
强化学习的可解释方法分类研究
2024-07-31 00:00:00唐蕾牛园园王瑞杰行本贝王一婷
计算机应用研究 2024年6期

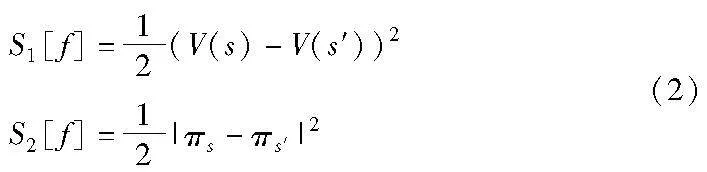

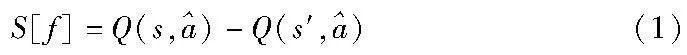
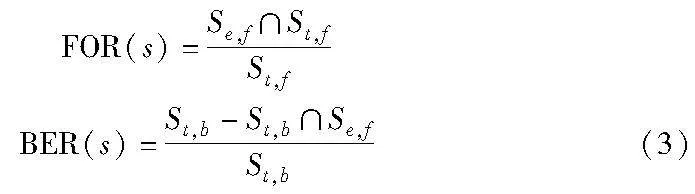
摘 要:强化学习能够在动态复杂环境中实现自主学习,这使其在法律、医学、金融等领域有着广泛应用。但强化学习仍面临着全局状态空间不可观测、对奖励函数强依赖和因果关系不确定等诸多问题,导致其可解释性弱,严重影响其在相关领域的推广,会遭遇诸如难以判断决策是否违反社会法律道德的要求,是否准确及值得信任等的限制。为了进一步了解强化学习可解释性研究现状,从可解释模型、可解释策略、环境交互、可视化等方面展开讨论。基于此,对强化学习可解释性研究现状进行系统论述,对其可解释方法进行归类阐述,最后提出强化学习可解释性的未来发展方向。
关键词:强化学习;可解释性;策略-值函数;环境交互;视觉解释
中图分类号:TP309 文献标志码:A文章编号:1001-3695(2024)06-001-1601-09
doi: 10.19734/j.issn.1001-3695.2023.09.0430
Classification study of interpretable methods for reinforcement learning
Abstract:Reinforcement learning can achieve autonomous learning in dynamic and complex environments, which makes it widely used in fields such as law, medicine, and finance. However, reinforcement learning still faces many problems such as the unobservable global state space, strong dependence on the reward function, and uncertain causality, which results in its weak interpretability, seriously affecting its promotion in related fields. It will encounter limitations such as difficulty in ju-dging whether the decision-making violates social legal and moral requirements, whether it is accurate and trustworthy, etc. In order to further understand the current status of interpretability research in reinforcement learning, this article discussed from the aspects of interpretable models, interpretable strategies, environment interaction and visualization, etc. Based on these, this article systematically discussed the research status of reinforcement learning interpretability, classified and explained its explainable methods, and finally proposed the future development direction of reinforcement learning interpretability.
Key words:reinforcement learning; interpretability; strategy-value functions; environment interaction; visual interpretation
0 引言
随着科技的不断发展,强化学习在金融、医疗、交通、图像识别、语音识别等方面广泛应用[1],大幅缩减了各领域的人工成本,提升了各行业的工作效率,也在一定程度上推动了经济的发展。在交通、医学、金融等领域,对算法可信性的要求会更加严格。强化学习算法通常需要基于大样本的历史数据集来对深度神经网络进行迭代训练,以获取最优的策略模型,决策的准确性是衡量深度神经网络性能的重要指标之一,而若决策过程所依据的思想违反法律和网络安全的原则,则强化学习算法的决策结果在公众面前将会缺乏可信度[2]。此外,算法训练出的策略模型,对于多数训练样本都具有良好的表示能力,如若数据集与训练样本分布存在显著差异,由于策略不具备显著的因果关系,将会造成预测准确率大幅下降[3]。
随着强化学习算法的应用日益广泛,人们对其解释能力的需求也在不断提高。虽然强化学习(reinforcement learning,RL)也被广泛应用于科研与工业领域,可解释强化学习(explainable reinforcement learning,XRL)也受到更多关注,但强化学习一般通过优化方法来解决问题,很少真正关注任务的内在结构,且难以创建人类用户可以理解的更高层次的表示。在强化学习框架中,智能体通过奖励与环境迭代交互生成目标策略,可能导致状态空间和动作空间过大,是强化学习解释难以广泛应用的原因[4]之一,因此,导致可解释算法的设计复杂、计算成本高昂。此外,RL通常适用于模型训练,而很少应用于对话式场景,造成用户不能直接与之交互。总体而言,人工智能的可解释性可分为事前可解释性和事后可解释性[5],事前解释代表模型的可解释性来自于模型自身的内部结构,如线性回归模型、决策树等,事后可解释性即对已经训练好的机器学习模型进行可解释性开发。在人工智能领域的研究中,强化学习从最基础的数学理论逐步演变,至今已然具有较强的逻辑性,且该特性与可解释性的可开发程度密切相关,故进一步对强化学习模型进行可解释性开发,使其更具有优越性。
目前国内外解释黑盒模型的主要方法为基于注意力的方法[6~8]和基于显著图的方法[9~12],通过可视化图像中的像素或者语义对象解释任务[13],易于识别关键决策信息。但这两种方法的解释效果存在局限性,比如在Breakout游戏中高亮Atari智能体及其影响因素,并没有具体解释智能体决策过程。通过构造决策树的方法[14]可以更具体地解释智能体决策,使其具有模块化、灵活性和可扩展性的特点,但该方法受特征表示的限制,并不能处理图像、文本这些非结构化数据;在视觉解释的基础上考虑加入文本解释,生成视觉和文本结合的多模态解释[15,16],以便用户更易于理解。除此之外,针对智能体行为及智能体与环境交互进行可解释开发以便解释智能体策略[17],可通过反事实解释方法[18~23]对比模型变化,辅以因果可解释模型回答因果关系[24],如“模型为什么会作出这样的决策?”“去掉某种特征,模型决策变化的影响因素是什么?”,进而理解模型的决策过程。而目前对于可解释方法质量的评估并没有统一的标准,常用方法是将算法解释的结果与标记的真实结果进行一致性比较,从而评估模型可解释的性能,但并没有定量的指标。强化学习解释方法评估标准的制定实施任重而道远。
随着强化学习应用的日益广泛,强化学习可解释发展的必要性日益提升,已有部分学者对强化学习可解释方法进行了一定的归纳总结。Puiutta等人[25]根据解释信息提取时间(事前解释、事后解释)、解释范围(局部、全局)等特性将强化学习可解释方法分为程序可解释的强化学习、多任务强化学习的分层解释、基于决策树的强化学习可解释、因果可解释四个大类,Wells等人[26]将强化学习解释方法主要分为视觉解释、策略解释、基于查询的解释、基于验证的解释四大类,这两种分类方法的维度差异略大。Heuillet等人[27]提出的分类方法也与Puiutta等人[25]相似,将强化学习可解释方法根据事前解释与事后解释两个维度分类,分类粒度较粗。与前几篇文献相比,Qing等人[28]主要从模型解释、奖励解释、状态解释、任务解释四个方面系统地概述强化学习方法,涵盖文献较丰富、阐述更全面。Glanois等人[5]从可解释的输入、可解释的模型和可解释的决策三方面对强化学习可解释方法进行分类。刘潇等人[29]从环境解释、任务解释、策略解释三个方面对强化学习可解释方法进行了系统阐述。Milani等人[30]主要着眼于解释强化学习智能体,提出了特征重要性、学习过程和马尔可夫决策过程、策略解释三个分类标准。此外,Guidotti等人[31]和Adadi等人[32]的综述主要讨论机器学习黑盒模型的可解释方法,Arrieta等人[33]的综述主要是对可解释人工智能进行总结归纳与展望,但文献[31~33]均并没有专注于强化学习可解释方法。本文则从基于强化学习框架的解释、基于环境交互的解释、基于视觉解释三方面系统分类强化学习可解释方法。该分类方法主要特点为从强化学习方法范围递增进行描述,首先对强化学习框架内部进行的可解释开发进行描述、其次对智能体与环境交互层面的可解释开发进行描述、最后专注于最外部的视觉解释描述,层层递进,系统阐述强化学习可解释方法。
1 强化学习与可解释的定义
1.1 强化学习的定义
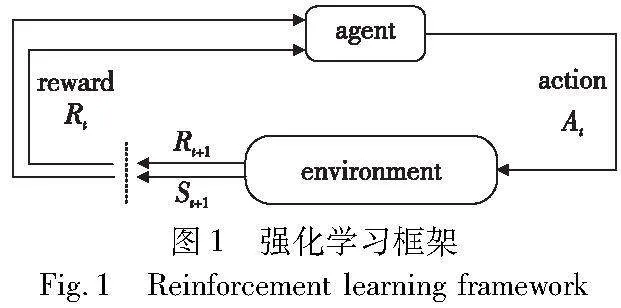
强化学习中作出决策的一方称为智能体(agent),智能体每作出一个动作,环境给予相应反馈,智能体在评估反馈后决定下一个动作。在强化学习中,回报是智能体作出动作的基础,其目标是得到尽可能多的奖励。在强化学习中主要关注状态(state)、动作(action)、奖励(reward)三个指标,其结构框架[34]如图1所示。state代表智能体在所处环境下的状态,对于不同状态,智能体会生成不同的响应动作集合。reward则是一个实数,每当智能体采取动作之后会得到相应奖励,若reward为正数,则代表智能体的行为是受到鼓励的,反之则代表不希望此行为发生,以此进行迭代,使智能体的行为朝着拥有更高奖励的方向逐步调整,最终智能体总体回报达到最优。
根据强化学习算法是否训练环境动态模型,可将强化学习模型分为基于无模型(model-free)的框架和基于模型(model-based)的框架两大类。从模型的表示形式方面,model-free进一步被分为基于值函数、基于策略函数、基于值-策略函数三种模型。在基于策略函数的强化学习模型中,主要注意点在于策略函数的最优化选择。模型主要通过策略函数表示智能体决策过程,首先初始化策略函数,输入t时刻智能体状态St与策略函数π后,执行相应action。在训练过程中,以最大化奖励函数为目的对模型部分参数调整,直到获得奖励相对最优的策略函数。在基于值函数的强化学习模型中,通过值函数对模型进行评估,该类算法主要通过值函数Q去衡量动作空间A下每一个动作所获得的reward,最终选择Q函数数值最大的相应动作。基于策略-值函数的强化学习模型同时学习值函数和策略函数,以逼近最优模型。
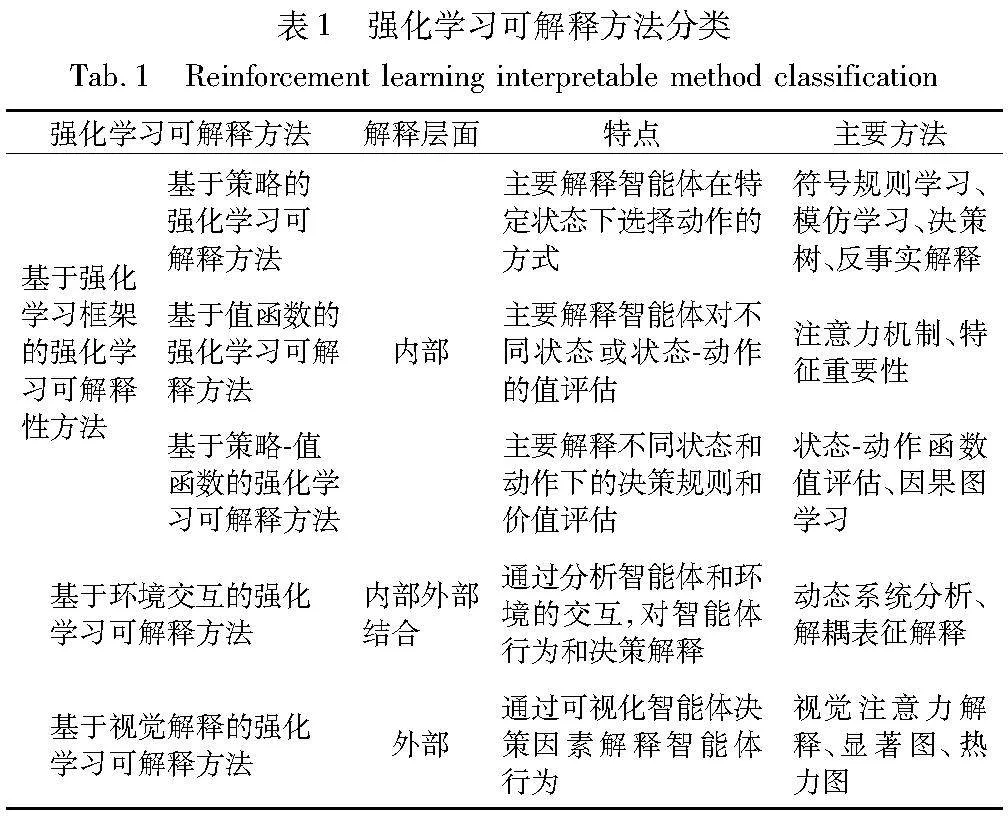
基于model-based的强化学习算法涉及到复杂的决策和状态空间,模型内部的运作往往难以理解,需要花费大量的时间和精力来设计和实现可解释性的算法,造成基于model-based的强化学习可解释性开发难度高的问题。此外现有研究[35]表明,基于model-free的强化学习算法可解释开发的可行性高,且目前已有多种可解释方法。故本文在基于强化学习框架开展相关研究时,主要从基于值函数、基于策略函数、基于值-策略函数三种强化学习算法的可解释性开发进行总结叙述,即从强化学习内部结构方面进行可解释性开发,此外,许多方法也基于强化学习框架无关方面进行可解释性开发,即环境交互、视觉解释方法,故本文同时对基于环境交互、视觉解释的可解释性开发方法进行总结,如表1所示。
1.2 可解释的定义
关于模型的可解释性开发的方法多种多样[35],这表明可解释性并非单一概念。Miller的非数学定义中[36],可解释性指人们能够理解决策原因的程度,模型的可解释性越高,人们对某些决策或预测方法的理解程度则越高,可解释方法不仅输出预测值,同时也会输出预测背后的原因,而本文中的解释即人工智能的可解释性,对模型进行可解释性开发,可从度量模型的质量、提高用户对模型的可信度以及接受度等方面入手,也可从解释的影响因素,如环境、任务、智能体策略等方面入手提升模型性能。
解释可分为事前解释和事后解释[5]。事前解释一般指自解释模型,即可被人类直接查看和理解的算法模型,模型自身就可说明决策相关含义、原因等,比较常见的自解释模型包括决策树、回归模型(包括逻辑回归)等。自解释模型属于内在解释,例如线性模型的权值,或者由决策树学习得到的树结构。事后解释通常指由其他软件工具或人工方式生成的解释,旨在描述、说明特定算法模型如何运作或如何得到特定输出结果,对于具有黑箱属性的深度学习算法,通常只能诉诸事后解释。事后解释还可分为局部解释和全局解释[37],局部解释聚焦于理解算法模型的特定输出结果,而全局解释则侧重于对算法模型整体的理解。
1.3 强化学习可解释性
强化学习可解释性是指对于强化学习算法的决策过程和行为结果进行解释的能力。以下是几个常用的强化学习可解释性的性能指标:
a)可解释性度量:这是一个定性指标,用于评估强化学习算法提供的解释能力。可以考虑以下问题:算法是否能够提供决策的解释和原因?算法是否能够解释行为的结果和影响?算法是否能够提供可视化或图形化的解释?
b)透明度:用于衡量算法内部决策过程的可理解程度。例如,算法是否使用可解释的模型或规则来做决策?算法是否提供了决策的解释或决策路径的可追溯性?
c)可信度:是指算法的决策和行为是否能够被用户或利益相关者所接受和信任。算法是否提供了足够的证据和解释来支持其决策和行为结果的可信度?
d)公平性:是指算法是否在决策过程中考虑了不同群体的利益和权益。算法是否提供了公平性的解释,并能够解释其决策对不同群体的影响?
e)解释一致性:用于评估算法的解释是否与其实际决策和行为一致。算法的解释是否能够正确反映其决策的原因和影响?
目前,强化学习可解释性的性能指标还没有统一的标准和度量方法,不同的应用场景和问题可能需要特定的指标和评估方法来评估强化学习的可解释性。因此,选择哪些衡量指标还需要结合具体应用需求和背景去进行考量。
2 基于强化学习框架的可解释性
在研究强化学习可解释性的方法时,学者们提出了多种不同的分类方法,以帮助理解强化学习算法的决策过程和行为结果,可以根据不同的角度和目标对可解释性方法进行划分。在本章中,将介绍一些常见的基于强化学习框架的可解释性方法分类,分类方法如表2所示。
2.1 基于策略的强化学习可解释性
智能体可解释性的核心是策略解释,策略解释主要集中在智能体主体的动作推理和动作序列间的关联性。对强化学习的可解释性相关研究中,以策略解释的方式来表达模型决策中的隐式逻辑,是目前强化学习研究的热点问题。尽管策略并不能解释单一操作,但仍可以帮助提供上下文,说明为何进行特定操作,并更广义地解释为何智能体要执行全部操作。
在可解释性应用的发展历程中,基于策略的强化学习算法在可解释性方面得到了进展与提升。Fukuchi等人[38]提出基于指令的行为解释(instruction-based behavior explanation,IBE)方法,智能体可通过人类专家提供的指令,自主获得对自身行为进行解释的相关表达式,加快智能体策略的学习速度,此外IBE还可使开发智能体以充分的时间粒度对其行为进行解释,并将其扩展到智能体动态改变策略的场景中。Hayes等人[39]使用代码对动作函数和状态空间变量赋予标签,通过马尔可夫决策过程(Markov decision process,MDP)构建控制软件本身的域和策略模型。Amir等人[40]提出一个策略总结概念性框架,由智能状态提取、环境状态表示和策略汇总界面组成,该框架通过策略展示,向用户展示不同条件或场景下的预期结果及行为解释,使用户更好地理解所使用的系统。Lage等人[41]描述了不同的agent策略总结方法,使用反向强化学习和模仿学习方法进行策略模仿,以达到不断学习智能体策略的目的。Bastani等人[42]提出使用决策树代替策略模型解释强化学习算法,以达到策略解释的目的,在该过程中,使用Q-DAGGER (Q-function dataset aggregation)算法进行决策树策略提取,有效解决了决策树过于复杂的问题。同时,有些研究者以新的决策树模型为基础,以增强树的表示能力,实现对行为的克隆。比如Frosst等人[43]提出利用已训练好的神经网络,建立更容易理解的软决策树模式,采用随机梯度下降进行训练,并利用神经网络进行预测,从而使目标含有更丰富的信息。基于输入示例,软决策树通过学习得到的滤波函数以实现决策的分层处理,最后将该类别中特定静态概率分布值作为其输出,与直接训练数据的决策树相比,该方法虽具有更好的泛化性,但性能仍差于用于提供软目标训练的神经网络。Ding等人[44]的研究表明,基于软决策树(soft decision tree,SDT)和基于离散可微决策树(discretized differentiable decision tree,DDT)算法均可获得较好的分类效果,且均为可解释策略,进一步改进基于树的可解释RL的性能和可解释性后,将其引入到决策过程中,使决策过程具备更加丰富的表达能力的级联决策树(cascading decision tree,CDT)概念开始出现。
传统的可解释技术通常依赖于特征和结果变量两者间的相关性,得出一些与事实相反甚至病态的解释,且不能对“若更改模型的某个干预,则接下来模型所采取的决策或判断会是什么?”这样的反事实问题进行回答,而对该类反事实解释问题的研究主要集中在图像数据和表格数据[45~48]。强化学习也被应用于反事实解释相关研究中,如Numeroso等人[49]使用MEG(molecular explanation generator)框架进行反事实解释,为使其充分对模型进行解释,需满足生成的反事实实例与原始实例在预测模型中的输出值的差值达到最大的条件,同时保持原始实例和反事实实例之间的相似性。因果关系通常是多场景稳定的,且与相关关系相比,其受到的干扰较小。因此,以因果关系为依据的决策更加稳定,这是希望强化学习可解释性开发能够学习到的关系类型。因果模型的决策系统(或智能体)具有可解释性、高样本效率和输入分布变化健壮性等特点,为决策系统(或智能体)带来诸多好处。Madumal等人[3]使用因果模型推导因果解释行为的强化学习智能体主体,提出在强化学习训练过程中学习结构因果模型,并对变量间的因果关系进行编码,该模型随后被用于因果模型的反事实分析,生成对行为的解释。Madumal等人[50]介绍并评估了一个针对无模型强化学习体的远端解释模型,该模型可以对“为什么要”和“为什么不”这类问题进行解释。目前在可解释性深度学习方面的工作仅侧重于由输入特征解释单个决策,不适合对系列决策进行解释。为解决这一需求,Topin等人[51]引入抽象策略图,即抽象状态的马尔可夫链,用于对由APG Gen方法生成的策略表示进行解释。诸如S-RL Toolbox[52]允许从嵌入状态空间(通过状态表示学习)进行采样,实现对模型内部状态的可视解释,并将其与相关的输入观察进行配对,以此提高可解释性。目前在可解释性方面的研究通常是对预测模型进行解释,以帮助用户理解和预测模型的输出结果[53],但这些方法却面临着泛化性较差的问题。为解决上述问题,可使agent在新状态下采取与原始状态不同的动作,即反事实行为。Stein[54]对反事实动作与原始实例动作的Q函数数值差进行计算,并使用掩码梯度下降法,使算法生成只包含智能体认为重要的子目标属性的解释,找到决策边界后,使用基于规则的语言将其转换为自然语言解释,最终生成可解释高级行为的反事实解释。Frost等人[55]通过设计反事实轨迹,得到智能体的多样轨迹分布,并通过分析智能体在这些轨迹分布变化下的表现,对强化学习智能体决策行为进行解释。此外,实验过程对下游任务的预测能力进行评估,最终实验结果表明智能体行为策略的可解释性与泛化性均有所提高。
2.2 基于值函数的强化学习可解释性
使用值函数解释智能体行为的目的是解释为什么在特定的状态下,一个行为比另一个行为更受欢迎,即智能体为什么选择动作a1而不是a2,表示为Q(s,a1)>Q(s,a2)。Juozapaitis等人[56]提出了奖励差异解释(reward difference explanations,RDX),定义为向量Δ(s,a1,a2)=Δ(s,a1)-Δ(s,a2)的分解向量Δc(s,a1,a2)之间的差异,RDX的每个组成Δc(s,a1,a2)是智能体动作偏好的正向或反向原因,这表明了a1在奖励类型c方面是否比a2有优势。而当存在多种奖励类型时,解释智能体行为就更为困难,所以需要去确定一小部分重要原因,引入了最小充分解释(minimal sufficient explanations,MSX),对偏好解释进行排序并选择能够解释重要部分的内容。在CV领域有基于像素扰动[57]的可解释性方法,即Greydanus等人[9]利用显著图的方法进行解释,而显著部分的选取主要通过Q函数的数值大小进行判断,在该模型的基础上,扰动It的像素(It表示在t时刻的图像),若对分类结果影响越大,则该像素点越重要。当对图像的像素点的重要性全都计算后,相应地可对图片分类结果进行解释。在强化学习中,关注像素变化对策略输出的影响,更多的则是关注动作产生的相对回报是否随扰动而变化,用Q(s,a)表示,公式如式(1)所示,该方法可用于对Atari游戏中智能体的行为进行解释。
在强化学习算法中,通常通过Q函数去估计状态-动作对的预期奖励,但仅使用Q函数会使模型忽略对许多知识的解释,故Liu等人[58]开发了Q函数的模拟学习框架,在该框架中,引入线性U-Tree模型(linear model U-Tree,LMUT)近似表示预测过程,并通过存储在LMUT树结构中的知识计算特征的影响、分析提取的规则、突出超像素,达到解释模型决策的目的。Mott等人[6]引入注意力机制提供强化学习可解释性,在提高可解释性的同时提高模型效果,其优势在于注意力机制可挖掘出不同空间位置物体之间的关系,且长短时记忆网络(LSTM)可提供时间序列信息,根据历史信息提取出当前决策相关因素。Hüyük等人[59]提出一个可解释策略学习模型(INTERPOLE),其主要计算决策动态和决策边界,并用期望最大化算法(expectation maximization,EM)训练模型。
2.3 基于策略-值函数的强化学习可解释性
基于策略-值函数的强化学习可解释性开发的主要研究目标是在环境观测(图像)中,对智能体决策(actor输出)和值函数建模(critic输出)的关键成分进行查找,进而为智能体动作提供可解释性。文献[9]使用的显著性方法(式(2)),虽聚合了所有动作的变化,但并未关注具体动作效果。文献[60]提出的显著性计算在某种程度上则更聚焦于动作空间(式(2)),但却忽略了对Q函数的影响是自身还是所有动作空间所造成。Gupta等人[61]则认为在Breakout游戏中需关注策略和状态价值函数的变化,故提出式(1)(2)的组合方案。
如图2[61]所示,在象棋实例中文献[9,60]使用作用值函数Q(s,a)和状态值函数V(s)的差异或策略向量的L2范数来计算显著性映射,生成的显著性地图可体现与智能体所采取的移动无关部分,相比之下,SARFA生成的显著性图突出的是与移动相关的部分。对图2分析可知,诸如白皇后这样的棋子对胜负的影响均是显著的。
在利用RL学习因果图过程[62]中,获取最终的DAG过程每添加一条边,需检查得到的图是否为有向无环图,并使用得分函数和惩罚项去设计reward函数,其中第一项是得分函数,可衡量给定有向图和观测数据的匹配度,第二和第三项作为惩罚项,通过选择合适的惩罚权重,最大化reward等价于之前打分法[63]的形式,不断更新DAG。而actor-critic强化学习算法则被用于优化目标。由于惩罚项系数的缘故,RL算法最终得到的为无环图。强化学习图神经网络本身解释性弱,但可以通过设计解释器,确定出最有影响力的子图对实例预测过程进行解释,从而增强可解释性,GNNExplainer[64]和PGExplainer[65]尝试用连续放缩方法搜索最优子图,SubgraphX[66]和Causal Screening[67]设计搜索条件,使用基于启发式的搜索方法解决优化问题,但上述提到的方法存在子图不能可视化信息传递路径、搜索标准通用性差的缺点。为解决上述问题,Shan等人[68]受到经典组合优化求解器的启发,使用强化学习去解释GNN的预测,提出RG-Explainer框架,生成解释性更强的子图去解释实例的预测过程。除此之外,Fukuchi等人[38]提出基于分层强化学习,使用A2C优化策略法,即通过k个技能获取阶段来学习最终的层次策略。在两阶段的学习中,将每个阶段分为基础技能习得阶段和新技能习得阶段。在每个阶段中,所有策略均使用有利的A2C进行训练。
3 基于环境交互的强化学习可解释性
环境可解释性是指可对环境转移态势的内部机理进行解释。在强化学习中,环境充满一定的黑盒性。环境可解释性的构建,有利于理解环境态势变化对智能体决策的影响,可更准确地建立模型和环境态势数据的关联性,实现有效的智能体建模。另外,在具备可解释的环境中,人类更容易判断智能体模型是否能学习到真实规律,也可采取相关措施提升模型的泛化能力,避免因环境的细微变化导致智能体决策出现的较大偏差。
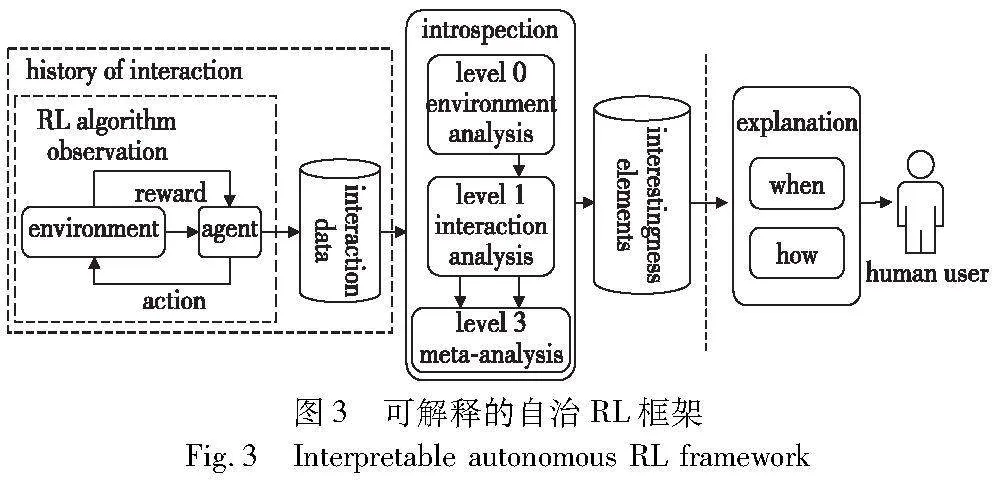
逆向强化学习算法则是为有效规避行为克隆单一地模仿专家行为,而不去推理行为产生的原因,其核心是寻找环境规律,利用对模型的强化学习过程进行逆向计算,进而对环境中的知识进行拟合。在XRL中,有些工作借鉴了逆强化学习的思想。Sequeira等人[69]提出一个强化学习可解释框架,其结构如图3[70]所示,该框架对智能体与环境交互过程进行分析(交互过程中,智能体负责统计相关信息,根据收集到的数据元素,对元素进行筛选,得到有解释作用的元素,以视觉形式展示给用户),以提取有助于解释智能体行为的元素。为利用环境对算法进行可解释性开发,渊亭科技提出DataExa-Nash[70]方法,即面向决策智能应用场景的强化学习可解释性方法。DataExa-Nash集成多种可解释性算法(模仿学习类型、注意力类型、基于分析统计类型),因此可利用其本身具有的可解释性算法解释智能体行为、对环境中全局态势和单个观测态势解释,也可通过观察态势、行为及奖励对结果的影响,对决策作出可解释性分析。Van Der Waa等人[71]提出一种可以解释智能体对动作偏好的方法,其主要思想是学习一种特殊的动作价值网络,通过嵌入式自我预测模型并对比每个动作的未来属性,预测解释对应的动作偏好。
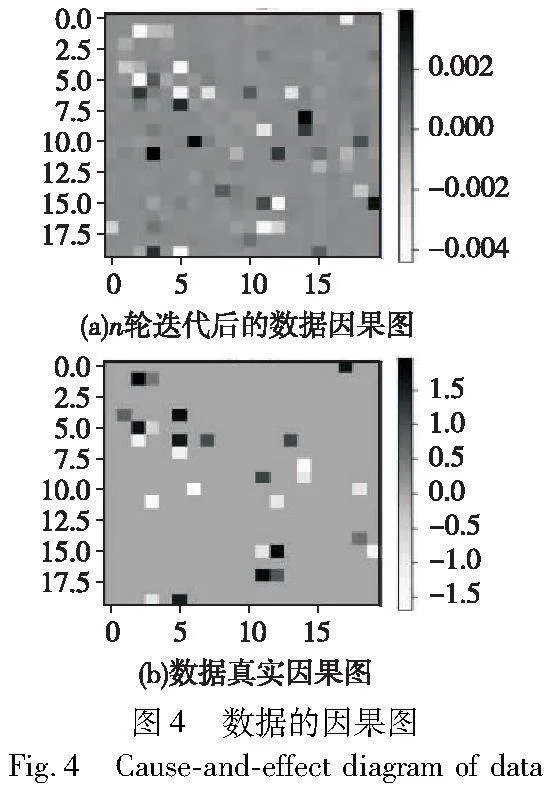
此外,通过学习解耦的潜在表征,捕获语义上有意义的特征,同样可提高可解释性[72],解耦[73]就是将原始数据空间中纠缠着的数据变化,变换到一个好的表征空间中,在这个空间中,不同要素的变化是可以彼此分离的,并且多基于变分自编码模型(variational auto-encoders,VAE)[74]学习。故解耦表征可解析环境特征,加快强化学习在多种操作任务上的学习速度,并提高其泛化能力,通过生成可解释的潜在策略,并使潜在目标直接与环境的可控特征保持一致,从而达到更好的效果。Caselles-Dupré等人[75]近期提出的基于对称性的解耦表示学习算法可以得到泛化性更强的特征表示,即对初始环境以及将初始环境进行对称性转换后的新环境进行交互后计算得到最终特征表示。目前的方法笼统地认为统计相关性即因果关系,该观点在实际应用过程中可能导致模型出现错误决策[76]。Yang等人[77]认为图像解耦后的潜在变量在生成原图像的过程中存在因果关系,提出基于VAE的框架CasualVAE,该模型中包含一个因果层,可挖掘数据间的因果关系,进而形成因果矩阵,最终形成因果图,使环境中数据元素的因果关系达到语义上的可解释性,如文献[62]根据样本数据进行迭代生成数据因果图,如图4所示。图4(a)为样本数据经过n轮迭代得到的数据因果图,图4(b)为真实数据因果图,通过不断迭代,生成的样本数据因果图逐渐接近真实数据因果图,能更好地挖掘出数据间的潜在关系以及本质关系,展现出良好的因果解释效果。当前解释方法多为将属性分数分配给输入图像中的像素区域,表明图片特定区域对模型决策的重要性,为了获得含有更多因果关系的显著图,Klein等人[78]提出学习解耦的潜在特征去捕捉环境中语义意义上的有用特征的框架,其可以可视化解耦地表示,进而使专家能够利用自己的知识研究决策因果关系,该框架同时可用于下游任务预测。
4 基于视觉解释的强化学习可解释性
使模型可解释的一种方法就是视觉注意力解释[15],以图片为输入的任务中,通过观察任务中的侧重部分,使用显著图法或注意力机制[79]的掩码机制,得到掩码后与原图片叠加实现相关区域的高亮,进而实现视觉解释。在大多数情况下,显著图或热力图应用于图像领域,可突出显示智能体显著区域。显著图的一个突出优势是其可生成易于人类(甚至是非专家)理解的元素。当然,显著图的解释难度很大程度上取决于用于计算该图的显著性方法及其他参数,如配色方案或突出显示技术,其缺点是对不同的输入变化非常敏感,并且此类可视化解释方案不可直接进行调试。Annasamy等人[80]提出用于Q学习的可解释神经网络架构,利用键值存储器、注意力和可重构嵌入,进而为模型的行为提供全面解释。显著图通过突出显示智能体行为的强相关状态特性,重点关注智能体如何学习和执行策略,以达到解释智能体行为的目的。
现有基于扰动的显著性方法[81]虽突出显示了输入的区域,但这些区域与智能体所采取的动作并无实际关联。Kim等人[81]提出的注意力瓶颈架构将视觉注意力与信息瓶颈融合[82],使视觉注意力可以识别模型正在使用输入的内容,信息瓶颈则可以使模型只关注输入过程中的重要部分。这不仅可提供稀疏和可解释的注意力图(例如只关注场景中的特定车辆),而且可在不显著影响模型精度的情况下增加其透明性。Greydanus等人[9]引入新的基于扰动的显著性计算方法,可使在OpenAI Gym环境下,Atari 2600游戏的RL智能体生成清晰且易于解释的显著图,其主要思想是对所考虑的图像进行扰动,在不添加新信息的情况下去除特定像素上的信息(通过对同一图像的高斯模糊生成插值),该方法对强化学习智能体的解释集中于生成显著图,并输入扰动函数,通过观察策略变化幅度去解释智能体行为,这种方式可以解释一些参与智能体决策的区域,但它不能解释某些类型的行为,比如解释框架中组成成分缺失智能体作出的决策。Mott等人[6]引入注意力机制,使用空间注意力去挖掘在图像状态空间中对当前决策重要的因素,通过挖掘不同空间位置物体之间的相互关系,同时对得到的注意力权重在图像中进行可视化,发现智能体的关注区域,以此解释智能体策略。该方法产生的注意力图中,智能体更关注智能体遵循的路径以及未来可能的长期路径,而Greydanus等人的方法更注重策略的显著性,与该方法相比,注意力图可以告知智能体其策略的信息而进行更全面的分析。Gupta等人[61]提出的SARFA(specific and relevant feature attribution)方法,通过平衡特异性和相关性两个方面以捕获不同的显著性需求,从而生成更有针对性的显著性图。第一种是扰动要解释的智能体行为,观察扰动对智能体动作的影响,第二种则是降低一些与行为弱相关特征的影响程度。基于显著图和注意力图的特性,Shi等人[83]同时使用显著图和注意力图解决两个解释性要素:智能体创建策略时的重点关注区域(显著图)和智能体在时间步上对过去重点关注区域的移动(注意力图)。不论是显著图还是注意力图的生成,都是掩码生成后与原图片的重叠效果,而如何衡量各个算法生成的视觉释效果亟待解决。在该实验中,评价掩码质量的定量指标为特征重叠率(feature overlapping rate,FOR)与背景消除率(background elimination rate,BER)。FOR即真实掩码与学习到的掩码区域之间的重叠率,BER即掩码消除的背景区域和整个背景区域的比率。对于特定的状态s,掩码度量FOR(s)和BER(s)的计算如式(3)所示。
其中:∩是相交运算符;Se,f、St,f、St,b分别是提取到的特征区域、真实的特征区域、真实的背景区域。FOR表示agent从状态中提取有用的信息,BER表示掩码如何在状态中消除与任务无关的信息。FOR和BER度量从像素分类角度等效于真阳性率(TPR)和真阴性率(TNR),而使用FOR和BER度量评估RL领域中生成掩码的质量,其含义更直观且非专家也可以理解。
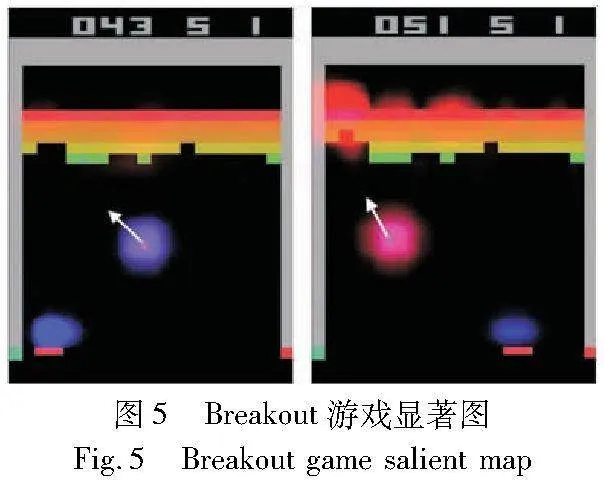
基于显著图的视觉解释实例如图5所示,已学习好的智能体,可视化展示智能体具体根据输入状态中的哪些特征作出相应决定,即能够对智能体采取某个行动的原因进行解释,图5中蓝色荧光对影响智能体当前决策的一些重要特征(对于图片而言就是像素点)进行标记(参见电子版)。观察图5的Breakout游戏[9],高亮区域代表影响智能体当前决策的一些重要因素,即小球的位置和左上角的一些残缺砖块位置,通过区域热力图并结合游戏知识,用户可判断出,小球在运动时需关注底部板,完成弹射,且倾向于上方较空缺位置,方便不断与顶部板碰撞,达到解释智能体行为的目的。
现有基于显著图的可解释RL方法包括Jacobian显著图和基于扰动的显著图,然而,显著性方法并不适用于所有场景,均局限于视觉输入问题,如文献[84]所指出的,显著图要遵守一定数量的规则,例如实现不变性、输入不变性以及可靠性。Wang等人[85]提出适用于视觉输入和数字输入的基于属性的显著性方法,该方法对关于每个输入状态所贡献的策略进行解释,其主要目标是了解RL智能体在决策时所关注的信息。Pan等人[86]提出可预测未来视觉输入特征表示的驾驶策略学习框架,该模型不仅可推断未来事件,还可推断语义,这为政策决策提供了可视化解释。除此之外,也可以通过反事实方法形成显著图,从而进行模型决策的可视化解释。Atrey等人[87]提出以反事实推断为基础,测试从显著图中产生的假设,并对其与RL环境在语义上的一致性进行评估,但由于显著图预测覆盖了每一个可能的原因,所以需对输入的差异部分着重强调。视觉输入环境中的反事实工作依赖于其他技术,如Chang等人[22]提出FIDO算法,该算法需确定出在生成模型输出值过程中,哪些区域会最大程度地改变图像的预测类别,从而为图像生成反事实,使用现有生成模型进行填充生成显著图。Goyal等人[88]对图像进行反事实的视觉解释,找出原始图像I(c)和干扰图像I′(c′)之间的最小区域交换数,去创建反事实的解释,但这类区域互换的方式可能会生成奇怪的反事实显著图,造成解释不够明确的问题。对此,可以利用反事实解释智能体决策,Olson等人[89]引入了产生反事实状态解释的解释生成模型,首先生成反事实状态s′,利用原始状态s与反事实状态s′的绝对差值,生成反事实mask并与原始状态s结合生成显著图,去获取深层RL智能体的决策。
5 结束语
5.1 强化学习可解释现状与展望
通过对上述方法的归纳,不难发现目前强化学习可解释方法在各个方面都有了一定的进展,但由于强化学习可解释方法通常关注局部解释,且解释方法多为语言解释、视觉解释、模型解释混合使用去解释局部算法,但仍未达到直观的解释效果,需要借助开发者提升可解释性,故强化学习方法的透明度仍较差。此外,这些解释方法可以使用户或者操作人员在强化学习算法应用于实际问题时,充分理解算法过程以便在程序异常时作出实际且关键的决策。另一方面,在众多解释方法中,虽然都在一定程度上说明了可解释程度与范围,但是如何评估各个方法之间的优劣,尚无定论,目前主要依赖透明度、可解释范围等定性指标进行评估,但这些指标并不能明确表示可解释方法之间的性能差异,也无法证明解释方法在实际问题应用中的有效性,更需要像累计回报(cumulative reward,CR)、最大回报(maximum reward,MR)等强化学习定量指标去衡量算法优劣。
目前国内外可解释强化学习方法亟待完善,该部分主要针对强化学习可解释开发的挑战讨论一些可能的改进方法。首先,从启发式解释方面出发,引入解释学习的方法,例如用户通过问答系统、对话代理等方式,提出问题、请求解释,使用户能够通过与算法进行互动和对话来学习算法的决策过程,以加强用户对强化学习内部结构的理解。此外,现有的对智能体行为的解释大多只解释智能体间行为的表象原因,即对现有结果的原因分析,但Yau等人[90]发现,如果解释强化学习智能体所隐含的预期结果,会得到更好的解释效果,且具有在多个强化学习问题上的有效性。
从完善评估解释方法的指标方面,可以通过衡量解释内容的完整性,包括涵盖的决策因素、关键特征、算法内部状态等方面,通过计算解释中所包含的信息比例或涵盖的关键特征数量评估解释方法性能。同理,解释方法的可靠性与一致性意味着指标的结果应是准确稳定和可重复的,不受随机性和偶然因素的影响,量化解释方法的可靠性与一致性可以通过重复实验、交叉验证等方法确定解释结果的准确性。除此之外,若期望可解释方法的评估指标逐渐统一,在建立算法实验时,应自觉根据基线及理论知识建立算法评估标准,尽可能使用与基线方法较为一致的评估指标,在解释方法评估指标的完善与统一中逐渐完善评估标准。
5.2 总结与讨论
前期基于决策树和软决策等对强化学习的可解释进行开发及解释。在深度学习风靡前期,决策树作为准确性和可解释性的标杆,不仅可给出输入数据x的预测结果,还能一同输出预测过程的中间决策部分。而在图像分类数据集上,决策树的准确率要比神经网络落后40%左右。因此亟需一个精确率高、可解释性强的模型。但传统的可解释技术更多的依赖于特征和结果变量之间的相关性,造成从强化学习自身出发进行可解释性开发,即在因果模型的反事实分析基础上,因果结构模型被用于生成行为的解释。除了从模型本身开发去提高算法的可解释性外,也可从外部环境入手,通过逆强化学习等方法,发现环境规律或者使用解耦表示解析环境特征数据,发现环境相关性。无论哪种可解释方法,拥有可视化效果可使算法解释性更显著,通常使用扰动显著图或注意力机制掩码实现可视化,可展示给“观众”达到可解释效果。
由于大多数XAI方法均是为有监督学习量身定制的,所以想要对仅应用于RL算法的方法进行概述,必须首要解决一些关键问题。自解释模型的可解释性发展因RL模型的复杂性而受到诸多限制,而事后可解释模型较内在可解释模型要更容易实现,在发展事后可解释方法时,致力于追求模型无关的方法,以达到高泛化性目的,但由于其可与标准RL方法结合使用,故不必修改学习机制本身。当可解释性与模型底层分离时,可解释的发展才能更加开放,因此当前学者研究的重点在于与模型无关的可解释性方法。与模型无关的可解释性方法具有自身底层模块化的模型可与解释方法易分割的优点,这种可解释方法的独立性使其能够与不同类型的模型相结合,并适应不同领域和应用的需求,从而更便于进行扩展。
此外,在发展模型的可解释性时,重点应该在于分析模型而非分析数据。可解释挖掘关注的并非数据本身,而是数据中蕴涵的知识,故原始数据本身的作用并不大,模型的可解释就是一种从数据中提取知识的好方法。在未来发展中,人工智能模型可能具备自主决策的能力,或与人类用户合作进行决策,因此对模型决策的解释及证明变得至关重要。为实现这一目标,需要将重点放在跨学科工作上,例如将人工智能、机器学习、心理学和人机交互等领域相结合,开发出以人为中心的模型,实现高效人机交互合作。
参考文献:
[1]赵廷玉,赵晓永,王磊,等. 可解释人工智能研究综述 [J]. 计算机工程与应用,2023,59(14): 1-14. (Zhao Tingyu,Zhao Xiaoyong,Wang Lei,et al. A review of explainable artificial intelligence research [J]. Computer Engineering and Applications,2023,59(14): 1-14.)
[2]Buolamwini J,Gebru T. Gender shades: intersectional accuracy disparities in commercial gender classification [C]// Proc of Conference on Fairness,Accountability and Transparency. 2018: 77-91.
[3]Madumal P,Miller T,Sonenberg L,et al. Explainable reinforcement learning through a causal lens [C]// Proc of AAAI Conference on Artificial Intelligence. 2020: 2493-2500.
[4]Molnar C. 可解释机器学习: 黑盒模型可解释性理解指南 [M]. 朱明超,译. 北京:电子工业出版社,2021. (Molnar C. Interpretable machine learning: a guide to understanding the interpretability of black box models [M]. Zhu Mingchao,Trans. Beijing:Electronic Industry Press,2021.)
[5]Glanois C,Weng P,Zimmer M,et al. A survey on interpretable reinforcement learning [EB/OL].(2021).https://arxiv.org/abs/2112.13112.pdf.
[6]Mott A,Zoran D,Chrzanowski M,et al. Towards interpretable reinforcement learning using attention augmented agents [C]//Advances in Neural Information Processing Systems. 2019.
[7]Bhattacharya M,Jain S,Prasanna P. Radio transformer: a cascaded global-focal transformer for visual attention-guided disease classification [C]// Proc of European Conference on Computer Vision. Cham: Springer,2022: 679-698.
[8]Fanda L,Cid Y D,Matusz P J,et al. To pay or not to pay attention: classifying and interpreting visual selective attention frequency features [C]// Proc of the 3rd International Workshop on Explainable and Transparent AI and Multi-Agent Systems. Cham:Springer,2021: 3-17.
[9]Greydanus S,Koul A,Dodge J,et al. Visualizing and understanding Atari agents [C]//Proc of International Conference on Machine Learning. 2018: 1792-1801.
[10]Zahavy T,Ben-Zrihem N,Mannor S. Graying the black box: understanding DQNs [C]//Proc of International Conference on Machine Learning. 2016: 1899-1908.
[11]Peng Yitao,Yang Longzhen,Liu Yihang,et al. MDM: visual explanations for neural networks via multiple dynamic mask [EB/OL]. (2022-07-17). https://arxiv.org/abs/2207.08046.pdf.
[12]Srinivas S,Fleuret F. Full-gradient representation for neural network visualization [C]// Advances in Neural Information Processing Systems. 2019.
[13]张一飞,孟春运,蒋洲,等. 可解释的视觉问答研究进展 [J]. 计算机应用研究,2024,41(1):10-20. (Zhang Yifei,Meng Chunyun,Jiang Zhou,et al. Research progress on interpretable visual question answering [J]. Application Research of Computers,2024,41(1):10-20.)
[14]Zhu Yuanyang,Xiao Yin,Li Ruyu,et al. Extracting decision tree from trained deep reinforcement learning in traffic signal control [C]// Proc of International Conference on Cyber-Physical Social Intelligence. 2021: 1-7.
[15]Park D H,Hendricks L A,Akata Z,et al. Multimodal explanations: justifying decisions and pointing to the evidence [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 8779-8788.
[16]邹芸竹,杜圣东,滕飞,等. 一种基于多模态深度特征融合的视觉问答模型 [J]. 计算机科学,2023,50(2): 123-129. (Zou Yunzhu,Du Shengdong,Teng Fei,et al. A visual Q&A model based on multimodal deep feature fusion [J]. Computer Science,2023,50(2): 123-129.)
[17]Ribeiro M T,Singh S,Guestrin C. “Why should I trust you?”Explaining the predictions of any classifier [C]// Proc of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York:ACM Press,2016: 1135-1144.
[18]Grgic-Hlaca N,Redmiles E M,Gummadi K P,et al. Human perceptions of fairness in algorithmic decision making: a case study of criminal risk prediction [C]// Proc of World Wide Web Conference. 2018: 903-912.
[19]Wachter S,Mittelstadt B,Russell C. Counterfactual explanations without opening the black box: automated decisions and the GDPR [J]. Harvard Journal of Law & Technology,2017,31: 841-887.
[20]Karimi A H,Barthe G,Balle B,et al. Model-agnostic counterfactual explanations for consequential decisions [C]//Proc of International Conference on Artificial Intelligence and Statistics. 2020: 895-905.
[21]朱霄,邵心玥,张岩,等. 面向数据库配置优化的反事实解释方法 [J/OL]. 软件学报. (2023-10-19) [2023-11-16]. https://doi.org/10.13328/j.cnki.jo s.006977. (Zhu Xiao,Shao Xinyue,Zhang Yan,et al. Counterfactual explanation method for database configuration optimization [J/OL]. Journal of Software. (2023-10-19) [2023-11-16]. https://doi.org/10.13328/j.cn ki.jos.006977.)
[22]Chang C K,Creager E,Goldenberg A,et al. Explaining image classifiers by counterfactual generation [EB/OL]. (2018).https://arxiv. org/abs/1807. 08024. pdf.
[23]Karimi A H,Schlkopf B,Valera I. Algorithmic recourse: from counterfactual explanations to interventions [C]// Proc of ACM Confe-rence on Fairness,Accountability and Transparency. New York: ACM Press,2021: 353-362.
[24]Moraffah R,Karami M,Guo R,et al. Causal interpretability for machine learning-problems,methods and evaluation [J]. ACM SIGKDD Explorations Newsletter,2020,22(1): 18-33.
[25]Puiutta E,Veith E M S P. Explainable reinforcement learning: a survey [C]//Proc of International Cross Domain Conference for Machine Learning and Knowledge Extraction. Cham: Springer,2020: 77-95.
[26]Wells L,Bednarz T. Explainable AI and reinforcement learning—a systematic review of current approaches and trends [J]. Frontiers in Artificial Intelligence,2021,2021(4): article ID 550030.
[27]Heuillet A,Couthouis F,Díaz-Rodríguez N. Explainability in deep reinforcement learning [J]. Knowledge-Based Systems,2021,2021(214): article ID 106685.
[28]Qing Yunpeng,Liu Shunyu,Song Jie,et al. A survey on explainable reinforcement learning: concepts,algorithms,challenges [EB/OL]. (2022).https://arxiv.org/abs/2211.06665.pdf.
[29]刘潇,刘书洋,庄韫恺,等. 强化学习可解释性基础问题探索和方法综述 [J]. 软件学报,2023,34(5): 2300-2316. (Liu Xiao,Liu Shuyang,Zhuang Yunkai,et al. Exploration and methodological survey of fundamental issues of interpretability of reinforcement learning [J]. Journal of Software,2023,34(5): 2300-2316.)
[30]Milani S,Topin N,Veloso M,et al. Explainable reinforcement lear-ning: a survey and comparative review [J]. ACM Computing Surveys,2024,56(7): article No.168.
[31]Guidotti R,Monreale A,Ruggieri S,et al. A survey of methods for explaining black box models [J]. ACM Computing Surveys,2018,51(5): 1-42.
[32]Adadi A,Berrada M. Peeking inside the black-box: a survey on explainable artificial intelligence (XAI) [J]. IEEE Access,2018,6: 52138-52160.
[33]Arrieta A B,Díaz-Rodríguez N,Ser J D,et al. Explainable artificial intelligence (XAI): concepts,taxonomies,opportunities and challenges toward responsible AI [J]. Information Fusion,2020,58: 82-115.
[34]Sun Yuewen,Zhang Kun,Sun Changyin. Model-based transfer reinforcement learning based on graphical model representations [J]. IEEE Trans on Neural Networks and Learning Systems,2021,34(2): 1035-1048.
[35]Miller T. Explanation in artificial intelligence: insights from the social sciences [J]. Artificial Intelligence,2019,267: 1-38.
[36]Holzinger A,Langs G,Denk H,et al. Causability and explainability of artificial intelligence in medicine [J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery,2019,9(4): e1312.
[37]Mcdermid J A,Jia Yan,Porter Z,et al. Artificial intelligence explaina-bility: the technical and ethical dimensions [J]. Philosophical Trans of the Royal Society A,2021,379(2207): article ID 20200363.
[38]Fukuchi Y,Osawa M,Yamakawa H,et al. Autonomous self-explanation of behavior for interactive reinforcement learning agents [C]// Proc of the 5th International Conference on Human Agent Interaction.New York: ACM Press,2017: 97-101.
[39]Hayes B,Shah J A. Improving robot controller transparency through autonomous policy explanation [C]// Proc of ACM/IEEE International Conference on Human-Robot Interaction. 2017: 303-312.
[40]Amir O,Doshi-Velez F,Sarne D. Summarizing agent strategies [J]. Autonomous Agents and Multi-Agent Systems,2019,33: 628-644.
[41]Lage I,Lifschitz D,Doshi-Velez F,et al. Toward robust policy summarization [J]. Autonomous Agents and Multi-Agent Systems,2019,2019: 2081-2083.
[42]Bastani O,Pu Yewen,Solar-Lezama A.Verifiable reinforcement lear-ning via policy extraction [C]// Advances in Neural Information Processing Systems. 2018.
[43]Frosst N,Hinton G E. Distilling a neural network into a soft decision tree [EB/OL]. (2017).https://arxiv. org/abs/1711. 09784. pdf.
[44]Ding Zihan,Hernandez-Leal P,Ding G W,et al. CDT: cascading decision trees for explainable reinforcement learning [EB/OL].(2020). https://arxiv. org/abs/1711. 09784. pdf.
[45]Vermeire T,Brughmans D,Goethals S,et al. Explainable image classification with evidence counterfactual [J]. Pattern Analysis and Applications,2022,25(2): 315-335.
[46]Mothilal R K,Sharma A,Tan Chenhao. Explaining machine learning classifiers through diverse counterfactual explanations [C]// Proc of Conference on Fairness,Accountability and Transparency. 2020: 607-617.
[47]Dhurandhar A,Chen Pinyu,Luss R,et al. Explanations based on the missing: towards contrastive explanations with pertinent negatives [J]. Advances in Neural Information Processing Systems,2018,31: 592-603.
[48]Cheng Furui,Ming Yao,Qu Huamin. DECE: decision explorer with counterfactual explanations for machine learning models [J]. IEEE Trans on Visualization and Computer Graphics,2020,27(2): 1438-1447.
[49]Numeroso D,Bacciu D. Explaining deep graph networks with molecular counterfactuals [C]// Advances in Neural Information Processing Systems,Workshop on Machine Learning for Molecules. 2020.
[50]Madumal P,Miller T,Sonenberg L,et al. Distal explanations for explainable reinforcement learning agents [C]// Proc of AAAI Confe-rence on Artificial Intelligence. 2020: 13724-13725.
[51]Topin N,Veloso M. Generation of policy-level explanations for reinforcement learning [C]// Proc of the 33rd AAAI Conference on Artificial Intelligence. 2019: 2514-2521.
[52]Garnelo M,Shanahan M. Reconciling deep learning with symbolic artificial intelligence: representing objects and relations [J]. Current Opinion in Behavioral Sciences,2019,29: 17-23.
[53]Hoffman R R,Mueller S T,Klein G,et al. Metrics for explainable AI: challenges and prospects [EB/OL]. (2018).https://arxiv.org/abs/1812.04608.pdf.
[54]Stein G.Generating high-quality explanations for navigation in partially-revealed environments [J]. Advances in Neural Information Processing Systems,2021,34: 17493-17506.
[55]Frost J,Watkins O,Weiner E,et al. Explaining reinforcement learning policies through counterfactual trajectories [EB/OL].(2022). https://arxiv. org/abs/2201. 12462. pdf.
[56]Juozapaitis Z,Koul A,Fern A,et al. Explainable reinforcement lear-ning via reward decomposition [C]//Proc of IJCAI/ECAI Workshop on Explainable Artificial Intelligence. 2019.
[57]Fong R C,Vedaldi A. Interpretable explanations of black boxes by meaningful perturbation [C]// Proc of IEEE International Conference on Computer Vision. Piscataway,NJ:IEEE Press,2017: 3429-3437.
[58]Liu Guiliang,Schulte O,Zhu Wang,et al. Toward interpretable deep reinforcement learning with linear model U-trees [C]// Proc of European Conference on Machine Learning and Knowledge Discovery in Databases.Berlin: Springer,2019: 414-429.
[59]Hüyük A,Jarrett D,Tekin C,et al. Explaining by imitating: understanding decisions by interpretable policy learning [C]// Proc of International Conference on Learning Representations. 2021.
[60]Iyer R,Li Yuezhang,Li Huao,et al. Transparency and explanation in deep reinforcement learning neural networks [C]//Proc of AAAI/ACM Conference on AI,Ethics,and Society. 2018: 144-150.
[61]Gupta P,Puri N,Verma S,et al. Explain your move: understanding agent actions using specific and relevant feature attribution [C]// Proc of International Conference on Learning Representations. 2020.
[62]Zhu Shengyu,Ng I,Chen Zhitang. Causal discovery with reinforcement learning [EB/OL]. (2019).https://arxiv. org/abs/1906. 04477. pdf.
[63]Peters J,Mooij J,Janzing D,et al. Causal discovery with continuous additive noise models [J]. The Journal of Machine Learning Research,2014,15(1): 2009-2053.
[64]Ying R,Bourgeois D,You Jiaxuan,et al. GNNExplainer: generating explanations for graph neural networks [J]. Advances in Neural Information Processing Systems,2019,32:9244-9255.
[65]Luo Dongsheng,Cheng Wei,Xu Dongkuan,et al. Parameterized explainer for graph neural network [J]. Advances in Neural Information Processing Systems,2020,33: 19620-19631.
[66]Yuan Hao,Yu Haiyang,Wang Jie,et al. On explainability of graph neural networks via subgraph explorations [C]// Proc of International Conference on Machine Learning. 2021: 12241-12252.
[67]Wang Xiang,Wu Yingxin,Zhang An,et al. Causal screening to interpret graph neural networks [EB/OL]. (2021). https://arxiv.org/abs/2112.15089.
[68]Shan Caihua,Shen Yifei,Zhang Yao,et al. Reinforcement learning enhanced explainer for graph neural networks [J]. Advances in Neural Information Processing Systems,2021,34:22523-22533.
[69]Sequeira P,Gervasio M. Interestingness elements for explainable reinforcement learning: understanding agents’ capabilities and limitations [J]. Artificial Intelligence,2019,288: 103367.
[70]构建可信的智能决策体系: 渊亭科技多智能体强化学习可解释性探索 [EB/OL]. (2022-11-01) [2023-11-20]. http://www. 81it. com/2022/1101/13848. html. (Building trusted intelligent decision systems: an explainable exploration of multi-intelligent body reinforcement learning in yuanting technology [EB/OL]. (2022-11-01) [2023-11-20]. http://www. 81it. com/2022/1101/13848. html.)
[71]Van Der Waa J,Van Diggelen J,Van Den Bosch K,et al. Contrastive explanations for reinforcement learning in terms of expected consequences [C]// Proc of IJCAI Explainable Artificial Intelligence Workshop. 2018.
[72]Locatello F,Bauer S,Lucic M,et al. Challenging common assumptions in the unsupervised learning of disentangled representations [C]// Proc of International Conference on Machine Learning. [S.l.]: PMLR,2019: 4114-4124.
[73]Higgins I,Amos D,Pfau D,et al. Towards a definition of disentangled representations [EB/OL]. (2018).https://arxiv. org/abs/1812. 02230. pdf.
[74]Kingma D P,Welling M. Auto-encoding variational Bayes [EB/OL]. (2013).https://arxiv. org/abs/1312. 6114. pdf.
[75]Caselles-Dupré H,Garcia-Ortiz M,Filliat D. Symmetry-based disentangled representation learning requires interaction with environments [C]// Advances in Neural Information Processing Systems. 2019: 4606-4615.
[76]Holzinger A,Müller H. Toward human-AI interfaces to support explainability and causability in medical AI [J]. Computer,2021,54(10): 78-86.
[77]Yang Mengyue,Liu Furui,Chen Zhitang,et al. CausalVAE: disentangled representation learning via neural structural causal models [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. 2021: 9593-9602.
[78]Klein L,Carvalho J B S,El-Assady M,et al. Improving explainability of disentangled representations using multipath-attribution mappings [C]// Proc of Machine Learning Research-Under Review. 2022.
[79]Vaswani A,Shazeer N,Parmar N,et al. Attention is all you need [C] // Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY:Curran Associates Inc.,2017:6000-6010.
[80]Annasamy R M,Sycara K. Towards better interpretability in deep Q-networks [C]// Proc of the 33rd AAAI Conference on Artificial Intelligence.2019: 4561-4569.
[81]Kim J,Bansal M. Towards an interpretable deep driving network by attentional bottleneck [J]. IEEE Robotics and Automation Letters,2021,6(4): 7349-7356.
[82]Goyal A,Islam R,Strouse D,et al. Infobot: transfer and exploration via the information bottleneck [EB/OL].(2019) https://arxiv. org/abs/1901. 10902. pdf.
[83]Shi Wenjie,Huang Gao,Song Shiji,et al. Self-supervised discovering of interpretable features for reinforcement learning [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2020,44(5): 2712-2724.
[84]Adebayo J,Gilmer J,Muelly M,et al. Sanity checks for saliency maps [J]. Advances in Neural Information Processing Systems,2018,31:9525-9536.
[85]Wang Yuyao,Mase M,Egi M. Attribution-based salience method towards interpretable reinforcement learning [C]//Proc of AAAI Spring Symposium Combining Machine Learning with Knowledge Enginee-ring. 2020.
[86]Pan Xinlei,Chen Xiangyu,Cai Qizhi,et al. Semantic predictive control for explainable and efficient policy learning [C]//Proc of International Conference on Robotics and Automation. Piscataway,NJ:IEEE Press,2019: 3203-3209.
[87]Atrey A,Clary K,Jensen D D. Exploratory not explanatory: counterfactual analysis of saliency maps for deep reinforcement learning [C]// Proc of the 8th International Conference on Learning Representations. 2020.
[88]Goyal Y,Wu Ziyan,Ernst J,et al. Counterfactual visual explanations [C]// Proc of International Conference on Machine Learning. 2019: 2376-2384.
[89]Olson M L,Khanna R,Neal L,et al. Counterfactual state explanations for reinforcement learning agents via generative deep learning [J]. Artificial Intelligence,2021,295: article ID 103455.
[90]Yau H,Russell C,Hadfield S. What did you think would happen?Explaining agent behaviour through intended outcomes [J]. Advances in Neural Information Processing Systems,2020,33: 18375-18386.
