
基于空间注意力图的知识蒸馏算法
2024-07-31 00:00:00王礼乐刘渊
计算机应用研究 2024年6期




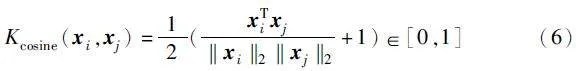
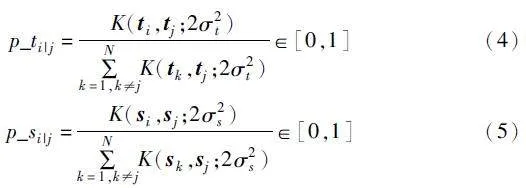



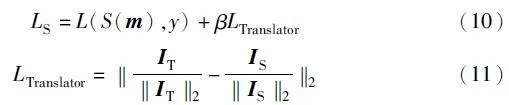


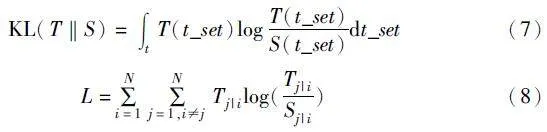
摘 要:知识蒸馏算法对深度神经网络的精简具有很大的推动作用。当前基于特征的知识蒸馏算法或只关注单个部分进行改进,忽视了其他有益部分,或是对小模型应重点关注的部分提供有效指导,这使得蒸馏的效果有所欠缺。为了充分利用大模型的有益信息并处理,以提升小模型知识转换率,提出一种新型蒸馏算法。该算法首先使用条件概率分布对大模型中间层进行特征空间分布拟合,提取拟合后趋于相似的空间注意力图,将其与其他有益信息一起,通过用于缩小模型间差距的小型卷积层,将转换后的信息传递给小模型,实现蒸馏。实验结果表明,该算法具有多师生组合适用性与多数据集通用性,相比于当前较为先进的蒸馏算法,性能提升约1.19%,用时缩短0.16 h。对大型网络的优化与深度学习部署在低资源设备上的应用具有重要的工程意义与广泛的应用前景。
关键词:知识蒸馏;知识迁移;模型压缩;深度学习;图像分类
中图分类号:TP301.6 文献标志码:A文章编号:1001-3695(2024)06-013-1693-06
doi: 10.19734/j.issn.1001-3695.2023.10.0496
Knowledge distillation algorithm based on spatial attention map
Abstract: Knowledge distillation algorithms have a great effect on the streamlining of deep neural networks. The current feature-based knowledge distillation algorithms either focus on a single part for improvement and ignore other beneficial parts, or provides effective guidance for the part that a small model should focus on, which makes the distillation effect insufficient. In order to make full use of the beneficial information of the large model and process it to improve the knowledge conversion rate of the small model, this paper proposed a new distillation algorithm. Firstly, it used the conditional probability distribution to fit the feature spatial distribution of the large model’s middle layer, and then extracted the spatial attention maps that tended to be similar after fitting together with other beneficial information. Finally, it used the small convolutional layer, narrowed the gap between models, transmitted the transformed information to the small model to achieve distillation. Experimental results show that the algorithm has the applicability of multiple teacher-student combinations and the generality of multiple data sets, and compared with the current more advanced distillation algorithms, the performance is improved by about 1.19% and the time is shortened by 0.16 h. It has important engineering significance and wide application prospects for large networks’ optimization and the application of deep learning on low-resource devices.
Key words:knowledge distillation; knowledge transfer; model compression; deep learning; image classification
0 引言
深度学习[1]被广泛应用于计算机视觉[2,3]、自然语言处理[4]、推荐系统[5]等人工智能相关领域中。然而近年来模型深度的增加导致了参数量以及计算量的爆炸性增长[6],使得深度学习在低资源设备上的应用受到了限制。
为提升资源利用率,去除网络中冗余的模型压缩算法[3,7]应运而生。目前,在模型压缩和加速方面常用的方法可分为剪枝[8,9]与量化[10,11]、低秩因子分解[12,13]、迁移/压缩卷积滤波器[14]以及蒸馏学习四类。
其中,量化通过减少权重位数达到压缩网络的目的;剪枝主要修剪网络模型的冗余权重;迁移/压缩卷积滤波器引入两个全局超参数,依靠平移不变性和卷积权重共享实现良好的预测性能。知识蒸馏(knowledge distillation,KD)是用浅层的模型训练重现较大网络的输出[15],由Hinton 等人于2015年首次提出[16]。根据提取的知识类型分类可以概括为基于响应、基于关系和基于特征的蒸馏[17]。
基于响应的方式关注网络的最后一层,用大模型分类的结果协调小模型的最终预测。HKD(heterogeneous knowledge distillation)应用辅助教师网络传输信息流以缩小师生能力差距[18]。DGKD(densely guided knowledge distillation)采用多种引导模式联合执行多步蒸馏训练学生模型[19]。SFTN(student friendly teacher networks)则通过培训师生分支,并从中挑选出更易于传递的知识给学生,以提升学习效果[20]。
基于关系的蒸馏可以将过程看作一个实例图,节点表示样本的特征嵌入。Zhao等人[21]提出了一种新颖的对比知识迁移框架(compare knowledge transfer framework,CKTF),通过优化跨中间表示的多个对比目标,将足够的结构知识从大模型移到小模型。DarkRank[22]方法使用欧几里德距离来检查跨样本的相似性。REFILLED让教师模型衡量学生模型转发来的硬三元组,并与之进行关系匹配来实现目的[23]。
基于特征的蒸馏主要针对中间层特征图及其细化信息蒸馏。方式有引入跨各层特征图测量求解的流程[24] 、让学生模仿特征图表示方式[25]、引入转换复杂知识信息的自动编码器[26]、利用表示学习获取网络间传输对比目标[27]以及使用教师的判别分类器进行推理[28]等。
由于模型中间层包含许多有益信息,合理利用可以更好地实现蒸馏,所以本文主要研究基于特征的蒸馏方式,而目前基于特征蒸馏算法都存在一些问题。例如,在不同维度的层上实现转移时,对特征空间采用概率分布拟合的方式忽视了特征知识的重要性、仅依靠额外引入的小型网络结构提升信息转换率忽略了教师原有信息中大量可开发的部分,这导致学生模型在准确度方面仍有不足,同时大多数知识蒸馏算法都是学生直接学习教师模型传递来的知识,这些知识并没有区分重要性,使得学生训练的效果不能足够地接近预期。
本文提出了APF-KD(attention-based probabilistic factor knowledge distillation)算法,针对目前只关注结构或只关注特征知识的单一知识蒸馏,可以同时关注中间层蕴涵的特征结构与知识信息,双管齐下的方式使得学生学习时不会遗漏蒸馏各个环节的有益知识。同时让学生回归教师特征空间的几何图形,根据教师的注意力图直接关注到需要关注的区域,使学生学习更有效率。算法先对师生模型进行特征空间匹配,再对教师进行空间注意力提取,最后将训练好的模型知识经由解释器二次翻译传递给学生。在提升灵活性的同时,也使学生学习效果达到了最优化。
本文的研究贡献主要是:
a)实现了资源开销和精度提升的平衡,深度挖掘教师模型中间层中包含的结构信息,向学生模型传递更为精细的知识内容,提高了学生模型的表现。
b)将对教师空间结构的学习分为两步:对教师特征空间结构采用概率获取学习控制开销成本;在师生进行信息传递时,连同教师注意力图一起放入用于转译知识的小卷积层中,以降低学生模型理解难度。上述操作提升了学生网络精度。
c)算法对教师中间层进行多步操作,在控制模型资源开销的前提下,提升学生模型的效果。实验证明,与其他知识蒸馏算法相比,本算法性能最高可提升约18.87%,蒸馏效果更好。
1 基于特征的知识蒸馏算法
知识蒸馏采用teacher-student模式, teacher是知识的输出者,student是知识的接受者。知识蒸馏的过程分为两个阶段:a)教师模型预训练,训练一个大模型并保存其网络结构相关信息,为训练学生作准备;b)学生模型训练,挑选一个参数量较小、模型结构相对简单的模型,并结合教师模型的信息进行训练。
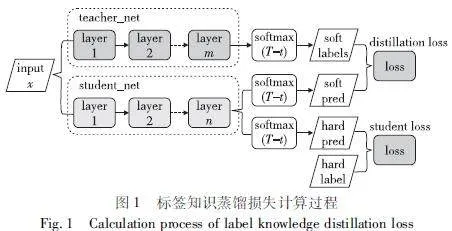
用教师学习的知识训练学生,可以增强学生模型的泛化能力。传统知识蒸馏算法就是学生用教师模型关于分类的信息进行训练,不断降低loss值,获得与大模型相近的性能,过程如图1所示。
loss计算方法如式(1)所示。
L=(1-α)LT+αLS(1)
其中:LT、LS分别为教师与学生模型的训练损失。
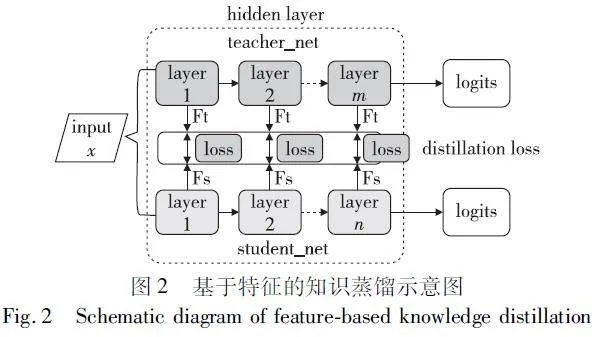
传统的标签蒸馏效果不佳,根本原因在于标签内包含的信息远低于中间层的信息,故学习大模型的中间层信息可有效提升小模型的表现。基于特征的知识蒸馏不同于传统的标签蒸馏,它关注用于训练的中间层并从中挖掘大量有用信息训练小模型,流程如图2所示。
引入跨各层特征图测量求解的流程[24]让研究的目光不再局限于大模型的softmax层;以学生模仿特征图表示方式[25] 可以很好地从学习方式上助推小模型效果提升;考虑到小模型的理解能力,引入能转换复杂知识信息的自动编码器帮助小模型理解信息[26];利用表示学习获取网络间的传输对比目标[27],增强类别内互信息的相似与类别间互信息的差异,实现小模型对大模型的学习;类似引入自动编码器的策略开发一个投影结构,让学生能够使用教师的判别分类器进行推理[28]等。
目前基于特征的同构知识蒸馏算法中,SemCKD算法提出了让学生自动与语义相关的目标层进行匹配,实现注意力分配的方法[30],兼顾了注意力机制与候选层数量不匹配的问题。而ER-KD利用教师预测中的熵,在样本的基础上重新加权蒸馏损失,实现了更平衡的知识转移[31]。
2 APF-KD知识蒸馏算法设计
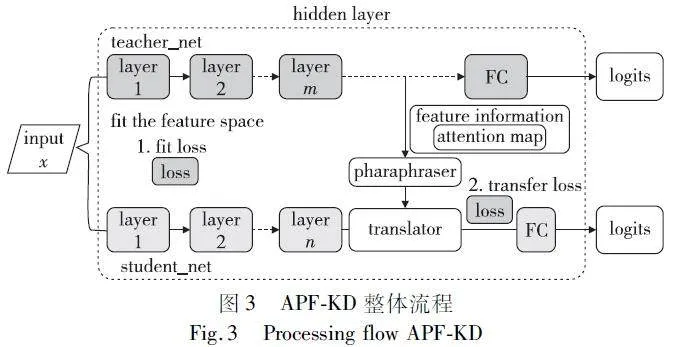
教师模型的知识转换能力直接关系到学生模型最终的性能,因此APF-KD算法为了提升模型知识转移能力,首先对模型特征空间进行操作,增强学生的学习理解能力。同时引入注意力机制,对教师的注意力图进行提取,并将信息传递给学生,让学生模型关注到更有意义的内容。考虑到师生模型差异较大的情况,算法引入因子转移模式,在师生模型中分别加入释义器与解释器,将教师模型知识进行翻译转述传递给学生,指导学生模型进行训练。APF-KD的整体流程如图3所示。
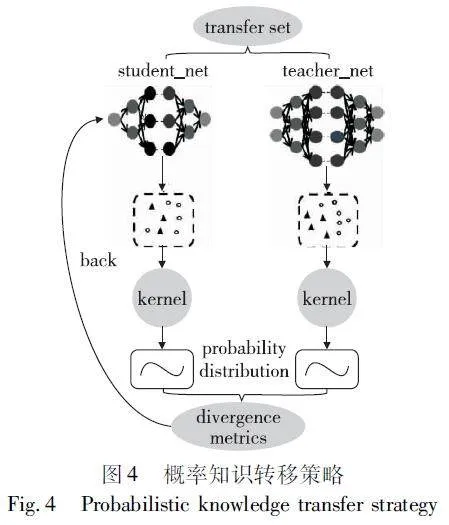
2.1 概率知识转移策略
本文引入概率知识转移策略,利用教师模型的特征空间信息训练学生模型,让学生通过学习教师的特征空间结构提升学习效果[25],如图4所示。
设置一个具有N个对象的转换集T_set,表示教师传递给学生的知识集合,学生通过T_set获取教师网络的知识并进行学习。教师与学生的输出表示如式(2)(3)所示。
t=f(t_set)(2)
s=g(t_set,W)(3)
其中:t_set为转换集T_set中的对象,对大小模型关于同一转换集T_set的输出t和s进行操作,方便达到拟合师生特征空间结构的目的。学生需要去学习教师的结果,所以计算学生网络输出的公式中,额外加入了用于训练学习教师的参数W。
基于每批数据样本间的关联性,对特征空间中的两个数据点进行条件概率密度计算,可以描述出特征空间的几何形
状。所以式(4)(5)为教师和学生中任意两个数据点间的条件概率分布。
条件概率分布p_t、p_s计算式中的K函数为基于有限样本推断总体数据分布的核密度估计。对两个数据点向量进行内积归一化可以解决不断调整内核宽度的问题,故采用余弦相似度核函数作为K函数,如式(6)所示。
式(4)已经获得了教师的特征空间结构信息,计算师生的概率分布相似度,学生可以拟合教师的特征空间,故引入KL散度,并采用损失函数缩小学生与教师空间结构上的差异。相应计算及其损失函数如式(7)(8)所示。
其中:T与S是式(4)(5)中获得的师生模型概率分布;t_set为转换集T_set中的对象。
经过拟合特征空间操作后,师生的特征图空间分布趋于相似,学生模型对于信息的处理能力得到了提升。
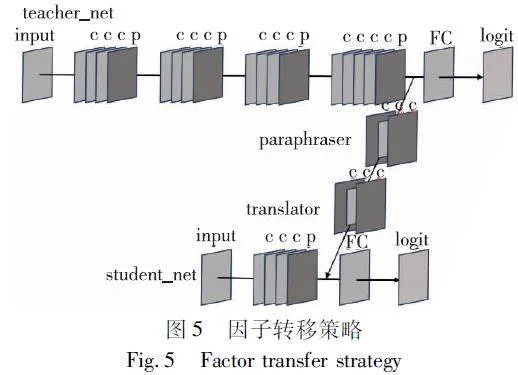
2.2 因子转移策略
概率知识转移策略关注到了教师特征空间结构上所蕴涵的信息,有意识地指导学生学习结构可以提升模型的效果。但该策略忽视了中间层特征知识的学习,为弥补这一缺陷,本文加入因子转移策略,让学生模型学习的同时把握住中间层的结构信息与特征知识。
直接学习教师模型传递来的知识不能有效提升学生模型的表现。故本文引入利用因子转移的“释义器-解释器”[26] 模式,将教师模型传递的信息进行“翻译”以帮助学生模型学习,如图5所示。
由于大模型与小模型专注于同一任务,大模型最后一层的特征图中存在对小模型训练有益的因素,所以可以采用释义器作为获取教师模型输出特征图的中转,以无监督的方式对
其训练并重建损失获取有益因素,损失计算如下:
LParaphraser=‖m-P(m)‖2(9)
其中:m表示的是教师模型的特征图;P(m)表示释义器的输出特征图。
得到教师因素后,释义器将信息传递给插入小模型最后一组卷积层后的解释器中,让学生同时进行训练,在此过程中会产生两种损失:学生自身训练损失与解释器传递知识带来的损失。故损失计算如式(10)所示。
其中:式(10)第一项L(S(m),y)计算学生网络对于输入图像m的输出与真实标签间y的交叉熵;第二项βLTranslator即为解释器的损失,其计算如式(11)所示,其中IT与IS为师生网络中的信息因素。经过释义器和解释器的信息能够降低学生理解的困难,提升学生模型的准确率。
2.3 APF-KD算法设计
概率知识转移策略关注教师的空间结构,因子转移策略关注的是教师的输出信息,两者结合后,学生可以同时把握结构与知识。但因子转移策略中关注的输出信息并无侧重,而师生模型在经过 2.1 节的空间拟合操作后,特征图空间分布已趋于相似。此时若引入更具解释性的空间注意力图,学生蒸馏效果将进一步提升。
教师模型的注意力图中包含了信息处理重点,如图6 所 示,而学生可以根据这一信息调整学习权重。
本文选取跨多个层中用于计算的空间注意力图,对其进行映射转换,将三维转为一维,如图7所示。由于获取教师的注意力图只在每一次迭代时进行,没有多余步骤,所以不会产生额外计算开销[29]。
将注意力图信息传递给学生的过程与信息传递给释义器同步,故计算转移损失时应加入对注意力图的转移损失,计算如式(12)所示。
其中:式(12)为式(10)加入转移注意力图后损失的变式。式(12)中α与β为两项损失的权重。式(13)中Mj是第j对师生注意力图的矢量化形式表达。
APF-KD算法的训练流程如图8所示。为了让学生能直接关注到应当集中注意力的地方,在到达分类层之前先对网络的特征空间进行匹配拟合,然后将教师模型中的注意力图有关的网络参数提取出来指导学生。最后为了让学生模型更好地接受传递来的知识信息,以一个小型网络作为媒介,把知识进行一次理解消化,将信息进行二次转述,从而完成教师模型的蒸馏。
算法 1 APF-KD算法
3 实验
实验配置:Tesla GPU_V100显卡,32 GB显存,CPU为8核32 GB内存,Windows 10操作系统。实验开发语言为Python 3.7。
3.1 实验相关介绍
在3.2节中选取标签蒸馏算法KD(knowledge distillation)、概率知识转移算法PKT(probability knowledge transfer)[25]、因子转移算法FT(factor transfer)[26]、异构知识蒸馏HKD(heterogeneous knowledge distillation)[18]、具有语义校准的跨层蒸馏SemCKD(cross-layer distillation with semantic calibration)[30]、熵重加权知识蒸馏ER-KD(entropy-reweighted know-ledge distillation)[31]与APF-KD进行对比。PKT与FT均采用单一策略蒸馏,前者学习教师特征空间结构,后者学习教师中间层的最后一层信息;HKD算法允许师生网络结构不相似;SenCKD算法与APF-KD均引入注意力机制;SemCKD侧重于学生自动匹配与语义相关的目标层来分配注意力;APF-KD则借助拟合特征空间后已趋于相似的空间注意力图直接操作;ER-KD利用教师预测中的熵对蒸馏损失重新加权。根据提取的知识类型分类的不同,本次选取的三种先进算法HKD、SemCKD、ER-KD分别对应基于响应、基于特征、基于关系的蒸馏。
实验选取的师生模型均为ResNet结构,但深度差异较大,ResNet-50中包含了49个卷积层和1个全连接层,ResNet-18中包含17个卷积层与1个全连接层。ResNet-18的基本模块为Basicblock,包含2次卷积;ResNet-50的基本模块为Bottleneck,包含3次卷积;ResNet-18的基本模块为Basic-block,同样是3次卷积。
在3.3节中选取3组教师学生模型结构,证明算法适用于不同的网络。第一组师生模型选取具有相同宽度(通道数)和不同深度(块数)的ResNet-34与ResNet-18。第二组选取不同残差块的ResNet-50与ResNet-18。第三组选取相同深度不同宽度的WRN-16-2与WRN-16-1。WRN-16为宽残差网络结构,网络深度为16。WRN通过在原始残差模块的基础上加上了一个系数k拓宽卷积核的个数,即第三组实验中的1与2。同时为了验证APF-KD适用于多种数据集,实验分别在Cifar-10与Cifar-100数据集上运行,Cifar-10数据集共有60 000个样本,每个样本都是一张32×32像素的RGB图像(彩色图像),每个RGB图像分为3个通道。Cifar-100数据集有100个类。每个类有600张大小为32×32的彩色图像,其中500张作为训练集,100张作为测试集,同样是3通道。
实验选取ResNet-18作为学生模型,ResNet-34作为教师模型。
为保证本文实验的公平性,所有的对比实验选取的教师学生初始模型均相同,实验结果均保留两位小数。
3.2 APF-KD性能测试
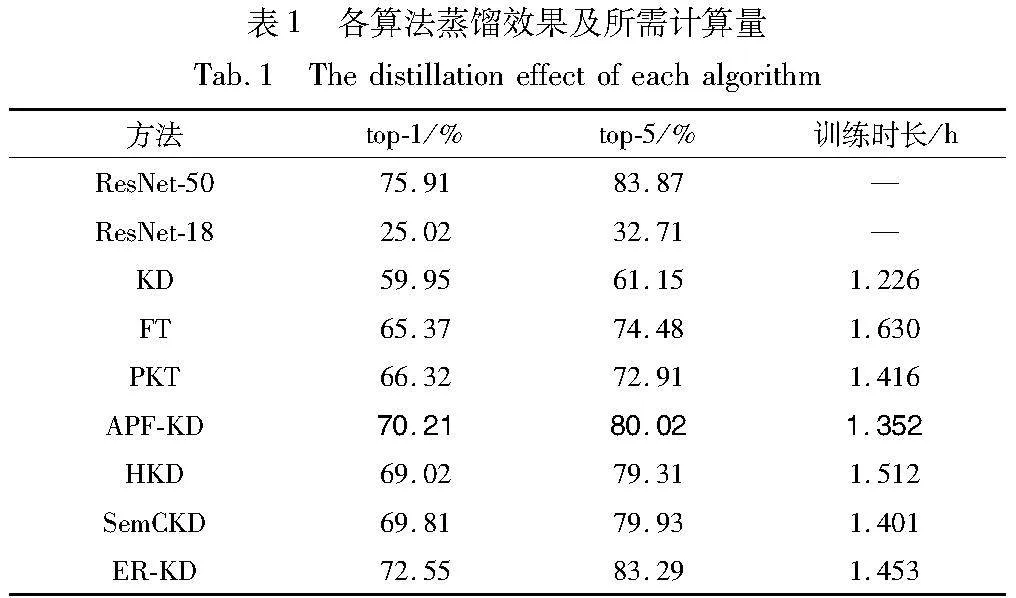
实验选取KD、FT、PKT三种基线算法与三种当前较为先进的蒸馏算法(HKD、SemCKD、ER-KD与APF-KD)对比。实验结果如表1所示,以加粗字体标记APF-KD实验结果,分隔开基线算法与先进算法,表中 ResNet50与ResNet18分别代表预处理后的教师模型与未经训练的学生模型。
由于本次实验选取的师生模型、数据集均一致,所以模型的FLOPs与params都相同。total params为11 689 512,total memory为0.53 MB,total madd为75.26 Madd,total FLOPs为37.67 MFLOPs。据此,本文从训练所需时间角度来比较APF-KD的开销优势。
与基线蒸馏算法相比, APF-KD的蒸馏效果与教师模型效果最为接近,只低5.7%,具有更好的蒸馏性能。相比于KD算法,本文算法在top-1与top-5情况下分别提升了10.26%与18.87%,且比只用一种策略的FT和PKT算法在top-1情况下性能分别高出4.84%与3.89%。
在模型与数据集均一致的前提下,对比当前较为先进的基于特征的同构蒸馏算法SemCKD,APF-KD的准确度提升0.4%与0.09%,时间上短0.049 h。而相比于基于响应的异构知识蒸馏算法HKD,APF-KD的准确度不仅高出1.19%与0.71%,且计算时间上也短0.16 h。但对比ER-KD算法,虽然APF-KD在准确度上略低于ER-KD,但在用时上节约了0.101 h。
3.3 APF-KD适用性与通用性测试
为验证算法具有适用性,本文设置了三种师生组合,将蒸馏结果与初始学生模型准确度进行比较。为验证算法的通用性,将分别在Cifar-10与Cifar-100数据集上运行。实验结果如表2所示,其中表格第四、五列的师生模型的准确度为投入各数据集训练的效果。
实验结果表明,在三种不同师生模型组合的情况下,在Cifar-10数据集上使用APF-KD算法的准确度比未经训练的学生模型准确度分别提升了34.81%、39.39%和15.01%,在Cifar-100数据集上分别提升了38.01%、44.29%和15.43%。综上可得,APF-KD不仅适用于不同师生搭配的情况,且在不同数据集上表现均佳。
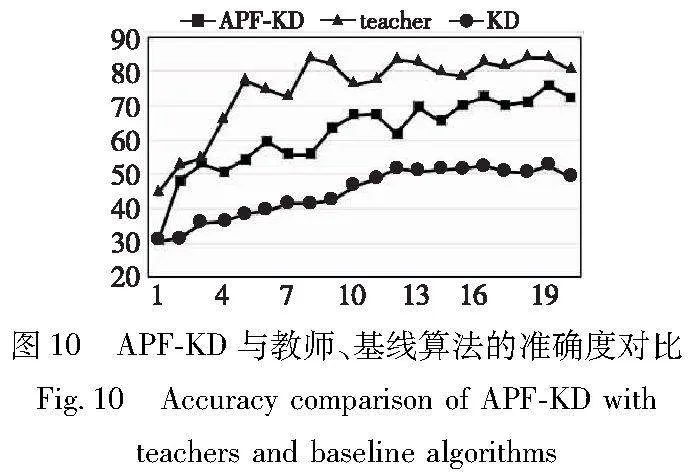
图9所示为第二种师生组合下使用APF-KD的学生模型数据迭代情况。可以看出,当训练至第20个epoch时,学生模型准确度与训练损失逐渐趋于稳定,且此时准确度达到较高水平。
图10反映的是经过20个epoch训练后第二种师生组合下教师及分别采用APF-KD、KD算法后学生模型准确度的变化。
比较可知,APF-KD性能在初始阶段就已显示出远超KD的优势,且仅经过极少的epoch就可以接近教师性能,如图中epoch为3时两者准确度几乎重叠。由此可知,前期对于教师模型空间曲线的拟合很有效果,所以模型可以在前期就呈现出好的表现。继续训练后,其表现已逐渐逼近教师,说明经过重点内容的指导与信息的二次转译,模型的优势持续扩大。
3.4 APF-KD消融研究
本文3.2节实验验证了APF-KD的有效性,为了证明本文算法的各部分均有益,本节将对APF-KD进行消融实验,结果如表3所示。
观察实验1、2、3组可知,仅采取单个策略的效果均不如4~7组的混合策略效果。将表中1、5组与第3、5组数据分别对比可知,结合概率知识转移策略与因子转移策略可以实现性能的提升。但再次深入对比5、7两组可以发现,第5组的效果还是略低于第7组,对比其中不同的部分可以发现,第7组是实验中加入对于重点部分指导即注意力图信息后达到的效果,使得算法效果达到最优,即75.72%。相似的情况也出现在6、7两组与4、7两组之间,这三种情况均是对比7组少采取一个策略,由此可知三部分均是不可缺少的。
综上可知,概率知识转移策略、因子转移策略以及注意力机制三部分对于APF-KD算法而言均为有益因素。
4 结束语
本文提出了一种对师生网络中间层进行加工的知识蒸馏算法APF-KD。首先对教师网络特征空间进行处理,缩小师生空间结构差异,然后在传递的信息中加入注意力图,提示学生重点所在,并对所有传递信息二次加工以帮助学生理解,提升小模型的学习性能。
实验证明,本文提出的APF-KD算法具有通用性与适用性的特点,且算法中各部分均有益。在性能方面,APF-KD算法更具有竞争力。但由于算法在中间层进行多步操作,相比其他算法更加耗时,未来笔者将进一步探索如何缩减算法所需时间以扩大优势。
参考文献:
[1]LeCun Y,Bengio Y,Hinton G. Deep learning [J]. Nature,2015,521: 436-444.
[2]Krizhevsky A,Sutskever I,Hinton G. ImageNet classification with deep convolutional neural networks [J]. Communications of the ACM,2012,60: 84-90.
[3]He Kaiming,Ren Shaoqing,Sun Jian,et al. Deep residual learning for image recognition [C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2016: 770-778.
[4]Ravali B,Gowtham R. A survey on NLP based text summarization for summarizing product reviews [C]// Proc of the 2nd International Conference on Inventive Research in Computing Applications. 2020: 352-356.
[5]Jennifer J,Eric B,Gregory L,et al. Recommendation system: USA,7908183 [P]. [2023-12-12].
[6]Taigman Y,Yang M,Ranzato M,et al. DeepFace: closing the gap to human-level performance in face verification [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2014: 1701-1708.
[7]Li Shen,Sun Yan,Yu Zhiyuan,et al. On efficient training of large-scale deep learning models: a literature review [EB/OL]. (2023) [2023-12-12]. https://api. semanticscholar. org/CorpusID: 258041319.
[8]Wu Jiaxiang,Leng Cong,Wang Yuhang,et al. Quantized convolutional neural networks for mobile devices [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2015: 4820-4828.
[9]Song Han,Mao Huizi,Dally W. Deep compression: compressing deep neural network with pruning,trained quantization and Huffman coding [EB/OL]. (2015) [2023-12-12]. https://api. semanticscholar. org/CorpusID: 2134321.
[10]Ullrich K,Meeds E,Welling M. Soft weight-sharing for neural network compression [EB/OL]. (2017) [2023-12-12]. https://api. semanticscholar. org/CorpusID: 7067017.
[11]Chen Shi,Zhao Qi. Shallowing deep networks: layer-wise pruning based on feature representations [J]. IEEE Trans on Pattern Analy-sis and Machine Intelligence,2019,41: 3048-3056.
[12]Shi Bowen,Sun Ming,Kao C C,et al. Compression of acoustic event detection models with low-rank matrix factorization and quantization training [EB/OL]. (2018) [2023-12-12]. https://api. semanticscholar. org/CorpusID: 53381522.
[13]Povey D,Cheng Gaofeng,Wang Yiming,et al. Semi-orthogonal low-rank matrix factorization for deep neural networks [C]//Proc of the 19th Annual Conference on the International Speech Communication Association. 2018: 3743-3747.
[14]Howard A G,Zhu Menglong,Chen Bo,et al. MobileNets: efficient convolutional neural networks for mobile vision applications [EB/OL]. (2017) [2023-12-12]. https://api. sem-anticscholar. org/CorpusID: 12670695.
[15]Bucila C,Caruana R,Niculescu-Mizil A. Model compression: know-ledge discovery and data mining [C]// Proc of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York: ACM Press,2006: 535-541.
[16]Li Zhihui,Xu Pengfei,Chang Xiaojun,et al. When object detection meets knowledge distillation: a survey [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2023,45: 10555-10579.
[17]Yang Chuanguang,Yu Xinqiang,An Zhulin,et al. Categories of response-based,feature-based,and relation-based knowledge distillation [EB/OL]. (2023) [2023-12-12]. https: //api. semanticscholar. org/CorpusID: 259203401.
[18]Passalis N,Tzelepi M,Tefas A. Heterogeneous knowledge distillation using information flow modeling [C]// Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. 2020: 2336-2345.
[19]Son W,Na J,Choi J. Densely guided knowledge distillation using multiple teacher assistants [C]// Proc of IEEE/CVF International Conference on Computer Vision. 2020: 9375-9384.
[20]Courbariaux M,Bengio Y. BinaryNet: training deep neural networks with weights and activations constrained to+1 or-1 [EB/OL]. (2016) [2023-12-12]. https://api. semanticscho-lar. org/CorpusID: 6564560.
[21]Zhao Kaiqi,Chen Yitao,Zhao Ming. A contrastive knowledge transfer framework for model compression and transfer learning [C]// Proc of IEEE Internationape+AlhneHmiRd4zQJR7vDQ==l Conference on Acoustics,Speech and Signal Processing. Piscataway,NJ:IEEE Press,2023: 1-5.
[22]Chen Yuntao,Wang Naiyan,Zhang Zhaoxiang. DarkRank: accelerating deep metric learning via cross sample similarities transfer [EB/OL]. (2017) [2023-12-12]. https://api. semanticscholar. org/CorpusID: 19207026.
[23]Ye Hanjia,Lu Su,Zhan Dechuan. Distilling cross-task knowledge via relationship matching [C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12393-12402.
[24]Yim J,Joo D,Bae J H,et al. A gift from knowledge distillation: fast optimization,network minimization and transfer learning [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2017: 7130-7138.
[25]Passalis N,Tzelepi M,Tefas A. Probabilistic knowledge transfer for lightweight deep representation learning [J]. IEEE Trans on Neural Networks and Learning Systems,2020,32: 2030-2039.
[26]Kim J,Park S,Kwak N. Paraphrasing complex network: network compression via factor transfer [EB/OL]. (2018) [2023-12-12]. https://api. semanticscholar. org/CorpusID: 36 08236.
[27]Tian Yonglong,Krishnan D,Isola P. Contrastive repre-sentation distillation [EB/OL]. (2019) [2023-12-12]. https://api. semanticscholar. org/CorpusID: 204838340.
[28]Chen Defang,Mei Jianhan,Zhang Hailin,et al. Knowledge distillation with the reused teacher classifier [C]// Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition. 2022: 11923-11932.
[29]Zagoruyko S,Komodakis N. Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer [EB/OL]. (2016) [2023-12-12]. https://api. semanticscholar. org/Corpus ID: 829159.
[30]Chen Defang,Mei Jianping,Zhang Yuan,et al. Cross-layer distillation with semantic calibration [C]// Proc of AAAI Conference on Artificial Intelligence. 2020.
[31]Su Chiping,Tseng C H,Lee S J. Knowledge from the dark side: entropy-reweighted knowledge distillation for balanced knowledge transfer [EB/OL]. (2023) [2023-12-12]. https://api.semanticscholar. org/CorpusID: 265444951.
