
基于目标图像先验信息的无监督多聚焦图像融合
2024-07-31 00:00:00谢明曲怀敬吴延荣王纪委张汉元
计算机应用研究 2024年6期
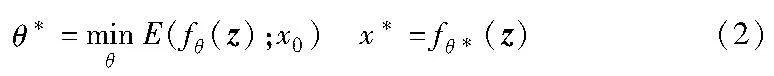

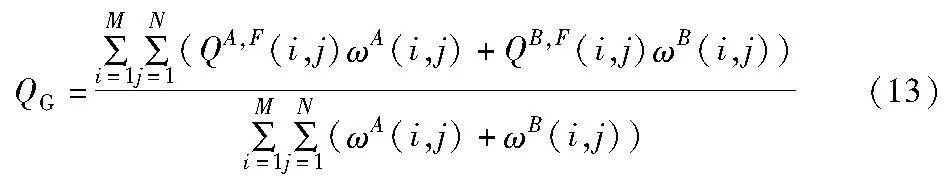
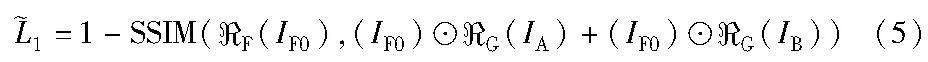


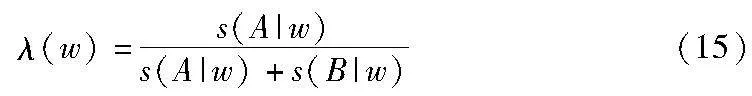

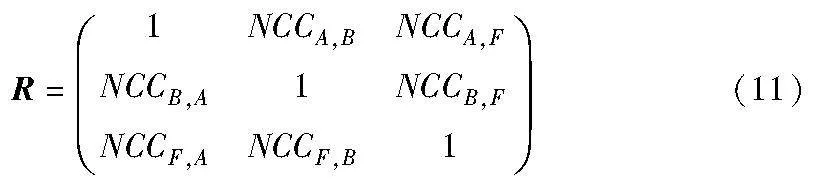

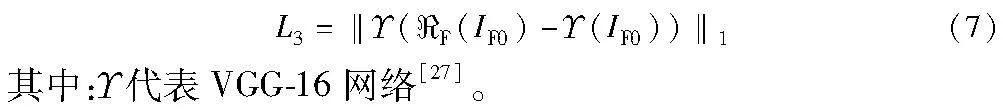
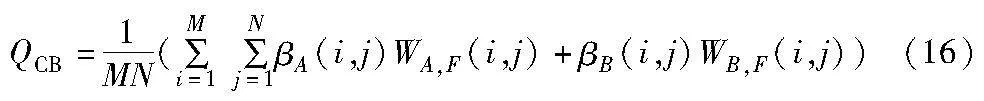


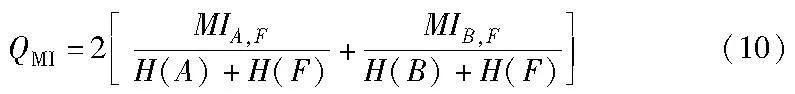








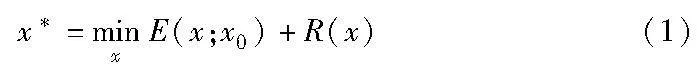

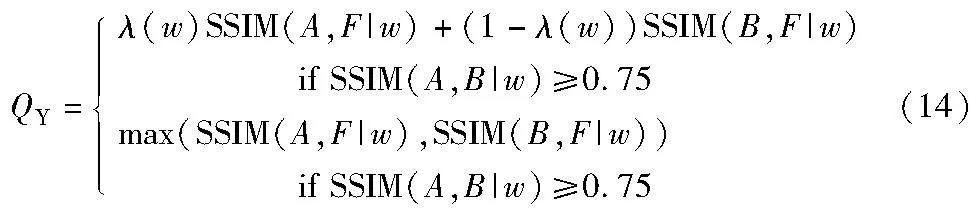
摘 要:多聚焦图像融合(MFIF)是从不同源图像中获取聚焦区域,以形成全清晰图像的一种图像增强方法。针对目前MFIF方法主要存在的两个方面问题,即传统的空间域方法在其融合边界存在较强的散焦扩散效应(DSE)以及伪影等问题;深度学习方法缺乏还原光场相机生成的数据集,并且因需要大量手动调参而存在训练过程耗时过多等问题,提出了一种基于目标图像先验信息的无监督多聚焦图像融合方法。首先,将源图像本身的内部先验信息和由空间域方法生成的初始融合图像所具有的外部先验信息分别用于G-Net和F-Net输入,其中,G-Net和F-Net都是由U-Net组成的深度图像先验(DIP)网络;然后,引入一种由空间域方法生成的参考掩膜辅助G-Net生成引导决策图;最后,该决策图联合初始融合图像对F-Net进行优化,并生成最终的融合图像。验证实验基于具有真实参考图像的Lytro数据集和融合边界具有强DSE的MFFW数据集,并选用了5个广泛应用的客观指标进行性能评价。实验结果表明,该方法有效地减少了优化迭代次数,在主观和客观性能评价上优于8种目前最先进的MFIF方法,尤其在融合边界具有强DSE的数据集上表现得更有优势。
关键词:多聚焦图像融合; 深度图像先验; U-Net; 散焦扩散效应
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)06-044-1901-09
doi:10.19734/j.issn.1001-3695.2023.09.0444
Unsupervised multi-focus image fusion based on target image prior information
Abstract:Multi-focus image fusion(MFIF) is an image enhancement method that combines the focused regions from different source images to form a fully sharp image. Currently, in the context of MFIF methods, there are two main challenges. First, traditional methods such as spatial domain approaches produce fusion images with high objective scores, but they suffer from strong defocus spread effects(DSE) and artifacts at the fusion boundaries. Second, deep learning methods lack a dataset generated from plenoptic cameras and require extensive manual parameter tuning, resulting in time-consuming training processes. To address these challenges, this paper proposed an unsupervised multi-focus image fusion method based on target image prior information. Firstly, it utilized the internal prior information of the source image itself and the external prior information of the initial fusion image generated by a spatial domain method as inputs for the G-Net and F-Net, respectively, both the G-Net and F-Net were components of the UNet-based deep image prior(DIP) network. Then,it introduced a reference mask generated by a spatial domain method to assist G-Net network for generating a guiding decision map. Finally, it used the decision map and the initial fusion image to jointly optimize the F-Net, producing the final fusion image. It conducted validation experiments on the Lytro dataset with real reference images and the MFFW dataset with strong DSE exhibiting in the fusion boundaries, and employed five widely used objective metrics for performance evaluation. The experimental results demonstrate that the proposed method significantly reduces the number of optimization iterations, and outperforms eight state-of-the-art MFIF approaches in terms of the subjective and objective performance evaluation, and especially shows superior performance on the datasets with strong DSE exhibiting in the fusion boundaries.
Key words:multi-focus image fusion; deep image prior; U-Net; defocus spread effect
0 引言
多聚焦图像融合在计算机视觉和图像处理领域是一项重要和充满挑战的研究工作。在场景摄影中,景深导致了同一场景中的不同物体或目标呈现出聚焦或散焦状态。由于硬件设备以及光学透镜的限制,通过单一传感器或者单独拍摄很难捕捉到包含所有物体的全聚焦图像。通常,在景深范围内获取的场景保持清晰,而在景深之外的区域往往是模糊的。为了解决这一问题,多聚焦图像融合(MFIF)技术应运而生。MFIF作为一种图像增强技术,可以有效地融合多源图像的不同聚焦区域,从而生成一幅全聚焦的图像。目前,MFIF方法在图像恢复、显微成像、医学影像以及机器视觉等领域得到了广泛应用[1]。
随着多聚焦图像融合技术数十年来的发展,研究人员提出了许多图像融合方法。总体而言,这些方法可以分为变换域、空间域和深度学习三类。其中,基于变换域的方法主要是将源图像分解成不同的变换系数,并按照预设的融合规则对系数进行融合,最后通过逆变换得到融合图像。在多聚焦图像融合领域,随着多尺度分解(MSD)理论的发展,涌现出了多种基于多尺度变换的图像融合方法[2]。同时,基于稀疏表示(SR)方法[3]、基于梯度域方法[4]以及基于其他一些变换域的方法[5]也在多聚焦图像融合领域得到了广泛应用。通常,变换域方法在多聚焦图像融合领域具有显著优势,因为它们与人类视觉系统感知处理信息的方式相匹配,并能够生成较为自然的视觉效果,尤其是在聚焦和散焦区域的边界(FDB)附近。然而,分解、融合和重构的每个步骤都可能引入像素强度误差,并且相对于原始图像,通过变换域方法得到的融合图像往往会失去一定的清晰度。
在空间域方法中,通常使用源图像的某些空间特征来进行融合。相较于变换域方法,空间域方法最显著的特点是不需要进行图像重建融合的逆变换阶段。在空间域方法中,可以将其分为基于像素、基于块和基于区域的方法。其中,基于像素的方法一直是空间域方法中的一个热点,该方法依赖于焦点测量,能够更好地比较多聚焦图像中像素的清晰度,从而能够获取精确的像素权重图(或决策图)。然而,由于基于像素的融合算法只考虑单个像素或使用局部邻域中的信息,这可能会导致融合边界出现伪影以及噪声等问题。相比之下,基于块的方法通常采用经验性设置的固定大小的块,并需要测量每个块的活动水平。然而,在基于固定块的方法中,由于块中可能同时包含散焦区域和聚焦区域,从而使这种方法往往会产生块效应[6]。与基于块的方法不同,基于区域的方法中,活动水平测量(或焦点测量)是在大小不规则的分段区域中进行的。然而,这种方法若对区域的分割不准确,容易在融合结果中引入一些错误信息。
随着深度学习在计算机视觉、图像处理和模式识别等领域的广泛应用和卓越表现,其在多聚焦图像融合领域日益得到关注和应用。基于深度学习的方法主要分为有监督和无监督[7]两种类型。其中,有监督方法使用标注的多聚焦图像数据集进行训练,并通过深度神经网络学习源图像和融合图像之间的映射关系,生成高质量的融合图像。相比之下,无监督方法则通过自动学习源图像的相关性和差异性,实现多聚焦图像的融合。特别地,无监督方法通过无监督学习算法利用大量未标注的多聚焦图像数据进行训练。这种方法能够方便学习源图像到焦点图或融合图像之间的直接映射,即通过训练网络可以联合生成活动水平测量和融合规则。目前,由于光学相机生成的源图像缺乏真实参考图像、生成的训练数据集很难去还原相机产生的离焦区域、缺乏相关基于深度学习的MFIF算法的标记数据集以及网络训练困难且复杂,使得有监督方法实现理想的融合效果变得比较困难。尽管无监督的深度学习方法能有效地解决上述问题,但其需要更复杂的训练策略以更好地提取图像特征,并且相对于有监督方法,其融合效果仍有待于改善和提高。
最近,基于深度图像先验(DIP)的无监督图像处理方法[8]的成功问世及应用引起了广大研究者的关注。DIP是一种基于深度神经网络迭代优化学习的图像恢复框架。与传统的图像恢复方法不同,DIP利用深度卷积神经网络的结构和参数来实现对退化图像的恢复。它不需要额外的训练数据,而是通过获取深度网络中的隐式先验并采用适当的迭代次数来恢复图像。目前,DIP已开始用于多聚焦图像融合领域[9]。然而,基于DIP的图像处理方法仍面临许多问题与挑战。一方面,DIP方法对迭代次数的选择非常敏感,选择过少可能无法充分恢复图像的细节,而选择过多可能导致过度恢复和噪声的引入。另一方面,由于以受到噪声或失真影响的退化图像为目标图像,DIP方法的性能还远没有达到最先进的程度。
为了解决上述问题,本文提出了一种基于内外先验信息的MFIF方法。具体地,首先将多聚焦图像融合视为图像恢复问题;然后,将目标图像的外部先验和内部先验信息用于深度网络输入,其中所采用的深度网络为U-Net;最后,拟合出合适的损失函数并通过初始引导的掩膜帮助网络缩短优化迭代次数,从而有效地获得高质量的融合图像。本文的主要贡献有以下三个方面:
a)在网络输入方面,本文采用了一种新的策略。该策略利用源图像本身丰富的内部先验信息和通过空间域方法生成的初始融合图像中包含的外部先验信息作为U-Net的输入。由于这些先验信息能够为U-Net提供最有价值的引导,并用于对清晰融合图像的先验进行建模,从而优化网络的收敛速度并提高融合性能。
b)本文采用一种新的生成引导U-Net的初始掩膜的空间域方法。它可以有效地缩短优化迭代时间,并提升融合效果。
c)为了有效解决源图像聚焦和散焦区域边界周围的散焦扩散效应(DSE),本文特别选取具有强DSE的MFFW数据集作为主要的实验数据集。实验结果表明,本文方法能够有效地解决融合边界处的伪影、噪声以及光环等问题。
1 相关工作
1.1 典型的MFIF方法
1.1.1 基于变换域的方法
为了更好地保留源图像的细节、减少融合过程中产生的伪影等问题,Li等人[2]首次在图像融合领域引入了离散小波变换(DWT)。该方法使用最大选择规则,通过在局部小窗口内选取具有最大绝对值的小波系数来测量活动水平,并据此将这些小波系数进行融合。另一方面,Yang等人[3]首次在多聚焦图像融合领域引入了稀疏表示(SR)。该方法首先使用过完备字典将源图像表示为稀疏系数,然后利用最大选择融合规则将这些系数组合起来,最后通过组合的稀疏系数和字典重构融合图像。类似地,Liu等人[10]提出了一种基于卷积稀疏表示的MFIF方法。此外,Bavirisetti等人[11]提出了一种基于引导图像滤波器的通用、简单且快速的MFIF算法。具体地,该方法通过多尺度图像分解、结构传递属性、视觉显著性检测和权重图构建,能够将有用的源图像信息很好地融合到多聚焦融合图像中。目前,变换域方法在处理图像边缘和细节时容易引入伪影,以及产生模糊效应,从而可能导致融合结果的失真。
1.1.2 基于空间域的方法
基于像素的融合方法是空间域中最流行的方法,因为它们能够获得精确的像素决策图。其中,Li等人[7]于2003年提出了一种基于像素的MFIF方法,该方法对每个像素计算其可见度,并根据像素的可见度进行融合。Kumar等人[12]提出了一种通过加权平均融合源图像的方法,其中权重是使用交叉双边滤波器(CBF)从源图像中提取的细节图像计算得出。此外,基于块的方法也在多聚焦图像融合领域得到了广泛应用,如Bai等人[13]提出了一种基于四叉树的MFIF方法,该方法采用改进的四叉树分解策略和基于修正拉普拉斯能量和(SML)的焦点度量。然而,这些基于像素或者块的方法,往往会导致细节丢失以及边界产生伪影和噪声等问题。
1.1.3 基于深度学习的方法
Liu等人[14]首次引入了基于卷积神经网络(CNN)的MFIF方法,为多聚焦图像融合领域带来了一种新的解决方案。随后,Zhang等人[15]提出了一种通用的图像融合框架IFCNN,它同样基于CNN进行多聚焦等图像的融合。Wang等人[16]采用生成对抗网络MFIF-GAN,提出了一种新的基于自适应和梯度联合约束的MFIF方法。其中,通过引入自适应决策块,并根据重复模糊的差异判断源像素是否聚焦,从而有效地提高了具有较强DSE的多聚焦图像的融合性能。此外,Xu等人[17]提出了一种全新的无监督端到端的图像融合网络U2Fusion,其通过特征提取和信息度量,能够自动估计对应源图像的重要性,并自适应地确定信息保留的程度,从而在同一框架内处理不同的融合任务。然而,由于大多数基于深度学习的多聚焦图像融合方法缺乏大规模的训练数据集以及训练模型泛化能力一般等问题,在图像融合的性能和效率方面仍存在着很大的提升空间。
1.2 深度图像先验
通常,图像恢复中的逆问题,如去噪、融合、超分辨率和修复等,都可以通过能量最小化的形式进行求解。用公式可以概括为
其中:x为待恢复图像(或目标图像);x0为给定的退化图像;E(x;x0)为面向任务的数据项,例如E(x;x0)=‖x-x0‖2等;R(x)为显式的正则项,它用于捕捉真实图像中的一般先验信息,引导最终的输出结果向着更合理的方向发展。
在式(1)中,设计有效的正则项通常是比较困难的,而通过深度卷积神经网络自身的结构获取图像的先验信息,不失为研究逆问题的一种有效的无监督方法。为此,在2018年,Ulyanov等人[8]提出了深度图像先验(DIP)框架。其中,DIP是一种基于深度学习的图像恢复方法,它利用深度神经网络的结构和特性来恢复退化图像。DIP模型用公式可以描述为
其中:x为待恢复图像;x0为已知的退化图像;θ为网络参数;z为一个随机向量(或图像);x=fθ(z)为深度神经网络的参数化表示;E(fθ(z);x0)为面向任务的数据项,例如E(fθ(z);x0)=‖fθ(z)-x0‖2等。
由式(2)可见,在DIP模型中,正则项由深度神经网络本身的结构信息隐含表征。DIP模型中使用的骨干网络为具有“沙漏”结构的U-Net。此网络本身可交替进行卷积、上采样和非线性激活等滤波操作。通常,U-Net具有常用的卷积神经网络结构,所含有的编码器和解码器具有结构的对称性,这样有助于在恢复图像过程中保留输入图像的细节信息。具体地,U-Net的编码器(encoder)由多个卷积层和池化层组成,它通过逐渐降低特征图的尺寸和通道数,从而有效地提取图像的抽象特征;其解码器(decoder)由多个卷积层和上采样层组成,它通过逐渐恢复特征图的尺寸和通道数,使得恢复图像的分辨率与输入图像相同;此外,U-Net还采用跳跃连接(skip connection)将编码器中不同层的特征图与解码器中对应层的特征图进行连接,从而有助于传递更多底层的细节信息。
通常,原始DIP框架把图像恢复问题看作一个逆问题,并且根据生成器网络的结构在没有任何学习的情况下可以捕捉到大量的底层图像统计信息。随后,Gandelsman等人[18]通过耦合多个DIP网络,为图像分解成基本组成部分提供了强大的工具,并适用于各种相关的应用。例如,Xu等人[19]将包含丰富外部先验信息的去噪图像与多个标准DIP框架内给定的噪声图像一起作为额外的目标图像,实现了高效的无监督图像去噪过程。最近,Ma等人[20]提出了一种将DIP扩展到图像融合领域的新型方法,并将DIP表述为求逆问题的融合任务。值得一提的是,该方法是在经典DIP网络的基础上采用多通道方法进一步增强DIP的图像融合效果,但限于网络结构和损失函数单一等问题,其融合效果欠佳。Hu等人[9]提出了一种零样本学习的方法,并用于多聚焦图像的融合。它既不需要采用收集耗时的数据集进行训练,又避免了由于人工生成的多聚焦图像与真实图像不一致而引起的领域迁移问题。然而,目前将DIP框架用于多聚焦图像融合仍存在一些问题,如难以确定迭代中止次数、网络输入的噪声图像所含有的融合图像先验信息有限等,从而导致多聚焦图像融合效率低、性能较差。
1.3 本文研究的动机
目前,基于DIP框架的图像处理方法性能差的主要原因是它将退化图像(例如含噪图像、多聚焦源图像等)作为目标图像。这样,如果将DIP框架用于多聚焦图像融合,由于目标图像自身不完善的先验信息质量,就可能影响到优化迭代的有效收敛和融合性能。为了解决上述问题,本文使用具有外部先验信息的、较高质量的初始融合图像和具有内部先验信息的源图像作为DIP框架的目标图像。通常,图像的外部先验信息是指通过基于空间域、变换域或深度学习等的方法获取的融合图像信息。目前,目标图像的内部和外部先验信息在图像去噪、多光谱图像融合等领域得到了越来越多的应用,并取得了较好的效果[21,22]。
另一方面,目前在基于深度学习的多聚焦图像融合领域,广泛地存在着缺乏逼近真实参考图像的训练数据集以及训练需要较多耗时等问题;同时,传统的基于变换域与空间域方法所生成的融合图像边界存在着较强的DSE和伪影等问题。为了有效地解决上述两方面的问题,本文提出了一种基于目标图像的外部和内部先验信息的无监督MFIF方法。该方法能有效地提高DIP框架的融合质量,并且能够缩短迭代次数以提高融合效率,同时它也能够有效解决融合边界的DSE、伪影及噪声等问题。
2 基于内外部先验信息的无监督多聚焦图像融合
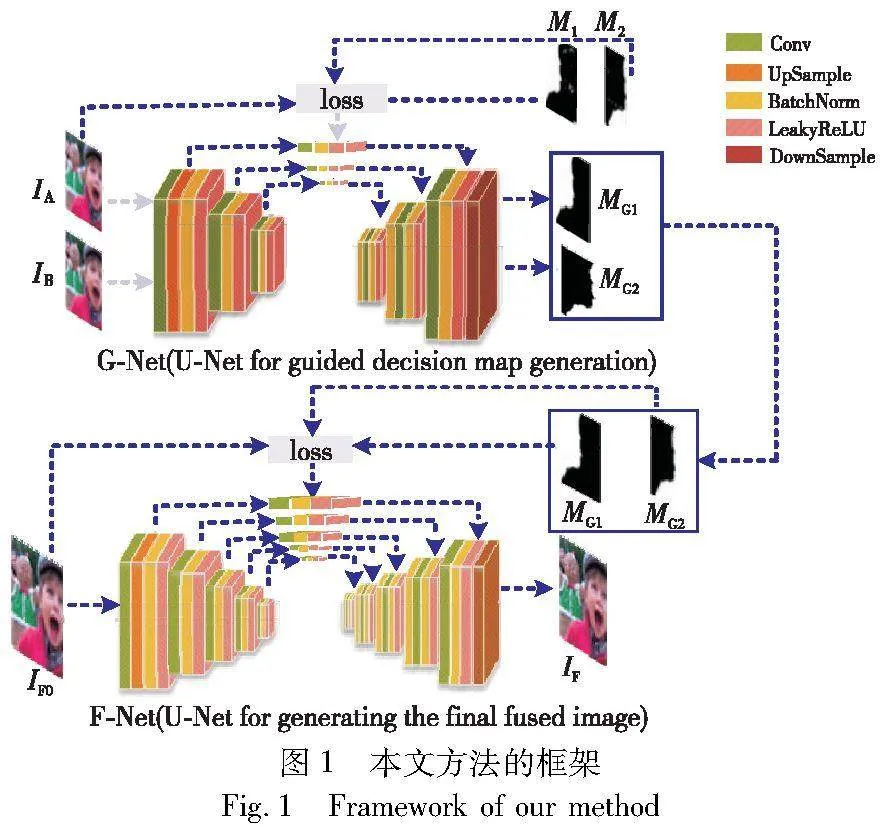
本文方法的框架如图1所示,它将改进的DIP框架用于实现多聚焦图像的融合。
图中,IA、IB为G-Net输入的一对源图像;M1、M2为由空间域方法生成的初始掩膜;MG1、MG2为IA、IB对应的G-Net输出掩膜;IF0为由空间域方法生成的初始融合图像,并作为F-Net输入;IF为F-Net输出的最终融合图像。两个具有U-Net结构[20]的G-Net和F-Net构成了一个联合学习的过程。其中,G-Net用于生成一对源图像IA、IB对应的决策图MG1和MG2;然后,这些决策图将在F-Net中引导融合图像的生成。具体地,首先采用包含丰富内部先验信息的源图像对IA、IB作为G-Net的输入,同时引入一对由空间域方法生成的初始掩膜M1和M2,该掩膜对能够高效引导G-Net生成源图像对应的决策图MG1和MG2;然后,利用空间域方法生成初始融合图像IF0;最后,将包含外部先验信息的IF0作为F-Net的输入,同时使用决策图MG1和MG2引导F-Net生成最终的融合图像IF。需要说明的是,在图1中只使用一对源图像作为示例,本文多聚焦图像融合方法可以扩展到多个源图像。
2.1 网络结构设置
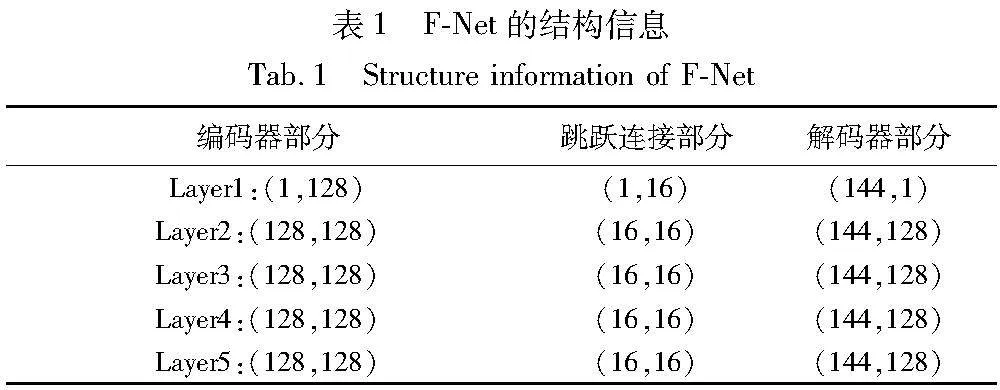
鉴于一些主流DIP网络采用的编码器-解码器结构存在一些常见问题,比如深度通常较浅(常见的是3×3网络),以及上采样和下采样采用对称设计等,本文采用了一种不同的结构。具体而言,本文通过增加编码器-解码器网络的深度,并采用了非对称的结构设计。此外,本文还引入了跳跃连接U-Net,以便解码器能够充分利用编码器中的底层特征信息,从而提高了融合结果的准确性。 如图1所示,本文网络由G-Net和F-Net两部分组成。考虑到U-Net能够更好地提取图像中的高频和低频信息,因此本文使用由U-Net构成的G-Net和F-Net作为主干网络。这两种网络的编码器和解码器在结构上是相同的,但层数不同。其中,两种网络编码器部分的结构为Conv-UpSample- BatchNorm-LeakyReLU;而其解码器部分的结构为Conv-BatchNorm-LeakyReLU-DownSample。此外,这两种网络采用的跳跃连接部分的结构为Conv-BatchNorm-LeakyReLU。具体地,F-Net和G-Net的主要结构参数信息如表1和2所示。
2.2 采取的内外部先验信息
在原始的DIP框架中,通常会选择随机噪声图像作为深度网络的输入。与有监督的网络模型相比,这种框架中仅包含有限的外部先验信息用于图像融合,这可能对DIP融合框架优化迭代过程的收敛性和融合图像的质量产生不良影响。为了改善这些情况,一方面通过利用简单的空间域方法生成融合图像作为深度网络的输入,可提供一种更有效的替代方案。这种方案不仅能够快速且相对准确地生成较高质量的初始融合图像,还可以充分利用此融合图像中包含的外部先验信息。另一方面,鉴于源图像对中包含着丰富的内部先验信息,在DIP融合框架优化迭代过程中可显著地减少图像空间的搜索范围,从而有效地提高收敛的效率。综上所述,为了提高DIP融合框架优化迭代的收敛速度和融合图像的性能,本文选择使用多聚焦图像数据集中的源图像对代替随机噪声图像作为深度网络的输入,以丰富目标图像的内部先验信息;同时,本文引入一种简单的空间域方法[23],用于为G-Net和F-Net两个深度网络提供包含丰富的外部先验信息的一对互补的二值初始掩膜M1、M2以及初始融合图像IF0。
具体而言,本文采用空间域法进行多聚焦图像融合的过程为:首先获取由源图像与均值滤波后的源图像相减所得到的绝对差值图像;再通过导向滤波并根据局部标准差检测得到聚焦区域;然后根据像素最大化原则形成决策图;最后由决策图得到初始融合图像IF0。其中,该空间域方法生成的决策图为G-Net提供初始掩膜M1和M2,而生成的初始融合图像用作F-Net的输入。在图2中,给出了在Lytro数据集[24]上的部分示例,它们包括由所采用的空间域方法得出的决策图M1和对应的初始融合图像。
2.3 优化实验细节
为了引导本文采用的网络模型学习如何从输入图像中有效提取信息,并将这些信息综合成高质量的融合图像,在本文中引入重建损失来反映深度网络的隐式先验。结合图1中所采用的深度网络及其输入特点,定义重建损失为
另一方面,本文通过引入空域法生成的决策图,可以帮助G-Net更好地学习源图像对中包含的内部先验信息。因此,为了给G-Net提供更好的引导信息,以帮助生成有效的引导决策图MG1和MG2,在本文中引入了引导决策损失,用公式可表示为
由式(4)可以看出,初始掩膜M1和M2的质量对于G-Net的输出性能有着重要的影响。由图2(a)可以看出,空间域方法生成的掩膜M1中还存在着一些黑白像素误差。尽管如此,M1及其对应的M2仍可以为G-Net输出的源图像决策图提供关键的先验引导信息,从而产生有效的引导决策图。值得说明的是,在聚焦和散焦区域的边界处,本文方法综合了焦点图估计和融合图像生成方法的优点,可以有效地减少因像素错误分类带来的问题。
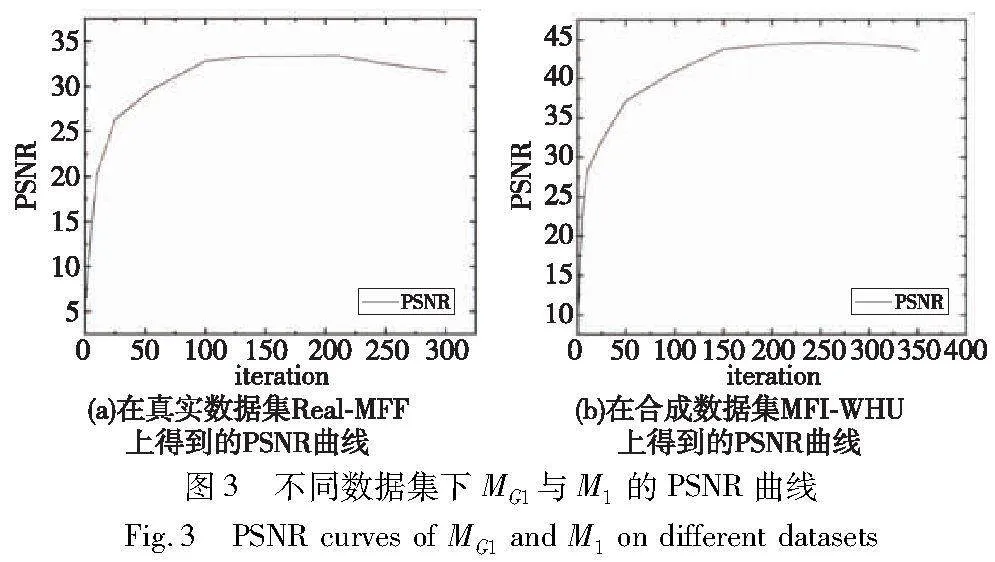
由式(4)还可以得出,G-Net初始输出的掩膜将尽可能接近于掩膜M1和M2。鉴于M1和M2存在着一些瑕疵,而本文旨在获得更加出色的输出掩膜,因此需要进一步探索G-Net初始输出的掩膜向M1和M2趋近的迭代次数阈值。本文为了更直观、准确地展现融合图像质量随着迭代次数的变化规律,选择采用PSNR曲线进行说明。由于本文所采用的Lytro和MFFW数据集缺乏参考图像,而在Real-MFF[25]和MFI -WHU[16]数据集中提供了参考图像,所以在图3中,本文呈现了在真实数据集Real-MFF中获得的MG1与M1的PSNR曲线。从式(4)和图3中可以看出,当迭代次数达到某一阈值时,G-Net生成的掩膜无限接近于M1、M2,L2会趋于0;而当迭代次数继续增加,L2会变差,可能无法生成最终理想的决策图。
具体地,从图3中还可以观察到,在Real-MFF数据集上,当迭代次数超过150次时,PSNR曲线基本趋于稳定;然而,当迭代次数超过220次后,PSNR曲线开始出现下降趋势。对于MFI-WHU数据集,也呈现出类似的趋势。PSNR曲线趋于稳定的迭代次数约为160次。考虑到本文所采用实验数据集的特点,结合这两个数据集的PSNR曲线变化规律,本文最终确定初始迭代次数为160次。
当迭代次数大于160次之后,为了进一步提高F-Net输出的融合图像性能以及G-Net和F-Net的迭代效率,本文将重构损失替换为
其中:SSIM[26]代表两幅图像的结构相似度,其对应的公式如下:
另一方面,为了使得到的融合图像具有更好的视觉感知效果,在本文方法中引入了感知损失,其具体公式如下:
综上所述,为了保证有效地提高图像融合的性能,本文采用的损失函数根据迭代次数iteration的阈值(160次)分为两个阶段,具体如式(8)和(9)所示。
a)当iteration≤160时,
L=L1+λ1L2+λ2L3(8)
b)当iteration>160时,
其中:λ1和λ2为加权系数,用于折中不同损失之间的权重。
类似地,本文也测试了最终融合图像IF与Real-MFF数据集和MFI-WHU数据集上相应真实图像的PSNR曲线,并最终实验确定中止迭代次数Iters为600次。具体地,本文算法如下所示。
算法1 本文方法流程
3 实验与分析
3.1 实验参数设置和数据集选择
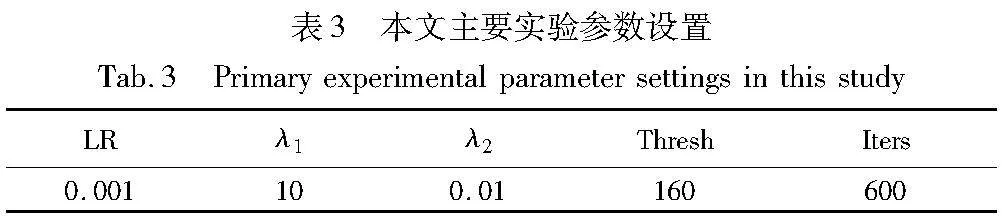
本文实验使用PyTorch,在配置为NVIDIA RTX3060 12 GB GPU的计算机上完成。主要实验参数如表3所示,其中:实验学习率设为0.001;λ1设置为10,λ2设置为0.01,并且通过多组实验发现,在性能和效率方面,这两个参数的调整对结果影响不敏感;优化迭代阈值设为160次,总迭代次数设为600次。
为了对本文方法进行综合评估,在实验中使用了两个MFIF数据集,即Lytro数据集和MFFW数据集[28]。其中,Lytro数据集包含20对多聚焦图像,这些图像都是使用光场相机捕捉的。特别地,考虑到Lytro数据集的散焦扩散效应(DSE)并不明显,本文实验还选取了DSE更加明显且场景更加复杂的MFFW数据集,它包含13对多聚焦源图像。图4给出了Lytro和MFFW数据集中的一些示例,通过示例比较可以明显地看出MFFW数据集的源图像对具有较强的DSE。
3.2 采用的客观评价指标
本文在实验中使用了五个被广泛应用于MFIF方法的客观指标进行评估。它们包括归一化互信息(QMI)[29]、非线性相关信息熵(QNICE)[30]、基于梯度的度量(QG)[31]、Yang等人提出的基于结构相似性的度量(QY)[32]以及Chen等人提出的基于人类感知的度量(QCB)[25]。本文将根据这些客观指标的实验值来评估不同方法融合结果的质量和性能,并进行深入的分析。其中,归一化互信息(normalized mutual information)QMI定义为
其中:H(·)表示图像的熵;MI为两幅图像间的互信息。QMI值越大,表示融合性能越好。
非线性相关信息熵(nonlinear correlation information entropy)QNICE用于测量源图像A、B和融合图像F之间的非线性相关性。首先,基于源图像和融合图像之间的非线性相关系数(nonlinear correlation coefficient,NCC)构建非线性相关矩阵R,即
然后,QNICE 可以计算为
其中:λi为矩阵R的特征值。QNICE值越大,表示源图像和融合图像间的非线性相关性越强。
基于边缘的相似性度量(edge based similarity measurement)QG表示从源图像传输到融合图像的边缘信息量。它可以由下式计算得到。
其中:QA,F(i,j)为边缘信息保持值;ω表示每个源图像对融合图像的重要性。通常,较大的QG值表示较良好的融合性能。
杨的度量(Yang’s metric)QY是一种基于结构相似度SSIM的融合质量度量。它表示来自两个源图像的融合图像F中保留的结构信息量。QY定义为
其中:ω是一个局部窗口,而λ(w)表示为
其中:s是ω窗口内图像的局部方差度量。QY值越大,则融合图像中保留的源图像信息越多,融合性能越好。QY的最大值为1。
基于人类视觉感知的度量QCB定义为
其中:WA,F(i,j)和WB,F(i,j)分别表示从源图像转换到融合图像的对比度;βA 和βB分别为WA,F(i,j)和WB,F(i,j)的显著性图。QCB值越大,表示融合图像中保留的源图像信息越多,表明融合性能越好。QCB 的值在[0,1]内。
3.3 模型选择
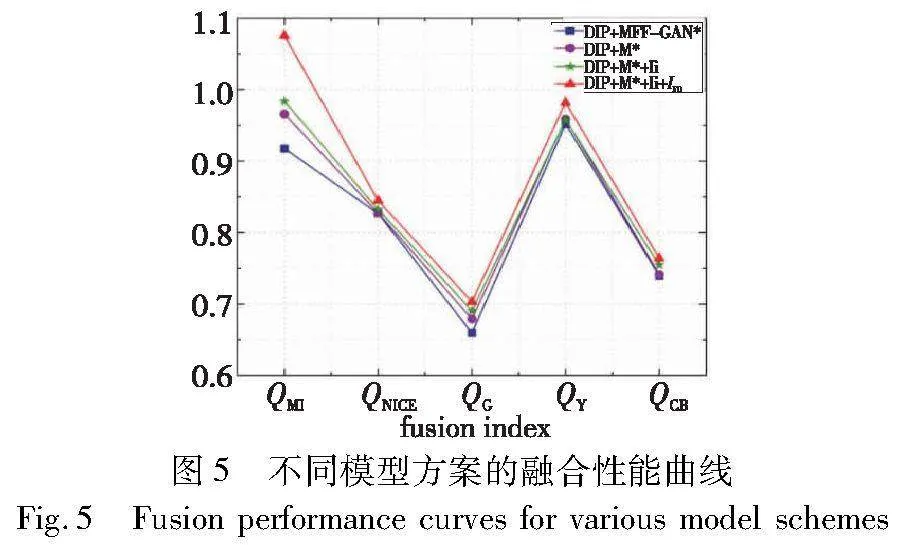
为了验证本文提出的网络优化模型的有效性和可行性,实验选用DIP网络(即G-Net和F-Net)作为主干网络,并在Lytro数据集上完成多聚焦图像的融合。在Lytro数据集上获得的平均实验结果如表4和图5所示。其中,表4和图5中的MFF-GAN*表示由MFF-GAN生成参考掩膜的方法;M*表示本文生成参考掩膜的方法;Ii表示使用源图像对作为G-Net的输入;IF0表示使用由空间域方法生成的初始融合图像作为F-Net的输入。
具体地,首先选取DIP+MFF-GAN*模型作为评价基准。然后,进行不同的模型选择尝试和比较。由表4中的数据以及图5中代表DIP+M*+Ii+IF0模型的红色曲线与另外三种方案曲线之间的纵向差距比较可以更加直观地看出,DIP+M*+Ii+IF0组合模型为最优方案。因此,本文选用DIP+M*+Ii+IF0模型作为最终的模型。此外,通过比较表4中的不同模型方案在Lytro数据集上的平均耗时可以看出,随着模型选择方案的优化,融合效率也在不断提高,其中DIP+M*+Ii+IF0模型的耗时最少,它相对于其他三种模型方案的融合效率也得到了明显的提高。
3.4 用于对比的MFIF方法
本文方法与八种先进的MFIF方法进行了比较,如表5所示。其分别是CBF[12]、MGFF[11]、CSR[10]、MFF-GAN[15]、U2Fusion[17]、IFCNN[15]、U-DIP[20]以及ZMFF[9]方法。这些方法几乎包含了常见的全部类型的MFIF方法。具体而言,一种空域方法为CBF方法;两种变换域方法为MGFF和CSR方法;三种深度学习方法为MFF-GAN、U2Fusion和IFCNN方法;两种DIP方法为ZMFF和U-DIP方法。
3.5 在Lytro数据集上的性能比较
3.5.1 主观评价
为了更直观地比较不同方法的融合性能,本文选择了Lytro-17源图像对作为示例,实验结果如图6所示。在图6中,本文将不同方法生成的融合图像中位于相同融合边界位置的区域用红色方框标出,并将放大后的区域显示在各自融合图像的右下方。同时,为了更好地评估不同方法的融合质量,本文还提供了相应的差值图像(即通过用融合图像减去源图像A来获取差值图像),并在融合图像下方列出。通常,如果生成的融合图像接近于真实图像,那么对应的差值图像中不应该包含源图像A聚焦区域的相关细节。此外,相同的分析方法也适用于下述示例MFFW-02和MFFW-04。
通过观察图6中不同融合图像的放大区域可以看出,MFF-GAN、U2Fusion以及U-DIP方法的“小熊”放大区域呈现出明显的模糊;而在CBF、IFCNN和MGFF方法的放大区域也出现了或多或少的模糊。相比较而言,ZMFF、CSR和本文方法则表现出较高的清晰度。另一方面,通过比较各种方法的差值图像可以更加清晰地看出CBF、IFCNN、MGFF以及U-DIP方法最下方的红色框圈出的区域中出现了地板的细节,这说明源图像A中的聚焦区域细节并没有完全迁移到融合图像中;CSR方法最下端的整个区域中出现了地板细节;而MFF-GAN和U2Fusion方法在地板处也出现了模糊区域。相对而言,ZMFF方法几乎没有呈现源图像A的聚焦区域细节,但是在红色圆圈的区域出现了一定程度的模糊和地板细节。与其他方法相比较,本文方法对应的差值图像中基本上没有呈现源图像A的聚焦区域细节,这说明其能够有效地保留聚焦信息,并且在融合图像的边界清晰度较高、伪影和噪声相对较少。综上这些观察结果表明,本文方法在Lytro数据集上的融合效果具有明显的优势,它能够较好地保持源图像对的聚焦信息,并能有效地减少模糊、伪影以及噪声等问题。
3.5.2 客观评价
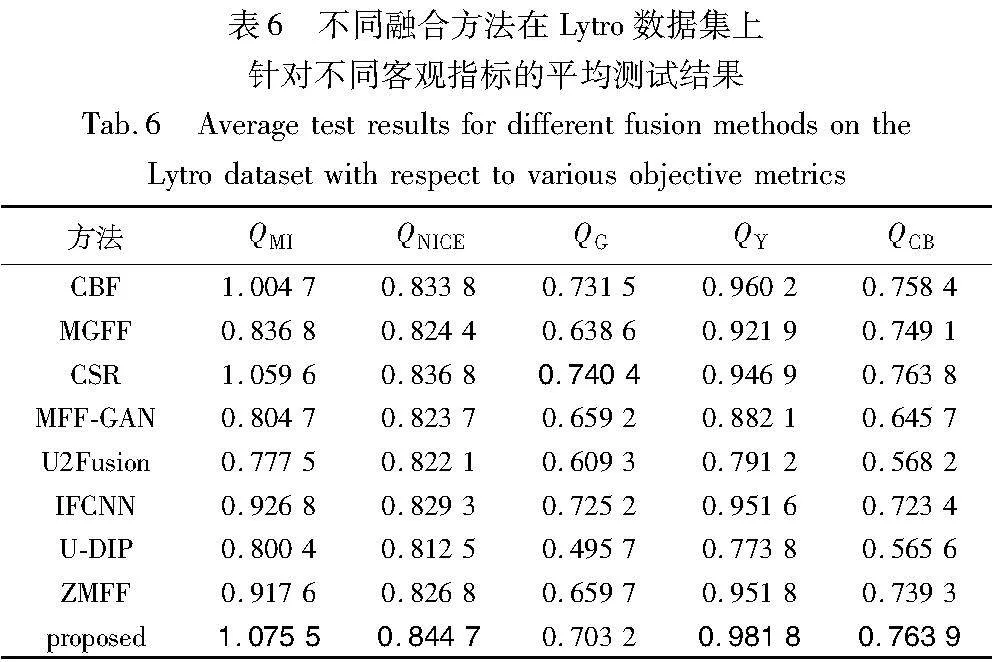
本文对不同的融合方法分别在Lytro数据集上进行客观指标测试,实验结果如表6所示。其中,对于每种方法,表中的数据是在实验数据集中每个样本上所进行的客观指标度量的平均值。对于每个客观指标,性能表现最好的结果用黑体字体显示。
由表6的数据可以清楚地看出,针对Lytro彩色图像数据集,CSR和本文方法获得了较高的指标值。相对而言,本文方法表现更佳,其中在5个指标中有4个指标位列第1名,而仅在QG指标上排名第4。ZMFF方法也出现了在QG这一指标下值较低的情况。这是因为,基于DIP的方法在图像融合过程中对边缘信息进行了自适应的平滑处理,从而导致边缘梯度信息下降,进而使得QG值降低。然而,另一方面,当处理融合边界具有较强DSE的数据集(例如,MFFW数据集)时,本文方法可以有效地平滑或减少融合边界的伪影、噪声和颜色失真等,从而将降低融合边界的DSE效应、改善QG指标的性能(表7)。
3.6 在MFFW数据集上的性能比较
3.6.1 主观评价
为了评估本文方法在融合边界具有强DSE效应的数据集上的融合性能,本文选择了MFFW数据集进行测试。为了充分展示本文方法在降低融合边界DSE方面的有效性,选取了MFFW-04和MFFW-02作为示例,并通过主观视觉效果验证融合性能,实验结果如图7和8所示。在图7和8中,本文使用红色方框标出了位于融合图像边界处的区域,并将放大后的区域显示于融合图像的右下角。另一方面,在图7的差值图像中,本文用红框分别标注融合边界和背景区域的“花”。同样地,在图8的差值图像中,本文用红框分别标注了老者手腕部分的细节以及其他残留的较为明显的细节。
首先,由图7中不同方法的融合图像的局部放大区域可以看出,CBF、MFF-GAN、MGFF、U2Fusion以及U-DIP方法中“脚”的放大区域呈现出程度不一的模糊、伪影以及光环现象。对于IFCNN和CSR方法的放大区域,融合图像相对较为清晰,但在放大区域周围仍存在光环现象。而ZMFF方法在放大区域边界部分表现较为平滑,但与本文方法相比,其清晰度相对较低。另一方面,由差值图像还可以更加直观地看出,CBF方法不仅边界处模糊,而且背影中残留了大量源图像A中聚焦区域的细节信息;IFCNN、MFF-GAN以及U2Fusion方法的边界存在伪影,背景细节信息也有残留,甚至背景的“花”也出现了不同程度的颜色残留;CSR方法相对较好,但边界处出现光环和伪影;观察发现,U-DIP得到的差值图像中没有出现颜色细节,但是出现了许多源图像A的细节。ZMFF方法和本文方法表现较好,然而,在标注的方框区域中,ZMFF方法仍然保留了源图像A中聚焦区域的一些细节。综合比较示例融合图像和差值图像的结果可见,本文方法的整体融合效果最佳。
同样地,由图8可以看出,放大区域里面IFCNN、MFF-GAN、MGFF、U2Fusion、CBF和U-DIP方法的融合图像边界呈现出较模糊的特征,特别是MGFF方法出现了明显的伪影;而CSR、ZMFF以及本文方法的放大区域较为清晰,没有出现明显的伪影及噪声。此外,通过差值图像的比较也能更加直观地评估融合效果。具体而言,IFCNN、MFF-GAN、U2Fusion和CBF方法出现了源图像A聚焦区域中的“老者”细节,而且衣领处出现了或多或少的颜色细节;MGFF方法表现得相对也较差,出现了“老者”很多细节,并且伴随出现了颜色信息和伪影光环等问题;CSR和ZMFF方法整体较好,然而,CSR方法的“老者”手臂部位出现了颜色细节纹理。U-DIP方法的差值图像的红色方框区域没有出现相应的颜色细节,但是“老者”的整体轮廓细节仍然能够观测到。而ZMFF方法与本文方法相比,在红色圆圈中的区域出现了少许源图像A聚焦区域的细节,说明源图像A的细节信息没有完全转移到其融合图像之中。综上分析,无论是融合图像还是差值图像,针对MFFW数据集中的这两个示例的实验结果都充分说明,本文方法在具有较强DSE现象的数据集上进行融合的主观视觉效果较为突出,它能够有效地降低融合图像边界DSE的不良影响。
3.6.2 客观评价
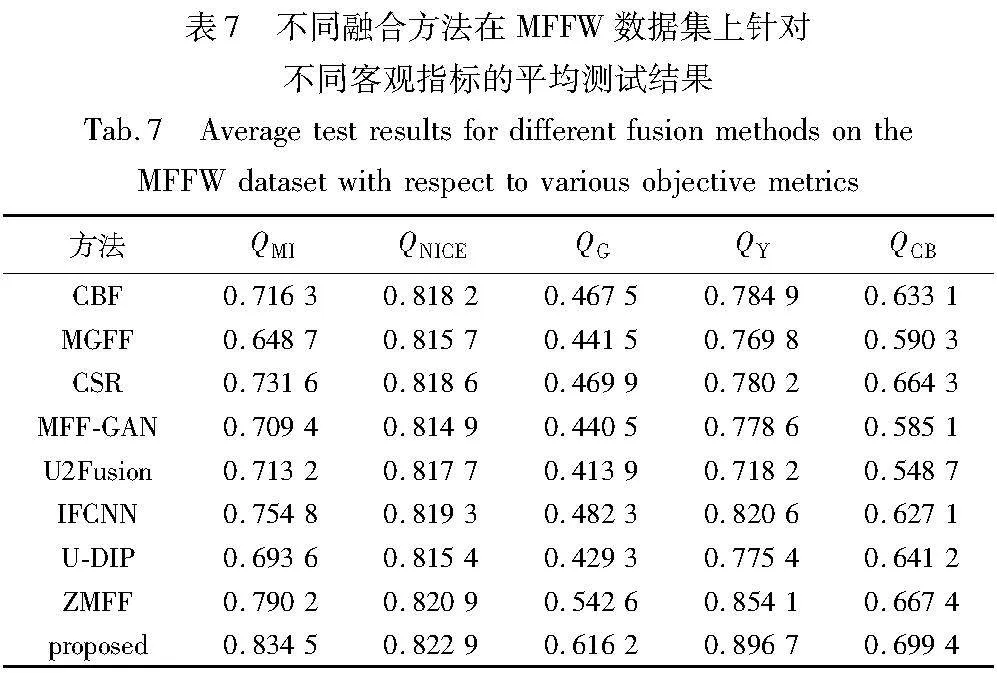
本文在MFFW数据集的13对源图像上,针对上述8种用于对比的融合方法进行了评价测试,所得到的五个客观指标的平均值如表7所示。
对于MFFW数据集,由表7中的数据可以清楚地看出,与其他方法相比,本文方法在该数据集上的融合性能具有显著的优势。具体地,与目前最先进的其他八种方法相比,本文方法在所有五个客观指标上均位列第1位。尤其值得注意的是,对于QG指标,本文方法虽然在Lytro数据集上排名第4(参见表6),但在MFFW数据集上却以较大的优势位居第1。这说明,在数据集的源图像边界存在强DSE的情况下,本文方法能够较好地平滑融合边界、过滤掉多余的噪声,从而有效地降低融合边界的DSE影响、改善融合图像的质量。
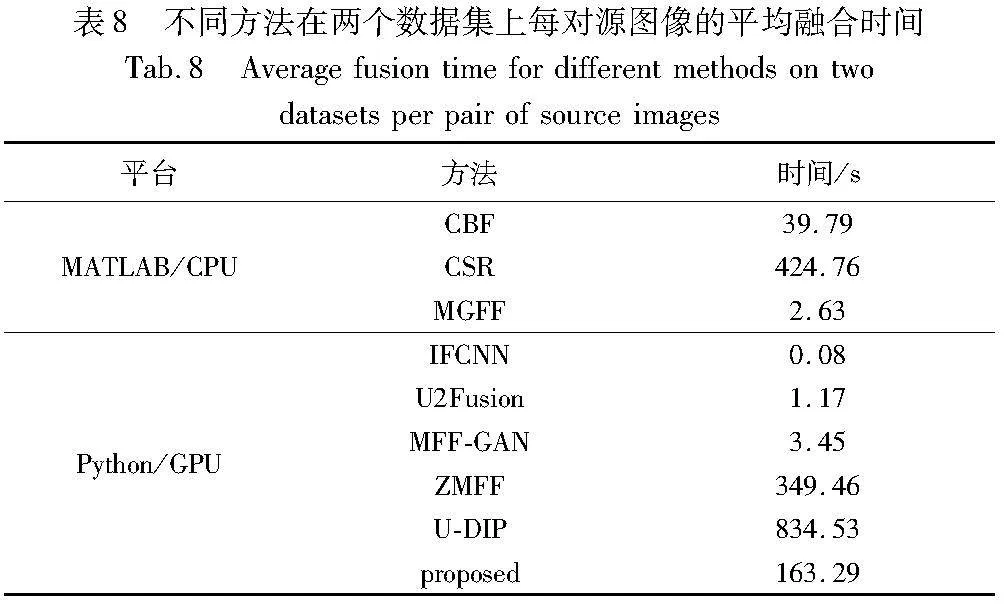
3.7 计算效率分析
为了综合评估不同融合方法的计算效率,表8列出了九种方法在两个数据集上针对每对源图像对融合的平均运行时间。其中,CBF、CSR和MGFF方法是在处理器为AMD Ryzen 7 5800H with Radeon Graphics的CPU 上进行测试(软件平台为MATLAB);而IFCNN、U2Fusion、MFF-GAN、ZMFF、U-DIP和本文方法是在NVIDIA RTX3060 GPU 12 GB上进行测试(软件平台为PyTorch)。根据实验结果显示,MGFF、IFCNN、MFF-GAN和U2Fusion方法在每对源图像上的平均运行时间相对较短;CBF方法的运行时间相对适中;而U-DIP方法因为在原始DIP上增加通道数,损失函数较为单一,所以很难确定合适的迭代次数,导致该方法运行时间显著延长。而CSR、ZMFF和本文方法的运行时间相对较长。这是因为,CSR方法采用变换域的融合策略进行融合,所以需要更多的处理时间;而ZMFF和本文方法虽然无须进行训练或构建“真实”数据集,但基于深度神经网络的优化迭代往往需要较多的耗时。然而,如果考虑深度学习方法的训练时间,这些方法的整体耗时也会相对较长。此外,深度学习方法在构建“真实”数据集和进行有效训练方面都存在较多的耗时,这是不能忽视的。因此,考虑到本文方法既是零样本训练方法,又能有效地降低融合边界的DSE,其综合性能就具有较强的竞争力。特别地,本文方法通过充分利用多聚焦图像的内外先验信息来确定最优的迭代次数,相较于同类的ZMFF方法在效率上有了显著提升。
3.8 扩充到多源图像融合
当需要融合多于两个多聚焦源图像时,本文方法同样适用。为了验证这一点,本文在一个包含三个多聚焦源图像的序列上进行了实验。具体地,本文首先将其中两个源图像进行融合,然后将这个中间融合结果与最后一个源图像进行融合,最后得到最终的融合图像。在图9中,本文示例了使用Lytro数据集提供的两组三个多聚焦源图像进行融合的结果。值得指出的是,本文方法也可以扩充到同时对两个以上的源图像进行融合。由图9的实验结果表明,本文方法能够有效地将输入多源图像中的所有聚焦区域综合到融合图像中,且没有引入明显的空间伪影。此外,考虑到多源图像本身特征的复杂性,并且需要两两进行融合,所以使用本文方法优化处理时会尤为耗时。因此,将来的研究有必要进一步改进和提高本文方法的效率。
4 结束语
本文提出了一种基于目标图像先验信息的无监督MFIF方法。该方法首先利用目标图像的内部和外部先验信息作为网络输入,并使用F-Net和G-Net两个U-Net网络分别作为融合和决策图形成的主干网络;然后,通过选择适当的优化迭代次数和损失函数,使得F-Net能够生成高质量的最终融合图像。本文方法的融合性能验证实验基于真实数据集Lytro和具有强DSE的MFFW数据集。实验结果表明,本文方法在综合融合性能方面优于目前最先进的方法,并且它能够有效地降低或消除融合图像的边界DSE、伪影和噪声。
然而,在本文方法中仍然存在一些问题。例如,针对多聚焦图像融合领域如何为DIP网络设计出更合适的迭代终止策略,以及如何确定最优的DIP网络等问题,都是笔者在后续工作中需要进一步研究和改进的内容。
参考文献:
[1]Ma Jiayi, Ma Yong, Li Chang. Infrared and visible image fusion methods and applications: a survey[J]. Information Fusion, 2019,45: 153-178.
[2]Li Hui, Manjunath B S, Mitra S K. Multisensor image fusion using the wavelet transform[J]. Graphical Models and Image Proces-sing, 1995,57(3): 235-245.
[3]Yang Bin, Li Shutao. Multi-focus image fusion and restoration with sparse representation[J]. IEEE Trans on Instrumentation and Measurement, 2009,59(4): 884-892.
[4]Petrovic V S, Xydeas C S. Gradient-based multiresolution image fusion[J]. IEEE Trans on Image Processing, 2004,13(2): 228-237.
[5]Liu Wei, Wang Zengfu. A novel multi-focus image fusion method using multiscale shearing non-local guided averaging filter[J]. Signal Processing, 2020,166: 107252.
[6]De I, Chanda B. Multi-focus image fusion using a morphology-based focus measure in a quad-tree structure[J]. Information Fusion, 2013,14(2): 136-146.
[7]Li Zhenhua, Jing Zhongliang, Liu Gang, et al. Pixel visibility based multifocus image fusion[C]//Proc of International Conference on Neural Networks and Signal Processing. Piscataway,NJ:IEEE Press, 2003:1050-1053.
[8]Ulyanov D, Vedaldi A, Lempitsky V. Deep image prior[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2018: 9446-9454.
[9]Hu Xingyu, Jiang Junjun, Liu Xianming, et al. ZMFF: zero-shot multi-focus image fusion[J]. Information Fusion, 2023, 92: 127-138.
[10]Liu Yu, Chen Xun, et al. Image fusion with convolutional sparse representation[J]. IEEE Signal Processing Letters, 2016, 23(12): 1882-1886.
[11]Bavirisetti D P, Xiao Gang, Zhao Junhao, et al. Multi-scale guided image and video fusion: a fast and efficient approach[J]. Circuits, Systems, and Signal Processing, 2019,38(12): 5576-5605.
[12]Kumar B K S. Image fusion based on pixel significance using cross bilateral filter[J]. Signal, Image and Video Proces-sing, 2015,9(5): 1193-1204.
[13]Bai Xiangzhi, Zhang Yu, Zhou Fugen, et al. Quadtree-based multi-focus image fusion using a weighted focus-measure[J]. Information Fusion, 2015, 22: 105-118.
[14]Liu Yu, Chen Xun, Peng Hu. et al. Multi-focus image fusion with a deep convolutional neural network[J]. Information Fusion, 2017,36: 191-207.
[15]Zhang Yu, Liu Yu, Sun Peng, et al. IFCNN: a general image fusion framework based on convolutional neural network[J]. Information Fusion, 2020, 54: 99-118.
[16]Wang Yicheng, Xu Shuang, Liu Junmin, et al. MFIF-GAN: a new generative adversarial network for multi-focus image fusion[J]. Signal Processing: Image Communication, 2021, 96: 116295.
[17]Xu Han, Ma Jiayi, Jiang Junjun, et al. U2Fusion: a unified unsupervised image fusion network[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2020,44(1): 502-518.
[18]Gandelsman Y, Shocher A, Irani M. “Double-DIP”: unsupervised image decomposition via coupled deep-image-priors[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2019: 11026-11035.
[19]Xu Shaoping, Cheng Xiaohui, Luo Jie, et al. Boosting deep image prior by integrating external and internal image priors[J]. Journal of Electronic Imaging, 2023, 32(1): 013021.
[20]Ma Xudong, Hill P, Anantrasirichai N, et al. Unsupervised image fusion using deep image priors[C]//Proc of IEEE International Conference on Image Processing. Piscataway,NJ:IEEE Press, 2022: 2301-2305.
[21]Xu Shaoping, Chen Xiaojun, Luo Jie, et al. A deep image prior-based three-stage denoising method using generative and fusion strategies[J]. Signal, Image and Video Processing, 2023, 17: 2385-2393.
[22]Li Shutao, Dian Renwei, Liu Haibo. Learning the external and internal priors for multispectral and hyperspectral image fusion[J]. Science China Information Sciences, 2023, 66(4): 140303.
[23]谢明, 曲怀敬, 张志升,等. 基于导向滤波和聚焦区域局部标准差的多聚焦图像融合[J]. 计算机与数字工程, 2023, 51(2): 348-354. (Xie Ming, Qu Huaijing, Zhang Zhisheng,et al. Multi-focus image fusion based on local standard deviation of focus region[J]. Computer and Digital Engineering, 2023,51(2): 348-354.
[24]Li Heng, Zhang Liming, Jiang Meirong, et al. Multi-focus image fusion algorithm based on supervised learning for fully convolutional neural network[J]. Pattern Recognition Letters, 2021,YfBCQH3jQkeyRSXzgYthFQ== 141: 45-53.
[25]Zhang Juncheng, Liao Qingmin, Liu Shaojun, et al. Real-MFF: a large realistic multi-focus image dataset with ground truth[J]. Pattern Recognition Letters, 2020,138: 370-377.
[26]Wang Zhou, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans on Image Processing, 2004,13(4): 600-612.
[27]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2014). https://arxiv.org/abs/1409.1556.
[28]Xu Shuang, Wei Xiaoli, Zhang Chunxia, et al. MFFW: a new dataset for multi-focus image fusion[EB/OL]. (2020). https://arxiv.org/abs/2002.04780.
[29]Hossny M, Nahavandi S, Creighton D. Comments on′Information measure for performance of image fusion′[J]. Electronics Letters, 2008, 44(18): 1066-1067.
[30]Wang Qiang, Shen Yi, Jin Jing. Performance evaluation of image fusion techniques[J]. Image Fusion: Algorithms and Applications, 2008,19: 469-492.
[31]Wang Qiang, Shen Yi,Zhang Jianqiu. A nonlinear correlation mea-sure for multivariable data set[J]. Physica D: Nonlinear Pheno-mena, 2005, 200(3-4): 287-295.
[32]Di Gai, Shen Xuanjing, Chen Haipeng, et al. Multi-focus image fusion method based on two stage of convolutional neural network[J]. Signal Processing, 2020, 176: 107681.
