
基于特征级损失和可学习噪声的医学图像域泛化方法
2024-07-31 00:00:00史轶伦于磊徐巧枝
计算机应用研究 2024年6期
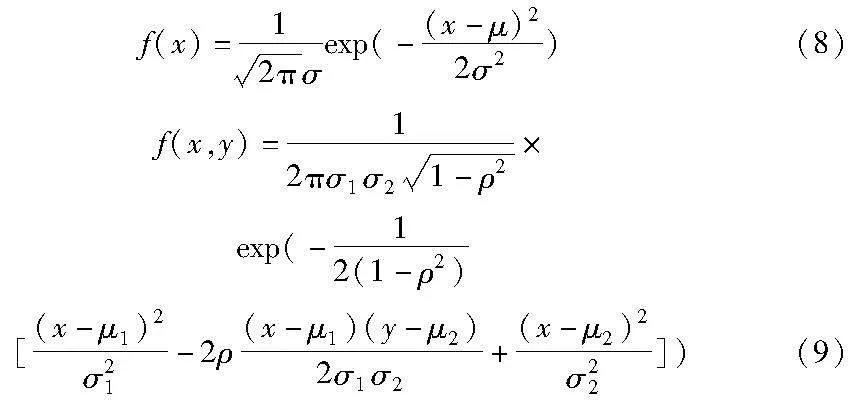


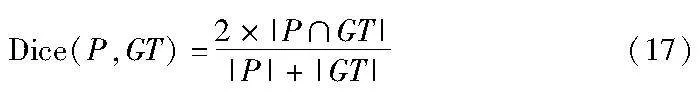
摘 要:在医学图像分割任务中,域偏移问题会影响训练好的分割模型在未见域的性能,因此,提高模型泛化性对于医学图像智能模型的实际应用至关重要。表示学习是目前解决域泛化问题的主流方法之一,大多使用图像级损失和一致性损失来监督图像生成,但是对医学图像微小形态特征的偏差不够敏感,会导致生成图像边缘不清晰,影响模型后续学习。为了提高模型的泛化性,提出一种半监督的基于特征级损失和可学习噪声的医学图像域泛化分割模型FLLN-DG,首先引入特征级损失改善生成图像边界不清晰的问题,其次引入可学习噪声组件,进一步增加数据多样性,提升模型泛化性。与基线模型相比,FLLN-DG在未见域的性能提升2%~4%,证明了特征级损失和可学习噪声组件的有效性,与nnUNet、SDNet+AUG、LDDG、SAML、Meta等典型域泛化模型相比,FLLN-DG也表现出更优越的性能。
关键词:医学图像分割; 域泛化; 表示学习; 特征级损失; 可学习噪声
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)06-041-1882-06
doi:10.19734/j.issn.1001-3695.2023.08.0408
Domain generalization method for medical images based onfeature-level loss and learnable noise
Abstract:In medical image segmentation tasks, the domain shift problem affects the performance of trained segmentation models in the unseen domain. Therefore, improving model generalization is crucial for the practical application of intelligent models for medical images. Representation learning is currently one of the dominant methods for solving domain generalization problems, mostly using image-level loss and consistency loss to supervise image generation. However, it is not sensitive enough to the deviation of small morphological features of medical images, which can lead to unclear edges of the generated images and affect the subsequent learning of the model. In order to improve the generalization of the model, this paper proposed a semi-supervised feature-level loss and learnable noise domain generalization(FLLN-DG) method for medical image segmentation. Firstly, the introduction of feature level loss improved the problem of unclear boundaries of the generated images. Secondly, the introduction of the learnable noise components further increased the data diversity and improved the model generalization. Compared with the baseline model, FLLN-DG improves the performance in the unseen domain by 2% to 4%, which demonstrates the effectiveness of to feature-level loss and to learnable noise components. FLLN-DG also has the best generalization and segmentation results compared to typical generalization models such as nnUNet, SDNet+AUG, LDDG, SAML and Meta.
Key words:medical image segmentation; domain generalization; representation learning; feature-level loss; learnable noise
0 引言
近年,基于深度学习技术的医学图像智能分割模型(如U-Net[1]、ResNet[2]和VGG[3]等)表现出优越的性能,有效提升了疾病诊断的效率和准确率。大多数分割模型都假设训练数据与测试数据满足独立同分布(independent and identically distributed,i.i.d)[4],但实际上,由于成像设备和成像条件的不同,训练数据与测试数据并不满足该假设,即存在域偏移问题,将导致模型实际部署后性能急剧下降。
域泛化技术无须访问目标域数据就可提升模型在不同域的泛化性,是解决域偏移问题的重要方法之一[4]。而增加数据多样性,让模型学习更多风格的数据,是目前实现域泛化的主要思想和技术[5]。
医学图像域泛化分割模型通常分为数据增强和图像分割训练两个阶段。其中,数据增强是关键部分,大多采用基于表示学习的方法[6],即将图像分解为域不变特征和域可变特征,之后通过混合、交叉合并等方法来增强数据,进而提高模型泛化能力。在数据增强过程中,现有研究[7~9]大多采用图像级损失和一致性损失来监督图像生成,以保持域不变特征,缺点是对医学图像微小形态特征的偏差不够敏感,会导致生成图像边缘不清晰,影响模型的后续学习。此外,简单将域不变特征和域可变特征混合的数据增强方法并不能很好地模拟实际的域偏移现象,限制了模型的泛化性。一些研究通过在数据增强过程中引入噪声来提高模型泛化性[10~12],但其添加方式相对简单,可能导致图像边界损坏,影响模型提取特征的能力。
针对上述问题,本文首先提出一种基于特征级损失的方法,通过将生成图像映射到特征空间,并计算特征级损失,改善了生成图像边缘不清晰的问题。其次,本文在图像生成过程中引入可学习噪声,使编码器和解码器能够学习噪声对生成图像的影响,进而使分割网络中的噪声添加更合理。最后,为了缓解医学图像标注少对模型性能的影响,本文采取半监督学习策略,通过共同训练有标签和无标签数据,提高了模型的泛化性能。
1 相关工作
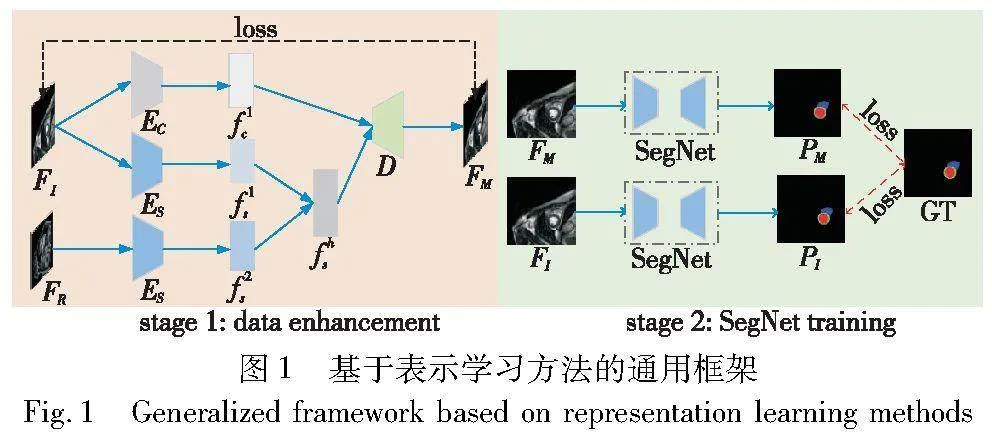
基于表示学习的医学图像域泛化方法的主要思想是让模型学习域不变的特征表示,忽略域可变信息,如图1所示。该过程分为两个阶段:第一阶段为数据增强。首先选择一个已知域的医学图像FI并将其分解为风格信息f1s与内容信息f1c,其中风格信息与域相关,称为域可变信息,内容信息与域无关,称为域不变信息;再选择其他已知域的医学图像FR,提取其风格信息f2s;然后将f1s与f2s混合,再与内容信息f1c组合,生成更多内容相同而风格不同的图像,它们共用图像FI的标注结果,达到丰富标注数据集的目的。第二阶段为分割网络训练。使用成对标注结果相同的增强图像与原始图像共同训练网络,计算它们的相似度损失,使模型更关注内容信息,忽略风格信息,进而实现域泛化。
目前,域泛化研究主要针对数据增强阶段进行改进,目标是提升增强数据的质量,最终提高模型的泛化性。例如,Huang等人[13]利用轮廓图和分割图分离风格信息和内容信息,使模型能够持续学习。叶怀泽等人[14]定义了多个特定领域重构迁移网络,提高对风格特征的提取能力。Liu等人[15]引入元学习方法,使内容特征与风格特征尽可能远离,以实现风格迁移。这些方法均提高了模型的泛化能力,但引入新网络,导致模型参数量和训练难度都有所增加。
一些研究集中于风格信息的提取,以便生成风格多样化数据,实现模型泛化。例如,刘义鹏等人[16]把风格特征分为低频和高频信息,对低频分量进行随机融合,中频分量使用随机权重增强,使风格提取更精细。Han等人[17]改进了傅里叶变化,使用窗格防止频域泄露,更精细地提取了输入图像的不同特征。Liu等人[18]加入分辨率增强组件,便于生成风格更加多样的图像。Li等人[19]通过变分编码器学习具有代表性的特征空间,以捕获不同域数据的共享信息。上述方法只使用图像级损失来重建图像,可能导致图像边界不清晰。
还有一些研究通过增加噪声的方式进一步提升数据的风格多样性。例如,Chen等人[20]利用真实对抗生成数据的方法,通过增加多种扰动生成多样化数据,并且使用四种数据扩充方案对每种方案赋予权重,通过对抗的方式获取数据增强的最优方案,生成具有挑战性的示例。Hu等人[21]通过对图像添加随机噪声和反转增加图像的多样性。这些方法通过对图像添加噪声扩充了数据的风格,但添加方式过于简单,可能会导致图像边界信息丢失,从而影响模型的精确性。
综上,现有研究在图像重建过程中均使用图像级损失,通过最小化生成图像和原始图像之间的差异来训练网络。虽然取得了一定效果,但对图像细节的捕捉不够精细,可能会导致图像边界模糊,从而使分割模型难以收敛并影响其性能。在重建图像中添加噪声,可增强数据的多样性,但直接对重建图像添加噪声,也会导致图像边界信息丢失,影响模型性能。针对这些问题,本文提出一种半监督的基于特征级损失和可学习噪声的医学图像域泛化分割模型FLLN-DG(feature-level loss and learnable noise domain generalization,FLLN-DG),其创新点主要包括三方面:
a)在图像生成阶段引入特征级损失,提升图像对细节的还原度,使生成图像边界更加清晰,进而更好地训练分割网络,提升模型的泛化性。
b)在图像生成阶段引入噪声组件,使网络能学习噪声对生成图像的影响,确保分割阶段增加的噪声不会影响网络性能,增加了数据多样性,进一步提升了模型泛化性。
c)引入半监督分割框架,利用无标签数据和有标签数据共同训练分割网络,缓解医学图像标注样本少的问题,提升模型性能。
2 基于特征级损失和可学习噪声的医学图像域泛化分割模型
2.1 方法概述
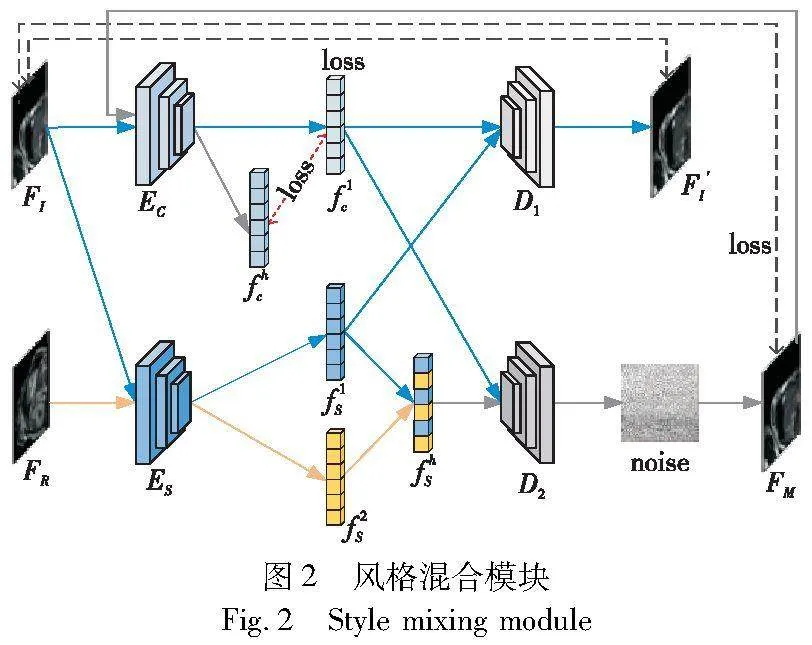
本研究提出基于表示学习的FLLN-DG模型,整体架构与图1类似,分为数据增强和分割训练两阶段。首先利用生成网络生成多样化数据,之后利用增强数据训练分割网络,提高模型的泛化能力。数据增强阶段的主要组件是风格混合模块,负责将不同域的数据风格进行混合,为分割网络提供具有相同内容但风格不同的输入图像。分割训练阶段包括两个分割网络,它们相互学习,使其分割结果一致,最终实现模型的精准分割。
风格混合模块首先从一个域选择一张图像作为原始输入数据FI,提取其风格特征f1s和内容特征f1c,再从另一个域随机选择一张图像FR,提取其风格特征f2s,然后将提取到的风格特征f1s与f2s按一定比例混合得到fhs,再将其与FI的内容特征f1c进行组合,生成与原始图像内容相同但风格不同的图像F′M。为了增加图像风格的多样性,对生成的图像添加高斯噪声,得到最终生成图像。
分割训练阶段由两个结构相同但初始权重不同的分割网络组成,采用交叉伪监督方式的半监督架构[22]。为了解决域偏移问题中由于风格差异较大导致的伪标签质量较低的问题,本文引入置信度交叉感知方法[23],利用KL散度对得到的伪标签进行判断,改进伪标签质量,提高半监督网络性能。两个分割网络的输入分别为原始图像FI和生成图像FM。FM的内容特征来自FI,所以具有与FI一致的分割结果,本文将两个分割结果的均值作为最终分割预测结果。两个分割网络的输入内容相同,应具有相同的分割结果,因此两个网络可以相互学习,相互指导,最终模型收敛,达到良好的分割性能。在测试阶段,将一张测试图片送入两个网络得到预测结果后取均值,即为模型的分割结果。
2.2 风格混合模块
现有基于表示学习的方法大多利用图像重建来增强数据,提升模型泛化性。通过计算重建图像与原始输入图像的像素级损失来训练网络,忽略了图像特征级别的约束,会导致图像细节的还原度不高,进而影响分割网络的训练。本文在风格混合模块中引入图像特征级损失来弥补该不足,如图2所示。
风格混合模块由内容编码器EC,风格编码器ES,解码器D1、D2和噪声组件构成。内容编码器EC负责提取与分割任务相关的内容特征,即图像的边界信息。风格编码器提取与分割任务无关的风格特征,主要包括光照强度、背景信息等。解码器D1将图像FI从特征空间映射回图像空间,通过与原始图像FI计算图像级损失,训练编码器EC、ES和解码器D1。解码器D2将混合后的风格特征fhs与原始图像FI的内容特征f1c解码,得到与FI内容相同但风格不同的图像。再利用噪声组件对生成的图像添加高斯噪声,得到最终的生成图像FM。然后计算FM与FI的损失,并将其映射到内容特征空间,进一步计算它们的特征级损失,以保证生成图像的边界更清晰。
具体来说,对于原始输入图像FI,将其送入内容编码器EC提取其内容特征f1c,送入风格编码器ES提取其风格信息f1s,再将提取到的特征送入解码器D1中还原图像,得到原始输入图像的还原图像F′I,如式(1)所示。之后使用一致性损失约束生成图像,与原始图像保持一致,如式(2)所示,其中,LOSSMSE是均方差损失函数。
F′I=D1(f1c,f1s)=D1[EC(F1),ES(FI)](1)
LR1=LOSSMSE(F′I,FI)(2)
然后,将随机选取的图像FR送入风格编码器ES,以提取其风格信息f2s,再将原始输入图像FI的风格特征f1s与FR的风格特征f2s混合,得到混合风格特征fhs,α为图片混合率,如式(3)所示。
fhs=αf1s+(1-α)f2s(3)
将fhs与f1c共同输入到解码器D2,生成具有混合风格的图像FM′,然后对图像加入高斯噪声扰动,使数据更具多样性,如式(4)所示。由于FM的内容特征来自FI,所以它们具有相同的内容,故使用一致性损失来训练生成网络,如式(5)所示。
FM=D2(fhs,f1c)+noise(4)
LR2=LOSSMSE(FM,FI)(5)
现有方法使用图像级损失保证生成图像的质量,但图像级损失细节捕获较差,导致生成图像的边界相对模糊。为了使生成图像具有更好的边界信息,文章引入特征级损失,即将生成的FM再次送入内容编码器EC中获取其内容特征,通过约束其内容特征一致,以确保生成图像的边界清晰,为后续分割提供有效指导,该过程如式(6)所示。最后,基于特征级损失的生成网络总损失如式(7)所示。
Lf=LOSSMSE(fhc,f1c)=LOSSMSE(EC(FM),EC(FI))(6)
LOSS=Lf+LR1+LR2(7)
2.3 噪声组件
相较于自然图像,医学图像标注样本少,很难获取到多样化的数据来训练网络,从而提升模型泛化性。一些研究在分割阶段对图像直接添加一种或多种噪声来增加数据多样性,模拟域偏移现象,但这样会导致数据边界不清晰,使模型无法更好地训练。为解决该问题,本文在图像生成阶段引入噪声组件,让噪声也参与图像生成的训练,使得生成网络能够适应噪声对图像的扰动,即使在分割网络中添加噪声也不会导致图像边界差异太大,影响分割网络的训练,同时也实现了增强数据多样性的目的。
由于拍摄设备不同、光照不同,可能会在图像中引入高斯噪声[24],医学图像的域偏移问题通常也是类似原因,所以本文使用高斯噪声对生成图像进行扰动,以增强模型的泛化性。高斯噪声的分布概率服从高斯分布,如式(8)所示,其中μ是服从高斯分布中的均值,σ代表标准差,exp指以常数e为底的指数函数,该表达式为一维表达。本文使用2D医学图像进行模型的训练,所以对应的表达如式(9)所示,其中x和y是二维随机变量的取值,μ1、μ2是两个维度的均值,σ1、σ2是两个维度的标准差,ρ表示相关系数,相关系数用来衡量两个变量相关程度的统计指标。
本方法将添加噪声后的生成图像与重建图像进行相似度比较,保证添加噪声后的图像与原始图像相似,并且将图像送入编解码网络提取其内容特征,保证生成图像的边界完整。
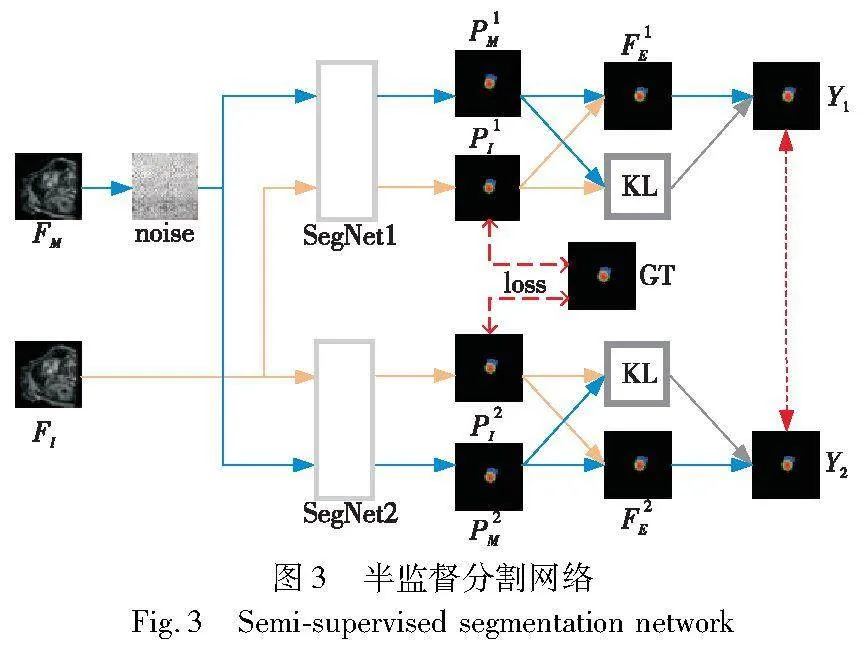
2.4 半监督分割网络
为解决医学图像标注样本少的问题,本方法采用半监督框架训练分割模型,使用两个结构相同但初始权重不同的网络分割内容相同的图片,分割结果相互指导,使网络最终收敛,如图3所示。
首先,对数据增强阶段生成图像FM添加噪声,然后将其与FI同时送入2个分割网络,得到4个分割预测结果,分别是P1M、P1I、P2M、P2I。之后,两个分割网络分别对两张图像的分割结果计算均值,分别得到该分割网络的预测结果FiE,i是分割网络编号,如式(10)(11)所示。
为了进一步提升分割预测结果的可靠性,引入KL散度置信度感知算法,之后使用交叉熵损失函数优化网络。置信度感知算法如式(12)(13)所示,其中Y1、Y2是F1E、F2E预测结果的one-hot向量,Lce表示交叉熵损失函数。对于无标注数据,使用无监督损失,如式(14)所示。
L1=E[Lce(F2E,Y1)](12)
L2=E[Lce(F1E,Y2)](13)
Lc=L1+L2(14)
对于有标签数据,增加Dice损失函数,进行有监督训练,损失函数如式(15)所示,其中,LDice表示Dice损失函数,GT表示原始输入图片的标签。
LDice=E[LDice(P1I,GT)+LDice(P2I,GT)](15)
因此,该网络的总损失如式(16)所示,其中β是平衡两个损失的超参数。对有标签数据,需使用Dice损失和无监督损失Lc,对无标签数据,仅使用无监督损失Lc。
L=LDice+βLc(16)
3 实验评估
本实验环境为IntelXeonCPU E5-2680 v4 @ 2.40 GHz 处理器,128 GB内存,PyTorch框架和Python语言环境,训练过程依靠NVIDIA TESLA P100 16 GB GPU进行加速。
3.1 数据集及参数设置
本实验使用多中心、多供应商和多疾病的心脏分割数据集M&MS[25]进行评估。该数据集包含320名患者,使用西门子、飞利浦、通用电气和佳能4个厂商的核磁共振仪,在3个不同国家、6个临床中心拍摄。本实验将相同厂商拍摄的图像定义为一个域,即可获得4个不同域的数据,表示为A、B、C、D,其中只有心脏收缩末期和舒张末期的图像是有标注的。
分割网络的主干框架为DeepLabv3+[26],采用在ImageNet上训练的权重,使用AdamW优化器,学习率为1E-4,批次大小为8,运行6个epochs。式(3)中α设置为0.5,式(16)中的超参数β沿用文献[23]的设置,值为3。
3.2 评价指标
本实验使用Dice分数[27]评估模型性能,其定义如式(17)所示,其中P表示预测分割结果,GT表示标签。|P∩GT|表示P和GT之间的重叠区域,|P|+|GT|表示并集区域。Dice越高表明预测结果与标签更接近,即网络的分割效果越好。
3.3 不同模型的性能对比
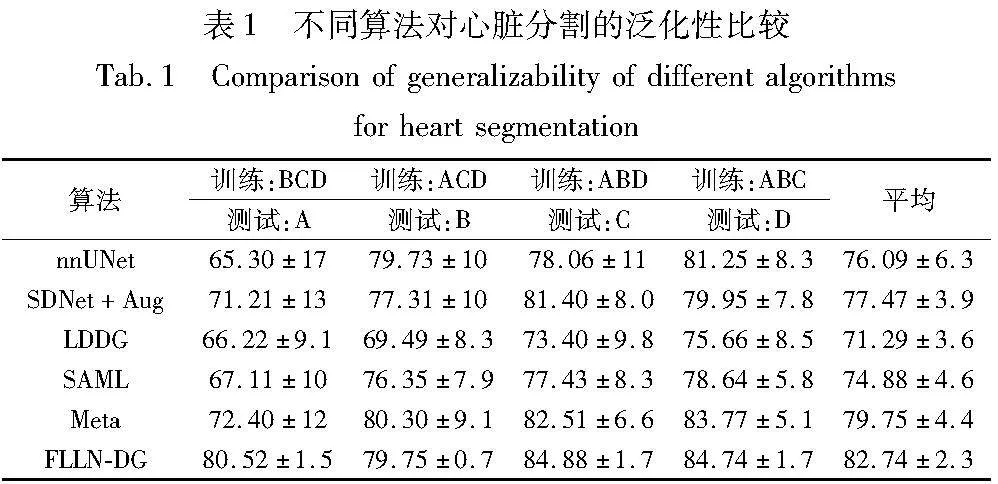
本实验将FLLN-DG与nnUNet[28]、SDNet+AUG[18]、LDDG[19]、SAML[29]、Meta[15]等模型进行比较,除nnUNet以外,其他四种模型均为域泛化模型,对比结果如表1所示。
nnUNet: 一种基于2D和3D U-Net的自适应框架,可用于快速而有效的分割任务。虽然该框架并非专为领域泛化而设计,但也具有较好的泛化能力,是很多域泛化方法的实验对比模型。
SDNet+Aug:首先将图像缩放到不同的分辨率,以生成涵盖不同扫描仪协议的数据。然后,通过将原始样本映射到潜在空间并利用从不同领域学习的解剖和形态因素进行融合,生成更加多样化的数据。
LDDG:提出了使用一种新的线性依赖正则化项,通过变分编码来学习代表性特征空间的方法,以捕获不同领域的医疗数据中可共享的信息。该模型在完全监督的环境下应用于领域通用的医学图像分析。
SAML:是一种基于梯度的元学习方法,它以完全有监督的方式约束元训练集和元测试集上分割掩码的紧凑性和光滑性。
Meta:是一个半监督的元学习框架,它通过解耦来模拟域偏移,并通过基于梯度的元学习方法应用多个约束来提取健壮的解剖特征,从而以半监督的方式预测分割掩码。
在SDNet+AUG、Meta和FLLN-DG中,训练域包含源域的所有未标记数据和5%的已标记数据,其他模型仅使用5%的标记数据进行训练。
从表1可知,FLLN-DG在A、C、D域上的性能达到最佳,与次优模型Meta相比,平均提高3%。FLLN-DG在B域的性能未达最优,原因是B域数据来自两个临床中心,虽然使用同一厂商设备进行拍摄,但仍然存在一定差异。此外,B域数据与C、D域数据的风格相似度较高,使用风格混合的数据增强方法对于B域并没有产生更多的域风格变化,导致其性能未达到最佳。类似地,本研究在B、C、D域上进行训练,在A域上进行测试,实验结果显示其性能提升最大。A域数据与B、C、D域数据的风格存在较大的差异,使用本方法可以获取风格多样化的数据,提高模型的泛化性能。
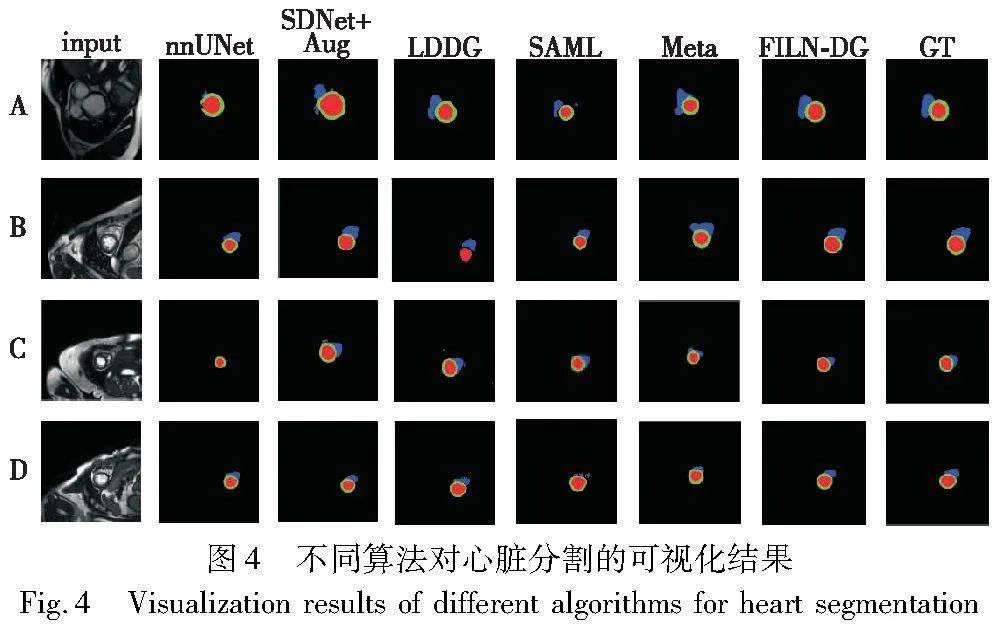
实验从A、B、C、D四个域中分别随机选择一张图像进行结果可视化,如图4所示,红色、蓝色和绿色分别表示左室血池、右室血池和左室心肌。从图4可知,大多数网络相对准确地定位了待分割区域,但是某些方法在心肌分割方面存在不准确的情况,例如LDDG方法在B域的分割结果未能准确分割心肌结构。另外,在左室血池的分割方面,大多数方法均表现出较高的准确度,但是某些方法在右室血池的分割边界上存在欠缺,甚至无法识别出右室血池。综合观察四个域的可视化结果,FLLN-DG表现与标签结果最为接近。
3.4 消融实验
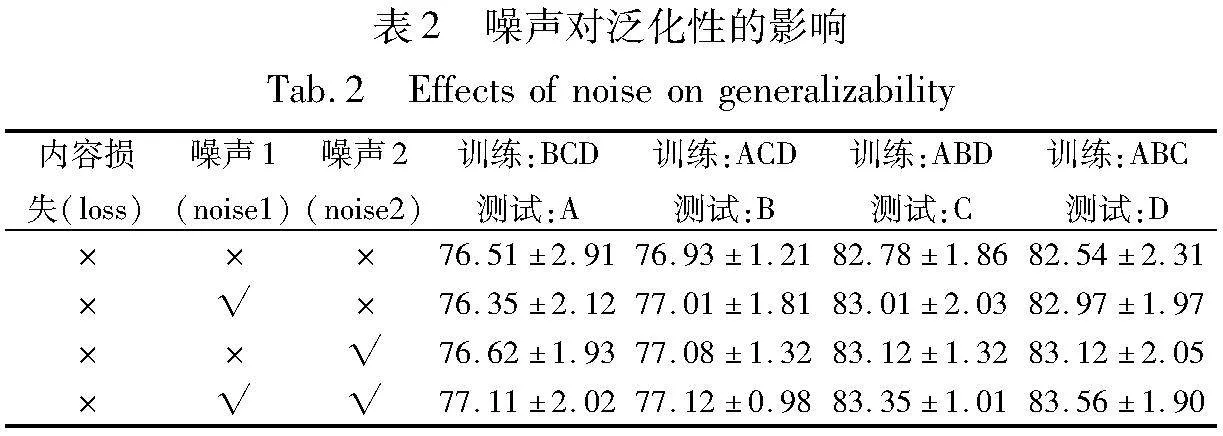
为了验证特征级损失和噪声组件的有效性,本文进行了消融实验,用Dice系数作为评估指标,结果如表2、3所示,本实验的基线模型为不包含生成噪声组件和特征级损失函数的模型。
3.4.1 噪声有效性验证
为了增加模型的泛化性,本文在基线模型中添加高斯噪声,增加生成图像的多样性,如表2所示,该方法提高了模型的性能。其中噪声1表示在图像生成网络中添加噪声,噪声2表示分割网络中生成图像后的添加噪声,从表2中可知,添加噪声组件后,模型的泛化性得到提升。
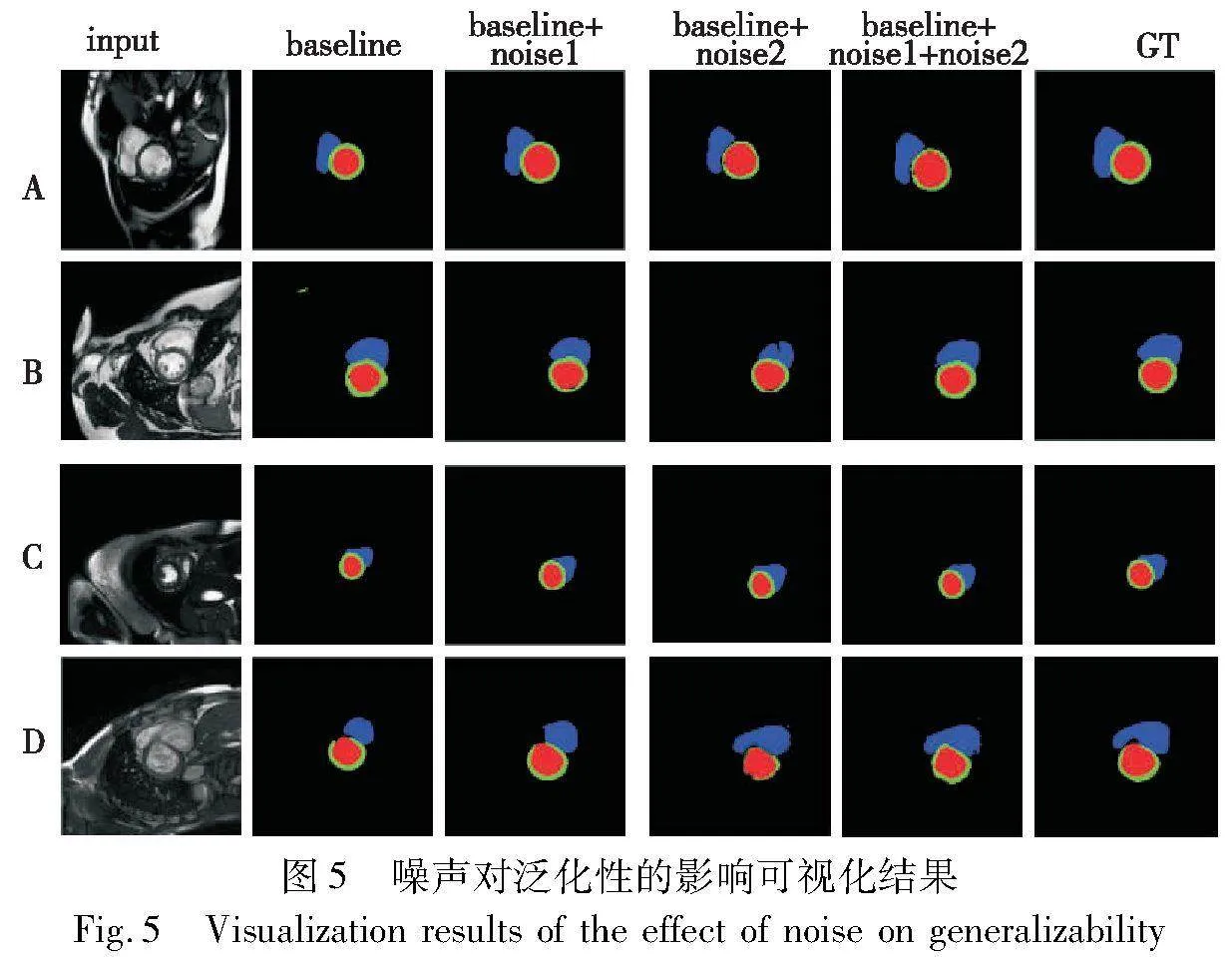
为更加直观地观察噪声组件对模型性能的影响,本研究从每个域中随机选取一张图像进行可视化比较,如图5所示,其中红色、蓝色和绿色分别表示左室血池、右室血池和左室心肌。
由图5可知,基线模型基本能够准确定位分割位置,随着噪声的加入,模型性能逐步提高,尤其对D域,添加噪声后模型能够逐步对右心室血池的外轮廓定位。实验证明,在生成网络和分割网络中同时添加噪声,模型的泛化性最佳。但是总体来看,分割结果与标签仍然有一定差异,分割边界不清晰,存在错误分割的问题。这是由于生成图像边界模糊,分割模型在相互指导时出现学习偏差,从而导致分割结果不准确。
3.4.2 特征级损失的有效性验证
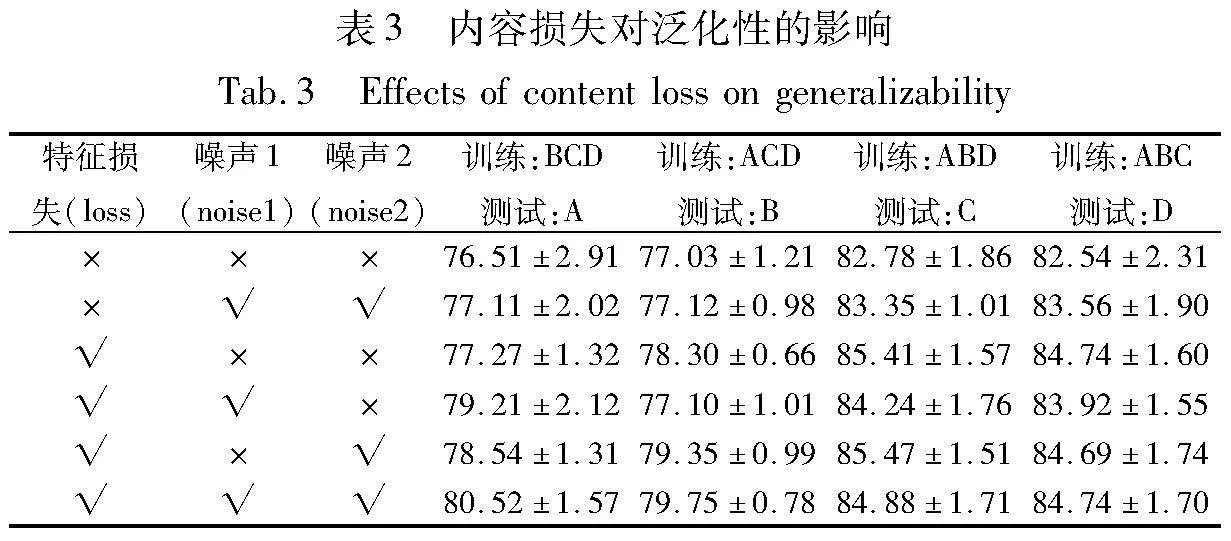
在基于编码器-解码器框架进行图像生成任务时,标签往往为原始输入图像。此前的工作通常采用图像级损失来提高生成图像与原始图像的一致性,进而训练模型参数。然而,笔者发现该方法可能会导致生成图像边界不够清晰。本研究提出增加特征级损失,以进一步提高生成图像的清晰度。具体方法是将生成图像和原图像映射到特征空间再进行比较,以计算生成图像与原始图像之间的特征级损失,从而提升生成图像质量,实验结果如表3所示。
由表3可知,特征级损失对模型性能产生了重要作用,提升了生成图像的恢复完整性。分割网络的训练受输入图像相似性的影响较大,本文所研究的域偏移现象来源于成像原理或光照强度不同等设备差异,因此生成具有相似内容但风格不同的图像时,保持分割边界的清晰尤为重要。引入特征级损失可提高生成图像的边界清晰性,从而提高模型训练的准确性和泛化性。
图6展示了不同组件对网络性能影响的可视化结果,其中loss表示特征级损失,noise1表示在图像生成网络中添加噪声的操作,noise2表示分割网络中生成图像后添加噪声的操作。随机选择每个域中的一张图像进行分割时,即使不添加任何损失和噪声,FLLN-DG也能准确地定位分割位置。随着组件的逐步添加,分割性能得到显著提高,特征级损失和噪声组件的加入,可使模型在A、B、D三个域的性能达到最优。值得注意的是,在C域经过两次添加噪声后,性能略有下降。笔者认为这是由于C域待分割区域的颜色较深,在添加噪声后影响了模型对边界的判断,从而影响了分割精度。
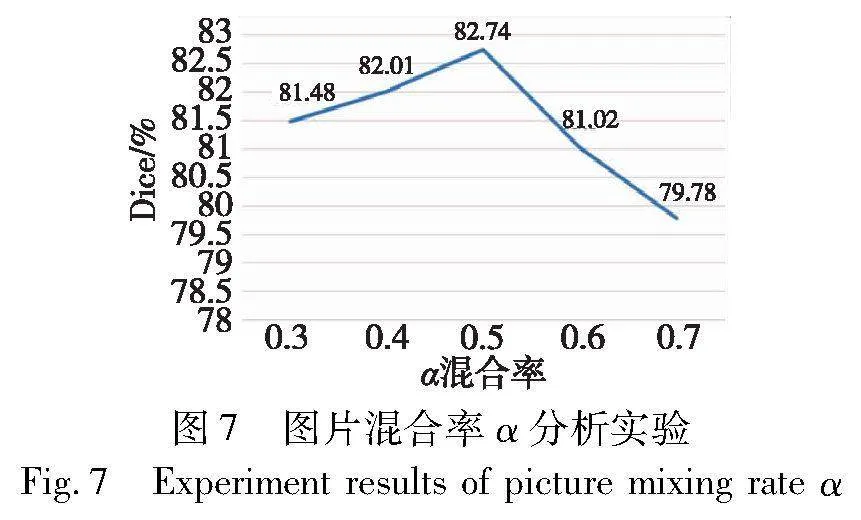
3.5 图片混合率参数分析实验
为进一步分析超参数α对模型分割精度的影响,本实验进行了图片混合率α的消融实验,结果如图7所示。由图可知,当α取0.5时,模型性能达到最优。
4 结束语
心脏结构的精确分割是医生对心脏类疾病诊断、治疗的首要步骤。但是域偏移问题的存在,会导致训练好的模型无法适应新的领域而崩溃,所以提升模型的泛化性具有重要意义。本文提出一种半监督的基于特征级损失和可学习噪声的医学图像域泛化分割模型FLLN-DG,首先引入特征级损失改善了生成图像边界不清晰的问题,其次引入可学习噪声组件,进一步增加数据多样性,提升了模型泛化性,最后,引入半监督学习框架,缓解了医学图像标注样本少的问题。实验结果表明,相较于其他方法,FLLN-DG具有更好的泛化性和更准确的分割效果。但是本研究对于B域的泛化性未达到最优,分析原因是B域数据扩充后的多样性仍然较小。接下来将继续对数据增强阶段进行改进,利用聚类等方式将风格类别进行聚类,通过计算类间距找到风格差异最大的域进行风格混合,进一步提高数据的多样性。在分割网络阶段,将通过添加注意力等方式,进一步提升分割精度,提高模型的泛化性。
参考文献:
[1]Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//Proc of International Confe-rence on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2015: 234-241.
[2]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2016: 770-778.
[3]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10). https://arxiv.org/abs/1409. 1556.
[4]徐海, 谢洪涛, 张勇东. 视觉域泛化技术及研究进展[J]. 广州大学学报: 自然科学版, 2022, 21(2): 42-59. (Xu Hai, Xie Hongtao, Zhang Yongdong. Review of domain generalization in vision[J]. Journal of Guangzhou University: Natural Science Edition, 2022, 21(2): 42-59.)
[5]Wang Jindong, Lan Cuiling, Liu Chang, et al. Generalizing to unseen domains: a survey on domain generalization[J]. IEEE Trans on Knowledge and Data Engineering, 2022,35(8): 8052-8072.
[6]Zhou Kaiyang, Liu Ziwei, Qiao Yu, et al. Domain generalization: a survey[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2022, 45(4): 4396-4415.
[7]Zhang Zuyu, Li Yan, Shin B S. Robust color medical image segmentation on unseen domain by randomized illumination enhancement[J]. Computers in Biology and Medicine, 2022,145: 105427.
[8]Li Chenxin, Qi Qi, Ding Xinghao, et al. Domain generalization on medical imaging classification using episodic training with task augmentation[J]. Computers in Biology and Medicine, 2022, 141: 105144.
[9]Ouyang Cheng, Chen Chen, Li Surui, et al. Causality-inspired single source domain generalization for medical image segmentation[J]. IEEE Trans on Medical Imaging, 2022,42(4): 1095-1106.
[10]Mahajan D, Tople S, Sharma A. Domain generalization using causal matching[C]//Proc of International Conference on Machine Lear-ning. New York:ACM Press, 2021: 7313-7324.
[11]Li Yumeng, Zhang Dan, Keuper M, et al. Intra-source style augmentation for improved domain generalization[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway,NJ:IEEE Press, 2023: 509-519.
[12]Liu Chang, Wang Lichen, Li Kai, et al. Domain generalization via feature variation decorrelation[C]//Proc of the 29th ACM International Conference on Multimedia. New York:ACM Press,2021: 1683-1691.
[13]Huang Yuhao, Yang Xin, Huang Xiaoqiong, et al. Online reflective learning for robust medical image segmentation[C]//Proc of International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2022: 652-66174a7c5f47a770285ed9d41173ea19ba2600e19684336c6062df3b03b07dcb2d2.
[14]叶怀泽, 周子奇, 祁磊, 等. 基于特定领域解码的域泛化医学图像分割方法[J]. 数据采集与处理, 2023, 38(2): 324-335. (Ye Huaize, Zhuo Ziqi, Qi Lei, et al. Domain generalization via domain-specific decoding for medical image segmentation[J]. Journal of Data Acquisition and Processing, 2023, 38(2): 324-335.)
[15]Liu Xiao, Thermos S, O’Neil A, et al. Semi-supervised meta-learning with disentanglement for domain-generalised medical image segmentation[C]//Proc of the 24th International Conference on Me-dical Image Computing and Computer Assisted Intervention. Cham:Sprin-ger International Publishing, 2021: 307-317.
[16]刘义鹏, 曾东旭. 眼底数据频域增强算法[J]. 小型微型计算机系统,2024,45(1):177-184. (Liu Yipeng, Zeng Dongxu. Frequency domain augmentation algorithm for eye fundus data[J]. Journal of Chinese Computer Systems, 2024,45(1): 177-184.)
[17]Han Qi, Hou Mingyang, Wang Hongyi, et al. EHDFL: evolutionary hybrid domain feature learning based on windowed fast Fourier convolution pyramid for medical image classification[J]. Computers in Biology and Medicine, 2023, 152: 106353.
[18]Liu Xiao, Thermos S, Chartsias A, et al. Disentangled representations for domain-generalized cardiac segmentation[C]//Proc of the 11th International Workshop on Statistical Atlases and Computational Models of the Heart. Cham:Springer International Publishing, 2021: 187-195.
[19]Li Haoliang, Wang Yufei, Wan Renjie, et al. Domain generalization for medical imaging classification with linear-dependency regularization[J]. Advances in Neural Information Processing Systems, 2020, 33: 3118-3129.
[20]Chen Chen, Qin Chen, Ouyang Chen, et al. Enhancing MR image segmentation with realistic adversarial data augmentation[J]. Medical Image Analysis, 2022, 82: 102597.
[21]Hu Shishuai, Liao Zehui, Zhang Jianpeng, et al. Domain and content adaptive convolution based multi-source domain generalization for medical image segmentation[EB/OL]. (2021). https://arxiv.org/abs/2109.05676.
[22]Chen Xiaokang, Yuan Yuhui, Zeng Gang, et al. Semi-supervised semantic segmentation with cross pseudo supervision[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2021: 2613-2622.
[23]Yao Huifeng, Hu Xiaowei, Li Xiaomeng. Enhancing pseudo label quality for semi-supervised domain-generalized medical image segmentation[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2022: 3099-3107.
[24]Gu Shuhang, Zuo Wangmeng, Xie Qi, et al. Convolutional sparse coding for image super-resolution[C]//Proc of IEEE International Conference on Computer Vision. Piscataway,NJ:IEEE Press,2015: 1823-1831.
[25]Campello V M, Gkontra P, Izquierdo C, et al. Multi-centre, multi-vendor and multi-disease cardiac segmentation: the M&Ms challenge[J]. IEEE Trans on Medical Imaging, 2021,40(12): 3543-3554.
[26]Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. (2017-12-05). https://arxiv.org/abs/1706.05587.
[27]Tanabe Y, Ishida T, Eto H, et al. Evaluation of the correlation between prostatic displacement and rectal deformation using the Dice similarity coefficient of the rectum[J]. Medical Dosimetry, 2019, 44(4): e39-e43.
[28]Isensee F, Jaeger P F, Kohl S A A, et al. nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation[J]. Nature Methods, 2021,18(2): 203-211.
[29]Liu Quande, Dou Qi, Heng P A. Shape-aware meta-learning for gene-ralizing prostate MRI segmentation to unseen domains[C]//Proc of the 23rd International Conference on Medical Image Computing and Computer Assisted Intervention. Cham:Springer International Publishing, 2020: 475-485.
