
汽车电驱动系统多源异构信号融合分类研究
2024-07-07 04:34奚易
科技创新与应用 2024年18期
关键词:特征提取
奚易

摘 要:多源异构数据融合作为汽车电驱动系统领域中的重要数据处理手段备受瞩目,其在汽车电驱动系统领域中扮演着关键角色,为深入理解系统运行特征和解决复杂问题提供有效手段。该文通过对多源异构信号特点、融合层次分类的剖析,提出一种应用于汽车电驱动系统的多源异构数据融合方法,并利用采集到的电驱动多源异构数据对融合算法进行验证,结果表明,融合分析能够有效地区分汽车电驱动系统质量。
关键词:电驱动系统;多源异构数据;特征提取;多源融合;加权融合
中图分类号:TP393 文献标志码:A 文章编号:2095-2945(2024)18-0020-04
Abstract: Multi source heterogeneous data fusion, as an important data processing method in the field of automotive electric drive systems, has attracted much attention. It plays a key role in the field of automotive electric drive systems, providing an effective means for a deeper understanding of system operation characteristics and solving complex problems. This paper proposes a multi-source heterogeneous data fusion method applied to automotive electric drive systems by analyzing the characteristics of multi-source heterogeneous signals and the classification of fusion levels. The fusion algorithm is validated using the collected multi-source heterogeneous data of electric drive systems, and the results show that fusion analysis can effectively distinguish the quality of automotive electric drive systems.
Keywords: electric drive system; multi-source heterogeneous data; feature extraction; multi-source fusion; weighted fusion
汽车电驱动系统是一种使用电能来推动车辆的系统,主要由电动机、电池和电控系统组成。在其工作过程中[1],“机-电-控-磁-热”异构信号十分繁杂,而且系统涉及到的高速旋转件众多,因此表现出极强的异构信号耦合和多源扭振问题,此外,由于单一信息源提供的信息无法准确揭示电驱动系统的全貌,无法对多源异构信号进行准确测试、辨识和融合,所以多源数据融合成为揭示汽车电驱动系统动力学规律、验证系统动力学机理的关键[2]。在此背景下,深入分析汽车电驱动系统各个方面变得至关重要。通过精确测试、辨识和融合异构信号,研究人员可以更全面地理解汽车电驱动系统的行为,从而优化系统设计、提高性能,并解决异构信号带来的复杂问题。这一过程对于推动汽车电驱动技术的发展和应用至关重要。
本文基于多源异构信号特点、异构数据融合层次分类方法提出了一种汽车电驱动系统多源异构融合算法,利用实测汽车电驱动系统多源异构数据对融合方法进行了验证。
1 异构数据特点和融合分类
1.1 多源异构数据特点
多源异构数据是指来自不同来源、不同类型或不同结构的数据集合[3]。这种异构数据常常体现出数据的差异性,会使得采集到的数据不经过处理难以进行分析和利用,因此在进行分析、整合和利用的时候,需要处理其差异性,同时,为了提升数据的完整性和全面性,以及提高数据的准确性和可信度,必须进行多源融合。
多源异构数据主要有多源性、异构性和复杂性3个特点,具体如下。
多源性:指数据来自不同的数据源。例如,在汽车电驱动系统中的电流、电压、温度和转速等数据被视为多源异构数据,因为他们来自汽车电驱动系统中的不同组成部分。
异构性:指数据的类型、格式、结构等方面存在差异。例如,在汽车电驱动系统中,电流、转速、温度等数据的多源异构性体现在他们不仅单位和量纲不同,并且采样频率也存在差异。
复杂性:在电驱动系统中,需要综合考虑电流、转速、温度等多种异构数据。为有效处理这些数据的多源性和异构性,需要应用适当的融合技术。解决复杂性涉及数据预处理、特征工程和融合算法的运用,才能得到多源异构数据的融合结果。
1.2 多源异构数据融合层次分类
多源异构数据按融合层次分类可分为像素级融合、特征级融合和决策级融合3类[4]。
像素级融合是指直接对原始数据进行关联融合,不对原始数据作任何处理,在融合之后进行特征提取和做决策,如图1所示。这种融合方法在最大程度上保留了原始数据特征,能够提供更多的细节信息,但是融合受原始数据的不确定性、不完整性和不稳定性的影响较大并且对传感器、通信能力等要求较高。
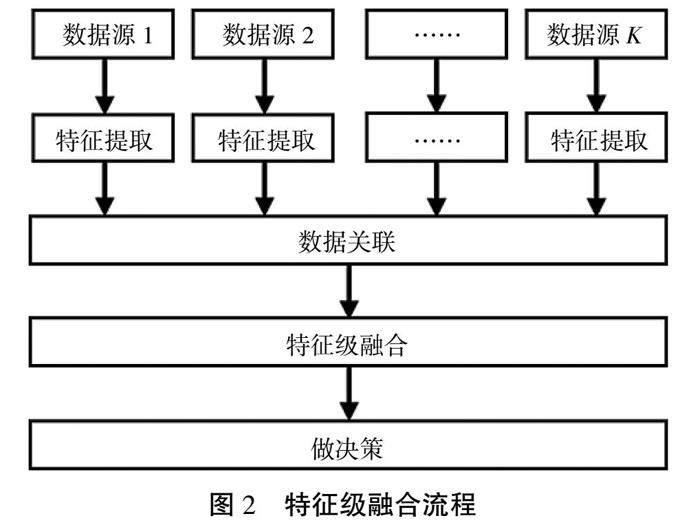
特征级融合是指先提取原始数据特征信息再进行融合,融合之后进行关联和做决策,如图2所示。特征信息可以是数量、方向、距离等信息。特征级融合的融合顺序使得其可以做到较好的信息压缩,较像素级融合而言有更好的实时性。同时由于特征提取部分直接与决策分析相关,因而在保证实时性的同时也能够最大程度地给出决策所需的特质信息,但是该方法在特征信息提取阶段会损失数据,可能会导致结果不精确。
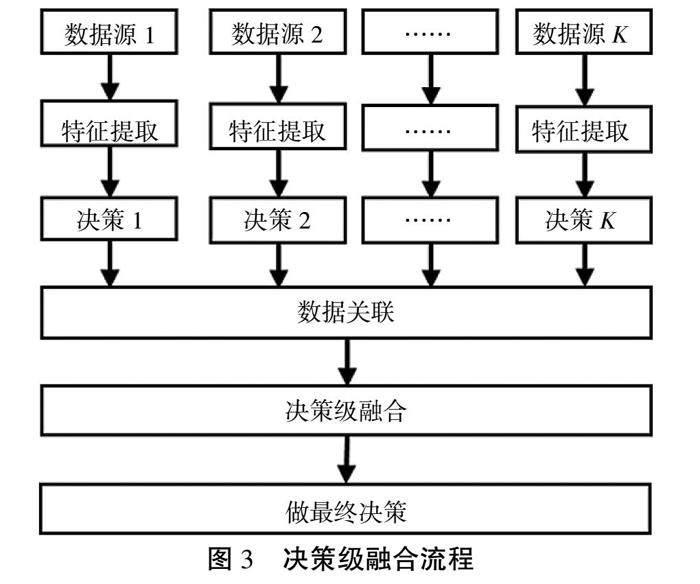
决策级融合是从各个特征源获取信息并进行决策之后再融合[5],并对融合之后的结果进行最终决策,如图3所示。该方法能提高容错性,对传感器的依赖较小,但是融合结果的精度低、决策的初始代价高。
3种融合层次各有其优势和限制,本文在处理汽车电驱动系统多源异构数据上选择特征级融合作为主要策略,其在保留原始数据关键特征的同时,通过信息压缩实现更好的实时性,相较于像素级融合具有更好的灵活性。同时,通过细致的特征提取和融合,特征级融合能够一定程度上克服决策级融合的精度问题,提高整体融合结果的准确性,使系统更具鲁棒性。
2 电驱动系统多源异构数据融合
在多源异构数据融合中,常见的算法包括D-S证据理论、支持向量机和加权融合[6-7]。D-S证据理论以其处理不确定性和冲突信息的优势而被选用,其计算过程较为复杂,涉及Belief函数和Plausibility函数的组合规则。支持向量机适用于高维空间的分类问题,通过找到最优超平面分离不同类别的数据,但在大规模数据上的计算开销较大。相对而言,加权融合算法简单直观,通过动态调整权重灵活适应不同数据源的贡献,提高整体融合效果。因此,本文选择使用加权平均融合算法对汽车电驱动系统多源异构信号进行特征级融合处理。
加权平均算法的核心原理是在多源异构信息融合中通过计算每个信息源的加权平均值来得到整体融合结果[8]。其步骤如下:首先,为每个信息源分配权重,这些权重反映了各信息源在最终融合结果中的相对贡献。这一权重的确定可以基于各信息源的可靠性、精度、信任度等因素,以确保对不同信息源进行合理的重要性分配。
其次,在每个时刻或数据更新周期,通过将每个信息源的值与其相应的权重相乘,得到各信息源的加权值。这一步考虑了不同信息源的权重,使得对于更为可信或准确的信息源,其在融合结果中的贡献更为突出。
最后,通过将所有信息源的加权值相加,得到加权平均值。这个最终结果即为融合后的数据,其中每个信息源的贡献被动态地考虑并体现在最终结果中。通过这种方式,加权平均算法能够灵活地适应不同信息源在不同时刻的贡献度,从而实现更为全面和准确的数据融合。其融合公式为
, (1)
式中:Fw为融合结果;?棕1,?棕2,…,?棕n为对应的权重;F1,F2,…,Fn为特征。
不同特征或数据源可能具有不同的数值范围,例如一个特征的数值范围在0到1之间,而另一个特征可能在几百或几千的数量级。如果在不进行归一化的情况下直接进行加权融合,数值较大的特征或数据源可能会在融合结果中占据主导地位,而数值较小的特征则可能被忽略。
因此,为确保不同特征或数据源的数值范围一致,防止某些特征或数据源对融合结果产生过大的影响[9],在融合前需对原始数据进行归一化处理,以保证各个特征的数值映射到相似的尺度范围内,使他们具有相对一致的权重,从而能够在加权融合中更公平地贡献到最终结果。
最小-最大值归一化的过程公式为
式中:Xn为归一化结果;X为当前值;Xmin为最小值;Xmax为最大值。
接着,在对原始数据进行归一化处理后,为确保各项归一化特征在融合中能够合理贡献,一般采用确定各项归一化特征结果的权重。这一步骤是为了在加权融合过程中考虑不同特征的相对重要性,避免某些特征对最终融合结果产生不必要的过大影响[9]。权重的确定可以根据特征的重要性、可靠性或者其他相关因素进行赋值。一种常见的做法是基于信息熵来为每个特征进行权重分配,公式为
将式(3)计算得到的权重和式(2)计算得到的归一化结果带入式(1)得到加权融合结果。
3 汽车电驱动多源异构数据融合
从电驱动系统总成下线检测试验台(图4)获取约5 000台电驱动系统下线检测数据,其中下线检测不合格产品约500台,合格产品约4 500台。为了进行全面的性能评估,我们从电驱动系统下线测试环节中整理了多个关键特征,包括平均转速、振动均方根值、A计权声压级等作为多源特征,接下来进行多源融合分析,并以下线检测结果作为判断结果。
首先,对于每个电驱动系统的特征,包括平均转速、振动均方根值、A计权声压级等,进行最小-最大归一化处理,将原始数据映射到[0, 1]的范围内,以消除不同特征之间的尺度差异,确保他们在融合分析中具有相似的权重。归一化的过程采用了式(2)。接下来,通过式(3)利用信息熵为每个特征计算权重。将归一化结果带入权重计算公式计算出权重系数见表1。
对于每个样本,使用之前计算得到的权重系数与归一化后的特征值,按照加权融合式(1)进行计算得到样本加权融合结果,将每个样本的融合结果与下线检测判断结果结合,得到下线检测合格产品与不合格产品分布区间,如图5所示。
从融合结果分布区间可看出,不合格产品融合分析结果大致分布于(300,350),合格产品融合分析结果大致分布于(170,300), 两者数据分布区间并不重叠,且与下线检测结果分布一致。探究不合格分布在(300,350)区间的原因发现当电驱动系统出现问题时会导致噪声或者振动值变大,从而使加权结果值变大。这突显了通过融合分析的敏感性,其能够捕捉到系统性能异常,并且可有效区分汽车电驱动系统质量。此外,数据分布在(170,350)的原因是因为在进行加权融合的过程中,由于平均转速提供的有用信息较少,故使用归一化的结果,会对融合结果产生很大的影响,因此,本文使用原始的平均转速数据进行融合。
4 结论
多源异构数据融合在深入理解汽车电驱动系统运行特征和解决复杂问题中可发挥关键作用。本文深入研究了汽车电驱动系统的多源异构数据融合问题。通过对多源异构数据特点和融合分类的探讨,提出了加权融合算法。在电驱动系统数据分析中,采用了加权融合算法对转速、噪声和振动等数据进行处理与融合。实验结果表明,融合分析能有效区分汽车电驱动系统的合格和不合格产品,为系统设计和性能优化提供了有力支持。
此外,加权融合算法在处理样本不足和特征不全面时表现不够完善,需要进一步优化以提高其稳定性和可靠性。
参考文献:
[1] 杜克强,许檬,李璇,等.纯电动汽车用高速电驱动系统发展综述[J].汽车实用技术,2022,47(3):10-16.
[2] 侯磊,范旭红,杜长虹,等.多合一电驱动系统的结构原理及CAE仿真分析[J].微特电机,2019,47(10):1-5,10.
[3] 唐莉,程世娟,张晓洁,等.多源异构数据贝叶斯变权融合可靠性评估模型[J].重庆理工大学学报(自然科学),2023,37(2):272-277.
[4] 祁友杰,王琦.多源数据融合算法综述[J].航天电子对抗,2017,33(6):37-41.
[5] 贺雅琪.多源异构数据融合关键技术研究及其应用[D].成都:电子科技大学,2018.
[6] 谢保林.基于DS证据理论的多传感器数据融合方法研究[D].郑州:河南大学,2022.
[7] 张宁波.基于SVM和DS证据理论的多传感器信息融合故障诊断[J].山西电子技术,2015(4):44-46.
[8] 袁维,李小春,白冰,等.透镜体对尾矿坝安全性影响的参数敏感性分析[J].中南大学学报(自然科学版),2013,44(3):1174-1183.
[9] 聂庆科,孙广,郝永攀,等.多源异构监测数据融合方法及应用[J].科学技术与工程,2022,22(13):5348-5357.
猜你喜欢
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
中国生物医学工程学报(2017年6期)2017-02-10
广西科技大学学报(2016年1期)2016-06-22
计算机工程(2015年4期)2015-07-05
制造技术与机床(2015年10期)2015-04-09
机电信息(2015年3期)2015-02-27
机械工程师(2015年10期)2015-02-02
噪声与振动控制(2015年4期)2015-01-01
