11],如式(1)所示。
It=F(Ii)(1)
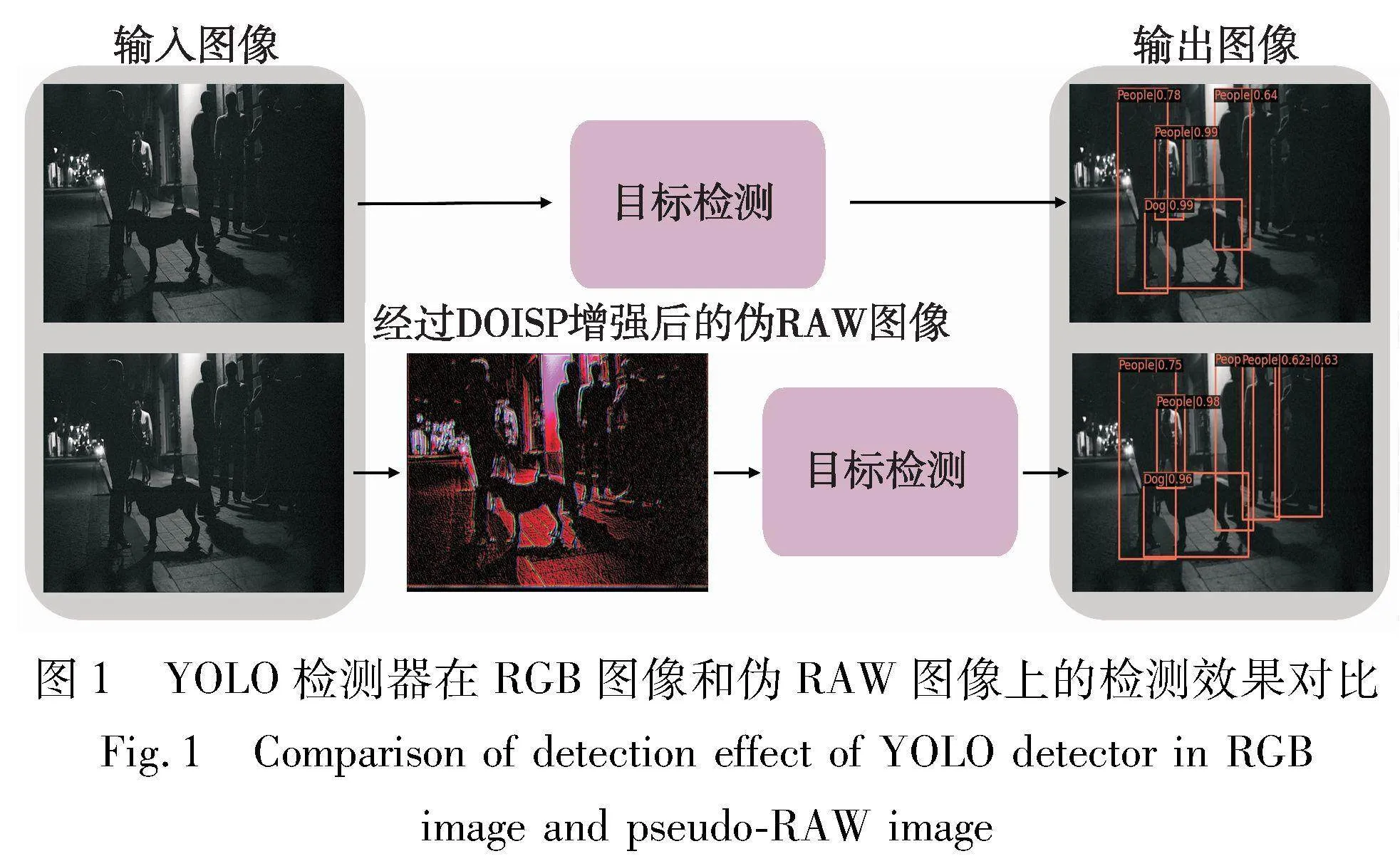
在图像成像原理中,RAW图像会经过ISP处理,包括图像压缩、白平衡矫正、黑电平矫正、色彩矫正、锐化等步骤。受图像成像原理启发,设计了一个伪ISP增强网络称为DOISP,直接从伪RAW图像中估计各类矫正参数,用于增强伪RAW图像。为了让MVP-Net能够面向机器视觉优化,本文将MVP-Net与经典目标检测网络YOLOv3[12]相结合,形成端到端的增强检测框架MVP-YOLO。MVP-Net依靠检测器的函数进行优化,使得增强后的图像能够适应检测器。如图1所示,YOLO在经过基于机器视觉优化的DOISP图像上的检测效果明显优于RGB图像,能够在低光环境下检测到更多的物体和种类。本文的主要贡献总结如下:
a)提出了一个新的面向机器视觉感知的暗光图像目标检测端到端框架MVP-YOLO。
b)MVP-Net由逆映射网络和DOISP网络构成。本文利用RAW图像的增强原理,提出了一种基于伪RAW图像的伪ISP增强网络DOISP,用于实现面向机器视觉感知的图像增强。在这个网络中,伪RAW图像通过一个逆映射网络将输入RGB变换为伪RAW图像。通过巧妙地利用RAW图像增强方法的优势,并在目标检测损失的约束下,DOISP使得检测器能够实现端到端的暗光目标检测。
c)大量的实验证明了本文方法在低光环境下,检测性能具有竞争力。
1 相关概念
1.1 目标检测
目标检测是计算机视觉中的基础研究问题之一。早期的目标检测方法主要是基于手工设计的特征和分类器[13]。近年来,深度学习中的卷积神经网络极大地推进了这个领域的发展。R-CNN[14]是第一个将深度学习引入目标检测任务的方法,它基于selective search生成候选区域,然后输入卷积网络提取特征,最后用SVM分类。尽管效果出众,但训练和检测都非常缓慢。为了提高检测速度和训练速度,SPPNet[15]提出了空间特征金字塔池化算法来避免重复计算特征,Fast R-CNN[16]则推进了检测算法的端到端训练。Faster R-CNN[17]使用了RPN生成候选框,成为第一个实时的深度学习目标检测系统。随后,单阶段检测器开始大放光彩,如YOLOv3[12]和SSD[18]。它们删除了候选框生成步骤,直接在密集的取样点上作分类和回归,因此速度相比于两阶段算法有明显提升。最近五年,目标检测技术也取得了一些新进展。FCOS[19]和FoveaBox[20]设计了新的Anchor-free范式。为了增强模型对全局的建模能力,DETR[21]首次引入了Transformer模块,将目标检测转换为一个集合预测问题。
1.2 恶劣环境下的目标检测
除了引言所提到基于图像增强[4~7]的方法,近年来,一些多任务学习(MTL-based)方法被提出用于改善恶劣环境下的目标检测性能。如Cui等人[22]提出了考虑光照因素和噪声因素的多任务自动编码变换模型MAET,探索了因照明变化引发图像退化的内在表示,可以同时预测图像的退化参数和检测对象。一些基于自适应域方法也被应用在暗光检测领域。如Sasagawa等人[23]提出了gule layer提取两个不同模型的潜在特征,用自适应域方法融合了两个模型,该方法可以直接从RAW图像中检测目标,比直接从RGB图像检测可以获得更好的性能。Liu等人[24]将检测驱动和基于梯度优化的DIP模块用于对多雾天气图像的自适应增强。Qin等人[25]将传统的拉普拉斯金字塔算法引入深度学习增强模型,构成了由检测驱动的端到端检测网络DE-YOLO。
1.3 伪RAW图像
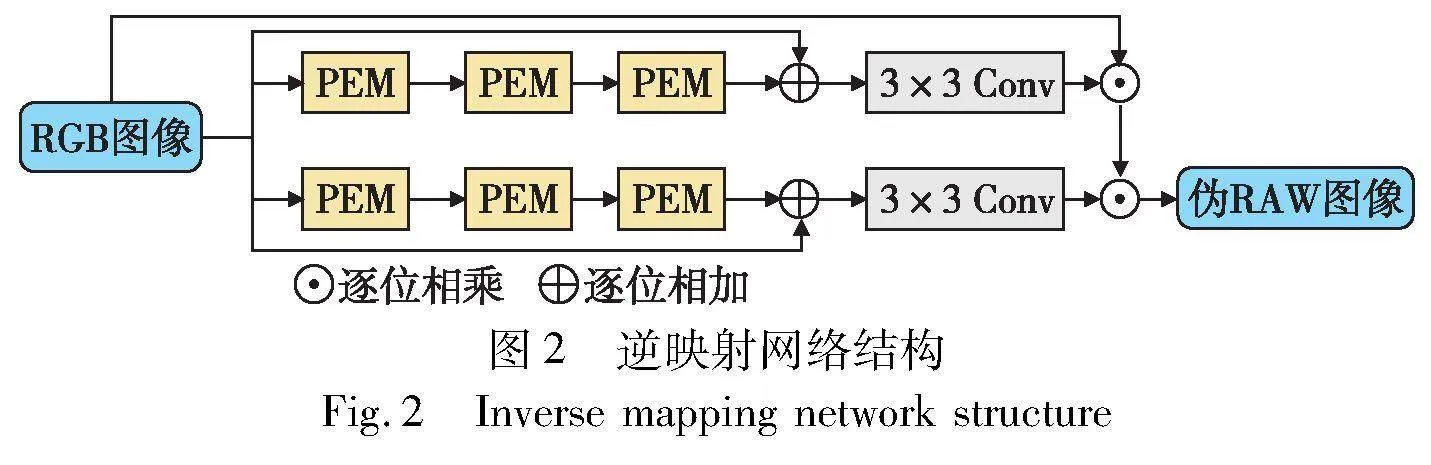
RAW图像实际是CMOS图像传感器将捕捉到的光源信号转换为数字信号的原始数据。由于RAW格式能够保留所有信息并具有极高的比特深度,在诸如图像超分辨率[26]、图像去噪[27]等领域展现出极高的应用潜力。然而,值得注意的是,由于RAW图像文件巨大,这在实际应用中面临推广的挑战。本文选用了关于RAW的逆映射网络[10]。如图2所示,逆映射网络与常见的U-Net[28]架构不同,没有采用自编码器结构,而是通过跳跃连接方式,利用逐位相乘和逐位相加的方式,维持图像原始分辨率,减少映射过程中的信息丢失。逆映射网络核心是像素增强模块(pixel-wise enhancement module)。像素增强模块主要通过深度可分离卷积对图像位置信息进行编码,并且通过残差结构,增强局部细节信息。
2 本文方法
2.1 联合暗光增强检测框架MVP-YOLO
在低光环境中,检测网络的检测性能通常会受到低光、大噪声等因素影响。为了解决这个问题,并且充分利用RAW信息的优势,本文提出了由暗光增强模型MVP-Net和检测模块YOLOv3构成的联合增强检测框架MVP-YOLO。如图3所示,MVP-Net负责面向机器视觉增强暗部细节的潜在判别特征,如暗部物体色彩、对比度等,并且抑制提升亮度带来的噪声信号。MVP-Net目的是在检测网络损失函数的帮助下,对图像进行面向机器视觉的增强,所以无须建立从低光图像到真实图像域的复杂映射,仅仅一些简单的网络结构就能发挥出令人惊讶的效果。
2.2 暗光增强模块MVP-Net
如图3所示,MVP-Net由逆映射网络和DOISP构成。首先RGB图像通过逆映射网络转换成对应的伪RAW图像,然后经过DOISP模块,对图像进行机器视觉方向的增强。在DOISP中,本文提出了两个子模块DO-AWB(detection-optimized auto white balance)和DO-CCMA(detection-optimized color correction matrix and gamma)来模拟ISP中的矫正流程。
在ISP处理中,自动白平衡处理的目的是通过改变图像中
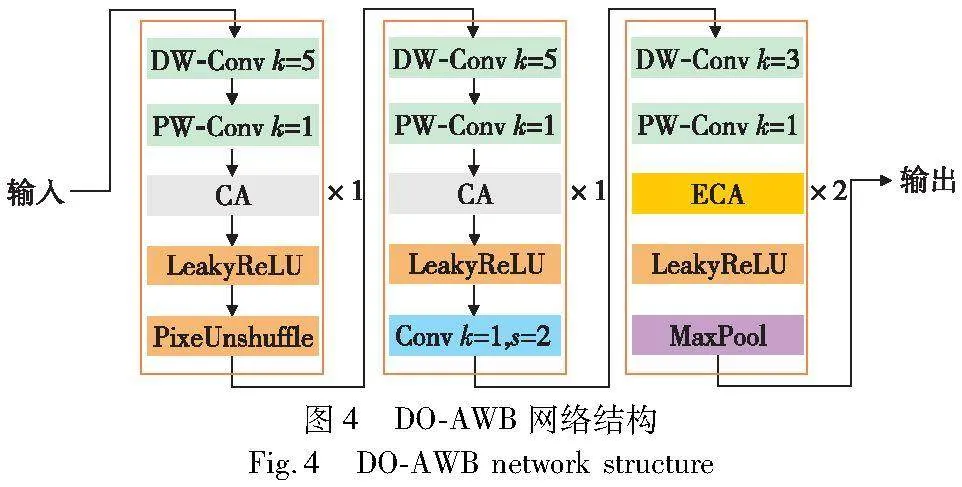
DO-AWB首先经过四个阶段,均使用深度可分离卷积提取图像基本特征,并且为了捕获多尺度信息,分别采用5×5、3×3、3×3、1×1的滤波器。DO-AWB网络结构如图4所示。前两个阶段增加了通道注意力CA(channel attention)[29]增强网络特征,后面两个阶段增加了ECA[30]注意力(efficient channel attention)增加网络特征。ECA注意力引入了一种1D卷积结构,可以高效地学习通道之间的交互依赖关系,并且通过1×1卷积核对通道进行建模,以生成注意力向量,与直接使用全连接层相比,其计算量更小,计算更高效。在四个下采样阶段中,为了进一步减少网络参数,在第一个阶段使用的是PixelUnshuffle[31]。PixelUnshuffle仅对图像的通道和空间结构进行重组,在卷积通道升维的同时不会引发额外的卷积计算量。为了进一步扩大感受野,第二个阶段使用的是卷积下采样。最后两个阶段下采样采用最大自适应池化。最大自适应池化能够将各种尺寸的输入特征图标转换为特定的维度,同时在降低计算成本的过程中,仍然维持了关键特征的信息。图像经过四个阶段的特征提取后,通过到双层MLP进行信息融合,生成颜色平衡矩阵。
经过DO-AWB对图像色彩和噪声进行了初步的调整后,图像在DO-CCMA网络调整下将会被进一步面向机器视觉的色彩调整,放大暗部物体细节特征。DO-CCMA包括色彩矫正矩阵参数、伽马矫正系数。DO-CCMA与DO-AWB结构类似,在经过四个阶段特征提取后送入到双层MLP中,学习色彩矫正矩阵、伽马矫正系数。在ISP处理中,色彩矫正矩阵是为了对光学器件合成得到的颜色进行校正,以满足人眼视觉感受。DO-CCMA的色彩矫正矩阵是模仿ISP中色彩矫正主流方案,即使用一个3×3的矩阵对图像通道进行色彩矫正。如式(4)所示,W2表示生成的颜色矫正矩阵参数值,ti,i∈(1,9)表示对每个通道的颜色矫正值。在DO-CCMA 中,还有参与亮度调节的Gamma系数,负责调节机器视觉下的图像全局亮度,Gamma系数如式(5)所示,W3表示DO-CCMA生成的Gamma系数值。DO-CCMA整个优化处理流程如式(6)所示,Xt代表最终增强后的图像,Xt将会被直接传入检测网络,用于后续检测。
3 实验结果与分析
3.1 实验数据集
两个真实场景下,弱光图像检测数据集将被用于实验中。本文针对两个数据集训练单独的模型进行公平对比。
Exdark[31]数据集是第一个针对低光照度图像检测的大规模数据集,总共包含7 363张低光照的图片。Exdark数据集的光照环境从极弱光环境到普通弱光环境,总计10种不同的光照条件。Exdark图像包括多种拍摄场景,如室内、室外、人像、建筑物、道路等,一共有12个类别。本实验中将每个类别80%数据将用于训练集,剩下20%将用于测试集。
UG2+DARK FACE[32]暗光人脸检测数据集一共有6 000张低光照人脸图像,其中90%图像将用于训练集,10%图像用于测试集。
3.2 实验细节
在本文中,为了保证公平对比和全面评估,经典的YOLOv3检测器将被作为检测模块。所有的检测模块都带有基于COCO数据集的预训练权重。本文基于开源目标检测工具箱MMDetection实现了联合暗光增强检测框架MVP-YOLO。MVP-YOLO在训练过程中使用了数据增强策略。例如随机裁剪、随机翻转,并且将图像resize到608×608,数据批处理大小是8,优化器SGD optimizer,初始学习率0.001且带step学习率衰减,训练25个epochs。为了稳定训练,早期训练时加入了学习率预热策略。所有实验均基于单张NVIDIA RTX 3090 GB。
3.3 评估指标
mAP(mean average precision)[33]是一种用于评估目标检测算法性能的指标,它是精度(precision)与召回率(recall)之间的综合度量。mAP在计算机视觉领域被广泛用于评估目标检测器的性能。实验采用mAP(50%)作为评估指标。
3.4 对比实验
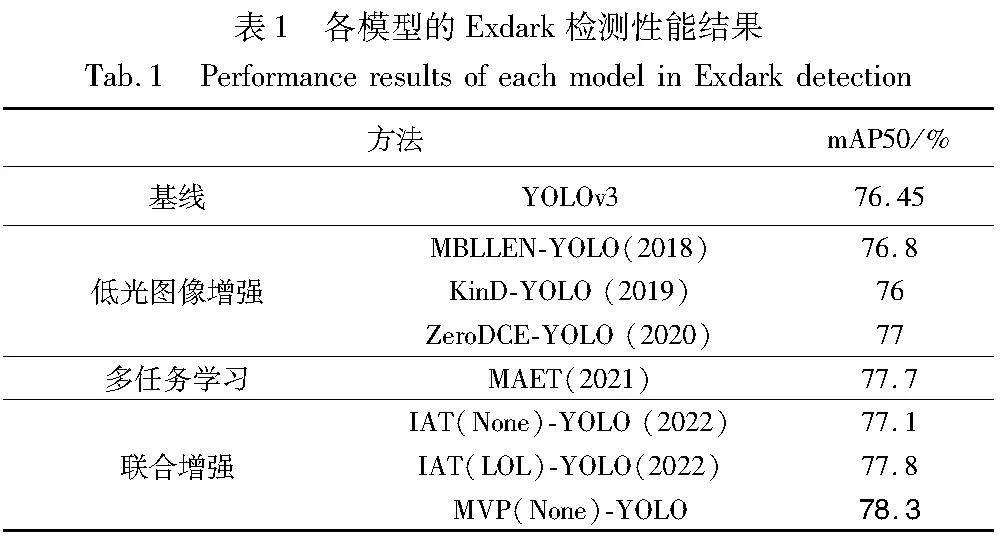
将本文方法与几种最新的方法进行了综合比较,即MBLLEN[34]、KIND[35]、ZeroDCE[36]、MAET[22]、IAT[9]。其中MBLLEN 、KIND、ZeroDCE暗光增强模型属于低光图像增强方法,在YOLO检测器前的图像将被预训练模型先增强。MAET暗光检测方法是在合成的暗光COCO数据集上预训练,然后在Exdark数据集上微调,属于多任务学习方法。IAT暗光增强模型在暗光增强数据集LOL[37]上进行预训练,然后和YOLO检测器构成端到端联合检测网络IAT(LOL)-YOLO,属于联合增强方法。IAT(None)-YOLO是指IAT未在暗光增强数据集LOL上进行预训练,直接与YOLO检测器构成端到端联合检测网络。各类网络模型在Exdark数据集上的检测性能如表1所示。由表1可知:a)在基于人眼视觉恢复的低光图像增强模型中简单添加YOLO检测器并不能显著提高暗光场景下的检测效果,甚至可能导致原方法的检测性能下降,如MBLLEN-YOLO、KinD-YOLO;b)在多任务学习和联合训练方法,YOLO检测器在暗光场景下的检测性能有一定程度提升,MVP-YOLO相比YOLO提高了1.85%;c)在联合训练范式中,MVP-YOLO也展现出一定的竞争力。IAT(LOL)方法性能优于IAT(None),而MVP-Net(None)不需要在其他暗光数据集上进行预训练,比IAT(LOL)方法获得了更强大的检测性能,提升了0.5%。
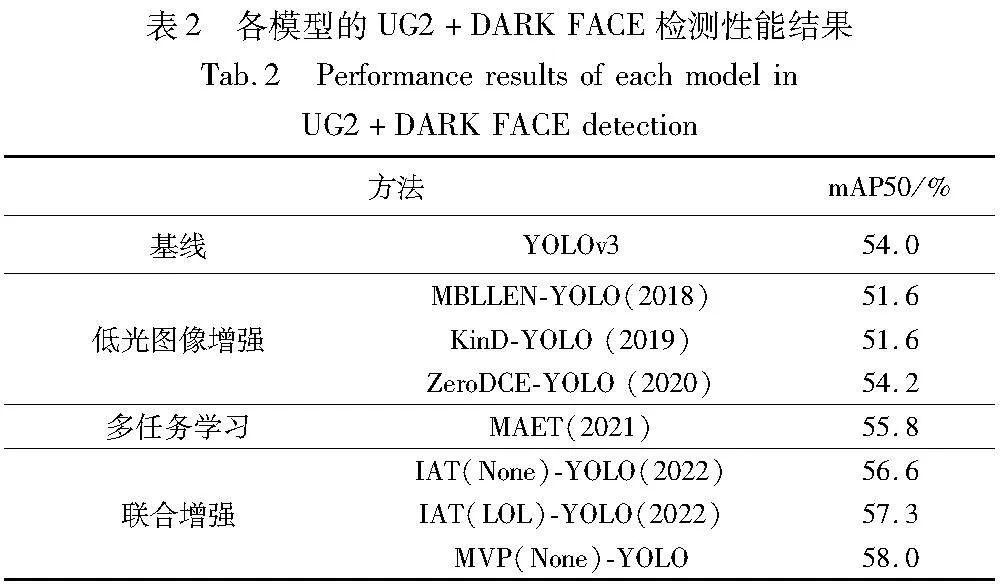
为了进一步验证MVP-Net模型的有效性,本文在UG2+DARK FACE数据集上进行了类似的对比实验。如表2所示,MVP-YOLO方法取得了最好的检测性能结果,比次优的IAT-YOLO方法提升了0.7%,相比于基线模型YOLOv3提高了4%。KinD-YOLO出现了比在表1实验时更加明显的性能下降的情况,在表2中相比于基线下降达2.4%。实验结果表明,MVP-YOLO框架在多个暗光检测数据集上都能得到增强,验证了模型的有效性。
3.5 可视化分析
为了更好地说明基于机器视觉增强的检测器在低光环境下的检测性能优于基于人眼视觉增强的检测器,选取了各模型在Exdark数据集中的两组检测图像可视化,并且结合表1和2进行比较分析。
两组检测图像可视化如图5所示。第一组图像是在夜景街道上,MEBBLN、Kind、ZeroDCE均为基于低光图像增强的方法,该方法虽然对图像亮度有一定程度的提升,使得人眼在感官上有一定程度增强,但是也会放大图像噪声,出现色彩过曝的情况。从检测效果看,检测器在基于低光增强方法的图像上都未能完整检测出夜景中的人和摩托车。从表1可知,检测器在基于低光图像增强的方法上,出现了一定程度的性能下降情况。这是因为该类方法为了迎合人眼视觉,设计了许多增强损失函数,例如VGG16感知损失、结构相似性损失以及L1损失函数。尽管这些增强损失函数在减小训练和测试图像之间的域间距离方面表现出色,但在此过程中,它们可能会忽视甚至干扰那些对物体检测具有关键性意义的结构性特征,从而影响后续检测器的性能。从MVP-YOLO检测效果可以看到,MVP-YOLO检测出的人和摩托车数量最多,检测效果最接近真实框效果,并且检测框的置信度也明显高于其他方法。
在第一组图像中,MVP-YOLO能够检测出左侧夜景街道极暗条件下的人和摩托车。在第二组图像中,MVP-YOLO能在灯光昏暗的教室检测出远处和右侧被其他方法漏检的课桌,而且边框回归明显接近真实框位置。这一成绩可以归因于两个关键技术因素。首先,通过逆映射网络,低光图像被映射到伪RAW图像的特征空间,从而使得检测器能在机器视觉成像条件下进行目标检测。其次,MVP-Net整合了DOISP增强模块,该模块不仅在机器视觉方向上增强了图像的色彩和亮度,而且通过采用多种注意力与下采样结合设计模式生成自适应参数,并直接在伪RAW图像上进行优化。这一设计成功地保留了对目标检测具有决定性意义的结构性特征,进而减小了对这些特征的干扰,在一定程度上提升了检测性能。
3.6 消融实验
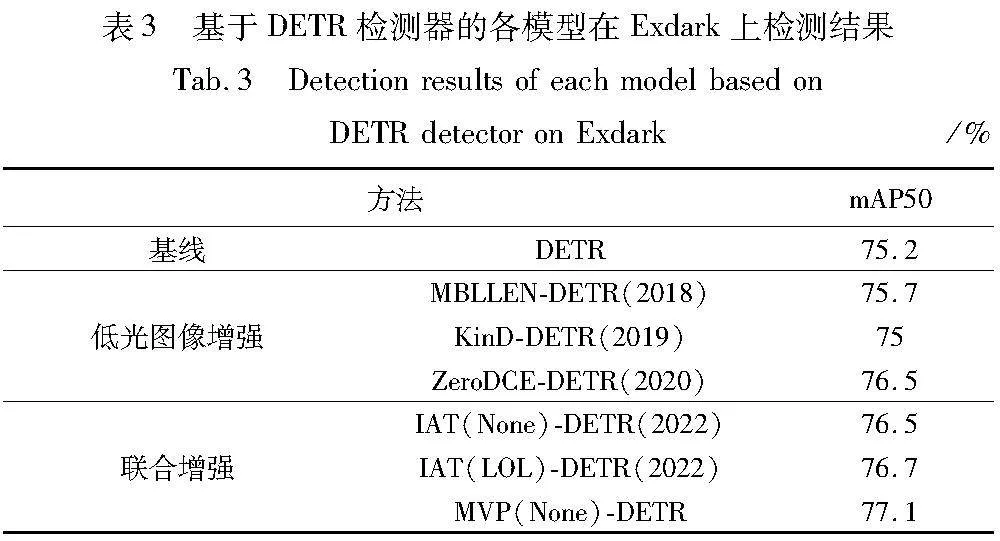
首先,为了评估MVP-Net模型的泛化性,MVP-Net模型被用于与不同架构的检测器联合增强训练。本文将MVP-Net与基于Transformer架构的检测器DETR[21]构成DREE-DETR联合检测框架,并且在Exdark数据集上评估其检测性能。与前面的实验类似,在训练过程中采用了随机裁剪、随机Resize、随机翻转等数据增强策略,使用Adam优化器训练了20轮epochs。表3显示了各模型在Exdark数据集上的检测性能结果,MVP-DETR实现了最佳的检测性能,并且相比DETR检测精度提升1.9%,与IAT-DETR相比也有0.4%检测精度的提升,说明MVP-Net模型可以有效地应用在不同架构的检测器上,提升检测模块的暗光场景检测精度,具有一定的泛化性。
MVP-Net的适应性来自MVP和检测器之间直接的端到端训练。训练时,逆映射网络会自动根据检测器传来的梯度优化信息进行权重调整,将RGB图像映射成伪RAW图像特征空间。但是由于每类检测器架构不尽相同,所以传递的优化信息存在不同,进而导致逆映射网络自适应不同的检测器架构,从而提高了MVP-Net的泛化性。
DOISP网络由DO-CCMA和DO-AWB模块构成。为了探究DO-CCMA与DO-AWB模块对MVP-Net模型的影响,本文进行了DO-CCMA和DO-AWB模块的消融实验。DO-CCMA与DO-AWB模块是对伪RAW图像特征进行增强。从表4可以看出,如果不添加DOISP网络,只添加逆映射网络,相比原有的YOLO检测器有小幅提升。逆映射网络将RGB转换为伪RAW图像特征空间,给检测器提供了一个机器视觉下的低光图像,更加符合检测器的视角,一定程度上提高了检测性能。
DO-AWB模块的加入使MVP-YOLO相比YOLO检测性能有1.05%的上升。DO-AWB模块中引入了ECA注意力机制和多尺度下采样结构,引导网络在捕捉全局特征时重点关注图像光照分布情况,最后生成自适应参数调整全局的机器视觉下的色彩平衡分布,有效提高了MVP-YOLO对低光环境的感知能力。DO-AWB和DO-CCMA模块联合时,MVP-YOLO发挥出最佳性能,其检测精度相比YOLO提高了1.85%。DO-CCMA模块中不仅引入了能矫正色彩参数的CCM矩阵,并且设计了伽马参数,通过伽马亮度调节提升机器视觉下的全局图像亮度。
在DO-CCMA和DO-AWB模块中,使用了CA通道注意力和ECA注意力机制提高网络提取特征的能力。本文也对这两种注意力对DOISP的贡献度进行了评估。如表5所示,如果在MVP-YOLO中不添加任何注意力机制,其检测性能mAP50达77.4%,相比于YOLO提升了0.95%。如果只添加CA注意力在MVP-YOLO中,提升效果不明显。如果只添加ECA注意力在MVP-YOLO中,相比YOLO提升了1.45%。CA和ECA注意力均添加在MVP-YOLO中将实现最佳的检测精度。从对比数据来看,得益于ECA注意力的1D卷积层近似通道注意力减少了计算量,可以建立更深层的注意力模块,捕捉到更丰富的特征,感知暗部细节。ECA注意力比CA注意力对DOSIP模块的贡献度更高。
4 结束语
在本文中,提出了一种面向机器视觉感知的暗光图像增强网络MVP-Net。该模型借助了逆映射网络将RGB图像映射成伪RAW图像,为了充分发挥伪RAW图像的优势,设计了用于增强伪RAW图像的DOISP网络。DOISP利用图像成像原理,设计了DO-CCMA和DO-AWB子模块分别用于增强图像机器视觉下的白平衡、色彩显示和亮度。在两个子模块中,利用不同尺度的深度可分离卷积提取特征,以增强图像的全局特征和降低模型参数量,并且引入了ECA和CA注意力,促使多通道信息融合,引导模型关注局部暗光场景。大量充分实验证明,MVP-Net与检测器形成的端到端检测网络较原有的检测器,不仅在多个真实场景的低光检测数据集上有明显的检测性能提升,而且能适配多种架构的检测器,如YOLO、基于Transformer架构的检测器。MVP-YOLO与现有其他的低光增强检测方法相比,可以识别出更多在低光环境下的类别和物体。后续工作将继续探索MVP-Net如何在维持检测性能和低参数量的同时,进一步提高模型推理速度。
参考文献:
[1]Abdullah-Al-Wadud M, Kabir M H, Dewan M A A, et al. A dyna-mic histogram equalization for image contrast enhancement[J]. IEEE Trans on Consumer Electronics, 2007,53(2): 593-600.
[2]Land E H, McCann J J. Lightness and Retinex theory[J]. Journal of The Optical Society of America, 1971,61(1): 1-11.
[3]Jobson D J, Rahman Z, Woodell G A. Properties and performance of a center surround Retinex[J]. IEEE Trans on Image Processing, 1997,6(3): 451-462.
[4]Lore K G, Akintayo A, Sarkar S. LLNet: a deep autoencoder approach to natural low-light image enhancement[J]. Pattern Recognition, 2017,61: 650-662.
[5]ShenWlbDrKuLW04CxKLcihBFT2gQEM2s2A6upbHSprqE6RU= Liang, Yue Zihan, Feng Fan, et al. MSR-Net: low-light image enhancement using deep convolutional network[EB/OL]. (2017-11-07). https://doi.org/10.48550/arXiv.1711.02488.
[6]Fan Chimao, Liu T J, Liu K H. Half wavelet attention on M-Net+ for low-light image enhancement[C]//Proc of IEEE International Conference on Image Processing. Piscataway, NJ: IEEE Press, 2022: 3878-3882.
[7]Jiang Yifan, Gong Xinyu, Liu Ding, et al. EnlightenGAN: deep light enhancement without paired supervision[J]. IEEE Trans on Image Processing, 2021, 30: 2340-2349.
[8]Xing Yazhou, Qian Zian, Chen Qifeng. Invertible image signal processing[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press,2021: 6287-6296.
[9]Chen Chen, Chen Qifeng, Xu Jia, et al. Learning to see in the dark[C]//Proc of IEEE Conference on Computer Vision and Pattern Re-cognition. Piscataway, NJ: IEEE Press,2018: 3291-3300.
[10]Cui Ziteng, Li Kunchang, Gu Lin, et al. You only need 90K para-meters to adapt light: a light weight transformer for image enhancement and exposure correction[EB/OL]. (2022-10-08). https://arxiv.org/abs/2205.14871.
[11]Zamir S W, Arora A, Khan S, et al. CycleISP: real image restoration via improved data synthesis[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press,2020: 2693-2702.
[12]Redmon J, Farhadi A. YOLOv3: an incremental improvement[EB/OL]. ( 2018-04-08). https://doi.org/10.48550/arXiv.1804.02767.
[13]Viola P, Jones M J. Robust real-time face detection[J]. International Journal of Computer Vision, 2004, 57: 137-154.
[14]Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2014: 580-587.
[15]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2015,37(9): 1904-1916.
[16]Girshick R. Fast R-CNN[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press,2015: 1440-1448.
[17]Ren Shaoqing, He Kaiming, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proc of the 28th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015:91-99.
[18]Liu Wei, Anguelov D, Erhan D, et al. SSD: single shot multibox detector[C]//Proc of the 14th European Conference on Computer Vision. Cham:Springer, 2016: 21-37.
[19]Tian Zhi, Shen Chunhua, Chen Hao, et al. FCOS: fully convolutio-nal one-stage object detection[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 9626-9635.
[20]Kong Tao, Sun Fuchun, Liu Huaping, et al. FoveaBox: beyond anchor-based object detection[J]. IEEE Trans on Image Proces-sing, 2020, 29: 7389-7398.
[21]Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//Proc of European Conference on Computer Vision. Cham:Springer, 2020: 213-229.
[22]Cui Ziteng, Qi Guojun, Gu Lin, et al. Multitask AET with orthogonal tangent regularity for dark object detection[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 2533-2542.
[23]Sasagawa Y, Nagahara H. YOLO in the dark-domain adaptation me-thod for merging multiple models[C]//Proc of the 16th European Conference on Computer Vision. Cham: Springer, 2020: 345-359.
[24]Liu Wenyu, Ren Gaofeng, Yu Runsheng, et al. Image-adaptive YOLO for object detection in adverse weather conditions[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 1792-1800.
[25]Qin Qingpao, Chang Kan, Huang Mengyuan, et al. DENet: detection-driven enhancement network for object detection under adverse weather conditions[C]//Proc of the 16th Asian Conference on Computer Vision. Berlin: Springer-Verlag, 2022: 491-507.
[26]Zhang Xuaner, Chen Qifeng, Ng R, et al. Zoom to learn, learn to zoom[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 3762-3770.
[27]Wang Yuzhi, Huang Haibin, Xu Qin, et al. Practical deep raw image denoising on mobile devices[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2020: 1-16.
[28]Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//Proc of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2015: 234-241.
[29]Hu Jie, Shen Li, Sun Gang. Squeeze-and-excitation networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018: 7132-7141.
[30]Wang Qilong, Wu Banggu, Zhu Pengfei, et al. ECA-Net: efficient channel attention for deep convolutional neural networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press,2020: 11534-11542.
[31]Loh Y P, Chan C S. Getting to know low-light images with the exclusively dark dataset[J]. Computer Vision and Image Understan-ding, 2019, 178: 30-42.
[32]Yang Wenhan, Yuan Ye, Ren Wenqi, et al. Advancing image understanding in poor visibility environments: a collective benchmark study[J]. IEEE Trans on Image Processing, 2020, 29: 5737-5752.
[33]Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: common objects in context[C]//Proc of the 13th European Conference on Computer Vision. Cham: Springer,2014: 740-755.
[34]Lyu Feifan, Lu Feng, Wu Jianhua, et al. MBLLEN: low-light image/video enhancement using CNNs[C]//Proc of British Machine Vision Conference. 2018.
[35]Zhang Yonghua, Zhang Jiawan, Guo Xiaojie. Kindling the darkness: a practical low-light image enhancer[C]//Proc of the 27th ACM International Conference on Multimedia. New York: ACM Press, 2019: 1632-1640.
[36]Guo Chunle, Li Chongyi, Guo Jichang, et al. Zero-reference deep curve estimation for low-light image enhancement[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 1780-1789.
[37]Wei Chen, Wang Wenjing, Yang Wenhan, et al. Deep Retinex decomposition for low-light enhancement[EB/OL]. (2018-08-14). https://doi.org/10.48550/arXiv.1808.04560.
